三个微调步骤讨论
第 1 步:监督微调
监督微调(SFT)确实在大型语言模型(LLM)领域取得了重大进展。但是,仍可能发生意外行为,例如重复内容生成以及困惑度 (PPL) 分数与生成功能之间的不一致。
根据我们的测试,有几个术语会影响生成行为:
weight decay:OPT模型经过权重衰减预训练。之后,微调通常会继承此设置。但是,它可能不会产生所需的模型。特别是,对于我们的OPT-1.3B示例,我们禁用了重量衰减。dropout:与上述类似,辍学用于OPT预训练。但是,SFT可能不需要它。特别是,对于我们的 OPT-1.3B 示例,我们启用了 dropout。dataset:使用更多数据通常提供更好的模型质量。但是,如果数据集的来源差异太大,则可能会损害性能。对于我们的 OPT-1.3B 示例,我们使用以下四个数据集:.Dahoas/rm-static Dahoas/full-hh-rlhf Dahoas/synthetic-instruct-gptj-pairwise yitingxie/rlhf-reward-datasetstraining epochs通常,为了避免过度拟合,如果较小的时期可以实现相似的模型质量,我们会选择较小的训练时期而不是较长的时期(在这种情况下,我们使用 PPL 作为指标)。然而,与 InstructGPT 指出的类似,我们发现即使由于训练时间较长而导致过度拟合,仍然建议使用更长的训练时期来获得更好的生成质量。特别是,对于我们的 OPT-1.3B 示例,我们使用 16 个 epoch,即使我们发现 1 或 2 个 epoch 训练可以达到相同的 PPL 分数。
第 2 步:奖励模型微调
奖励模型(RM)微调确实与SFT相似,主要区别在于:(1)训练数据集不同 - RM需要对同一查询的良好响应和不良响应;(2)训练损失不同 - RM要求对排名损失作为优化目标。
我们为奖励模型提供了两个指标:(1)接受的响应(和不良响应)的奖励分数,以及(2)准确性,即何时接受的响应可以获得比拒绝的响应更高的分数。有时,我们观察到准确率非常高,但接受答案的平均奖励分数为负,或者被拒绝答案的分数与接受的答案相似。这会影响步骤3模型的质量吗?如果我们使用步骤 3 的指标奖励分数增益,这可能没有任何问题。但是,此机器学习指标(奖励分数增加/增加)无法真正反映步骤3模型生成质量。因此,我们还没有明确的答案。
在这里,我们分享更多关于我们在探索过程中观察到的内容:
weight decay:对于我们的 OPT-350m 示例,我们启用了 0.1 的重量衰减。dropout:对于我们的OPT-350m示例,我们禁用了辍学。dataset:对于我们的 OPT-350m 示例,我们使用以下四个数据集:。Dahoas/rm-static Dahoas/full-hh-rlhf Dahoas/synthetic-instruct-gptj-pairwise yitingxie/rlhf-reward-datasetstraining epochsInstructGPT 建议使用 1 个 epoch 微调模型,因为过度拟合会损害步骤 3 的性能。在我们的探索过程中,当我们增加训练周期时,我们没有看到过度拟合行为。但是,要遵循作者的指示。我们将训练周期设置为 1。
此外,我们在此处提供了更多探索,即使我们尚未将它们设置为选项或将它们包含在当前管道中
