对于现代操作系统,虚拟文件系统是一个几乎无处不见的功能,因此,要探究现代操作系统的运行机制,对其进行讨论是必然的。
本文使用的是Linux 2.6.x.x,这是一个变革性的版本,无论是内存管理,进程管理,文件管理还是设备管理都出现了开天辟地的变化,因此,以这个版本进行探究是很有必要的。
引流:现代操作系统的内存管理原理:以Linux2.6.x.x为例
虚拟文件系统概述
root@huawei linux-version # df [0]
Filesystem 1K-blocks Used Available Use% Mounted on
udev 1967860 0 1967860 0% /dev
tmpfs 402568 1580 400988 1% /run
/dev/vda1 41020640 26749836 12157372 69% /
tmpfs 2012832 0 2012832 0% /dev/shm
tmpfs 5120 4 5116 1% /run/lock
tmpfs 2012832 0 2012832 0% /sys/fs/cgroup
tmpfs 402564 40 402524 1% /run/user/122
tmpfs 402564 0 402564 0% /run/user/0
如上,tmpfs,是一种基于内存的虚拟文件系统,虚拟的意思就是文件系统里的文件不对应硬盘上任何文件。(有一种说法叫做逻辑文件系统)
传统上,文件系统用于在块设备上持久存储系统,但也可以使用文件系统来组织、提供或交换并不存储在块设备上的信息,这些信息可以由内核动态生成。(从这句话来看普通文件系统和proc这些貌似是对等的关系,那么暂且把他们叫做逻辑文件系统吧)
常见的如proc、tmpfs和sysfs
此处要注意逻辑文件系统和文件系统,磁盘文件系统和内存文件系统的区别
特定虚拟文件系统只是一个中间层,有如下几种:
proc:操作系统本身和应用程序之间的通信提供了一个安全的接口devfs:在2.6内核以前使用devfs来提供一种类似于文件的方法来管理位于/dev目录下的所有设备sysfs:sysfs文件系统把连接在系统上的设备和总线组织成为一个分级的文件,用户空间的程序同样可以利用这些信息,以实现和内核的交互,一般来说是替代devfs的。sysfs文件系统是当前系统上实际设备树的一个直观反映,它是通过kobject子系统来建立这个信息的,当一个kobject被创建的时候,对应的文件和目录也就被创建了。tmpfs:Linux特有的文件系统,标准挂载点是/dev/shm,默认大小是实际内存的一半。tmpfs可以使用物理内存,也可以使用swap交换空间。是一种普遍的对文件整理的虚拟文件系统。优点:临时性;快速读写和动态收缩具体的文件系统如:
minix、ext3、ext4等
磁盘文件系统:文件系统在磁盘中,速度较慢
内存文件系统:文件系统在内存中,速度更快
文件系统类型:基于磁盘的文件系统Disk-based Filesystem、虚拟文件系统Virtual Filesystem在内核中生成,是一种使用户应用程序与用户通信的方法和网络文件系统Network Filesystem是基于磁盘的文件系统和虚拟文件系统之间的折中。
VFS不仅为文件系统提供了方法和抽象,还支持文件系统中对象(或文件)的统一视图。
inode的成员有以下几类:
- 描述文件状态的元数据。例如,访问权限或上次修改的日期。
- 保存实际文件内容的数据段
- 该目录项的数据所在inode的编号
- 文件或目录的名称
下面是查找/usr/bin/emacs的过程
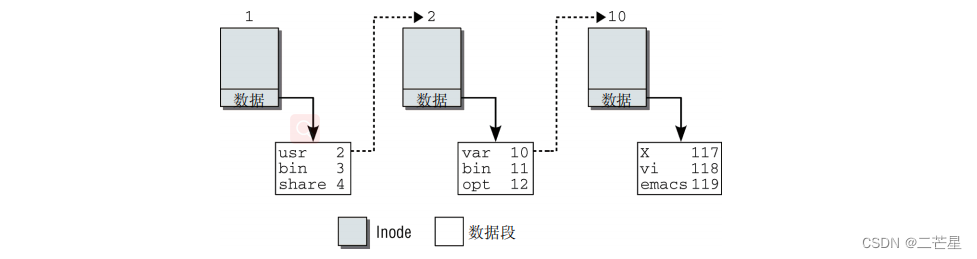
万物皆文件
大多数内核导出、用户程序使用的函数都可以通过VFS定义的文件接口访问。以下是使用文件作为其主要通信手段的一部分内核子系统:字符和块设备;进程之间的管道;用于所有网络协议的套接字;用于交互式输入和输出的终端;
VFS由两部分组成:文件和文件系统
struct inode {
struct hlist_node i_hash;
struct list_head i_list; // 链接iNode
struct list_head i_sb_list;
struct list_head i_dentry;
unsigned long i_ino; // inode唯一编号
atomic_t i_count; // 引用技术
unsigned int i_nlink; // 硬链接总数
uid_t i_uid; // 用户ID
gid_t i_gid; // 组ID
dev_t i_rdev; // 表示设备特殊文件的专用指针
unsigned long i_version; //
loff_t i_size; // 文件大小
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
struct timespec i_atime; // 最后访问的时间
struct timespec i_mtime; // 最后修改的时间
struct timespec i_ctime; // 最后修改iNode的时间
unsigned int i_blkbits;
blkcnt_t i_blocks; // 文件按块计算的长度
unsigned short i_bytes; // 文件按字节计算的长度
