【阅读清单】
This post is all you need(上卷)Transformer
This post is all you need(下卷)BERT
一文读懂Transformer和Attention (原文:The Illustrated Transformer )对QKV详细介绍
【讲解视频】
注意力机制的本质|Self-Attention|Transformer|QKV矩阵_bilibili
【Attention is all you need(上卷)】
1、出发点:
序列模型:循环结构,时间/输出依赖,不能并行
=>Transformer架构(输入输出的隐含表示)
2、自注意力与多头注意力
Self-Attention自注意力:句子在每个位置的权重,再权重和方式计算句子隐含向量表示
Multi-head attention:
①Self-A过分集中于自己位置
②增加模型表达能力(细分QKV更多注意力权重分配方式)
3、Transformer
位置编码与编码解码:
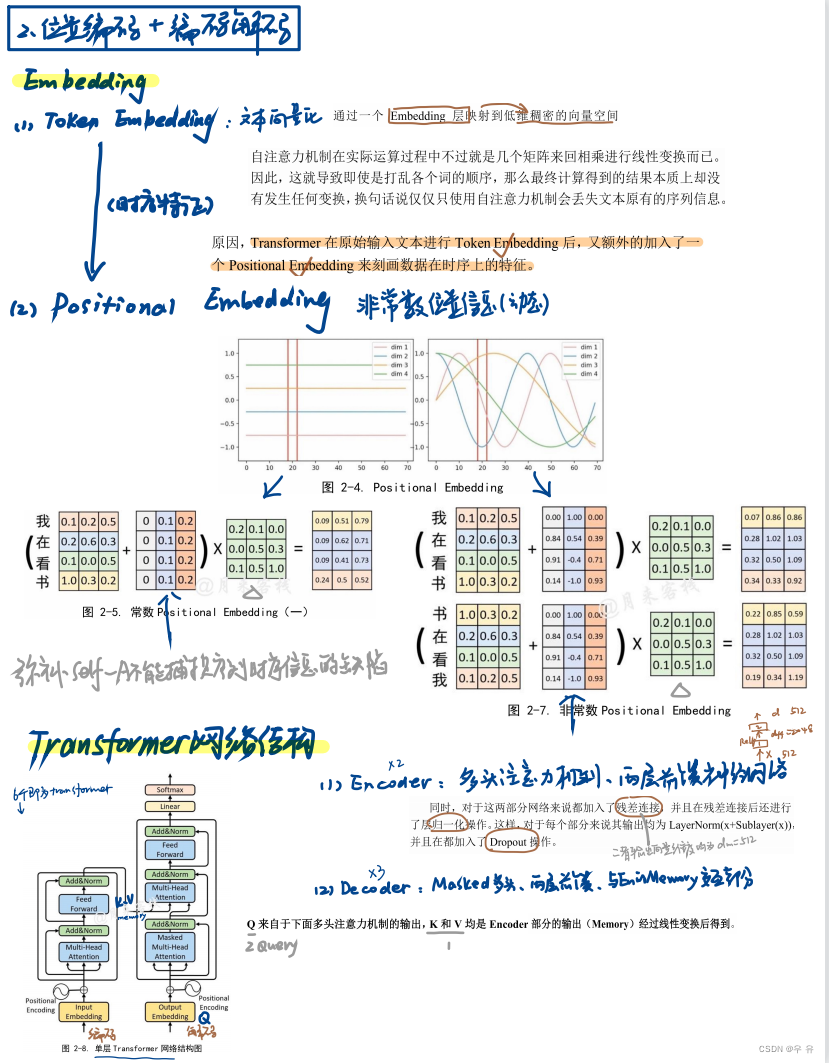
Embedding
(1)token embedding : 文本的向量表示: 文本通过embedding层映射到低纬稠密的向量空间
↓只是几个矩阵来回相乘进行线性变化,丢失文本原有序列信息↓(额外加入PE)
(2)Positional embedding : 位置信息非常数(曲线变化)
网络结构(6个相同单层transformer模块堆叠)
Encoder:x2[KV] 多头注意力、两层前馈NN
这两部分共同:残差连接+归一化、输入加入Dropout
Decoder:x3[Q] masked多头注意力、与En的Memory(KV)交互注意力、两层前馈NN
训练解码过程:En/De一次接收所有时刻的输入(提高训练速度、送gt非pre更准确训练)
attention mask(盖住后面-序列依次送入De)+ Positional Embedding(保持语句本身语序)
关于QKV的总结:


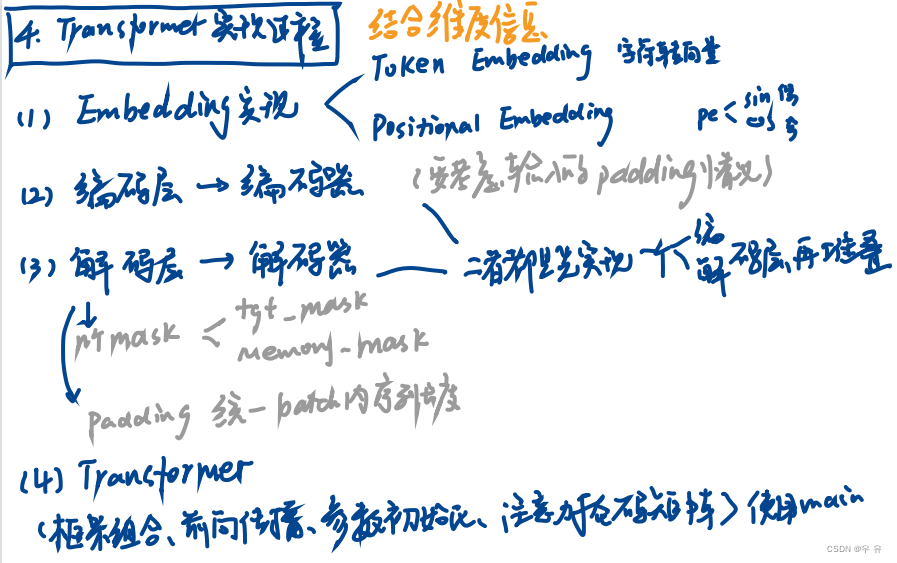
基础模块实现
1、6个En+6个Dn堆叠成Transformer
两处Mask:
①Attention mask:在训练过程中掩盖掉当前时刻之后所有位置上的信息(只保证输入的序列性)
②padding mask:同一个batch包含多个文本序列,不同的文本序列长度不一致=>padding到相同长度
2、多头注意力机制实现(避免单自注意力机制的权重过度集中于当前编码位置)
注意维度的变化、几个重要变量、几次.Linear操作


Transformer网络结构实现
