一、故障发现到解决,仅用15分钟
一、问题描述
上午11点半左右,平台接到医院某软件PACS+数据库离线和CPU使用率异常告警。

(告警信息)
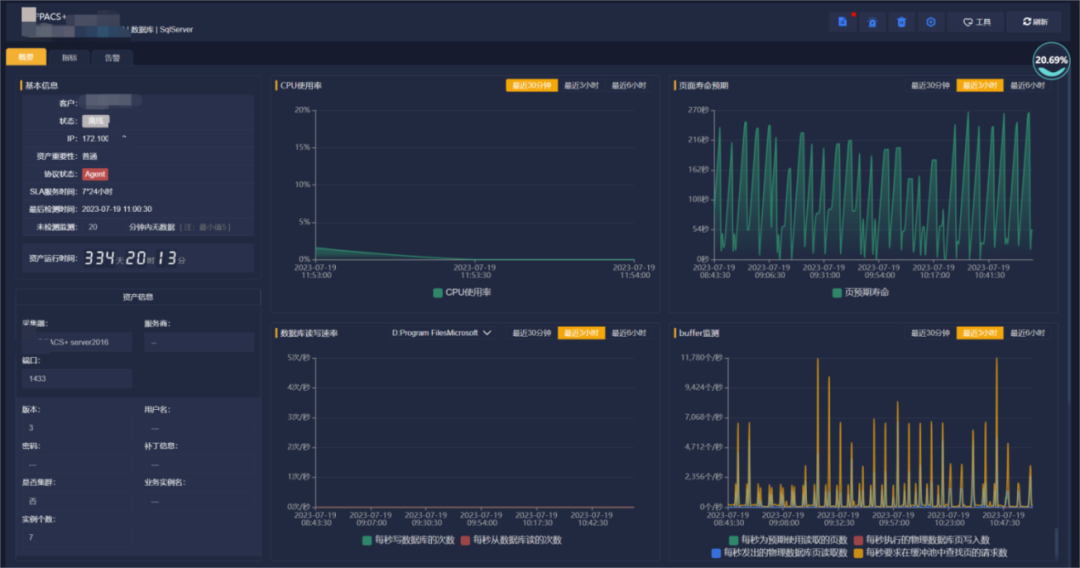
(告警详情)
二、查找问题的原因
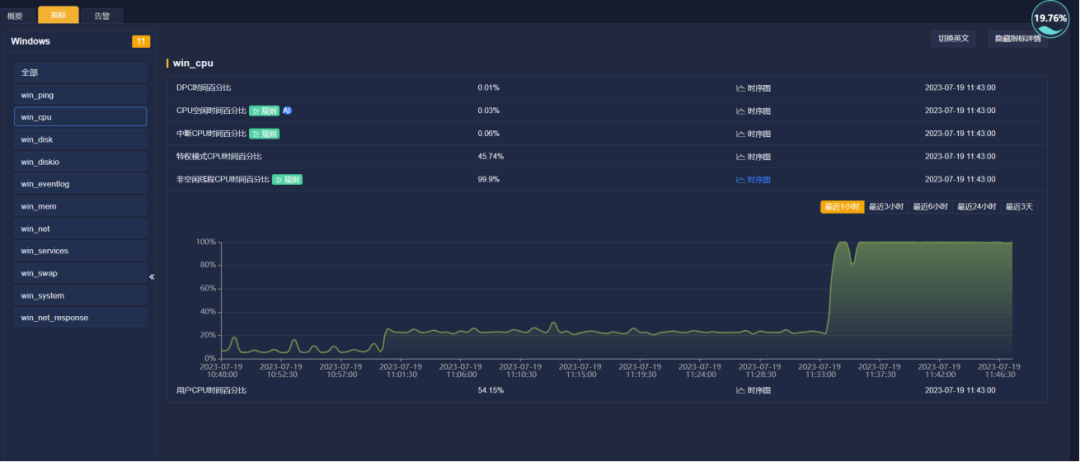
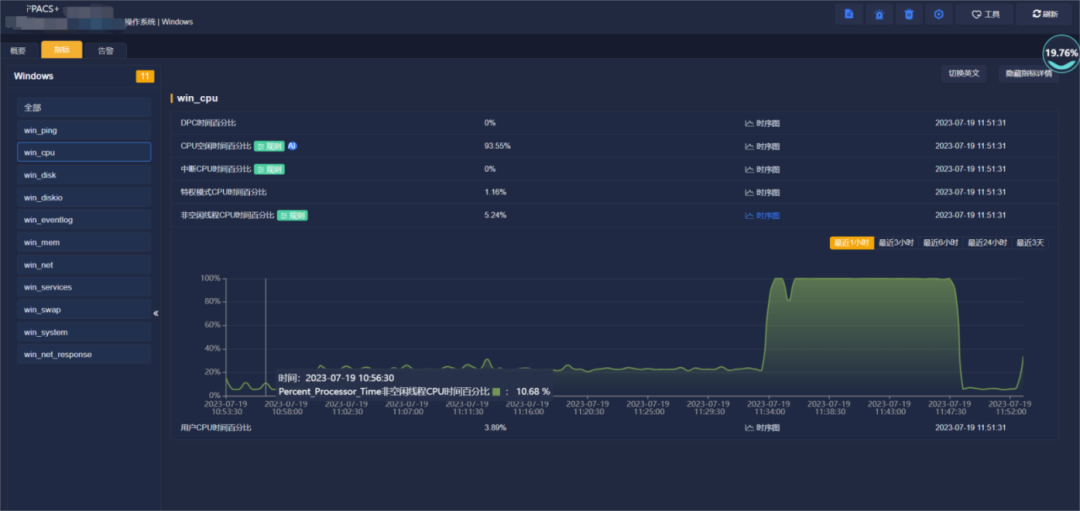
cpu使用率时序图
从CPU使用率时序图中,可以看到11点33分左右,CPU使用率迅速从20%左右增长到100%。因为操作系统的CPU资源不足,导致SQL Server数据库软件不能正常工作,平台检测不到数据库运维参数,生成离线告警。
三、问题处理步骤
1、通知现场工程师。
某软件PACS+数据库离线,需要协助排查软件PACS+数据库是否正常运行。现场工程师远程连接服务器,确认服务器操作系统正常运行。
