本篇继续分享关于C++入门的相关知识,有关命名空间、缺省参数和函数重载的部分欢迎阅读我的上一篇文章【C++】C++入门基础详解(1)_王笃笃的博客-CSDN博客
继续我们的学习
引用
在C语言中我们接触过指针,很多人都或多或少为他感到头痛过,很多C语言的使用者包括创始人都觉得很难用,所以便创造出了引用。
1.引用的概念
引用不是定义一个新的变量,而是给已经存在的一个变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共享同一块空间。
举个例子,就比如你叫李四,同学给你起了外号叫小四,你妈妈给你取的小名叫四四,这些名字都指的是李四,这么说应该不难理解;
上代码感受一下
int main()
{
int a = 0;
int& b = a;
return 0;
}可以看到我们创建出了一个整形a,使用&符号创建了b,这里的b就是a的别名,他们公用一段内存空间。
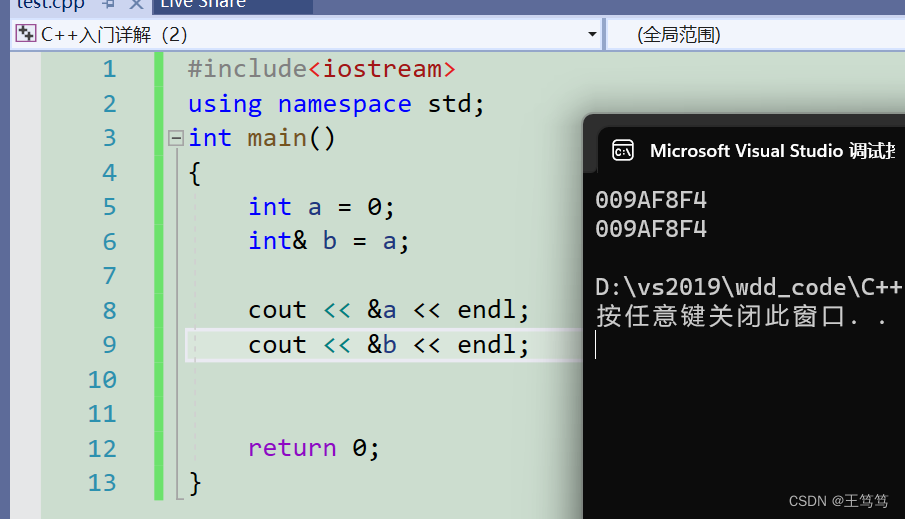
很明显&符号在类型和定义的变量中间会被当作引用符号,否则就是取地址,我们也可以看出a和b共用同一块空间;
当我们给a和b同时++运算时
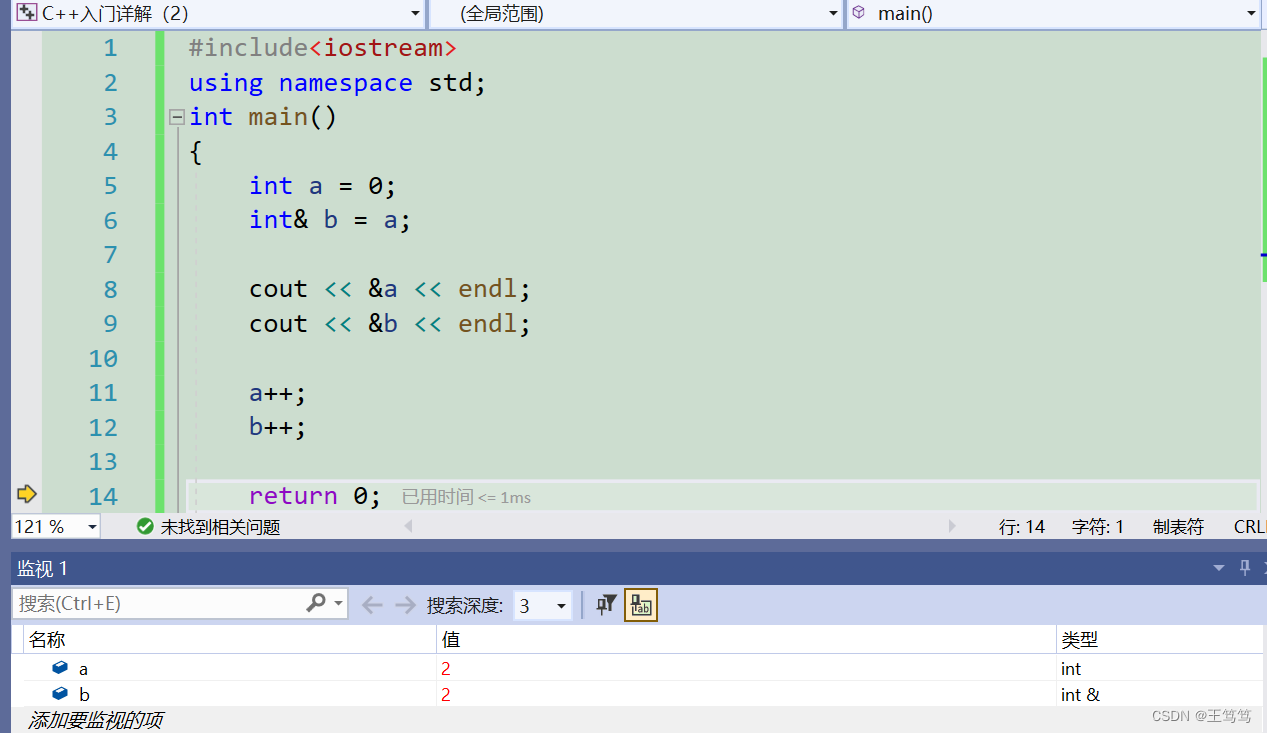
可以看到他们都参与了运算,因为他们本质上就是对同一个数据进行操作;
可以简单的使用在两数交换之中
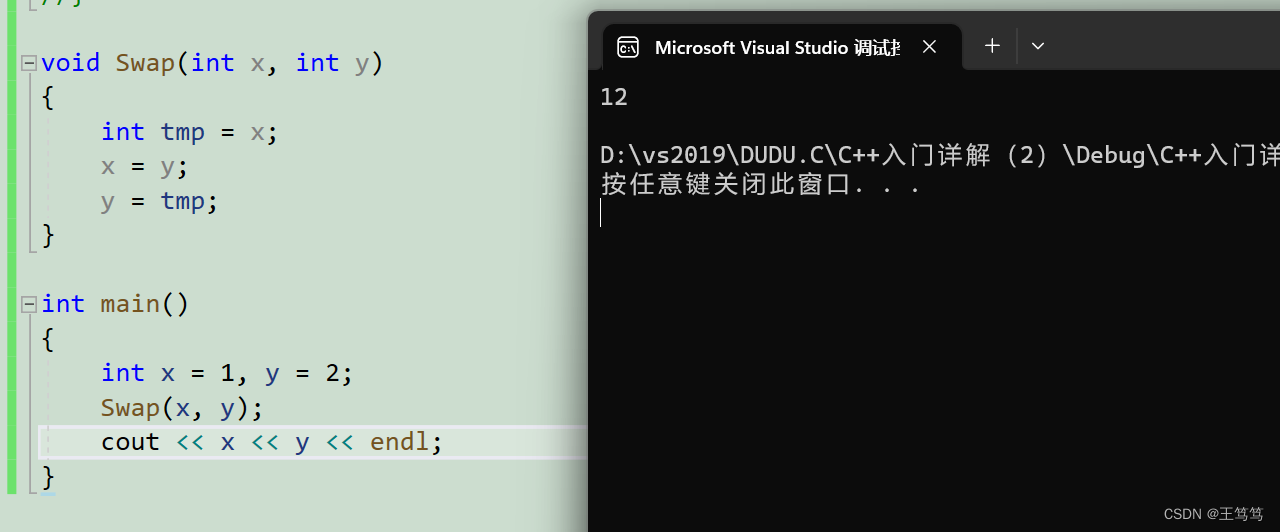
可以看到传值并不会真正的实现转换,但是我们用引用的方法传参
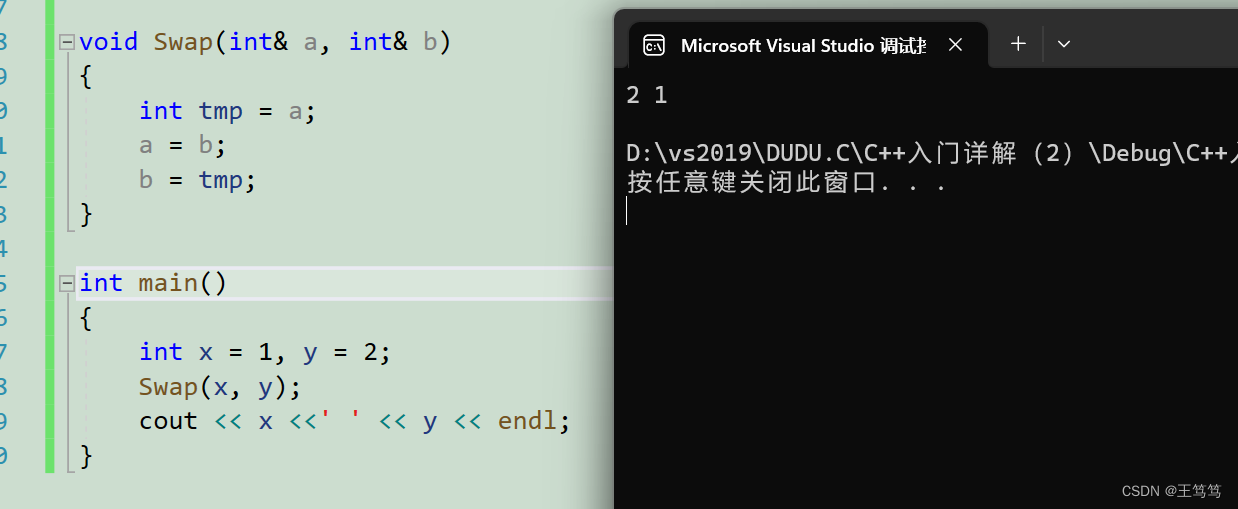
可以看到两数交换成功了。
