以前,公司网络限制,无法通过用户名密码登录某些网站,但是可以通过浏览器打开网站,而这些网站有个问题,非登录用户,不能复制博客中的代码,这个就有些麻烦了。
好在,这些代码是可以通过查看网页源代码的方式获取。如下所示,我们看到csdn的代码:
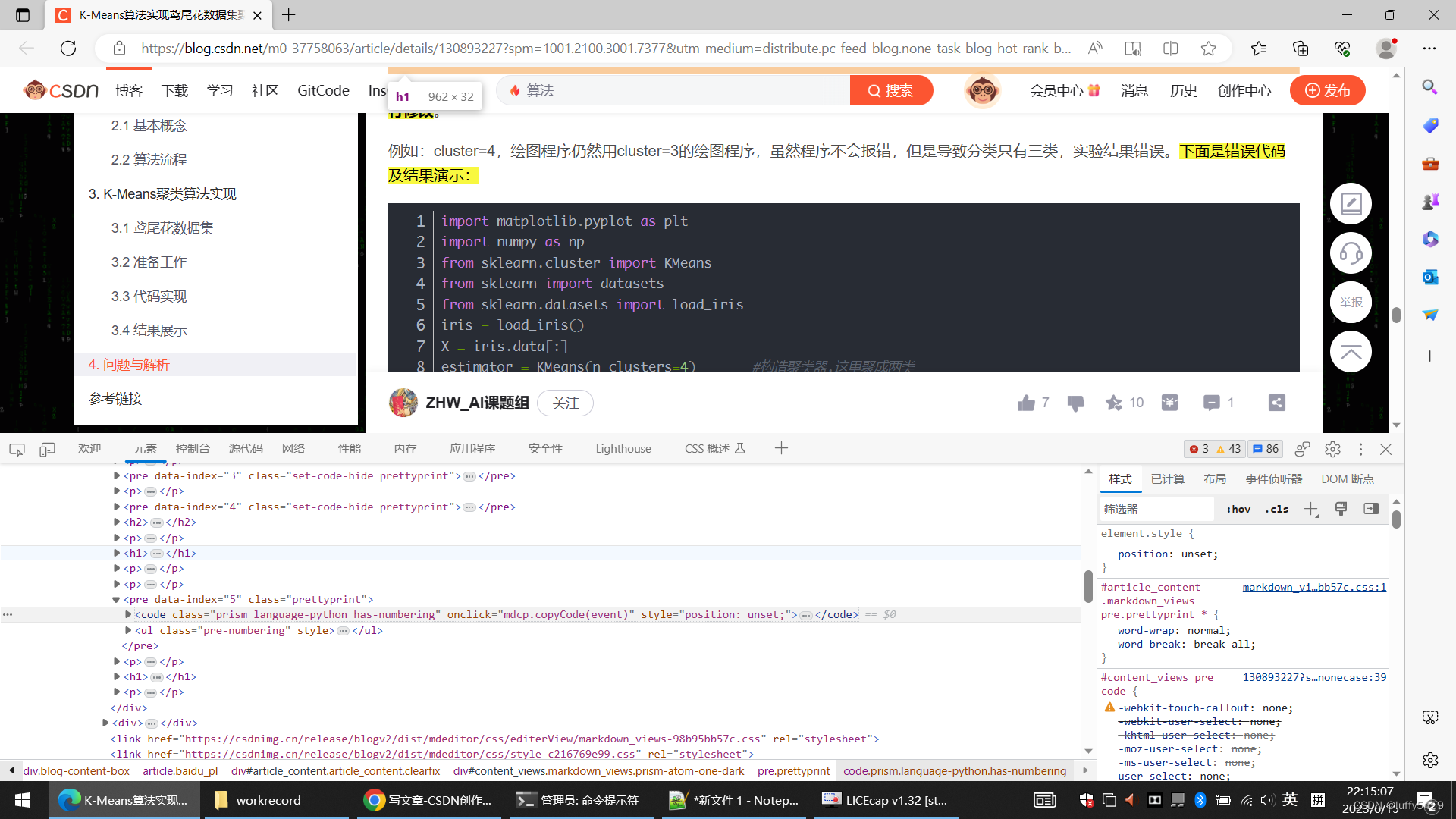
拿到html元素内容的办法:
1、开启F12,进入开发者调试界面,
2、切换到 元素 tab页,
3、使用鼠标选择 代码部分。
4、拷贝元素。
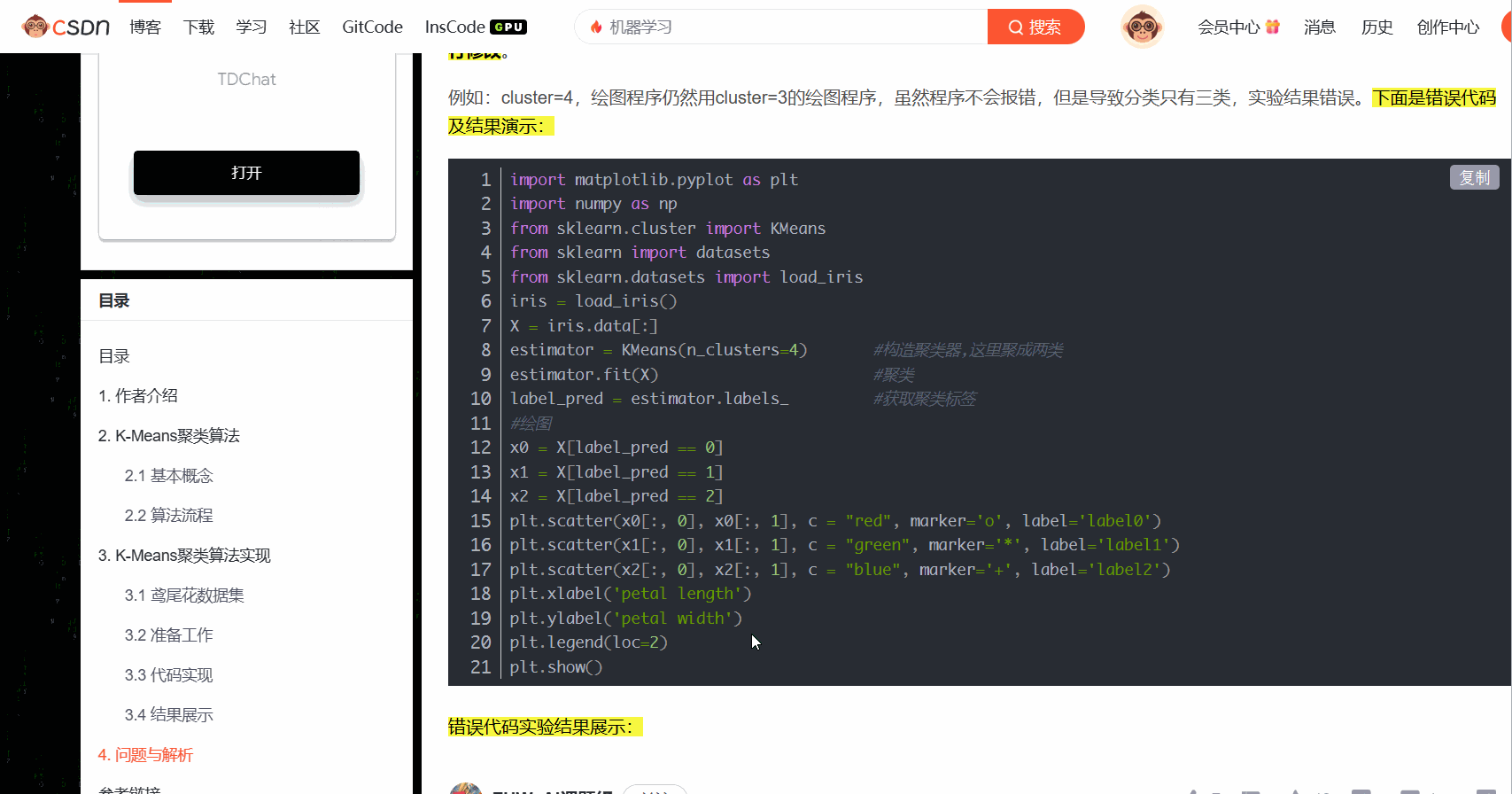