一 关于nginx uri过往整理
说明: 第'二'部分案例比较'深入',初学者可以选择'跳过'这些细节以下'涉及':
1) location 与'$uri' --> '路由匹配' --> 通过'debug日志观察'
2) proxy_paas --> attach_url'是否'有,有'是否是变量',决定透传给'上游uri'的形式
3) $request、$request_uri、$uri --> '日志记录和响应体值形式'
4) if ($uri ~ '^([a-zA-Z0-9=%&?\-_]+$)') --> 'URI白名单或者URI截断'
5) rewrite .. break 、set、proxy_paas 改变 '$args'nginx(七十九)rewrite模块指令再探之(一)变量漫谈
二 关于$uri和$request_uri难点探究
① 相关参考
② 转义、编码、解码
escape --> '转义'
encode --> '编码'
decode --> '解码'
遗留:编码和转义是'一个意思'吗? ③ 日志细节探讨
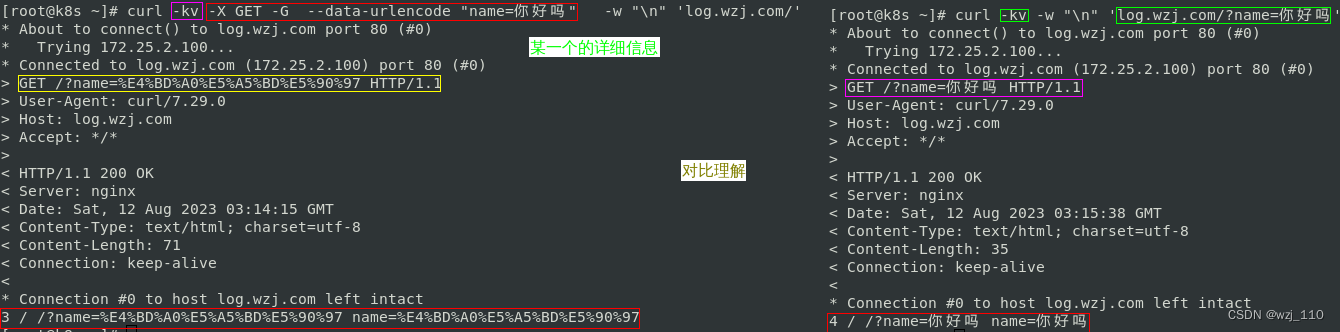
1) 关注: log_format 'escape属性'探究
2) 对比'nginx日志'和'响应体'理解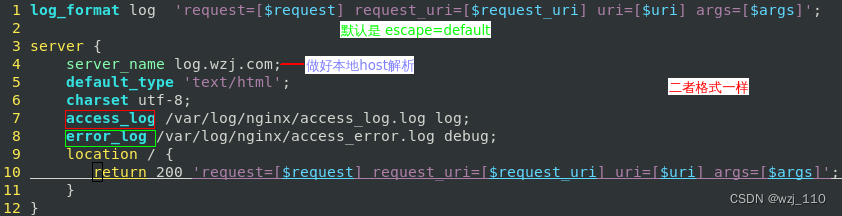
说明: 默认是'escape=default'
细节: 浏览器自动对'中文'进行'编码'传输
原因: 由于'中文'不是浏览器认为的合法'ASCII字符',会按照'既定的规则'进行'编码'
'特殊的字符'转换成'ASCII码'规则:
1) 一个'中文'字符'utf-8'编码,对应'3'个'字节'
重点:utf-8编码之后得到的已经'没有非ascii'的其他字符了,'都是ascii字符'
2) 每个'字节'对应'%hex%hex%hex'形式
3) 例如:'我'--> '%E6%88%91' --> '理解'为三个'ASCII'字符
思考1: 为什么'nginx日志'和'响应体'不一样?
1) escape '转义' --> '仅仅是nginx 日志格式的可读性'
2) charset '编码' --> 设置'网页[响应体]'编码格式,而页面的解码与编码不一致则导致'乱码'
思考2: 为什么'$args'没有转义,nginx到底对于'url各部分'是如何处理转义的?
