Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
42、Flink 的table api与sql之Hive Catalog
文章目录
本文以一个详细的示例介绍了Flink与hive的集成,其中涉及的版本在示例部分有消息的说明。
本文依赖有hadoop、hive、kafka、mysql、flink等所有环境可用。
本分分为6个部分,即hivecatalog介绍、依赖、怎么使用和详细示例、flink与hive的胡数据类型映射等。
一、Hive Catalog
多年来,Hive Metastore已经发展成为Hadoop生态系统中事实上的元数据中心。许多公司在其生产中只有一个 Hive Metastore service实例来管理其所有元数据(Hive 元数据或非 Hive 元数据)。
对于同时拥有 Hive 和 Flink 部署的用户,HiveCatalog 使他们能够使用 Hive Metastore 来管理 Flink 的元数据。
对于刚刚部署 Flink 的用户,HiveCatalog 是 Flink 提供的唯一开箱即用的持久目录。如果没有持久目录,使用 Flink SQL CREATE DDL 的用户必须在每个会话中重复创建像 Kafka 表这样的元对象,这会浪费大量时间。HiveCatalog 填补了这一空白,使用户能够只创建一次表和其他元对象,并在以后跨会话方便地引用和管理它们。
二、Set up HiveCatalog
1、Dependencies
在 Flink 中设置 HiveCatalog 需要与整个 Flink-Hive 集成相同的依赖关系。具体参考:16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
2、Configuration
在 Flink 中设置 HiveCatalog 需要与整个 Flink-Hive 集成相同的配置。
具体参考:16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
三、How to use HiveCatalog
正确配置后,HiveCatalog 应该可以开箱即用。用户可以用 DDL 创建 Flink 元对象,之后应该会立即看到它们。
HiveCatalog 可用于处理两种类型的表:与 Hive 兼容的表和泛型表(Hive-compatible tables and generic tables)。与 Hive 兼容的表是以 Hive 兼容方式存储的表,就存储层中的元数据和数据而言。因此,通过 Flink 创建的 Hive 兼容表可以从 Hive 端查询。
另一方面,Generic tables是特定于 Flink 的。使用 HiveCatalog 创建Generic tables时,我们只是使用 HMS 来保存元数据。虽然这些表对 Hive 可见,但 Hive 不太可能理解元数据。因此,在 Hive 中使用此类表会导致未定义的行为。
Flink 使用属性 ‘is_generic’ 来判断表是与 Hive 兼容还是泛型。使用 HiveCatalog 创建表时,默认情况下将其视为泛型表。如果要创建与 Hive 兼容的表,请确保在表属性中将 is_generic 设置为 false。
如上所述,不应从 Hive 使用泛型表。在 Hive CLI 中,可以为表调用描述格式,并通过检查 is_generic 属性来确定它是否为泛型。泛型表将具有 is_generic=true。
四、示例-Flink 集成 Hive
本示例是介绍flink集成hive的内容,主要体现的是flink和hive共用hive的元数据。
本示例中hive的版本是3.1.2
flink的版本是1.13.6
hadoop的版本是3.1.4
kafka的版本是2.12-3.0.0
mysql的版本是5+,非8
1、修改hive的配置文件
下面的配置在我们部署hive的时候已经配置过,可能内容不一样,详见1、apache-hive-3.1.2简介及部署(三种部署方式-内嵌模式、本地模式和远程模式)及验证详解
非常重要
网络上很多都是介绍jar文件的,没有该种情况介绍
如果hive的其他机器上如果hive-site.xml文件中配置的如下远程访问hiveserver2的,则需要按照如下方式配置,否则flink不能访问hive的metadata服务。
网络上很多都是介绍jar文件的,没有该种情况介绍
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 远程模式部署metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://server4:9083</value>
</property>
</configuration>
不能访问元数据的错误提示
Flink SQL> show tables;
+----------------------+
| table name |
+----------------------+
| alanchan_kafka_table |
| source_table |
+----------------------+
2 rows in set
Flink SQL> desc source_table;
[ERROR] Could not execute SQL statement. Reason:
org.apache.hadoop.hive.metastore.api.MetaException: Your client does not appear to support Hive tests. To skip capability checks, please set metastore.client.capability.check to false. This setting can be set globally, or on the client for the current metastore session. Note that this may lead to incorrect results, data loss, undefined behavior, etc. if your client is actually incompatible. You can also specify custom client capabilities via get_table_req API.
