括号里都是弹幕大佬的高赞发言
1 前言

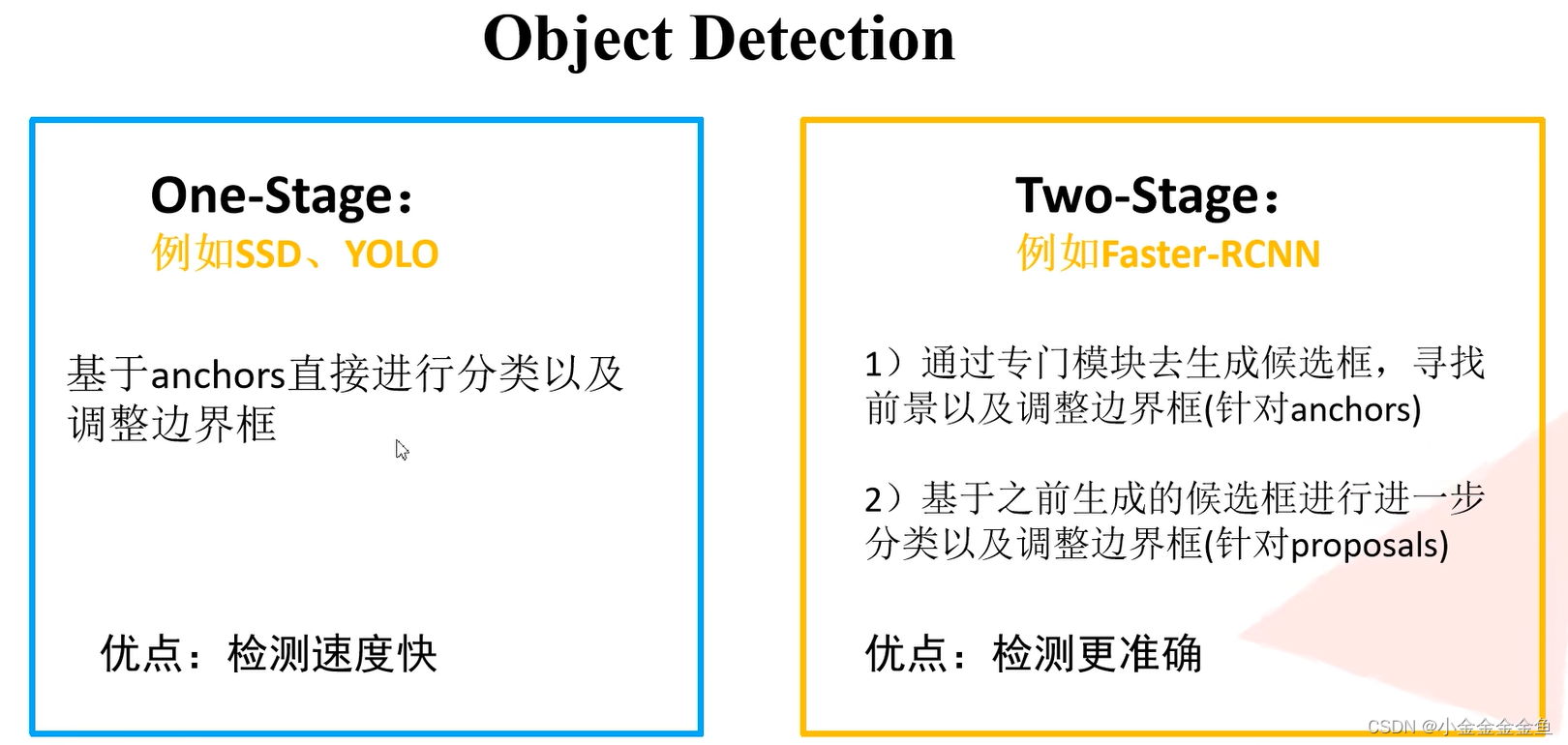
Two Stage检测过程分两步走
前景:需要检测的目标
背景:不感兴趣的
生成候选框:将感兴趣目标框选出来,但是没有进行分类

