第1章.Elasticsearch简介
1-1.Elasticsearch介绍
-
Elasticsearch官方网站:https://www.elastic.co/cn/elasticsearch/
-
Elasticsearch是一个基于Lucene的搜索服务器
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
-
提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
-
Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎
-
Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言都可以使用
-
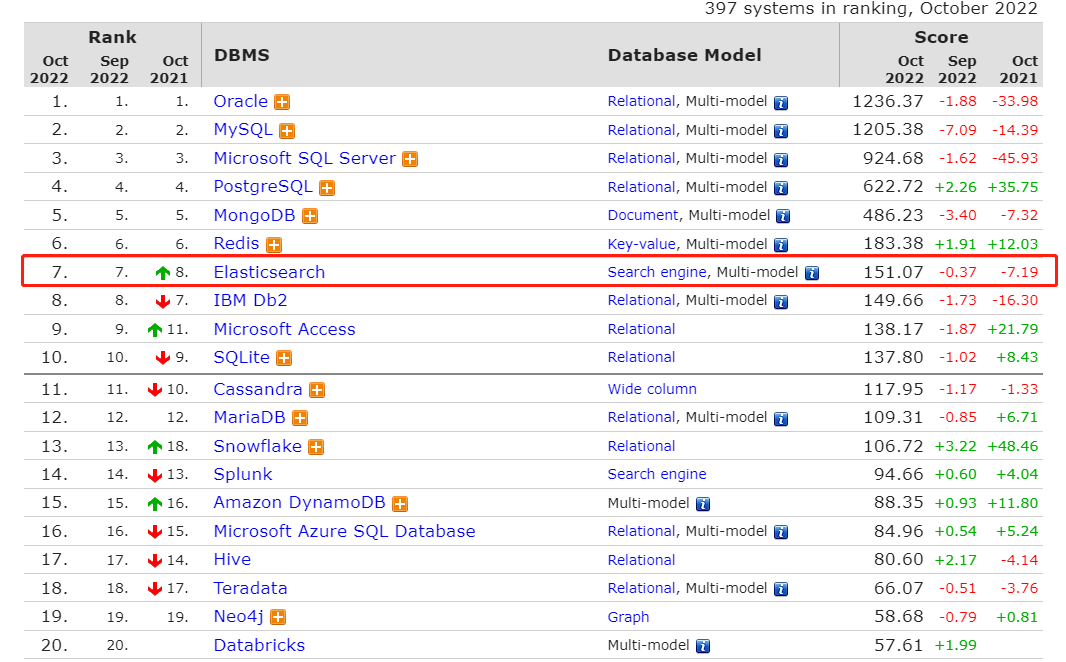
根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎
搜索引擎分类,Elasticsearch已经遥遥领先,其次是Apache Solr也较为出名,两者都是基于Lucene
DB-Engines官网:https://db-engines.com/en/ranking
- Elasticsearch的创始人是:Shay Banon (谢巴农)
1-2.Elasticsearch使用场景
-
信息检索
- 百度搜索
- 淘宝京东主页商品搜索
- CSDN主页关键词搜索
- …
-
企业内部系统搜索
-
公司内网系统的OA、CRM、ERP搜索
- 关系型数据库使用like进行模糊检索,会导致索引失效,效率低下
- 可以基于Elasticsearch来进行高效检索
-
-
数据分析引擎
- Elasticsearch 聚合可以对数十亿行日志数据进行聚合分析,探索数据的趋势和规律
1-3.Elasticsearch知名企业使用场景
- 2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。“GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”
- 维基百科:启动以elasticsearch为基础的核心搜索架构
- SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
- 百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
- 新浪使用ES分析处理32亿条实时日志
- 阿里使用ES构建挖财自己的日志采集和分析体系
1-4.Elasticsearch特点
-
海量数据处理
- 大型分布式集群(数百台规模服务器)
- 处理PB级数据
- 也支持单机运作
-
开箱即用
- 简单易用,操作相对便捷
- 可快速部署生产环境
-
可作为传统数据库的功能补充
-
传统关系型数据库不擅长全文检索
MySQL自带的全文索引,与ES性能差距非常大
-
传统关系型数据库无法支持搜索排名、海量数据存储、分析等功能
-
Elasticsearch可以作为传统关系数据库的补充,提供RDBM无法提供的功能
-
1-5.Elasticsearch对比Solr

Solr 和 Elasticsearch 都在快速发展,但从近几年的流行趋势来看,与 Solr 相比,Elasticsearch 具有很大的吸引力;其次,与 Solr 相比,Elasticsearch 易于安装且非常轻巧;ES 增长非常的迅速。
1-6.Elasticsearch发展历史
- 2004年,发布第一个版本名为Compass的搜索引擎,创建搜索引擎的目的主要是为了搜索食谱
- 2010年,发布第二个版本更名为Elasticsearch,基于Apache Lucene开发并开源
- 2012年,创办Elasticsearch公司
- 2015年,Elasticsearch公司更名为Elastic,是专门从事与Elasticsearch相关的商业服务,并衍生了Logstash和Kibana两个项目,填补了在数据采集、数据可视化的空白。于是,ELK就诞生了
- 2015年,Elastic公司将开源项目Packetbeat整合到Elasticsearch技术栈中,并更名为Beats,它专门用于数据采集的轻量级组件,可以将网络日志、度量、审计等各种数据作为不同的源头发送到Logstash或者Elasticsearch
- 此后ELK不再包括Elastic公司所有的开源项目,ELK开始更名为Elastic Stack,将来还有更多的软件加入其中,包括数据采集、清洗、传输、存储、检索、分析、可视化等
- 2018年,Elastic公司在纽交所挂牌上市Elastic NV
第2章.Lucene全文检索库(铺垫加深es的检索逻辑)
2-1.全文检索介绍
- 结构化数据与非结构化数据、
- 结构化数据
- 指具有固定格式或有限长度的数据
- 如数据库,元数据等
- 非结构化数据
- 指不定长或无固定格式的数据
- 如邮件,word文档等磁盘上的文件
- 结构化数据
- 搜索结构化数据和搜索非结构化数据
- 使用SQL语言专门搜索结构化的数据
- 使用ES/Lucene/Solor建立倒排索引,根据关键字就可以搜索一些非结构化的数据
- 全文检索
- 通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数
- 用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读读取出来
- 类似于通过字典中的检索字表查字的过程
2-2.Lucene简介
-
Lucene是一种高性能的全文检索库,在2000年开源,最初由Doug Cutting(道格·卡丁)开发
除了Lucene,还开发了著名的网络爬虫工具Nutch,分布式系统基础架构Hadoop
-
Lucene是Apache的一个顶级开源项目,是一个全文检索引擎工具包。但Lucene不是一个完整的全文检索引擎,它只是提供一个基本的全文检索的架构,还提供了一些基本的文本分词库
-
Lucene是一个简单易用的工具包,可以方便的实现全文检索的功能
2-3.通过Lucene实现美文搜索案例
2-3-1.需求背景
在资料中的文章文件夹中,有很多的文本文件。这里面包含了几篇文章,通过搜索一个关键字就能够找到哪些文章包含了这些关键字。例如:搜索「hadoop」,就能找到hadoop相关的文章
需求分析:
方案1:
用户输入搜索关键字,遍历读取文件,并查找每个文件中是否包含关键字
方案2:
预先遍历读取文件,对每个文件的文本内容进行分词(例如:按标点符号),然后建立索引,用户输入关键字,根据之前建立的全部索引,逐个匹配搜索的关键字。
对比两种方案,方案2要比第1种效果好得多,性能也好得多。下面就使用Lucene来建立索引,然后根据索引来进行检索。
2-3-2.开发环境准备
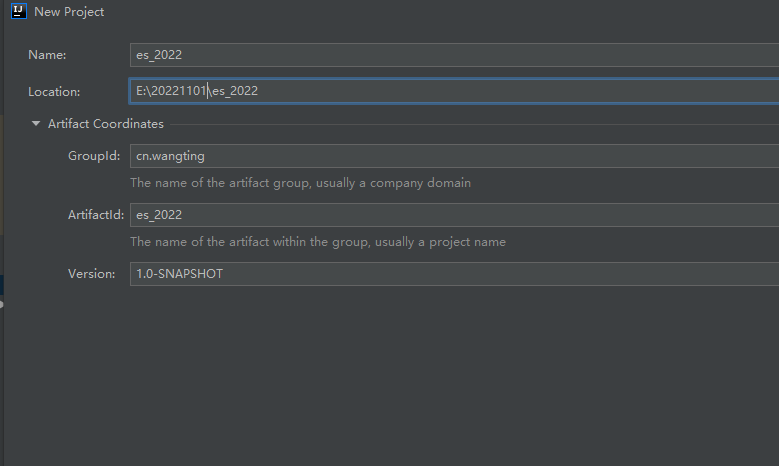
- 创建一个Maven项目
GroupId: cn.wangting
ArtifactId: es_2022
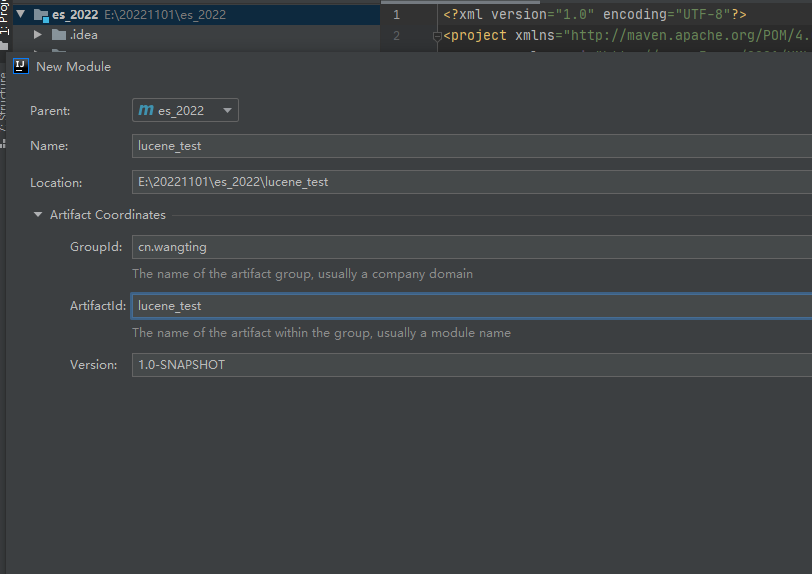
- 创建module模块
创建完毕后,右键项目名称: es_2022 - > New -> Module 创建一个新maven模块
GroupId:cn.wangting
ArtifactId:lucene_test
- 导入模块的pom文件
注意是es_2022项目下,lucene_test模块下的pom.xml文件,不是父项目的总pom文件
E:\20221101\es_2022\lucene_test\pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>es_2022</artifactId>
<groupId>cn.wangting</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>lucene_test</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>8.4.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
- java下创建包和类
- 在java目录创建 cn.wangting.lucene 包结构
- 创建BuildArticleIndex类
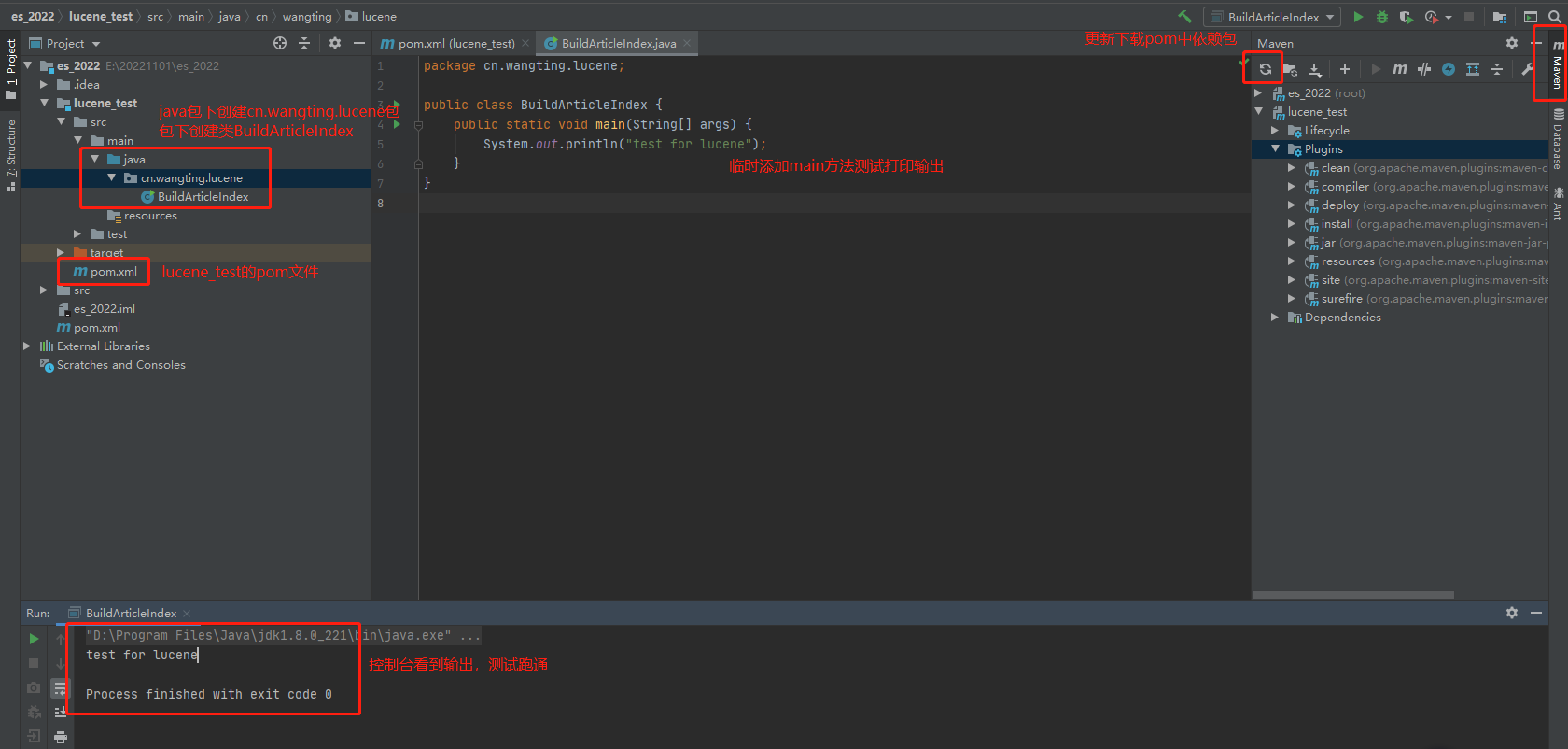
- 导入测试文章数据
模块下创建data目录用来存放文章文件( 被处理的数据文件 )
模块下创建index目录用于存放最后生成的索引文件( 处理完毕后的输出结果文件 )
测试样例文章素材:
https://osswangting.oss-cn-shanghai.aliyuncs.com/elasticsearch/data_for_lucene_test.zip
2-3-3.建立索引库代码实现
实现步骤:
1.构建分词器(StandardAnalyzer)
2.构建文档写入器配置(IndexWriterConfig)
3.构建文档写入器(IndexWriter)
4.读取所有文件构建文档
5.文档中添加字段
| 字段名 | 类型 | 说明 |
|---|---|---|
| file_name | TextFiled | 文件名字段,需要在索引文档中保存文件名内容 |
| content | TextFiled | 内容字段,只需要能被检索,但无需在文档中保存 |
| path | StoredFiled | 路径字段,无需被检索,只需要在文档中保存即可 |
6.写入文档
7.关闭写入器
BuildArticleIndex类代码:
package cn.wangting.lucene;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
public class BuildArticleIndex {
public static void main(String[] args) throws IOException {
// 1.构建分词器(StandardAnalyzer)
IKAnalyzer standardAnalyzer = new IKAnalyzer();
// 2.构建文档写入器配置(IndexWriterConfig)
IndexWriterConfig writerConfig = new IndexWriterConfig(standardAnalyzer);
// 3.构建文档写入器(IndexWriter,注意:需要使用Paths来)
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(Paths.get("E:\\20221101\\es_2022\\lucene_test\\index")), writerConfig);
// 4.读取所有文件构建文档
File dataDir = new File("E:\\20221101\\es_2022\\lucene_test\\data");
File[] fileArray = dataDir.listFiles();
// 迭代data目录中所有的文本文件,读取文件并建立索引
for (File file:fileArray){
// 5.文档中添加字段
Document doc = new Document();
doc.add(new TextField("file_name",file.getName(), Field.Store.YES));
doc.add(new TextField("content", FileUtils.readFileToString(file),Field.Store.NO));
doc.add(new StoredField("path",file.getAbsolutePath()));
// 6.写入文档
indexWriter.addDocument(doc);
}
// 7.关闭写入器
indexWriter.close();
}
}
将代码执行后,在index目录会生成索引文件
有了索引库,接下来需要有一个查询类,来测试索引查询
2-3-4.关键字查询代码实现
需求:输入一个关键字,根据关键字查询索引库中是否有匹配的文档
1.前提:基于文章文本文件,已经生成好了索引
2.在cn.wangting.lucene包下创建一个类KeywordSearch
实现步骤:
1.使用DirectoryReader.open构建索引读取器
2.构建索引查询器(IndexSearcher)
3.构建词条(Term)和词条查询(TermQuery)
4.执行查询,获取文档
5.遍历打印文档(可以使用IndexSearch.doc根据文档ID获取到文档)
6.关键索引读取器
KeywordSearch
package cn.wangting.lucene;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import java.io.IOException;
import java.nio.file.Paths;
public class KeywordSearch {
public static void main(String[] args) throws IOException {
// 1. 使用DirectoryReader.open构建索引读取器
DirectoryReader reader = DirectoryReader.open(FSDirectory.open(Paths.get("E:\\20221101\\es_2022\\lucene_test\\index")));
// 2. 构建索引查询器(IndexSearcher)
IndexSearcher indexSearcher = new IndexSearcher(reader);
// 3. 构建词条(Term)和词条查询(TermQuery)
TermQuery termQuery = new TermQuery(new Term("content", "座位"));
// 4. 执行查询,获取文档
TopDocs topDocs = indexSearcher.search(termQuery, 50);
// 5. 遍历打印文档(使用IndexSearch.doc根据文档ID获取到文档)
ScoreDoc[] scoreDocArray = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocArray) {
// 在Lucene中,每一个文档都有一个唯一ID
// 根据唯一ID就可以获取到文档
Document document = indexSearcher.doc(scoreDoc.doc);
// 获取文档中的字段
System.out.println("-------------");
System.out.println("文件名:" + document.get("file_name"));
System.out.println("文件路径:" + document.get("path"));
System.out.println("文件内容:" + document.get("content"));
}
// 6. 关闭索引读取器
reader.close();
}
}
输入一个关键词:”座位“,执行结果筛选出在《永远的坐票》文章中出现了关键词:座位
原文章路径均在索引定义的对应关系中:
| 字段名 | 类型 |
|---|---|
| file_name | TextFiled |
| content | TextFiled |
| path | StoredFiled |
2-4.倒排索引结构
倒排索引是一种建立索引的方法。是全文检索系统中常用的数据结构。通过倒排索引,就是根据单词快速获取包含这个单词的文档列表。倒排索引通常由两个部分组成:单词词典、文档
2-5.企业不直接使用Lucene原因分析
- Lucene的内建不支持分布式
- Lucene是作为嵌入的类库形式使用的,本身是没有对分布式支持
- 区间范围搜索速度非常缓慢
- Lucene的区间范围搜索API是扩展补充的,对于在单个文档中term出现比较多的情况,搜索速度会变得很慢
- Lucene只有在数据生成索引文件之后(Segment),才能被查询到,做不到实时
- 可靠性无法保障
- 无法保障Segment索引段的可靠性
第3章.Elasticsearch中的核心概念
3-1.索引-index
- 一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引
- 一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字
- 在一个集群中,可以定义任意多的索引
3-2.映射-mapping
- ElasticSearch中的映射(Mapping)用来定义一个文档
- mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置
3-3.字段-Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
3-4.类型-Type
针对每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等
3-5.文档-document
- 一个文档是一个可被索引的基础信息单元
- 某一个客户的文档
- 某一个产品的一个文档
- 某个订单的一个文档
- 文档以JSON(Javascript Object Notation)格式来表示
3-6.集群-cluster
- 一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
- 一个集群由一个唯一的名字标识在定义,这个名字默认就是“elasticsearch”
- 定义的这个名字非常重要,因为一个节点只能通过指定某个集群的名字,来加入这个集群,来发现探寻
3-7.节点-node
- 一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能
- 一个节点可以通过配置集群名称的方式来加入一个指定的集群。每个节点都会被安排加入到配置文件中定义的集群名中,例如默认的“elasticsearch”
- 如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中
- 在一个集群里,可以拥有任意多个节点。而且,如果当前网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群
3-8.分片-shards
- 一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢
- Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片
- 当创建一个索引的时候,可以指定分片数量
- 每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上
- 分片允许水平分割/扩展你的内容容量
- 分片允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
- 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户来说,这些都是透明的
3-9.副本-replicas
- 在一个网络/云的环境里,任务失败或者故障随时都可能发生,在某个分片/节点出现问题导致离线状态,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许创建的分片有一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本
- 副本在分片/节点失败的情况下,提供了高可用性。注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的
- 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行
- 每个索引可以被分成多个分片。一个索引有0个或者多个副本
- 一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引创建的时候指定
- 在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量
第4章.Elasticsearch安装部署
4-1.环境准备
4-1-1.机器规划
| IP地址 | 操作系统 | 主机名 |
|---|---|---|
| 172.28.54.207 | CentOS7.8 | es01 |
| 172.28.54.208 | CentOS7.8 | es02 |
| 172.28.54.209 | CentOS7.8 | es03 |
各节点设置主机名:
