Kafka分布式发布订阅消息系统

目录
1. 概述
Kafka是由Apache软件基金会开发的一个开源流处理平台,它由Scala和Java语言编写,是一个基于Zookeeper系统的分布式发布订阅消息系统,该项目的设计初衷是为实时数据提供一个统一、高通量、低等待的消息传递平台。
主要应用场景是:日志收集系统和消息系统。分布式消息传递基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。
有两种主要的消息传递模式:点对点传递模式、发布-订阅模式。
大部分的消息系统选用发布-订阅模式。

1.1 点对点消息传递模式
在点对点消息系统中,消息持久化到一个queue(队列)中。此时,将有一个或多个消费者消费队列中的数据。但是一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除。该模式即使有多个消费者同时消费数据,也能保证数据处理的顺序。

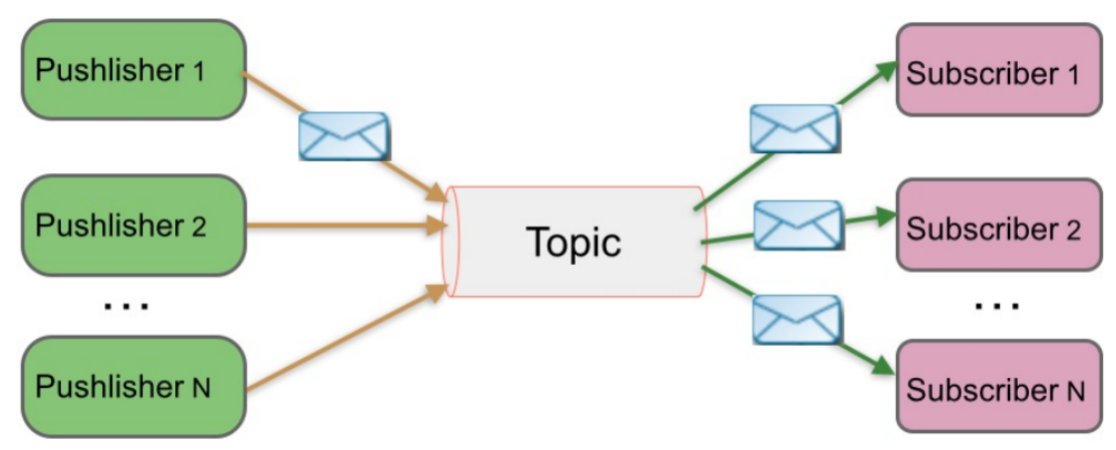
1.2 发布-订阅消息传递模式
在发布-订阅消息系统中,消息被持久化到一个topic中。与点对点消息系统不同的是,消费者可以订阅一个或多个topic(分类),消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者称为发布者,消费者称为订阅者。
1.3 Kafka特点
高吞吐率。即使在廉价的商用机器上也能做到单机支持每秒100000条消息的传输。
支持消息分区,及分布式消费,同时保证每个分区内消息顺序传输。
同时支持离线数据处理和实时数据处理。
Scale out:支持在线水平扩展
1.4 kafka拓扑图
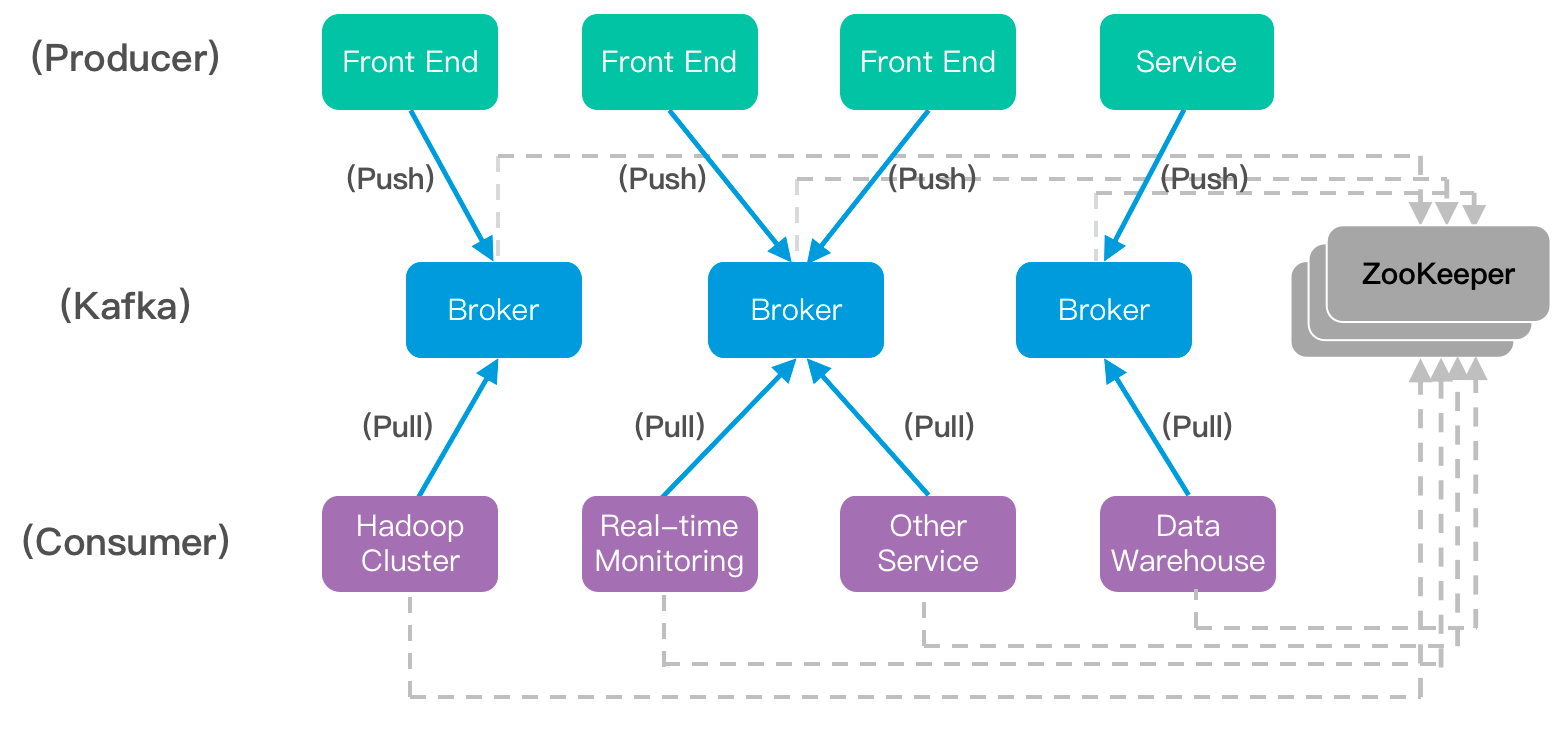
一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干Broker(Kafka支持水平扩展,一般broker(代理)数量越多,集群吞吐率越高),若干Consumer,以及一个Zookeeper集群。
Kafka通过Zookeeper管理集群配置,选举Leader,以及在Consumer发生变化时进行rebalance。Producer使用push模式将消息发布到Broker,Consumer使用pull模式从Broker订阅并消费消息。
Broker:Kafka集群包含一个或多个服务实例,这些服务实例被称为Broker。
Producer:负责发布消息到Kafka Broker。
Consumer:消息消费者,从Kafka Broker读取消息的客户端。
2. Kafka工作原理
2.1 Kafka核心组件介绍
| 组件名称 | 相关说明 |
|---|---|
| Topic | 特定类别消息流称为主题,数据存在主题中,主题被拆分成分区 |
| Partition | 主题的数据分割为一个或多个分区,每个分区的数据使用多个segment文件存储,分区中的数据是有序的 |
| Offset | 每个分区消息具有的唯一序列标识 |
| Replica | 副本只是一个分区的备份,它们用于防止数据丢失 |
| Producer | 生产者即数据发布者,该角色将消息发布到Kafka集群主题中 |
| 组件名称 | 相关说明 |
|---|---|
| Consumer | 消费者可从Broker中读取数据,可消费多个主题数据 |
| Broker | 每个Kafka服务节点都为Broker,Broker接收消息后,将消息追加到segment文件中 |
| Leader | 负责分区的所有读写操作 |
| Follower | 跟随领导指令,若Leader发生故障则选一个Follower为新Leader |
