1.什么是Hadoop
Hadoop是Apache基金会旗下的一个分布式系统基础架构。
主要包括:
(1)分布式文件系统HDFS(Hadoop Distributed File System)
(2)分布式计算系统Map Reduce
(3)分布式资源管理系统YARN
Hadoop使用户可以在不了解分布式系统底层细节的情况下,开发分布式程序并充分利用集群的分布式能力进行运算和存储
2.Hadoop核心构成
Hadoop框架主要包括三大部分:分布式文件系统、分布式计算系统、资源管理系统。
1.分布式文件系统HDFS
主要任务:主要负责分布式文件存储,可看成一个容量巨大、具有高容错性的磁盘,在使用的时候完全可以当作普通的本地磁盘使用。
HDFS的基本原理:将数据文件拆分成指定大小的数据块,并将数据块以副本的方式存储到多台机器上,即使某个节点出现故障,该节点上存储的数据块副本丢失,但是在其他节点上还有对应的数据副本,所以在HDFS中即使某个节点出现问题也不会造成数据的丢失(前提是你的Hadoop集群的副本系数大于1)
2.分布式计算系统Map Reduce
**主要任务:**负责计算
工作原理:
Map Reduce的名字源于这个模型中的两项核心操作:Map(映射)和Reduce(归纳)
一个Map Reduce作业通常会把输入的数据集切分为若干独立的数据块,由map任务以并行的方式处理它们,对map的输出先进行排序,然后再把结果输入reduce任务,由reduce任务来完成最终的统一处理。
Map Reduce框架处理数据的输入源和输出目的地的大部分场景都是存储在HDFS上的
注意:
在部署Hadoop集群时,通常是将计算节点和存储节点部署在相同的节点之上,这样做的好处是允许计算框架在进行任务调度时,可以将作业优先调度到那些已经存有数据的节点上进行数据的计算,使整个集群的网络带宽被非常高效地利用,这就是大数据中非常有名的一句话“移动计算而不是移动数据”
3.资源管理系统YARN
主要任务:进行资源管理
YARN的基本思想:
将Hadoop1.x中Map Reduce架构中的Job Tracker的资源管理和作业调度监控功能进行分离,解决了在Hadoop1.x中只能运行Map Reduce框架的限制
3.hadoop发行版本
Hadoop的发行版除了由社区维护的 Apache Hadoop之外,Cloudera、Hortonworks、Map R等都提供了自己的商业版
(1)Cloudera CDH
Cloudera CDH版本的Hadoop是现在国内公司使用最多的。
优点:Cloudera Manager(简称CM)采取“小白”式安装,配置简单、升级方便,资源分配设置方便,非常利于整合Impala,而且文档写得很好,与Spark的整合力度也非常好。在CM的基础之上,我们通过页面就能完成对Hadoop生态圈各种环境的安装、配置和升级。
缺点:CM不开源,Hadoop的功能和社区版有些出入
(2)Hortonworks HDP
优点:原装Hadoop、纯开源,版本和社区版一致,支持Tez,集成开源监控方案Ganglia和Nagios。
缺点:安装、升级、添加、删除节点比较麻烦。
(3)原生hadoop
官网下载即可
4.Hadoop生态圈
狭义的Hadoop:是一个适合大数据分布式存储和分布式计算的平台,包括HDFS、Map Reduce和YARN。
广义的Hadoop:指以Hadoop为基础的生态圈,Hadoop只是其中最重要、最基础的一部分;生态圈中的每个子系统只负责解决某一个特定的问题域(甚至可能更窄),它并不是一个全能系统,而是多个小而精的系统。
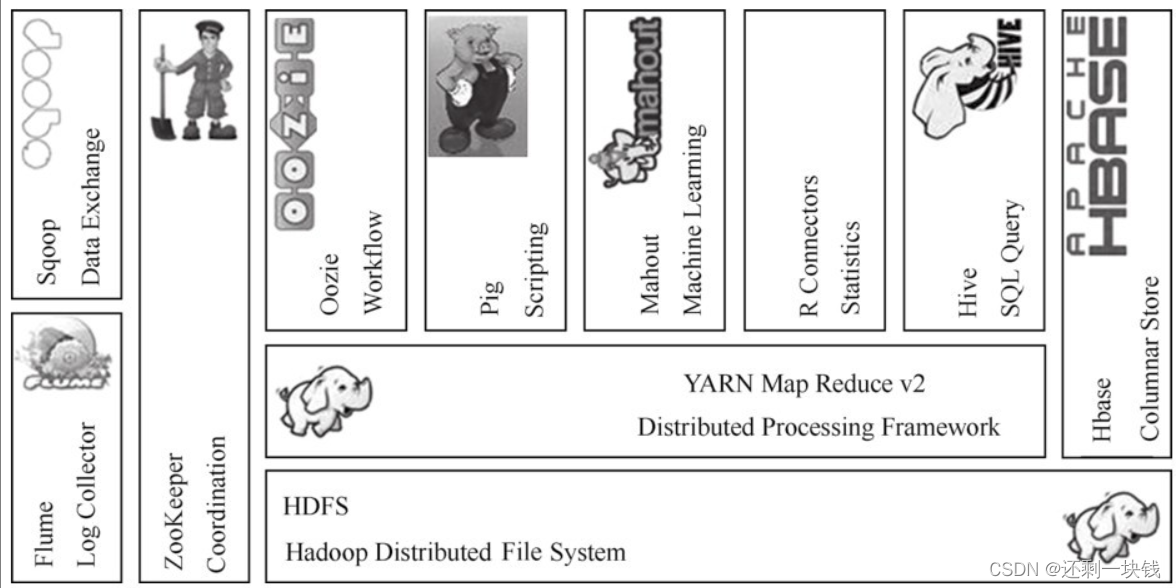
HDFS:大数据处理框架如Map Reduce或者Spark等要处理的数据源大部分都是存储在HDFS之上,Hive或者HBase等框架的数据通常情况下也是存储在HDFS之上。简而言之,HDFS为大数据的存储提供了保障。
Map ReduceMap Reduce:是一个分布式、并行处理的编程模型。开发人员只需编写Hadoop的Map Reduce作业就能使用存储在HDFS中的数据来完成相应的数据处理功能。
YARN:负责整个系统的资源管理和调度,而且在YARN之上能运行各种不同类型(Map Reduce、Tez、Spark)的执行框架。
HBase:是一个建立在HDFS之上的面向列的数据库,用于快速读/写大量数据。HBase使用Zoo Keeper进行管理,以确保所有组件都能正常运行。HBase保障查询速度的一个关键因素就是其Row Key设计得是否合理,这点需要重点关注。
Zoo Keeper:是分布式协调服务的框架。Hadoop的许多组件都依赖于Zoo Keeper,比如HDFS Name Node HA的自动切换、HBase的高可用,以及Spark Standalone模式Master的HA机制都是通过Zoo Keeper来实现的。
Hive:Hive的执行原理就是将SQL语句翻译为Map Reduce作业,并提交到Hadoop集群上运行。因为只需要写SQL语句,而不需要面向Map Reduce编程API进行相应代码的开发,大大降低了学习的门槛,同时也提升了开发的效率。
Pig:是一个用于并行计算的高级数据流语言和执行框架,有一套和SQL类似的执行语句,处理的对象是HDFS上的文件。Pig的数据处理语言采取数据流方式,一步一步地进行处理(该框架简单了解即可,近些年在生产上使用得并不是太多)。