# 172.28.54.207
hostnamectl set-hostname es01
# 172.28.54.208
hostnamectl set-hostname es01
# 172.28.54.209
hostnamectl set-hostname es01
4-1-2.各节点创建普通用户
ES不能使用root用户来启动,否则会报错,使用普通用户来安装启动。创建一个普通用户以及定义一些常规目录用于存放我们的数据文件以及安装包等
# 3台机器都需要执行
[root@es01 ~]# useradd wangting
[root@es01 ~]# echo wangting|passwd --stdin wangting
4-1-3.各节点将普通用户权限提高
[root@es01 ~]# visudo
# 增加一行普通用户权限内容
wangting ALL=(ALL) NOPASSWD:ALL
让普通用户有更大的操作权限,一般都会给普通用户设置sudo权限,方便普通用户的操作,避免操作时频繁输入密码
4-1-4.各节点添加hosts主机名解析
[root@es01 ~]# vim /etc/hosts
# es
172.28.54.207 es01
172.28.54.208 es02
172.28.54.209 es03
如果在各节点的/etc/hosts中都配置了节点的ip解析,那后续在配置文件中,相关的ip配置都可以用解析名代替;
例如:network.host: 172.28.54.207 等同于 network.host: es01
4-1-5.安装包准备
各组件均可以在官方找到对应版本下载:
elasticsearch:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
kibana:https://www.elastic.co/cn/downloads/past-releases#kibana
本文章所有相关组件安装包以及素材均分享在云盘:
链接:https://pan.baidu.com/s/1NI9vDPNZHJkqzNevwZFOmw?pwd=54lg
提取码:54lg可以根据需要自行获取
注意:ES相关的各组件工具,版本需要对齐一致
[root@es01 ~]# su - wangting
Last login: Wed Nov 2 15:50:21 CST 2022 on pts/0
[wangting@es01 ~]$ ll
total 533168
-rw-r--r-- 1 wangting wangting 296454172 Nov 2 15:37 elasticsearch-7.6.1-linux-x86_64.tar.gz
-rw-r--r-- 1 wangting wangting 249498863 Nov 2 15:49 kibana-7.6.1-linux-x86_64.tar.gz
4-1-6.各节点环境优化
注意各节点执行的命令,需要自行在其它每个节点去执行
优化1:
系统允许 Elasticsearch 打开的最大文件数需要修改成65536
[root@es01 ~]# vim /etc/security/limits.conf
# End of file
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 65536
# 断开重连会话
[root@es01 ~]# ulimit -n
65535
这个配置不优化启动服务会出现:
[error] max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] elasticsearch
优化2:
允许最大进程数配置修该成4096;不是4096则需要修改优化
[root@es01 ~]# vim /etc/security/limits.d/20-nproc.conf
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
* soft nproc 4096
root soft nproc unlimited
这个配置不优化启动服务会出现:
[error]max number of threads [1024] for user [judy2] likely too low, increase to at least [4096]
优化3:
设置一个进程可以拥有的虚拟内存区域的数量
# 增加配置项vm.max_map_count
[root@es01 ~]# vim /etc/sysctl.conf
vm.max_map_count=262144
# 重载配置
[root@es01 ~]# sysctl -p
这个配置不优化启动服务会出现:
[error]max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
4-2.安装es
4-2-1.解压安装
[wangting@es01 ~]$ sudo mkdir -p /opt/module/
[wangting@es01 ~]$ sudo chown -R wangting.wangting /opt/module/
[wangting@es01 ~]$ tar -xf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /opt/module/
[wangting@es01 ~]$ cd /opt/module/elasticsearch-7.6.1/
4-2-2.修改配置文件
elasticsearch.yml
[wangting@es01 elasticsearch-7.6.1]$ cd config/
[wangting@es01 config]$ mv elasticsearch.yml elasticsearch.yml_bak
[wangting@es01 config]$ vim elasticsearch.yml
cluster.name: wangting-es
node.name: es01
path.data: /data
bootstrap.memory_lock: false
network.host: es01
http.port: 9200
bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"
discovery.seed_hosts: ["es01", "es02", "es03"]
cluster.initial_master_nodes: ["es01", "es02"]
配置项说明:
cluster.name: wangting-es # 集群名称;同一集群各节点名称必须相同
node.name: es01 # 当前节点名称;可理解成在集群中各自用这个名称区别
path.data # 数据存储路径
path.logs # 服务日志路径
bootstrap.memory_lock: false # bootstrap自检程序
network.host: es01 # 当前节点host主机
http.port: 9200 # es启动端口
bootstrap.system_call_filter: false # 禁用系统调用过滤器
http.cors.enabled: true # 是否支持跨域
http.cors.allow-origin # 跨域范围
discovery.seed_hosts # 所有可以被检索的节点列表清单
cluster.initial_master_nodes # 用于在es集群初始化时选举主节点master
jvm.options
# 修改-Xms和-Xmx参数为2g
[wangting@es01 config]$ vim jvm.options
-Xms2g
-Xmx2g
调整jvm堆内存大小
创建data目录和log目录
[wangting@es01 ~]$ sudo mkdir /data && sudo chown -R wangting:wangting /data
4-2-3.分发安装目录
在各节点上先创建好目录
[root@es02 ~]# sudo mkdir -p /opt/module/ && sudo chown -R wangting.wangting /opt/module/
[root@es03 ~]# sudo mkdir -p /opt/module/ && sudo chown -R wangting.wangting /opt/module/
分发安装目录
[wangting@es01 ~]$ scp -r /opt/module/elasticsearch-7.6.1 es02:/opt/module/
[wangting@es01 ~]$ scp -r /opt/module/elasticsearch-7.6.1 es03:/opt/module/
修改其它节点的配置文件:
# 修改node.name和network.host两个参数,其它一样均可
# es02
[root@es02 ~]# cd /opt/module/elasticsearch-7.6.1/config/
[root@es02 config]# vim elasticsearch.yml
node.name: es02
network.host: es02
# es03
[root@es03 ~]# cd /opt/module/elasticsearch-7.6.1/config/
[root@es03 config]# vim elasticsearch.yml
node.name: es03
network.host: es03
创建data目录
[root@es02 ~]# sudo mkdir /data && sudo chown -R wangting:wangting /data
[root@es03 ~]# sudo mkdir /data && sudo chown -R wangting:wangting /data
4-2-4.启动服务
[wangting@es01 ~]$ /opt/module/elasticsearch-7.6.1/bin/elasticsearch -d
[wangting@es02 ~]$ /opt/module/elasticsearch-7.6.1/bin/elasticsearch -d
[wangting@es03 ~]$ /opt/module/elasticsearch-7.6.1/bin/elasticsearch -d
【注意】:
- -d 为后台运行,不加-d只能前台运行,关了会话窗口服务也会同时终止
- 3台机器都需要启动elasticsearch
- 运行日志没有配置定义,默认在服务目录下:elasticsearch-7.6.1/logs/ ,有异常可以先查看日志
4-3.验证es服务
4-3-1.命令验证服务
curl 服务端口查看基本信息
[wangting@es01 ~]$ curl http://es01:9200
{
"name" : "node-es01",
"cluster_name" : "wangting-es",
"cluster_uuid" : "_na_",
"version" : {
"number" : "7.6.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b",
"build_date" : "2020-02-29T00:15:25.529771Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
[wangting@es01 ~]$ curl http://es02:9200
{
"name" : "node-es02",
"cluster_name" : "wangting-es",
"cluster_uuid" : "_na_",
"version" : {
"number" : "7.6.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b",
"build_date" : "2020-02-29T00:15:25.529771Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
[wangting@es01 ~]$ curl http://es03:9200
{
"name" : "node-es03",
"cluster_name" : "wangting-es",
"cluster_uuid" : "_na_",
"version" : {
"number" : "7.6.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b",
"build_date" : "2020-02-29T00:15:25.529771Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
4-3-2.查看集群状态
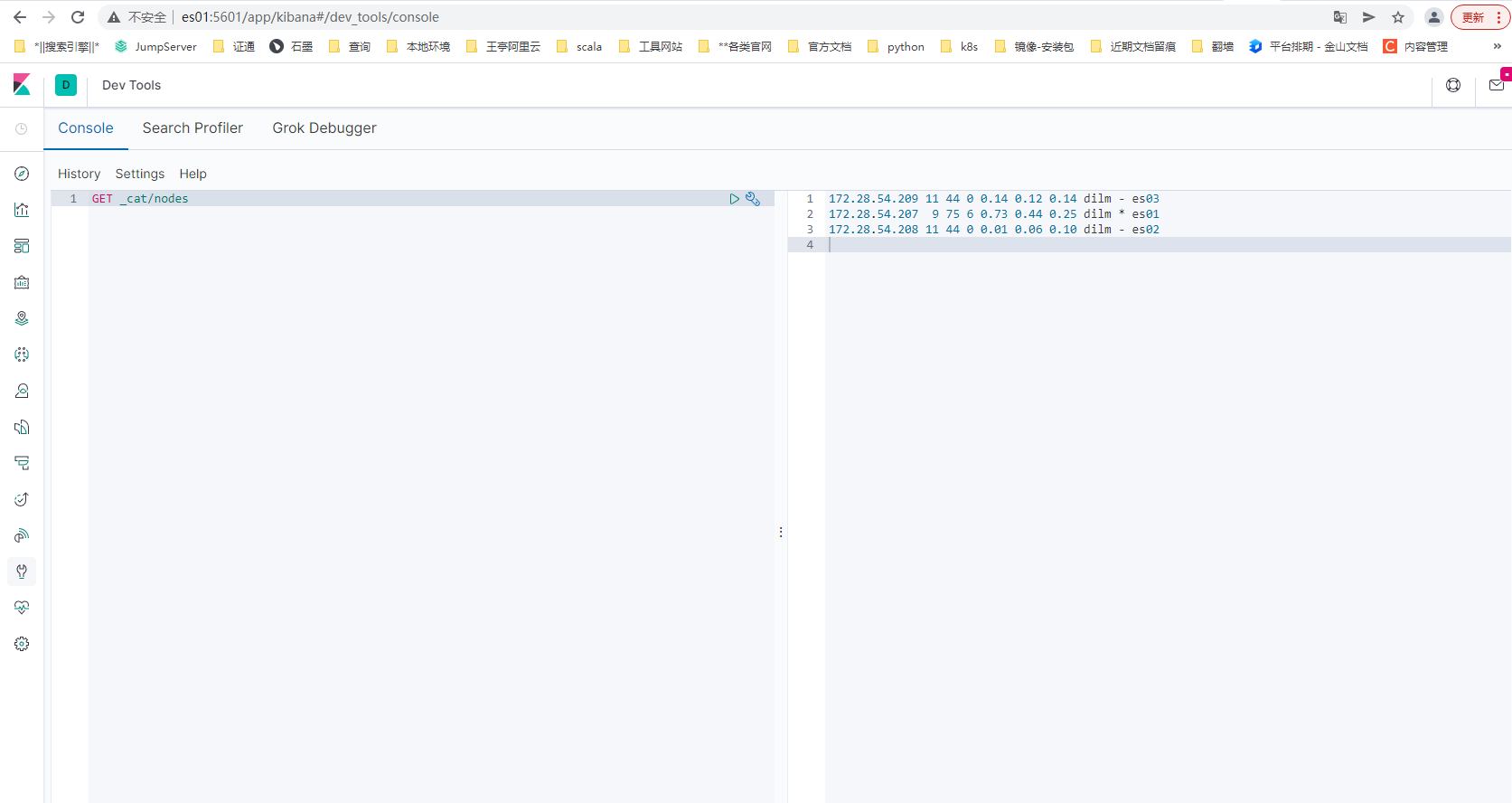
[wangting@es01 config]$ curl http://es01:9200/_cat/nodes
172.28.54.209 10 44 28 0.88 0.33 0.19 dilm - es03
172.28.54.207 11 51 28 0.69 0.26 0.15 dilm * es01
172.28.54.208 9 44 25 0.70 0.25 0.15 dilm - es02
【注意】:正常运行的es集群,curl各个节点nodes状态都是可以返回结果
4-4.安装kibana
kibana功能后续会详细介绍使用,这里提前部署kibana为了测试es方便
# 安装kibana kibana只是一个工具 挑一台服务器安装即可
[wangting@es01 ~]$ tar -xf kibana-7.6.1-linux-x86_64.tar.gz -C /opt/module/
[wangting@es01 ~]$ cd /opt/module/kibana-7.6.1-linux-x86_64/config/
# 配置文件修改2处
[wangting@es01 config]$ vim kibana.yml
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://es01:9200"]
# 启动kibana
[wangting@es01 config]$ cd ..
[wangting@es01 kibana-7.6.1-linux-x86_64]$ nohup bin/kibana &
打开kibana管理页面:http://ip:5601
在哪个节点部署,则使用对应地址+5601端口访问
http://es01:5601/
4-5.安装Elasticsearch-head插件
- 为了更好的查看索引库当中的信息,我们可以通过安装elasticsearch-head这个插件来实现,这个插件可以更方便快捷的看到es的管理界面
- elasticsearch-head这个插件是es提供的一个用于图形化界面查看的一个插件工具,可以安装上这个插件之后,通过这个插件来实现我们通过浏览器查看es当中的数据
- 安装elasticsearch-head插件,需要先安装Node.js
- 安装elasticsearch-head这个插件这里提供两种方式进行安装
- 下载源码包进行编译安装(下载资源较大且均为外网耗时较大)
- 使用编译好的安装包,进行修改配置启动
4-5-1.安装nodejs
# 下载安装包
[wangting@es01 ~]$ wget https://npm.taobao.org/mirrors/node/v8.1.0/node-v8.1.0-linux-x64.tar.gz
# 解压安装
[wangting@es01 ~]$ tar -xf node-v8.1.0-linux-x64.tar.gz -C /opt/module/
# 可执行文件创建软连接
[wangting@es01 ~]$ sudo ln -s /opt/module/node-v8.1.0-linux-x64/lib/node_modules/npm/bin/npm-cli.js /usr/local/bin/npm
[wangting@es01 ~]$ sudo ln -s /opt/module/node-v8.1.0-linux-x64/bin/node /usr/local/bin/node
# 修改环境变量
[wangting@es01 ~]$ sudo vim /etc/profile
# Node
export NODE_HOME=/opt/module/node-v8.1.0-linux-x64
export PATH=:$PATH:$NODE_HOME/bin
# 验证安装是否成功
[wangting@es01 ~]$ node -v
v8.1.0
[wangting@es01 ~]$ npm -v
5.0.3
4-5-2.本地安装elasticsearch-head
本文章所有相关组件安装包以及素材均分享在云盘:
链接:https://pan.baidu.com/s/1NI9vDPNZHJkqzNevwZFOmw?pwd=54lg
提取码:54lg
# 将下载的elasticsearch-head-compile-after.tar.gz解压
[wangting@es01 ~]$ tar -xf elasticsearch-head-compile-after.tar.gz -C /opt/module/
# 修改Gruntfile.js配置
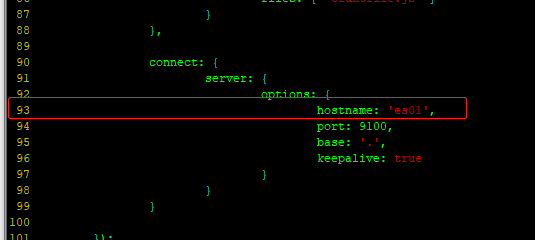
[wangting@es01 ~]$ cd /opt/module/elasticsearch-head/
[wangting@es01 elasticsearch-head]$ vim Gruntfile.js
# 找到93行的 hostname: 'es01',
修改app.js配置文件
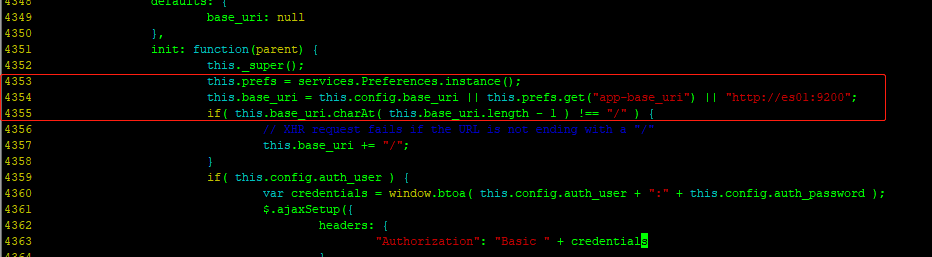
[wangting@es01 elasticsearch-head]$ cd _site/
[wangting@es01 _site]$ vim app.js
# 修改4354行,localhost改成对应自己环境的主机
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://es01:9200";
在vim编辑器中可以:4354直接跳到对应行
4-5-3.启动head服务
# 启动
[wangting@es01 _site]$ cd /opt/module/elasticsearch-head/node_modules/grunt/bin/
[wangting@es01 bin]$ nohup ./grunt server &
# 查看日志
[wangting@es01 bin]$ tail -f nohup.out
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://es01:9100
停止服务可以根据9100端口查询到进程kill -9 进程号
netstat -nltp | grep 9100
kill -9 进程号
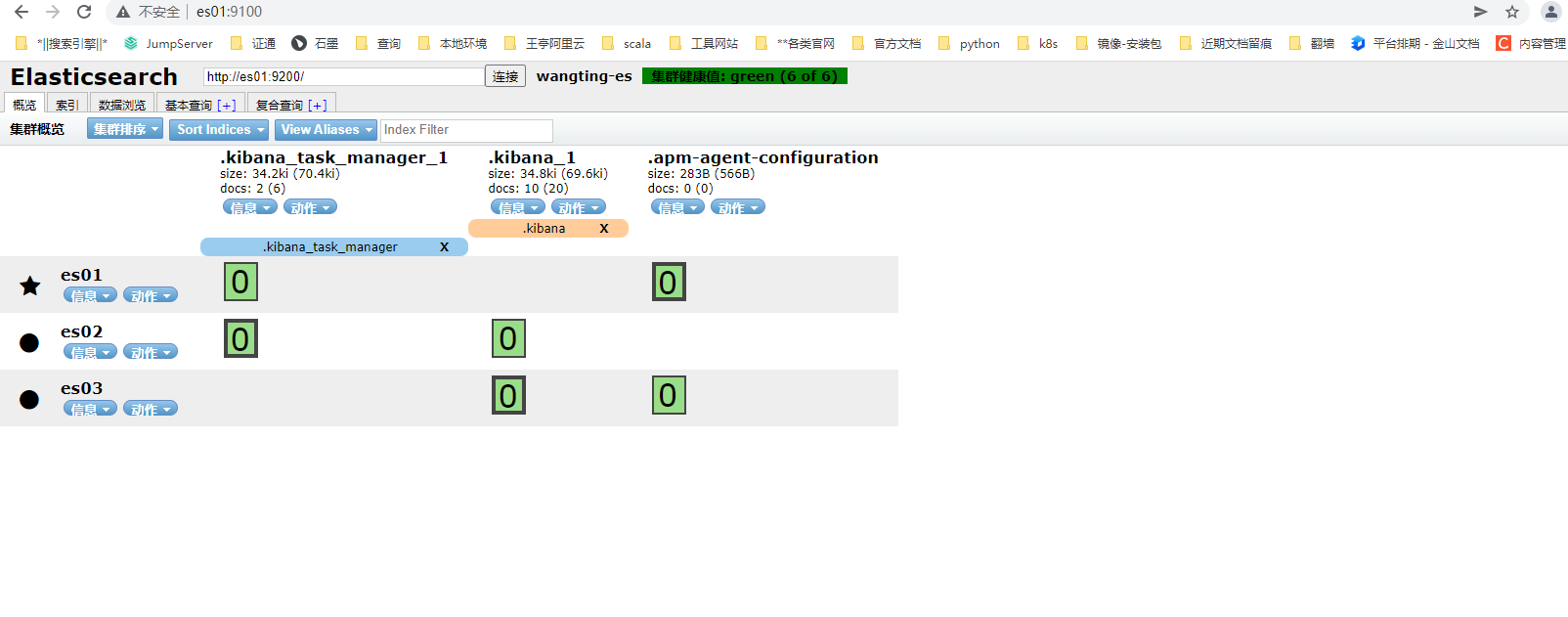
4-5-4.页面验证服务
机器ip加9100端口
4-6.安装IK分词器
4-6-1.IK分词器安装
IK分词器的github官网:https://github.com/medcl/elasticsearch-analysis-ik/releases
可以直接在云盘中下载安装包
链接:https://pan.baidu.com/s/1NI9vDPNZHJkqzNevwZFOmw?pwd=54lg
提取码:54lg
# 创建插件目录ik
[wangting@es01 ~]$ mkdir -p /opt/module/elasticsearch-7.6.1/plugins/ik
# 拷贝插件包
[wangting@es01 ~]$ cp elasticsearch-analysis-ik-7.6.1.zip /opt/module/elasticsearch-7.6.1/plugins/ik/
[wangting@es01 ~]$ cd /opt/module/elasticsearch-7.6.1/plugins/ik
[wangting@es01 ik]$ ls
elasticsearch-analysis-ik-7.6.1.zip
# 解压
[wangting@es01 ik]$ unzip elasticsearch-analysis-ik-7.6.1.zip
# 删除原压缩包
[wangting@es01 ik]$ rm -f elasticsearch-analysis-ik-7.6.1.zip
[wangting@es01 ik]$ cd ..
