目录
一、ElasticSearch简介
1.ES与关系型数据库对比
| 关系型 | database(数据库) | table(表) | row(行) | column(列) |
|---|---|---|---|---|
| ES | index(索引库) | type(类型) | document(文档) | field(字段) |
2.什么是全文检索
全文检索:
通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数。
当用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了。
3.分词原理(基于倒排索引)
上来就懵逼了,何为倒排索引呢?还有正排索引?
先跟着我的步骤先来了解一下数据是怎么存到ES中的
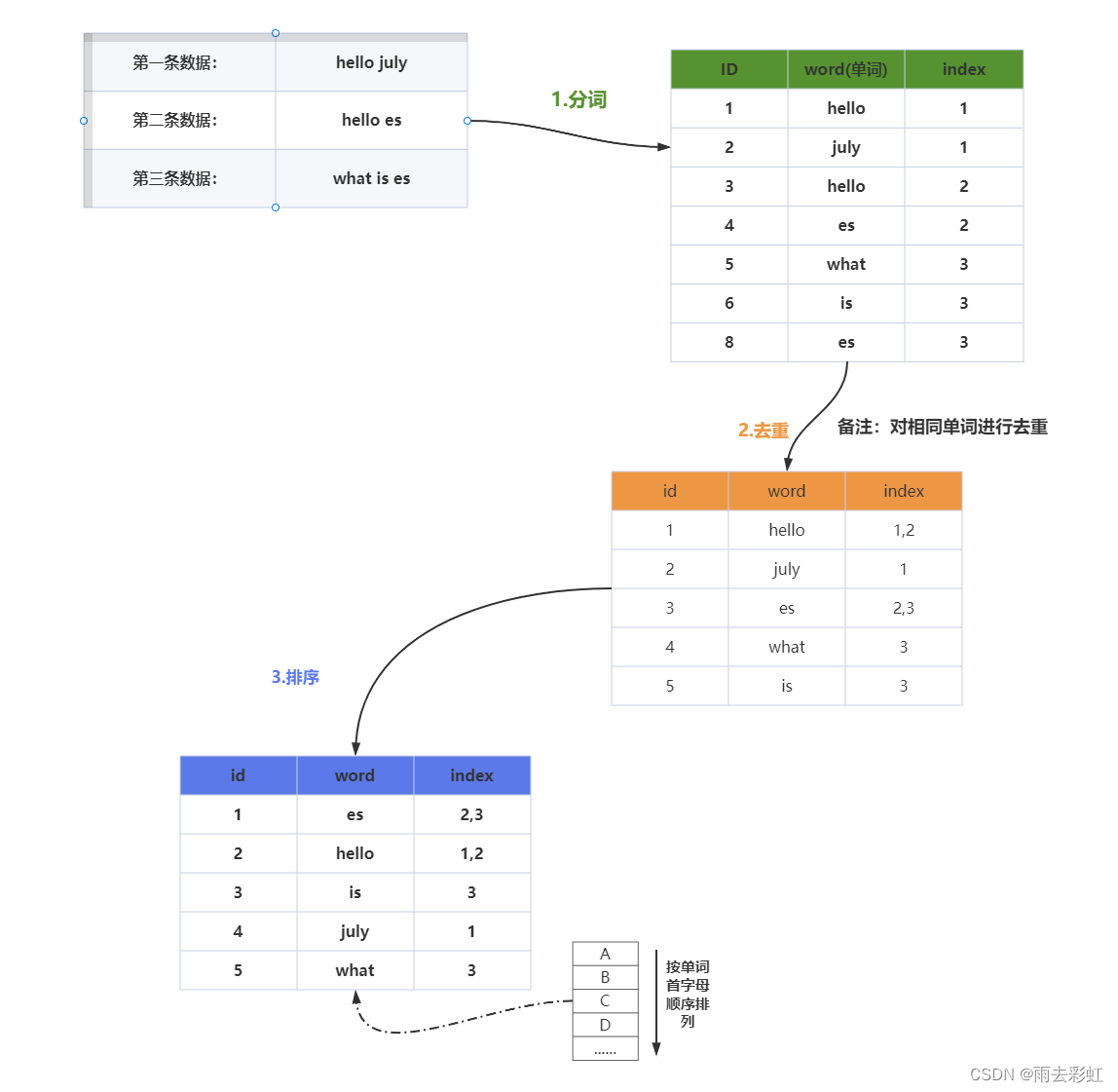
主要分为三个步骤
①分词
②去重
③排序
我们把如下数据存到ES中(以英文内容为例)
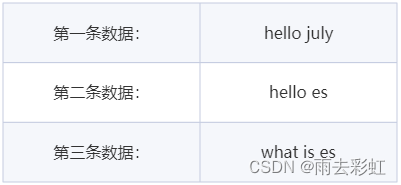
首先第一步:①分词