umode_t i_mode; // 文件类型
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
struct mutex i_mutex; // 互斥量
struct rw_semaphore i_alloc_sem;
const struct inode_operations *i_op; // inode操作数据结构
const struct file_operations *i_fop; /* inode默认操作结构 */
struct super_block *i_sb;
struct file_lock *i_flock;
struct address_space *i_mapping;
struct address_space i_data;
#ifdef CONFIG_QUOTA
struct dquot *i_dquot[MAXQUOTAS];
#endif
struct list_head i_devices; // 利用该成员作为链表元素,使得块设备或字符设备可以维护一个inode的链表,每个inode表示一个设备文件,通过设备文件可以访问对应的设备
union {
struct pipe_inode_info *i_pipe; // 于实现管道的inode的相关信息
struct block_device *i_bdev; // 块设备
struct cdev *i_cdev; // 字符设备
};
int i_cindex;
__u32 i_generation;
#ifdef CONFIG_DNOTIFY
unsigned long i_dnotify_mask; /* Directory notify events */
struct dnotify_struct *i_dnotify; /* for directory notifications */
#endif
#ifdef CONFIG_INOTIFY
struct list_head inotify_watches; /* watches on this inode */
struct mutex inotify_mutex; /* protects the watches list */
#endif
unsigned long i_state;
unsigned long dirtied_when; /* jiffies of first dirtying */
unsigned int i_flags;
atomic_t i_writecount;
#ifdef CONFIG_SECURITY
void *i_security;
#endif
void *i_private; /* fs or device private pointer */
};
对于iNode的操作,使用i_op成员进行指定
struct inode_operations {
int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,int);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,int,dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
int (*readlink) (struct dentry *, char __user *,int);
void * (*follow_link) (struct dentry *, struct nameidata *);
void (*put_link) (struct dentry *, struct nameidata *, void *);
void (*truncate) (struct inode *);
int (*permission) (struct inode *, int, struct nameidata *);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *);
int (*setxattr) (struct dentry *, const char *,const void *,size_t,int);
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*removexattr) (struct dentry *, const char *);
void (*truncate_range)(struct inode *, loff_t, loff_t);
long (*fallocate)(struct inode *inode, int mode, loff_t offset, loff_t len);
};
而对于如proc这种的文件系统,其管理对象是进程task_struct
struct task_struct {
// ...
int link_count, total_link_count; // 文件系统信息 查找环形链表时防止无限循环
// ...
struct fs_struct *fs; // 文件系统信息
struct files_struct *files; // 打开文件系统
struct nsproxy *nsproxy; // 命名空间
// ...