| Consumer Group | 实现一个主题消息的广播和单播的手段 |
2.2 Kafka工作流程分析
2.2.1 生产者生产消息过程
生产者向Kafka集群中生产消息。Producer是消息的生产者,通常情况下,数据消息源可是服务器日志、业务数据及Web服务数据等,生产者采用推送的方式将数据消息发布到Kafka的主题中,主题本质就是一个目录,而主题是由Partition Logs(分区日志)组成,每条消息都被追加到分区中。
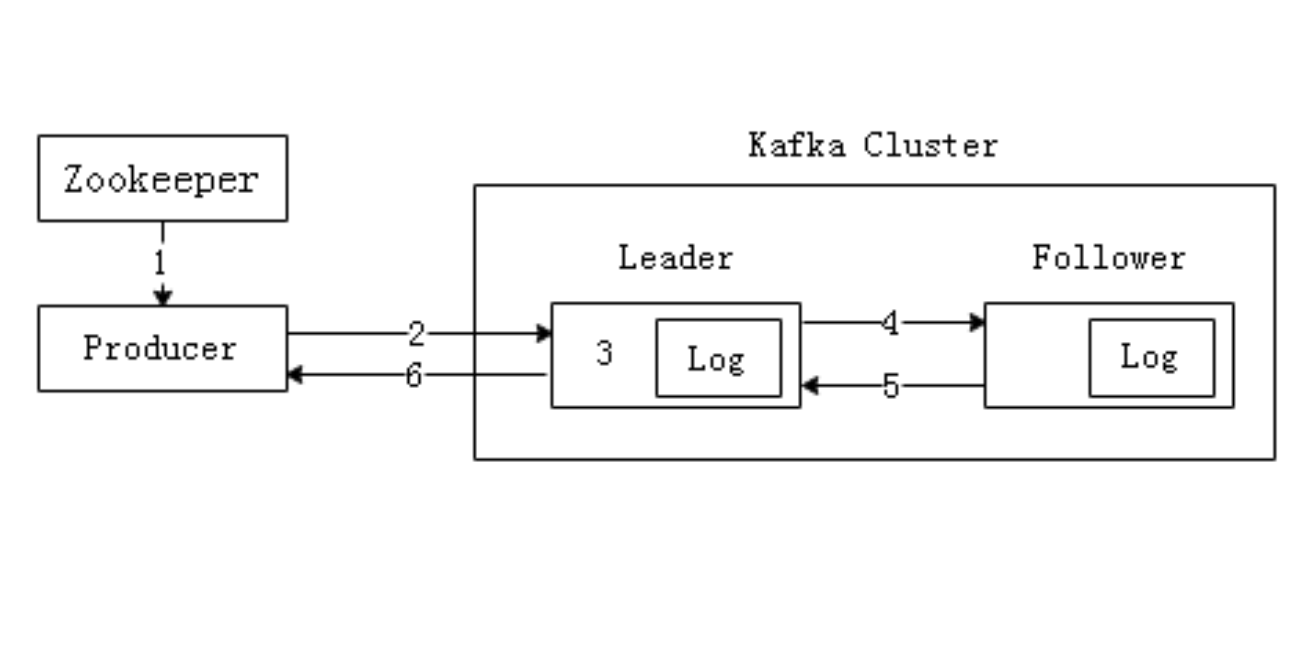
- Producer先读取Zookeeper的“/brokers/.../state”节点中找到该Partition的Leader。
- Producer将消息发送给Leader。
- Leader负责将消息写入本地分区Log文件中。
- Follower从Leader中读取消息,完成备份操作。
- Follower写入本地Log文件后,会向Leader发送Ack,每次发送消息都会有一个确认反馈机制,以确保消息正常送达。
- Leader收到所有Follower发送的Ack后,向Producer发送Ack,生产消息完成。
2.2.2 消费者消费消息过程
Kafka采用拉取模型,由消费者记录消费状态,根据主题、Zookeeper集群地址和要消费消息的偏移量,每个消费者互相独立地按顺序读取每个分区的消息,消费者消费消息的流程图如下所示。
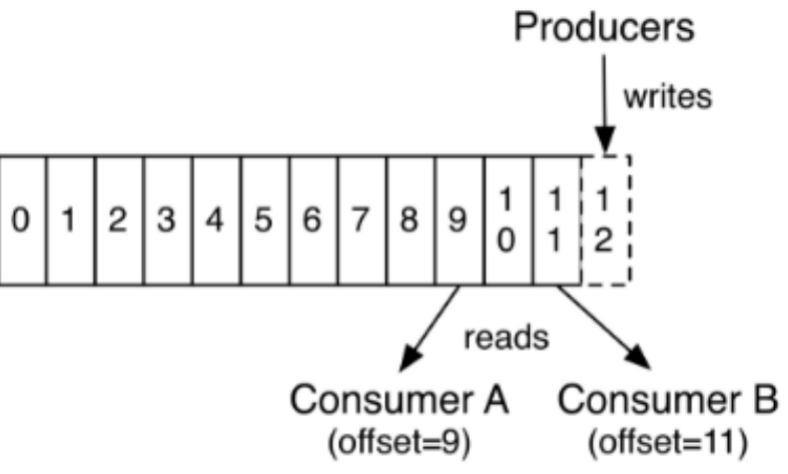
2.2.3 Kafka Topics
每条发布到Kafka的消息都有一个类别,这个类别被称为Topic,也可以理解为一个存储消息的队列。例如:天气作为一个Topic,每天的温度消息就可以存储在“天气”这个队列里。
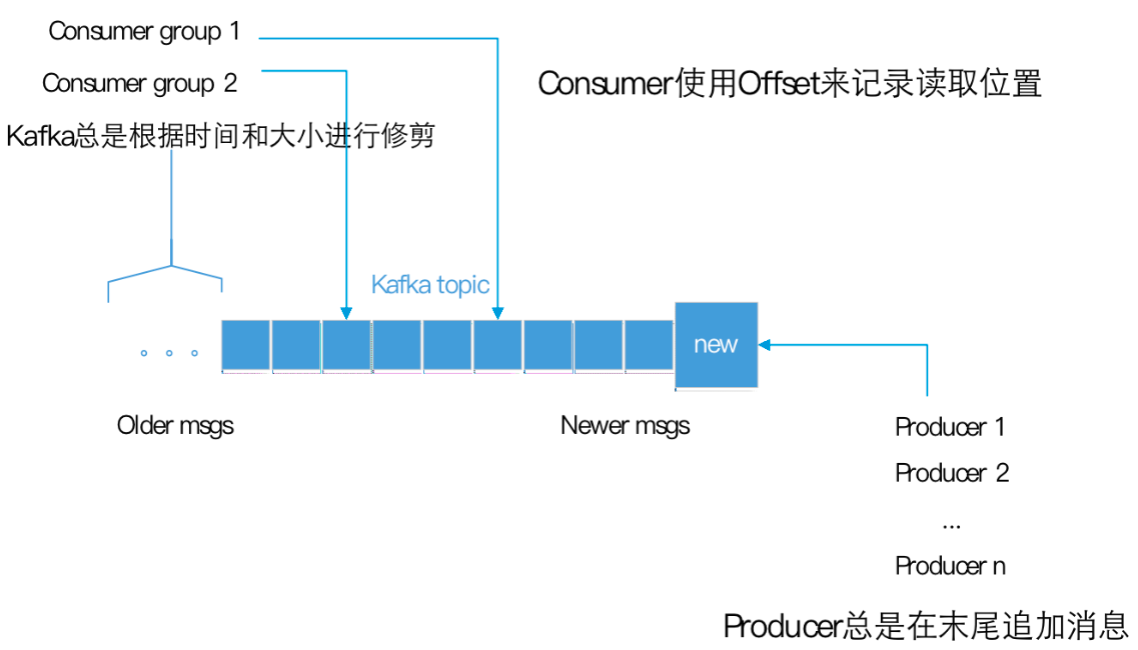
每条发布到Kafka的消息都有一个类别,这个类别被称为Topic,也可以理解为一个存储消息的队列。例如:天气作为一个Topic,每天的温度消息就可以存储在“天气”这个队列里。
图片中的蓝色框为Kafka的一个Topic,即可以理解为一个队列,每个格子代表一条消息。生产者产生的消息逐条放到Topic的末尾。消费者从左至右顺序读取消息,使用Offset来记录读取的位置。
2.2.4 Kafka Partition
为了提高Kafka的吞吐量,物理上把Topic分成一个或多个Partition,每个Partition都是有序且不可变的消息队列。每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
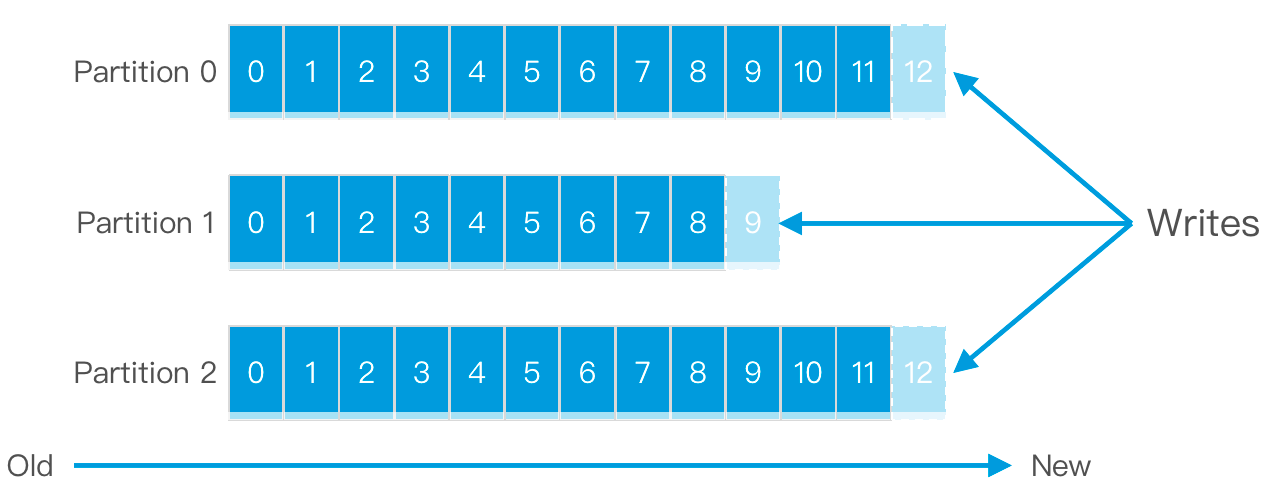
每个topic被分成多个partition(区),每个partition在存储层面对应一个log文件,log文件中记录了所有的消息数据。
引入Partition机制,保证了Kafka的高吞吐能力,因为Topic的多个Partition分布在不同的Kafka节点上,这样一来多个客户端(Producer和Consumer)就可以并发访问不同的节点对一个Topic进行消息的读写。
2.2.4 Kafka Partition offset
每条消息在文件中的位置称为offset (偏移量),offset是一个long型数字,它唯一标记一条消息。消费者通过 (offset、partition、topic) 跟踪记录。

任何发布到此Partition的消息都会被直接追加到log文件的尾部。
2.2.5 offset存储机制
Consumer在从broker读取消息后,可以选择commit,该操作会在Kakfa中保存该Consumer在该Partition中读取的消息的offset。