Sqoop:是一个用于在关系数据库、数据仓库(Hive)和Hadoop之间转移数据的框架。可以借助Sqoop完成关系型数据库到HDFS、Hive、HBase等Hadoop生态圈中框架的数据导入导出操作,其底层也是通过Map Reduce作业来实现的。
Flume:是由Cloudera提供的一个分布式、高可靠、高可用的服务,是用于分布式的海量日志的高效收集、聚合、移动/传输系统的框架;Flume是一个基于流式数据的非常简单的(只需要一个配置文件)、灵活的、健壮的、容错的架构。
Oozie:是一个工作流调度引擎,在Oozie上可以执行Map Reduce、Hive、Spark等不同类型的单一或者具有依赖性(后一个作业的执行依赖于前一个或者多个作业的成功执行)的作业。可以使用Cloudera Manager中的HUE子项目在页面上对Oozie进行配置和管理。类似的在大数据中使用的工作流调度引擎还有Azkaban。
MahoutMahout:是一个机器学习和数据挖掘库,它提供的Map Reduce包含很多实现,包括聚类算法、回归测试、统计建模。
5.安装hadoop
须知:
使用的是分布式主机安装方式,有三台主机进行组合,主机名分别是A,B,C
三台主机对应的ip如下(前面为主机名,后面为ip
A 123
B 456
C 789
软件版本
hadoop: 原生版3.1.3
jdk:1.8.0
1.修改配置并密网穿透
1.分别修改三台主机的名称,分别为A,B,C
三台主机上面都修改,修改完成后保存并退出
vim /etc/hostname
重启主机
reboot
2.配置映射关系
先在主机A上修改host文件,这里只在A主机上改,其他主机不要改
vim /etc/hosts内容如下
删除默认 localhost,添加 3 个节点的 IP
123 A 456 B 789 C
3.配置 ssh 登陆
在三台主机上面同时执行下面命令,注意是三台
ssh-keygen -t rsa ---四个回车
**在A主机上执行,**将hosts文件发给B, A主机已经对B,C主机做好了映射,所以可以直接分发
scp /etc/hosts root@B:/etc/ 将hosts文件发给B - scp /etc/hosts root@C:/etc/ 将hosts文件发给C
在三台主机上分别操作,分发秘钥,一份发给自己,另外两份发给其他
ssh-copy-id A ssh-copy-id B ssh-copy-id C
4.测试
测试从A主机穿透到B主机,C主机
ssh B ssh C
2.安装jdk
创建两个目录,在/opt目录下
software目录: 用于保存安装包
module目录:用于存放解压后的组件
三台主机都需要创建这两个目录
mkdir /opt/software mkdir /opt/module
安装
将jdk-8u212-linux-x64.tar.gz安装包提前存放在A主机的/opt/software目录下
#在A主机上面操作下面步骤
-
cd /opt/software
-
#将jdk压缩包解压到/opt/module目录下
tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module
-
#配置环境变量,添加以下内容
vim /etc/profile
内容
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=${JAVA_HOME}/bin:$PATH
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
-
#刷新环境变量
source /etc/profile
#查看是否安装成功
java –version
将在A主机上配置好的jdk分发到B,C主机
scp -r /opt/module/jdk1.8.0_212 root@B:/opt/module/ #分发给B主机 scp -r /opt/module/jdk1.8.0_212 root@C:/opt/module/ #分发给C主机
将在A主机上配置好的环境变量分发给B,C主机
scp /etc/profile root@B:/etc/ scp /etc/profile root@C:/etc/
在B,C主机上面分别刷新一下环境变量,并测试java是否安装成功
#刷新环境变量 source /etc/profile #查看是否安装成功 java –version
4.安装hadoop
将hadoop-3.1.3.tar.gz安装包提前存放在A主机的/opt/software目录下
进入A主机的/opt/software目录并解压文件
cd /opt/software - tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module #将hadoop安装包解压到/opt/module目录下
集群节点规划
| 组件 | A主机 | B主机 | C主机 |
|---|---|---|---|
| HDFS | DataNode | NameNode,DataNode | SecondaryNameNode, DataNode |
| YARN | ResourceManager,NodeManager | NodeManager | NodeManager |
第一步:进入解压好的hadoop目录----A主机上操作