我的环境配置文件本地路径是 /usr/local/bigdata/apache-hive-3.1.2-bin/conf/hive-site.xml ,配置如下所示:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/metastore?createDatabaseIfNotExist=true</value>
<description>metadata is stored in a MySQL server</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>MySQL JDBC driver class</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>user name for connecting to mysql server</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password for connecting to mysql server</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://server4:9083</value>
<description>IP address (or fully-qualified domain name) and port of the metastore host</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
</property>
</configuration>
将hive的配置文件配置好后,进行启动,然后验证hive运行情况。
- 启动命令
nohup /usr/local/bigdata/apache-hive-3.1.2-bin/bin/hive --service metastore > /usr/local/bigdata/apache-hive-3.1.2-bin/logs/metastore.log --hiveconf hive.root.logger=WARN,console 2>&1 &
nohup /usr/local/bigdata/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 > /usr/local/bigdata/apache-hive-3.1.2-bin/logs/hiveserver2.log --hiveconf hive.root.logger=WARN,console 2>&1 &
或
hive-metastore service hive-metastore start
hive-server2 service hive-server2 start
! connect jdbc:hive2://server4:10000
- 验证hive
[alanchan@server4 apache-hive-3.1.2-bin]$ beeline
Beeline version 3.1.2 by Apache Hive
beeline> ! connect jdbc:hive2://server4:10000
Connecting to jdbc:hive2://server4:10000
Enter username for jdbc:hive2://server4:10000: alanchan(根据自己当初配置的用户名和密码输入)
Enter password for jdbc:hive2://server4:10000: ********(根据自己当初配置的用户名和密码输入)
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://server4:10000> show databases;
+--------------------------+
| database_name |
+--------------------------+
| alan_hivecatalog_hivedb |
| default |
| test |
| testhive |
+--------------------------+
4 rows selected (0.14 seconds)
0: jdbc:hive2://server4:10000> use test;
No rows affected (0.025 seconds)
0: jdbc:hive2://server4:10000> show tables;
+----------------+
| tab_name |
+----------------+
| dim_address |
| dim_channel |
| dim_date |
| dim_product |
| dim_region |
| dim_user |
| dms_content_t |
| dw_sales |
| fact_order |
| fact_order2 |
+----------------+
10 rows selected (0.031 seconds)
0: jdbc:hive2://server4:10000>
2、配置Flink集群和SQL cli
1)、将所有 Hive 依赖项添加到 Flink 发行版中的 /lib 文件夹中
注意版本和名称,flink不同的版本要求不同。我的环境下总计如下jar包,
antlr-runtime-3.5.2.jar
flink-connector-hive_2.12-1.13.6.jar
flink-connector-jdbc_2.11-1.13.6.jar
flink-csv-1.13.5.jar
flink-dist_2.11-1.13.5.jar
flink-json-1.13.5.jar
flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
flink-shaded-hadoop-3-3.1.1.7.2.9.0-173-9.0.jar
flink-shaded-zookeeper-3.4.14.jar
flink-sql-connector-elasticsearch7_2.11-1.13.6.jar
flink-sql-connector-hive-3.1.2_2.12-1.13.6.jar
flink-sql-connector-kafka_2.11-1.13.5.jar
flink-table_2.11-1.13.5.jar
flink-table-blink_2.11-1.13.5.jar
guava-27.0-jre.jar
hive-exec-3.1.2.jar
libfb303-0.9.3.jar
mysql-connector-java-6.0.6.jar
而集成hive的jar如下
antlr-runtime-3.5.2.jar
flink-connector-hive_2.12-1.13.6.jar
flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
flink-shaded-hadoop-3-3.1.1.7.2.9.0-173-9.0.jar
flink-sql-connector-hive-3.1.2_2.12-1.13.6.jar
guava-27.0-jre.jar
hive-exec-3.1.2.jar
libfb303-0.9.3.jar
mysql-connector-java-6.0.6.jar
2)、修改 SQL CLI 的 yaml 配置文件 sql-cli-defaults.yaml
- 配置
如下所示(仅示例部分):
execution:
planner: blink
type: streaming
...