包括:Token Embedding(字符转向量)、Positional Embedding、编码器和解码器等Token是指文本中的最小单位,通常是单词、标点符号、数字等。在自然语言处理中,我们将文本分割成一系列的token,然后再对这些token进行分析和处理。通常将每个token表示为一个向量,这个向量包含了该token的语义信息。这个向量的维度大小可以是任意的,通常会根据任务的需要和计算资源的限制来确定。例如,在一个情感分类任务中,我们可能使用100维的向量来表示每个单词,而在一个机器翻译任务中,我们可能使用512维的向量来表示每个单词。"emb_size"表示每个token在模型中被嵌入为一个向量时,该向量的维度大小。
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1):torch.arange(start, end, step)函数返回一个张量,包含从start到end(不包括end)的以step为间隔的一系列数值。在这里,我们使用torch.arange()函数生成一个从0到max_len-1的一维张量,表示输入序列中每个位置的位置编码。我们使用dtype=torch.float来指定张量的数据类型为浮点型,以便后续计算。然后,我们使用unsqueeze(1)方法将这个一维张量扩展为二维张量,其中第一维表示序列的位置,第二维为1,以便后续计算位置编码矩阵(这里是在1维度上增加一个维度,如果里面参数是0就是在0维度上增加一个维度)。
pe[:,0::2] =torch.sin(position * div_term) # [max_len, d_model/2]
pe[:, 1::2] = torch.cos(position * div_term)
使用torch.sin()和torch.cos()函数分别计算了位置编码矩阵中的sin项和cos项,并将它们分别赋值给了pe的偶数列和奇数列,即pe[:, 0::2]和pe[:, 1::2]。这是由于在位置编码矩阵中,相邻位置的编码值在偶数位上使用了sin函数进行编码,在奇数位上使用了cos函数进行编码,这是因为sin和cos函数具有不同的周期性质,能够更好地表达不同位置之间的关系。这样的编码方式可以使得不同位置之间的编码在向量空间上具有一定的区分度,从而提高模型的表达能力。具体来说,sin和cos函数的周期分别为2π和π,这意味着在不同的位置上,它们的取值变化更加多样化,有助于模型更好地学习不同位置之间的相对位置关系。
编码

右图EncoderLayer 就是左图对应的 Encoder 再结合一下最开始说的单层transformer网络结构
解码
注意一下几个mask(tgt_mask、memory_mask)、padding保证batch内序列长度一致
编码解码都是先实现单层再堆叠
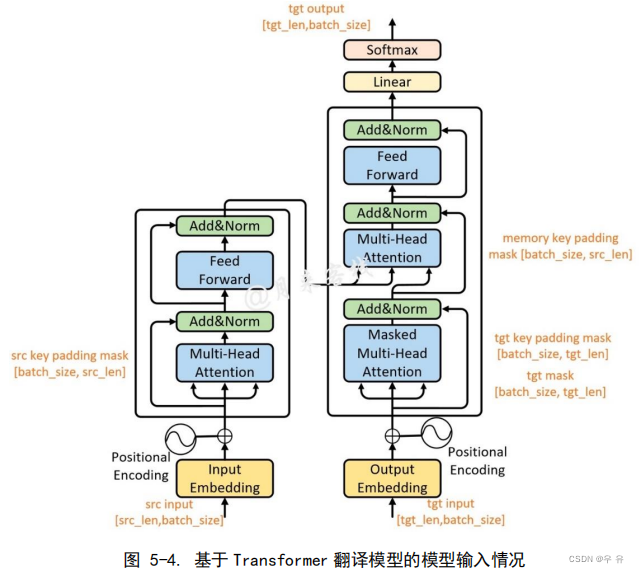
Transformer


基于Transformer 的翻译模型(主要是预处理和加载):搭建翻译模型将德语翻译为英语1、数据集构建