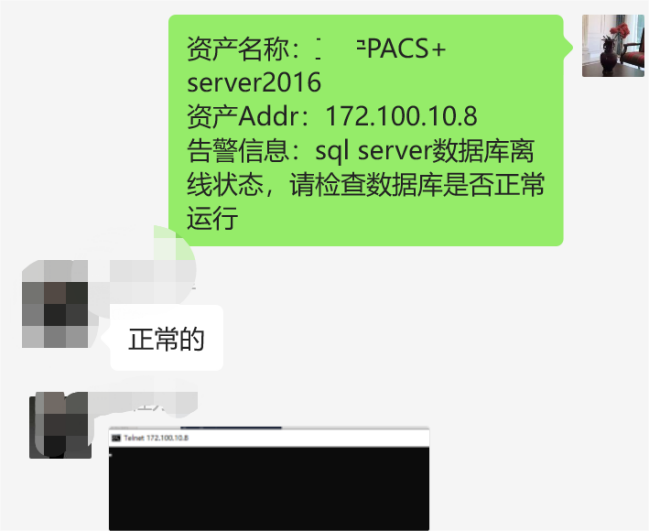
2、通知软件工程师查看SQL server数据库是否正常运行
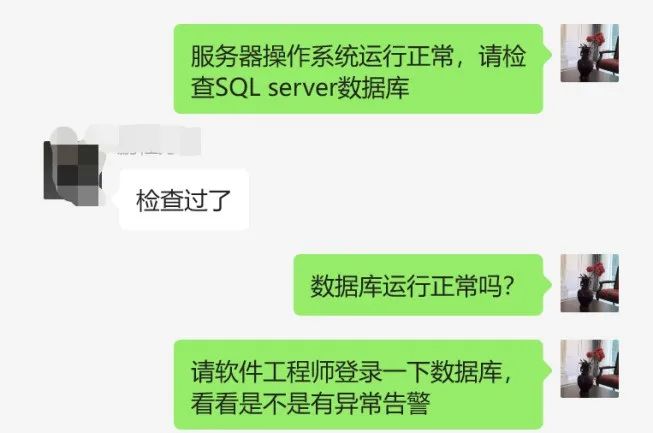
3、查找数据库离线原因
4、问题解决
将数据库重启,并对数据库占用资源设置限制,继续观察;
CPU使用率下降,恢复正常,Sql Server数据库运行正常。
小结:医院应用软件较多,软件工程师人力有限,未能及时发现PACS+数据库离线问题。MOC工程师在数据库卡死的第一时间联系用户工程师,并协助现场工程师进一步检查SQL server数据库。最终锁定数据库占用CPU资源未释放,将数据库使用资源情况做限定,从发现到问题解决只用15分钟。
二、减少90%以上IT故障,医院效率狂飙