# 分发
[wangting@es01 plugins]$ scp -r ik es02:$PWD
[wangting@es01 plugins]$ scp -r ik es03:$PWD
插件需要重启加载生效,重启elasticsearch
# 杀掉进程
[wangting@es01 plugins]$ ps -ef | grep elasticsearch
[wangting@es01 plugins]$ kill -9 12637
# 启动服务
[wangting@es01 plugins]$ /opt/module/elasticsearch-7.6.1/bin/elasticsearch -d
4-6-2.测试验证IK分词器
查看原始的Standard标准分词器效果:
POST _analyze
{
"analyzer":"standard",
"text":"我爱你中国"
}
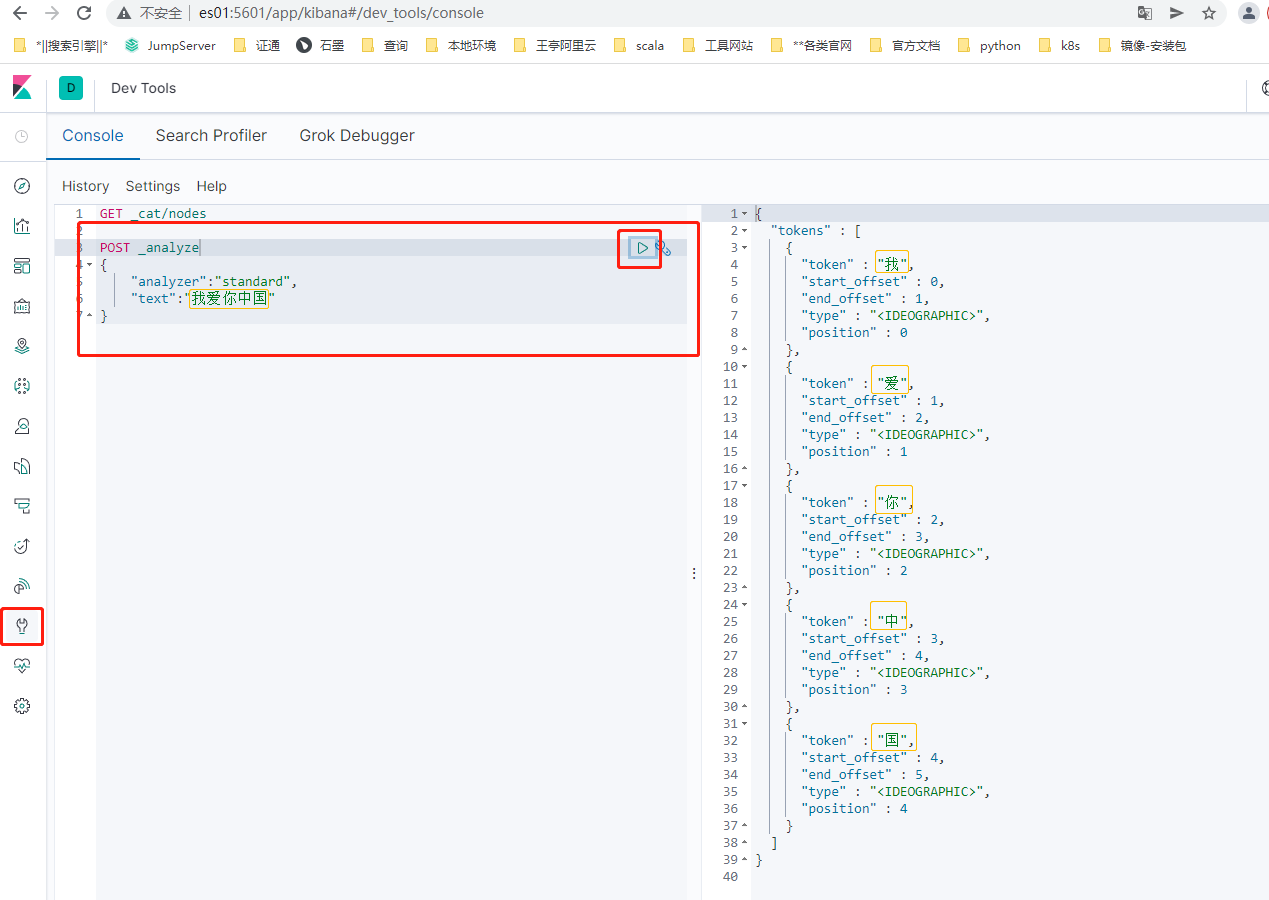
Standard标准分词器,是一个个将文字切分,效果欠佳不理想
查看使用IK分词器效果
POST _analyze
{
"analyzer":"ik_max_word",
"text":"我爱你中国"
}
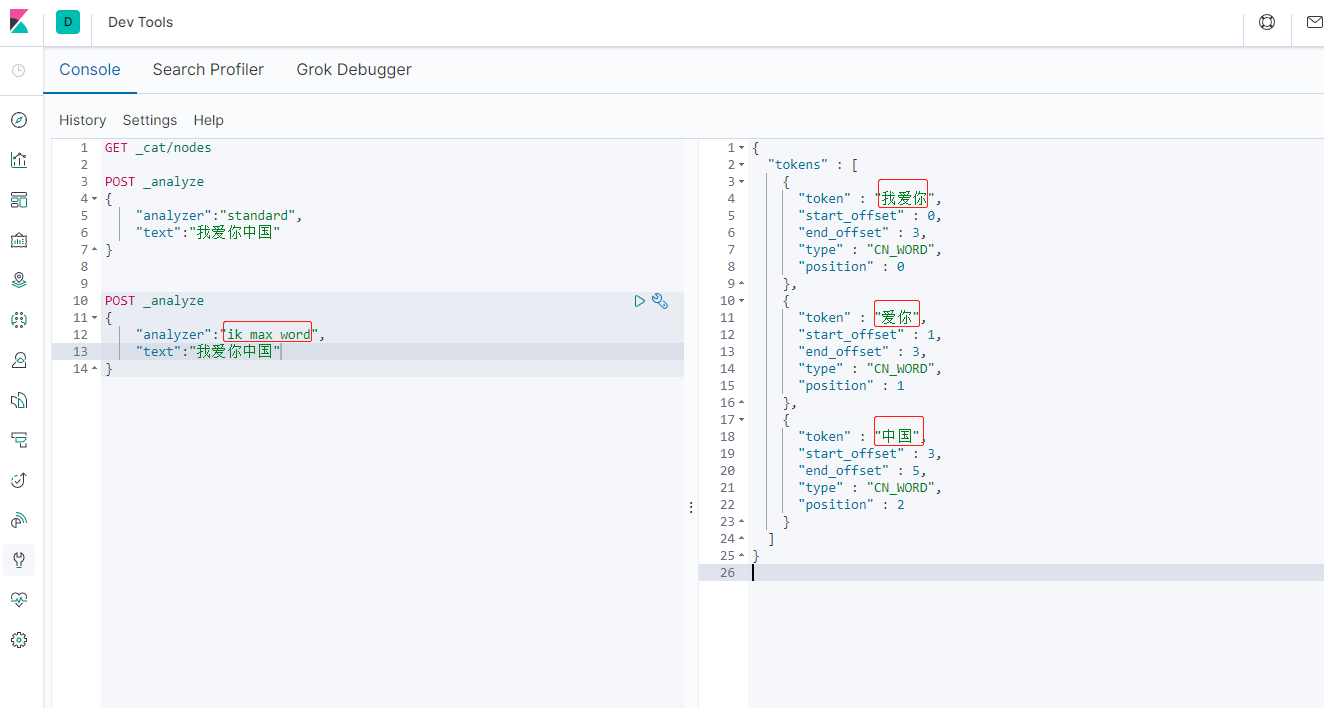
IK分词器,可以将词语完整的切分
4-7.安装部署汇总
# es节点的信息情况URL:
http://es01:9200/
# kibana看板URL:
http://es01:5601/
# elasticsearch-head管理界面工具URL:
http://es01:9100/
windows机器的浏览器地址如果输入主机名打开,则需要将windows的hosts文件中加上解析ip,否则可以直接使用IP浏览
第5章.Elasticsearch案例全流程实践
Elasticsearch案例全流程实践通过一个完整的案例,来实践全部的es常见操作
5-1.需求
背景:
本次案例,要实现一个类似于猎聘网的案例,用户通过搜索相关的职位关键字,就可以搜索到相关的工作岗位。我们已经提前准备好了一些数据,这些数据是通过爬虫爬取的数据,这些数据存储在CSV文本文件中。我们需要基于这些数据建立索引,供用户搜索查询
为测试更加直观,操作均在kibana页面上执行,避免命令行各种输出零散
数据集介绍:
| 字段名 | 说明 | 数据 |
|---|---|---|
| doc_id | 唯一标识(作为文档ID) | 29097 |
| area | 职位所在区域 | 工作地区:深圳-南山区 |
| exp | 岗位要求的工作经验 | 1年经验 |
| edu | 学历要求 | 大专以上 |
| salary | 薪资范围 | ¥ 6-8千/月 |
| job_type | 职位类型(全职/兼职) | 实习 |
| cmp | 公司名 | 乐有家 |
| pv | 浏览量 | 61.6万人浏览过 / 14人评价 / 113人正在关注 |
| title | 岗位名称 | 桃园 深大销售实习 岗前培训 |
| jd | 职位描述 | 【岗位职责】 1.爱学习,有耐心… |
5-2.创建索引
为了能够搜索职位数据,我们需要提前在Elasticsearch中创建索引,然后才能进行关键字的检索。这里先回顾下,我们在MySQL中创建表的过程。在MySQL中,如果我们要创建一个表,我们需要指定表的名字,指定表中有哪些列、列的类型是什么。同样,在Elasticsearch中,也可以使用类似的方式来定义索引。
5-2-1.创建带有映射的索引
Elasticsearch中,我们可以使用RESTful API(http请求)来进行索引的各种操作。创建MySQL表的时候,我们使用DDL来描述表结构、字段、字段类型、约束等。在Elasticsearch中,我们使用Elasticsearch的DSL来定义——使用JSON来描述。
PUT /my-index
{
"mappings": {
"properties" : {
"employee-id": {
"type":"keyword",
"index":false
}
}
}
}
my-index # 索引名称
employee-id # 字段名称
type # 字段类型
index # 是否需要创建索引
5-2-2.字段类型介绍
在Elasticsearch中,每一个字段都有一个类型(type)。以下为Elasticsearch中可以使用的类型:
| 分类 | 类型名称 | 说明 |
|---|---|---|
| 简单类型 | text | 需要进行全文检索的字段,通常使用text类型来对应邮件的正文、产品描述或者短文等非结构化文本数据。分词器先会将文本进行分词转换为词条列表。将来就可以基于词条来进行检索了。文本字段不能用户排序、也很少用户聚合计算。 |
| 简单类型 | keyword | 使用keyword来对应结构化的数据,如ID、电子邮件地址、主机名、状态代码、邮政编码或标签。可以使用keyword来进行排序或聚合计算。注意:keyword是不能进行分词的。 |
| 简单类型 | date | 保存格式化的日期数据,例如:2015-01-01或者2015/01/01 12:10:30。在Elasticsearch中,日期都将以字符串方式展示。可以给date指定格式:”format”: “yyyy-MM-dd HH:mm:ss” |
| 简单类型 | long/integer/short/byte | 64位整数/32位整数/16位整数/8位整数 |
| 简单类型 | double/float/half_float | 64位双精度浮点/32位单精度浮点/16位半进度浮点 |
| 简单类型 | boolean | “true”/”false” |
| 简单类型 | ip | IPV4(192.168.1.110)/IPV6(192.168.0.0/16) |
| JSON分层嵌套类型 | object | 用于保存JSON对象 |
| JSON分层嵌套类型 | nested | 用于保存JSON数组 |
| 特殊类型 | geo_point | 用于保存经纬度坐标 |
| 特殊类型 | geo_shape | 用于保存地图上的多边形坐标 |
5-2-3.创建保存职位信息的索引
-
使用PUT发送PUT请求
-
索引名为 /job_idx
-
判断是使用text、还是keyword,主要就看是否需要分词
| 字段 | 类型 |
|---|---|
| area | text |
| exp | text |
| edu | keyword |
| salary | keyword |
| job_type | keyword |
| cmp | text |
| pv | keyword |
| title | text |
| jd | text |
创建索引:
PUT /job_idx
{
"mappings": {
"properties" : {
"area": {
"type": "text", "store": true},
"exp": {
"type": "text", "store": true},
"edu": {
"type": "keyword", "store": true},
"salary": {
"type": "keyword", "store": true},
"job_type": {
"type": "keyword", "store": true},
"cmp": {
"type": "text", "store": true},
"pv": {
"type": "keyword", "store": true},
"title": {
"type": "text", "store": true},
"jd": {
"type": "text", "store": true}
}
}
}
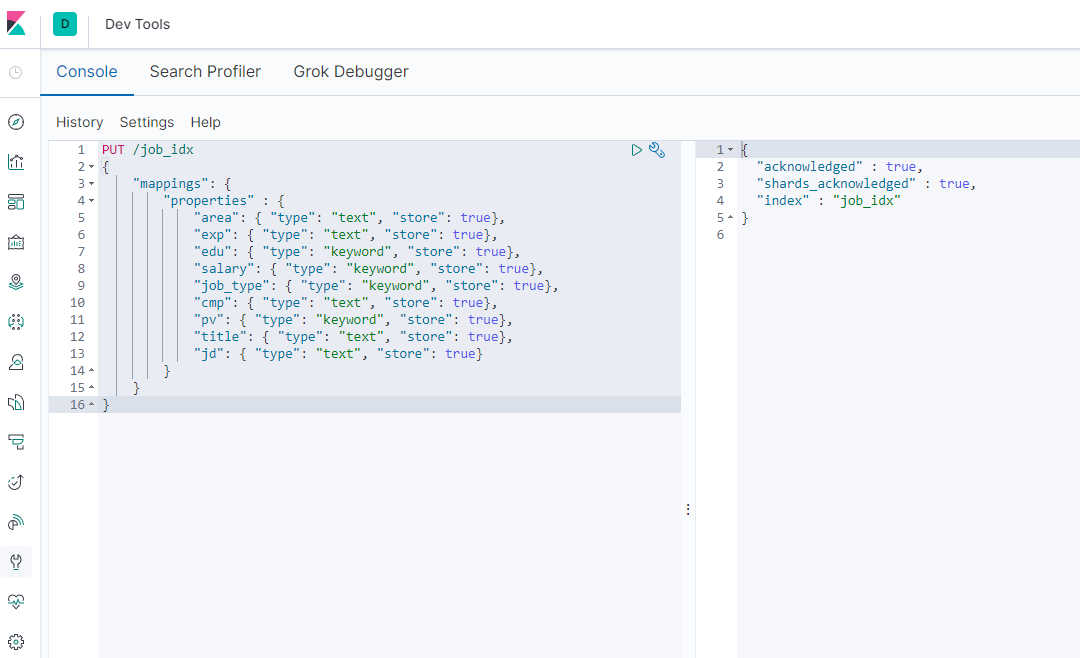
5-2-4.查看索引映射
// 查看索引映射
GET /job_idx/_mapping
{
"job_idx" : {
"mappings" : {
"properties" : {
"area" : {
"type" : "text",
"store" : true
},
"cmp" : {
"type" : "text",
"store" : true
},
"edu" : {
"type" : "keyword",
"store" : true
},
"exp" : {
"type" : "text",
"store" : true
},
"jd" : {
"type" : "text",
"store" : true
},
"job_type" : {
"type" : "keyword",
"store" : true
},
"pv" : {
"type" : "keyword",
"store" : true
},
"salary" : {
"type" : "keyword",
"store" : true
},
"title" : {
"type" : "text",
"store" : true
}
}
}
}
}
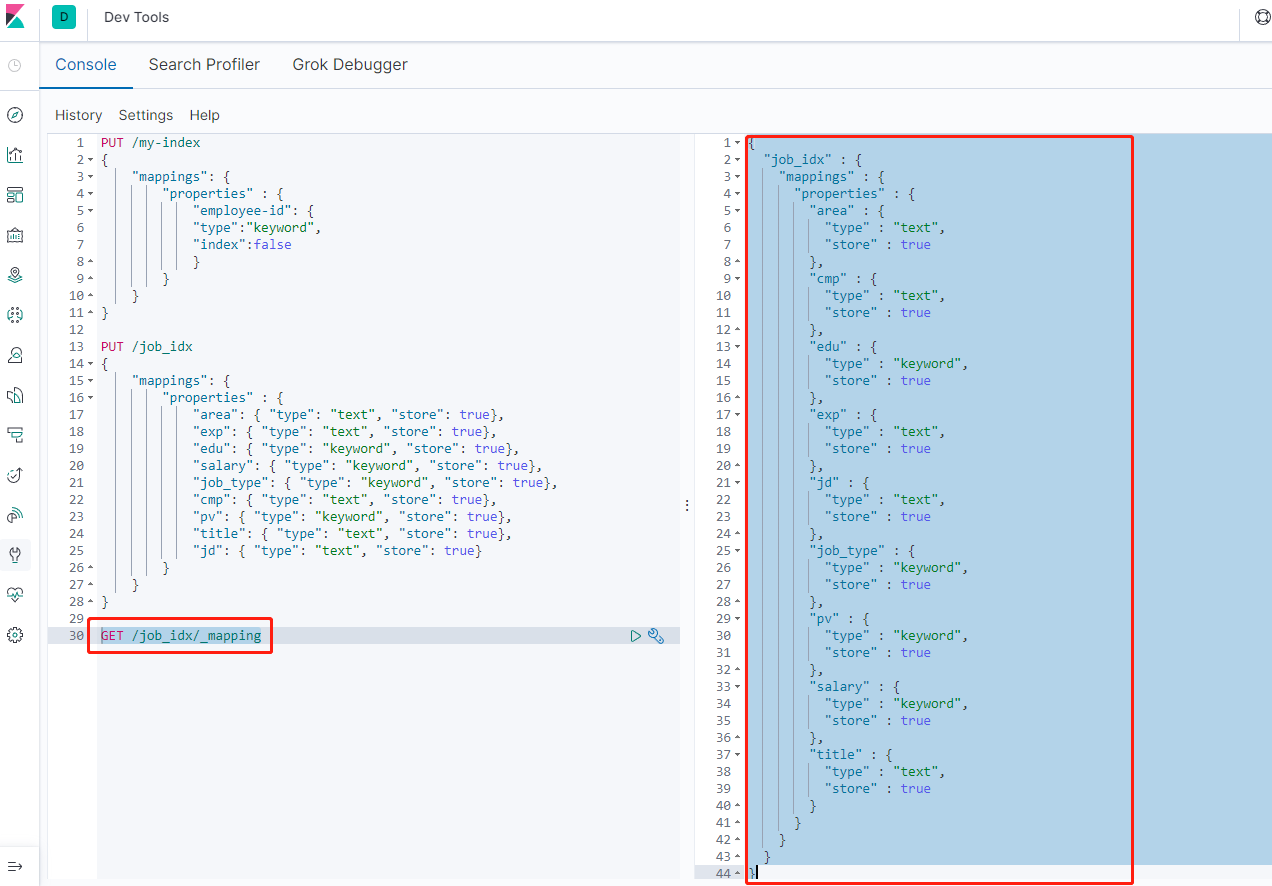
使用elasticsearch-head查看索引映射
5-2-5.查看集群中所有索引信息
// 查看所有的索引
GET _cat/indices
green open .kibana_task_manager_1 _rknRBEpRve8Npx8AxYcYA 1 1 2 0 55.7kb 35.5kb
green open my-index zuED2iEhTo6z7F_2UcW7UA 1 1 0 0 566b 283b
green open .apm-agent-configuration NvxyGE9ESCOLY75m8Oo8Hw 1 1 0 0 566b 283b
green open job_idx MwMb0bb3QkWQAy6qvZvI_A 1 1 0 0 566b 283b
green open .kibana_1 -qOYtk3GQem2ocvLL0m-bw 1 1 13 3 49.2kb 24.6kb
5-2-6.删除索引
// 删除索引
delete /job_idx
{
"acknowledged" : true
}
5-2-7.指定使用IK分词器创建索引
因为存放在索引库中的数据,是以中文的形式存储的。所以,为了有更好地分词效果,我们需要使用IK分词器来进行分词。这样,将来搜索的时候才会更准确
PUT /job_idx
{
"mappings": {
"properties" : {
"area": {
"type": "text", "store": true, "analyzer": "ik_max_word"},
"exp": {
"type": "text", "store": true, "analyzer": "ik_max_word"},
"edu": {
"type": "keyword", "store": true},
"salary": {
"type": "keyword", "store": true},
"job_type": {
"type": "keyword", "store": true},
"cmp": {
"type": "text", "store": true, "analyzer": "ik_max_word"},
"pv": {
"type": "keyword", "store": true},
"title": {
"type": "text", "store": true, "analyzer": "ik_max_word"},
"jd": {
"type": "text", "store": true, "analyzer": "ik_max_word"}
}
}
}
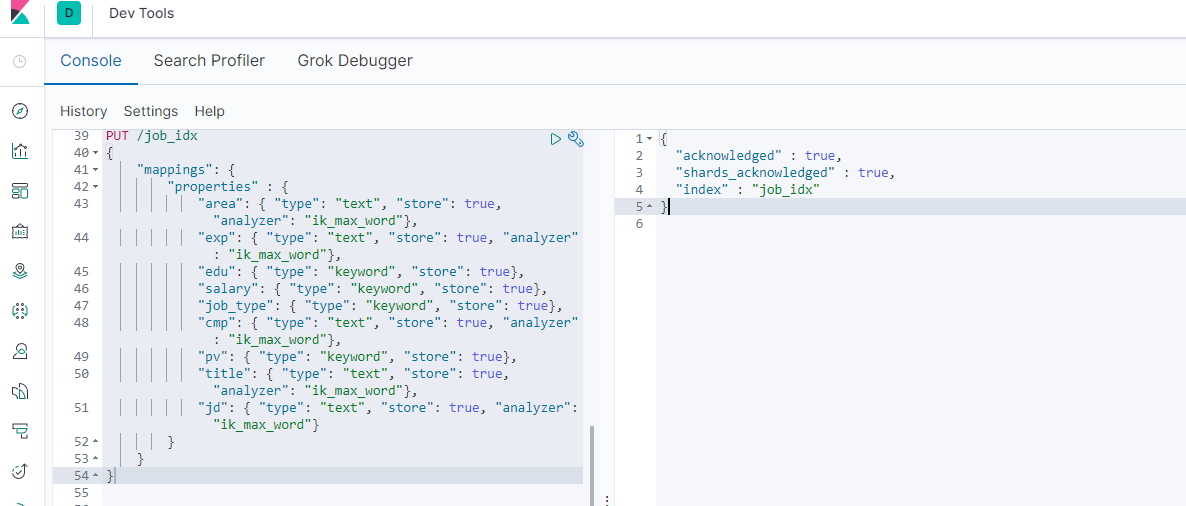
5-3.PUT数据
5-3-1.需求
背景:
我们现在有一条职位数据,需要添加到Elasticsearch中,后续还需要能够在Elasticsearch中搜索这些数据
5-3-2.PUT请求
可以通过PUT请求直接完成PUT数据操作。在Elasticsearch中,每一个文档都有唯一的ID。也是使用JSON格式来描述数据
PUT /job_idx/_doc/29097
“area”: “深圳-南山区”
- job_idx 索引名称
- 29097 文档编号
- “area”: “深圳-南山区” 字段数据
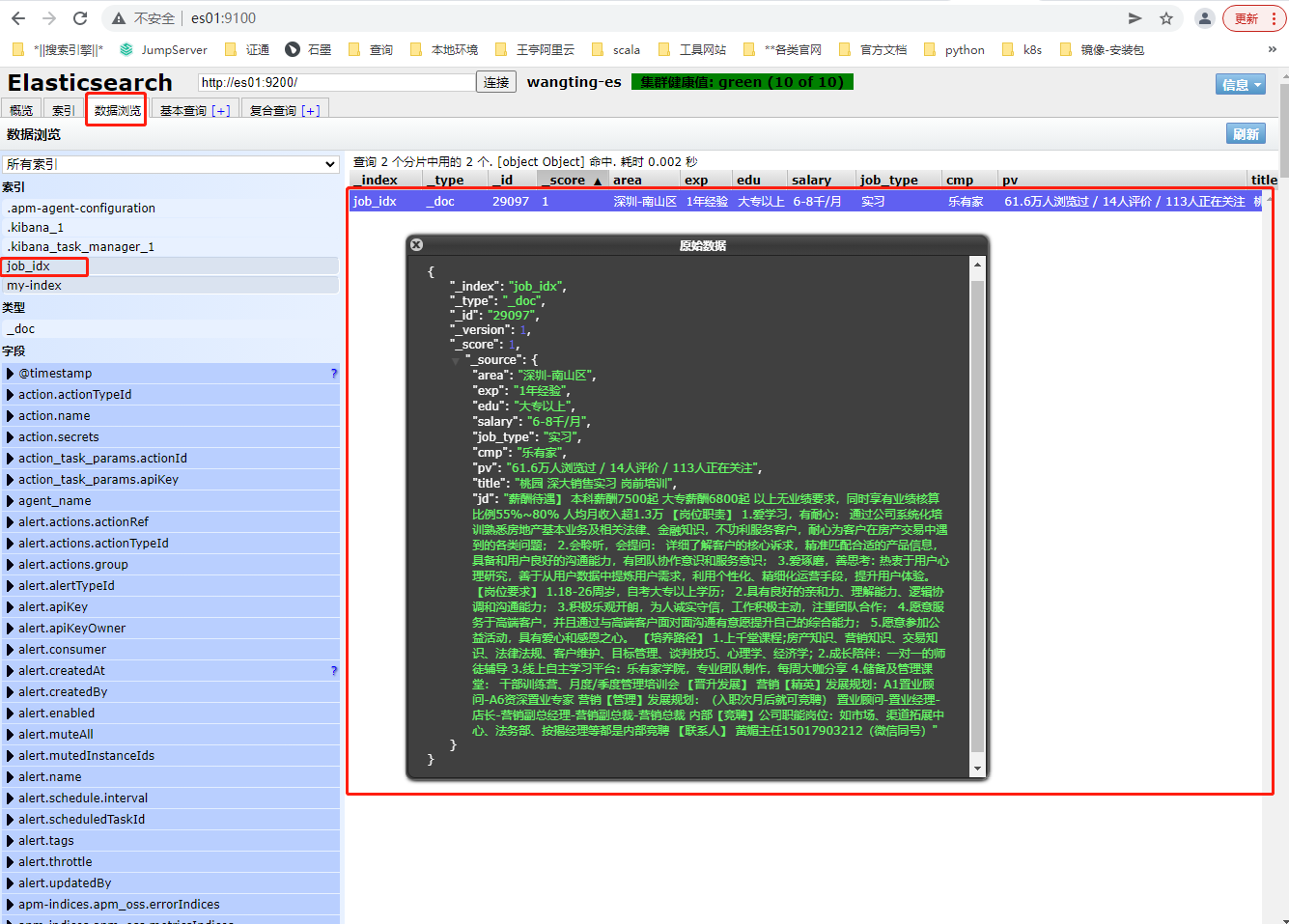
5-3-3.添加职位信息请求
在job_idx索引中添加一条职位信息数据
// 新增一条数据
PUT /job_idx/_doc/29097
{
"area": "深圳-南山区",
"exp": "1年经验",
"edu": "大专以上",
"salary": "6-8千/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "61.6万人浏览过 / 14人评价 / 113人正在关注",
"title": "桃园 深大销售实习 岗前培训",
"jd": "薪酬待遇】 本科薪酬7500起 大专薪酬6800起 以上无业绩要求,同时享有业绩核算比例55%~80% 人均月收入超1.3万 【岗位职责】 1.爱学习,有耐心: 通过公司系统化培训熟悉房地产基本业务及相关法律、金融知识,不功利服务客户,耐心为客户在房产交易中遇到的各类问题; 2.会聆听,会提问: 详细了解客户的核心诉求,精准匹配合适的产品信息,具备和用户良好的沟通能力,有团队协作意识和服务意识; 3.爱琢磨,善思考: 热衷于用户心理研究,善于从用户数据中提炼用户需求,利用个性化、精细化运营手段,提升用户体验。 【岗位要求】 1.18-26周岁,自考大专以上学历; 2.具有良好的亲和力、理解能力、逻辑协调和沟通能力; 3.积极乐观开朗,为人诚实守信,工作积极主动,注重团队合作; 4.愿意服务于高端客户,并且通过与高端客户面对面沟通有意愿提升自己的综合能力; 5.愿意参加公益活动,具有爱心和感恩之心。 【培养路径】 1.上千堂课程;房产知识、营销知识、交易知识、法律法规、客户维护、目标管理、谈判技巧、心理学、经济学; 2.成长陪伴:一对一的师徒辅导 3.线上自主学习平台:乐有家学院,专业团队制作,每周大咖分享 4.储备及管理课堂: 干部训练营、月度/季度管理培训会 【晋升发展】 营销【精英】发展规划:A1置业顾问-A6资深置业专家 营销【管理】发展规划:(入职次月后就可竞聘) 置业顾问-置业经理-店长-营销副总经理-营销副总裁-营销总裁 内部【竞聘】公司职能岗位:如市场、渠道拓展中心、法务部、按揭经理等都是内部竞聘 【联系人】 黄媚主任15017903212(微信同号)"
}
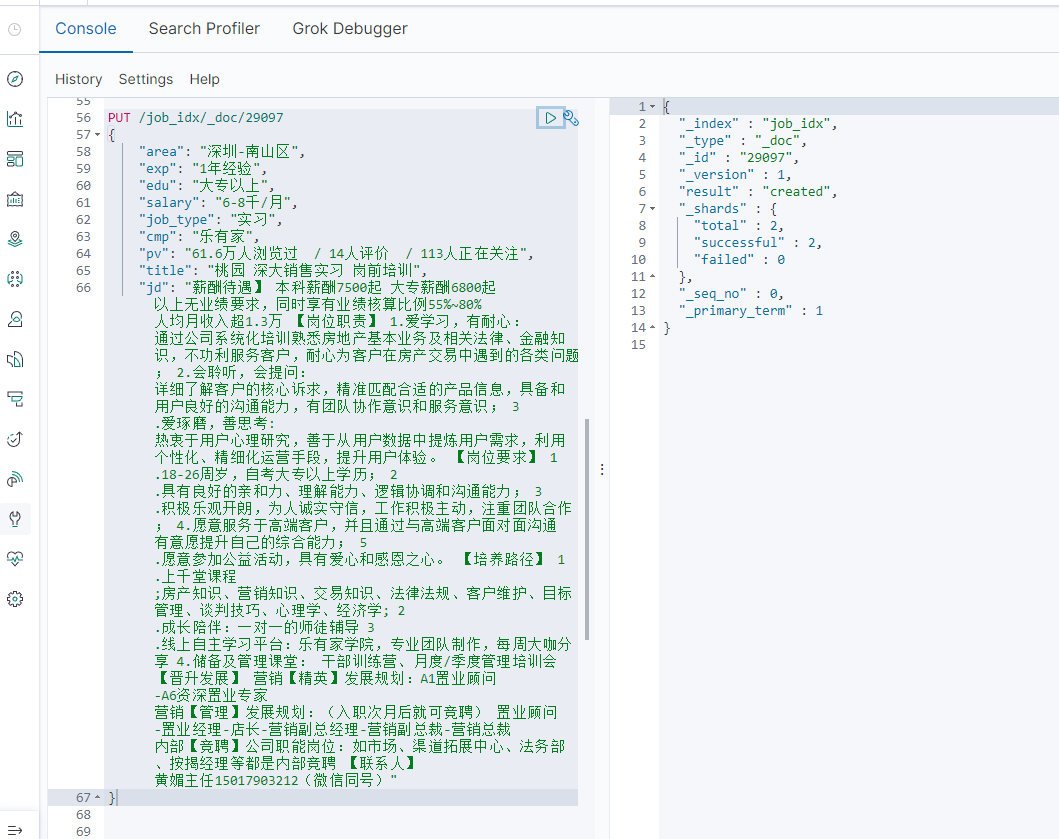
通过head界面查看PUT的数据:
5-4.update修改数据
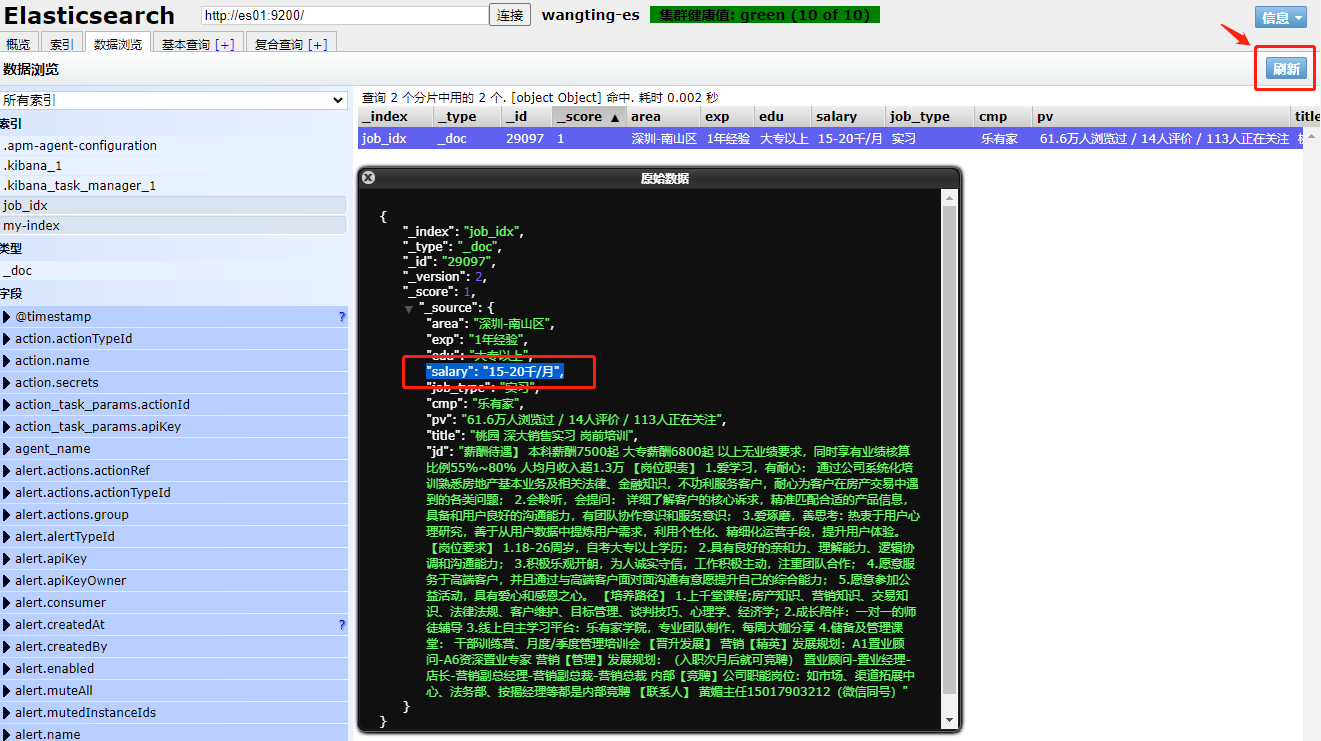
5-4-1.需求
背景:将原有PUT的数据中,薪资6-8千/月,修改为15-20千/月
5-4-2.执行update操作
// 更新指定文档的某个字段的数据
POST /job_idx/_update/29097
{
"doc": {
"salary": "15-20千/月"
}
}
5-5.delete删除数据
5-5-1.需求
背景:在索引库中删除ID为29097的职位岗位
5-5-2.执行delete操作
// 删除ES索引中的文档
DELETE /job_idx/_doc/29097
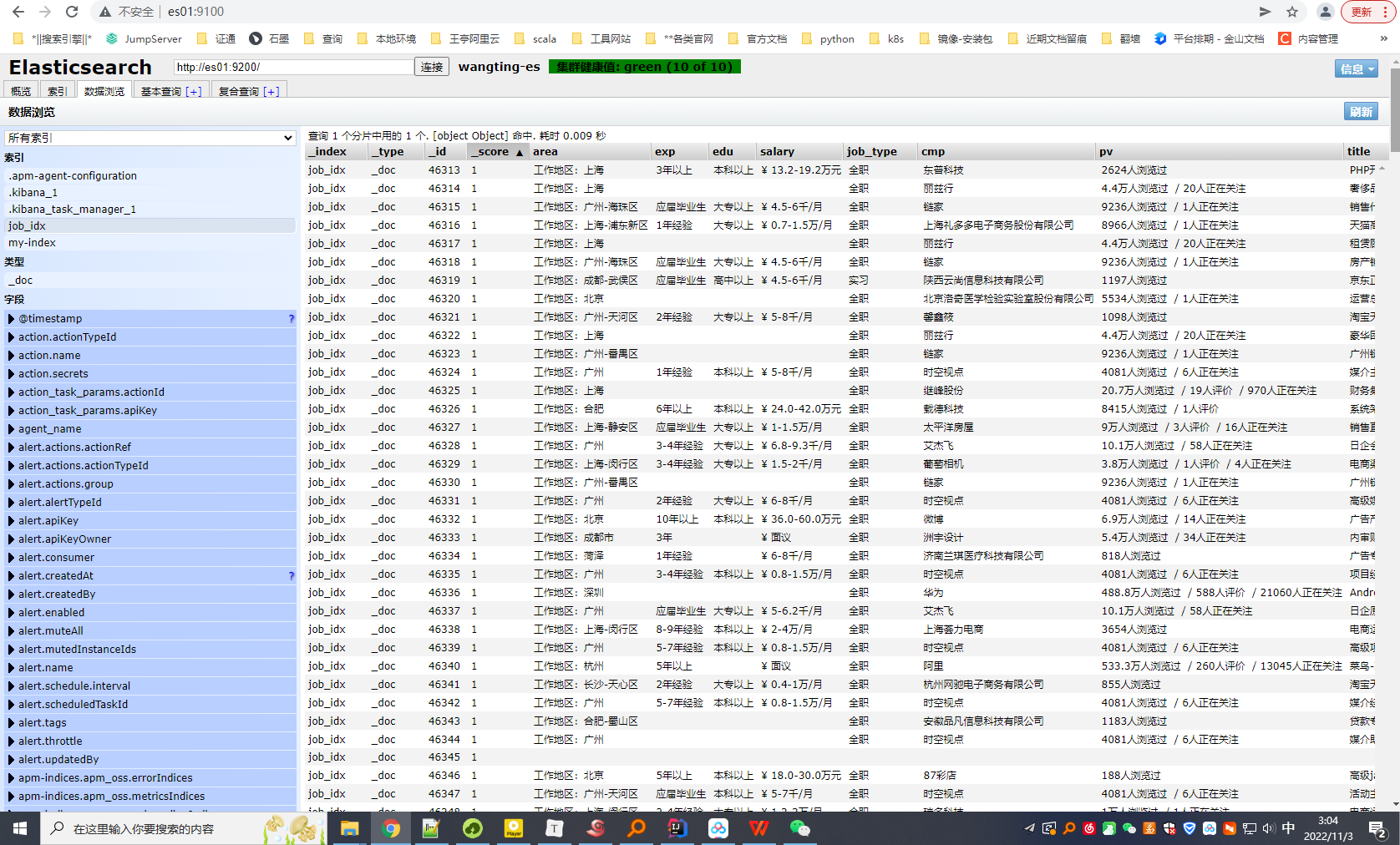
5-6.批量导入json数据
bulk导入
现有一个job_info.json数据文件,我们可以使用Elasticsearch中自带的bulk接口来进行数据导入
job_info.json上传至网盘
链接:https://pan.baidu.com/s/1NI9vDPNZHJkqzNevwZFOmw?pwd=54lg
提取码:54lg
[wangting@es01 ~]$ ll | grep job_info
-rw-r--r-- 1 wangting wangting 10565056 Nov 3 2020 job_info.json
[wangting@es01 ~]$ curl -H "Content-Type: application/json" -X POST "es01:9200/job_idx/_bulk?pretty&refresh" --data-binary @job_info.json
导数后查看索引状态
// 查看索引状态
GET _cat/indices?index=job_idx
green open job_idx kYjGiwo6Q9WmU9Ts75syZg 1 1 6764 0 23.2mb 11.6mb
head界面查看数据导入是否成功
5-7.根据ID检索数据
5-7-1.需求
用户提交一个文档ID,Elasticsearch将ID对应的文档直接返回给用户
5-7-2.实现
在Elasticsearch中,可以通过发送GET请求来实现文档的查询
// 查询指定ID的文档
GET /job_idx/_search
{
"query": {
"ids": {
"values": ["46313"]
}
}
}

5-8.根据关键字检索数据
5-8-1.需求
搜索职位中带有「销售」关键字的职位
5-8-2.实现
检索jd中销售相关的岗位
// 关键字检索
GET /job_idx/_search
{
"query": {
"match": {
"jd": "销售"
}
}
}
多个关键字组合查询,查询职位描述和岗位名称2个字段中都包含“销售”数据
GET /job_idx/_search
{
"query": {
"multi_match": {
"query": "销售",
"fields" : ["jd", "title"]
}
}
}
5-9.根据关键字分页搜索