具体使用哪一种,根据项目需求
自定义数据集
自己写一个dataset,而不是使用pytorch提供的一些方法读取图像文件

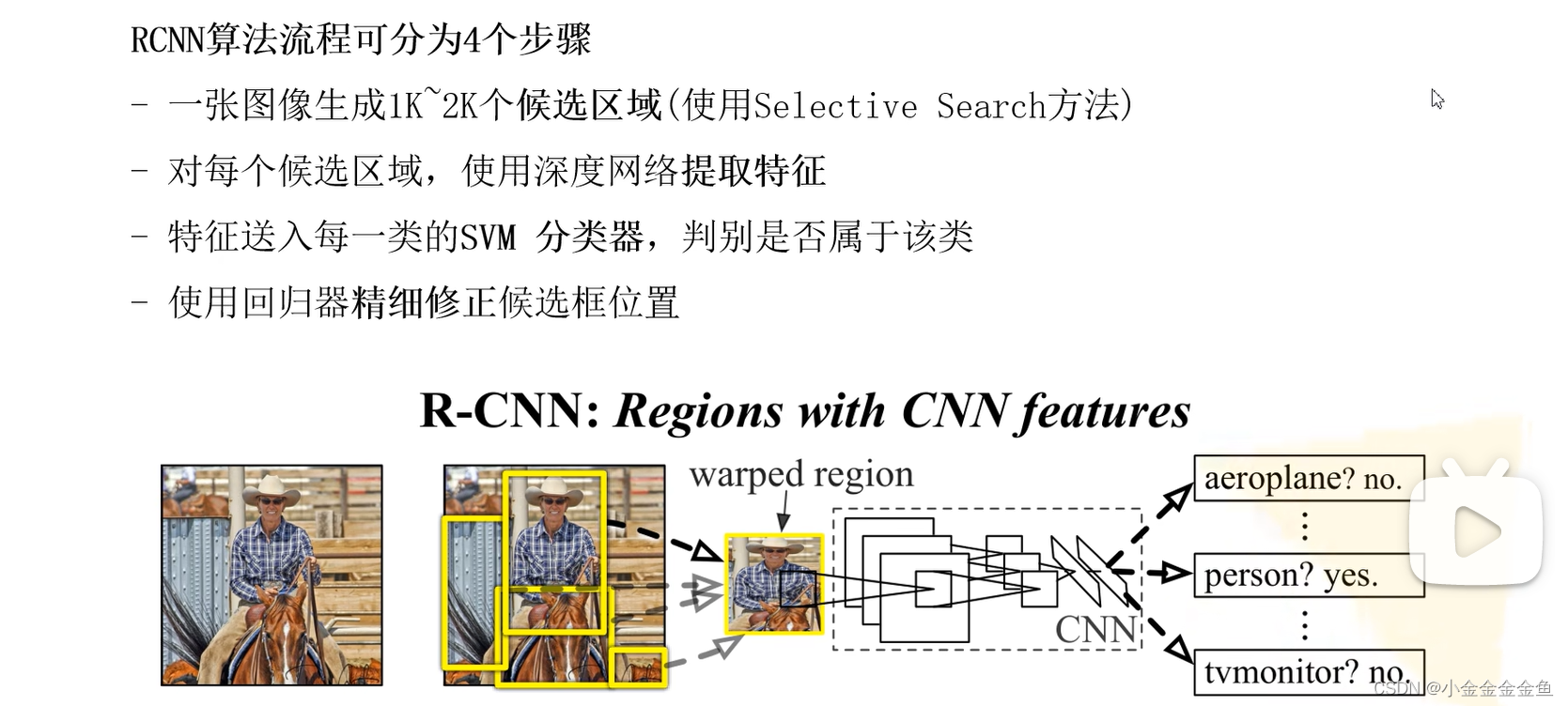
R-CNN