(1)tokenize文本分割:大部分就是直接按空格切分即可,缩写也需要给分割出来可借助 torchtext中的get_tokenizer方法实现。得到的是2个序列化的德语、英语tokenizer
(2)建立词表:通过torchtext.vocab中的Vocab方法来构建词典,得到2个Vocab 类的实例化对象
特殊字符列表specials
<unk>表示未知词,通常在处理文本数据时,会将出现频率较低、无法识别或不在词汇表中的单词替换为<unk>,避免出现未知词导致的模型误差。
<pad>表示填充字符,通常在将序列数据处理成等长的张量时,需要用<pad>进行填充,使得所有序列长度都相同,使得序列长度一致,方便进行批处理。
<bos>表示序列起始符,通常在处理文本数据时,会在每个句子的开头添加<bos>符号。
<eos>表示序列结束符,通常在处理文本数据时,会在每个句子的结尾添加<eos>符号,使用<bos>和<eos>可以使得模型更好地理解文本序列的开始和结束。遍历文件中的每一个样本(每行一个)并进行 tokenize 和计数counter.update(tokenizer(string_)) :若string_为"hello world hello",则tokenizer(string_)会返回["hello", "world", "hello"],而counter.update(tokenizer(string_))会将"hello"计数为2, "world"计数为1,最终得到一个counter对象,其中counter["hello"]为2,counter["world"]为1
(3)转换为 Token 序列:将训练集、验证集和测试集转换成Token序列(根据字典转换成索引的形式)
一行构成一个样本,左原始token右目标token;tensor
(4)padding 处理:模型在训练过程中只需要 保证同一个batch中所有的原始序列等长,所有的目标序列等长即可,也就是说不需要在整个数据集中所有样本都保证等长。以每个 batch 中 最长的样本为标准对其它样本进行 padding(5)构造 mask 向量:生成形状为 [sz,sz]的注意力掩码矩阵(attention mask在解码过程中掩盖当前 position 之后的 position)(6)构造 DataLoade 与使用:将训练集、验证集和测试集转换为Token序列,再分别构造3个DataLoader,其中generate_batch 将作为一个参数传入来对每个batch的样本进行处理。
2、翻译模型(1)网络结构:被单独拎出来的Embedding部分:因为不同的文本生成模型,Embedding 部分会不一样 (如在诗歌生成这一情景中编码器和解码器共用一个TokenEmbedding 即可,而在翻译模型中就需要两个),所以将两者进行了拆分。同时,待模型训练完成后,在inference过程Encoder只需要执行一次,所以在此过程中也需要单独使用Transformer中的Encoder和Decoder【这里是position_embedding和token_embedding(src/tgt)】注意常用参数的定义和使用(2)模型训练:(在config中写好了配置参数)数据集载入、模型定义/实例化并初始化权重、loss/动态lr/优化器、开始训练(3)模型预测:
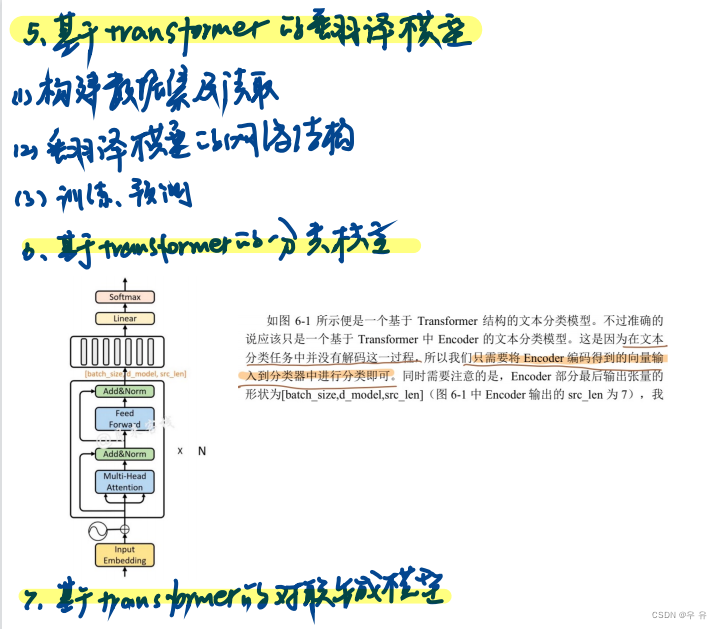
基于Transformer 的分类模型(AG_News文本分类模型)准确的说应该只是一个基于 Transformer 中 Encoder 的文本分类模型。这是因为在文本分类任务中并没有解码这一过程,所以我们只需要将 Encoder 编码得到的向量输入到分类器中进行分类即可。
其实BERT模型的网络结构本质上就等同于图 6-1 所示 1、数据预处理
AG_News 数据集:所有样本均使用逗号作为分隔符;数据集构建:定义tokenize、定义字符串清晰( 原始语料中有很多奇奇怪怪的字符)、 建立词表(Vocab 方法)、转换为 Token序列( 将每一句话中的每一个词根据字典转换成索引的形式,同时返回所有样本中最长样本的长度 )、padding、构造 DataLoade 与使用示例、2、文本分类模型
最后需要将Encoder 的输出喂入到一个 softmax 分类器即可完成分类任务
模型训练:数据集载入、模型定义/实例化并初始化权重、loss/动态lr/优化器、开始训练
补充:
softmax
dropout
分类任务只需要将网络最后的输出做argma操作



多图详解attention和mask: 从循环神经网络、transformer到GPT2_attention mask_神洛华的CSDN
快速回顾-笔记





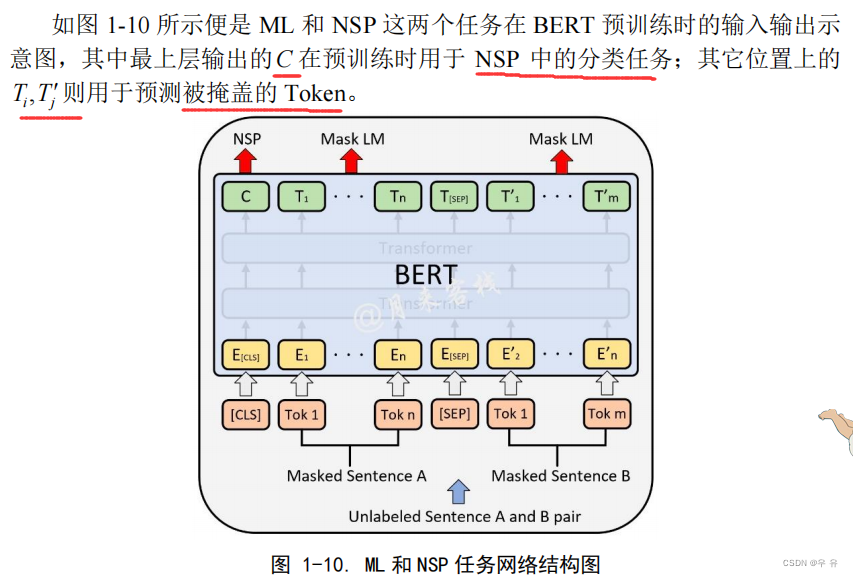
【阅读笔记-This post is all you need(下卷)- - 步步走进BERT】
BERT(Bidirectional Encoder Representations from Transformers)双向编码学习能力模型:为了使得模 型能够有效的学习到双向编码的能力,BERT 在训练过程中使用了基于掩盖的语言模型(Masked Language Model, MLM),即随机对输入序列中的某些位置进行遮蔽,然后通过模型来对其进行预测。MLM预测任务能够使得模型编码得到的结果同时包含上下文的语境信息,因此有利于训练得到更深的 BERT 网络模型。除此之外,在训练BERT的过程中作者还加入了下句预测任务(Next Sentence Prediction, NSP), 即同时输入两句话到模型中,然后预测第2句话是不是第1句话的下一句。