5-9-1.需求
背景:
在存在大量数据时,一般我们进行查询都需要进行分页查询。例如:我们指定页码、并指定每页显示多少条数据,然后Elasticsearch返回对应页码的数据
5-9-2.分页实现
使用from和size来进行分页,在执行查询时,可以指定from(从第几条数据开始查起)和size(每页返回多少条)数据,就可以轻松完成分页
from = (page – 1) * size
// 分页查询
GET /job_idx/_search
{
"from": 10,
"size": 5,
"query": {
"multi_match": {
"query": "销售",
"fields": ["title", "jd"]
}
}
}
5-9-3.使用scroll方式进行分页
上面使用from和size方式,如果数据非常多的时候,会出现性能问题。Elasticsearch做了一个限制,不允许查询的是10000条以后的数据。如果要查询一万条以后的数据,需要使用Elasticsearch中提供的scroll游标来查询。
在进行大量分页时,每次分页都需要将要查询的数据进行重新排序,这样非常浪费性能。使用scroll是将要用的数据一次性排序好,然后分批取出。性能要比from + size好得多。使用scroll查询后,排序后的数据会保持一定的时间,后续的分页查询都从该快照取数据即可。
- 第一次使用scroll分页查询
scroll=1m表示让排序的数据保持1分钟有效期
// 使用ES的scroll分页查询
GET /job_idx/_search?scroll=1m
{
"query": {
"multi_match": {
"query": "销售",
"fields": ["title", "jd"]
}
},
"size": 100
}
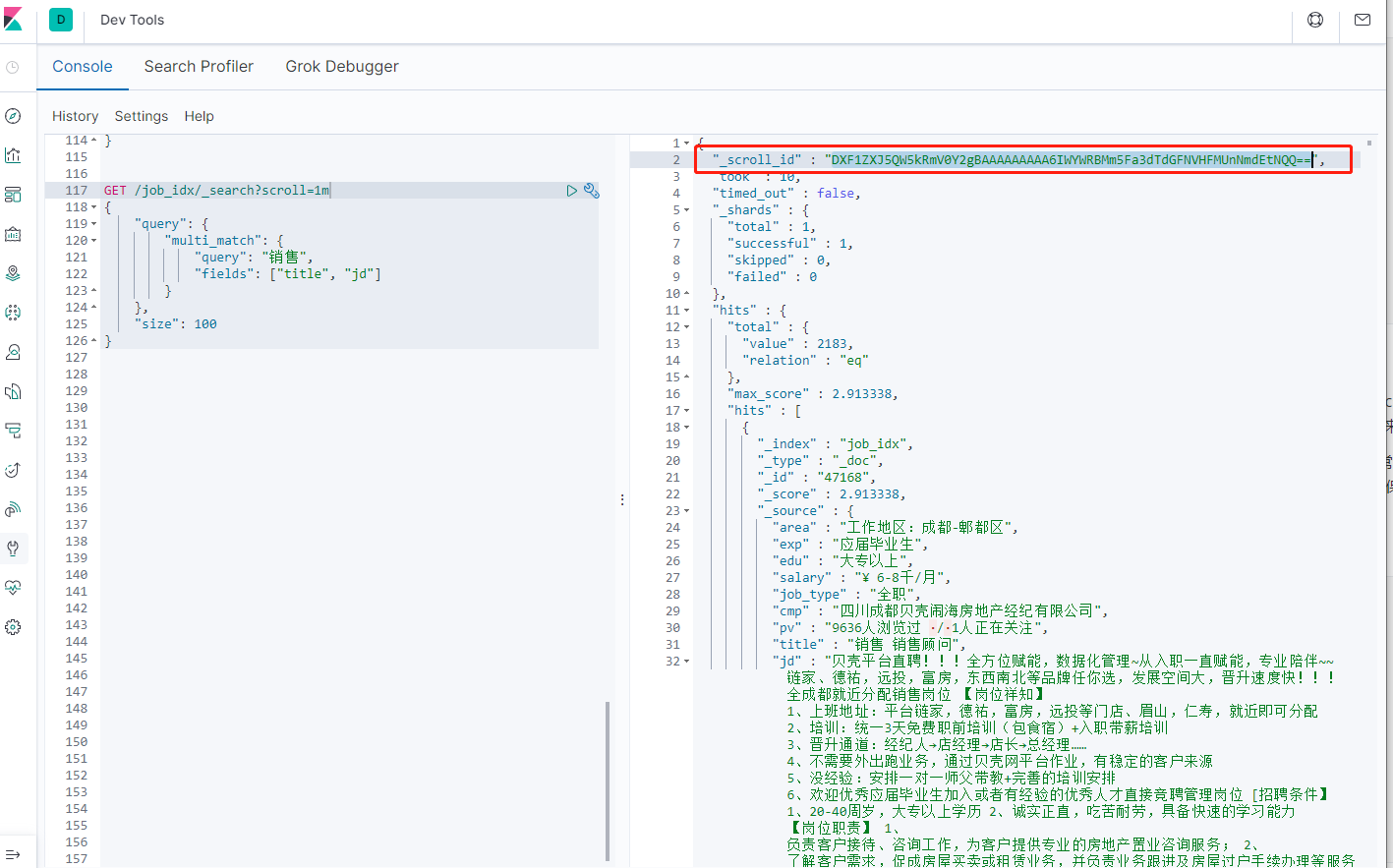
从执行结果中可以获取到_scroll_id
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAA6IWYWRBMm5Fa3dTdGFNVHFMUnNmdEtNQQ=="
第二次查询需要基于scroll_id来查询接下来的分页数据
- 第二次直接使用scroll id进行查询
GET _search/scroll?scroll=1m
{
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAA6IWYWRBMm5Fa3dTdGFNVHFMUnNmdEtNQQ=="
}
第6章.Elasticsearch开发编程
在之前创建的Maven项目:es_2022下,创建一个module模块:elasticsearch_example
GroupId:cn.wangting
ArtifactId:elasticsearch_example
创建包:
cn.wangting.entity
cn.wangting.service
cn.wangting.service.impl
- pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>es_2022</artifactId>
<groupId>cn.wangting</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>elasticsearch_example</artifactId>
<repositories><!-- 代码库 -->
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
</repository>
<repository>
<id>elastic.co</id>
<url>https://artifacts.elastic.co/maven</url>
</repository>
</repositories>
<dependencies>
<!-- ES的高阶的客户端API -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
<!-- 阿里巴巴出品的一款将Java对象转换为JSON、将JSON转换为Java对象的库 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
<!-- ES SQL驱动 -->
<dependency>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>x-pack-sql-jdbc</artifactId>
<version>7.6.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<target>1.8</target>
<source>1.8</source>
</configuration>
</plugin>
</plugins>
</build>
</project>
可以正常控制台输出,则环境依赖等正常
- 创建用于保存职位信息的实体类
cn.wangting.elasticsearch.entity包下创建JobDetail类:
package cn.wangting.elasticsearch.entity;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.annotation.JSONField;
public class JobDetail {
@JSONField(serialize = false)
private long id;
private String area;
private String exp;
private String edu;
private String salary;
private String job_type;
private String cmp;
private String pv;
private String title;
private String jd;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getArea() {
return area;
}
public void setArea(String area) {
this.area = area;
}
public String getExp() {
return exp;
}
public void setExp(String exp) {
this.exp = exp;
}
public String getEdu() {
return edu;
}
public void setEdu(String edu) {
this.edu = edu;
}
public String getSalary() {
return salary;
}
public void setSalary(String salary) {
this.salary = salary;
}
public String getJob_type() {
return job_type;
}
public void setJob_type(String job_type) {
this.job_type = job_type;
}
public String getCmp() {
return cmp;
}
public void setCmp(String cmp) {
this.cmp = cmp;
}
public String getPv() {
return pv;
}
public void setPv(String pv) {
this.pv = pv;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getJd() {
return jd;
}
public void setJd(String jd) {
this.jd = jd;
}
@Override
public String toString() {
return id + ":" + JSONObject.toJSONString(this);
}
}
- 编写接口和实现类
cn.wangting.elasticsearch.service包下创建JobFullTextService类
JobFullTextService接口
package cn.wangting.elasticsearch.service;
import cn.wangting.elasticsearch.entity.JobDetail;
import java.io.IOException;
import java.util.List;
import java.util.Map;
// 定义一些数据操作的接口
public interface JobFullTextService {
// 添加一个职位数据
void add(JobDetail jobDetail) throws IOException;
// 根据ID检索指定职位数据
JobDetail findById(long id) throws IOException;
// 修改职位薪资
void update(JobDetail jobDetail) throws IOException;
// 根据ID删除指定位置数据
void deleteById(long id) throws IOException;
// 根据关键字检索数据
List<JobDetail> searchByKeywords(String keywords) throws IOException;
// 分页检索
Map<String, Object> searchByPage(String keywords, int pageNum, int pageSize) throws IOException;
// scroll分页解决深分页问题
Map<String, Object> searchByScrollPage(String keywords, String scrollId, int pageSize) throws IOException;
// 关闭ES连接
void close() throws IOException;
}
实现类
cn.wangting.elasticsearch.service.impl包下创建JobFullTextServiceImpl实现类
JobFullTextServiceImpl:各类数据操作的代码示例汇总
package cn.wangting.elasticsearch.service.impl;
import cn.wangting.elasticsearch.entity.JobDetail;
import cn.wangting.elasticsearch.service.JobFullTextService;
import com.alibaba.fastjson.JSONObject;
import org.apache.http.HttpHost;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.SearchScrollRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MultiMatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class JobFullTextServiceImpl implements JobFullTextService {
private RestHighLevelClient restHighLevelClient;
// 索引库的名字
private static final String JOB_IDX = "job_idx";
public JobFullTextServiceImpl() {
// 建立与ES的连接
// 1. 使用RestHighLevelClient构建客户端连接。
// 2. 基于RestClient.builder方法来构建RestClientBuilder
// 3. 用HttpHost来添加ES的节点
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost("es01", 9200, "http")
, new HttpHost("es02", 9200, "http")
, new HttpHost("es03", 9200, "http"));
restHighLevelClient = new RestHighLevelClient(restClientBuilder);
}
@Override
public void add(JobDetail jobDetail) throws IOException {
//1. 构建IndexRequest对象,用来描述ES发起请求的数据。
IndexRequest indexRequest = new IndexRequest(JOB_IDX);
//2. 设置文档ID。
indexRequest.id(jobDetail.getId() + "");
//3. 使用FastJSON将实体类对象转换为JSON。
String json = JSONObject.toJSONString(jobDetail);
//4. 使用IndexRequest.source方法设置文档数据,并设置请求的数据为JSON格式。
indexRequest.source(json, XContentType.JSON);
//5. 使用ES High level client调用index方法发起请求,将一个文档添加到索引中。
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
}
@Override
public JobDetail findById(long id) throws IOException {
// 1. 构建GetRequest请求。
GetRequest getRequest = new GetRequest(JOB_IDX, id + "");
// 2. 使用RestHighLevelClient.get发送GetRequest请求,并获取到ES服务器的响应。
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
// 3. 将ES响应的数据转换为JSON字符串
String json = getResponse.getSourceAsString();
// 4. 并使用FastJSON将JSON字符串转换为JobDetail类对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 5. 记得:单独设置ID
jobDetail.setId(id);
return jobDetail;
}
@Override
public void update(JobDetail jobDetail) throws IOException {
// 1. 判断对应ID的文档是否存在
// a) 构建GetRequest
GetRequest getRequest = new GetRequest(JOB_IDX, jobDetail.getId() + "");
// b) 执行client的exists方法,发起请求,判断是否存在
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
if(exists) {
// 2. 构建UpdateRequest请求
UpdateRequest updateRequest = new UpdateRequest(JOB_IDX, jobDetail.getId() + "");
// 3. 设置UpdateRequest的文档,并配置为JSON格式
updateRequest.doc(JSONObject.toJSONString(jobDetail), XContentType.JSON);
// 4. 执行client发起update请求
restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
}
}
@Override
public boolean deleteById(long id) throws IOException {
// 1. 构建delete请求
DeleteRequest deleteRequest = new DeleteRequest(JOB_IDX, id + "");
// 2. 使用RestHighLevelClient执行delete请求
restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
return false;
}
@Override
public List<JobDetail> searchByKeywords(String keywords) throws IOException {
// 1.构建SearchRequest检索请求
// 专门用来进行全文检索、关键字检索的API
SearchRequest searchRequest = new SearchRequest(JOB_IDX);
// 2.创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3.使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keywords, "title", "jd");
// 将查询条件设置到查询请求构建器中
searchSourceBuilder.query(multiMatchQueryBuilder);