思考3: 为什么'十六进制的%'变为'\x'


④ %探究
1) 问题引入: '$uri'和'$request_uri'为什么'不一致'?

2) 测试2:在一个'uri中'包含了特殊字符'%'
现象: '400'报错
原理: '%号'后面如果'不是两位16进制数'会导致异常'NGX_HTTP_PARSE_INVALID_REQUEST'
目的: 防止'sql注入'等'攻击'风险
补充: 如果'特殊字符%'用在'查询参数中'则没问题

3) 测试3: 如何传递'%'特殊字符呢? --> 将'%'符号转义为'%25'
注意:特殊字符导致'400、404'的报错

⑤ nginx的uri转义机制
遗留:'阅读' src/core/ngx_string.h 和 src/core/ngx_string.c '源'文件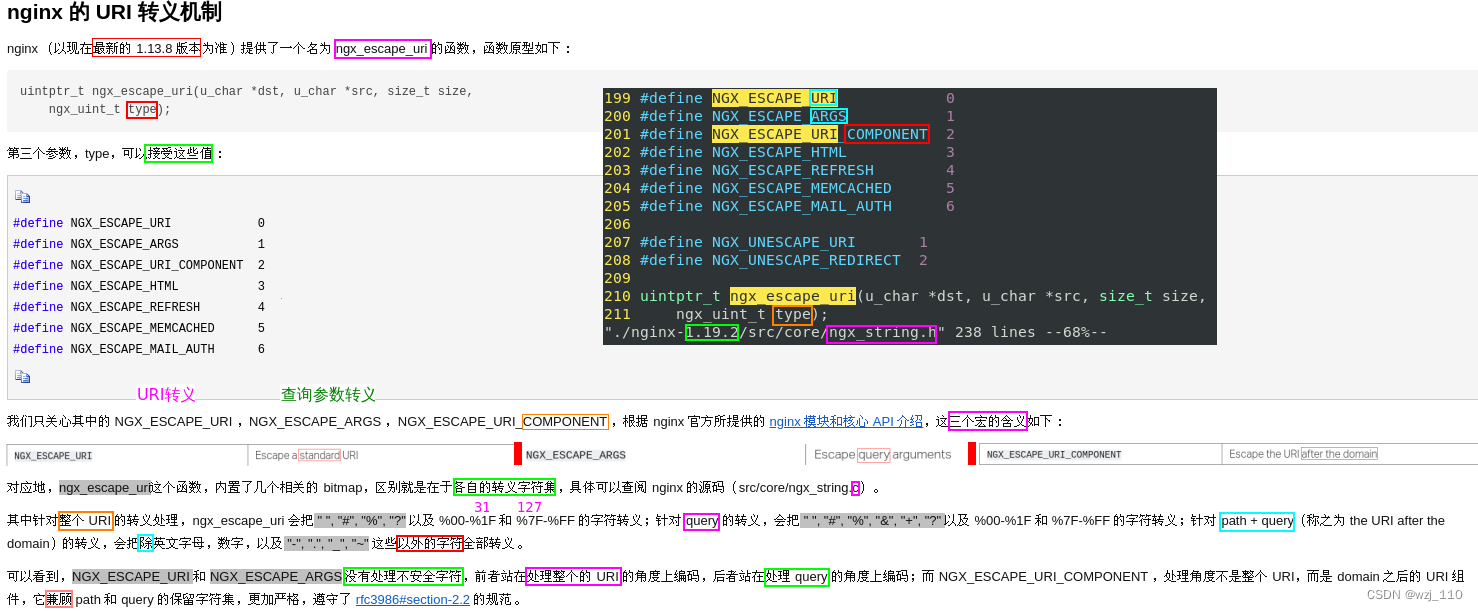
⑥ ngx_proxy模块对URI处理
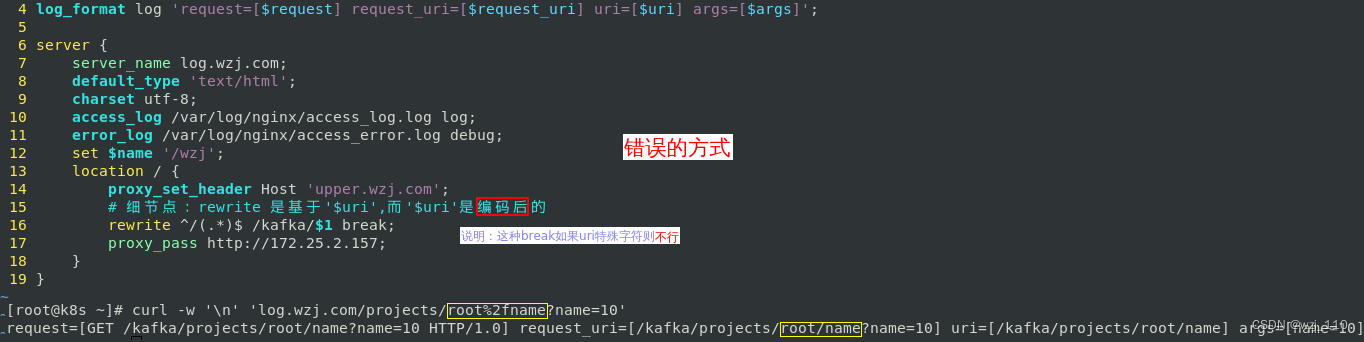
补充: 'rewrite ... break;'会改变'proxy_paas'的uri形式
遗留:
1) 物料:弄两个nginx,一个作为'代理',一个作为'上游'服务器