current-catalog: myhive # set the HiveCatalog as the current catalog of the session
current-database: mydatabase
catalogs:
- name: myhive
type: hive
hive-conf-dir: /opt/hive-conf # contains hive-site.xml
-------------------具体示例---------------------------
# 定义 catalogs
catalogs:
- name: alan_hivecatalog
type: hive
property-version: 1
hive-conf-dir: /usr/local/bigdata/apache-hive-3.1.2-bin/conf # 须包含 hive-site.xml
# 改变表程序基本的执行行为属性。
execution:
planner: blink # 可选: 'blink' (默认)或 'old'
type: streaming # 必选:执行模式为 'batch' 或 'streaming'
result-mode: table # 必选:'table' 或 'changelog'
max-table-result-rows: 1000000 # 可选:'table' 模式下可维护的最大行数(默认为 1000000,小于 1 则表示无限制)
time-characteristic: event-time # 可选: 'processing-time' 或 'event-time' (默认)
parallelism: 1 # 可选:Flink 的并行数量(默认为 1)
periodic-watermarks-interval: 200 # 可选:周期性 watermarks 的间隔时间(默认 200 ms)
max-parallelism: 16 # 可选:Flink 的最大并行数量(默认 128)
min-idle-state-retention: 0 # 可选:表程序的最小空闲状态时间
max-idle-state-retention: 0 # 可选:表程序的最大空闲状态时间
current-catalog: alan_hivecatalog # 可选:当前会话 catalog 的名称(默认为 'default_catalog')
current-database: alan_hivecatalog_hivedb # 可选:当前 catalog 的当前数据库名称(默认为当前 catalog 的默认数据库)
restart-strategy: # 可选:重启策略(restart-strategy)
type: fallback # 默认情况下“回退”到全局重启策略
# 用于调整和调优表程序的配置选项。
# 在专用的”配置”页面上可以找到完整的选项列表及其默认值。
configuration:
table.optimizer.join-reorder-enabled: true
table.exec.spill-compression.enabled: true
table.exec.spill-compression.block-size: 128kb
# 描述表程序提交集群的属性。
deployment:
response-timeout: 5000
- 验证配置内容
-- 1、启动flink sql(如果之前的sql cli启动中则需要重启,本示例使用的是yarn-session模式)
[alanchan@server1 bin]$ sql-client.sh -s yarn-session
2023-08-30 00:22:54,215 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-alanchan.
2023-08-30 00:22:54,215 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-alanchan.
No default environment specified.
Searching for '/usr/local/bigdata/flink-1.13.5/conf/sql-client-defaults.yaml'...found.
Reading default environment from: file:/usr/local/bigdata/flink-1.13.5/conf/sql-client-defaults.yaml
Command history file path: /home/alanchan/.flink-sql-history
-- 2、验证配置的catalog和database
Flink SQL> SHOW CURRENT CATALOG;
+----------------------+
| current catalog name |
+----------------------+
| alan_hivecatalog |
+----------------------+
1 row in set
Flink SQL> SHOW CURRENT DATABASE;
+-------------------------+
| current database name |
+-------------------------+
| alan_hivecatalog_hivedb |
+-------------------------+
1 row in set
Flink SQL> SHOW TABLES;
Empty set
3、验证kafka集群生产-消费功能
前提是kafka集群功能正常,以下仅仅是简单的验证指定的主题test_kafka_hive收发消息功能。
1)、kafka发送消息
[alanchan@server3 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic test_kafka_hive --partitions 1 --replication-factor 1
Created topic test_kafka_hive.
