一、扫码登录到底是怎么实现的
1、在网页端打开登录页面,展示一个二维码,这个二维码有一个唯一编号是服 务端生成的。然后浏览器定时轮询这个二维码的状态
2、APP 扫描这个二维码,把 APP 的 token 信息、二维码 ID 发送给 Server 端, Server 收到请求后修改二维码的扫码状态 ,并生成一个临时 token
3、网页端展示的二维码状态会提示已扫码,待确认。 而 APP 端扫码之后,会 提示确认授权的操作。
4、用户确认登录后 ,携带临时 token 给到 server ,server 端修改二维码状态 并为网页端生成授权 token
5、网页端轮询到状态变化并获取到 token ,从而完成扫码授权。
二、订单超时自动取消功能如何设计?
这个问题简单,直接写个定时任务去轮询数据库,根据订单时间找到超时的订单把它取 消就行了。
那个工作 7 年的粉丝也是这么回答的 ,结果挂了。
这种方式存在几个问题。
1. 轮询会存在延迟时间 ,也就是没办法准时实现订单的取消
2. 轮询数据库 ,会给数据库造成很大的压力 ,如果订单表的数据量比较大的情况下, 轮询的效率也会比较低。
如果要考虑到性能、又要考虑到实时性 ,有没有更好的方案呢?
当然有 ,比如
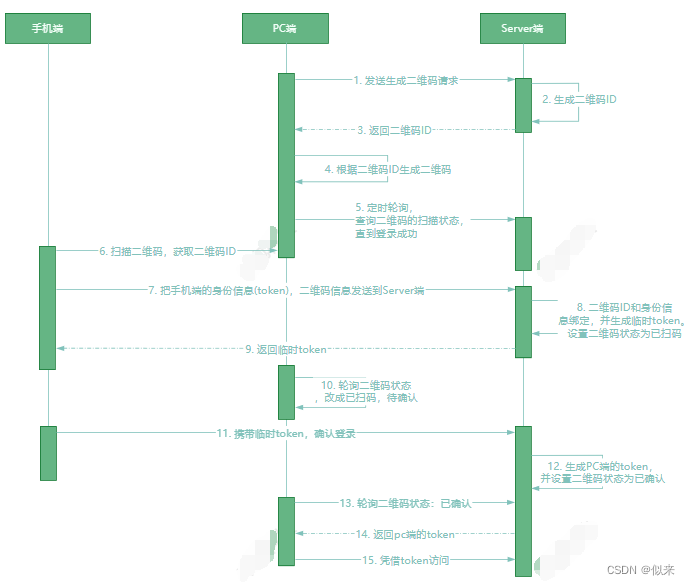
3. 时间轮算法 (如图) ,这种算法是采用了一个环状数组+链表的方式来管理延迟任 务 ,我们只需要计算这个订单的超时时间 ,再加入到时间轮里面即可。
时间轮算法唯一的缺点就是无法持久化 ,所以需要在服务重启后做一次数据预热。
4.. 利用主流 MQ 中的延迟消息功能,消息发送到 Broker 上以后并不会立刻投递,而是根据消息中设置的延迟时间去投递。我们只需要把新的订单并计算这个订单的超 时时间发送到 MQ 中即可。
MQ 这种实现方式在性能、可扩展性、稳定性上都比较好 ,是一个不错的选择。
三、怎么理解接口幂等 ,项目中如何保证的接口幂等
简单来说,就是一个接口,使用相同的参数重复执行的情况下,对数据造成的改变只发 生一次。
比如支付操作 ,如果支付接口被重复调了 N 次 ,那资金的扣减只发生一次 ,这就是幂
等。
有同学会比较好奇, 这个事情不是很正常吗?为什么还要单独拧出来说。
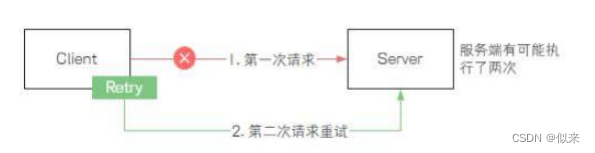
原因很简单 {如图} , 在分布式架构中, 由于引入了网络通信导致一个请求 ,除了成 功/失败以外 ,还多了一个未知状态。
也就是如果一次远程接口调用失败 ,有可能这个请求在服务端执行成功了。
而客户端为了确保本次请求执行成功,可能会发起重试的操作,导致同一个接口被重复 调用了多次。
为了保证服务端接口的幂等性,我们就需要在服务端的接口中去识别当前请求是重复请 求 ,从而不再进行数据的变更操作。
通常的解决方案有几种。
1. 使用数据库唯一索引的方式实现, 我们可以专门创建一个消息表,里面有一个消 息内容的字段并且设置为唯一索引 ,每次收到消息以后生成 md5 值插入到这个消 息表里面。一旦出现重复消息,就会抛异常,我们可以捕获这个异常来避免重复对 数据做变更。
2. 使用 Redis 里面的 setNx 命令,我们可以把当前请求中带有唯一标识的信息存储到 Redis 里面,根据 setNx 命令返回的结果来判断是否是重复执行,如果是则丢弃该 请求。
3. 使用状态机的方式来实现幂等 ,在很多的业务场景中 ,都会存在业务状态的流转, 并且这些状态流转只会前进,所以我们在对数据进行修改的时候,只需要在条件里 面带上状态 ,就能避免数据被重复修改的问题。
当然 ,除了这几种方法以外 ,肯定还有其他更多的解决方案。
不管采用哪种方案 ,核心本质都是需要去识别当前请求是重复请求。
四、消息推送中的已读消息和未读消息设计难题
“站内信”有两个基本功能:
1、点到点的消息传送。用户给用户发送站内信 ,管理员给用户发送站内信。
2、点到面的消息传送。管理员给用户 (指定满足某一条件的用户群) 群发消息
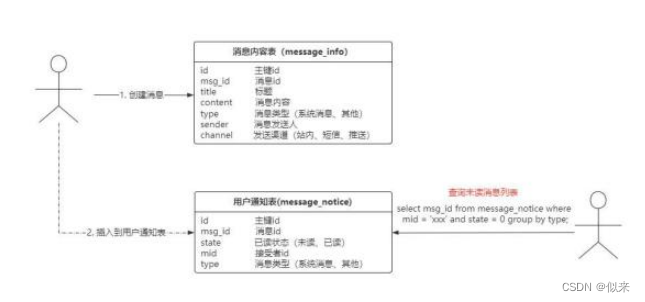
这两个功能实现起来也很简单 {如图} 。
只需要设计一个消息内容表和一个用户通知表,当创建一条系统通知后,数据插入到消息内容表。消息内容包含了发送渠道,根据发送 渠道决定后续动作。
如果是站内渠道 ,在插入消息内容后异步的插入记录到用户通知表。
这个方案看起来没什么问题,但实际上,我们把所有用户通知的消息全部放在一个表里 面 ,如果有 10W 个用户 ,那么同样的消息需要存储 10W 条。
很明显 ,会带来两个问题:
1. 随着用户量的增加,发送一次消息需要插入到数据库中的数据量会越来越大,导致 耗时会越来越长
2. 用户通知表的数据量会非常大 ,对未读消息的查询效率会严重下降
所以上面这种方案很明显行不通 ,要解决这两个问题 ,我有两个参考解决思路。
第一个方式 (如图) ,先取消用户通知表, 避免在发送平台消息的时候插入大量重复 数据问题。