备注:代理'proxy_paas'中'attach_url'三种形式 --> '本周闭环'
2) 测试: url带'特殊'字符,观察'代理和上游日志',以及'响应体'proxy_pass带attach_url导致解码后传输给上游 400报错
测试1: proxy_pass不带'attach_url'
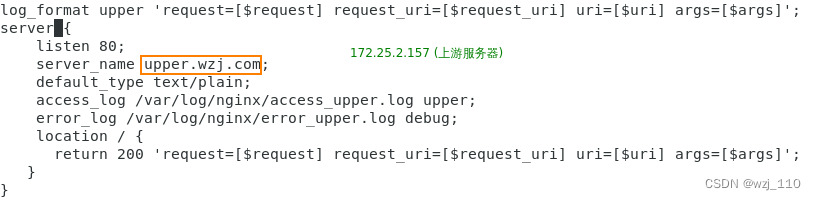
解读: 此时'上游服务器'看到的是'root%2fname' --> "正确"
测试2: proxy_pass带'attach_url',并且'不为'变量,场景如下:
1) 接口 '/projects/{name}'
2) 要'查询' name 名称为 'root/name' 的项目
3) 此时我们'不能'直接访问 '/projects/root/name'
4) 这样会被系统'误认为'是要查询名称为 'root' 的项目
5) 所以在'实际开发中'需要将 'root/name' 先进行url encode'编码' 再'拼接'到url上
6) 即 /projects/root%2fname --> "%2F <--> /"
结论: 这种形式的配置nginx会'自动'进行'url decode'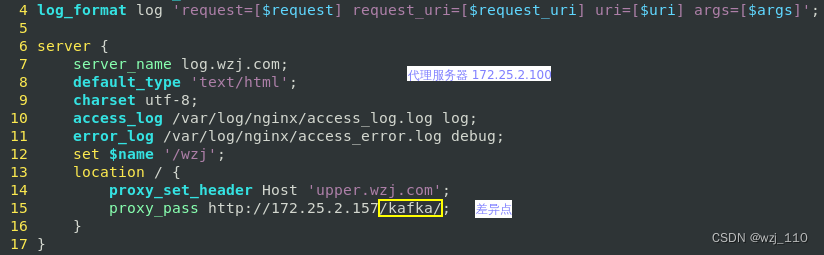