};
files包含当前进程的各个文件描述符
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
struct fdtable *fdt;
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
int next_fd; // 表示下一次打开新文件时使用的文件描述符
struct embedded_fd_set close_on_exec_init; // 位图
struct embedded_fd_set open_fds_init; // 位图
struct file * fd_array[NR_OPEN_DEFAULT];
};
struct embedded_fd_set {
unsigned long fds_bits[1];
};
默认情况下,内核允许每个进程打开 NR_OPEN_DEFAULT个文件。允许打开文件的初始数目是32。64位系统可以同时处理64个文件
#define BITS_PER_LONG 32
#define NR_OPEN_DEFAULT BITS_PER_LONG
而对于
struct fdtable {
unsigned int max_fds;
struct file ** fd; // 每个数组项指向一个file结构的实例,管理一个打开文件的所有信息
fd_set *close_on_exec; // 一个指向位域的指针,该位域保存了所有在exec系统调用时将要关闭的文件描述符的信息
fd_set *open_fds; //一个指向位域的指针,该位域管理着当前所有打开文件的描述符。
struct rcu_head rcu;
struct fdtable *next;
};
其他暂不做概述
proc
proc是一种逻辑文件系统,其信息不能从块设备读取,只有在读取文件内容时,才动态生成相应的信息。
使用proc文件系统,可以获得有关内核各子系统的信息(例如,内存利用率、附接的外设,等等),也可以在不重新编译内核源代码的情况下修改内核的行为,或重启系统。
与之相关联的是系统控制机制sysctl system control mechanism。通常,进程数据文件系统procfs装在在/proc,它的缩写是proc FS,即因此得名。
尽管proc文件系统的容量依系统而不同,其中仍然包含了许多深层嵌套的目录、文件、链接。但这些信息可以分为以下几大类:内存管理、系统进程的特征数据、文件系统、设备驱动程序、系统总线、电源管理、终端和系统控制参数。
对于某些进程的信息,可以在`/proc`下查看
root@huawei 2194 # cat cmdline
/usr/libexec/at-spi-bus-launcher#
root@huawei 2194 # pwd
/proc/2194
一般性系统信息
root@huawei /proc # cat stat [0]
cpu 12211193 7303 2174437 538380117 370471 0 21859 0 0 0
cpu0 6128342 3721 1085295 269120499 127141 0 7760 0 0 0
cpu1 6082850 3582 1089142 269259618 243329 0 14099 0 0 0
intr 1278733850 0 9 0 0 2566 0 3 0 0 0 277238 28 15 0 0 0 0 0 0 0 0 0 0 0 0 27 0 4839272 5689436 0 4780 5813 0 18799006 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ctxt 2490275942
btime 1663128233
processes 8110805
procs_running 1
procs_blocked 0
softirq 903628053 0 295168408 202239 20129044 18142070 0 22983 280585352 13555 289364402
数据结构
proc中的每个数据项都由proc_dir_entry来表示
struct proc_dir_entry {
unsigned int low_ino; // inode编号
unsigned short namelen; // 文件名的长度
const char *name; // 指向存储文件名的字符串的指针
mode_t mode; // 文件类型
nlink_t nlink; // 目录中子目录和符号链接的数目
uid_t uid; // 用户ID
gid_t gid; // 组ID
loff_t size; // 大小
const struct inode_operations *proc_iops; // 对iNode的操作
const struct file_operations *proc_fops; // 对文件的操作
get_info_t *get_info; // 相关子系统中返回所需数据的例程
struct module *owner; // 模块拥有者
