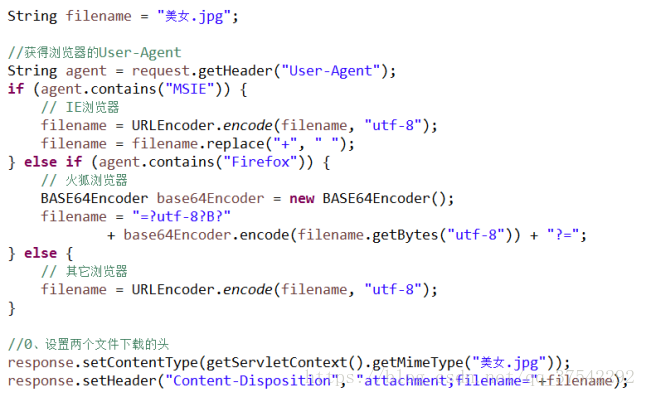
但是,如果下载中文文件,页面在下载时会出现中文乱码或不能显示文件名的情况, 原因是不同的浏览器默认对下载文件的编码方式不同,即是UTF-8编码方式,而火狐 浏览器是的Base64编码方式。所里这里需要解决浏览器兼容性问题,浏览解决器兼容 性问题的首要任务是要辨别访问者是即还是火狐(其他),通过的Http请求体中的一个属性可以辨别


解决乱码方法如下(不要记忆 -了解):
if(agent.contains(“MSIE”)){
// IE浏览器
filename = URLEncoder.encode(文件名,“utf-8”);
filename = filename.replace(“+”,“”);
} else if(agent.contains(“Firefox”)){
//火狐浏览器
BASE64Encoder base64Encoder = new BASE64Encoder();
filename =“=?utf-8?B?”
+ base64Encoder.encode(filename.getBytes(“utf-8”))+“?=”;
} else {
//其它浏览器
filename = URLEncoder.encode(文件名,“utf-8”);
}
其中代理就是请求头的User-Agent的值