解读: 此时'上游服务器'看到的是'root/name' --> '错误'
原因:
1) nginx 会把'decode 解码过'的,由'客户端'发来的 uri 里的 'path' 部分
也即: '/projects/root%2fname'
2) '去掉'和当前 location 的'公共'前缀,也即去掉'location /'中的'/'前缀
3) 得到'projects/root%2fname',然后按照'NGX_ESCAPE_URI' encode编码得'root/name'
4) 然后与proxy_pass 指令的 'attach_url' 拼接,发送到'上游'
测试3:proxy_pass带'attach_url',并且'包含'变量
结论: 如果指定的 uri 包含了'变量',将'解析变量',然后直接将'变量解析后的 uri' 发送到'上游'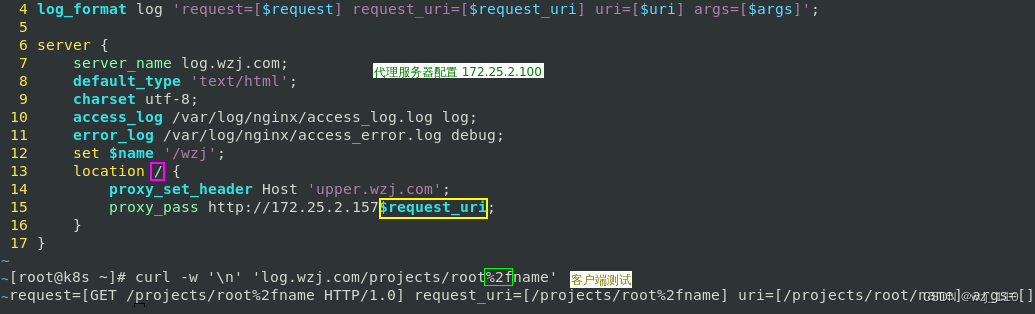
背景: proxy_pass带'attach_url',并且为'裸path'
需求: 如何转换,'避免' nginx 自动进行'url decode'编码 --> "attach_url通过变量的形式"
$request_uri :包含客户端发送的'原始未转义'的请求uri
对比: vs '测试2'
