前言:
在java中生成pdf基本都会使用itextpdf,但是使用该第三方jar包会在生成的pdf中添加关于工具名称和版本号等信息,且目前并未提供方法进行修改,所以当我们需要清除一下元数据信息时,可以使用如下方式:

生成pdf测试代码如下:
package org.example;
import com.itextpdf.text.*;
import com.itextpdf.text.pdf.*;
import com.sun.org.apache.bcel.internal.generic.NEW;
import sun.misc.Unsafe;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.Map;
public class Main {
public static void main(String[] args) {
String FILE_DIR = "./";
//Step 1—Create a Document.
Document document = new Document();
try {
//Step 2—Get a PdfWriter instance.
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(FILE_DIR + "createSamplePDF2.pdf"));
//Step 3—Open the Document.
document.open();
//Step 4—Add content.
document.add(new Paragraph("Hello World"));
//Step 5—Close the Document.
document.close();
} catch (Exception ex) {
System.out.print(ex);
}
}
}反射修改(失败):
方案一:
查看了itextpdf版本的生成主要是通过com.itextpdf.text的Version方法,所以一开始是想着修改iText和release,但是忽略了实例化的问题,失败:

虽然失败但是也做个记录,讲述为何失败,反射代码如下:
Class clazz = Class.forName("com.itextpdf.text.Version");
Object object = clazz.newInstance();
Field field = clazz.getDeclaredField("iText");
field.setAccessible(true);
System.out.println("field.get:" + field.get(object));
field.set(object,"aaaaaa");
System.out.println("field.get change:" + field.get(object));
String string = Version.getInstance().getVersion();
System.out.print(string);可以看到虽然反射修改成功,但是当调用Version.getInstance().getVersion()的时候又会实例化一个新的对象,这样我们之前修改的就会失效,所以这种方法失败。

方案二:
在调试中我发现其获取的pdf信息都存放在一个数组中:
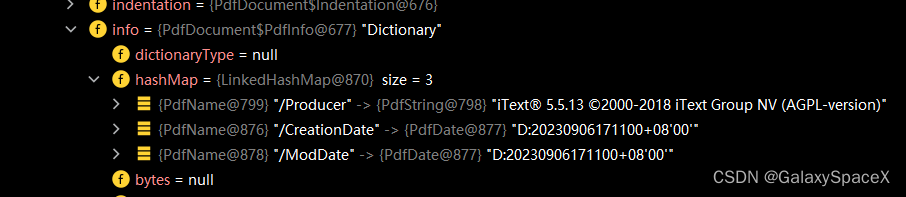
存储位置为PdfDictionary类中的hashMap中:

并且我发现其中还有remove函数,这样我可以调用remove删除其中包含敏感信息的数组:

反射代码如下:
Class documentclass = document.getClass();
Field field = documentclass.getDeclaredField("listeners");
field.setAccessible(true);
ArrayList<DocListener> arrayList = (ArrayList<DocListener>) field.get(document);
for (int i = 0; i < arrayList.size(); i++) {
PdfDocument pdfdocument = (PdfDocument) arrayList.get(i);
Class pdfcumentclass = pdfdocument.getClass();
field = pdfcumentclass.getDeclaredField("info");
field.setAccessible(true);
PdfDictionary pdfDictionary = (PdfDictionary) field.get(pdfdocument);
PdfObject pdfObject = pdfDictionary.get(PdfName.PRODUCER);
pdfDictionary.remove(PdfName.PRODUCER);
System.out.print(field.get(pdfdocument));
}执行成功后可以看到对应的producer已经被删除:
 但是最后生成的文档发现还是存在,跟了下源码才找到问题。
但是最后生成的文档发现还是存在,跟了下源码才找到问题。
原理分析:
最后生成pdf主要执行代码位于PdfDocument类的close方法,其中中间代码主要生成不同的流,生成最后的敏感信息位于最后的writer.close方法中:

 进入PdfWriter的close方法最重要的代码为如下两处,第一处为调用Version.getInstance().getVersion(),生成对应的版本信息然后存储在数组中,然后调用addToBody写入:
进入PdfWriter的close方法最重要的代码为如下两处,第一处为调用Version.getInstance().getVersion(),生成对应的版本信息然后存储在数组中,然后调用addToBody写入:

然后调用PdfDictionary的方法toPdf写入文件中:
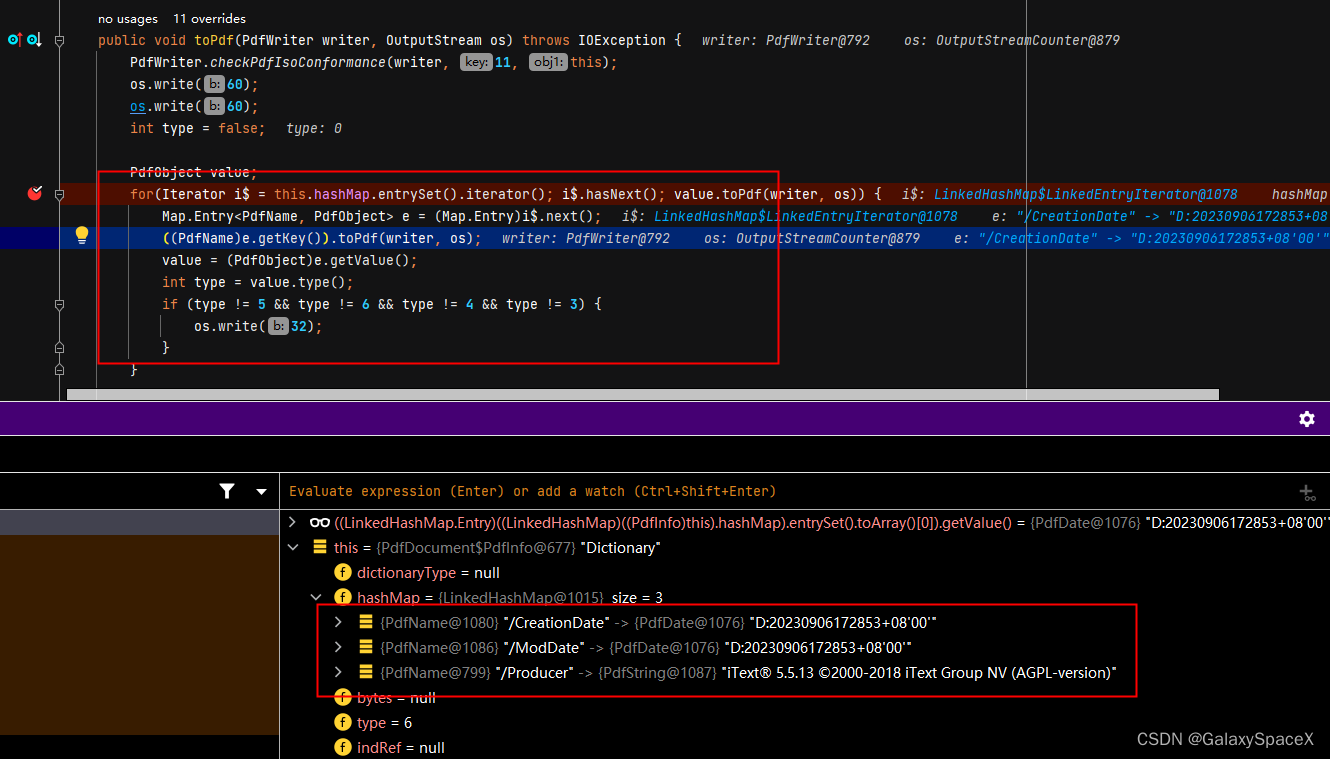 跟了一下流程就发现没有办法进行反射修改,其中也没有什么判断可以让我通过反射修改后跳入其他逻辑,并且其调用Version.getInstance().getVersion()新实例化了一个对象,我们没办法通过反射修改。所以向通过反射修改的方法这里行不通,只能修改jar包:
跟了一下流程就发现没有办法进行反射修改,其中也没有什么判断可以让我通过反射修改后跳入其他逻辑,并且其调用Version.getInstance().getVersion()新实例化了一个对象,我们没办法通过反射修改。所以向通过反射修改的方法这里行不通,只能修改jar包:
修改jar包:
源码下载地址:
https://github.com/itext/itextpdf这里修改有两种方式,一种是直接反编译后替换打包:
jar -xf itextpdf-5.5.12.jar
javac -cp Version.java
jar -cvfm0 itextpdf-5.5.12.jar META-INF/MANIFEST.MF ./其中找到源码中的Version.java,修改代码:

然后编译后替换重打包即可
编译源代码:
另外就是编译源代码,代码下载完成后,修改源代码后,执行如下命令:
mvn clean install -Dmaven.test.skip=true执行完成后,会有三个编译失败,这个需要另外设置环境,不过不需要,因为我们主要编译iText Core已经成功,直接在文件夹下就可以看到编译成功的文件。

后记:
看了下最新版本的itextpdf,发现版本已经变成了静态变量,那就可以用方案一的办法进行反射修改就可以了,就不用编译源码这么麻烦了。