医院运维的难点在于业务系统错综复杂,数据庞大、资产分布广,数据安全敏感。高度依赖信息系统稳定和安全运营。具有以下特点:
-
设备多、分布广,巡检工作量大,极易错检、漏检;
-
缺乏系统预警,无法预知设备运行状况;
-
故障处理无序状态,依赖个人技术、手工,分散运维,风险系数高。
LinkSLA深耕医疗行业,根据医院运维环境特点,打造专业的服务方案。
1、统一部署,全栈监控
医院拥有硬件设备、网络设备、数据库、中间件等多种资产,分别由不同的供应商提供维护服务。LinkSLA智能运维管家通过统一部署实现数据中心一体化监控和智能化运维,将所有的监控资源和对象统一采集,建立底层基础架构到上层业务应用的关联关系,在设备发生故障时,快速分析设备对业务系统造成的影响,有效降低故障风险。
LinkSLA智能运维管家SaaS云运维,降低部署难度可开箱即用,省去大量分级部署,迅速完成数据库、中间件、容器环境。大大提高运维效率。
2、AI趋势性预测,更精准高效
基于医院运维场景的需求和相关的时序数据集, 定制了ML算法(孤立森林、梯度提升树、 直方图检测),经过训练、调整后的模型, 实际验证准确率达到85%以上;经过一线值守服务的再次筛选,准确率达到95%左右。AI+人力服务最终达至了基本无误报的结果。
在业务数据上,提供一套完整的、处理分析与发现问题的算法。通过智能算法或规则实现异常监测,告警降噪,避免传统工具带来的告警风暴,集成告警事件工单,让故障得到快速响应。
3、MOC值守,诊断+修复
平台主动监控,MOC实时响应。基于资产价值定义SLA,量化服务水平,提供数字化决策依据。链接人员及流程,关联各种运维因子。平台内置ITIL流程,闭环运维,配套知识库,提供技能学习培训,避免人肉运维。也可远程申请MOC工程师协助,通过分析实时数据,查看时序图,迅速定位故障,实现高效远程协作指导。
4、极致的可视化用户体验