该Consumer下一次再读该Partition时会从下一条开始读取。
通过这一特性可以保证同一消费者从Kafka中不会重复消费数据。
2.2.6 Consumer group
每个consumer都属于一个consumer group,每条消息只能被consumer group中的一个Consumer消费,但可以被多个consumer group消费。即组间数据是共享的,组内数据是竞争的。
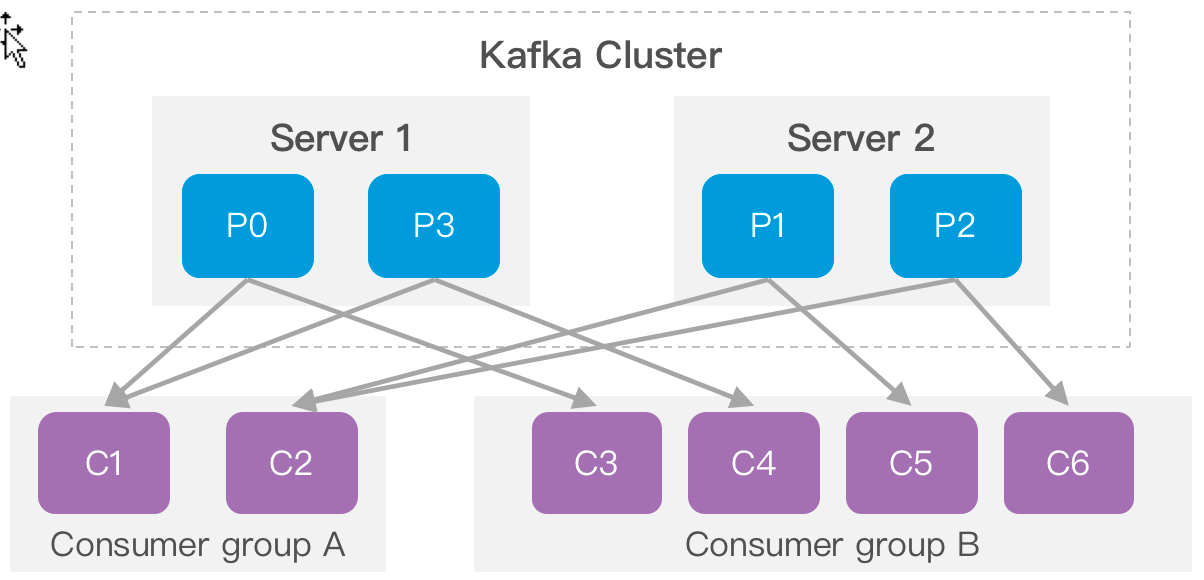
Consumer group A有两个消费者来读取4个Partition中数据;Consumer group B 有四个消费者来读取4个Partition中数据。
Topic的Partition数量可以在创建时配置。
Partition数量决定了每个Consumer group中并发消费者的最大数量。
3. kafka安装
#上传并解压
[root@master apps]# tar -zxvf kafka_2.12-1.1.0.tgz
#修改文件名
[root@master apps]# mv kafka_2.12-1.1.0 kafka3.1 修改配置文件
server.properties
zookeeper.connect=master:2181,slave01:2181,slave02:2181
server.properties参考
-----------------------------------------------------------------
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
port=19092 #当前kafka对外提供服务的端口默认是9092
host.name=192.168.7.100 #这个参数默认是关闭的,在0.8.1有个bug,DNS解析问题,失败率的问题。
num.network.threads=3 #这个是borker进行网络处理的线程数
num.io.threads=8 #这个是borker进行I/O处理的线程数
log.dirs=/opt/kafka/kafkalogs/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
num.partitions=1 #默认的分区数,一个topic默认1个分区数
log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天
message.max.byte=5242880 #消息保存的最大值5M
default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
replica.fetch.max.bytes=5242880 #取消息的最大直接数
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
zookeeper.connect=192.168.7.100:12181,192.168.7.101:12181,192.168.7.107:1218 #设置zookeeper的连接端口3.2 分发安装包
[root@master apps]$ scp -r kafka hd@slave01:/home/hd/apps
[root@master apps]$ scp -r kafka hd@slave02:/home/hd/apps3.3 再次修改文件
依次修改各服务器上配置文件的的broker.id,分别是1,2,3不得重复。
3.4 启动集群
先启动zookeeper
第一台:zkServer.sh start
第二台:zkServer.sh start