multiple answers for one prompt在 InstructGPT 中,作者特别提到,对一个提示使用配对的拒绝和接受答案不利于奖励模型训练。因此,InstructGPT 为每个提示解释数据集 4--9 个答案。但是,我们没有找到具有此功能的良好数据集。initialize RM with SFT or Pretrained checkpoint我们在内部对此进行了测试,但没有发现准确性或奖励分数有太大差异。此外,在InstructGPT中,作者也有同样的发现。但是,我们鼓励用户尝试使用它供自己使用。Reward score calculation我们使用最终令牌(或第一个填充令牌)来获取奖励分数。但是,它可能不是最佳选择。例如,用户可以尝试整个答案的平均分数等。Reward loss objective我们只是使用排名损失作为目标。但是,其他的,如MSE,也可以是一种选择。
第 3 步:RLHF 微调
RLHF微调是三步训练中最复杂的一步。与SFT类似,奖励分数不能真正反映模型生成质量。此外,我们观察到奖励分数在某个时间点下降到初始阶段,然后迅速恢复。更糟糕的是,我们还看到训练很容易出现分歧。我们在这里分享我们的设置和观察结果。
weight decay:对于我们的OPT-1.3B / 350m(演员/评论家)示例,我们禁用了两个模型的重量衰减。dropout:我们禁用了 OPT-1.3B 的退出,并为 OPT-350m 启用了它。dataset:我们使用以下单个数据集:。Dahoas/rm-statictraining epochs奖励分数很快变成platou。因此,我们将 OPT-1.1B/3m(演员/评论家)示例的训练周期设置为 350。但是,作为 SFT,更长的训练可能会带来更好的模型质量。ema checkpoint我们观察到 ema 检查点通常可以带来 bettr 模型生成质量,如 InstructGPT 中所述。PPO related hyperparametersPPO 训练有很多超参数,请参阅此处。目前,我们为用户对它们进行了硬编码,但你可能希望根据自己的使用情况调整它们。mix unsupervised trainingInstructGPT建议混合PPO和无监督训练,以防止模型基准质量的损失。但是,当我们直接应用 Instruct 中的超参数时,模型无法收敛。因此,我们停止探索这一点。但是,鼓励用户对其进行测试并调整超参数以供自己使用。diverging issue我们发现,使用不同的代训练批大小()和PPO训练批大小(),使用多个PPO训练周期()或多个代批大小()是非常不稳定的。这些都指向同一个问题:在生成实验数据后,我们无法多次更新Actor模型。因此,在我们所有的成功运行中,我们设置了和.这对于标准的 RL 训练管道来说是出乎意料的,我们已经尝试了不同的方法来克服这个问题,但都失败了。造成这种不稳定性的最可能原因之一是我们发现函数中使用的 and 即使在连续两次迭代内也会迅速发散,这导致对应的巨大。设置严格的上限可以缓解这个问题,但不能完全解决收敛问题。--per_device_train_batch_size--per_device_mini_batch_size--ppo_epochs--generation_batch_numbersper_device_train_batch_size=per_device_mini_batch_sizeppo_epochs=generation_batch_numbers=1log_probsold_log_probsactor_loss_fnratio
有的训练也可以分为四个步骤:
1.pretain model:这个阶段大部分情况是设计成无监督或者弱监督学习,让模型成为博览群书有知识的通才
2.模型微调:这部分主要对pretrain model做少量标签或者知识补充,让通才把自己的知识结构做梳理成为体系
3.上游任务学习:这部分任务训练模型专业技能,让模型在有通识时也有更强工作力,同时也会重塑通识体系
4.对齐学习:渊博且有能力,但是还得让它更懂人话,更容易和他沟通,所以需要做alignment,这部分现在主流是RLHF
上面的几个过程并非只做一轮,经常是需要做很多轮的迭代才可能让模型有较好表现。上面的流程分工在开始的几轮是顺序进行,有相对明显的界限。但是越到后面的迭代边界越模糊,往往是同时几种方法一起上。所以大家知道有这些流程和手段就好,不需要去纠结他们清晰边界。
大模型训练手段
finetune
Fine-tune的核心思想是利用在大型数据集(例如ImageNet、COCO等)上训练好的预训练模型,然后使用较小数据集(小于参数数量)对其进行微调[3]。这样做的优势在于,相对于从头开始训练模型,Fine-tune可以省去大量的计算资源和时间成本,提高了计算效率,甚至可以提高准确率[1][2]。
finetune是指在预训练模型的基础上,针对特定任务进行微调,以提高模型的性能。Fine-tune的具体方法有多种,但一般而言,可以通过调整模型的层数、调整学习率、调整批量大小等方式进行微调[2]。
Finetune的优势在于不用完全重新训练模型,从而提高效率,因为一般新训练模型准确率都会从很低的值开始慢慢上升,但是finetune能够让我们在比较少的迭代次数之后得到一个比较好的效果。
虽然Fine-tune有很多优势,但也存在一些不足之处。例如,Fine-tune需要大量的数据集才能提高模型的性能,这可能会导致一些任务难以实现。此外,Fine-tune的性能很大程度上依赖于预训练模型的质量和适用性,如果预训练模型和微调数据集之间存在差异,则Fine-tune可能无法提高模型性能[1]。
未来,Fine-tune技术将继续得到广泛的应用。一方面,随着深度学习模型的不断发展和改进,预训练模型的质量和适用性将会不断提高,从而更加适用于Fine-tune技术。另一方面,Fine-tune技术也将有助于解决一些实际应用中的难题,例如小数据集、数据集标注困难等问题[1][3]。

prompt learn
Prompt Learning的基本概念:Prompt Learning是一种自然语言处理技术,它通过在预训练模型的输入前面加上简短的提示文本来引导模型完成不同的任务[1]。这些提示文本通常是问题或指令形式,用来告诉模型如何理解输入并生成输出。Prompt Learning的优点在于它可以用少量的数据完成多个任务[2]。
Multi-Prompt Learning:Multi-Prompt Learning是Prompt Learning的一种扩展形式,它可以将多个Prompt应用于一个问题,达到数据增强或问题分解等效果[1]。常见的Multi-Prompt Learning方法包括并行方法、增强方法和组合方法[2]。并行方法将多个Prompt并行进行,并通过加权或投票的方式将多个单Prompt的结果汇总;增强方法会将一个与当前问题相似的案例与当前输入一起输入,以便模型能够更准确地进行预测;组合方法则将多个Prompt组合在一起使用,以便训练模型进行更复杂的任务[2]。
如何选择合适的预训练模型:选择合适的预训练模型是Prompt Learning的关键步骤之一。在选择模型时,需要考虑以下因素:任务类型、数据集、模型大小和训练时间等[1]。通常情况下,预训练模型的大小越大,它在各种任务上的表现也越好,但同时需要消耗更多的计算资源[1]。
