ELECTRA:将文本编码器作为判别器而不是生成器进行预训练
Introduction
- 提出了一种新的预训练策略:有一个判别式网络和一个生成式网络,判别式网络学习区分一个token是真实的还是生成式网络生成的替代品。(有点像GAN)
- 与Bert的区别:Bert相当于是一个生成器,用来生成被mask的token。ELECTRA是一个判别器,用来判别token是否被替换。
- 优势:从所有的输入文本中进行学习,而不仅仅是被mask掉的15%的token。
- 研究结果表明,区分真实的数据与具有挑战性的负样本的判别任务比现有的语言表征学习生成方法更具计算效率和参数效率。
Method
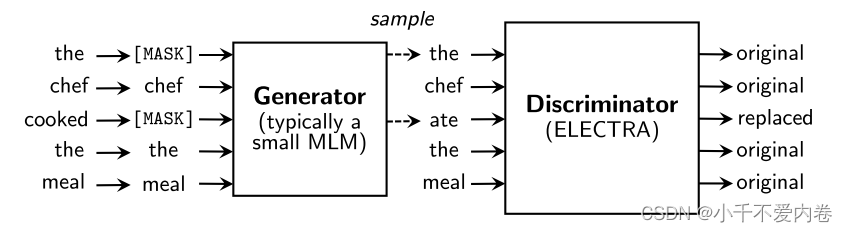
生成器可以使用一个小型的掩码语言模型,“生成”出被mask掉的字符,再将生成出来的语句送入判别器,使用判别器来判别所有的字符是否被替换了。
预训练之后,我们扔掉生成器,只在下游任务上微调鉴别器(ELECTRA模型)
生成器的输出用的是一个softmax,算出[mask],也就是x位置是xt的概率,并找出最大概率作为输出。
p G ( x t ∣ x ) = exp ( e ( x t ) T h G ( x ) t ) / ∑ x ′ exp ( e ( x ′ ) T h G ( x ) t ) p_G(x_t|\boldsymbol{x})=\exp\left(e(x_t)^T h_G(\boldsymbol{x})_t\right)/\sum_{x'}\exp\left(e(x')^T h_G(\boldsymbol{x})_t\right) pG(xt∣x)=exp(e(xt)ThG(x)t)/x′∑exp(e(x′)ThG(x)t)
也就是用xt的token embedding点乘生成器经过编码后的xt的embedding,然后除以所有的x的token embedding点乘的和,算出一个概率,找出最大的概率。
判别器也是一个encoder,经过编码之后,将向量映射到一维的向量空间中,再用一个sigmoid进行判断。
D ( x , t ) = s i g n o i d ( w T h D ( x ) t ) D(\boldsymbol{x},t)=\mathrm{signoid}(w^T h_D(\boldsymbol{x})_t) D(x,t)=signoid(wThD(x)t)
整个过程:
- 随机选择要被mask的token: m i ∼ unif { 1 , n } for i = 1 to k m_i\sim\operatorname{unif}\{1,n\}\operatorname{for}i=1\operatorname{to}k mi∼unif{ 1,n}fori=1tok
- 将这些位置的token替换为[mask]: x m a s s e d = R E P L A C E ( x , m , [ M A S K ] ) \boldsymbol{x}^{\mathrm{massed}}=\mathrm{REPLACE}\bigl(\boldsymbol{x},\boldsymbol{m},\left[\mathrm{MASK}\right]\bigr) xmassed=REPLACE(x,m,[MASK])
- 用生成器(掩码语言模型)网络预测被mask的token: x ^ i ∼ p G ( x i ∣ x m a s s e d ) f o r i ∈ m \hat{x}_i\sim p_G(x_i|\boldsymbol{x}^{\mathrm{massed}})\mathrm{for}i\in\boldsymbol{m} x^i∼pG(xi∣xmassed)fori∈m
- 用预测结果替换[mask] token: x c o r r u p t = R E P L A C E ( x , m , x ^ ) \boldsymbol{x}^{\mathrm{corrupt}}=\mathrm{REPLACE}(\boldsymbol{x},\boldsymbol{m},\hat{\boldsymbol{x}}) xcorrupt=REPLACE(x,m,x^)
- 再用判别器判别每个位置,是否是被替换了的。
损失函数:
L M L M ( x , θ G ) = E ( ∑ i ∈ m − log p G ( x i ∣ x m a s s e d ) ) \mathcal{L}_{\mathrm{MLM}}(\boldsymbol{x},\theta_G)=\mathbb{E}\left(\sum_{i\in\boldsymbol{m}}-\log p_G(x_i|\boldsymbol{x}^{\mathrm{massed}})\right) LMLM(x,θG)=E(i∈m∑−logpG(xi∣xmassed))
L B s c ( x , θ D ) = E ( ∑ t = 1 n − 1 ( x t o o r q t = x t ) log D ( x o o m p t , t ) − 1 ( x t o n r p t ≠ x t ) log ( 1 − D ( x o o r t , t ) ) ) {\mathcal{L}}_{\mathrm{Bsc}}(\boldsymbol{x},\theta_{D})=\mathbb{E}\left(\sum_{t=1}^{n}-1(x_{t}^{o o r q t}=x_{t})\log D(\boldsymbol{x}^{o o m p t},t)-1(x_{t}^{o n r p t}\neq x_{t})\log(1-D(\boldsymbol{x}^{o o r t},t))\right) LBsc(x,θD)=E(t=1∑n−1(xtoorqt=xt)logD(xoompt,t)−1(xtonrpt=xt)log(1−D(xoort,t)))
最小化综合损失:
min θ G , θ D ∑ x ∈ X L M L M ( x , θ G ) + λ L D i s c ( x , θ D ) \operatorname*{min}_{\theta_G,\theta_D}\sum_{\boldsymbol{x}\in\mathcal{X}}\mathcal{L}_{\mathrm{MLM}}(\boldsymbol{x},\theta_G)+\lambda\mathcal{L}_{\mathrm{Disc}}(\boldsymbol{x},\theta_D) θG,θDminx∈X∑LMLM(x,θG)+λLDisc(x,θD)
反向传播判别器的时候并不会经过生成器。
和GAN的区别:
- 生成器用极大似然训练的,而不是对抗性训练的。
- 如果生成器碰巧生成了正确的样本,token应该被认为是“真实的”。
思考:
-
使用小型的生成器,相比于大型生成器,降低了训练消耗。
-
为什么这种训练方式能够提升模型性能?和随机替换成其他token有什么区别?
相比于随机替换成其他token,使用一个生成器将生成的内容替换mask,使得生成的这个词比随机替换的词在语义上更接近真实词语,这就使得判别器需要更加深入理解上下文语意才能判别出这个词语是否被替换掉,提升了判别器的理解能力。