第三台:zkServer.sh start
启动kafka服务
第一台:[root@master bin]$./kafka-server-start.sh -daemon ../config/server.properties
第二台:[root@master bin]$./kafka-server-start.sh -daemon ../config/server.properties
第三台:[root@master bin]$./kafka-server-start.sh -daemon ../config/server.properties
关闭kafka服务
第一台:[root@master bin]$./kafka-server-stop.sh
第二台:[root@master bin]$./kafka-server-stop.sh
第三台:[root@master bin]$./kafka-server-stop.sh 4. Kafka常用操作命令
#创建一个kafka类别
[root@master bin]# ./kafka-topics.sh --create --zookeeper master:2181,slave01:2181,slave02:2181 --replication-factor 1 --partitions 1 --topic newtitle
-------------------------------------------------------------------------------
#--replication-factor 2 #复制两份
#--partitions 1 #创建1个分区
#--topic #主题
-------------------------------------------------------------------------------
#修改一个kafka类别
[root@master bin]# ./kafka-topics.sh --alter --topic newtitle --zookeeper master:2181,slave01:2181,slave02:2181 --partitions 3
#删除类别
[root@master bin]# .kafka-topics.sh --delete --topic newtitle --zookeeper master:2181,slave01:2181,slave02:2181
#不能删除
#彻底删除一个topic,需要在server.properties中配置delete.topic.enable=true,否则只是标记删除
#查看所有的类别
[root@master bin]# ./kafka-topics.sh --list --zookeeper master:2181,slave01:2181,slave02:2181
[root@master bin]# ./kafka-topics.sh --describe --topic newtitle --zookeeper master:2181,slave01:2181,slave02:2181
-------------------------------------------------------------------------------
Topic:newtitle PartitionCount:3 ReplicationFactor:1 Configs:
Topic: newtitle Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: newtitle Partition: 1 Leader: 3 Replicas: 3 Isr: 3