// 4.调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5.执行RestHighLevelClient.search发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hitArray = searchResponse.getHits().getHits();
// 6.遍历结果
ArrayList<JobDetail> jobDetailArrayList = new ArrayList<>();
for (SearchHit documentFields : hitArray) {
// 1)获取命中的结果
String json = documentFields.getSourceAsString();
// 2)将JSON字符串转换为对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 3)使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(documentFields.getId()));
jobDetailArrayList.add(jobDetail);
}
return jobDetailArrayList;
}
@Override
public Map<String, Object> searchByPage(String keywords, int pageNum, int pageSize) throws IOException {
// 1.构建SearchRequest检索请求
// 专门用来进行全文检索、关键字检索的API
SearchRequest searchRequest = new SearchRequest(JOB_IDX);
// 2.创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3.使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keywords, "title", "jd");
// 将查询条件设置到查询请求构建器中
searchSourceBuilder.query(multiMatchQueryBuilder);
// 每页显示多少条
searchSourceBuilder.size(pageSize);
// 设置从第几条开始查询
searchSourceBuilder.from((pageNum - 1) * pageSize);
// 4.调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5.执行RestHighLevelClient.search发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hitArray = searchResponse.getHits().getHits();
// 6.遍历结果
ArrayList<JobDetail> jobDetailArrayList = new ArrayList<>();
for (SearchHit documentFields : hitArray) {
// 1)获取命中的结果
String json = documentFields.getSourceAsString();
// 2)将JSON字符串转换为对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 3)使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(documentFields.getId()));
jobDetailArrayList.add(jobDetail);
}
// 8. 将结果封装到Map结构中(带有分页信息)
// a) total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
// b) content -> 当前分页中的数据
long totalNum = searchResponse.getHits().getTotalHits().value;
HashMap hashMap = new HashMap();
hashMap.put("total", totalNum);
hashMap.put("content", jobDetailArrayList);
return hashMap;
}
@Override
public Map<String, Object> searchByScrollPage(String keywords, String scrollId, int pageSize) throws IOException {
SearchResponse searchResponse = null;
if(scrollId == null) {
// 1.构建SearchRequest检索请求
// 专门用来进行全文检索、关键字检索的API
SearchRequest searchRequest = new SearchRequest(JOB_IDX);
// 2.创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3.使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keywords, "title", "jd");
// 将查询条件设置到查询请求构建器中
searchSourceBuilder.query(multiMatchQueryBuilder);
// 设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.field("jd");
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
// 给请求设置高亮
searchSourceBuilder.highlighter(highlightBuilder);
// 每页显示多少条
searchSourceBuilder.size(pageSize);
// 4.调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
//--------------------------
// 设置scroll查询
//--------------------------
searchRequest.scroll(TimeValue.timeValueMinutes(5));
// 5.执行RestHighLevelClient.search发起请求
searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
}
// 第二次查询的时候,直接通过scroll id查询数据
else {
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(TimeValue.timeValueMinutes(5));
// 使用RestHighLevelClient发送scroll请求
searchResponse = restHighLevelClient.scroll(searchScrollRequest, RequestOptions.DEFAULT);
}
SearchHit[] hitArray = searchResponse.getHits().getHits();
// 6.遍历结果
ArrayList<JobDetail> jobDetailArrayList = new ArrayList<>();
for (SearchHit documentFields : hitArray) {
// 1)获取命中的结果
String json = documentFields.getSourceAsString();
// 2)将JSON字符串转换为对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 3)使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(documentFields.getId()));
jobDetailArrayList.add(jobDetail);
// 设置高亮的一些文本到实体类中
// 封装了高亮
Map<String, HighlightField> highlightFieldMap = documentFields.getHighlightFields();
HighlightField titleHL = highlightFieldMap.get("title");
HighlightField jdHL = highlightFieldMap.get("jd");
if(titleHL != null) {
// 获取指定字段的高亮片段
Text[] fragments = titleHL.getFragments();
// 将这些高亮片段拼接成一个完整的高亮字段
StringBuilder builder = new StringBuilder();
for(Text text : fragments) {
builder.append(text);
}
// 设置到实体类中
jobDetail.setTitle(builder.toString());
}
if(jdHL != null) {
// 获取指定字段的高亮片段
Text[] fragments = jdHL.getFragments();
// 将这些高亮片段拼接成一个完整的高亮字段
StringBuilder builder = new StringBuilder();
for(Text text : fragments) {
builder.append(text);
}
// 设置到实体类中
jobDetail.setJd(builder.toString());
}
}
// 8. 将结果封装到Map结构中(带有分页信息)
// a) total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
// b) content -> 当前分页中的数据
long totalNum = searchResponse.getHits().getTotalHits().value;
HashMap hashMap = new HashMap();
hashMap.put("scroll_id", searchResponse.getScrollId());
hashMap.put("content", jobDetailArrayList);
return hashMap;
}
// 实现关闭客户端连接
@Override
public void close() {
try {
restHighLevelClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
第7章.Elasticsearch架构原理
7-1.Elasticsearch的节点类型
在Elasticsearch集群中有两类节点
- Master
- DataNode
7-1-1.Master节点
在Elasticsearch启动时,会选举出来一个Master节点。当某个节点启动后,然后使用Zen Discovery机制找到集群中的其他节点,并建立连接
discovery.seed_hosts: ["node1", "node2", "node3", "noden"...]
并从候选主节点中选举出一个主节点
cluster.initial_master_nodes: ["node1", "node2"...]
Master节点主要职责:
- 管理索引(创建索引、删除索引)、分配分片
- 维护元数据
- 管理集群节点状态
Master节点不负责数据写入和查询,比较轻量级
一个Elasticsearch集群中,只有一个Master节点。在生产环境中,内存可以相对小一点,但机器要稳定
7-1-2.DataNode节点
在Elasticsearch集群中,会有N个DataNode节点。
DataNode节点主要负责:
-
数据写入、数据检索,大部分Elasticsearch的压力都在DataNode节点上
-
在生产环境中,DataNode内存配置要求相对要高
7-2.分片和副本机制
7-2-1.分片
- Elasticsearch是一个分布式的搜索引擎,索引的数据也是分成若干部分,分布在不同的服务器节点中
- 分布在不同服务器节点中的索引数据,就是分片(Shard)。Elasticsearch会自动管理分片,如果发现分片分布不均衡,就会自动迁移
- 一个索引(index)由多个shard(分片)组成,而分片是分布在不同的服务器上
7-2-2.副本
为了对Elasticsearch的分片进行容错,假设某个节点不可用,会导致整个索引库都将不可用。所以,需要对分片进行副本容错。每一个分片都会有对应的副本。在Elasticsearch中,默认创建的索引为1个分片、每个分片有1个主分片和1个副本分片
- 每个分片都会有一个Primary Shard(主分片),也会有若干个Replica Shard(副本分片)
- Primary Shard和Replica Shard不在同一个节点上
指定分片、副本数关键词:
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
7-3.Elasticsearch重要工作流程
7-3-1.Elasticsearch文档写入原理
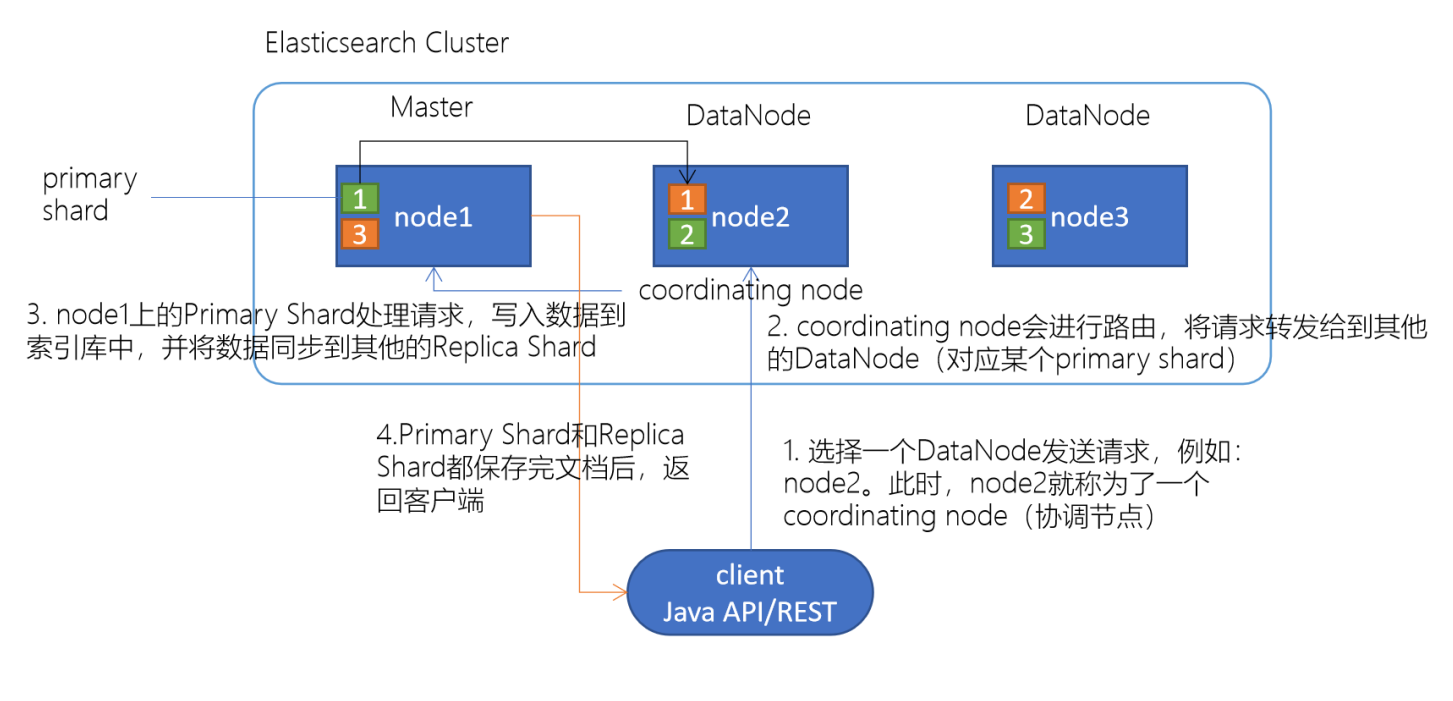
- 选择es集群任意一个DataNode发送请求,此时被连接的DataNode就成为一个coordinating node(协调节点)
- 计算得到文档要写入的分片
- shard = hash(routing) % number_of_primary_shards
- routing 是一个可变值,默认是文档的_id
- coordinating node协调节点会进行路由,将请求转发给对应的primary shard所在的DataNode(primary shard在一个DataNode、则replica shard在另一个DataNode)
- 接到请求的DataNode节点上的Primary Shard处理请求,写入数据到索引库中,并将数据同步到Replica shard
- Primary Shard和Replica Shard都存储完毕后返回client
7-3-2.Elasticsearch检索原理
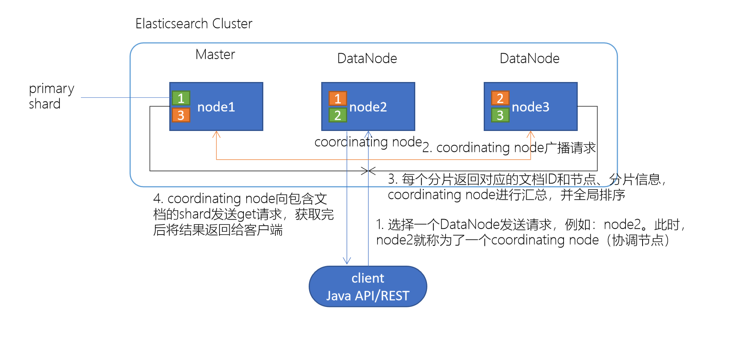
- client发起查询请求,某个DataNode接收到请求,该DataNode就会成为协调节点(Coordinating Node)
- 接到请求的协调节点(Coordinating Node)将查询请求广播到每一个数据节点,这些数据节点的分片会处理该查询请求。协调节点会轮询所有的分片来自动进行负载均衡
- 每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档ID、节点信息、分片信息返回给协调节点
- 协调节点将所有的结果进行汇总,并进行全局排序
- 协调节点向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据返回给客户端
7-4.Elasticsearch准实时索引实现
- 溢写到文件系统缓存
- 当数据写入到ES分片时,会首先写入到内存中,然后通过内存的buffer生成一个segment,并刷到文件系统缓存中,数据可以被检索(注意不是直接刷到磁盘)
- ES中默认1秒,refresh一次
- 写translog保障容错
- 在写入到内存中的同时,也会记录translog日志,在refresh期间出现异常,会根据translog来进行数据恢复
- 等到文件系统缓存中的segment数据都刷到磁盘中,清空translog文件
- flush到磁盘
- ES默认每隔30分钟会将文件系统缓存的数据刷入到磁盘
- segment合并
- Segment太多时,ES定期会将多个segment合并成为大的segment,减少索引查询时IO开销,此阶段ES会真正的物理删除(之前执行过的delete的数据)
第8章.Elasticsearch SQL
8-1.SQL于ES单位对应关系
Elasticsearch SQL允许执行类SQL的查询,可以使用REST接口、命令行或者是JDBC,都可以使用SQL来进行数据的检索和数据的聚合
Elasticsearch SQL特点:
- 本地集成
- Elasticsearch SQL是专门为Elasticsearch构建的。每个SQL查询都根据底层存储对相关节点有效执行
- 无额外要求依赖
- 不依赖其他的硬件、进程、运行时库,Elasticsearch SQL可以直接运行在Elasticsearch集群上
- 轻量且高效
- 像SQL那样简洁、高效地完成查询
SQL与Elasticsearch对应关系:
| SQL | Elasticsearch |
|---|---|
| column(列) | field(字段) |
| row(行) | document(文档) |
| table(表) | index(索引) |
| schema(模式) | mapping(映射) |
| database server(数据库服务器) | Elasticsearch集群实例 |
- es创建一个新索引的index相当于SQL的create table,都类似于存储一类数据
- es针对index中的一个document相当于SQL中的一条数据
- es的field意为字段等同于SQL的列字段column
- es不需要前置的schema定义,在索引doc时确定schema 因为es数据的交互形式是json,所以doc可以开箱即用,在写入doc时如果没有预先定义的mapping
8-2.Elasticsearch-SQL语法
SELECT select_expr [, ...]