cd /opt/module/hadoop-3.1.3/etc/hadoop/ - ll
第二步:修改core-site.xml文件-----A主机上操作
vim core-site.xml内容
<configuration> <!-- 指定 NameNode 的地址 ,这里需要修改一下主机名,将B修改成对应的主机名--> <property> <name>fs.defaultFS</name> <value>hdfs://B:8020</value> </property> <!-- 指定 hadoop 数据的存储目录,存放在data目录下,存放路径也可修改 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置 HDFS 网页登录使用的静态用户为 root 或 student --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>
第三步:修改:hdfs-site.xml文件----A主机编写
vim :hdfs-site.xml内容
<configuration> <!--配置 hdfs 文件系统的副本数,可以设置成3也可是其他--> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- NameNode web 端访问地址,这里设置为B主机的9870端口--> <property> <name>dfs.namenode.http-address</name> <value>B:9870</value> </property> <!-- SecondaryNameNode web 端访问地址,这是设置为C主机的9868端口--> <property> <name>dfs.namenode.secondary.http-address</name> <value>C:9868</value> </property> <!-- 修改块大小,默认为 134217728(字节数)即 128m,也可以写上单位,比如 128m,1g 等--> <property> <name>dfs.blocksize</name> <value>134217728</value> </property> </configuration>
第四步:修改mapred-site.xml文件----A主机编写
vim mapred-site.xml内容
<configuration> <!--指定 mapreduce 运行的框架名:yarn--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!--配置 mapreduce 的历史记录组件的内部通信地址即 RPC 地址,设置为A主机的10020端口,其实就是resource manager主机--> <property> <name>mapreduce.jobhistory.address</name> <value>A:10020</value> </property> <!--配置 mapreduce 的历史记录服务的web 管理地址,设置成A主机的resource manager 的19888--> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hd01:19888</value> </property> <!--配置 mapreduce 已完成的 job记录在 HDFS 上的存放地址--> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/history/done</value> </property> <!--配置 mapreduce 正在执行的 job记录在 HDFS 上的存放地址--> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/history/done_intermediate</value> </property> <!--为 MR 程序主进程程添加环境变量--> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value> </property> <!--为 Map 添加环境变量--> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value> </property> <!--为 Reduce 添加环境变量--> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value> </property> </configuration>
第五步:编写yarn-site.xml文件----A主机编写
vim yarn-site.xml内容