Topic: newtitle Partition: 2 Leader: 1 Replicas: 1 Isr: 1
PartitionCount:topic对应的partition的个数
ReplicationFactor:topic对应的副本因子,说白就是副本个数
Partition:partition编号,从0开始递增
Leader:当前partition起作用的breaker.id
Replicas: 当前副本数据坐在的breaker.id,是一个列表,排在最前面的其作用
Isr:当前kakfa集群中可用的breaker.id列表
-------------------------------------------------------------------------------
#生产者
[root@master bin]# ./kafka-console-producer.sh --broker-list master:9092 --topic newtitle
#消费者
[root@master bin]# ./kafka-console-consumer.sh --zookeeper master:2181,slave01:2181,slave02:2181 --topic newtitle --from-beginning 5. Kafka API操作
kafkaProducer常用API
| 方法名称 | 相关说明 |
|---|---|
| abortTransaction() | 终止正在进行的事物 |
| close() | 关闭这个生产者 |
| flush() | 调用此方法使所有缓冲的记录立即发送 |
| partitionsFor (java.lang.String topic) | 获取给定主题的分区元数据 |
| send (ProducerRecord<K,V> record) | 异步发送记录到主题 |
KafkaConsumer常用API
| 方法名称 | 相关说明 |
|---|---|
| subscribe(java.util.Collection<java.lang.String> topics) | 订阅给定主题列表以获取动态分区 |
| close() | 关闭这个消费者 |
| wakeup() | 唤醒消费者 |
| metrics() | 获取消费者保留的指标 |
| listTopics() | 获取有关用户有权查看的所有主题的分区的元数据 |
导入Maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>1.0.0</version>
</dependency>ProducerTest.java
package org.example;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
public class ProducerTest {
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers","192.168.20.52:9092,192.168.20.39:9092,192.168.20.56:9092");
props.put("acks", "all"); // 记录完整提交,最慢的但是最大可能的持久化
props.put("retries", 3); // 请求失败重试的次数
props.put("batch.size", 16384); // batch的大小
props.put("linger.ms", 1);
// 默认情况即使缓冲区有剩余的空间,也会立即发送请求,设置一段时间用来等待从而将缓冲区填的更多,单位为毫秒,producer发送数据会延迟1ms,可以减少发送到kafka服务器的请求数据