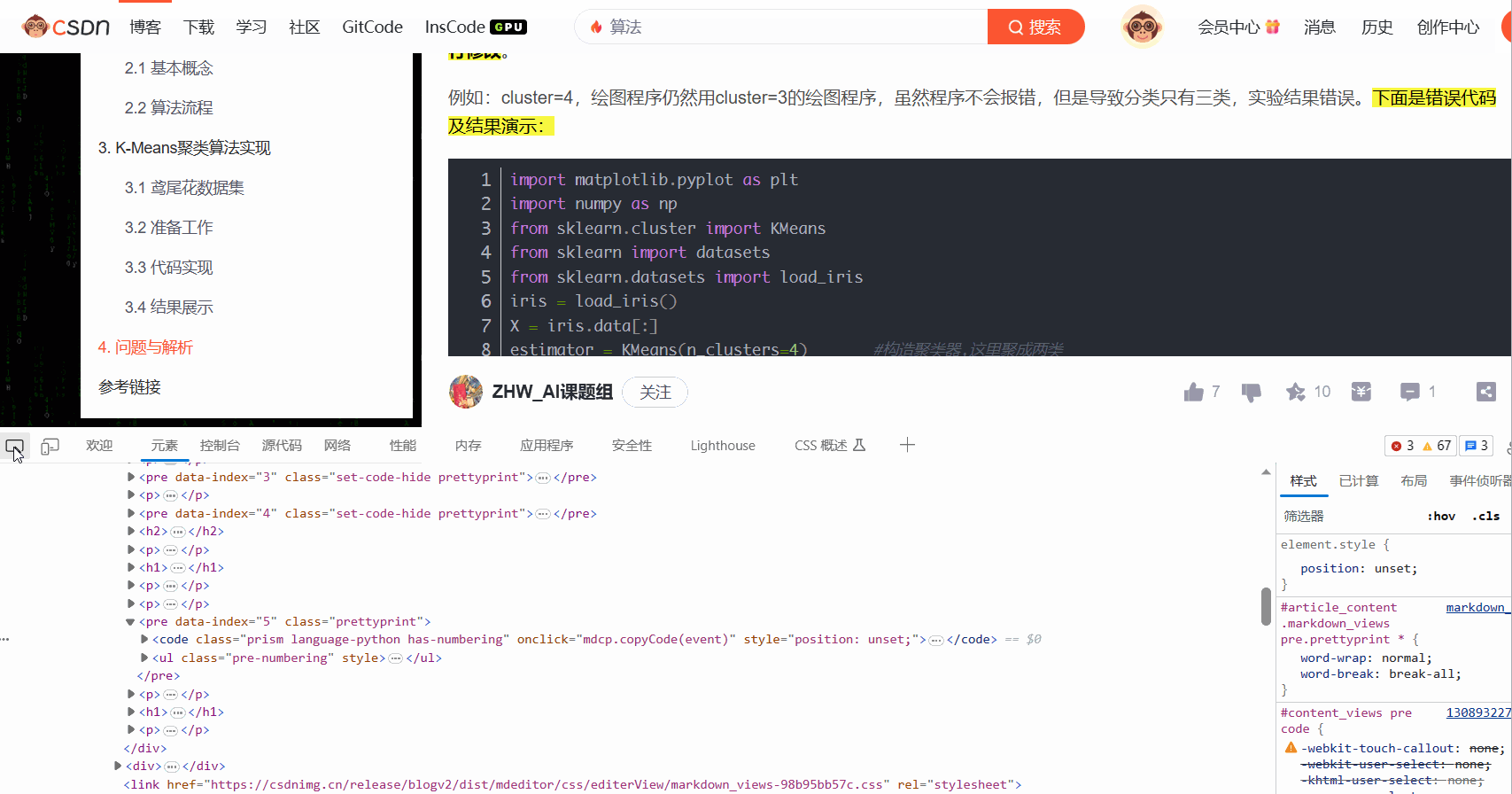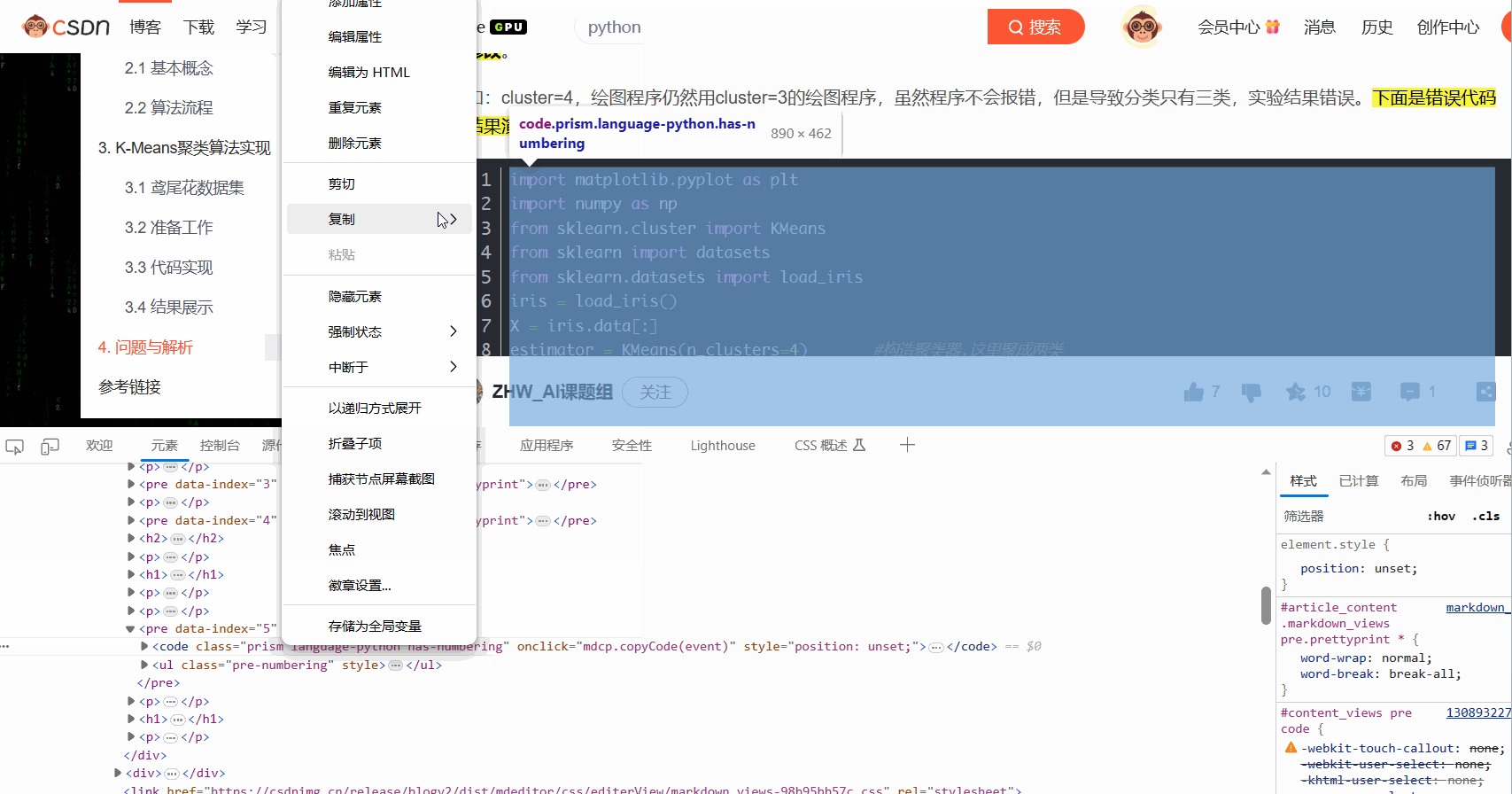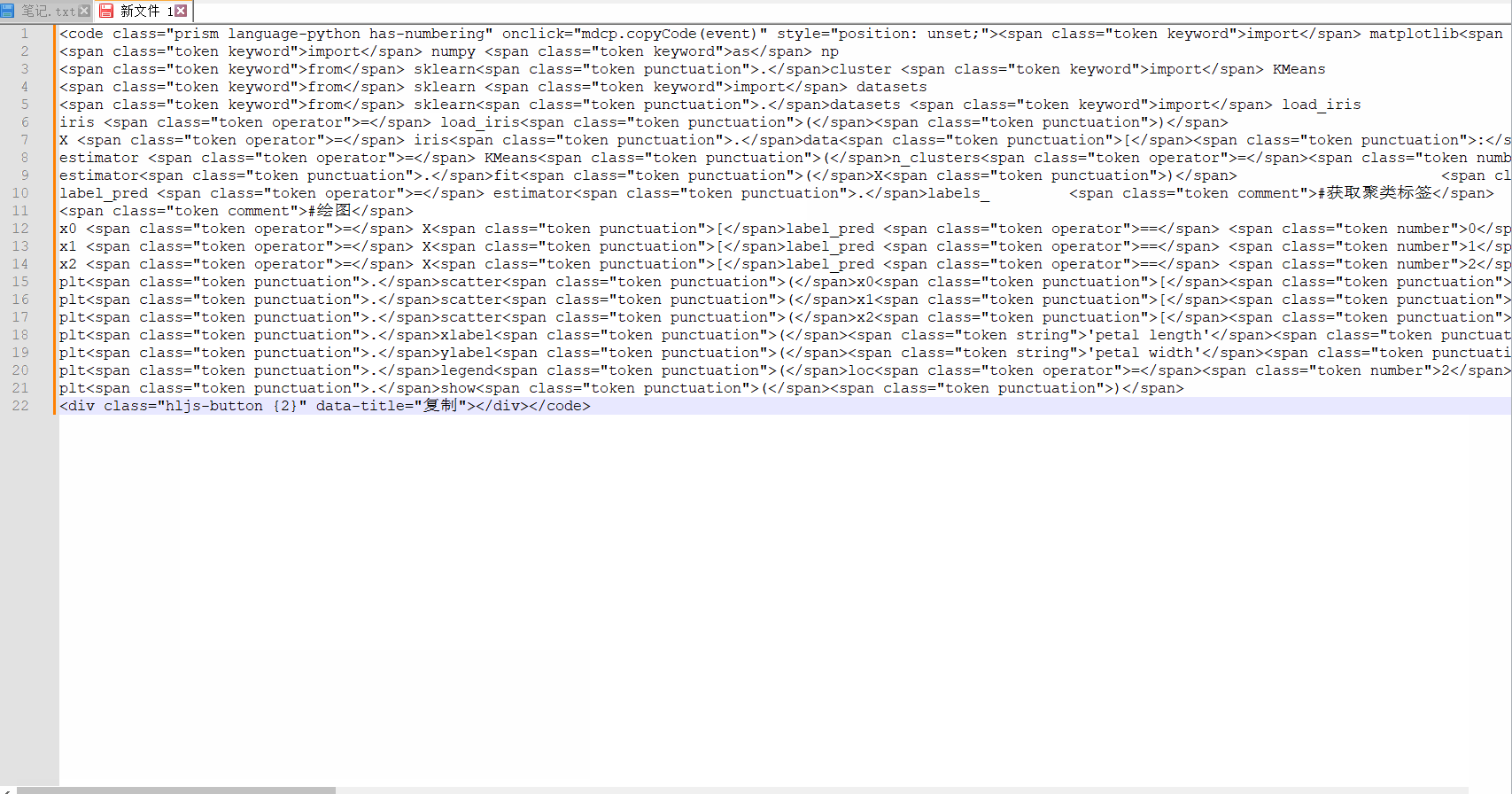
我们分析这段内容,主要由html标签包裹,我们需要去掉标签部分。
html标签有个特点,它是成对出现的,我们如果把所有的标签都去掉,那么其实就剩下内容部分了。有了这个思路,我们就可以开始工作了。
这里考虑使用正则替换的方式,将标签去掉,标签类似<div>或者</div>。我们直接通过正则<.*>可能会将所有内容都干掉。因为<div>xxx</div>这种其实也会匹配上<.*>。并不能只去掉两边的<div>和</div>。
