1 推荐文章
2 什么是倒排索引,为什么这么叫?
倒排索引(Inverted Index)是一种为快速全文搜索而设计的数据结构。它被广泛应用于搜索引擎,其中 Elasticsearch(简称 ES)是一个主要的使用者。
2.1 什么是倒排索引?
传统的索引(例如书的索引或数据库的B-Tree索引)是“正向”的:它们从“文档到词汇项”的映射。换句话说,你查找文档,然后列出文档中的词汇项。
相反,倒排索引从“词汇项到文档”的映射。这意味着,对于索引中的每一个唯一的词汇项,都有一个相关的文档列表,这些文档包含该词汇项。
例如,考虑以下简单文档集:
1. Apple is tasty.
2. Banana is tasty.
3. Apple and banana are fruits.
一个简单的倒排索引可能是:
Apple -> 1, 3
Banana -> 2, 3
tasty -> 1, 2
...
2.2 为什么叫“倒排索引”?
这个名称的由来是因为它与“正向索引”相对立。正向索引直接映射文档到其中的词汇项,而倒排索引则相反,映射词汇项到包含它们的文档。
2.2 为什么使用倒排索引?
倒排索引尤其对于全文搜索很有用,因为:
- 速度:它允许快速查找包含特定词汇项的文档。
- 空间效率:只为唯一的词汇项保存索引,并与相关的文档关联,这避免了重复。
- 排名和相关性:使用倒排索引,可以很容易地为搜索结果进行排名,基于词频、文档频率等。
Elasticsearch 作为一个分布式搜索和分析引擎,大量使用倒排索引来实现其高速和高效的文本搜索功能。
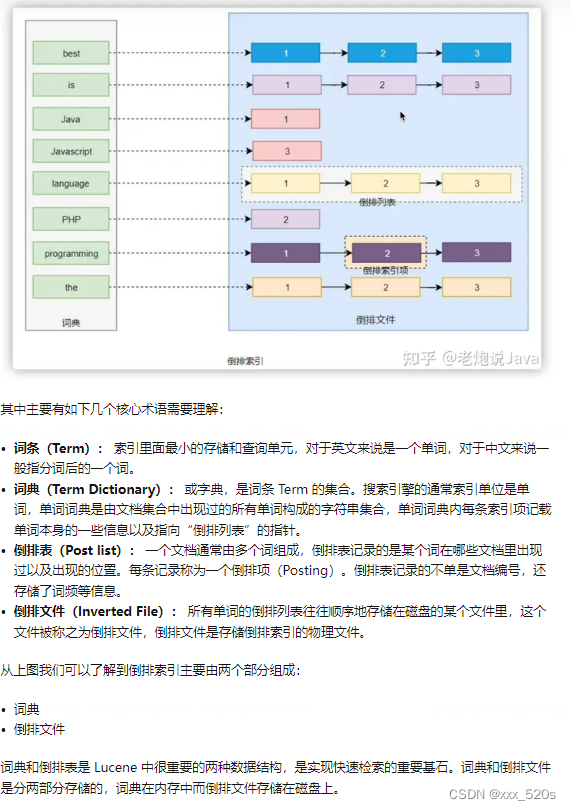
3 ES的内部FST索引

Elasticsearch 为了能快速找到某个 Term,先将所有的 Term 排个序,然后根据二分法查找 Term,时间复杂度为 logN,就像通过字典查找一样,这就是 Term Dictionary。
现在再看起来,和前缀树非常类似, 共享前缀,但是FST还能够共享后缀。但是如果 Term 太多,Term Dictionary 也会很大,放内存不现实,于是有了 Term Index。
就像字典里的索引页一样,A 开头的有哪些 Term,分别在哪页,可以理解 Term Index是一棵树。
这棵树不会包含所有的 Term,它包含的是 Term 的一些前缀。通过 Term Index 可以快速地定位到 Term Dictionary 的某个 Offset,然后从这个位置再往后顺序查找。
在内存中用 FST 方式压缩 Term Index,FST 以字节的方式存储所有的 Term,这种压缩方式可以有效的缩减存储空间,使得 Term Index 足以放进内存,但这种方式也会导致查找时需要更多的 CPU 资源。
对于存储在磁盘上的倒排表同样也采用了压缩技术减少存储所占用的空间。
3.1 ES中什么是FST
在Elasticsearch中,FST(Finite State Transducer)是一个数据结构,用于优化和压缩Term Dictionary。它是一种特殊的有限状态机,不仅可以表示键(在Elasticsearch的场景中,键通常是词项或term),还可以同时表示与该键关联的值。