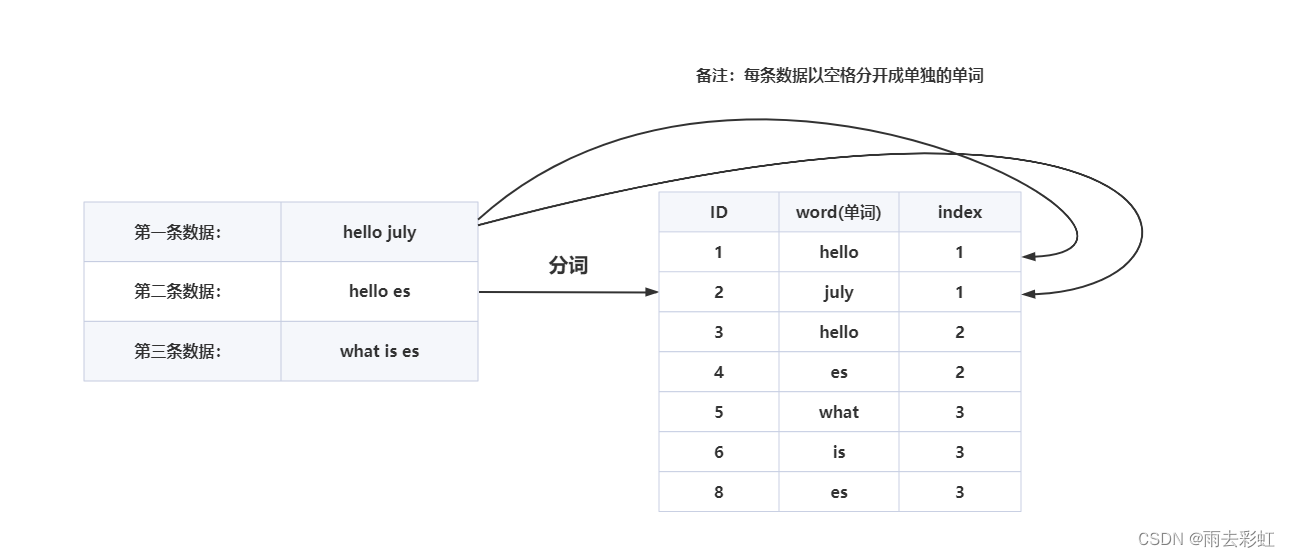
第二步:②去重
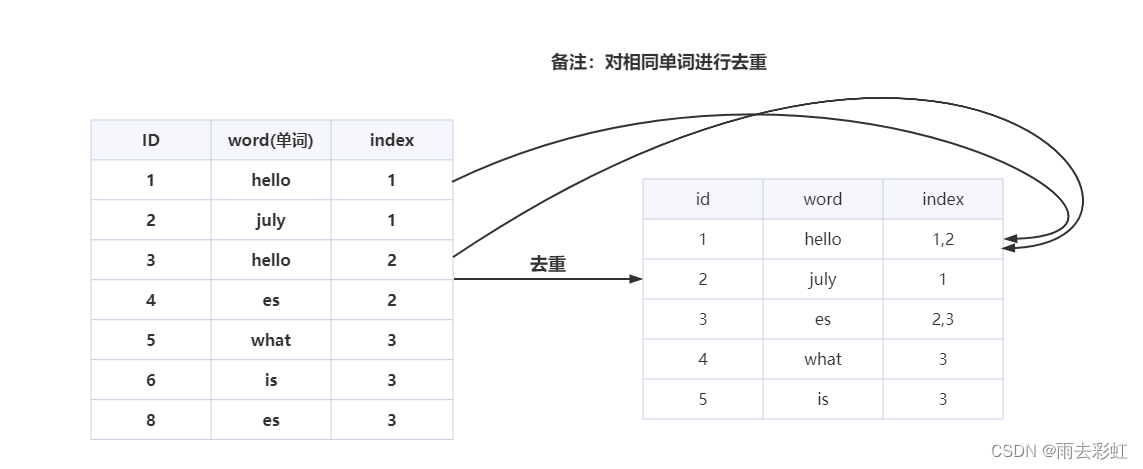
第三步:③排序
带着上边的疑问继续看。
我们要搜索一个内容如下
hello july what
搜索的内容背会拆开
分hello、july、what
根据这三个词去索引库搜索
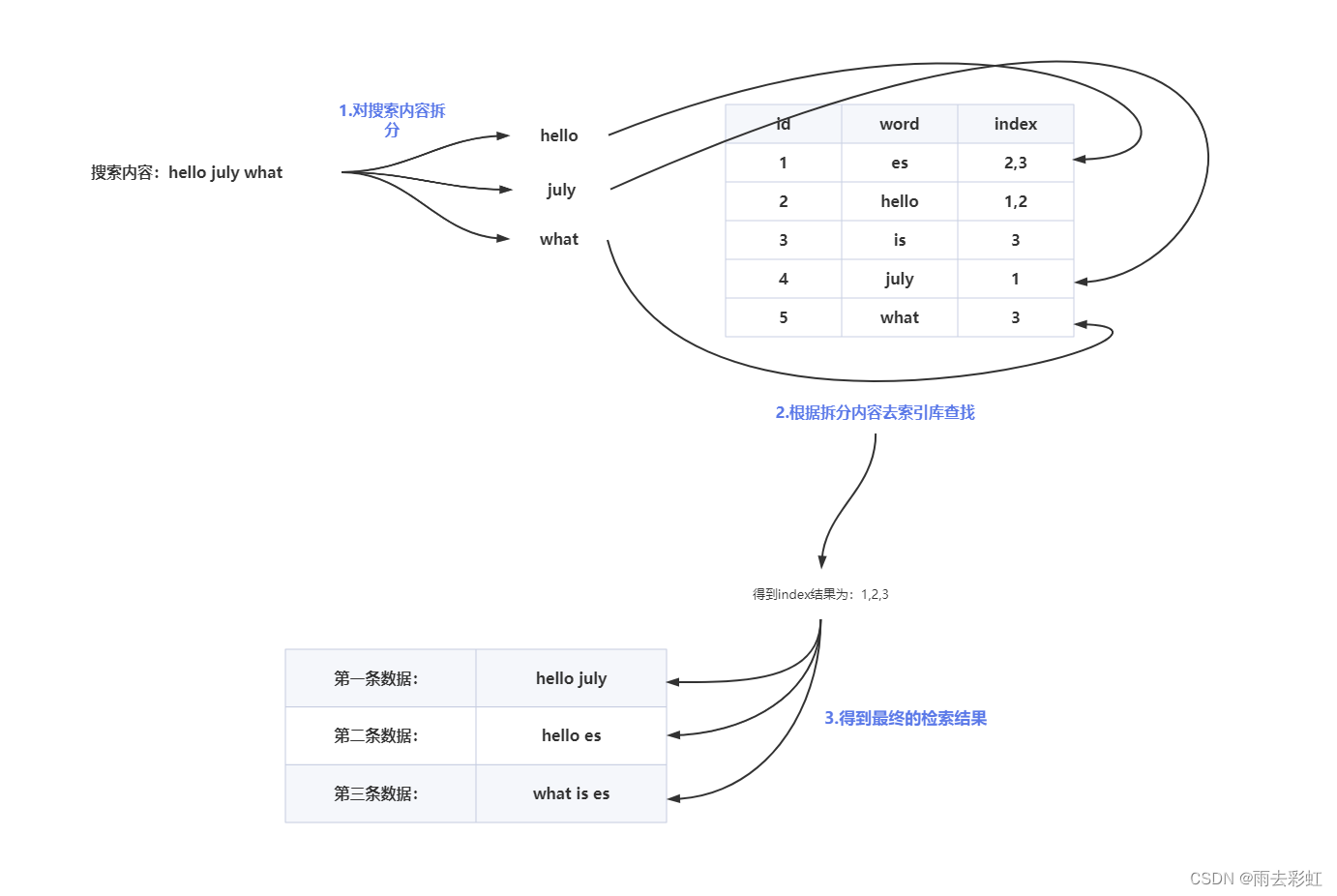
通过单词查找index的方式就称为倒排索引,那正排索引原理正好和它相反即通过index找word
完整流程如下
二、核心概念
1.索引index
一个索引就是一个拥有几份相似特征文档的集合。好比如上分讲解的倒排索引的例子(hello july,hello world)。
一个索引由一个名字来标识(必须全部是小写字母),并且对这个索引中文档进行索引、搜索、更新、删除的时候,都要使用到。简单理解为mysql的表名。
2.映射mapping
处理数据的方式和规则方面做一些限制,例如某个字段的数据类型、默认值、分词器、是否被索引等,都是映射里可以设置的。简单理解为mysql的表结构。
3.字段filed