在这里里我们在函数中用引用定义参数意义是给实参取了别名,x的别名就是a,y的别名就是b,我们对a和b进行操作实际上就是对x和y进行操作。
还有一种用C语言实现链表的场景
typedef struct ListNode
{
int val;
struct ListNode* next;
}ListNode;
void Push_back(ListNode** pphead, int x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode) * sizeof(int));
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
}
}
int main()
{
ListNode* plist = NULL;
Push_back(&plist, 1);
Push_back(&plist, 2);
Push_back(&plist, 3);
}这里的重点是二级指针的使用,当时我在写二级指针的时候也是非常头疼,但是我我们现在学习了引用可以对上面的代码进行优化;
typedef struct ListNode
{
int val;
struct ListNode* next;
}ListNode;
void Push_back(ListNode*& phead, int x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode) * sizeof(int));
if (phead == NULL)
{
phead = newnode;
}
else
{
}
}
int main()
{
ListNode* plist = NULL;
Push_back(plist, 1);
Push_back(plist, 2);
Push_back(plist, 3);
}可以看到现在的phead就是plist的别名,也就是说操作phead就可以达到操作plist的目的,这样就不用再纠结二级指针的使用,同样可以达到二级指针的效果。
通过以上代码我们可以知道引用作为形参,其他函数传参时引用可以影响实参。
接下来是引用使用时需要注意的一些小细节;
2.引用的特性
使用引用的时候必须初始化

不能说只取外号没有真正的名字,这样的用法是错误的;
同时一个变量可以被多次引用,也就是说一个人可以有很多个外号,也可以给外号取外号;
int main()
{
int a = 0;
int& b = a;
int& c = a;
int& d = a;
int& e = d;
return 0;
}这些都是可行的,虽然有很多引用但是它的底层都是对a进行操作;
还需要注意的是引用一但引用了一个实体,就不能再引用其他实体,也就是说上面的b、c、d、e不能再当作别人的外号。

可以看到报错说e被多次初始化,这也是C++的引用和java的引用区别,C++的引用只能引用一个实体,java的引用是可以改变指向的,这样就导致C++不能脱离指针,Java可以脱离指针。
3.引用做返回值
在刚开始认识函数时我们接触过传值返回

需要注意的是这里返回值并不是n,而是n的值
同时也有一种用法,但是这种用法非常危险。
那就是函数传引用返回
int& Count()
{
int n = 0;
n++;
return n;
}
int main()
{
int ret = Count();
cout << ret << endl;
return 0;
}为什么会这种用法会非常危险呢?