<configuration> <!-- Site specific YARN configuration properties --> <!--指定 resourcemanager 所在的主机,这里设置成A--> <property> <name>yarn.resourcemanager.hostname</name> <value>A</value> </property> <!--指定 mapreduce 的shuffle 处理数据方式--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--配置 resourcemanager 内部通信地址,设置成主机A,resource manager的8032端口--> <property> <name>yarn.resourcemanager.address</name> <value>A:8032</value> </property> <!--配置 resourcemanager 的 scheduler 组件的内部通信地址,设置成主机A,resource manager的8030端口--> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>A:8030</value> </property>1 <!--配置 resource-tracker 组件的内部通信地址,设置成主机A,resource manager的8031端口--> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>A:8031</value> </property> <!--配置 resourcemanager 的 admin 的内部途信地址,设置成主机A,resource manager的8033端口--> <property> <name>yarn.resourcemanager.admin.address</name> <value>A:8033</value> </property> <!--配置 yarn 的 web 管理地址,设置成主机A,resource manager的8088端口--> <property> <name>yarn.resourcemanager.webapp.address</name> <value>A:8088</value> </property> <!--yarn 的日志聚合是否开启--> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!--聚合日志在 hdfs 的存储路径--> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/tmp/logs</value> </property> <!--聚合日志在 hdfs 的保存时长,单位 S,默认 7 天--> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <!--聚合日志的检查时间段--> <property> <name>yarn.log-aggregation.retain-check-interval-seconds</name> <value>3600</value> </property> <!-- 设置日志聚合服务器地址 这里设置为主机A的19888--> <property> <name>yarn.log.server.url</name> <value>http://A:19888/jobhistory/logs</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
第六步:编辑works文件----A主机编写
vim workers内容
A B C
第七步:分发编写好的文件----A主机编写
scp -r /opt/module/hadoop-3.1.3 root@B:/opt/module/ 发给B主机 scp -r /opt/module/hadoop-3.1.3 root@C:/opt/module/ 发给C主机
第八步:编写配置环境----A主机编写
vim /etc/profile - 添加内容 export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH刷新环境
source /etc/profile分发给另外两台主机
scp /etc/profile root@B:/etc/ #环境发给B scp /etc/profile root@C:/etc/ #环境发给C - 之后刷新环境即可,三台主机都要刷新 source /etc/profile
第九步:验证是否安装成功
hadoop version
5.使用hadoop
hadoop version后出现了版本号,代表我们已经安装成功,但是我们还不能使用的,必须要进行格式化,我们在格式化的时候,必须在namenode节点上进行格式化,由于我们将第二台主机作为了namenode,所以下面会在B主机上面操作
第一步:namenode格式化----B主机上进行
hadoop namenode -format
第二步:启动hadoop—B主机上操作
start-all.sh
第三步:jps查看节点情况—三台都看
jps三台主机上的节点要与我们设置的一样
第四步:web UI要在windows浏览器上查看----三台都执行
#三台主机都关闭防火墙 systemctl stop firewalld systemctl disable firewalld打开windwos系统的C:\Windows\System32\drivers\etc目录,里面有一个 hosts 文件,没有的话我们就新建一个
hosts文件里面填写如下内容
# SwitchHosts! 123 A 456 B 789 C访问
打开浏览器,必须是namenode的主机(B),输入http://B:9870 或者输入B IP:http://456:9870