相当于mysql表中的列
4.字段类型type
每一个字段都应该有一个对应的类型,在es中例如:text 、keyword、byte等
5.文档document
一个文档一个可以被索引的基础信息单元,类似mysql中的一条记录。文档以json格式来表示。
6.集群cluster
一个集群就是一个或者多个节点组在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。
7.节点node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点可以通过配置集群名称的方式来加入一个值得的集群。默认情况下,每个节点都会被安排加入到一个叫"elasticsearch"的集群中。在一个集群里,可以拥有任意多个节点。并且,如果当前网络中没有运行任何es节点,这是启动一个节点,会默认创建并加入到"elasticsearch"集群。
8.分片
问题1:一个索引可以存储超出单个结点硬件限制的大量数据(这里理解为一台服务为一个节点,这台服务器硬盘空间最大1TB,意思就是说我有一个索引库里边存的数据占用空间比1TB还多,那么单个结点是无法全部存储下来。)。
问题2:再或者单个结点处理搜索请求,响应比较慢。
Elasticsearch解决这两个问题的方式就是分片,把一个索引划分成多份(假如把一个索引设置分片数量为10,那就是划分10份,每份加在一起是索引的全部内容)。
①当创建索引时,你可以指定分片数量,在es7.x版本默认分片和副本数量都是1。
②每个分片本身也是一个功能完善并且独立的"索引",这个"索引"可以被放置到集群中的任何节点上。
③分片的重要性:
允许水平分割/扩展你的内容容量
允许在分片之上进行分布式,并行的操作,从而提高性能,吞吐量。
④分片如何分布,怎么从这么多分片聚合回搜索的请求,都是由elasticsearch管理的。(如果想要深入了解还是建议去逛逛官网这里不详细展开说明)
9.副本
一些中间件高可用的策略,思路基本上大同小异(比如kafka)。在一个网络或者云服务环境中,可能因为各种各样的情况导致出现一些异常和报错甚至宕机,使得某个分片/节点处于离线状态,或者直接消失。这种情况下,有一个故障转移机制是非常有用的。而因为这样情况的存在,Elasticsearch允许创建分片的一份或者多份拷贝,这些拷贝叫做分片副本,或者称副本。