引申: uri'规范'的重要性
核心点: if 基于'$request_uri'补获'正则'变量,然后proxy_pass的attach_url引用'变量'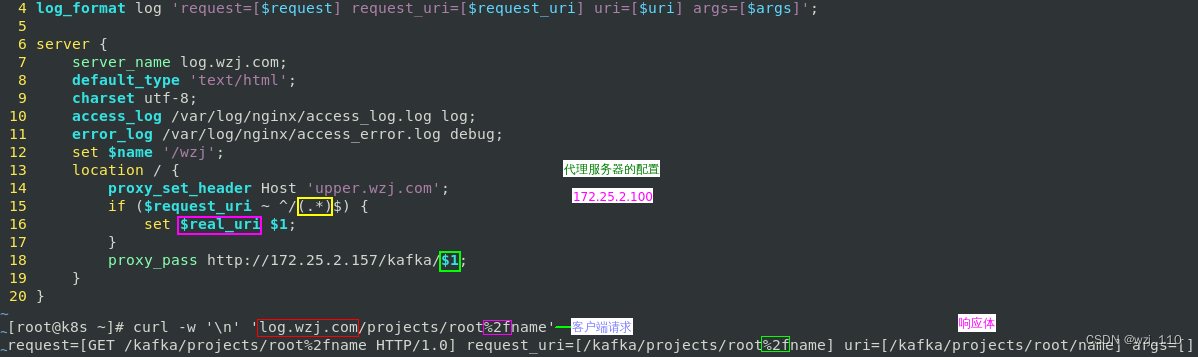
⑦ $uri判断
案例1: url'特殊'字符,多个'location 路由',观察匹配哪个'location'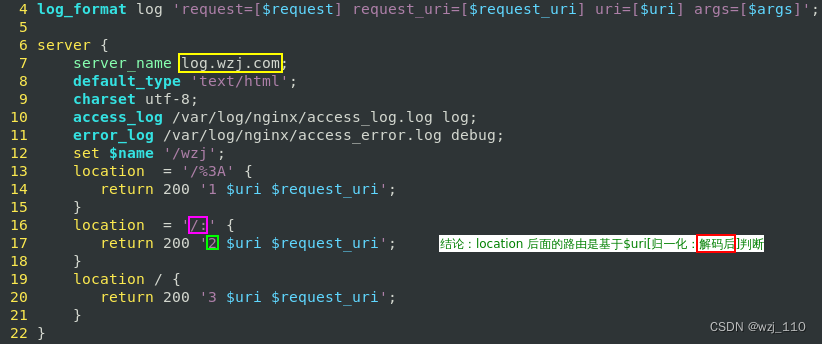

案例2: '类似 'if ($uri ~ ^([a-zA-Z0-9_/]+)$) {...} 观察debug日志'匹配'情况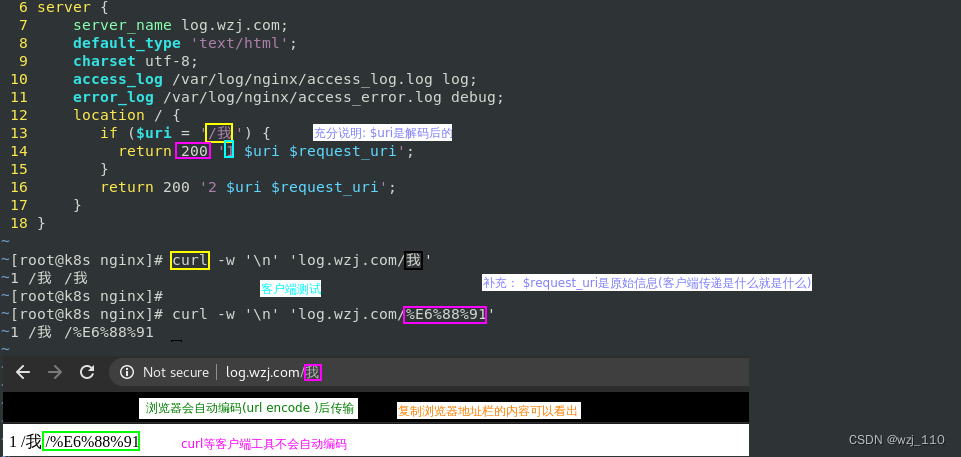
案例3: proxy_paas的attach_url使用'$uri',观察'CLCF'漏洞注入的现象案例4: rewrite source replace... ; --> $uri 与当前 'source'对比⑧ 与uri有关中文正则匹配
引出: if ($uri ~) 如何'正则'匹配'中文'nginx、PCRE、url中文 utf-8编码 、rewrite路径重写匹配问题
遗留: 回头根据这个'文章'升级'PCRE'1) 通识1: nginx的rewrite模块是'调用PCRE'来处理'正则'的