[alanchan@server3 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic test_kafka_hive
>hello alan
>hello alanchan
>good morning
>
2)、kafka接收消息
[alanchan@server3 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic test_kafka_hive --from-beginning
hello alan
hello alanchan
good morning
4、在Flink Cli创建kafka表
CREATE TABLE alanchan_kafka_table (
`id` INT,
name STRING,
age BIGINT,
t_insert_time TIMESTAMP(3) METADATA FROM 'timestamp',
WATERMARK FOR t_insert_time as t_insert_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'test_kafka_hive',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'format' = 'csv'
);
Flink SQL> CREATE TABLE alanchan_kafka_table (
> `id` INT,
> name STRING,
> age BIGINT,
> t_insert_time TIMESTAMP(3) METADATA FROM 'timestamp',
> WATERMARK FOR t_insert_time as t_insert_time - INTERVAL '5' SECOND
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'test_kafka_hive',
> 'scan.startup.mode' = 'earliest-offset',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.
Flink SQL> show tables;
+----------------------+
| table name |
+----------------------+
| alanchan_kafka_table |
| source_table |
+----------------------+
2 rows in set
Flink SQL> desc alanchan_kafka_table;
+---------------+------------------------+------+-----+---------------------------+---------------------------------------+
| name | type | null | key | extras | watermark |
+---------------+------------------------+------+-----+---------------------------+---------------------------------------+
| id | INT | true | | | |
| name | STRING | true | | | |
| age | BIGINT | true | | | |
| t_insert_time | TIMESTAMP(3) *ROWTIME* | true | | METADATA FROM 'timestamp' | `t_insert_time` - INTERVAL '5' SECOND |
+---------------+------------------------+------+-----+---------------------------+---------------------------------------+
4 rows in set
0: jdbc:hive2://server4:10000> use alan_hivecatalog_hivedb;
No rows affected (0.049 seconds)
0: jdbc:hive2://server4:10000> show tables;
+-----------------------+
| tab_name |
+-----------------------+
| alanchan_kafka_table |
| source_table |
+-----------------------+
2 rows selected (0.041 seconds)
0: jdbc:hive2://server4:10000> describe formatted alanchan_kafka_table;
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
| # col_name | data_type | comment |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | alan_hivecatalog_hivedb | NULL |
| OwnerType: | USER | NULL |
| Owner: | null | NULL |
| CreateTime: | Wed Aug 30 08:28:11 CST 2023 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://HadoopHAcluster/user/hive/warehouse/alan_hivecatalog_hivedb.db/alanchan_kafka_table | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | flink.connector | kafka |
| | flink.format | csv |
| | flink.properties.bootstrap.servers | 192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092 |
| | flink.scan.startup.mode | earliest-offset |
| | flink.schema.0.data-type | INT |
| | flink.schema.0.name | id |
| | flink.schema.1.data-type | VARCHAR(2147483647) |
| | flink.schema.1.name | name |
| | flink.schema.2.data-type | BIGINT |
| | flink.schema.2.name | age |
| | flink.schema.3.data-type | TIMESTAMP(3) |
| | flink.schema.3.metadata | timestamp |
| | flink.schema.3.name | t_insert_time |
| | flink.schema.3.virtual | false |
| | flink.schema.watermark.0.rowtime | t_insert_time |
| | flink.schema.watermark.0.strategy.data-type | TIMESTAMP(3) |
| | flink.schema.watermark.0.strategy.expr | `t_insert_time` - INTERVAL '5' SECOND |
| | flink.topic | test_kafka_hive |
| | transient_lastDdlTime | 1693355291 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | serialization.format | 1 |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
42 rows selected (0.279 seconds)
5、通过kafka发送消息,同时在flink中查询
1)、kafka发送消息
[alanchan@server3 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic test_kafka_hive --partitions 1 --replication-factor 1
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic test_kafka_hive.
