代码如下:
import numpy as np
import matplotlib.pyplot as plt
import os
import wave
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 获取语谱图、
# 读入音频。路径越简单越好,防止出错
path = "E:"
name = 'out.wav'
# 我音频的路径为E:out.wav
filename = os.path.join(path, name)
# 打开语音文件。
f = wave.open(filename, 'rb')
# 得到语音参数
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
# ---------------------------------------------------------------#
# 将字符串格式的数据转成int型
print("reading wav file......")
strData = f.readframes(nframes)
waveData = np.fromstring(strData, dtype=np.short)
# 归一化
waveData = waveData * 1.0 / max(abs(waveData))
# 将音频信号规整乘每行一路通道信号的格式,即该矩阵一行为一个通道的采样点,共nchannels行
waveData = np.reshape(waveData, [nframes, nchannels]).T # .T 表示转置
f.close() # 关闭文件
print("file is closed!")
# ----------------------------------------------------------------#
'''绘制语音频谱图'''
print("plotting signal wave...")
time = np.arange(0, nframes) * (1.0 / framerate) # 计算时间
time = np.reshape(time, [nframes, 1]).T
plt.plot(time[0, :nframes], waveData[0, :nframes], c="g") # c = 颜色可选 r g b
plt.xlabel("时间(s)") # x轴 lable
plt.ylabel("幅度") # y轴 lable
plt.title("时域频谱图") # 标题
plt.show()
# --------------------------------------------------------------#
''' 语谱图绘制
1.求出帧长、帧叠点数。且FFT点数等于每帧点数(即不补零)
2.绘制语谱图
'''
print("plotting spectrogram...")
framelength = 0.025 # 帧长20~30ms
framesize = framelength * framerate # 每帧点数 N = t*fs,通常情况下值为256或512,要与NFFT相等\
# 而NFFT最好取2的整数次方,即framesize最好取的整数次方
# 找到与当前framesize最接近的2的正整数次方
nfftdict = {}
lists = [32, 64, 128, 256, 512, 1024]
for i in lists:
nfftdict[i] = abs(framesize - i)
sortlist = sorted(nfftdict.items(), key=lambda x: x[1]) # 按与当前framesize差值升序排列
framesize = int(sortlist[0][0]) # 取最接近当前framesize的那个2的正整数次方值为新的framesize
NFFT = framesize # NFFT必须与时域的点数framsize相等,即不补零的FFT
overlapSize = 1.0 / 3 * framesize # 重叠部分采样点数overlapSize约为每帧点数的1/3~1/2
overlapSize = int(round(overlapSize)) # 取整
print("帧长为{},帧叠为{},傅里叶变换点数为{}".format(framesize, overlapSize, NFFT))
spectrum, freqs, ts, fig = plt.specgram(waveData[0], NFFT=NFFT, Fs=framerate, window=np.hanning(M=framesize),
noverlap=overlapSize, mode='default', scale_by_freq=True, sides='default',
scale='dB', xextent=None) # 绘制频谱图
plt.ylabel('频率(Hz)')
plt.xlabel('时间(s)')
plt.title("语谱图")
plt.show()
效果如下:
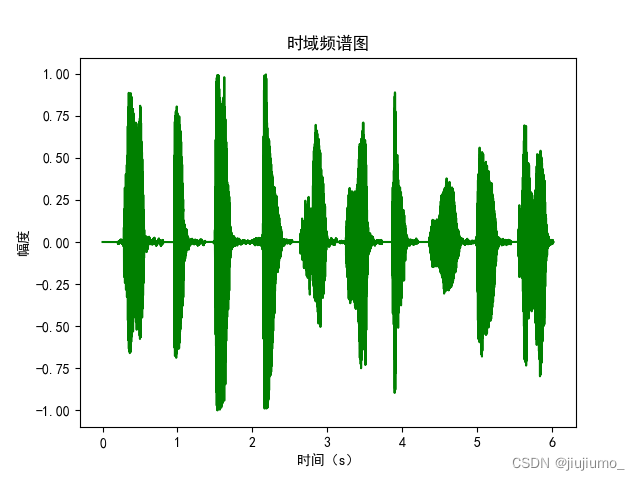
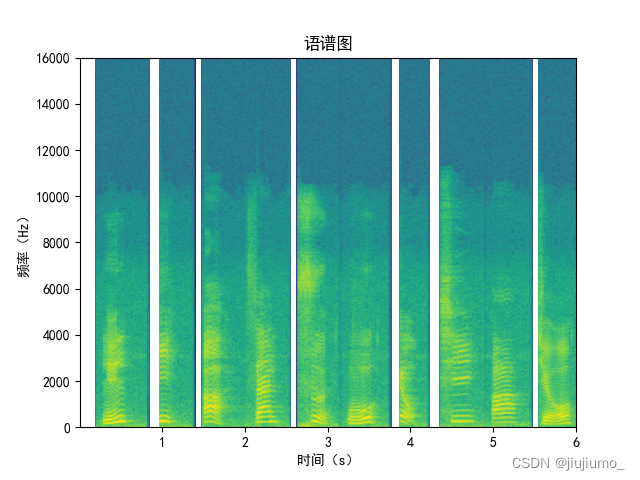
语谱图中间有间隙是因为这段音频是拼接而成的,拼接得不好。