props.put("buffer.memory", 33554432); // 提供给生产者缓冲内存总量
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 序列化的方式,
// ByteArraySerializer或者StringSerializer
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10000; i++) {
// 三个参数分别为topic, key,value,send()是异步的,添加到缓冲区立即返回,更高效。
producer.send(new ProducerRecord<String, String>("mytopic", "key" + i, "value" + i));
System.out.println("===>正在发送key->"+i);
Thread.sleep(1000);
}
producer.close();
}
}ConsumerTest.java
package org.example;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerTest {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers","192.168.20.52:9092,192.168.20.39:9092,192.168.20.56:9092");
props.put("group.id", "test"); // cousumer的分组id
props.put("enable.auto.commit", "true"); // 自动提交offsets
props.put("auto.commit.interval.ms", "1000"); // 每隔1s,自动提交offsets
props.put("session.timeout.ms", "30000"); // Consumer向集群发送自己的心跳,超时则认为Consumer已经死了,kafka会把它的分区分配给其他进程
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 反序列化器
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("mytopic")); // 订阅的topic,可以多个
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf(
"offset = %d, key = %s, value = %s", record.offset(), record.key(), record.value());
System.out.println();
}
}
}
}6. Kafka Streams概述
Kafka Streams是Apache Kafka开源的一个流处理框架,基于Kafka的生产者和消费者,为开发者提供流式处理能力,具有低延迟性、高扩展性、弹性、容错的特点,易于集成到现有应用程序中。它是一套处理分析Kafka中存储数据的客户端类库,处理完的数据可重新写回Kafka,也可发送给外部存储系统。
在流式计算框架模型中,通常需要构建数据流的拓扑结构,例如生产数据源、分析数据的处理器及处理完后发送的目标节点,Kafka流处理框架同样将“输入主题自定义处理器输出主题”抽象成一个DAG拓扑图。
生产者作为数据源不断生产和发送消息至Kafka的testStreams1主题中,通过自定义处理器对每条消息执行相应计算逻辑,最后将结果发送到Kafka的testStreams2主题中供消费者消费消息数据。
