在对大数据的认识中,人们总结出它的4V特征,即容量大、多样性、生产速度快和价值密度低,为此产生出大量的技术和工具,推动大数据领域的发展。为了利用好大数据,如何有效的从其中提取有用特征,也是重要的一方面,工具和平台化必须依靠正确的数据模型和算法才能凸显出其重要的价值。
现在就文本分析作为案例来分析数据处理技术在大数据领域的作用和影响。首先讨论文本分析的三种模型:词袋模型、TF-IDF短语加权表示和特征哈希。
“Bag ofwords,也叫做“词袋”,在信息检索中,Bag of wordsmodel假定对于一个文本,忽略其词序和语法、句法,将其仅仅看做是一个词集合或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。”
其处理过程如下:
· 分词:将分本分割为词的集合。
· 删除停用词,比如the、and、but等。
· 提取词干,即将各个词简化为其基本形式,也就是归一化。
· 向量化,用向量表示处理好的词,二元向量是最为简单的表示方式,用1/0来表示是否存在某个词。随着词数量的增加,比如几百万,使用稀疏矩阵仅仅记录该词是否出现过,从而节省内存和磁盘空间、计算时间。
这种假设虽然对自然语言进行了简化,便于模型化,但是其假定在有些情况下是不合理的,例如在新闻个性化推荐中,采用Bagof words的模型就会出现问题。例如用户甲对“南京醉酒驾车事故”这个短语很感兴趣,采用bagof words忽略了顺序和句法,认为用户甲对“南京”、“醉酒”、“驾车”和“事故”感兴趣,因此可能推荐出和“南京”、“公交车”、“事故”相关的新闻,这显然是不合理的。
下面介绍两种SparkMLlib包含的两种特征提取技术。
“TF-IDF,词频-逆文本频率。其中,词频基于单词在文本中出现的频率为每一个词赋予一个权值,逆文本频率则基于单词在所有文档中的频率计算得出。”
这一技术设计的初衷在于字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降,这样的设计均在于更好的表达此词或者短语的类别区分能力。适合用来分类TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
“特征哈希使用哈希方程对特征赋予向量下标,它需要预先选择特征向量的大小。”
如果特征数量爆炸式增长,就需要进行降维处理,比如聚类、PCA等,但这些方法在特征量和样本量都很大的时候其计算量很大,在文本和分类数据上有一种简单高效的高维数据处理技术就是特征哈希。
特征哈希法的目标是把原始的高维特征向量压缩成较低维特征向量,且尽量不损失原始特征的表达能力。其优势在于不需要构建映射且保存在内存,不需要预先扫描一遍数据集;它很容易实现且非常快,因为其维度远远小于数据集,限制了模型训练和预测时内存的使用量。
TF-IDF不是训练机器学习模型,而是做特征提取或者转化,经常用来作为降维、分类和回归等的预处理步骤。
利用Spark可以根据如下几步进行计算:
Step1. 使用HashingTF,利用特征哈希技术把每个输入文本的词项应设为一次词频向量的下标。
tf=hashingTF.transform(tokens)
Step2. 使用一个全局变量IDP向量把词频向量转换为TF-IDF向量。
idf=new IDF().fit(tf)
tfidf=idf.transform(tf)
Trident是基于Storm进行实时流处理的高级抽象,提供了对实时流的聚集、投影、过滤等操作,大大简化了Storm任务开发的工作量。另外,Trident提供了原语处理针对数据库或其他持久化存储的有状态的、增量的更新操作。
一个Trident任务可以有多个数据源,每个数据源都是以TridentState的形式定义在任务中。
现在利用Trident实现关于词频重要性的TF-IDF的计算,实现一个TridentTopology并定义一个Stream数据管道如下:
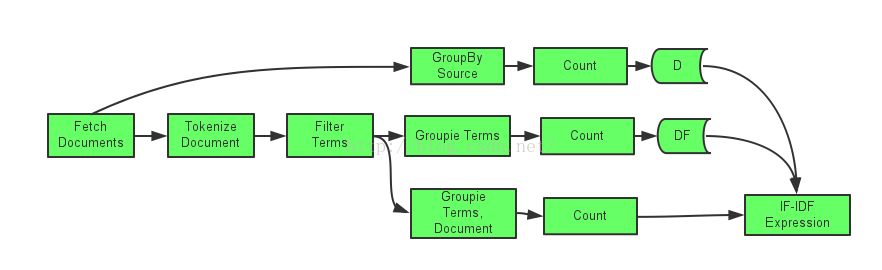
tf-idf计算公式如下:
tf-idf=tf(t,d)*log(D/1+df(t)
其中,tf(t,d)计算单词t 在文档d中出现的频率,df(t)计算单词t在所有文档中出现的频率,D计算文档总计。
其具体实现如下:
TridentState dfState=termStream.groupBy(newFileds(“term”))
.persistentAggregate(getStateFactory(“df”),newcount(),new Fields(“df”));
TridentState dState=termStream.groupBy(newFileds(“source”))
.persistentAggregate(getStateFactory(“d”),newcount(),new Fields(“d”));
Stream tfidfStream =termStream. groupBy(newFileds(“documentId”,”term”))
.persistentAggregate(new count(),new Fields(“tf”))
.each(newFileds(“term”,“documentId”,”tf”),newTfidfExpresssion(),new Fields(“tfidf”));