struct proc_dir_entry *next, *parent, *subdir; // parent指向父目录的指针 subdir和next支持文件和目录的层次化布置
void *data; // 保存的数据
read_proc_t *read_proc; // 支持从/向内核读取/写入数据
write_proc_t *write_proc;
atomic_t count; /* 计数器 */
int pde_users; /* number of callers into module in progress */
spinlock_t pde_unload_lock; /* proc_fops checks and pde_users bumps */
struct completion *pde_unload_completion;
shadow_proc_t *shadow_proc;
};
内核提供了一个数据结构proc_inode,支持以面向inode的方式来查看proc文件系统的数据项。
union proc_op {
int (*proc_get_link)(struct inode *, struct dentry **, struct vfsmount **);
int (*proc_read)(struct task_struct *task, char *page);
};
struct proc_inode {
// 该结构用来将特定于proc的数据与VFS层的inode数据关联起来
struct pid *pid;
int fd;
union proc_op op;
struct proc_dir_entry *pde; // 指针 指向关联的proc_dir_entry实例
struct inode vfs_inode; // 实际数据
};
换言之,在关联到proc文件系统的每个inode结构实例之前,内存中都有一些额外的数据属于对应的proc_inode实例,根据inode信息,可使用container_of机制获得proc_inode
static inline struct proc_inode *PROC_I(const struct inode *inode)
{
return container_of(inode, struct proc_inode, vfs_inode);
}
初始化和装载
装载proc文件系统
/proc的装载几乎与非虚拟文件系统是等同的。唯一的区别在于,将一个适宜的关键字(通常是proc或none)指定为数据源,而不使用设备文件
进程相关信息
输出与系统进程相关的信息,是proc文件系统最初设计的主要任务之一
系统控制信息
可以在运行时通过系统控制修改内核行为。控制参数从用户空间传输到内核,无须重启机器。操纵内核行为的传统方法是sysctl系统调用
联合文件系统UnionFS
Linux 3.18加入的内核特性,用于支持内核容器技术。
UnionFS 有很多种,Docker 目前支持的联合文件系统包括 OverlayFS, AUFS, Btrfs, VFS, ZFS 和 Device Mapper。
Union Mount技术
一般情况下,若通过某个文件系统挂载内容到挂载点,挂载点目录中原先的内容会被隐藏,而Union Mount不会将原来的内容隐藏,而是将挂载点的内容与被挂载的内容进行合并,并为合并后的内容提供一个统一的文件系统视角merge。
COW写时复制技术
COW指的是其从不覆盖已有文件系统中的内容,通过COW文件系统将两个文件系统合并,最终用户视角为合并后含有所有内容的文件系统(在Linux内核视角可以区分,即用户对lower的文件系统内容拥有可读权限,对upper的文件系统内容具有读写权限)
实验内容摘选自:深入学习docker – 联合文件系 OverlayFS
# 创建四个文件夹
mkdir upper lower merged work
# 存放内容
echo "I'm from lower!" > lower/in_lower.txt
echo "I'm from upper!" > upper/in_upper.txt
echo "In both. I'm from lower!" > lower/in_both.txt
echo "In both. I'm from upper!" > upper/in_both.txt
# 建立UnionFS
sudo mount -t overlay overlay \
-o lowerdir=./lower, upperdir=./upper,workdir=./work \
./merged
sysfs
sysfs是一个向用户空间导出内核对象的文件系统,它不仅提供了察看内核内部数据结构的能力,由于系统的所有设备和总线都是通过kobject组织的,所以sysfs提供了系统的硬件拓扑的一种表示。
struct kobject数据结构
kobject包含在一个层次化的组织中。最重要的一点是,它们可以有一个父对象,可以包含到一个kset中。这决定了kobject出现在sysfs层次结构中的位置:如果存在父对象,那么需要在父对象对应的目录中新建一项。否则,将其放置到kobject所在的kset所属的kobject对应的目录中- 每个