[ FROM table_name ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count ] ]
[ PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] ) ) ]
8-3.Elasticsearch-SQL使用案例
8-3-1.查询职位索引库中的一条数据
format:表示指定返回的数据类型
| 格式 | 描述 |
|---|---|
| csv | 逗号分隔符 |
| json | JSON格式 |
| tsv | 制表符分隔符 |
| txt | 类cli表示 |
| yaml | YAML人类可读的格式 |
代码示例:
// 1. 查询职位信息
GET /_sql?format=txt
{
"query": "SELECT * FROM job_idx limit 1"
}
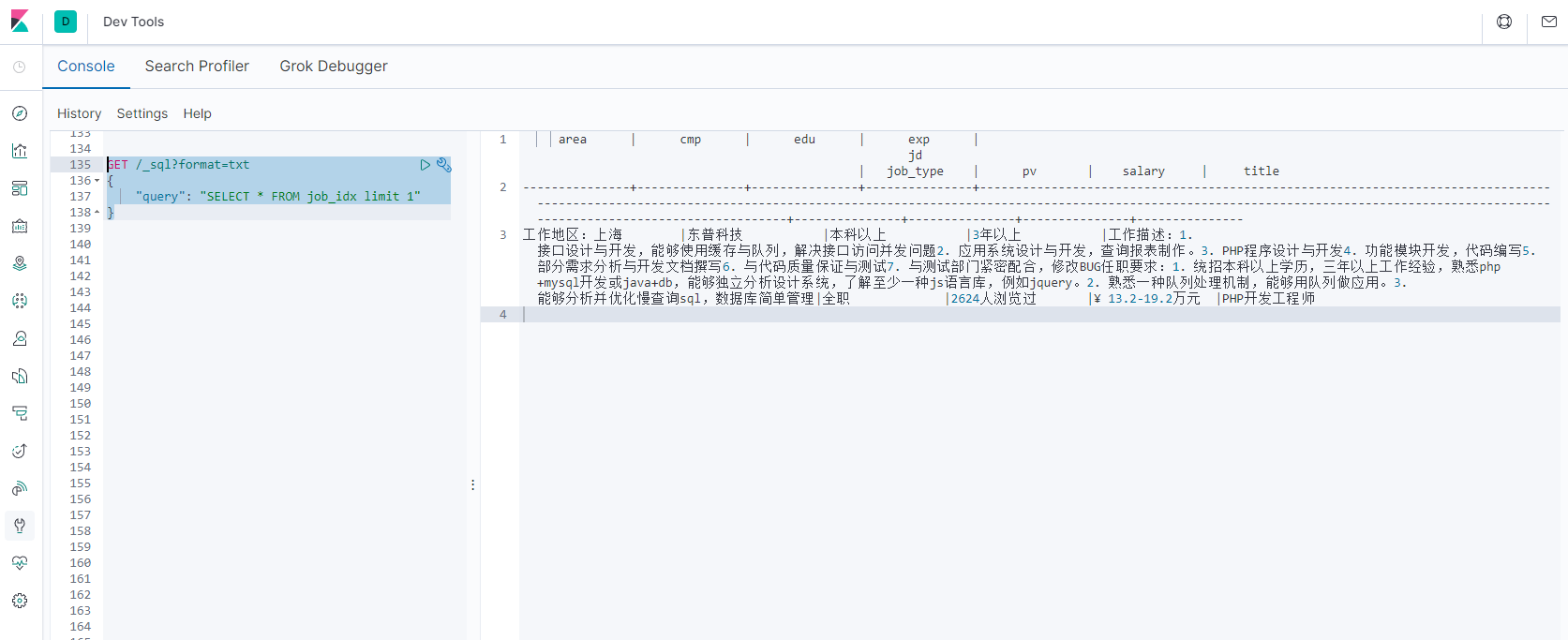
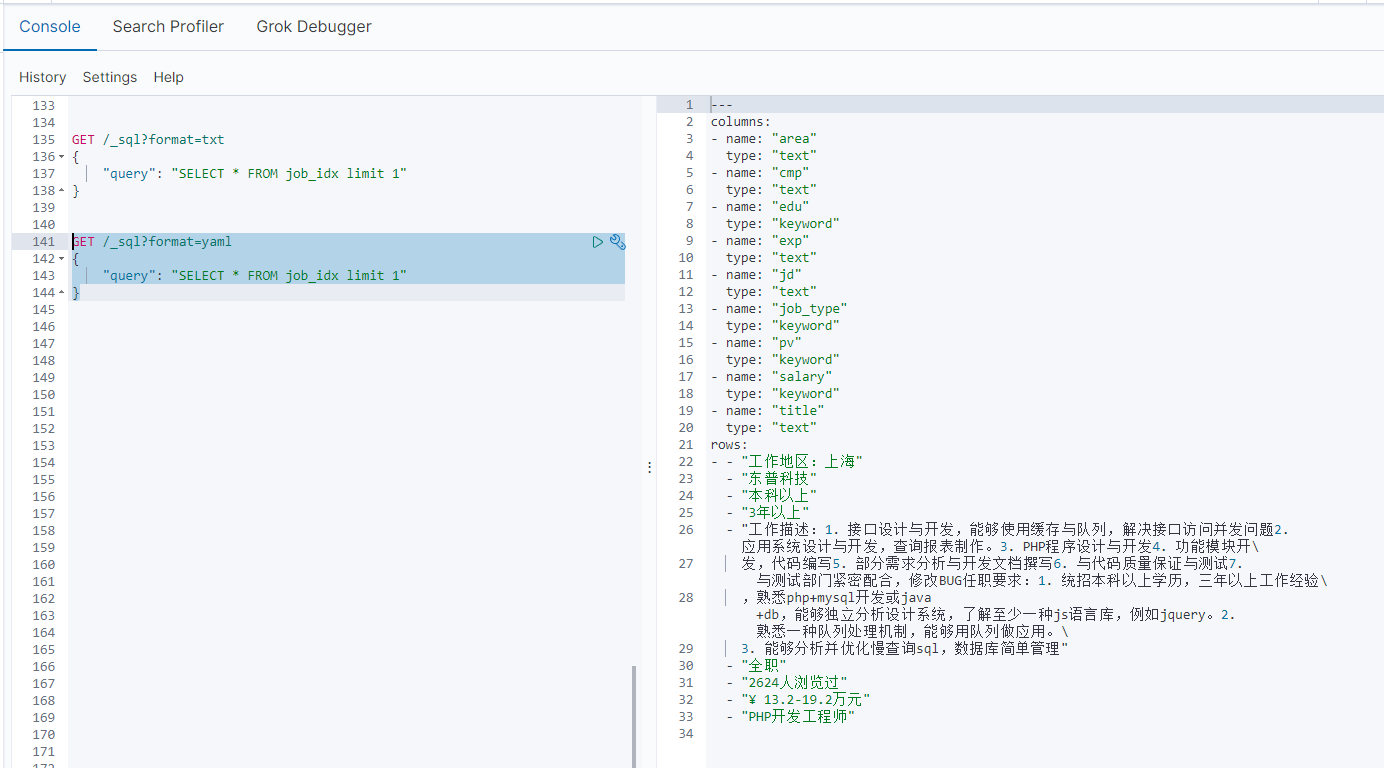
8-3-2.将SQL转化为DSL
GET /_sql/translate
{
"query": "SELECT * FROM job_idx limit 1"
}
执行效果:
{
"size" : 1,
"_source" : {
"includes" : [
"area",
"cmp",
"exp",
"jd",
"title"
],
"excludes" : [ ]
},
"docvalue_fields" : [
{
"field" : "edu"
},
{
"field" : "job_type"
},
{
"field" : "pv"
},
{
"field" : "salary"
}
],
"sort" : [
{
"_doc" : {
"order" : "asc"
}
}
]
}
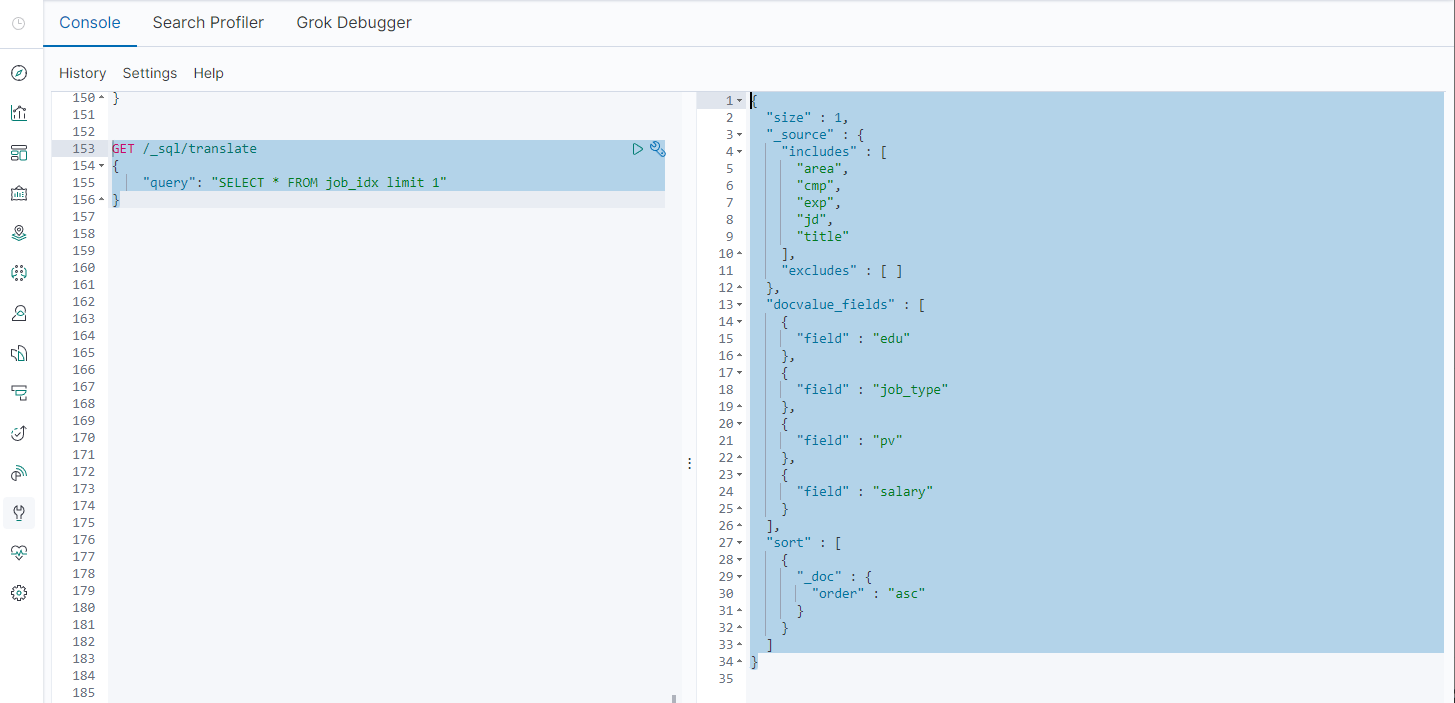
8-3-3.职位scroll分页查询
首次查询
// scroll分页查询
GET /_sql?format=json
{
"query": "SELECT * FROM job_idx",
"fetch_size": 10
}
在查询结果的末尾可以看到cursor关键字:
"cursor" : "5/WuAwFaAXNARFhGMVpYSjVRVzVrUm1WMFkyZ0JBQUFBQUFBQUk0UVdSamc0VG1KVVZVeFRjelptUW1NdGFWODRjVzFWUVE9Pf8PCQFmBGFyZWEBBGFyZWEBBHRleHQAAAABZgNjbXABA2NtcAEEdGV4dAAAAAFmA2VkdQEDZWR1AQdrZXl3b3JkAQAAAWYDZXhwAQNleHABBHRleHQAAAABZgJqZAECamQBBHRleHQAAAABZghqb2JfdHlwZQEIam9iX3R5cGUBB2tleXdvcmQBAAABZgJwdgECcHYBB2tleXdvcmQBAAABZgZzYWxhcnkBBnNhbGFyeQEHa2V5d29yZAEAAAFmBXRpdGxlAQV0aXRsZQEEdGV4dAAAAAL/AQ=="
}
fetch_size表示每页显示多少数据,而且当我们指定format为Json格式时,会返回一个cursor ID
默认快照的失效时间为45s,如果要延迟快照失效时间,如果第一次执行后,等待一段时间超过快照失效后去查询
GET /_sql?format=json { "cursor": "5/WuAwFaAXNARFhGMVpYSjVRVzVrUm1WMFkyZ0JBQUFBQUFBQUk0UVdSamc0VG1KVVZVeFRjelptUW1NdGFWODRjVzFWUVE9Pf8PCQFmBGFyZWEBBGFyZWEBBHRleHQAAAABZgNjbXABA2NtcAEEdGV4dAAAAAFmA2VkdQEDZWR1AQdrZXl3b3JkAQAAAWYDZXhwAQNleHABBHRleHQAAAABZgJqZAECamQBBHRleHQAAAABZghqb2JfdHlwZQEIam9iX3R5cGUBB2tleXdvcmQBAAABZgJwdgECcHYBB2tleXdvcmQBAAABZgZzYWxhcnkBBnNhbGFyeQEHa2V5d29yZAEAAAFmBXRpdGxlAQV0aXRsZQEEdGV4dAAAAAL/AQ==" }会提示404,查不到数据
默认快照的失效时间为45s,如果要延迟快照失效时间,page_timeout参数可以自定义
GET /_sql?format=json
{
"query": "select * from job_idx",
"fetch_size": 5,
"page_timeout": "10m"
}
---------
"cursor" : "5/WuAwFaAXNARFhGMVpYSjVRVzVrUm1WMFkyZ0JBQUFBQUFBQURpTVdZV1JCTW01RmEzZFRkR0ZOVkhGTVVuTm1kRXROUVE9Pf8PCQFmBGFyZWEBBGFyZWEBBHRleHQAAAABZgNjbXABA2NtcAEEdGV4dAAAAAFmA2VkdQEDZWR1AQdrZXl3b3JkAQAAAWYDZXhwAQNleHABBHRleHQAAAABZgJqZAECamQBBHRleHQAAAABZghqb2JfdHlwZQEIam9iX3R5cGUBB2tleXdvcmQBAAABZgJwdgECcHYBB2tleXdvcmQBAAABZgZzYWxhcnkBBnNhbGFyeQEHa2V5d29yZAEAAAFmBXRpdGxlAQV0aXRsZQEEdGV4dAAAAAL/AQ=="
}
第二次查询
GET /_sql?format=json
{
"cursor": "5/WuAwFaAXNARFhGMVpYSjVRVzVrUm1WMFkyZ0JBQUFBQUFBQURpTVdZV1JCTW01RmEzZFRkR0ZOVkhGTVVuTm1kRXROUVE9Pf8PCQFmBGFyZWEBBGFyZWEBBHRleHQAAAABZgNjbXABA2NtcAEEdGV4dAAAAAFmA2VkdQEDZWR1AQdrZXl3b3JkAQAAAWYDZXhwAQNleHABBHRleHQAAAABZgJqZAECamQBBHRleHQAAAABZghqb2JfdHlwZQEIam9iX3R5cGUBB2tleXdvcmQBAAABZgJwdgECcHYBB2tleXdvcmQBAAABZgZzYWxhcnkBBnNhbGFyeQEHa2V5d29yZAEAAAFmBXRpdGxlAQV0aXRsZQEEdGV4dAAAAAL/AQ=="
}
清除游标操作
POST /_sql/close
{
"cursor": "5/WuAwFaAXNARFhGMVpYSjVRVzVrUm1WMFkyZ0JBQUFBQUFBQURpTVdZV1JCTW01RmEzZFRkR0ZOVkhGTVVuTm1kRXROUVE9Pf8PCQFmBGFyZWEBBGFyZWEBBHRleHQAAAABZgNjbXABA2NtcAEEdGV4dAAAAAFmA2VkdQEDZWR1AQdrZXl3b3JkAQAAAWYDZXhwAQNleHABBHRleHQAAAABZgJqZAECamQBBHRleHQAAAABZghqb2JfdHlwZQEIam9iX3R5cGUBB2tleXdvcmQBAAABZgJwdgECcHYBB2tleXdvcmQBAAABZgZzYWxhcnkBBnNhbGFyeQEHa2V5d29yZAEAAAFmBXRpdGxlAQV0aXRsZQEEdGV4dAAAAAL/AQ=="
}
----------
{
"succeeded" : true
}
当清除游标返回true之后,再去查询则返回404
8-3-4.职位全文搜索案例
需求背景:
背景:检索title和jd中包含hadoop的职位
使用MATCH函数实践
在执行全文检索时,需要使用到MATCH函数
- field_exp:匹配字段
- constant_exp:匹配常量表达式
GET /_sql?format=txt
{
"query": "select * from job_idx where MATCH(title, 'hadoop') or MATCH(jd, 'hadoop') limit 1"
}
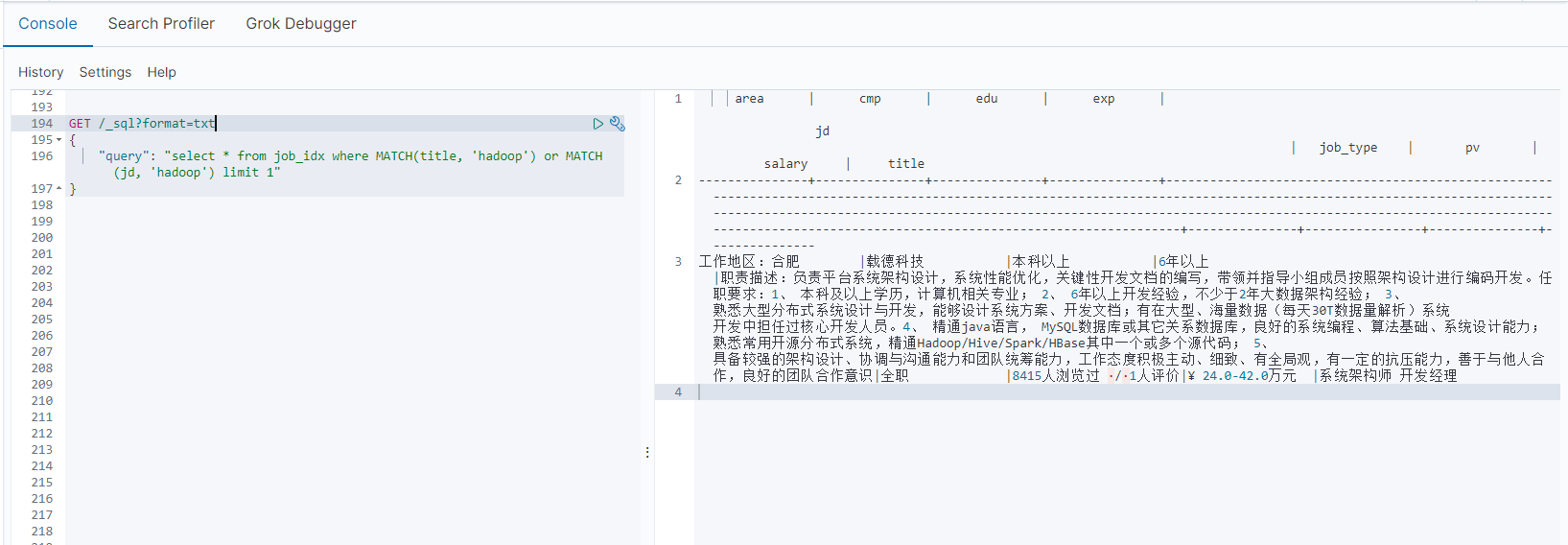
8-4.使用Elasticsearch SQL统计分析案例实践
背景:订单统计分析案例
我们需要基于按数据,使用Elasticsearch中的聚合统计功能,实现一些指标统计
| 订单ID | 订单状态 | 支付金额 | 支付方式ID | 用户ID | 操作时间 | 商品分类 |
|---|---|---|---|---|---|---|
| id | status | pay_money | payway | userid | operation_date | category |
| 1 | 已提交 | 4070 | 1 | 4944191 | 2020-04-25 12:09:16 | 手机; |
| 2 | 已完成 | 4350 | 1 | 1625615 | 2020-04-25 12:09:37 | 家用电器;;电脑; |
| 3 | 已提交 | 6370 | 3 | 3919700 | 2020-04-25 12:09:39 | 男装;男鞋; |
| 4 | 已付款 | 6370 | 3 | 3919700 | 2020-04-25 12:09:44 | 男装;男鞋; |
案例使用的样例数据文件:order_data.json 在网盘中
链接:https://pan.baidu.com/s/1NI9vDPNZHJkqzNevwZFOmw?pwd=54lg
提取码:54lg
8-4-1.创建索引
PUT /order_idx/
{
"mappings": {
"properties": {
"id": {
"type": "keyword",
"store": true
},
"status": {
"type": "keyword",
"store": true
},
"pay_money": {
"type": "double",
"store": true
},
"payway": {
"type": "byte",
"store": true
},
"userid": {
"type": "keyword",
"store": true
},
"operation_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"store": true
},
"category": {
"type": "keyword",
"store": true
}
}
}
}
返回结果:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "order_idx"
}
8-4-2.导入测试数据
order_data.json
将网盘中的order_data.json上传至服务器
使用bulk进行批量导入
[wangting@es01 ~]$ ll | grep order_data
-rw-r--r-- 1 wangting wangting 823356 Nov 3 2020 order_data.json
[wangting@es01 ~]$ curl -H "Content-Type: application/json" -X POST "es01:9200/order_idx/_bulk?pretty&refresh" --data-binary @order_data.json
8-4-3.统计不同支付方式的的订单数量
分别使用JSON DSL的方式和es SQL的方式查询对比
- 使用JSON DSL的方式来实现
本质是Elasticsearch原生支持的基于JSON的DSL方式来实现聚合统计
GET /order_idx/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "payway"
}
}
}
}
查询结果:
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 2,
"doc_count" : 1496
},
{
"key" : 1,
"doc_count" : 1438
},
{
"key" : 3,
"doc_count" : 1183
},
{
"key" : 0,
"doc_count" : 883
}
]
}
}
}
这种方式分析起来比较麻烦,如果将来我们都是写这种方式来分析数据,非常不直观也不容易理解。
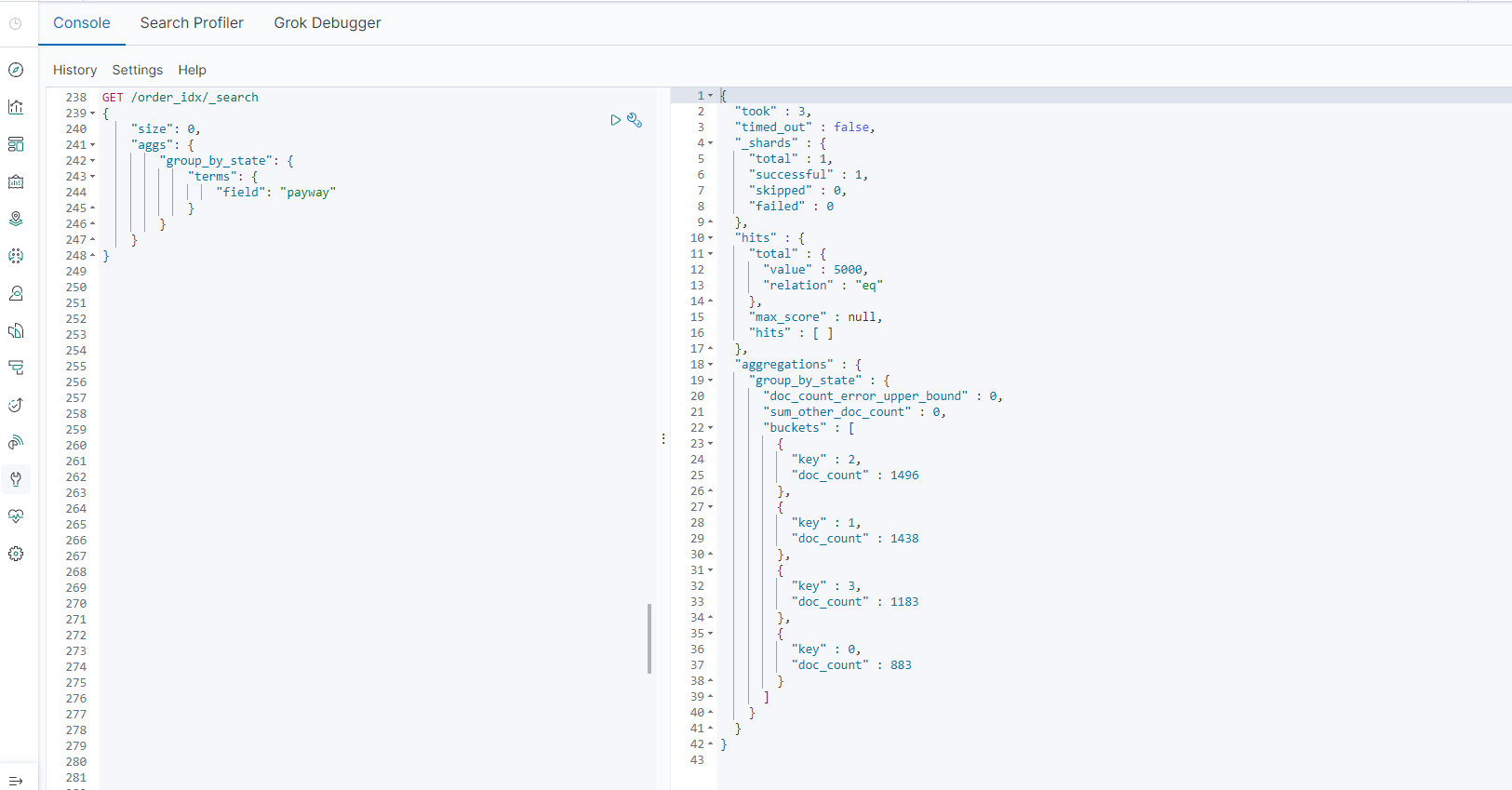
- 使用Elasticsearch SQL方式实现
GET /_sql?format=txt
{
"query": "select payway, count(*) cnt from order_idx group by payway"
}
查询结果:
payway | cnt
---------------+---------------
0 |883
1 |1438
2 |1496
3 |1183
这种SQL方式要更加直观、简洁
8-4-4.排序
统计不同支付方式订单数,并按照订单数量倒序排序
GET /_sql?format=txt
{
"query": "select payway, count(*) cnt from order_idx group by payway order by cnt desc"
}
返回结果:
payway | cnt
---------------+---------------
2 |1496
1 |1438
3 |1183
0 |883
只统计「已付款」状态的不同支付方式的订单数量
GET /_sql?format=txt
{
"query": "select payway, count(*) cnt from order_idx where status = '已付款' group by payway order by cnt desc"
}
返回结果:
payway | cnt
---------------+---------------
2 |624
1 |580
3 |455
0 |370
统计不同用户的总订单数量、总订单金额
GET /_sql?format=txt
{
"query": "select userid, count(*) cnt, sum(pay_money) total_money from order_idx group by userid order by cnt desc limit 10"
}
返回结果:
userid | cnt | total_money
---------------+---------------+---------------
7928516 |169 |978410.0
2393699 |163 |939700.0
4382852 |157 |935660.0
5301038 |146 |853740.0
1274270 |143 |845460.0
8051757 |118 |698930.0
6387107 |116 |645290.0
3919700 |115 |636290.0
5264116 |115 |715930.0
5837271 |112 |642550.0
第9章.数据发送器Beats
9-1.Beats介绍
Beats是一个开放源代码的数据发送器。我们可以把Beats作为一种代理安装在我们的服务器上,这样就可以比较方便地将数据发送到Elasticsearch或者Logstash中。Elastic Stack提供了多种类型的Beats组件。
常见的Beats组件:
| 审计数据 | AuditBeat |
|---|---|
| 日志文件 | FileBeat |
| 云数据 | FunctionBeat |
| 可用性数据 | HeartBeat |
| 系统日志 | JournalBeat |
| 指标数据 | MetricBeat |
| 网络流量数据 | PacketBeat |
| Windows事件日志 | Winlogbeat |
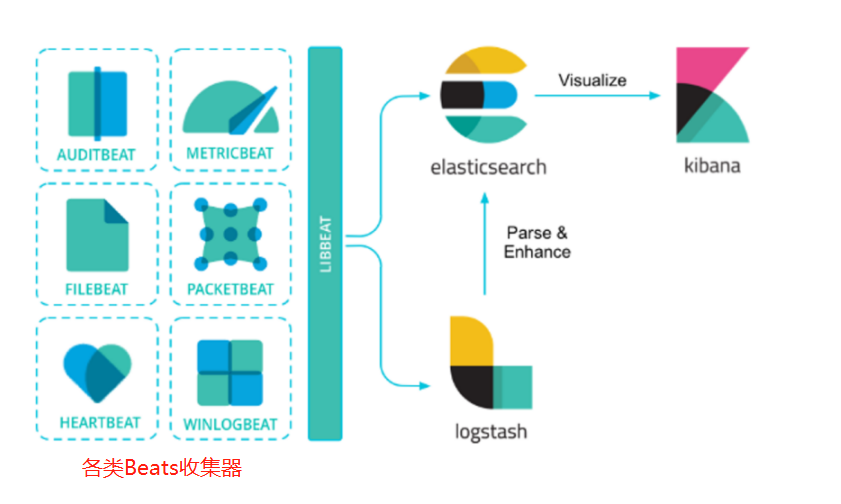
9-2.FileBeat简介
FileBeat专门用于转发和收集日志数据的轻量级采集工具。它可以为作为代理安装在服务器上,FileBeat监视指定路径的日志文件,收集日志数据,并将收集到的日志转发到Elasticsearch或者Logstash。
9-3.FileBeat工作原理
启动FileBeat时,会启动一个或者多个输入(Input),这些Input监控指定的日志数据位置。FileBeat会针对每一个文件启动一个Harvester(收割机)。Harvester读取每一个文件的日志,将新的日志发送到libbeat,libbeat将数据收集到一起,并将数据发送给输出(Output)

FileBeat主要由input和harvesters(收割机)组成。这两个组件协同工作,并将数据发送到指定的输出
inputs(输入)
- input是负责管理Harvesters和查找所有要读取的文件的组件
- 如果输入类型是log,input组件会查找磁盘上与路径描述的所有文件,并为每个文件启动一个Harvester,每个输入都独立地运行
Harvesters(收割机)
- Harvesters负责读取单个文件的内容,它负责打开/关闭文件,并逐行读取每个文件的内容,将读取到的内容发送给输出
- 每个文件都会对应启动一个Harvester
- Harvester运行时,文件将处于打开状态。如果文件在读取时,被移除或者重命名,FileBeat将继续读取该文件
FileBeats如何保持文件状态
-
FileBeat保存每个文件的状态,并定时将状态信息保存在磁盘的「注册表」文件中
-
该状态记录Harvester读取的最后一次偏移量,并确保发送所有的日志数据
-
如果输出(Elasticsearch或者Logstash)无法访问,FileBeat会记录成功发送的最后一行,并在输出(Elasticsearch或者Logstash)可用时,继续读取文件发送数据
-
在运行FileBeat时,每个input的状态信息也会保存在内存中,重新启动FileBeat时,会从「注册表」文件中读取数据来重新构建状态
-
filebeat-7.6.1-linux-x86_64/data/registry/filebeat目录下,data.json文件中记录了Harvester读取日志的offset
9-4.FileBeat安装部署
FileBeat官方下载地址:https://www.elastic.co/cn/downloads/past-releases/filebeat-7-6-1
云盘共享包里已上传:filebeat-7.6.1-linux-x86_64.tar.gz