以下是关于Elasticsearch中FST的一些核心点:
-
压缩:FST非常适合于压缩词典,因为它可以共享前缀和后缀。考虑到词汇中很多词项有共同的前缀和后缀,这种压缩方法是非常高效的。
-
快速查找:除了存储优势,FST还提供了快速的查找能力。当用户查询一个词项时,Elasticsearch可以迅速通过FST找到与该词项对应的元数据或其他相关信息。
-
存储键和值:与传统的前缀树(trie)不同,FST不仅存储词项(键)还可以存储与之关联的值。在Elasticsearch中,这些值可能是关于词项的元数据,例如其在倒排索引中的位置。
-
减少内存使用:由于其压缩特性,FST能够大大减少Term Dictionary在内存中的占用。这使得更多的数据可以被缓存在内存中,从而提高查询性能。
总之,在Elasticsearch中,FST是一个用于表示和压缩Term Dictionary的高效数据结构,使得Term Dictionary的存储更加高效,查询更加快速。
3.2 为什么前缀树也是一种有限状态机(FSM)
确切地说,前缀树(Trie)并不是FST(Finite State Transducer),但它们都属于有限状态机的范畴。FST是有限状态机的一个扩展,可以同时表示键和值。然而,Trie和FST都是基于有限状态机的数据结构,并且都能够有效地表示键的集合,这也是它们之间的相似之处。
让我们深入了解一下它们之间的区别和联系:
-
前缀树(Trie):
- Trie是一个树形数据结构,专门用于存储一个字符串集合。
- 它通过共享公共前缀来优化存储空间。
- 每个节点代表一个字符,从根节点到叶节点的路径表示一个字符串。
- Trie不直接存储与键关联的值,但可以将值附加到叶节点或某些特定节点上。
-
有限状态转换器(FST):
- FST是有限状态机的一个扩展,它可以表示状态之间的转换(即键)以及与每个转换关联的输出值。
- FST不仅可以共享前缀,还可以共享后缀,从而进一步压缩数据。
- 在FST中,一个状态可以代表一个字符串的前缀或后缀,或者代表一个完整的字符串。
- FST直接在其结构中表示与键关联的值。
由于FST能够共享前缀和后缀,并直接表示键和值,它比Trie更加灵活和高效,特别是在表示大量数据时。
简而言之,虽然Trie和FST都是基于有限状态机的数据结构,并有共享前缀的特性,但FST提供了更多的功能和更高的存储效率。在某些上下文中,如Elasticsearch的实现,FST由于其压缩和表示能力而被优先选择。
3.3 前缀树和FST的差异
FST和前缀树(Trie)在共享前缀的策略上是相似的。它们都会通过为字符串的每个字符建立路径来存储信息。在这种结构中,相同前缀的词汇会共享存储路径,直到它们的字符开始有所不同为止。
不过,FST与传统的前缀树有以下主要区别:
-
后缀共享:除了前缀共享,FST还试图共享后缀。这意味着,与前缀树可能会为相似的词后缀存储多次不同,FST会尝试重用和共享这些后缀,进一步减少所需的存储空间。
-
存储值:FST还能存储与键相关联的值。这使得FST可以被视为键-值映射,其中键是词项,值可以是任何相关数据,如词项在倒排索引中的位置。在Elasticsearch的上下文中,这通常是词项的元数据。
-