如何调整Prompt的训练策略:Prompt Learning的另一个关键步骤是如何调整Prompt的训练策略。可以采用全数据下单纯提高模型效果的方法,也可以采用few-shot/zero-shot下使用Prompt作为辅助的方法,或者固定预训练模型并仅训练Prompt[[1]。
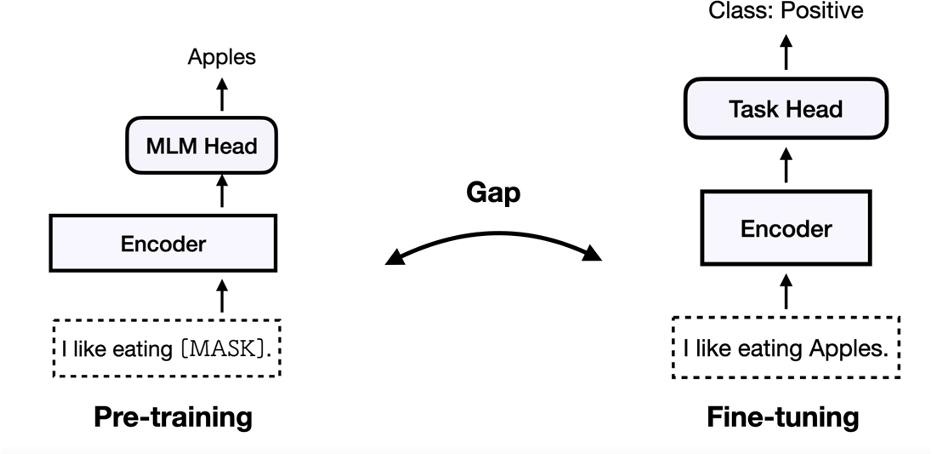
如上图所示,finetune的做法pre-traning使用PLMs作为基础编码器,finetune下游任务时候添加额外的神经层以进行特定任务,调整所有参数。预训练和微调任务之间存在差距。

如上图所示prompt,在pre-traing和finetuning下游任务时候使用同样的MLM任务。弥合模型调整和预训练之间的差距来增强 few-shot 学习能力。使用PLMs作为基础编码器,添加额外的上下文(模板)和[MASK]位置,将标签投影到标签词(verbalizer),缩小预训练和微调之间的差距。
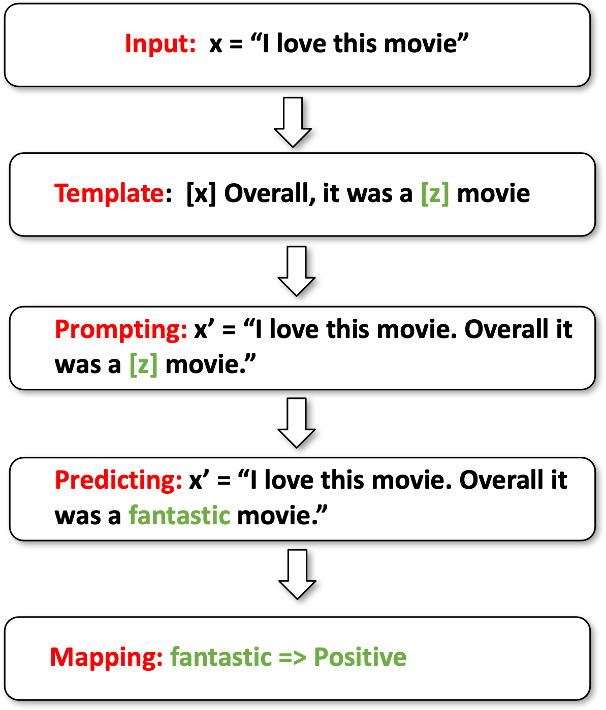
上面是用户评论问题转prompt的一个流程示意图,包括模版选择、模版包裹、MLM输出词选择、词映射到评论正负性这个几个流程。
模版选择
人工模版设计包括,就是专家根据对问题的了解,设计一套模版把专用问题的解决方法转成适合自然语言生成方式的表述方法。下面就是人针对QA问题做的结构化模版,把QA问题转成生成模型生成输出的问题。

自动搜索生成prompt模版,选择一个元模版,然基于现有单词的梯度搜索生成最优prompt模版。
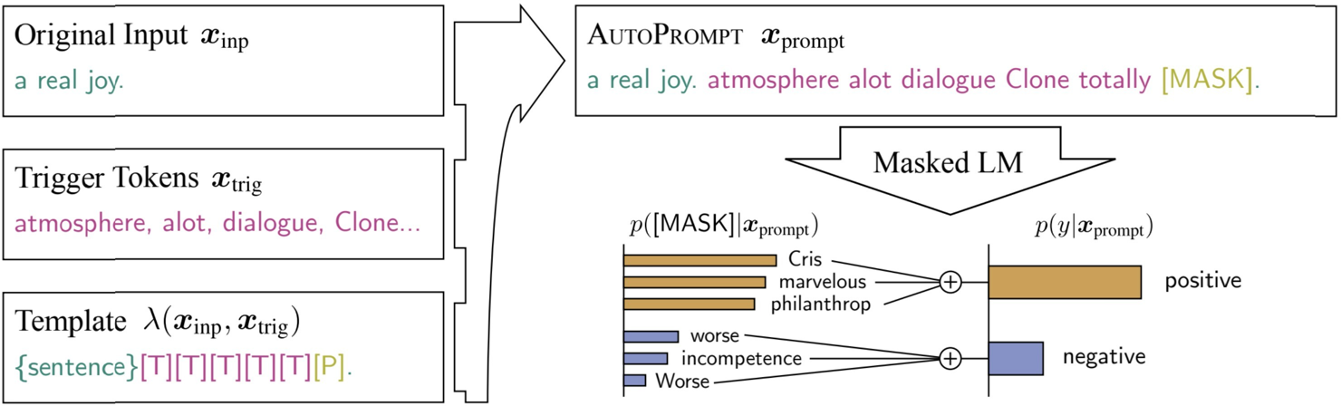
利用T5对输入的多个句子,做模版自动化生成。操作如下图,大致步骤:1.利用已有模版训练一个T5模型,让模型学会如何通过语料(把所有任务输入拉平作为向量输入,输出就是最后模版)2.把任务输入作为输入,用训好的模型做模版生成
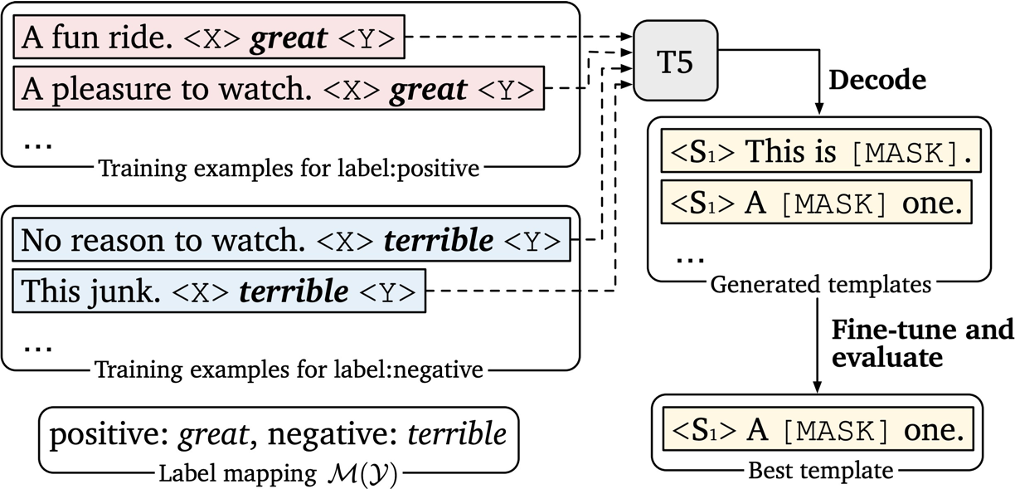
让pre-model自动化的生成模版,思路如下,fix主pre-train模型,让模型对有标注的任务做训练,模型学习后改的输入的句子embbeding,当然输入原句是不改的,只是让模型改非输入句子部分,最后就可以自动化的学习到最有prompt模版了。当然这模版有可能人是看不懂的。
P-tuning v1:将提示用于输入层(使用重新参数化)
P-tuning v2:将提示用于每个层(如前缀调整)

填入词选择
在做prompt任务设计适合,把任务都转成生成模式了,所以会存在怎么把生成的东西映射到想要结果这样一个转化过程,这中间词表的设计和选择对最后结果影响很大,所以我们需要对输出深词作设计。
Positive: great, wonderful, good.. Negative: terrible, bad, horrible…
手动生成

人脑爆生成一波关键词或者句子短语,然后利用已经有的知识库去召回更多相关的词、概念或者短语句子,然后再对召回的这些词、句子短语作排序精选。
自动化生成

和自动化模版生成很像,模型固定,用打标注的数据来训练,梯度反传时候改的是输入embedding的词。
delta learn