链接:https://pan.baidu.com/s/1NI9vDPNZHJkqzNevwZFOmw?pwd=54lg
提取码:54lg
将安装包上传至服务器解压即可使用:
[wangting@es01 ~]$ ll |grep filebeat
-rw-r--r-- 1 wangting wangting 24875671 Nov 3 2020 filebeat-7.6.1-linux-x86_64.tar.gz
[wangting@es01 ~]$ tar -xf filebeat-7.6.1-linux-x86_64.tar.gz -C /opt/module/
9-5.使用FileBeat采集服务日志发送到elasticsearch
9-5-1.需求案例
背景:服务器上有应用日志log文件,我们为了通过在Elasticsearch中快速查询这些日志,定位问题。需要用FileBeats将日志数据上传到Elasticsearch中
# 模拟数据日志文件
[wangting@es01 app_log]$ pwd
/home/wangting/app_log
[wangting@es01 app_log]$ vim app_info.log
[2022-11-04 16:40:02,872] WARN Attempting to send response via channel for which there is no open connection, connection id 192.168.88.100:9092-192.168.88.100:34490-75998 (kafka.network.Processor)
[2022-11-04 16:44:45,170] INFO [GroupMetadataManager brokerId=0] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
[2022-11-04 16:45:04,538] WARN Attempting to send response via channel for which there is no open connection, connection id 192.168.88.100:9092-192.168.88.100:39610-76230 (kafka.network.Processor)
[2022-11-04 16:50:03,824] WARN Attempting to send response via channel for which there is no open connection, connection id 192.168.88.100:9092-192.168.88.100:44554-76456 (kafka.network.Processor)
[2022-11-04 16:54:45,171] INFO [GroupMetadataManager brokerId=0] Removed 0 expired offsets in 1 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
我们要指定FileBeat采集哪些日志,因为FileBeats中必须知道采集存放在哪儿的日志,才能进行采集。
采集到这些数据后,还需要指定FileBeats将采集到的日志输出到Elasticsearch,那么Elasticsearch的地址也必须指定
9-5-2.配置FileBeats
FileBeats配置文件主要分为两个部分。
-
inputs( 输入数据 )
-
output( 输出数据 )
Input配置介绍
模板:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
- ...
在FileBeats中,可以读取一个或多个数据源

Output配置介绍
模板:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
- ...
output.elasticsearch:
hosts: ["es01:9200", "es02:9200", "es03:9200"]
output.elasticsearch: 表示输出到elasticsearch
hosts:表示被输出的es集群信息
9-5-3.配置文件
[wangting@es01 ~]$ cd /opt/module/filebeat-7.6.1-linux-x86_64/
[wangting@es01 filebeat-7.6.1-linux-x86_64]$ vim filebeat_app_log.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/wangting/app_log/*.log
output.elasticsearch:
hosts: ["es01:9200", "es02:9200", "es03:9200"]
9-5-4.执行任务
运行FileBeat:
[wangting@es01 filebeat-7.6.1-linux-x86_64]$ pwd
/opt/module/filebeat-7.6.1-linux-x86_64
[wangting@es01 filebeat-7.6.1-linux-x86_64]$ ./filebeat -c filebeat_app_log.yml -e
Exiting: error loading config file: config file ("filebeat_app_log.yml") can only be writable by the owner but the permissions are "-rw-rw-r--" (to fix the permissions use: 'chmod go-w /opt/module/filebeat-7.6.1-linux-x86_64/filebeat_app_log.yml')
# 提示报错了:
# 任务退出:加载配置文件filebeat_app_log.yml时出错:配置文件(“filebeat_app_log.yml”)只能由所有者写入,但权限为“-rw-r--”(要修复权限,请使用:'chmod go-w/opt/module/filebeat-7.6.1-linux-x86_64/filebeat_app_ log.yml')
# 按照提示处理
[wangting@es01 filebeat-7.6.1-linux-x86_64]$ ll | grep filebeat_app_log.yml
-rw-rw-r-- 1 wangting wangting 162 Nov 4 12:28 filebeat_app_log.yml
[wangting@es01 filebeat-7.6.1-linux-x86_64]$ chmod go-w /opt/module/filebeat-7.6.1-linux-x86_64/filebeat_app_log.yml
[wangting@es01 filebeat-7.6.1-linux-x86_64]$ ll | grep filebeat_app_log.yml
-rw-r--r-- 1 wangting wangting 162 Nov 4 12:28 filebeat_app_log.yml
[wangting@es01 filebeat-7.6.1-linux-x86_64]$ ./filebeat -c filebeat_app_log.yml -e
# 等待控制台输出
...
...
...
2022-11-04T12:33:47.494+0800 INFO [index-management] idxmgmt/std.go:295 Loaded index template.
2022-11-04T12:33:47.499+0800 INFO [index-management] idxmgmt/std.go:306 Write alias successfully generated.
2022-11-04T12:33:47.501+0800 INFO pipeline/output.go:105 Connection to backoff(elasticsearch(http://es02:9200)) established
2022-11-04T12:34:14.698+0800 INFO [monitoring] log/log.go:145 Non-zero metrics in the last 30s {
"monitoring": {
"metrics": {
"beat":{
"cpu":{
"system":{
"ticks":10,"time":{
"ms":18}},"total":{
"ticks":280,"time":{
"ms":292},"value":280},"user":{
"ticks":270,"time":{
"ms":274}}},"handles":{
"limit":{
"hard":131072,"soft":65536},"open":11},"info":{
"ephemeral_id":"2abe1488-e7e9-461d-9e36-1dfa835da266","uptime":{
"ms":30028}},"memstats":{
"gc_next":16741552,"memory_alloc":11184320,"memory_total":58913856,"rss":49434624},"runtime":{
"goroutines":33}},"filebeat":{
"events":{
"added":6,"done":6},"harvester":{
"files":{
"f62973fd-a078-4715-9026-8d07ce198cd3":{
"last_event_published_time":"2022-11-04T12:33:44.701Z","last_event_timestamp":"2022-11-04T12:33:44.701Z","name":"/home/wangting/app_log/app_info.log","read_offset":905,"size":905,"start_time":"2022-11-04T12:33:44.700Z"}},"open_files":1,"running":1,"started":1}},"libbeat":{
"config":{
"module":{
"running":0}},"output":{
"events":{
"acked":5,"batches":1,"total":5},"read":{
"bytes":7110},"type":"elasticsearch","write":{
"bytes":160095}},"pipeline":{
"clients":1,"events":{
"active":0,"filtered":1,"published":5,"retry":15,"total":6},"queue":{
"acked":5}}},"registrar":{
"states":{
"current":1,"update":6},"writes":{
"success":3,"total":3}},"system":{
"cpu":{
"cores":2},"load":{
"1":0.04,"15":0.05,"5":0.03,"norm":{
"1":0.02,"15":0.025,"5":0.015}}}}}}
注意,启动时为控制台启动,验证时不要关闭会话
待验证完毕后再关闭任务即可
9-5-5.查询验证数据
通过head插件,我们可以看到filebeat采集了日志消息,并写入到Elasticsearch集群中
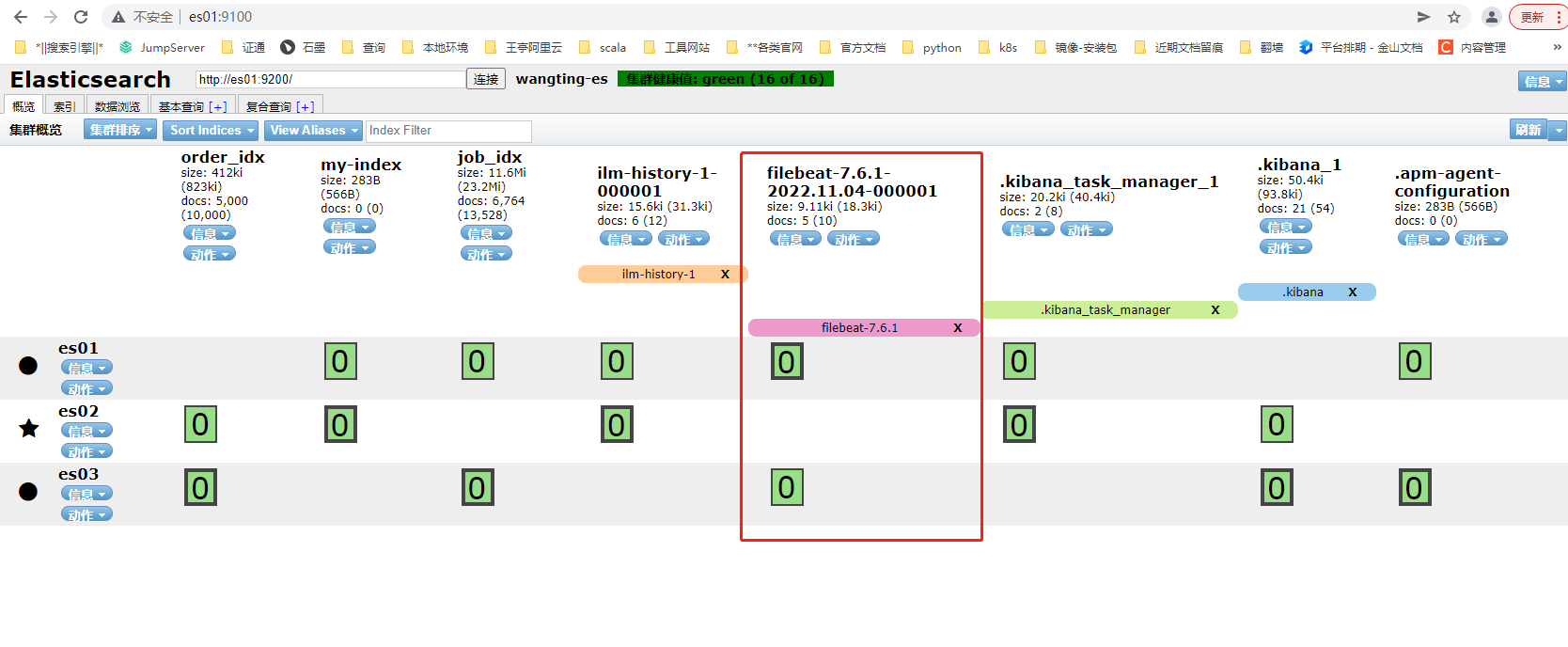
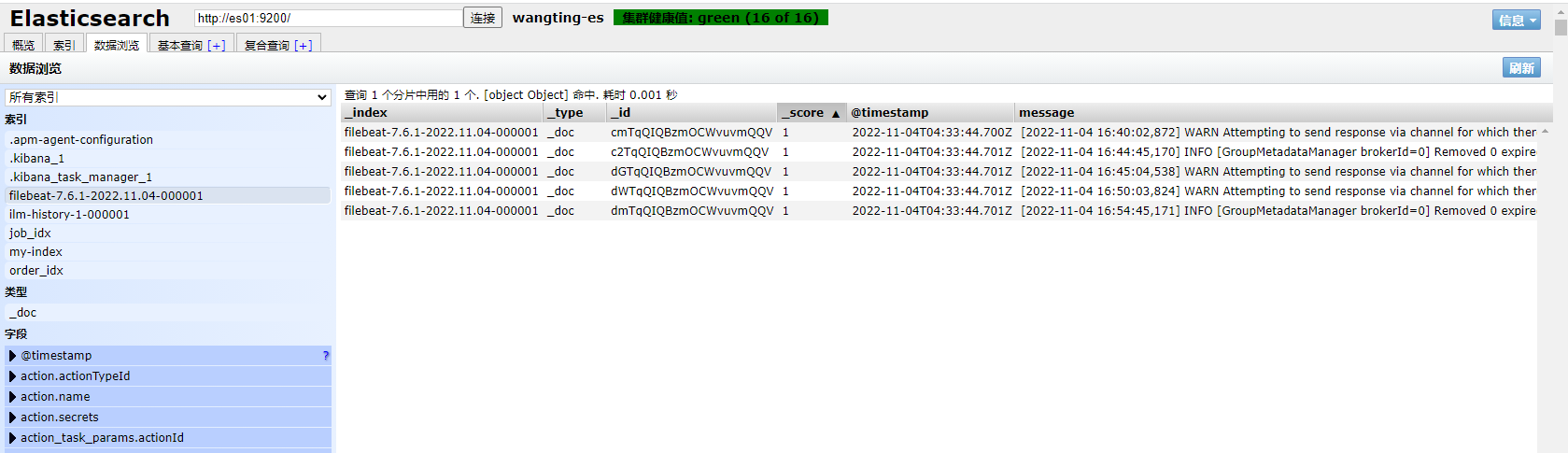
首页的ilm:索引生命周期管理所需的索引
filebeat-7.6.1:在ES中,可以创建索引的别名,可以使用别名来指向一个或多个索引,类似于windows的快捷方式。因为Elasticsearch中的索引创建后是不允许修改的,很多的业务场景下单一索引无法满足需求。别名也有利于ILM所以索引生命周期管理
从Kibana查看索引相关信息:
GET /_cat/indices?v

查询索引 filebeat-7.6.1-2022.11.04-000001 中的数据
GET /filebeat-7.6.1-2022.11.04-000001/_search
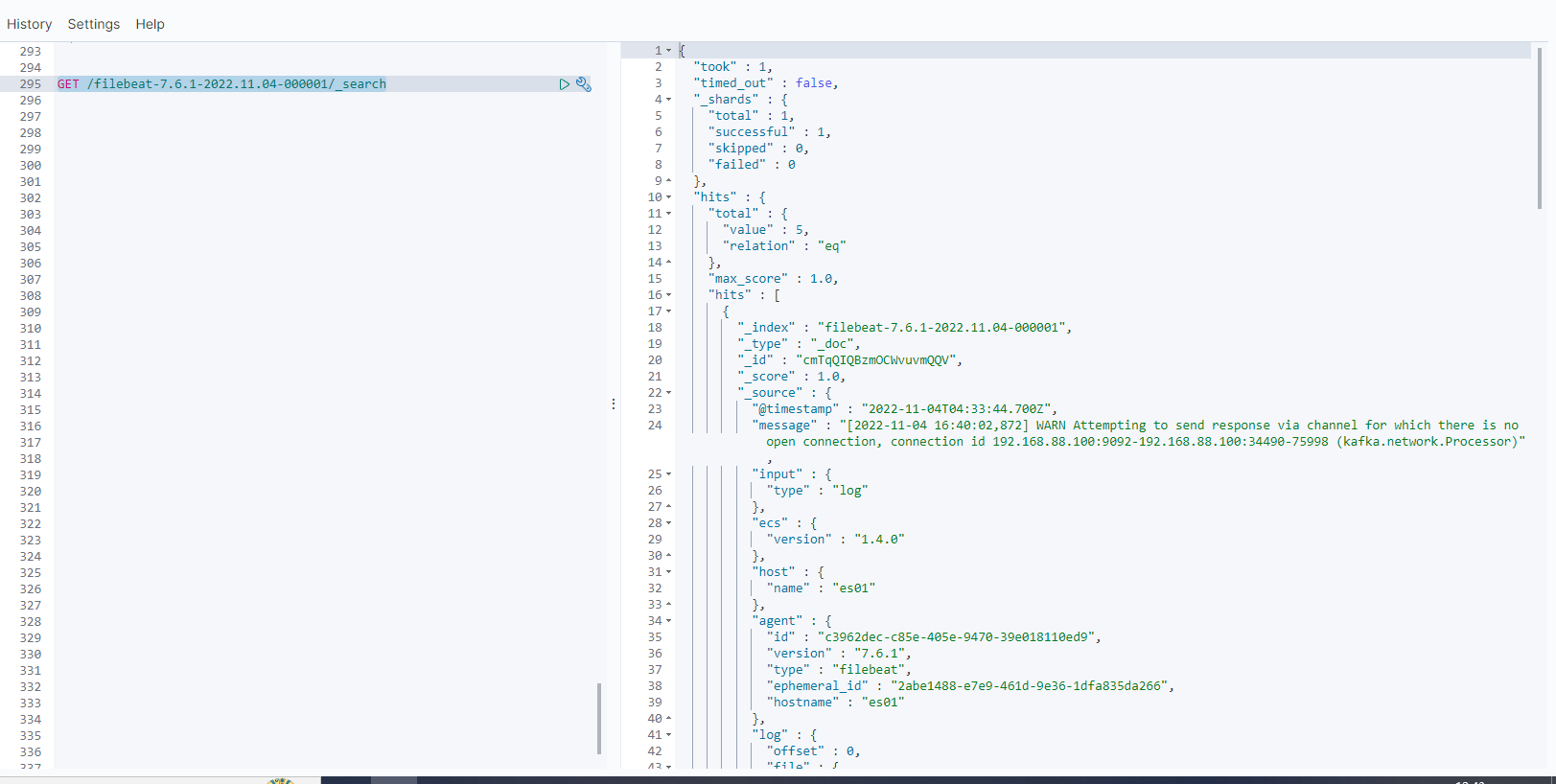
message内容对应一条条的日志数据信息
从查询的结果来看,除了log中识别匹配的字段外,FileBeat自动给我们添加了一些关于日志、采集类型、Host各种字段。
第10章.数据采集引擎Logstash
10-1.Logstash简介
Logstash是一个开源的数据采集引擎。它可以动态地将不同来源的数据统一采集,并按照指定的数据格式进行处理后,将数据加载到其他的目的地。最开始,Logstash主要是针对日志采集,但后来Logstash开发了大量丰富的插件,所以,它可以做更多的海量数据的采集
Logstash可以处理各种类型的日志数据,例如:Apache的web log、Java的log4j日志数据,或者是系统、网络、防火墙的日志等等。它也可以很容易的和Elastic Stack的Beats组件整合,也可以很方便的和关系型数据库、NoSQL数据库、Kafka、RabbitMQ等整合
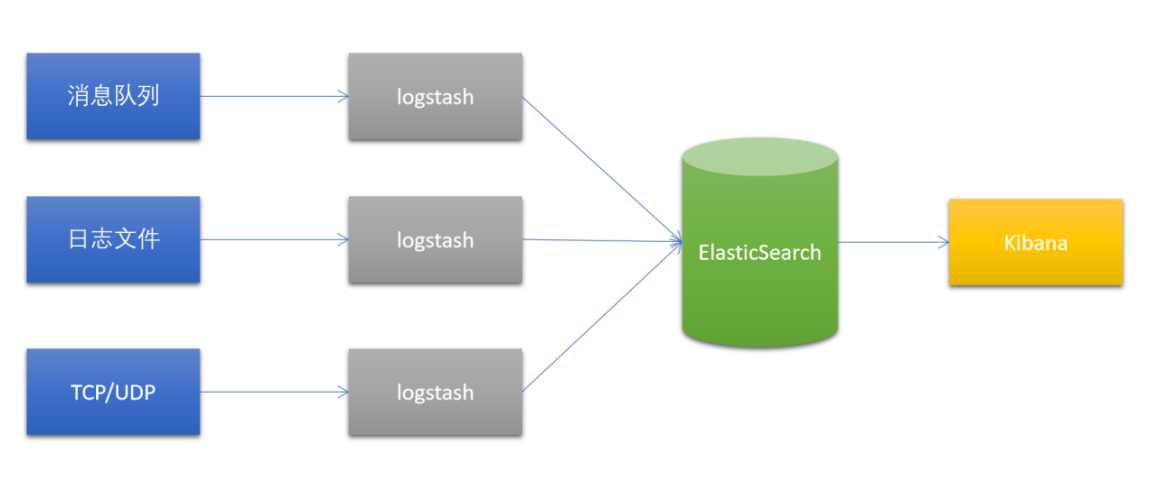
10-2.Logstash经典架构
10-3.Logstash对比Flume、FileBeat
- 对比Flume
- Flume是一个通用型的数据采集平台,它通过配置source、channel、sink来实现数据的采集,支持的平台也非常多。而Logstash结合Elastic Stack的其他组件配合使用,开发、应用都会简单很多
- Logstash比较关注数据的预处理,而Flume跟偏重数据的传输,几乎没有太多的数据解析预处理,仅仅是数据的产生,封装成Event然后传输
- 对比FileBeat
- logstash运行是基于jvm,资源消耗比较大
- FileBeat是基于golang编写的,功能较少但资源消耗也比较小,更轻量级
- logstash 和filebeat都具有日志收集功能,Filebeat更轻量,占用资源更少
- logstash 具有filter功能,能过滤分析日志
- 一般常见架构都是filebeat采集日志,然后发送到消息队列,redis,kafka中,然后logstash去获取,利用filter功能过滤分析,然后存储到elasticsearch中
- FileBeat和Logstash配合,实现背压机制
背压机制-让数据在的生产者与消费者平滑流动的机制
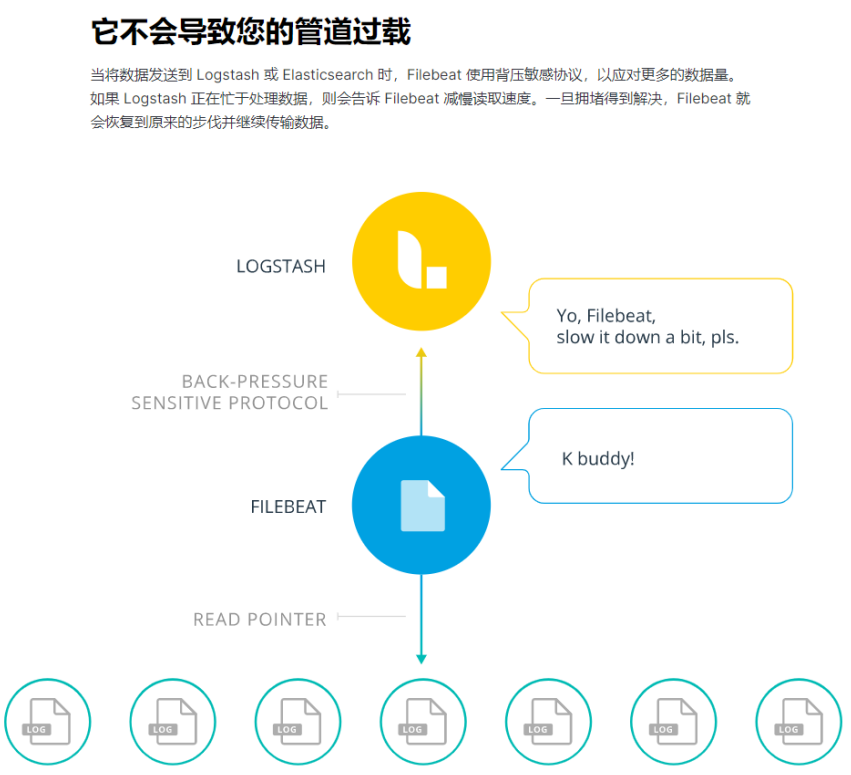
10-4.Logstash安装部署
Logstash下载地址:https://www.elastic.co/cn/downloads/past-releases/logstash-7-6-1
云盘中:
链接:https://pan.baidu.com/s/1NI9vDPNZHJkqzNevwZFOmw?pwd=54lg
提取码:54lg可自行下载:logstash-7.6.1.zip
[ 注意 ]:需要有java环境
如果没有jdk环境可以在云盘中下载:jdk-8u211-linux-x64.tar.gz
[wangting@es01 ~]$ ll | grep logstash
-rw-r--r-- 1 wangting wangting 179562660 Nov 3 2020 logstash-7.6.1.zip
[wangting@es01 ~]$ unzip logstash-7.6.1.zip -d /opt/module/
运行测试:
[wangting@es01 ~]$ cd /opt/module/logstash-7.6.1/
[wangting@es01 logstash-7.6.1]$ bin/logstash -e 'input { stdin {} } output { stdout {} }'
# -e选项表示,直接把配置放在命令中,这样可以有效快速进行测试
# 等待logstash启动
[2022-11-04T15:26:59,010][INFO ][logstash.javapipeline ][main] Pipeline started {
"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2022-11-04T15:26:59,094][INFO ][logstash.agent ] Pipelines running {
:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2022-11-04T15:26:59,328][INFO ][logstash.agent ] Successfully started Logstash API endpoint {
:port=>9600}
# 看到启动端口,已经成功启动服务
在控制台尝试输入内容,查看Logstash的输出
[2022-11-04T15:26:59,094][INFO ][logstash.agent ] Pipelines running {
:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2022-11-04T15:26:59,328][INFO ][logstash.agent ] Successfully started Logstash API endpoint {
:port=>9600}
wangting
/opt/module/logstash-7.6.1/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"host" => "es01",
"@version" => "1",
"@timestamp" => 2022-11-04T07:27:53.694Z,
"message" => "wangting"
}
666
{
"host" => "es01",
"@version" => "1",
"@timestamp" => 2022-11-04T07:28:05.011Z,
"message" => "666"
}
10-5.Logstash日志收集案例实践
10-5-1.需求
背景:使用Logstash来实现日志的采集,并把这些日志导入到Elasticsearch中
云盘中有login_info.log文件
[wangting@es01 app_log]$ ll | grep login_info