其次增加一个“ message_offset”站内消息进度表 ,每个用户维护一个消息消费的进 度 Offset。
每个用户去获取未读消息的时候,只需要查询大于当前维护的 msg_id_offset 的数据即 可。
在这种设计方式中 ,即便我们发送给 10W 人 ,也只需要在消息内容表里面插入一条记 录即可。
在性能上和数据量上都有较大的提升。
第二种方式,和第一种方式类似,使用 Redis 中的 Set 集合来保存已经读取过的消息 id。 使用 userid_read_message 作为 key ,这样就可以为每个用户保存已经读取过的所有 消息的 id。
当用户读取了未读消息后, 就直接在 redis 的已读消息 id的 set 中新增一条记录。 这样 ,在已经得知到已读消息的数量和具体消息 id 的情况下 ,我们可以直接使用消息 id 来查询没有消费过的数据。
你们看,一个小小的方案设计的优化,就能带来性能上的巨大提升,这就是为什么很多 企业宁愿多花点钱也要招技术厉害的人的原因了吧。
五、布隆过滤器到底是什么东西? 它有什么用?
在解释布隆过滤器之前,我先问大家一个问题,如果我想判断一个元素是否存在某个集 合里面怎么做?
一般的解决方案是先把所有元素保存起来 ,然后通过循环比较来确定。
但是如果我们有几千万甚至上亿的数据的时候 {如图} ,虽然可以通过不同的数据结构 来优化数据检索的时间复杂度 ,但是整体的效率依然很慢,而且会占用非常多的内存空间 ,这个问题该怎么解决呢?

这个时候 ,位图就派上了用场 {如图}
BitMap 的基本原理就是用一个 bit 位来存储当前数据是否存在的状态值,也就是把一 个数据通过 hash 运算取模后落在 bit 位组成的数组中 ,通过 1 对该位置进行标记。 这种方式适用于大规模数据,但数据状态又不是很多的情况,通常是用来判断某个数据 存不存在的。

布隆过滤器就是在位图的基础上做的一个优化设计 {如图} 。
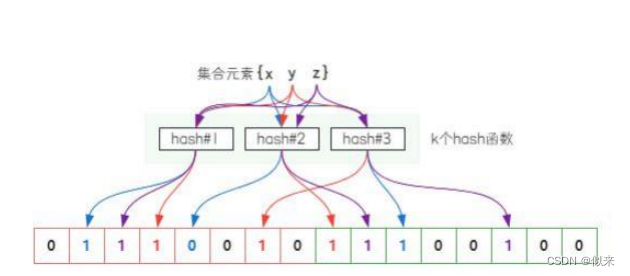
它的原理是,当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数 组中的 K 个点 ,把它们置为 1。
检索的时候,使用同样的方式去映射,只要看到每个映射的位置的值是不是 1,就可以大概知道该元素是否存在集合中了。
如果这些点有任何一个 0 ,则被检查的元素一定不在;如果都是 1 ,则被检查的元素很 可能存在。