压缩:FST还采用了多种压缩技巧,以减少实际的存储需求。
总体而言,虽然FST和前缀树在共享前缀的基本策略上相似,但FST包含了更多的优化和扩展功能,使其在某些应用中更为高效。
3.4 FST是如何做到后缀共享的
让我们来详细讨论后缀共享。
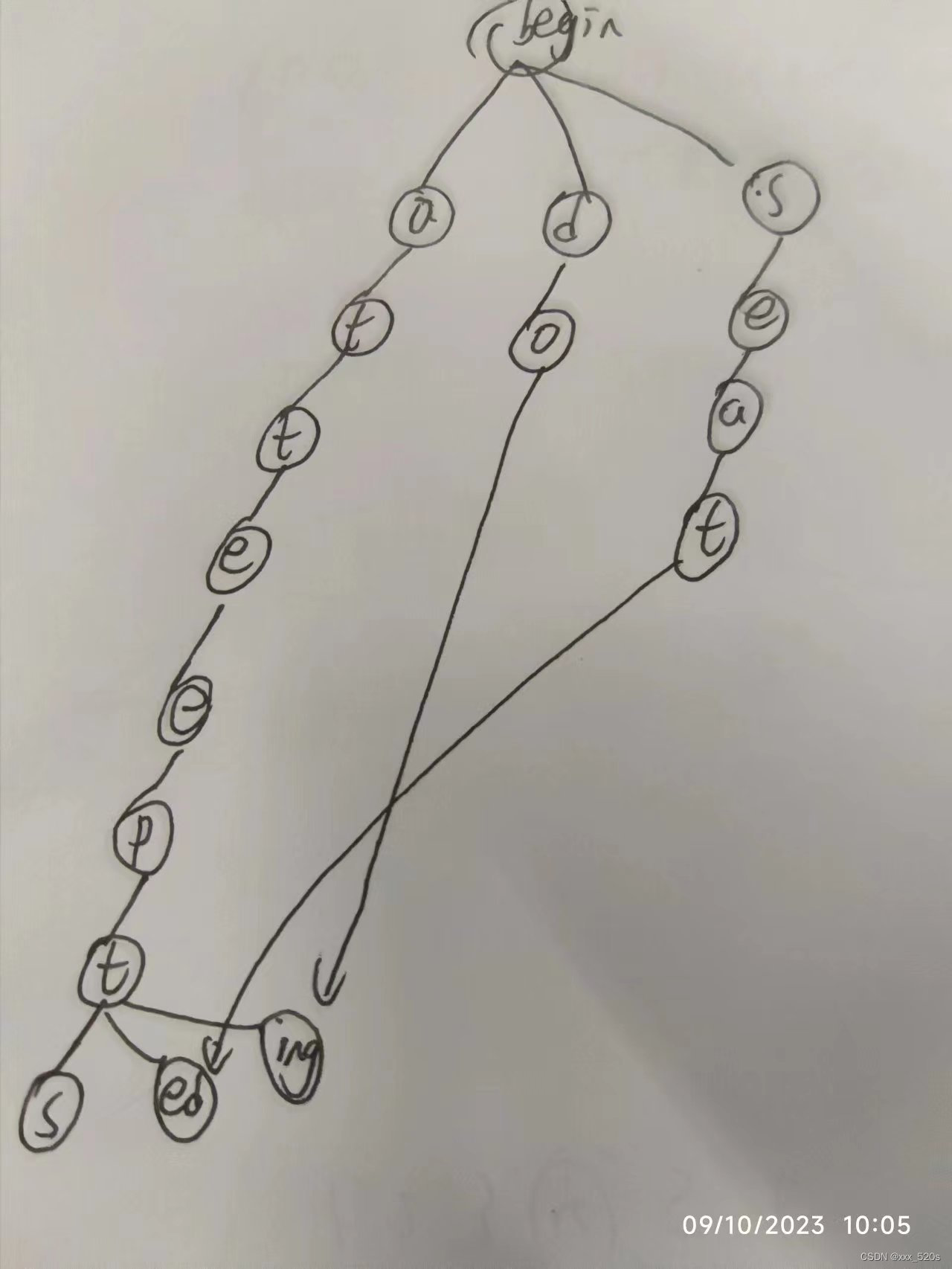
共享后缀在复杂的词集中更常见。考虑一组更复杂的词,例如:["attempt", "attempts", "attempted", "attempting", "doing", "seated"]。
在这些词中,我们看到了前缀"attempt"的共享,但还有后缀"s", "ed", 和"ing"。
为了构建一个考虑到后缀共享的FST:
- 从开始状态,我们首先连接到字符
a,然后依次到t,t,e,m,p。 - 到此为止,我们已经表示了词
"attempt"。 - 从
"attempt"的最后一个字符"t",我们可以分叉到三个不同的后缀:"s"表示"attempts""ed"表示"attempted""ing"表示"attempting"
- 为"doing"建立树中节点时,会依次向下层建立d->o节点,然后o节点的指针会指向3中的ing节点,这时ing实现了后缀共享
- 同理,为seated词条建立4个层级的节点,ed直接复用3中早已经建立的后缀
每个后缀都在FST中只存储一次,从而实现了后缀的共享。
共享前缀和后缀是FST高效性的关键。在真实的数据集中,这种共享可以极大地压缩存储需求,特别是当词集包含许多变种和派生词时。
可以如下图所示,看到上面这个例子中的后缀共享方法
3 使用ES查找流程
3.1 先弄清楚ES的主要数据结构
3.2 使用ES作为搜索引擎的查找流程
Elasticsearch(ES)是一个基于Lucene库的搜索引擎。当你在ES上执行搜索时,它会经过以下主要步骤:
-
查询解析:
- 用户发出查询请求,通常是一个JSON结构。
- ES解析这个请求,将查询语句转换为适合Lucene处理的内部格式。
- 这包括分析查询字符串、识别查询类型(如
match,term,range等)和其他可能的查询参数。
-
文本分析:
- 如果查询涉及到文本搜索,那么输入的文本会被分析。
- 分析器(Analyzer)会将文本拆分为单个的词条也称分词(tokens),并可能执行其他操作,如小写化、去除停用词或应用词干提取。
- 这个过程确保查询的词条和索引中的词条在相同的格式下。
-
查找Term Dictionary:
- 对于每个词条,ES首先会查找词汇表(Term Dictionary)来找到该词条的元数据和位置信息。这通常使用FST(Finite State Transducer)来优化查找速度。
-
倒排索引查找:
- 一旦找到词条,ES会查阅倒排索引来找出包含该词条的所有文档ID。
- 对于多词条查询,ES会为每个词条执行此操作,并根据查询类型(例如布尔查询)组合结果。
-
打分和排序:
- 使用BM25算法(默认)或其他相关性算法,ES为每个匹配的文档计算一个分数。
- 这个分数表示文档与查询的相关性。
- 所有匹配的文档根据分数进行排序。
-
获取文档:
- ES从主索引中获取与最高分匹配的文档的完整版本。