kobject在sysfs中都表示为一个目录。出现在该目录中的文件是对象的属性。用于导出和设置属性的操作由对象所属的子系统提供 - 总线、设备、驱动程序和类是使用
kobject机制的主要内核对象,因而也占据了sysfs中几乎所有的数据项
每个sysfs_dirent 都表示一个sysfs节点
struct sysfs_dirent {
atomic_t s_count; // 引用计数
atomic_t s_active; // 活动
struct sysfs_dirent *s_parent; // 父节点
struct sysfs_dirent *s_sibling; // 子节点
const char *s_name; // 文件、目录或符号链接的名称
union {
struct sysfs_elem_dir s_dir;
struct sysfs_elem_symlink s_symlink;
struct sysfs_elem_attr s_attr;
struct sysfs_elem_bin_attr s_bin_attr;
};
unsigned int s_flags; // 设置sysfs数据项的类型
ino_t s_ino;
umode_t s_mode;
struct iattr *s_iattr;
};
内核对象
内核中很多地方都需要跟踪记录C语言中结构的实例。尽管这些对象的用法大不相同,但各个不同子系统的某些操作非常类似,例如引用计数。这导致了代码复制。由于这是个糟糕的问题,因此在内核版本2.5的开发期间,内核采用了一般性的方法来管理内核对象
一般性的内核对象机制可用于执行下列对象操作:
- 引用计数;
- 管理对象链表(集合);
- 集合加锁;
- 将对象属性导出到用户空间(通过
sysfs文件系统)。
struct kobject {
const char * k_name; // 对象的文本名称
struct kref kref; // struct kref 简化引用计数的管理
struct list_head entry; // 链表元素
struct kobject * parent; // 指向父对象的指针
struct kset * kset; // kset
struct kobj_type * ktype; // 其他信息
struct sysfs_dirent * sd;
wait_queue_head_t poll;
};
引用计数
struct kref {
atomic_t refcount;
};
void kref_init(struct kref *kref);
void kref_get(struct kref *kref);
int kref_put(struct kref *kref, void (*release) (struct kref *kref));
对象集合:在很多情况下,必须将不同的内核对象归类到集合中,例如,所有字符设备集合,或所有基于PCI的设备集合
struct kset {
struct kobj_type *ktype; // kset中各个内核对象公用的kobj_type结构
struct list_head list; // 所有属于当前集合的内核对象的链表
spinlock_t list_lock;
struct kobject kobj;
struct kset_uevent_ops *uevent_ops; // 若干函数指针,用于将集合的状态信息传递给用户层
};
extern void kset_init(struct kset * k);
extern int __must_check kset_add(struct kset * k);
extern int __must_check kset_register(struct kset * k);
extern void kset_unregister(struct kset * k);
udev和devfs的区别
在2.6内核以前一直使用的是devfs,evfs挂载于/dev目录下,提供了一种类似于文件的方法来管理位于/dev目录下的所有设备,我们知道/dev目录下的每一个文件都对应的是一个设备,至于当前该设备存在与否先且不论,而且这些特殊文件是位于根文件系统上的,在制作文件系统的时候我们就已经建立了这些设备文件,因此通过操作这些特殊文件,可以实现与内核进行交互。
但是devfs也有一些缺点,如
- 不确定的设备映射,有时一个设备映射的设备文件可能不同,例如我的U盘可能对应
sda有可能对应sdb; - 没有足够的主/辅设备号,当设备过多的时候,显然这会成为一个问题;
/dev目录下文件太多而且不能表示当前系统上的实际设备;- 命名不够灵活,不能任意指定
因此,正因为上述的问题,udev横空出世:udev官网源码
在linux2.6内核以后,引入了一个新的文件系统sysfs,它挂载于/sys目录下,跟devfs一样它也是一个虚拟文件系统,也是用来对系统的设备进行管理的
root@huawei /sys # df .