2) 通识2: nginx使用PCRE只有'7.9以上'的版本才支持nginx这个"(*UTF8)"开头语法
3) 前置: 系统上的PCRE一定要使用'7.9+以上'的版本,并且'编译PCRE'时一定要'开启UTF8'支持
ps: pcre7.9以下的版本,默认是'不支持Unicode、UTF-8'的,要'重新编译'手动指定
核心操作: ./configure --enable-utf8 --enable-unicode-properties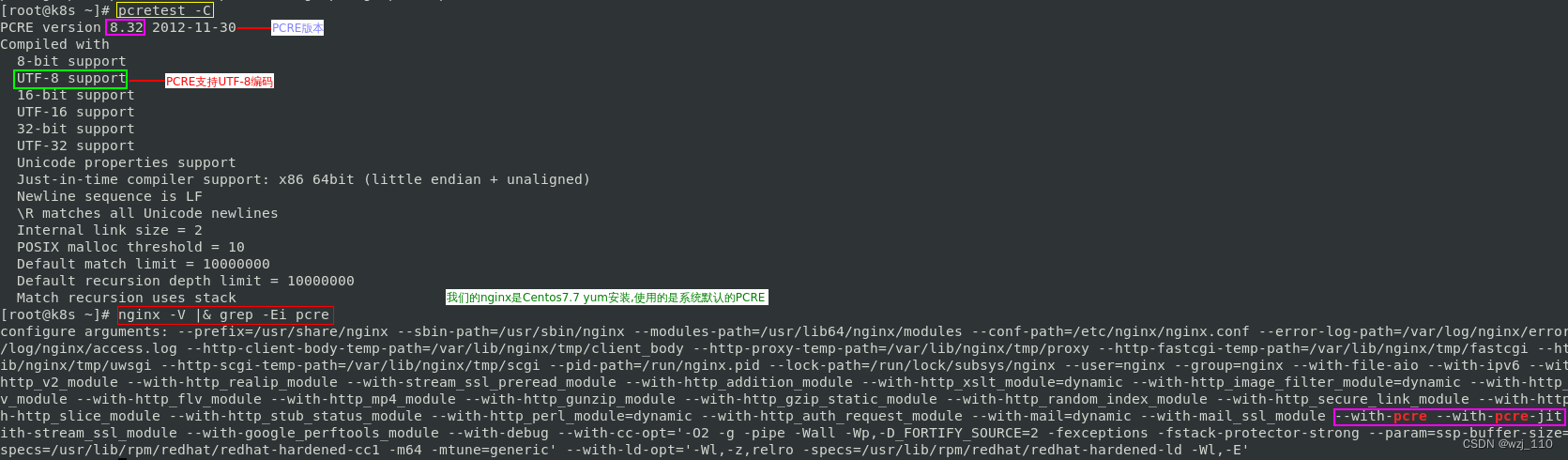

![]()
![]()
[a-zA-Z0-9 \x{4e00}-\x{9fa5}]+$ Unicode汉字正则表达式方法比较

PHP使用PCRE匹配中文 ngx_http_perl_module中的$r->uri处理中文
补充: PHP的'/u'就是'PCRE_UTF8'的含义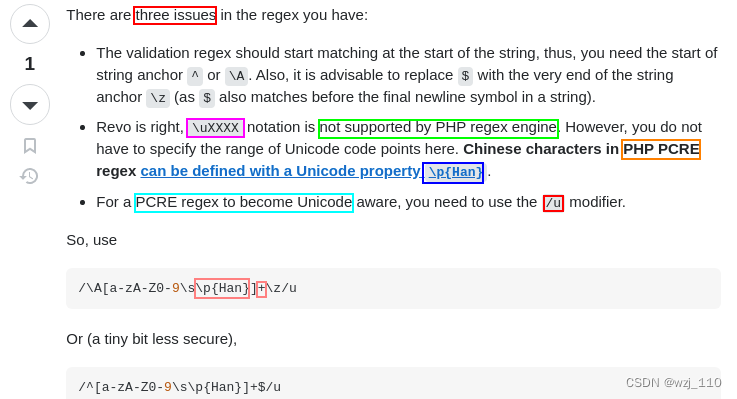
思考: nginx中'正则'也使用'pcre',nginx应该如何'匹配中文'呢?
尝试: 任何使用'正则'的地方使用,建议'(*UTF-8)'开头,并带上'单引号'
细节: 如果不使用'(*UTF-8)',各种匹配的'默认'行为是什么?