我们知道调用函数时会建立栈帧,函数内部的临时变量都会在调用函数结束时失效,在这里传引用返回就相当于给没有名字的空间起了别名,类似于野指针的后果,所以这种情况输出可能会有两种情况,一种是正常输出,一种会输出随机值
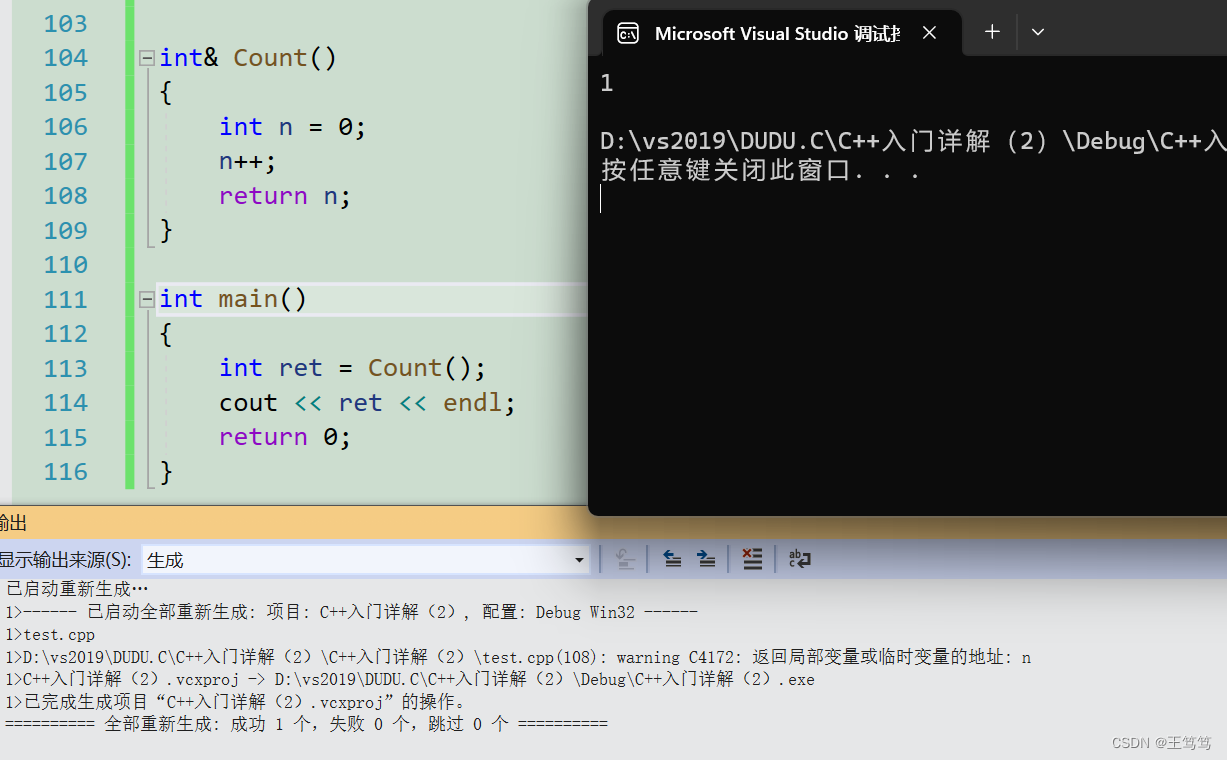
可以看到在vs的平台下会输出1,但是下方的结果或有一个waring
![]()
我们再用一段代码来解释传引用返回的影响;
int& Add(int x, int y)
{
int c = x + y;
return c;
}
int main()
{
int& ret = Add(1,2);
Add(2, 3);
cout << "Add(1,2) is" << ret << endl;
return 0;
}以下是运行结果
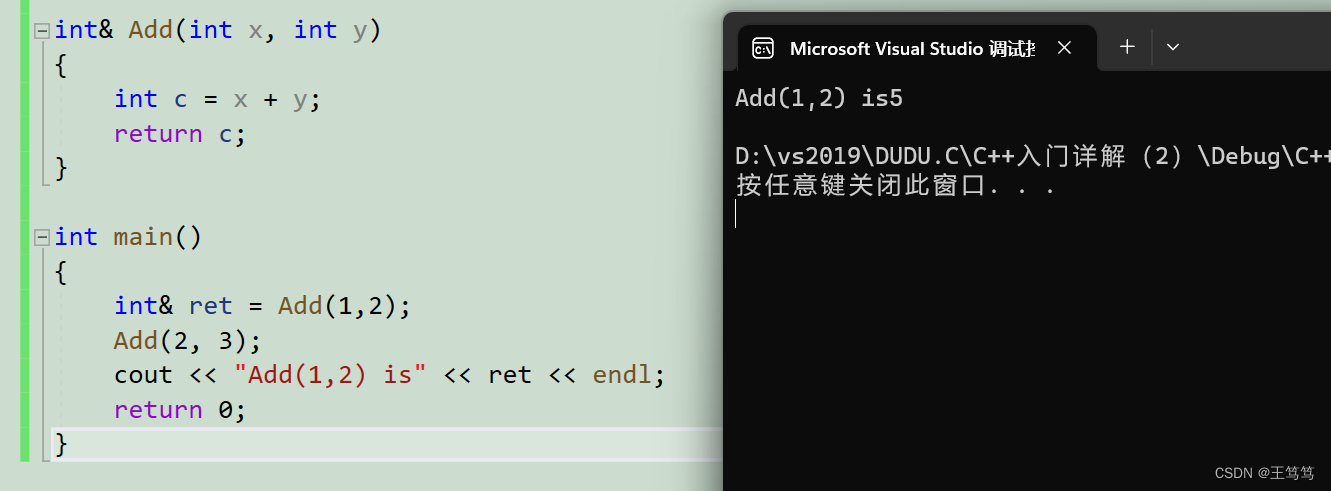
这里的原因是先用1和2调用了Add函数,并且将此次调用函数所占用的空间取了别名叫做ret,此时Add函数除了作用域后里面的数值都会被销毁,而空间还会被留下来,此时再次用2和3去调用Add,那么此次调用就会使用Add的栈帧空间,就得到了如上结果。
形象的说就是你在某一家酒店开了房,走的时候发现有东西没拿上,所以重新回房间里拿了东西,希望大家可以理解。
所以分享了以上错误的使用方式可以得到一个结论:如果函数返回时,出了函数作用域,如果返回对象没有返还给系统,则可以使用引用返回;如果已经返还给系统,则必须使用传值返回。