- 可以根据查询的需要返回所有或部分字段。
-
高亮和聚合(如果请求):
- 如果查询请求中包含高亮指令,ES会标记查询匹配的部分。
- 如果请求中包含聚合,ES会根据指定的字段和聚合类型计算统计信息。
-
返回结果:
- ES构建一个JSON响应,其中包含匹配的文档、分数、可能的高亮和聚合结果,并将其返回给客户端。
这就是ES的基本搜索流程。当然,实际操作可能会涉及更多的复杂性,例如分片的处理、多节点查询和结果合并、过滤器的应用等。
3.3.1 一般的浏览器的搜索引擎就是使用ES的吗?
不是。浏览器中的主要搜索引擎如Google、Bing、Yahoo等都使用的是他们自己的专有搜索技术。Elasticsearch通常用于网站内的搜索、日志分析、实时应用监控和其他场景,而不是为全球范围的网页搜索设计的。
3.3.2 ES返回的结果是docid对应的文档的元数据信息吗?还是文档内容?
ES返回的结果既可以是文档的元数据,也可以是文档的实际内容。当执行搜索查询时,你可以指定需要哪些字段作为返回结果。如果没有指定,那么默认情况下,ES会返回整个文档。
3.3.3 ES的BM25算法是什么?
BM25是一种现代的、基于概率的文档排序算法,被认为比传统的TF-IDF方法更有效。BM25考虑了词条频率(TF)和逆文档频率(IDF)来计算文档的相关性分数,但与TF-IDF相比,它对高频词条有一个上限,这可以避免某些词条过度影响文档的相关性得分。
3.3.4 获取文档: 这里的主索引是什么索引和FST的区别
当我们提到Elasticsearch的“主索引”,我们是指存储文档的数据结构, 类似于OS中的索引节点方式,主索引节点只存储文档的元数据信息和一个指向文档位置的指针。在这里,文档是按照其ID存储和检索的。FST是用于存储和查找词汇表中词项的数据结构。简单来说,主索引关注的是整个文档,而FST关注的是文档中的词条。
3.3.5 为什么仅仅只返回部门字段,这里的字段包含什么?
在某些场景下,为了提高效率和减少网络传输,你可能只对文档的某些字段感兴趣,而不是整个文档。例如,如果你的文档是一个包含多个字段的用户资料,但你只需要姓名和电子邮件地址,那么可以指定只返回这两个字段。在ES查询时,可以使用"_source"参数指定返回哪些字段。这里的“字段”指的是文档内的任何属性,例如标题、作者、发布日期等。
4 一般的浏览器的搜索引擎就是使用ES的吗
不是。浏览器中的主要搜索引擎如Google、Bing、Yahoo等都使用的是他们自己的专有搜索技术。Elasticsearch通常用于网站内的搜索、日志分析、实时应用监控和其他场景,而不是为全球范围的网页搜索设计的。
5 为什么ES是准实时的
6 ES怎么用
6.1 Elasticsearch是否单独建一个项目,作为全文搜索使用,还是直接在项目中直接用?
这取决于你的需求和项目的复杂性。很多公司和项目都选择将Elasticsearch作为一个单独的服务或微服务运行,与主应用分开。这样做的好处是,它可以独立于主应用进行扩展,维护和更新,从而实现了解耦。但如果你的应用较小,或者你只是想快速地进行原型开发,那么可以直接在应用中集成Elasticsearch。
6.2 新增数据时,插入到mysql中,需不需要同时插入到es中?