Filesystem 1K-blocks Used Available Use% Mounted on
sysfs 0 0 0 - /sys
它把实际连接到系统上的设备和总线组织成一个分级的文件,用户空间的程序同样可以利用这些信息以实现和内核的交互,该文件系统是当前系统上实际设备树的一个直观反应。
它是通过kobject子系统来建立这个信息的,当一个kobject被创建的时候,对应的文件和目录也就被创建了,位于/sys下的相关目录下,既然每个设备在sysfs中都有唯一对应的目录,那么也就可以被用户空间读写了。
用户空间的工具udev就是利用了sysfs提供的信息来实现所有devfs的功能的。
udev优点:
-
动态管理:当设备添加/删除时,
udev的守护进程侦听到来自内核的uevent,以此添加或者删除/dev下的设备文件,所以,udev只为 已经连接的设备产生设备文件,而不会在/dev/下产生大量虚无的设备文件.在发生热插拔时,设备的变化的相关信息会输出到内核的/sys(sysfs文 件系统),udev利用sysfs的信息来进行相应的设备节点的管理 -
自定义命名规则:通过规则文件,
udev在/dev/下为所有的设备定义了内核设备名称,比如/dev/sda,/dev/hda,/dev /fd(这些都是驱动层定义的设备名)等等。由于udev是在用户空间运行,Linux用户可以自己定义规则文件,产生标识性强的设备文件,比如/dev /boot_disk,/dev/root_disk,/dev/color_printer等等 -
设定设备的权限和所有者/组。同样在规则文件中,可以自己定义设备相关的权限和所有者/组
root@huawei tun # pwd
/sys/dev/char/10:1/subsystem/tun
root@huawei tun # ls
dev power subsystem uevent
root@huawei tun # cat dev
10:200
root@huawei tun # cat uevent
MAJOR=10 # 主设备号
MINOR=200 # 副设备号
DEVNAME=net/tun # 对应设备
Cgroup
最后,我还想在此提一下Cgroup,在查看文件系统列表中可以看到Cgroup是占了内核中文件系统的半壁江山的,谈fs不谈它貌似有点说不过去。
# ...
cgroup 0 0 0 - /sys/fs/cgroup/cpu,cpuacct
cgroup 0 0 0 - /sys/fs/cgroup/devices
cgroup 0 0 0 - /sys/fs/cgroup/blkio
cgroup 0 0 0 - /sys/fs/cgroup/freezer
cgroup 0 0 0 - /sys/fs/cgroup/memory
cgroup 0 0 0 - /sys/fs/cgroup/net_cls,net_prio
cgroup 0 0 0 - /sys/fs/cgroup/rdma
cgroup 0 0 0 - /sys/fs/cgroup/cpuset
cgroup 0 0 0 - /sys/fs/cgroup/perf_event
cgroup 0 0 0 - /sys/fs/cgroup/pids
cgroup 0 0 0 - /sys/fs/cgroup/hugetlb
# ...
查看Cgroup数据结构
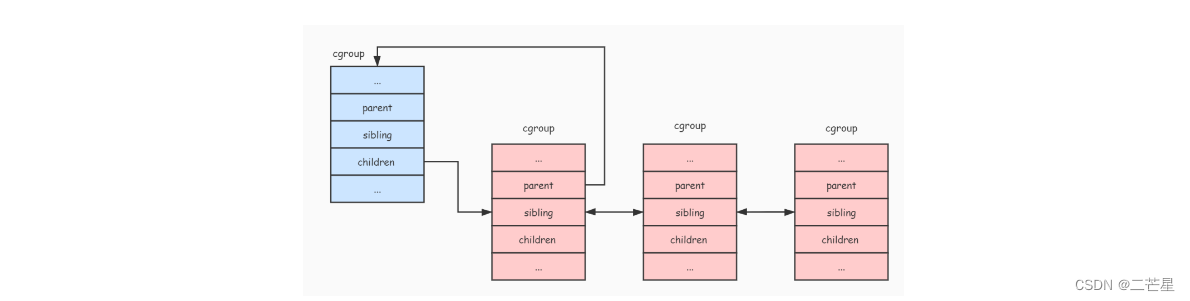
struct cgroup {
unsigned long flags; // 标识当前cgroup的状态
atomic_t count; // 引用计数器,表示有多少个进程在使用这个cgroup
struct list_head sibling; // 所有的兄弟节点
struct list_head children; // 所有子节点
struct cgroup *parent; // 父节点
struct dentry *dentry; // cgroup是层级的一个目录,该字段用于描述该目录
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT]; // 提供给各个子系统存放其限制进程组使用资源的统计数据
struct cgroupfs_root *root; // 保存层级的一些数据
struct cgroup *top_cgroup; // 层级的根节点
struct list_head css_sets;
struct list_head release_list;
};
每个子系统都有自己的资源控制统计信息结构
struct cgroup_subsys_state {
struct cgroup *cgroup; // 指向了这个资源控制统计信息所属的 cgroup