1、客户大屏
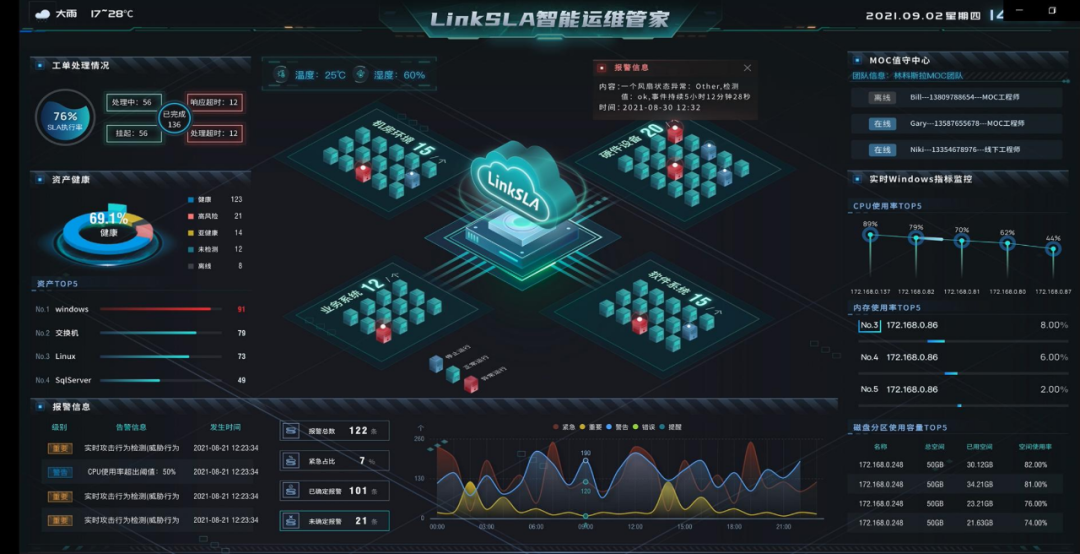
集中展示资产健康状况和服务水平
2、业务视图
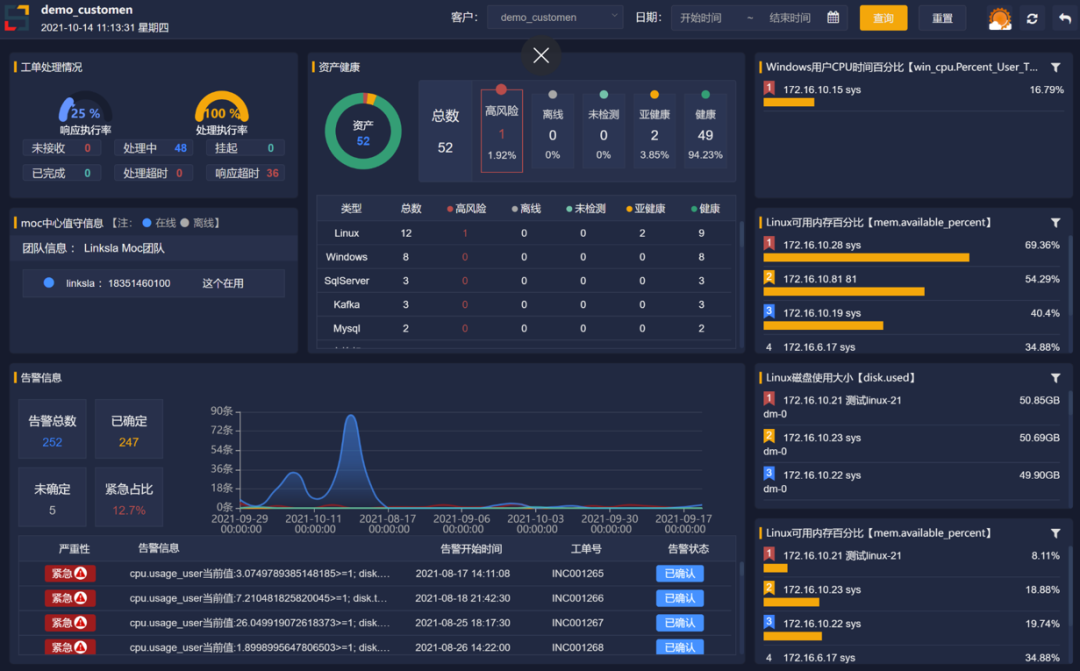
业务系统监控状况集中展示
3、工单详情
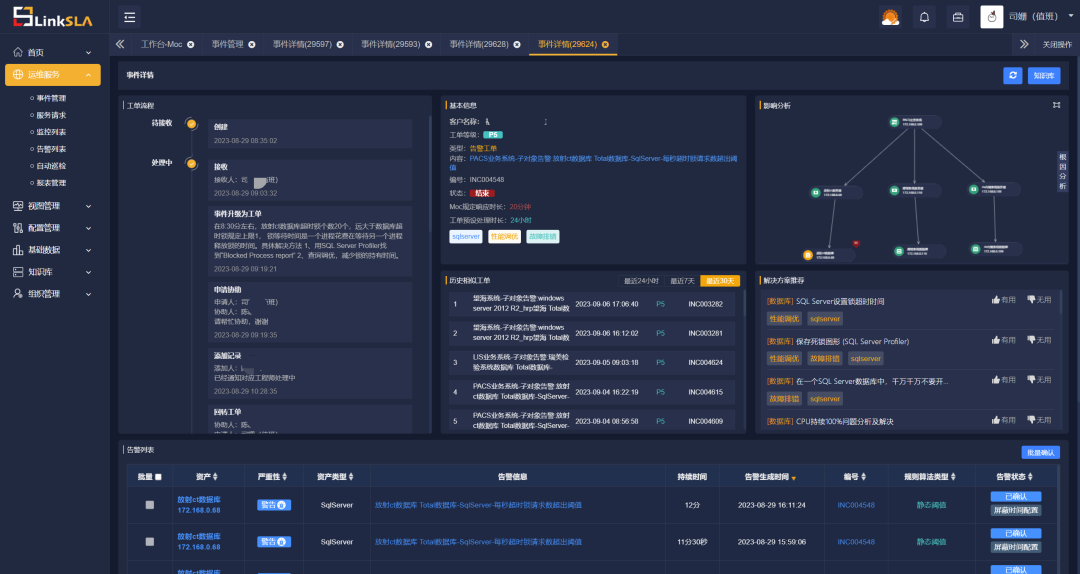
展示工单流程、基本信息、根因分析和历史相似工单
4、网络拓扑
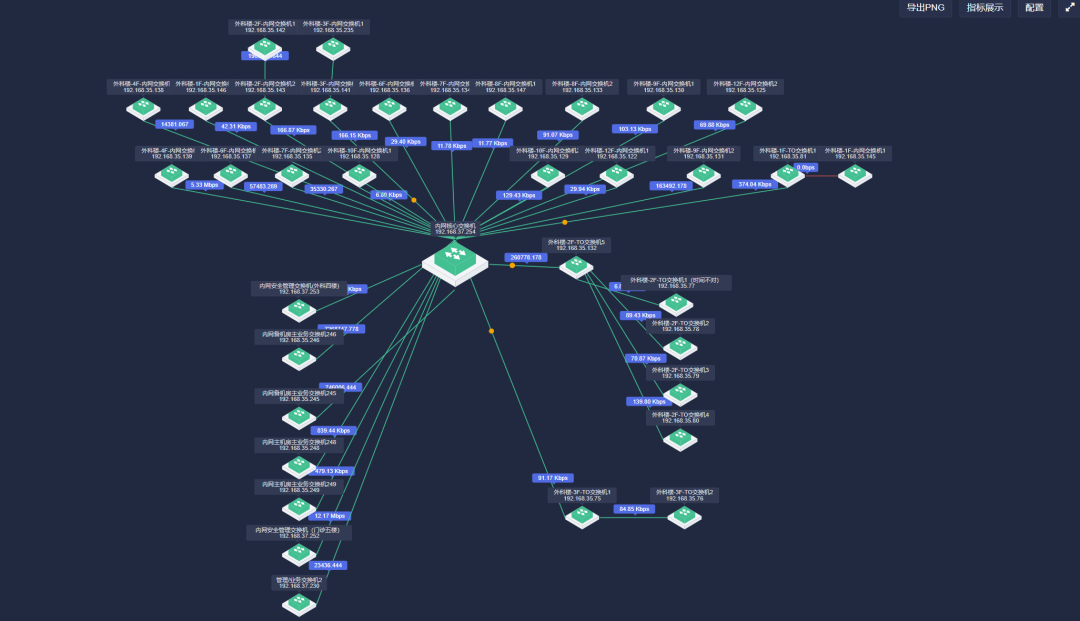
告警收敛和辅助根因分析的重要依据
将孤立分散的系统统一监控,减少重复和繁琐的日常巡检工作,使运维工作由被动变主动,提高IT服务的可用性、可靠性、和安全性的同时,实现低成本运维。LinkSLA智能运维管家,构建安全模式的纵深监控产品和服务,以稳定、高效、安全的特点助力智慧医疗加速发展。