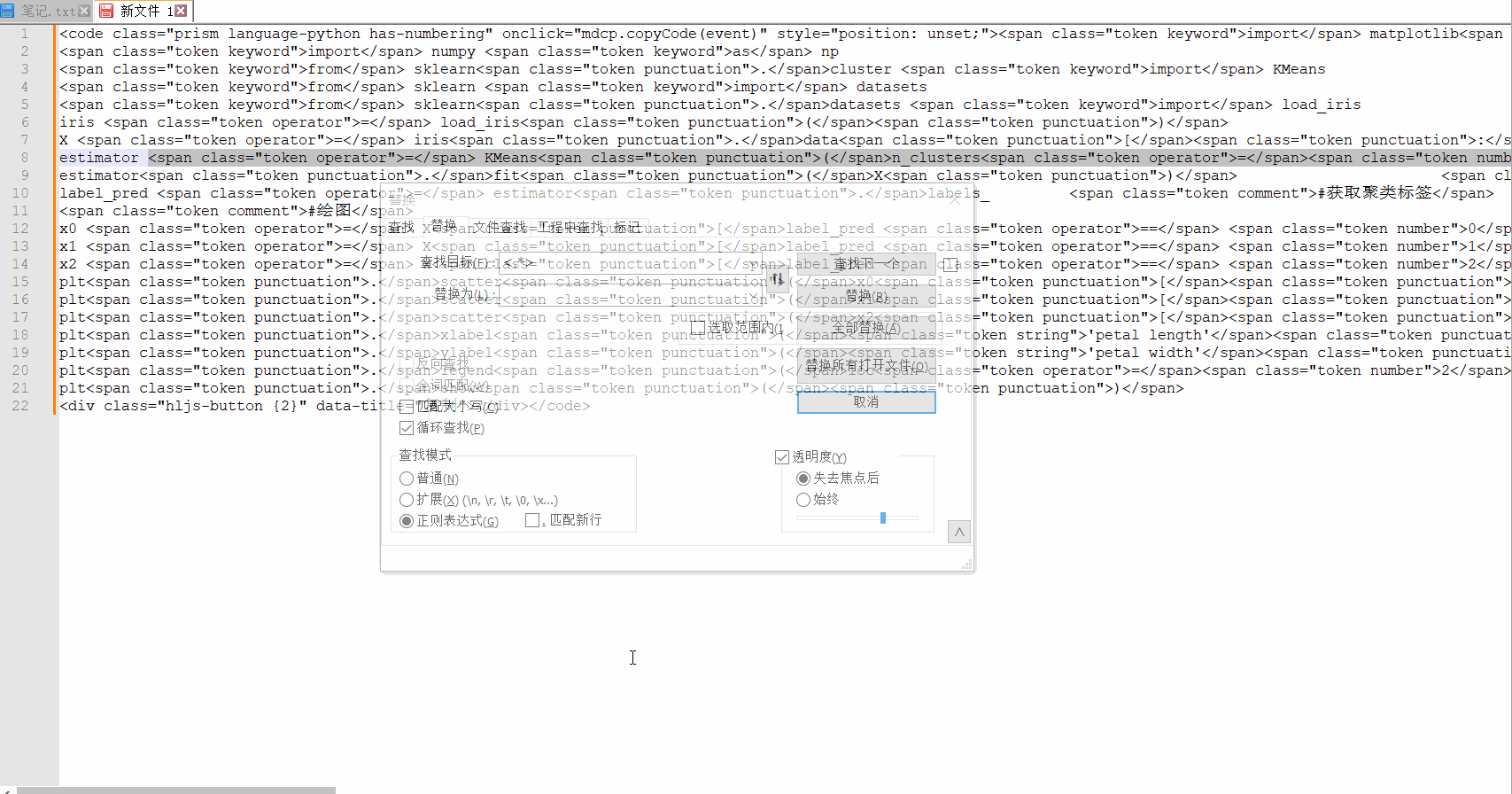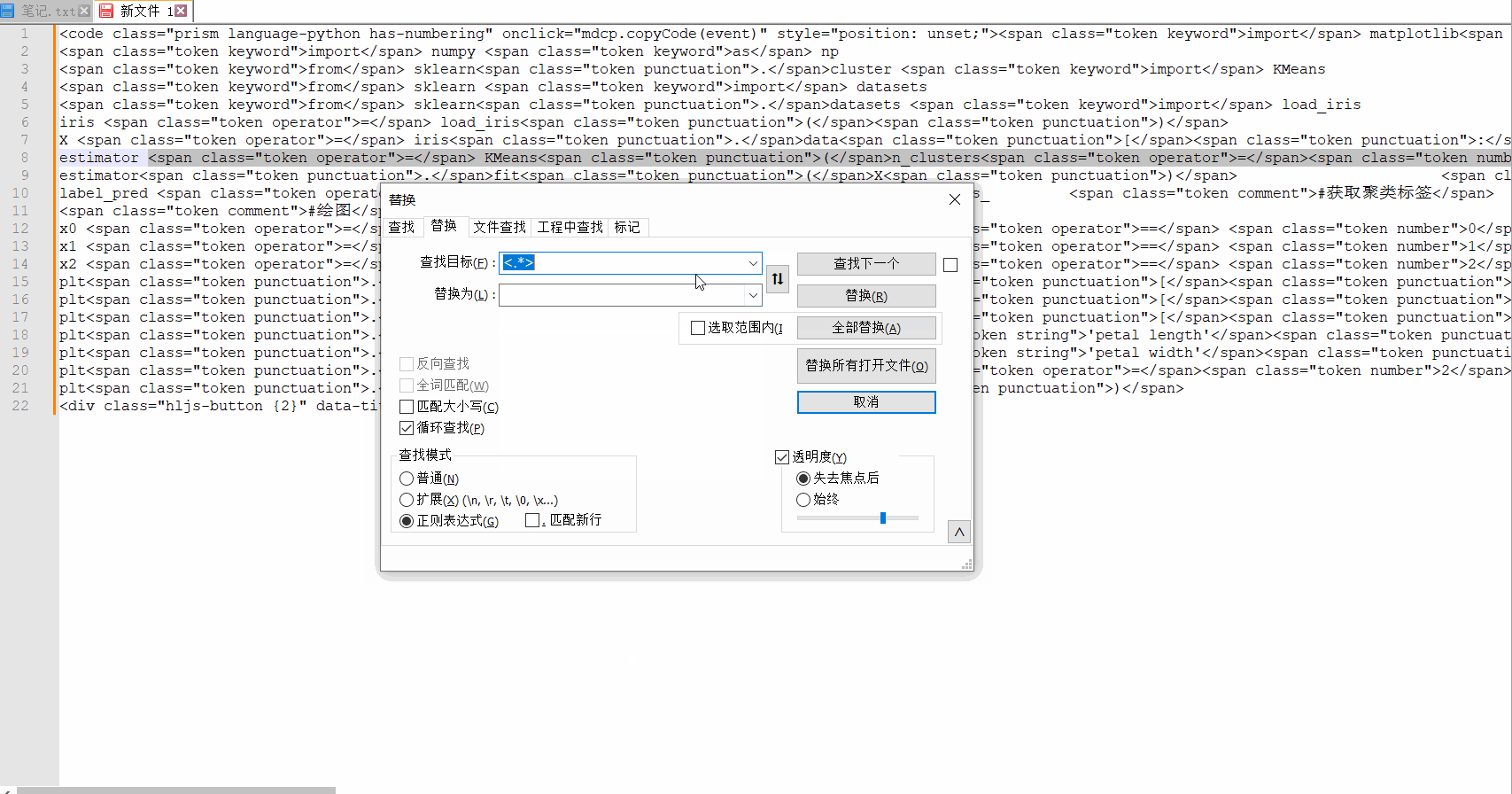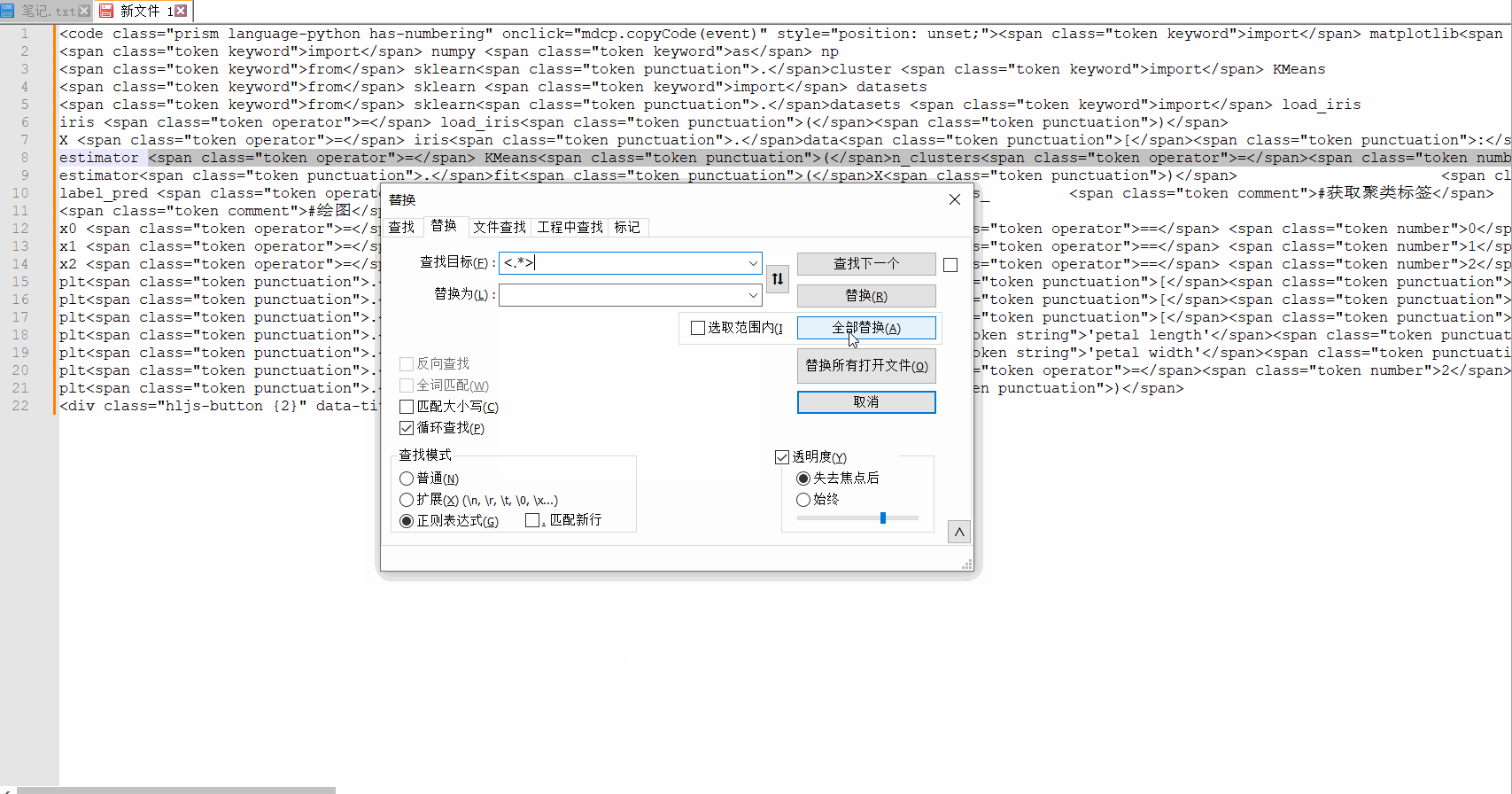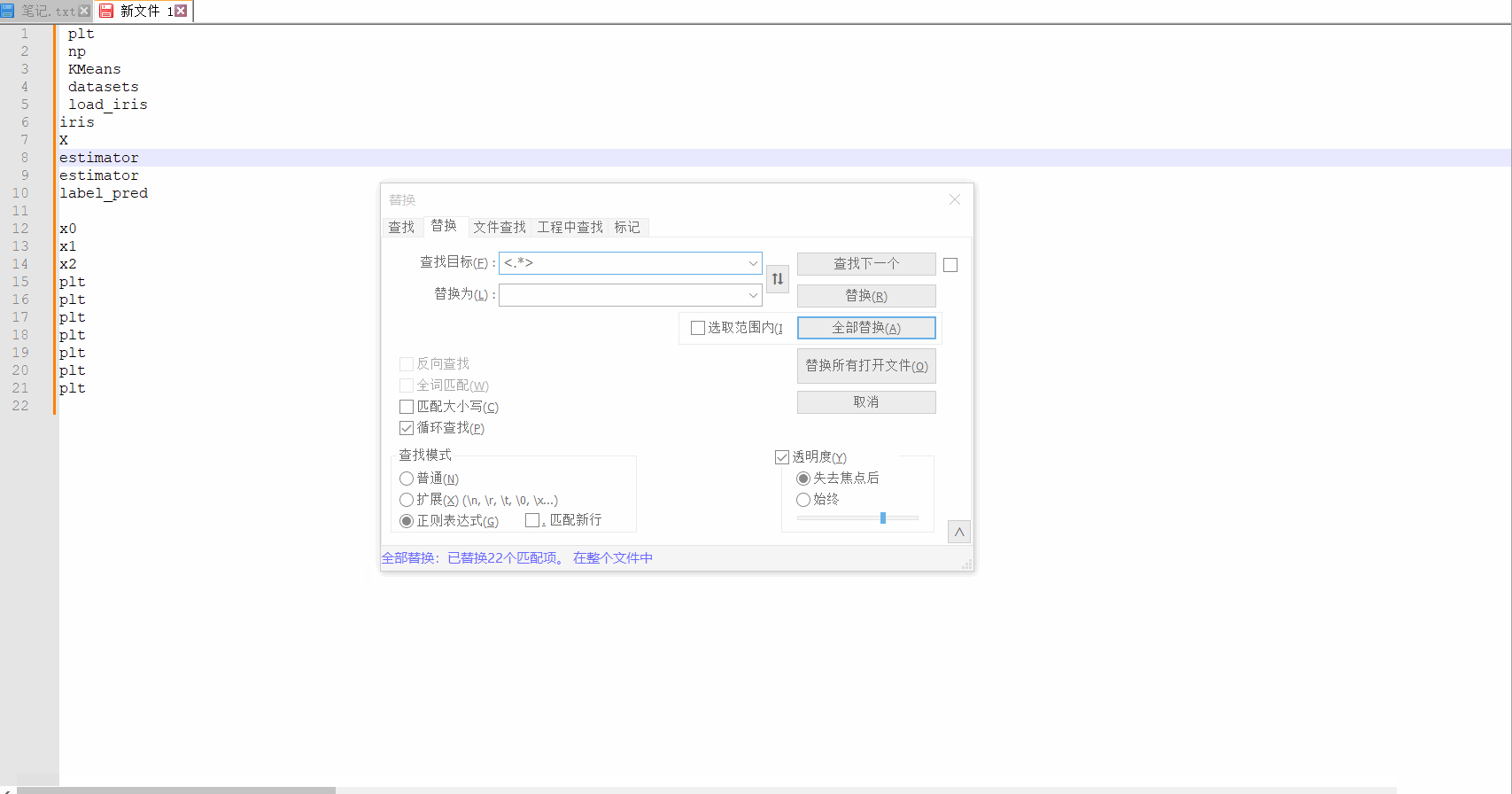
这里需要考虑<>内部不能再出现闭合标签">",似乎有点难以理解,意思这里只匹配唯一一个标签<>,不管是开始标签<div>,还是关闭标签</div>。
针对这个需求,正则再改变一下,<[^>]+>,替换效果如下所示:
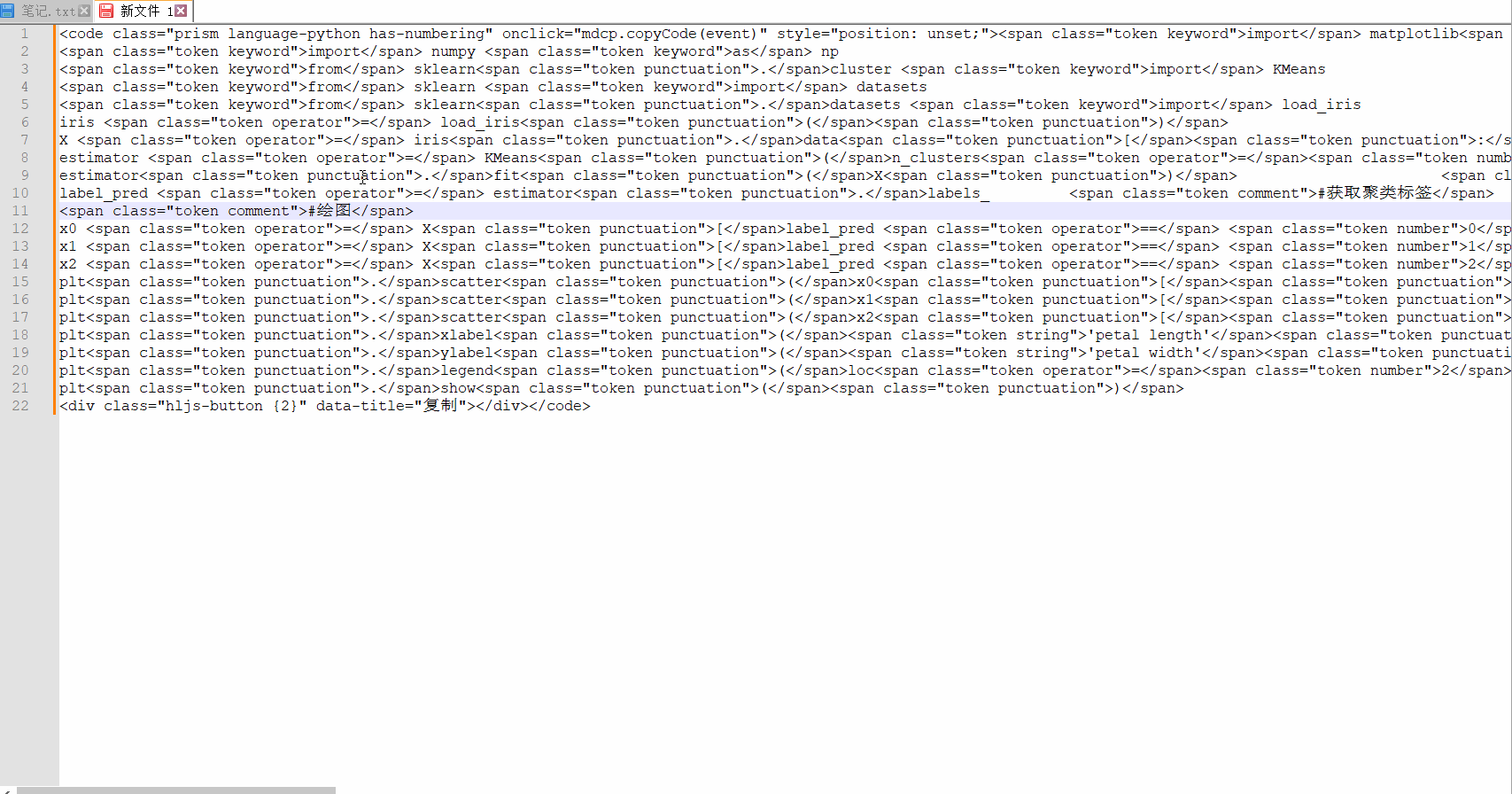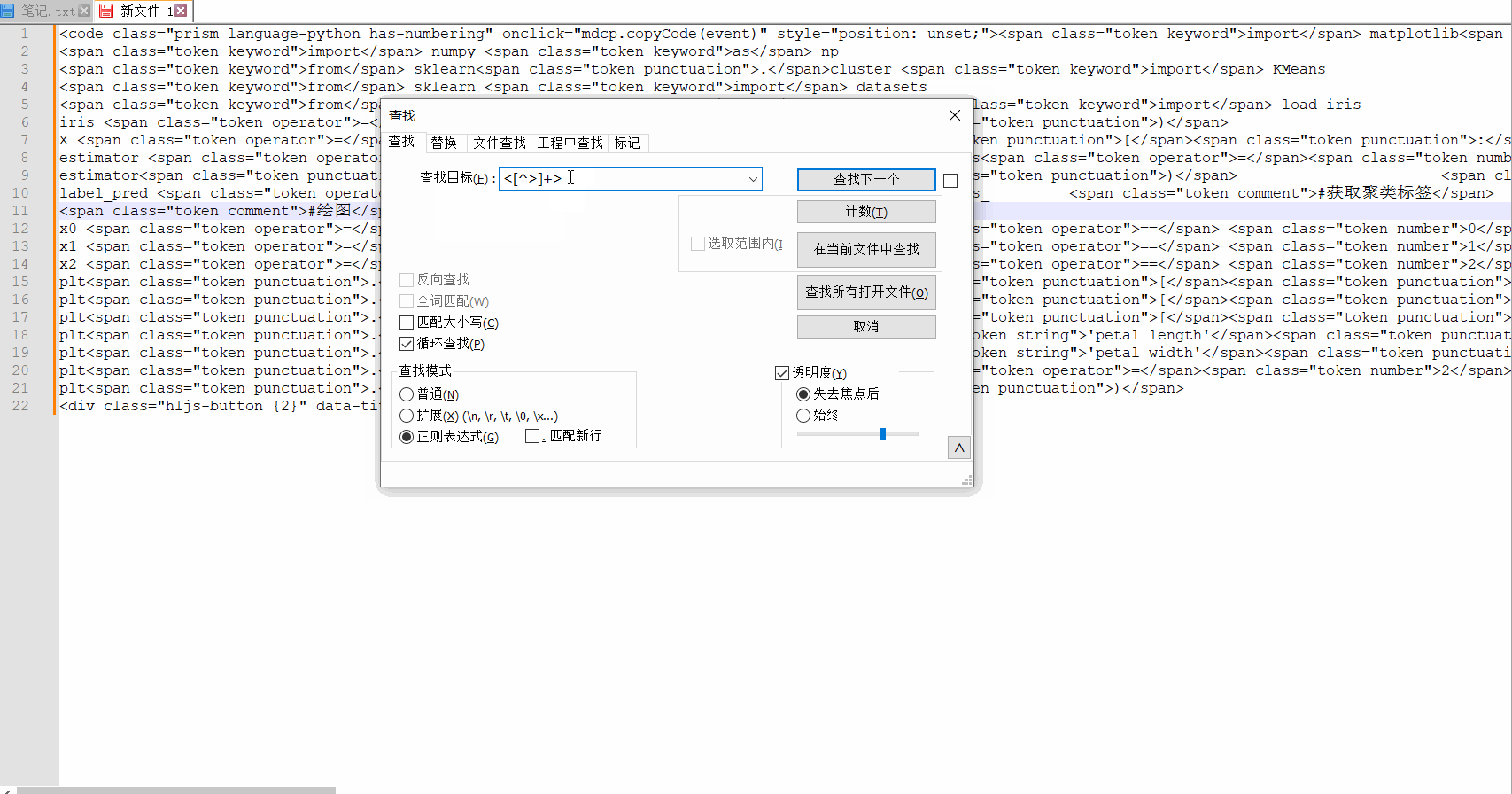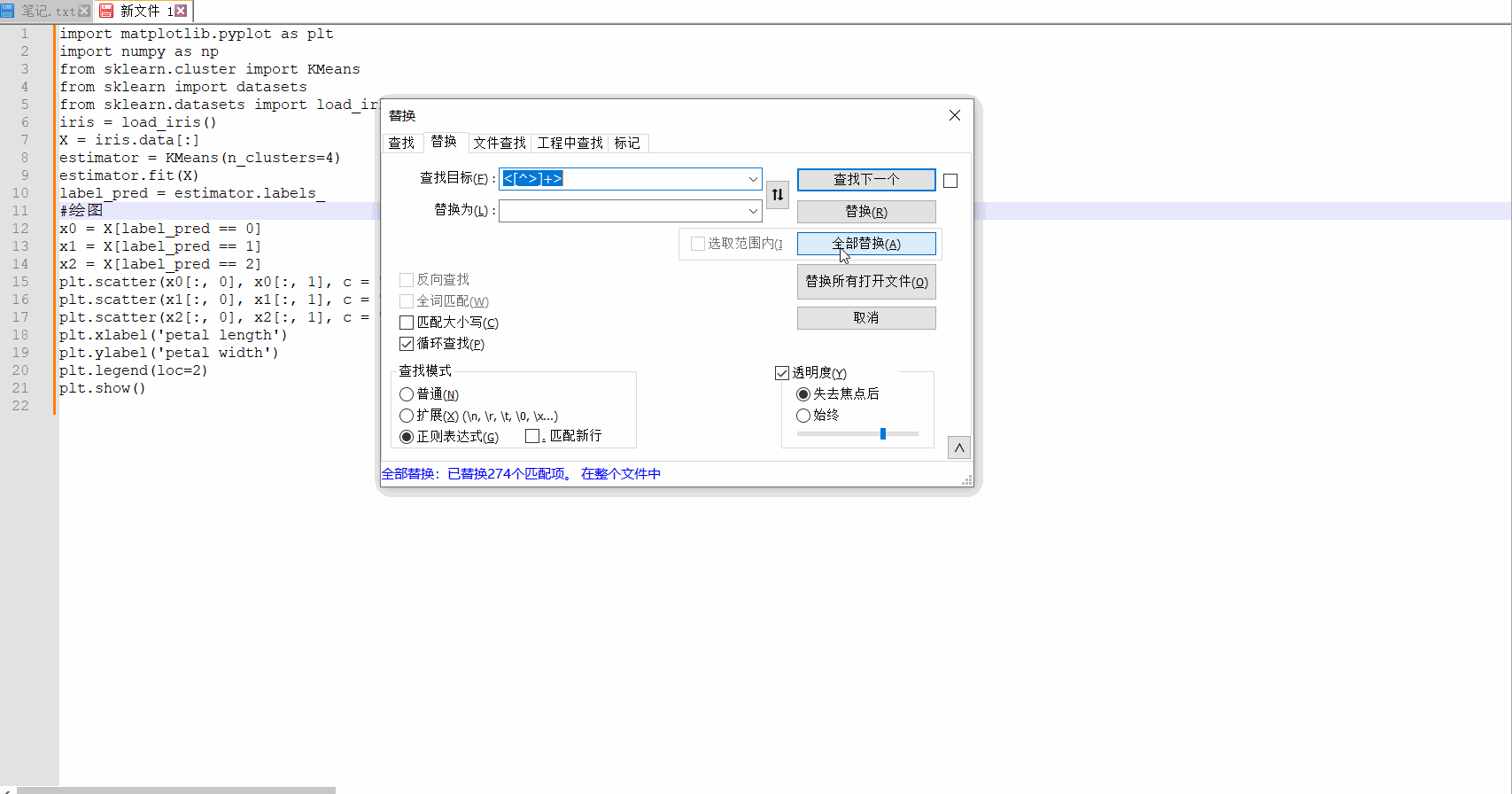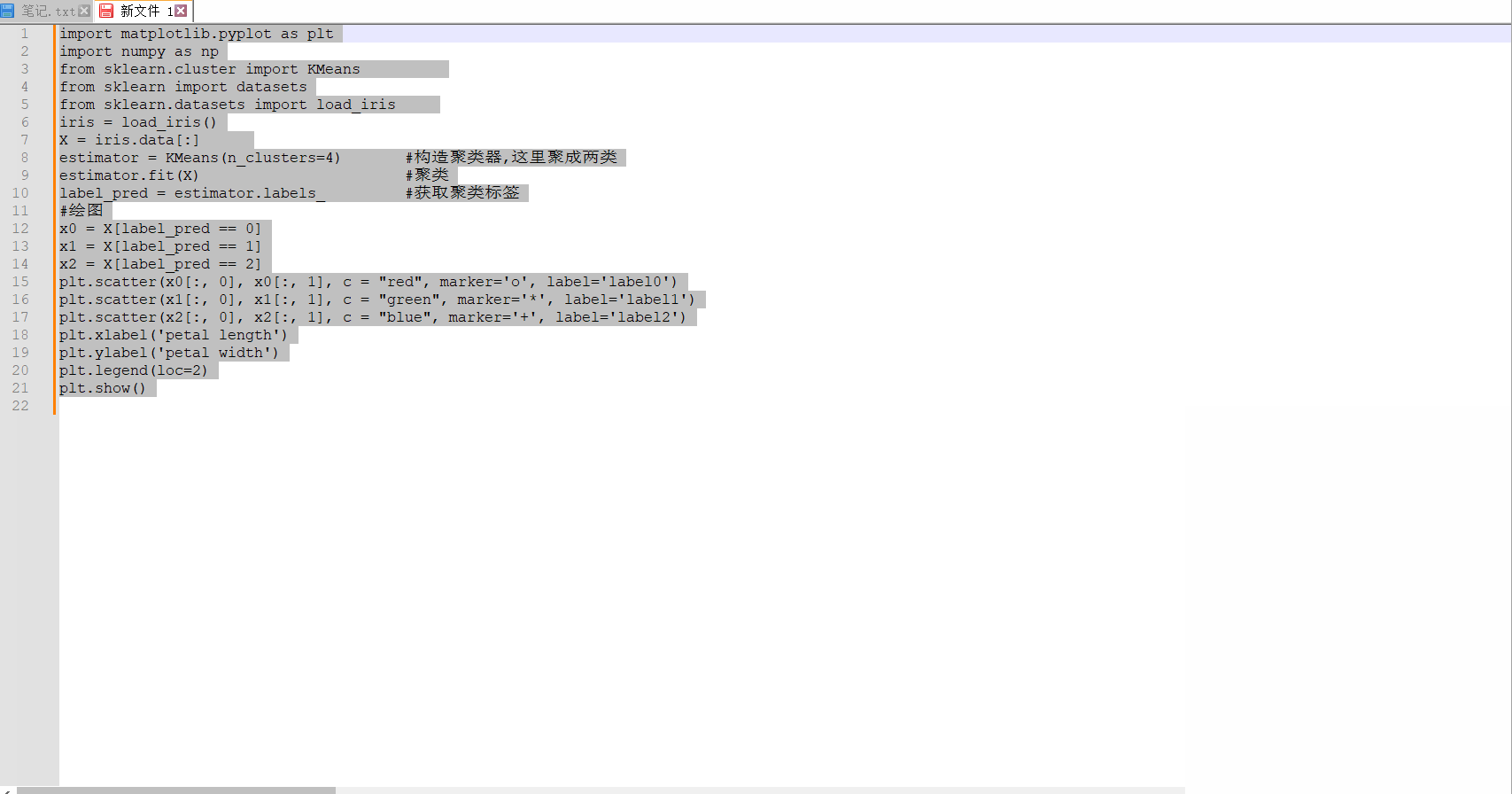
替换之后,正好剩下代码部分。就是我们需要的。
这里稍微说一下,这是使用notepad++来做的,它支持正则表达式书写,所以我们在替换界面可以看到这样的信息:
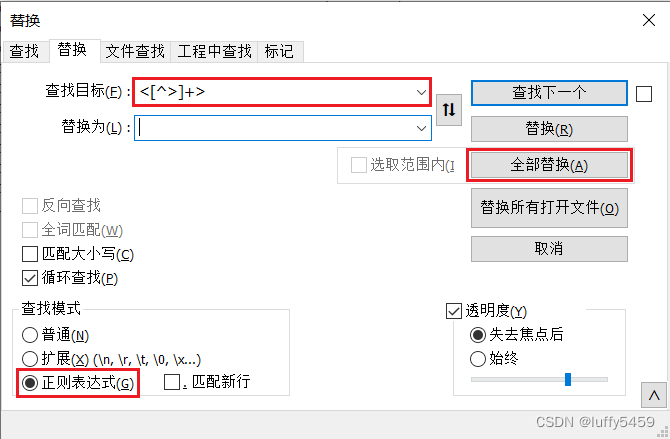