atomic_t refcnt; // 引用计数器
unsigned long flags; // 标志位
};
struct mem_cgroup {
struct cgroup_subsys_state css;
struct res_counter res;
struct mem_cgroup_lru_info info;
int prev_priority;
struct mem_cgroup_stat stat;
};
图例来自:cgroup图示
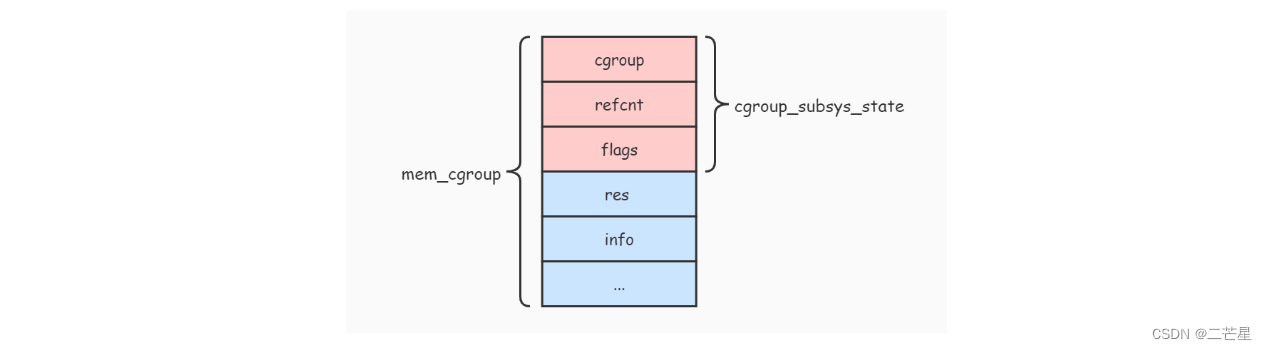
Cgroup系统图例

由于一个进程可以同时添加到不同的 cgroup 中(前提是这些 cgroup 属于不同的 层级)进行资源控制,而这些 cgroup 附加了不同的资源控制 子系统。所以需要使用一个结构把这些 子系统 的资源控制统计信息收集起来,方便进程通过 子系统ID快速查找到对应的 子系统 资源控制统计信息,而css_set结构体就是用来做这件事情
struct css_set {
struct kref ref; // 引用计数器,用于计算有多少个进程在使用
struct list_head list; // 用于连接所有 css_set
struct list_head tasks; // 由于可能存在多个进程同时受到相同的 cgroup 控制,所以用此字段把所有使用此 css_set 的进程连接起来
struct list_head cg_links;
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT]; //用于收集各种子系统的统计信息结构
};
CGroup 通过 cgroup_subsys 结构操作各个子系统,每个 子系统 都要实现一个这样的结构,
struct cgroup_subsys {
struct cgroup_subsys_state *(*create)(struct cgroup_subsys *ss,
struct cgroup *cgrp);
void (*pre_destroy)(struct cgroup_subsys *ss, struct cgroup *cgrp);
void (*destroy)(struct cgroup_subsys *ss, struct cgroup *cgrp);
int (*can_attach)(struct cgroup_subsys *ss,
struct cgroup *cgrp, struct task_struct *tsk);
void (*attach)(struct cgroup_subsys *ss, struct cgroup *cgrp,
struct cgroup *old_cgrp, struct task_struct *tsk);
void (*fork)(struct cgroup_subsys *ss, struct task_struct *task);
void (*exit)(struct cgroup_subsys *ss, struct task_struct *task);
int (*populate)(struct cgroup_subsys *ss,
struct cgroup *cgrp);
void (*post_clone)(struct cgroup_subsys *ss, struct cgroup *cgrp);
void (*bind)(struct cgroup_subsys *ss, struct cgroup *root);
int subsys_id; // 表示了子系统的ID
int active; // 子系统是否被激活
int disabled; // 子系统是否被禁止
int early_init;
const char *name; // 子系统名称
struct cgroupfs_root *root; // 被附加到的层级挂载点
struct list_head sibling; // 用于连接被附加到同一个层级的所有子系统
void *private; // 私有数据
};
内存子系统定义了一个名为 mem_cgroup_subsys的 cgroup_subsys 结构
struct cgroup_subsys mem_cgroup_subsys = {
.name = "memory",
.subsys_id = mem_cgroup_subsys_id,
.create = mem_cgroup_create,
.pre_destroy = mem_cgroup_pre_destroy,
.destroy = mem_cgroup_destroy,
.populate = mem_cgroup_populate,