传引用返回在有些场景下也有着便捷的作用;
当初在学习数据结构时使用C语言完成链表是非常繁琐的
这里简单使用链表找到第i个位置的数据和修改数据
struct SeqList
{
int* a;
int size;
int capacity;
};
//找到第i个位置
int SLAt(SeqList* ps, int i)
{
assert(i < ps->size);
return ps->a[i];
}
//修改
int SLModify(SeqList* ps, int i,int x)
{
assert(i < ps->size);
ps->a[i]=x;
}可以感觉到C语言的接口非常的繁琐;
下面是C++读或修改数据的接口
int& SLAt(SeqList* ps, int i)
{
assert(i < ps->size);
return ps->a[i];
}可以看到非常非常简单,只需要在返回类型前加上引用符号即可完成读取和修改的操作,
当然也可也全部使用引用减少拷贝的时间消耗
int& SLAt(SeqList& ps, int i)
{
assert(i < ps.size);
return ps.a[i];
}通过main函数来简单使用
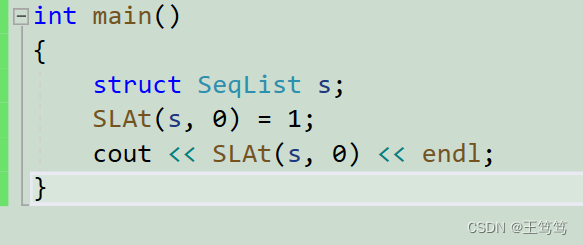
这样我们既可以完成读取![]() ,
,
也可以完成修改操作 ,
,
所以引用做返回值也有它合适的场景。
以上就是本片要分享的关于C++引用的使用,如果对你有所帮助还请三连支持,感谢您的阅读。