7. Kafka Streams开发单词计数
- 打开pom.xml文件,添加Kafka Streams依赖。
- 创建LogProcessor类,并继承Streams API中的Processor接口,实现单词计数业务逻辑。
- 单词计数的业务功能开发完成后,Kafka Streams需要编写一个运行主程序的类App,用来测试LogProcessor业务程序。
- 在hadoop01节点创建testStreams1和testStreams2主题。
- 分别在hadoop01和hadoop02节点启动生产者服务和消费者服务。
- 运行App主程序类。在生产者服务节点(hadoop01)中输入测试语句,返回消费者服务节点(hadoop02)中查看执行结果。
Pom.xml
添加依赖的时候注意版本号,避免兼容性问题
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.0.0</version>
</dependency>xLogProcessor.java
public void init (ProcessorContext processorContext) : 初始化上下文对象
public void process(byte[] key, byte[] value) :接收到一条消息时,会调用该方法处理并更新状态进行存储
public void close() :资源清理
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext;
import java.util.HashMap;
public class LogProcessor implements Processor<byte[],byte[]> {
//上下文对象
private ProcessorContext processorContext;
@Override
public void init(ProcessorContext processorContext) {
//初始化方法
this.processorContext=processorContext;
}
@Override
public void process(byte[] key, byte[] value) {
//处理一条消息
String inputOri = new String(value);
HashMap <String,Integer> map = new HashMap<String,Integer>();
int times = 1;
if(inputOri.contains(" ")){
//截取字段
String [] words = inputOri.split(" ");
for (String word : words){
if(map.containsKey(word)){
map.put(word,map.get(word)+1);
}else{
map.put(word,times);
}
}
}
inputOri = map.toString();
processorContext.forward(key,inputOri.getBytes());
}
@Override
public void close() {}
}App.java
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorSupplier;
import java.util.Properties;
public class App {
public static void main(String[] args) {
//声明来源主题