整体思路,通过增加一些控制参数,来让表现力强大的大模型可以可控的学习和使用。用个例子作比喻:控制论里面,用简单线性控制矩阵,来控制庞大且复杂系统;这个比喻不一定完全准确,因为deta learn其实还是可以合并到原模型,那其实就是对所学知识链路的重整理了。
实际操作就是使用增量调整来模拟具有数十亿参数的模型,并优化一小部分参数。
这张图表示的意思是,我还是我,但是我经过简单变化和学习后,我就可以成为多样不一样的我,但是pre-train模型是不动的,动的只是参入的参数,眼睛、一幅、装饰。很形象的表示训练过程,但是感觉对于表意不够。但这图传的很广,这边也就顺带放上来了。

Addtion:方法引入了额外的可训练神经模块或参数,这些模块或参数在原始模型中不存在;
Specification:方法指定原始模型或过程中的某些参数变为可训练,而其他参数被冻结;
Reparameterization:方法通过变换将现有参数重新参数化为参数高效形式。

detaleran很重要的3个因素:
1.插哪:和原有网络序列性插入,还是桥接式插入
2.怎么插:只插入某些层,还是整个网络每层都插入
3.多大矩阵控制:参入控制层参数多大,一bit、还是原参数0.5%

不同的插入方式、不同参数对于模型效果差异还是比较大的,这个大家可以在实际作模型微调时候去体会,上面表是对不同的方法做的数学抽象表示。大家在实操时候发现没有思路时候会过来看这个表,在结合问题想想会有不一样帮助。
实操部分
这部分是以chatglm 6B模型来做实验,具体的代码在这个链接:GitHub - liangwq/Chatglm_lora_multi-gpu: chatglm多gpu用deepspeed和
模型不一定非的要chatglm、llama或者其他什么模型都是可以的。用到了huggingface的peft来做delta学习,deepspeed做多卡分布式训练。
测试过:2卡A100 80G,8卡 A100 80G硬件配置数据和速度如下
50万 selefinstruct的数据,2卡、32核cpu、128G mem
batch 2 ,gd 4 也就是每个batch size=16;2个epoch lora_rank=8,插入参数量在7M左右,要训练20个小时
8卡差不多在5小时左右
微调,模型收敛很稳定效果不错
代码讲解:
数据处理逻辑
def data_collator(features: list) -> dict:
len_ids = [len(feature["input_ids"]) for feature in features]
longest = max(len_ids) + 1
input_ids = []
attention_mask_list = []
position_ids_list = []
labels_list = []
for ids_l, feature in sorted(zip(len_ids, features), key=lambda x: -x[0]):
ids = feature["input_ids"]
seq_len = feature["seq_len"]
labels = (
[-100] * (seq_len - 1)
+ ids[(seq_len - 1) :]
+ [tokenizer.eos_token_id]
+ [-100] * (longest - ids_l - 1)
)
ids = ids + [tokenizer.eos_token_id] * (longest - ids_l)
_ids = torch.LongTensor(ids)