[alanchan@server3 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic test_kafka_hive
>1,alan,15
>2,alanchan,20
>3,alanchanchn,25
>4,alan_chan,30
>5,alan_chan_chn,45
>
2)、Flink sql cli查询数据
Flink SQL> SET sql-client.execution.result-mode = tableau;
[INFO] Session property has been set.
Flink SQL> select * from alanchan_kafka_table;
+----+-------------+--------------------------------+----------------------+-------------------------+
| op | id | name | age | t_insert_time |
+----+-------------+--------------------------------+----------------------+-------------------------+
| +I | 1 | alan | 15 | 2023-08-30 09:29:33.993 |
| +I | 2 | alanchan | 20 | 2023-08-30 09:29:48.793 |
| +I | 3 | alanchanchn | 25 | 2023-08-30 09:29:54.795 |
| +I | 4 | alan_chan | 30 | 2023-08-30 09:30:01.480 |
| +I | 5 | alan_chan_chn | 45 | 2023-08-30 09:30:07.161 |
五、支持的数据类型
对于与 Hive 兼容的表,HiveCatalog 需要将 Flink 数据类型映射到相应的 Hive 类型,如下表所述:
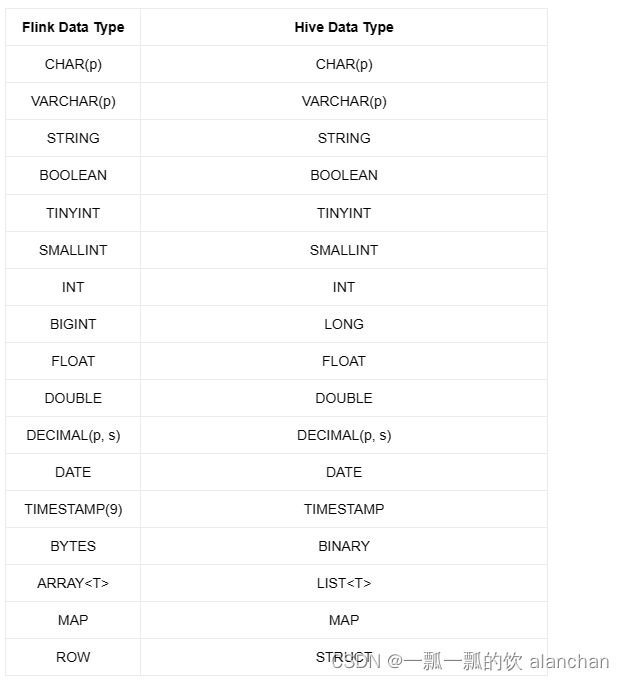
关于类型映射需要注意的事项:
- Hive CHAR § 类型的最大长度为255
- Hive VARCHAR§类型的最大长度为65535
- Hive MAP类型的key仅支持基本类型,而Flink’s MAP 类型的key执行任意类型
- Hive不支持联合数据类型,比如STRUCT
- Hive TIMESTAMP 的精度是 9 , Hive UDFs函数只能处理 precision <= 9的 TIMESTAMP 值
- Hive 不支持 Flink提供的 TIMESTAMP_WITH_TIME_ZONE, TIMESTAMP_WITH_LOCAL_TIME_ZONE, 及MULTISET类型
- Flink INTERVAL 类型与 Hive INTERVAL 类型不一样
六、Scala Shell
注意:由于 Scala Shell 目前不支持 blink planner,因此不建议在 Scala Shell 中使用 Hive 连接器。
以上,以一个详细的示例介绍了Flink与hive的集成,其中有很多的坑都解决了。