如果你依赖Elasticsearch进行搜索或其他需要快速读取的操作,当你在MySQL中插入数据时,你也应该将这些数据插入到Elasticsearch中。这样,你可以确保当用户尝试搜索新添加的内容时,Elasticsearch的索引是最新的。有多种方法可以做到这一点,例如使用日志文件同步或使用工具和库,如Logstash或Debezium。
当你在MySQL中新增数据并希望这些数据在Elasticsearch中可搜寻,你需要确保这些数据也被同步到Elasticsearch。关于数据同步的触发方式,有几种常见的方法:
-
客户端发起的双重写入: 当应用程序(客户端)在MySQL中插入数据后,它也可以负责将同样的数据发送到Elasticsearch。这种方法的挑战在于确保两边的写入都成功,否则可能出现数据不一致的情况。
-
MySQL的binlog监听与同步: 使用如Debezium或Logstash等工具监听MySQL的binlog(二进制日志),当检测到有新的数据变更时,自动将变更推送到Elasticsearch。这种方式相对客户端双重写入更为可靠,因为它确保了即使应用程序出现问题,数据也能被正确同步。
-
周期性的数据同步: 设定一个定时任务,例如每隔几分钟,检查MySQL的新数据,并同步到Elasticsearch。这适用于数据实时性要求不高的场景。
-
触发器: 在MySQL中设置触发器,当有新的数据插入或变更时,触发某些操作进行同步。但这种方法可能影响MySQL的性能,并且需要额外的工作来确保同步的成功。
总的来说,选择哪种方法取决于你的具体需求和系统的架构。但通常,监听binlog的方式因其相对的可靠性和低延迟而被广泛采用。
6.3 搜索时直接返回es搜索的结果,还是需要根据es的结果中的id,回mysql中重新查一遍?
这同样取决于你的应用和需求。在某些场景下,用户可能只需要从Elasticsearch中获取的元数据,所以直接返回Elasticsearch的结果就足够了。在其他情况下,可能需要返回更多详细的信息,那么可以使用Elasticsearch提供的ID在MySQL中进行查找。
关于使用MySQL:Elasticsearch主要是为搜索和分析设计的,并不是为了替代传统的关系数据库。MySQL(或其他RDBMS)提供了事务性、完整性、备份和恢复等功能,这些都是Elasticsearch不擅长或不支持的。而Elasticsearch主要针对的是大量数据的快速搜索和分析。所以,一般来说,MySQL用作主要的数据存储,而Elasticsearch用作搜索和分析工具。
7 ES在秒杀系统中的应用场景
7.1 我的秒杀系统中,哪一个部分可以用到这个ES呢
Elasticsearch(ES)主要用于搜索和分析大量数据。在一个秒杀系统中,这样的功能可能不是核心,但还是有一些地方可能会从ES中受益:
-
商品搜索: 如果你的秒杀系统有大量的商品或多次的秒杀活动,ES可以帮助用户快速找到他们感兴趣的商品。用户可以通过关键字、品牌、类别等进行高效搜索。
-
日志分析: 秒杀系统通常会面临巨大的流量。使用ES,你可以对系统的日志进行实时分析,快速发现任何潜在的问题、瓶颈或攻击。
-
用户行为分析: 通过将用户的浏览、点击和购买行为数据发送到ES,你可以进行深入的分析,了解用户的兴趣和行为模式,并据此优化秒杀活动的策略。
-
库存监控: 尽管MySQL或其他关系数据库是管理库存的首选,但在面对巨大的流量时,ES可以为你提供一个近实时的库存状态的快照,帮助你监控并调整策略。
-
推荐系统: 根据用户的搜索和购买历史,ES可以帮助你实现一个基本的推荐系统,为用户推荐可能感兴趣的商品。
-
报警系统: 你可以设置某些阈值或模式在ES中,并当达到这些条件时发送警报。例如,当某个商品的库存低于某个数量时,或当检测到异常流量时。
尽管如此,对于秒杀系统的核心功能,如库存减少、订单处理等,传统的关系数据库或特定的分布式解决方案更为合适。ES的主要价值在于它提供的搜索和分析功能。
7.2 如何使用ES实现商品搜索功能
7.2.1 如果我想在个人的秒杀系统中实现这个功能,应该如何使用
要在秒杀系统中实现商品搜索功能并使用Elasticsearch (ES),你可以按照以下步骤操作:
a. 数据同步:
当新的商品添加到秒杀活动中时(通常存储在MySQL中),同时将这些商品数据同步到Elasticsearch中。可以使用工具如Logstash、Debezium等来实现MySQL到Elasticsearch的数据同步,或者在你的应用层代码中同时向两者写入数据。
b. 数据结构设计:
在Elasticsearch中,你需要为商品数据定义一个合适的索引结构,考虑哪些字段需要被索引、哪些字段可能会用于过滤等。
c. 搜索接口:
在你的秒杀系统中,为用户提供一个搜索接口。当用户输入关键词并发起搜索请求时,你的系统应该向Elasticsearch发起查询,并返回搜索结果给用户。
7.2.2 在这个系统中,ES和mysql,redis之间的关系是什么,三者之间的数据流向是怎么样的
1 a. MySQL:
- 主要作用: 存储商品信息、用户信息、订单数据等核心数据。
- 与Elasticsearch的关系: 作为数据的主源,新的商品或更新的商品数据从MySQL同步到Elasticsearch。
2 b. Elasticsearch (ES):
- 主要作用: 提供高速、全文商品搜索功能。
- 数据流向:
- 来自MySQL: 新的或更新的商品数据被同步到ES。
- 到前端: 当用户发起搜索请求,系统查询ES并将结果返回给用户。
3 c. Redis:
- 主要作用: 由于秒杀活动的高并发特性,Redis常被用于缓存、库存计数、限流等功能。
- 与MySQL的关系: 商品的库存、用户的购买记录等可能会被缓存到Redis,以提供更快的读写速度。当库存发生变化,如秒杀成功,数据可能会先写入Redis,并在合适的时机同步回MySQL。
- 与Elasticsearch的关系: 通常二者之间没有直接的数据交互。但在某些场景下,如基于用户行为的实时商品推荐,Redis中的用户行为数据可能会被用于查询Elasticsearch。
4 总结:
- 当新商品加入时:应用 -> MySQL -> Elasticsearch。
- 当用户搜索时:应用查询 -> Elasticsearch -> 应用返回结果给用户。
- 秒杀或高并发操作:应用 -> Redis ->(延迟或批量同步)-> MySQL。
这种架构允许每种技术发挥其最大的优势,同时保证数据的完整性和系统的高可用性。
7.3 当新的商品添加到秒杀活动中时(通常存储在MySQL中),同时将这些商品数据同步到Elasticsearch中,如果数据库中库存更新成功,但是ES更新失败,怎么处理
当MySQL更新成功而Elasticsearch更新失败时,这是一个典型的分布式系统数据一致性问题。以下是几种常用的解决策略:
- 重试机制:如果失败是由于临时的网络问题或其他短暂的原因,可以简单地重试更新Elasticsearch。
- 日志记录:记录所有失败的更新操作,这样管理员可以手动介入或者通过脚本来重新处理这些失败的操作。
- 使用队列:将更新操作放入一个消息队列,如RabbitMQ或Kafka。消费者从队列中取出操作并尝试更新Elasticsearch。如果失败,可以重新放回队列并稍后重试。
7.4 在Elasticsearch中,你需要为商品数据定义一个合适的索引结构,考虑哪些字段需要被索引、哪些字段可能会用于过滤等。你能帮我设计一个索引结构吗
{
"mappings": {
"properties": {
"product_id": {
"type": "keyword"
},
"product_name": {
"type": "text",
"analyzer": "standard"
},
"description": {
"type": "text",
"analyzer": "standard"
},
"price": {
"type": "float"
},
"stock": {
"type": "integer"
},
"category": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"tags": {
"type": "keyword"
},
"created_at": {
"type": "date"
}
}
}
}
7.4.1 是的,标记为"type": "text"和"analyzer": "standard"的字段在Elasticsearch中会被分析,并生成词条(Terms)。"standard"分析器会对文本进行一系列的处理步骤,包括:分词、小写转换和某些常见的标点符号移除。
例如,假设有一个字段值为 “ElasticSearch is Great!”。使用"standard"分析器,这个文本可能会被分为三个词条:elasticsearch、is 和 great。
当我们在搜索时使用这些词条,Elasticsearch会使用这些生成的词条来进行匹配,从而实现文本搜索的功能。
另外,对于标记为"type": "keyword"的字段,它们不会被分析,而是作为整体存储和索引。这意味着这些字段的值会被看作是一个单一的词条,适用于那些不需要分词的字段,如标签、类别等。
7.5 应用查询的问题:
确实,从Elasticsearch查询返回的是结构化的JSON字符串。使用业务服务器作为中间层进行查询有几个原因:
- 安全性:直接让前端与Elasticsearch通信可能会暴露Elasticsearch的细节,可能被恶意用户利用。
- 灵活性:使用业务服务器作为中间层可以轻松更改或增强查询逻辑。
- 负载均衡与缓存:业务服务器可以进行查询结果缓存、负载均衡等优化。
7.6 业务服务器发送ES请求示例:
使用java的Elasticsearch客户端库为例:
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
public class ESExample {
public static void main(String[] args) throws IOException {
// 创建Elasticsearch客户端
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
// 插入数据
IndexRequest indexRequest = new IndexRequest("products");
indexRequest.id("1");
String jsonString = "{" +
"\"product_name\":\"电视\"," +
"\"price\":2999.99," +
"\"stock\":100" +
"}";
indexRequest.source(jsonString, XContentType.JSON);
client.index(indexRequest, RequestOptions.DEFAULT);
// 查询数据
SearchRequest searchRequest = new SearchRequest("products");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("product_name", "电视"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
searchResponse.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
// 删除数据
DeleteRequest deleteRequest = new DeleteRequest("products", "1");
client.delete(deleteRequest, RequestOptions.DEFAULT);
client.close();
}
}
这个示例中,我们首先连接到Elasticsearch服务,然后构建一个简单的匹配查询来搜索商品名称中包含“电视”的商品,最后打印每个命中的商品的源数据。
7.6.1 假如我要插入多个这样的商品,还说在products下添加吗?