补充: rewrite ^/(……)$ 可以匹配'2个汉字',中文'utf-8'编码,'3'个字节,6个'ASCII'字符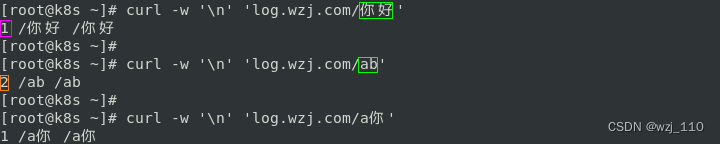
# 尝试过程
1) Unicode编码--> [\u4e00-\u9fa5]
2) location ~ "^(*UTF8)/[\x{4e00}-\x{9fa5}]+$"
3) location ~ "^(*UTF8)^/[a-Z]+$" {
4) location ~ ^(*UTF8)/[\u4e00-\u9fa5]+$ {
5) location ~ '(*UTF8)^/[\x{4e00}-\x{9fa5}]+$'
注意:'\u'换乘'\x',中间要有'花括号{}'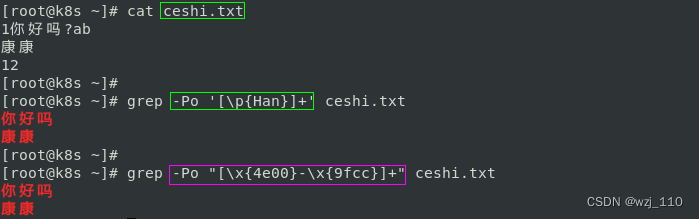
终极大招: nginx匹配'中文'
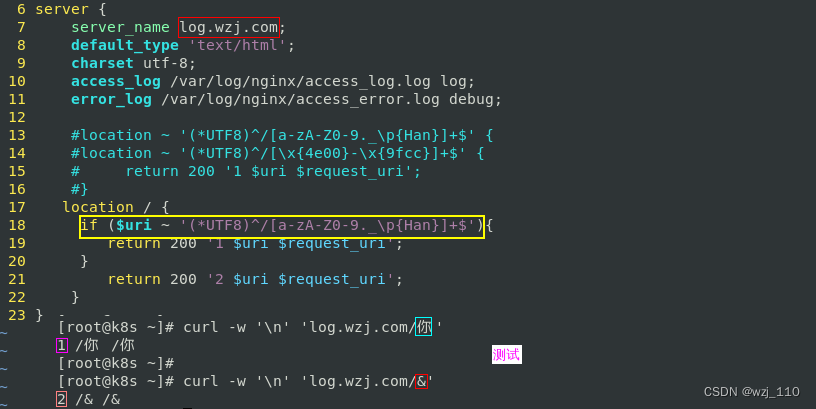
location ~ '(*UTF8)^/[a-zA-Z0-9._\p{Han}]+$' --> "可读性"更高
回头:location ~ '(*UTF8)^/[\x{4e00}-\x{9fcc}]+$' --> 也能匹配'汉字'
原因: 'error错误'的把'9fcc'写成'9f55'导致

![]()
遗留1: if 通过'$uri'可以'判断'URI白名单吗? --> "可以的" --> "下方案例验证"
if ($uri ~ (*UTF8)^/[a-zA-Z0-9._\p{Han}) {
# '正确'
}
遗留2: rewrite (*UTF-8)^regex replacement [flag]; --> 留给你'探究'
提示: rewrite也是基于当前'$uri'改变行为的⑨ 上面小结
1) 日志记录: escape=none|default --> 影响'$uri'的形式
1、escape=none --> "解码后记录",'中文'展示 --> "可读性好"
2、escape=default --> 特定'ASCII的字符'会转义,'中文'常展示'\x'形式,'default'行为