-rw-r--r-- 1 wangting wangting 25445 Nov 4 16:13 login_info.log
[wangting@es01 app_log]$ tail -5 login_info.log
114.85.194.81 - - [04/Nov/2022:16:07:46 +0800] "GET /login/ HTTP/1.1" 200 858 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
114.85.194.81 - - [04/Nov/2022:16:07:46 +0800] "GET /login/css/login.css HTTP/1.1" 200 2823 "https://www.wangting.fun/login/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
114.85.194.81 - - [04/Nov/2022:16:07:51 +0800] "GET / HTTP/1.1" 401 597 "https://www.wangting.fun/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
114.85.194.81 - - [04/Nov/2022:16:07:53 +0800] "GET / HTTP/1.1" 401 597 "https://www.wangting.fun/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
114.85.194.81 - - [04/Nov/2022:16:07:53 +0800] "GET /favicon.ico HTTP/1.1" 401 597 "https://www.wangting.fun:81/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
| 字段名 | 说明 |
|---|---|
| client IP | 浏览器端IP |
| timestamp | 请求的时间戳 |
| method | 请求方式(GET/POST) |
| uri | 请求的链接地址 |
| status | 服务器端响应状态 |
| length | 响应的数据长度 |
| reference | 从哪个URL跳转而来 |
| browser | 浏览器 |
因为最终我们需要将这些日志数据存储在Elasticsearch中,而Elasticsearch是有模式(schema)的,而不是一个大文本存储所有的消息,而是需要将字段一个个的保存在Elasticsearch中。所以,我们需要在Logstash中,提前将数据解析好,将日志文本行解析成一个个的字段,然后再将字段保存到Elasticsearch中
在使用Logstash进行数据解析之前,我们需要使用FileBeat将采集到的数据发送到Logstash。之前,我们使用的FileBeat是通过FileBeat的Harvester组件监控日志文件,然后将日志以一定的格式保存到Elasticsearch中,而现在我们需要配置FileBeats将数据发送到Logstash
10-5-2.FileBeat配置文件
[wangting@es01 app_log]$ cd /opt/module/filebeat-7.6.1-linux-x86_64/
[wangting@es01 filebeat-7.6.1-linux-x86_64]$ vim filebeat-logstash.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/wangting/app_log/login_info.log
multiline.pattern: '^\\d+\\.\\d+\\.\\d+\\.\\d+ '
multiline.negate: true
multiline.match: after
output.logstash:
enabled: true
hosts: ["es01:5044"]
启动FileBeat,并指定使用新的配置文件
[wangting@es01 filebeat-7.6.1-linux-x86_64]$ pwd
/opt/module/filebeat-7.6.1-linux-x86_64
[wangting@es01 filebeat-7.6.1-linux-x86_64]$ ./filebeat -e -c filebeat-logstash.yml
- 因为logstash暂时还没配置和启动,filebeat暂时会提示报错
- 会话窗口需要开着等待连接,后续操作另起一个窗口
10-5-3.配置Logstash接收FileBeat数据并打印
Logstash的配置文件和FileBeat类似,它也需要有一个input、和output
[wangting@es01 ~]$ cd /opt/module/logstash-7.6.1/
[wangting@es01 logstash-7.6.1]$ vim config/filebeat-print.conf
input {
beats {
port => 5044
}
}
output {
stdout {
codec => rubydebug
}
}
测试logstash配置是否正确
[wangting@es01 logstash-7.6.1]$ bin/logstash -f config/filebeat-print.conf --config.test_and_exit
Sending Logstash logs to /opt/module/logstash-7.6.1/logs which is now configured via log4j2.properties
[2022-11-04T16:39:39,133][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2022-11-04T16:39:40,366][INFO ][org.reflections.Reflections] Reflections took 50 ms to scan 1 urls, producing 20 keys and 40 values
Configuration OK
[2022-11-04T16:39:41,288][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
启动logstash
[wangting@es01 logstash-7.6.1]$ bin/logstash -f config/filebeat-print.conf --config.reload.automatic
# reload.automatic:修改配置文件时自动重新加载
# 稍等片刻后,logstash启动成功会在控制台输出相关信息
此时的filebeats也不再报错,开始正常传输信息:
2022-11-04T16:46:34.010+0800 INFO [monitoring] log/log.go:145 Non-zero metrics in the last 30s {
"monitoring": {
"metrics": {
"beat":{
"cpu":{
"system":{
"ticks":50,"time":{
"ms":2}},"total":{
"ticks":150,"time":{
"ms":3},"value":150},"user":{
"ticks":100,"time":{
"ms":1}}},"handles":{
"limit":{
"hard":131072,"soft":65536},"open":8},"info":{
"ephemeral_id":"848c9c0f-364d-4f96-9a84-c0787826d966","uptime":{
"ms":780026}},"memstats":{
"gc_next":8809344,"memory_alloc":4789224,"memory_total":22638536},"runtime":{
"goroutines":22}},"filebeat":{
"harvester":{
"open_files":0,"running":0}},"libbeat":{
"config":{
"module":{
"running":0}},"pipeline":{
"clients":1,"events":{
"active":0}}},"registrar":{
"states":{
"current":2}},"system":{
"load":{
"1":0.29,"15":0.21,"5":0.35,"norm":{
"1":0.145,"15":0.105,"5":0.175}}}}}}
2022-11-04T16:47:04.010+0800 INFO [monitoring] log/log.go:145 Non-zero metrics in the last 30s {
"monitoring": {
"metrics": {
"beat":{
"cpu":{
"system":{
"ticks":50},"total":{
"ticks":160,"time":{
"ms":2},"value":160},"user":{
"ticks":110,"time":{
"ms":2}}},"handles":{
"limit":{
"hard":131072,"soft":65536},"open":8},"info":{
"ephemeral_id":"848c9c0f-364d-4f96-9a84-c0787826d966","uptime":{
"ms":810027}},"memstats":{
"gc_next":8809344,"memory_alloc":4998680,"memory_total":22847992},"runtime":{
"goroutines":22}},"filebeat":{
"harvester":{
"open_files":0,"running":0}},"libbeat":{
"config":{
"module":{
"running":0}},"pipeline":{
"clients":1,"events":{
"active":0}}},"registrar":{
"states":{
"current":2}},"system":{
"load":{
"1":0.18,"15":0.2,"5":0.31,"norm":{
"1":0.09,"15":0.1,"5":0.155}}}}}}
10-5-4.Logstash输出数据到Elasticsearch
通过控制台,我们发现Logstash input接收到的数据没有经过任何处理就发送给了output组件。而其实我们需要将数据输出到Elasticsearch。所以,我们修改Logstash的output配置。配置输出Elasticsearch
[wangting@es01 logstash-7.6.1]$ vim config/filebeat-es.conf
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => [ "es01:9200","es02:9200","es03:9200"]
}
stdout {
codec => rubydebug
}
}
重新启动Logstash
# 将前一次启动的logstash关闭ctrl+c
[wangting@es01 logstash-7.6.1]$ bin/logstash -f config/filebeat-es.conf --config.reload.automatic
循环追加日志模拟刷新信息:
[wangting@es01 app_log]$ while true; do sleep 5 && tail -1 login_info.log >> login_info.log ;done
验证:
通过head界面查看
通过Kibana界面实践结果:
查询索引信息:
GET /_cat/indices?v
查看索引信息:
GET /logstash-2022.11.04-000001/_search?format=txt
options are specified
[2022-11-04T16:39:40,366][INFO ][org.reflections.Reflections] Reflections took 50 ms to scan 1 urls, producing 20 keys and 40 values
Configuration OK
[2022-11-04T16:39:41,288][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
启动logstash
```shell
[wangting@es01 logstash-7.6.1]$ bin/logstash -f config/filebeat-print.conf --config.reload.automatic
# reload.automatic:修改配置文件时自动重新加载
# 稍等片刻后,logstash启动成功会在控制台输出相关信息
此时的filebeats也不再报错,开始正常传输信息:
2022-11-04T16:46:34.010+0800 INFO [monitoring] log/log.go:145 Non-zero metrics in the last 30s {
"monitoring": {
"metrics": {
"beat":{
"cpu":{
"system":{
"ticks":50,"time":{
"ms":2}},"total":{
"ticks":150,"time":{
"ms":3},"value":150},"user":{
"ticks":100,"time":{
"ms":1}}},"handles":{
"limit":{
"hard":131072,"soft":65536},"open":8},"info":{
"ephemeral_id":"848c9c0f-364d-4f96-9a84-c0787826d966","uptime":{
"ms":780026}},"memstats":{
"gc_next":8809344,"memory_alloc":4789224,"memory_total":22638536},"runtime":{
"goroutines":22}},"filebeat":{
"harvester":{
"open_files":0,"running":0}},"libbeat":{
"config":{
"module":{
"running":0}},"pipeline":{
"clients":1,"events":{
"active":0}}},"registrar":{
"states":{
"current":2}},"system":{
"load":{
"1":0.29,"15":0.21,"5":0.35,"norm":{
"1":0.145,"15":0.105,"5":0.175}}}}}}
2022-11-04T16:47:04.010+0800 INFO [monitoring] log/log.go:145 Non-zero metrics in the last 30s {
"monitoring": {
"metrics": {
"beat":{
"cpu":{
"system":{
"ticks":50},"total":{
"ticks":160,"time":{
"ms":2},"value":160},"user":{
"ticks":110,"time":{
"ms":2}}},"handles":{
"limit":{
"hard":131072,"soft":65536},"open":8},"info":{
"ephemeral_id":"848c9c0f-364d-4f96-9a84-c0787826d966","uptime":{
"ms":810027}},"memstats":{
"gc_next":8809344,"memory_alloc":4998680,"memory_total":22847992},"runtime":{
"goroutines":22}},"filebeat":{
"harvester":{
"open_files":0,"running":0}},"libbeat":{
"config":{
"module":{
"running":0}},"pipeline":{
"clients":1,"events":{
"active":0}}},"registrar":{
"states":{
"current":2}},"system":{
"load":{
"1":0.18,"15":0.2,"5":0.31,"norm":{
"1":0.09,"15":0.1,"5":0.155}}}}}}
10-5-4.Logstash输出数据到Elasticsearch
通过控制台,我们发现Logstash input接收到的数据没有经过任何处理就发送给了output组件。而其实我们需要将数据输出到Elasticsearch。所以,我们修改Logstash的output配置。配置输出Elasticsearch
[wangting@es01 logstash-7.6.1]$ vim config/filebeat-es.conf
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => [ "es01:9200","es02:9200","es03:9200"]
}
stdout {
codec => rubydebug
}
}
重新启动Logstash
# 将前一次启动的logstash关闭ctrl+c
[wangting@es01 logstash-7.6.1]$ bin/logstash -f config/filebeat-es.conf --config.reload.automatic
循环追加日志模拟刷新信息:
[wangting@es01 app_log]$ while true; do sleep 5 && tail -1 login_info.log >> login_info.log ;done
验证:
通过head界面查看
[外链图片转存中…(img-xU8M5MMJ-1667553842717)]
[外链图片转存中…(img-fYOiYPKy-1667553842717)]
通过Kibana界面实践结果:
查询索引信息:
GET /_cat/indices?v
查看索引信息:
GET /logstash-2022.11.04-000001/_search?format=txt
Logstash功能不再展开介绍,这里只调试流程,介绍使用方式