是的,如果你要插入多个商品,你会在同一个products索引下添加多个文档。每个文档都有一个独特的ID,在这个例子中,该ID被硬编码为"1"。但在实际情况下,每个商品都应该有一个独特的ID,这样你就可以唯一地标识和引用它。
如果你要批量插入多个商品,你可以使用Elasticsearch的BulkRequest来一次性执行多个操作,这通常比单独发送每个请求更高效。
下面是一个批量插入的示例:
BulkRequest bulkRequest = new BulkRequest();
// 第一个商品
IndexRequest firstProduct = new IndexRequest("products");
firstProduct.id("1");
String firstProductJson = "{" +
"\"product_name\":\"电视\"," +
"\"price\":2999.99," +
"\"stock\":100" +
"}";
firstProduct.source(firstProductJson, XContentType.JSON);
bulkRequest.add(firstProduct);
// 第二个商品
IndexRequest secondProduct = new IndexRequest("products");
secondProduct.id("2");
String secondProductJson = "{" +
"\"product_name\":\"冰箱\"," +
"\"price\":3999.99," +
"\"stock\":50" +
"}";
secondProduct.source(secondProductJson, XContentType.JSON);
bulkRequest.add(secondProduct);
// ... 添加更多的商品
client.bulk(bulkRequest, RequestOptions.DEFAULT);
这样,所有的商品都会被存储在products索引下,每个商品都有其独特的ID。当你查询products索引时,你会得到所有存储在其中的商品。
7.6.2 这里的products相当于命名空间,每一个空间都有一个FST,这个空间下的所有被标记为text和keyword的字段都会作为FST的一部分,是这样的吗?
差不多,但有一些细节需要明确:
-
索引:在Elasticsearch中,
products是一个索引,而不只是一个命名空间。这个索引包含了映射(定义了字段的数据类型和其他属性)和文档数据。 -
FST:FST(有限状态转换器)是Elasticsearch用于压缩存储terms的数据结构,主要用于term dictionary。但并非每个字段都会有一个FST。只有被索引的字段(如标记为
text或keyword的字段)会在term dictionary中有条目,因此它们可能会使用FST。 -
映射类型:在早期的Elasticsearch版本中,一个索引可以有多个映射类型,这使得同一个索引可以存储结构不同的文档。但从Elasticsearch 7.0开始,索引只能有一个映射类型,这使得索引的使用更加简单和直观。
-
字段和FST:对于
text类型的字段,Elasticsearch会将它们分词,并将这些terms存储在term dictionary中。这些terms被用来建立FST。对于keyword类型的字段,整个字段值被视为一个单一的term并存储在term dictionary中。 -
多字段:有时,你可能想要将一个字段既作为
text(进行分词和搜索)又作为keyword(用于聚合或精确匹配)进行索引。Elasticsearch允许你这样做,通过所谓的"multi-fields"。例如,一个字段可以主要被视为text,但也可以有一个keyword子字段。
所以,简而言之,索引products中被标记为text和keyword的字段会被加入term dictionary,并且这个dictionary可能使用FST进行压缩存储。
7.6 大厂目前采用的是哪种mysql到ES的同步的方式呢,讲一讲具体的同步过程
大型公司(“大厂”)在选择MySQL到Elasticsearch的同步方式时,通常会根据自身的业务需求、现有技术栈和数据稳定性/实时性的要求进行选择。以下是一些常见的同步方式以及可能被大型公司采用的理由:
-
Logstash的JDBC插件:
- 优点:配置简单,易于启动,无需大量开发工作。
- 缺点:可能不适合高度实时的同步需求,因为它通常是基于轮询的。
- 适用场景:对数据同步实时性要求不高,或者是初步尝试Elasticsearch的公司可能会选择这种方法。
-
Debezium与Kafka:
- 优点:基于CDC(Change Data Capture),可以实时捕获数据库变更,结合Kafka可以确保数据的高度可靠性和扩展性。
- 缺点:需要额外的组件(如Kafka)和配置工作,可能需要更多的运维努力。
- 适用场景:对数据同步有实时性要求,且已经有Kafka基础设施的公司可能会选择这种方法。
-
Kafka Connect:
- 优点:与Debezium类似,Kafka Connect也是基于CDC,但它是Kafka的官方组件,与Kafka集成更加紧密。
- 缺点:同样需要Kafka基础设施。
- 适用场景:已经使用Kafka并希望进一步简化集成的公司可能会考虑这种方法。
-
自定义同步工具:
- 优点:完全根据公司的特定需求定制,可以对同步过程进行深度优化。
- 缺点:开发和维护成本高。
- 适用场景:有特定同步需求或希望深度集成的公司可能会开发自己的同步工具。
总的来说,不同的公司可能根据自己的业务场景和技术背景选择不同的方法。例如,已经大规模使用Kafka的公司可能会选择Debezium或Kafka Connect。而对实时性要求不高或者希望快速实验的公司可能会首先尝试Logstash的JDBC插件。
在大型互联网公司中,因为数据的实时性和稳定性都很关键,所以基于CDC的方法(如Debezium和Kafka Connect)比较受欢迎。但同时,一些大公司也可能因为自己的特定需求而开发自定义的同步工具。
7.7 对于秒杀系统,数据的实时性要求高吗?