String fromTopic = "testStreams1";
//声明目标主题
String toTopic = "testStreams2";
//设置参数
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG,"logProcessor");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"master:9092,slave01:9092,slave02:9092");
//实例化StreamsConfig
StreamsConfig config = new StreamsConfig(props);
//构建拓扑结构
Topology topology = new Topology();
//添加源处理节点,为源处理节点指定名称和它订阅的主题
topology.addSource("SOURCE",fromTopic)
//添加自定义处理节点,指定名称,处理器类和上一个节点的名称
.addProcessor("PROCESSOR", new ProcessorSupplier() {
@Override
public Processor get() {//调用这个方法,就知道这条数据用哪个process处理,
return new LogProcessor();
}
},"SOURCE")
//添加目标处理节点,需要指定目标处理节点的名称,和上一个节点名称。
.addSink("SINK",toTopic,"PROCESSOR");//最后给SINK
//实例化KafkaStreams
KafkaStreams streams = new KafkaStreams(topology,config);
streams.start();
}
}执行测试
代码编写完成之后,在master节点创建testStreams1,testStreams2主题
#创建来源主题
[root@master bin]# ./kafka-topics.sh --create --zookeeper master:2181,slave01:2181,slave02:2181 --replication-factor 1 --partitions 1 --topic testStreams1#创建目标主题
[root@master bin]# ./kafka-topics.sh --create --zookeeper master:2181,slave01:2181,slave02:2181 --replication-factor 1 --partitions 1 --topic testStreams2创建好主题之后,分别在master节点和slave01节点启动生产者服务和消费者服务。
#启动生产者服务命令
[root@master bin]# ./kafka-console-producer.sh --broker-list master:2181,slave01:2181,slave02:2181 --topic testStreams1 #启动消费者服务命令
[root@master bin]# ./kafka-console-consumer.sh --zookeeper master:2181,slave01:2181,slave02:2181 --topic testStreams2 --from-beginning最后,运行App主程序类,至此我们完成kafka streams所需的环境测试。
在生产者服务节点输入“hello kafka hello spark hello hadoop ” ,返回消费者节点查看运行结果。
关注博主下篇更精彩
一键三连!!!
一键三连!!!
一键三连!!!
感谢一键三连!!!