attention_mask, position_ids = get_masks_and_position_ids(
ids, seq_len, longest, _ids.device, gmask=False
)
labels_list.append(torch.LongTensor(labels))
input_ids.append(_ids)
attention_mask_list.append(attention_mask)
position_ids_list.append(position_ids)
input_ids = torch.stack(input_ids)
labels = torch.stack(labels_list)
attention_mask = torch.stack(attention_mask_list)
position_ids = torch.stack(position_ids_list)
return {
"input_ids": input_ids,
"labels": labels,
"attention_mask": attention_mask,
"position_ids": position_ids,
}插入lora,允许对在其它数据训练的lora加入训练,意思就是可以部分数据部分数据分开训练lora,需要可以把训练好的lora整合做共同训练,非常方便牛逼。对于机器配置不够的朋友绝对是好事
# setup peft
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=finetune_args.lora_rank,
lora_alpha=32,
lora_dropout=0.1,
)
model = get_peft_model(model, peft_config)
if finetune_args.is_resume and finetune_args.resume_path:
print("=====>load lora pt from =====》:", finetune_args.is_resume, finetune_args.resume_path)
model.load_state_dict(torch.load(finetune_args.resume_path), strict=False)
accelerate整合部分,因为它不会保留checkpoint,所以我hardcode写了每2000步保留一个checkpoint,这部分还没来得急把只保留最新两个checkpount代码写上去,所以会产生很多哥checkpount文件夹,这块如果大家用不到可以注释了,或则自己写下保留两个的代码。当然后面我会update。
if i%2000 ==0 and accelerator.is_main_process:
#accelerator.wait_for_everyone()
path = training_args.output_dir+'/checkpoint_{}'.format(i)
os.makedirs(path)
accelerator.save(lora.lora_state_dict(accelerator.unwrap_model(model)), os.path.join(path, "chatglm-lora.pt"))
#save_tunable_parameters(model, os.path.join(path, "chatglm-lora.pt"))
i +=1