查找模式,需要切换到正则表达式,因为我们要删除这些标签,匹配的内容直接替换为空,所以“替换为”这里不用填写任何东西。最后选择全部替换即可。
另外一个替换的示例,这里我们通过java代码来实现。
假设我们有一个字符串如下所示:
[{"name":"buejee","id":101,"email":[],"mobile":"15909062001"},{"name":"lucky","id":102,"email":["[email protected]"],"mobile":"15909062002"}]这里虽然是一个json格式,但是它本身是作为一个字符串存在的,我们需要删除email这个部分。上面的示例里面有两个email,分别是 "email":[], 和 "email":["[email protected]"], 。为了将他们都去掉,我们的正则可以考虑这样写:
"email":\[[^\]]*\], 其中[^\]]*表示的是[]内部不能出现 ],这里的*表示内容可以有多个字符,也可以没有,匹配[]和["[email protected]"]。另外,因为 "[" 和 "]" 本身是正则里面的关键字符号,所以这里需要转义。在java中,转义符号是两个反斜杠\\。
程序代码如下:
package com.xxx.reg;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringReplace {
public static void main(String[] args) {
String str = "[{\"name\":\"buejee\",\"id\":101,\"email\":[],\"mobile\":\"15909062001\"},{\"name\":\"lucky\",\"id\":102,\"email\":[\"[email protected]\"],\"mobile\":\"15909062002\"}]";
Pattern pattern = Pattern.compile("\"email\":\\[[^\\]]*\\],");
Matcher matcher = pattern.matcher(str);
System.out.println(str);
String result = matcher.replaceAll("");
System.out.println(result);
}
}
运行结果:

打印结果正好删除了email部分。
这两个示例有相同的部分,就是删除的内容需要进行一个过滤,不能贪婪匹配,否则就达不到效果,使用正则中的[^]语法来限制不能出现某个特定的标志。