2) 向上游转发,proxy_pass中带'attach_url'形式
1、不带'attach_url',则'原始透传'
2、带'attach_url',为'裸path'则'$uri解码后',去掉'location ...',拼接attach_url'透传'
3、带'attach_url',url路径包含'变量'则'原始'透传
3) location ... --> 基于'解码后'的$uri进行'路由'判断的
4) if ($uri ~) --> 基于'解码后'的$uri进行判断的
5) rewrite ... ... --> 基于'解码后'的$uri进行判断的![]()
⑩ $args查询字符串
+++++++++++++++++++ "知识点铺垫" +++++++++++++++++++
1) 浏览器会'自动'进行'url encode'编码 -> 'chrome'
2) curl 不会'显示'进行'url'编码
3) nginx 的'$arg_NMAE、$args'是客户端'原始传输'的形式
ps: 也即'客户端编码后',nginx展示是'客户端编码后';'客户端没有编码',nginx展示是'没有编码的'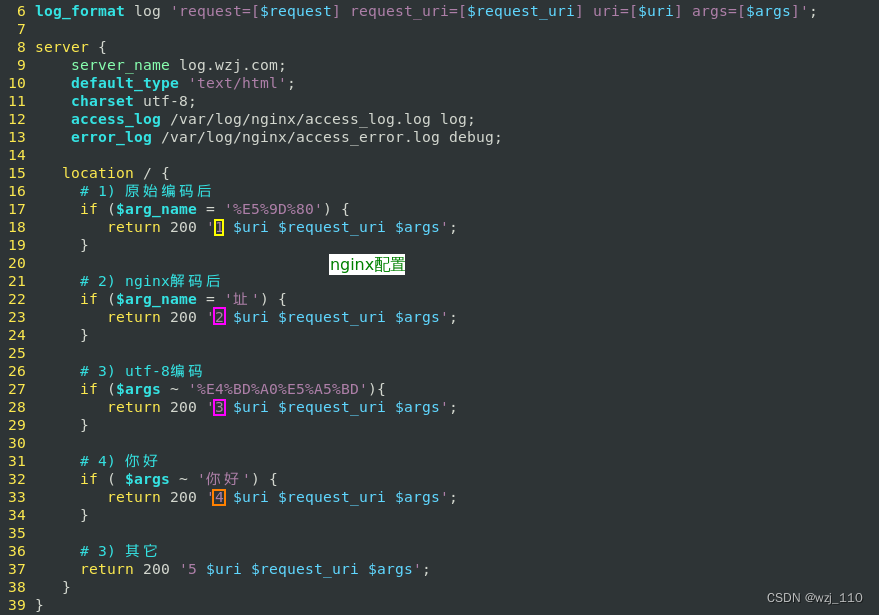

提示: curl 请求参数'较多'的时候,注意'顺序'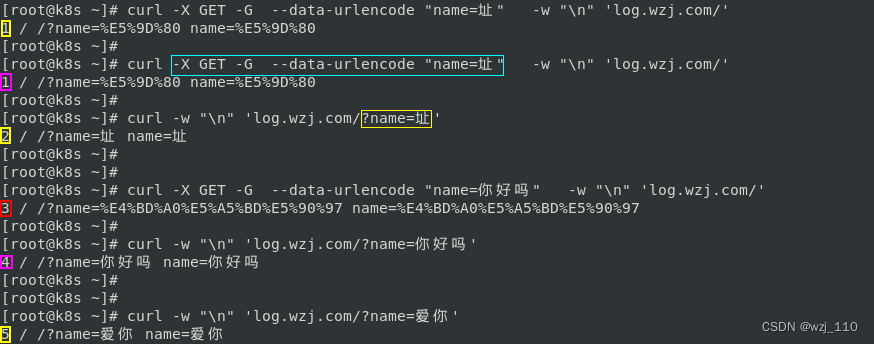
需求1:nginx 向'上游'转发时'drop过滤掉'查询字符串
rewrite ^(.+)$ $1? break;
# rewrite ^ $uri? break
proxy_pass http://$proxy_name$uri;⑪ ngx_lua 的 URI 转义机制
nginx access_log request_body 中文字符解析方法

1) 自动把原始 url 带给后端应该是 'ngx_proxy 模块'的行为,和 'ngx_lua 没有'任何关系
2) 想强制 uri的归一化,应该使用'ngx.req.set_uri()' 这样的 Lua API 来'改写'当前请求的uri
题外话: 加载'相对资源'的时候,会传递一个'Referer'请求头