“BERT 整体上就是由多层的 Transformer Encoder 堆叠而来;同时在Embedding部分多加了一个Segment Embedding”,所谓的“bidirectional”其实指的也就是Transformer 中的self-attention 机制。同时真正让 BERT 表现出色的应该是基于 MLM 和 NSP 这两种任务的预训练过程,使得训练得到的模型具有强大的表征能力。


Input Embedding×3:
主要包含三个部分:Token Embedding 、Positional Embedding 和 Segment Embedding
需要注意的是 BERT 中的 Positional Embedding 对于每个位置的编码并不是采用公式计算得到,而是类似普通的词嵌入一样为每一个位置初始化了一个向量,然后随着网络一起训练得到。(训练时PE最大程度512)Segment Embedding:由于 BERT 的主要目的是构建一个通用的预训练模型,因此难免需要兼顾到各种 NLP 任务场景下的输入。因此Segment Embedding 的作用便是用来区分输入序列中的不同部分,其本质就是通过一个普通的词嵌入来区分每一个序列所处的位置。例如在NSP 任务中,对于任意一个句子(一共两个)来说,其中的每一位置都将用同一 个向量来进行表示,以此来区分哪部分字符是第 1 句哪部分字符是第 2 句,即此 时 Segment 词表的长度为 2 。最后,将这三部分 Embedding 后的结果相加(并标准化)得到最终的Input Embedding输出
token:句子划分成单词 [SEP]两句话分开符
segment:第几个句子 层中对应的每个 Token 的位置向量都相同
position:位置 用来标识句子中每个 Token 各自所在的位置,使模型能捕捉到有序文本BertEncoder:
由 L 个 BertLayer 所构成、H表示模型的维度;A表示多头注意力中多头的个数



Masked Language Model,MLM基于掩盖的语言模型随机掩盖掉输入序列中15%的 Token (即用“ [MASK] ”替换掉原有的 Token ),然后在 BERT的输出结果中取对应掩盖位置上的向量进行真实值预测。但是fine-tuning 时输入序列中不存在 [MASK]这样的 Token ,因此导致 pre-training 和 fine-tuning 之间存在不匹配不一致的问题(gap)=>改动:先选定15%的Token,然后将其中的 80% 替换为“[MASK]”、10%随机替换为其它 Token、剩下的10%不变。最后取这15%的Token对应的输出做分类来预测其真实值。
Next Sentence Prediction,NSP二分类的下句预测任务每个样本来说都是由 A 和 B 两句话构成,其中 50% 的情况 B确实为 A 的下一句话(标签为 IsNext ),另外的 50% 的情况是 B 为语料中其它的随机句子(标签为 NotNext ),然后模型来预测 B 是否为 A 的下一句话。