.attach = mem_cgroup_move_task,
.early_init = 0,
};
另外Linux内核还定义了一个 cgroup_subsys 结构的数组 subsys,用于保存所有 子系统 的 cgroup_subsys结构
static struct cgroup_subsys *subsys[]
#ifdef CONFIG_CPUSETS
SUBSYS(cpuset)
#endif
#ifdef CONFIG_CGROUP_DEBUG
SUBSYS(debug)
#endif
#ifdef CONFIG_CGROUP_NS
SUBSYS(ns)
#endif
#ifdef CONFIG_FAIR_CGROUP_SCHED
SUBSYS(cpu_cgroup)
#endif
#ifdef CONFIG_CGROUP_CPUACCT
SUBSYS(cpuacct)
#endif
内存限制
root@huawei memory # ls
cgroup.clone_children memory.failcnt memory.kmem.slabinfo memory.kmem.usage_in_bytes memory.oom_control memory.usage_in_bytes tasks
cgroup.event_control memory.force_empty memory.kmem.tcp.failcnt memory.limit_in_bytes memory.pressure_level memory.use_hierarchy user.slice
cgroup.procs memory.kmem.failcnt memory.kmem.tcp.limit_in_bytes memory.max_usage_in_bytes memory.soft_limit_in_bytes notify_on_release
cgroup.sane_behavior memory.kmem.limit_in_bytes memory.kmem.tcp.max_usage_in_bytes memory.move_charge_at_immigrate memory.stat release_agent
docker memory.kmem.max_usage_in_bytes memory.kmem.tcp.usage_in_bytes memory.numa_stat memory.swappiness system.slice
root@huawei memory # pwd
/sys/fs/cgroup/memory
root@huawei memory # cat memory.limit_in_bytes # 限制使用的内存大小
9223372036854771712 # 9223372036854771712字节
root@huawei memory # head tasks # 限制使用的进程编号
1 2 3 4 6 9 10 112 13
处理器占用限制
root@huawei cpu # ls [0]
cgroup.clone_children cpuacct.stat cpuacct.usage_percpu cpuacct.usage_sys cpu.cfs_quota_us docker system.slice
cgroup.procs cpuacct.usage cpuacct.usage_percpu_sys cpuacct.usage_user cpu.shares notify_on_release tasks
cgroup.sane_behavior cpuacct.usage_all cpuacct.usage_percpu_user cpu.cfs_period_us cpu.stat release_agent user.slice
root@huawei cpu # cat cpuacct.stat
user 12278762
system 2208080
root@huawei cpu # cat cpuacct.usage
154089159888977
root@huawei cpu # cat cpu.stat
nr_periods 0
nr_throttled 0
throttled_time 0
root@huawei cpu # head tasks
1 2 3 4 6 9 10 11 12 13
最后,想在这里记录一个难点
tty0:当前虚拟终端的别名
tty1-ttyn:tty1-6是文本型控制台(虚拟终端),tty7是x-window图形控制台.(图形终端)
ttyS0:串口终端
console:控制台终端(计算机显示器)
pts:伪终端
谁与争锋?我辈当先!