对于秒杀系统,数据的实时性要求非常高。秒杀活动通常涉及到限时、限量的商品抢购,因此几个关键方面对实时性的要求尤为重要:
-
库存实时性:在秒杀活动中,商品的库存数量是非常关键的。如果系统不能实时更新和反馈库存信息,可能会导致超卖(即实际售出的数量超过库存)。超卖不仅可能导致退款和客户满意度下降,还可能面临法律风险。
-
订单处理实时性:一旦用户点击“购买”按钮,系统必须立即处理订单,确认是否可以完成交易。任何延迟都可能导致用户体验下降,甚至可能导致系统崩溃。
-
用户反馈实时性:秒杀活动中,用户总是希望能够实时知道自己是否成功抢到商品。任何延迟或误导性的信息都可能导致用户的不满。
-
流量监控和调整:由于秒杀活动通常引发大量流量,系统需要实时监控流量情况,并能够进行快速调整,以应对可能的流量峰值。
-
通知与消息实时性:关于秒杀活动的开始、库存变动或者其他相关信息,需要实时通知给用户,确保用户不会错过任何关键时刻。
考虑到上述的实时性需求,秒杀系统通常需要采用高性能、低延迟的技术解决方案,并在设计时特别考虑到高并发和高可用性。
7.8 kafka connect如何实现mysql到ES的数据同步(秒杀系统中同步商品)
Kafka Connect是一个可扩展的工具,用于将数据从不同的源系统导入Apache Kafka,以及将数据从Kafka导出到目标系统。要实现MySQL到Elasticsearch的数据同步,你可以使用Kafka Connect与特定的连接器(Connector)来实现。以下是实现步骤的大致流程:
-
使用Debezium Connector for MySQL:
- Debezium是一个开源的CDC(Change Data Capture)工具,可以捕获和监听数据库的变更事件。
- 对于MySQL,Debezium会监听其binlog来捕获数据更改,并将这些更改事件发布到Kafka主题。
-
设置Kafka Connect Elasticsearch Connector:
- Kafka Connect有一个官方的Elasticsearch连接器,它可以将数据从Kafka主题消费并写入Elasticsearch。
-
步骤:
a. 设置Debezium Connector for MySQL:
- 确保MySQL的binlog功能已开启。
- 配置Debezium,指定MySQL的相关参数。
- 启动Debezium Connector,此时它将开始监听MySQL的数据更改并发送到指定的Kafka主题。
b. 设置Kafka Connect Elasticsearch Connector:
- 配置连接器,指定Elasticsearch的相关参数,如地址、索引名称等。
- 指定从哪个Kafka主题读取数据。
- 启动Elasticsearch Connector,此时它将从指定的Kafka主题中获取数据并写入Elasticsearch。
-
操作:
- 一旦上述步骤设置完成,你在MySQL中做的任何数据更改(如插入、更新或删除)都会被Debezium捕获,并通过Kafka发送到Elasticsearch。
-
注意事项:
- 确保Kafka集群具有足够的资源和容量,以处理从MySQL捕获的数据变更。
- 考虑Kafka主题的分区和复制策略,以确保数据的高可用性和持久性。
- 在生产环境中,你可能需要考虑数据的转换、过滤或其他逻辑,可以使用Kafka Connect的Transform API进行处理。
使用Kafka Connect进行MySQL到Elasticsearch的数据同步,不仅可以确保数据的实时性,还可以利用Kafka作为一个缓冲区,以减少系统压力和确保数据的可靠性。