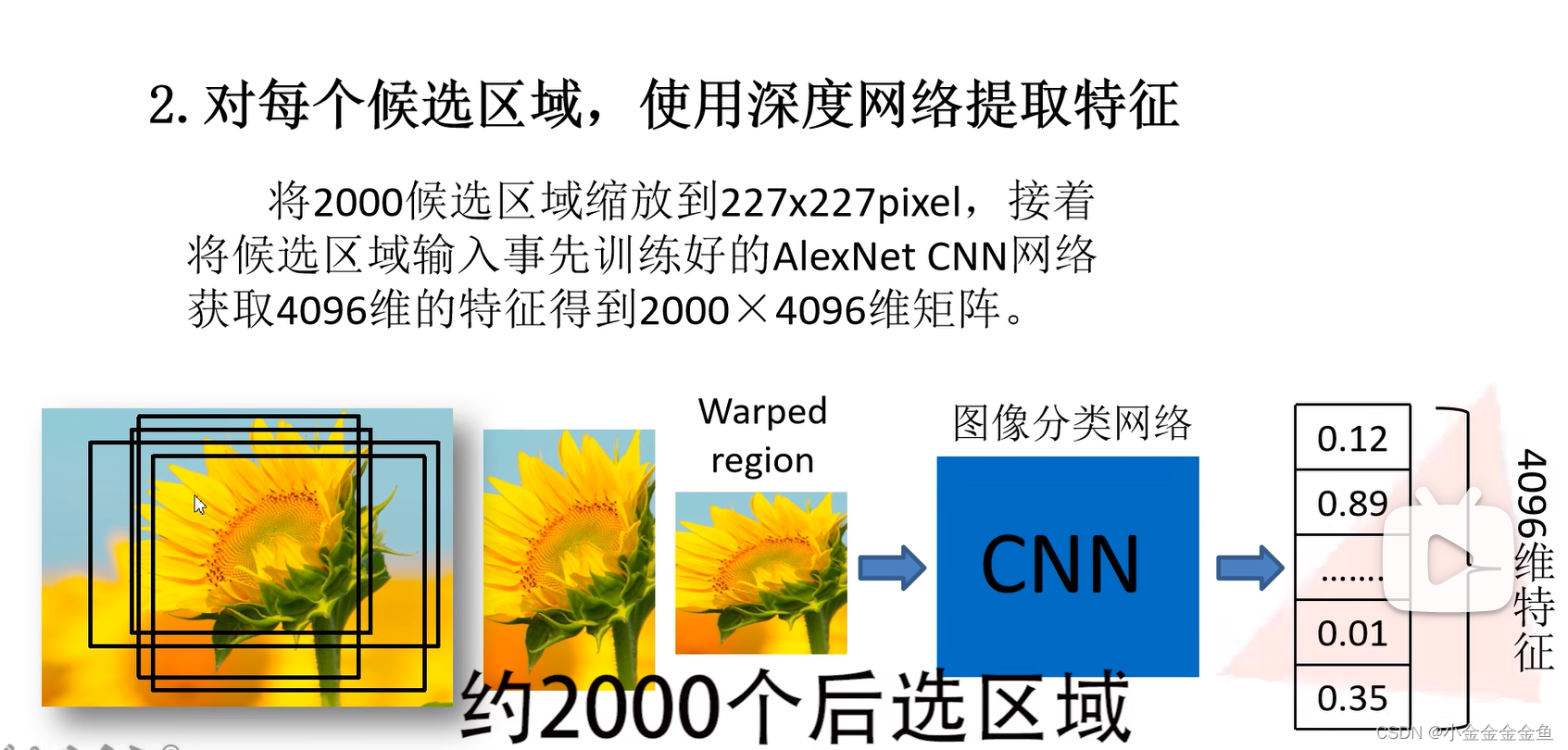
即在输入神经网络之前对图像进行resize处理
输入网络后得到对应的特征向量
输出一个展平向量(没有经过全连接层)。每一行对应一个候选区域的特征向量
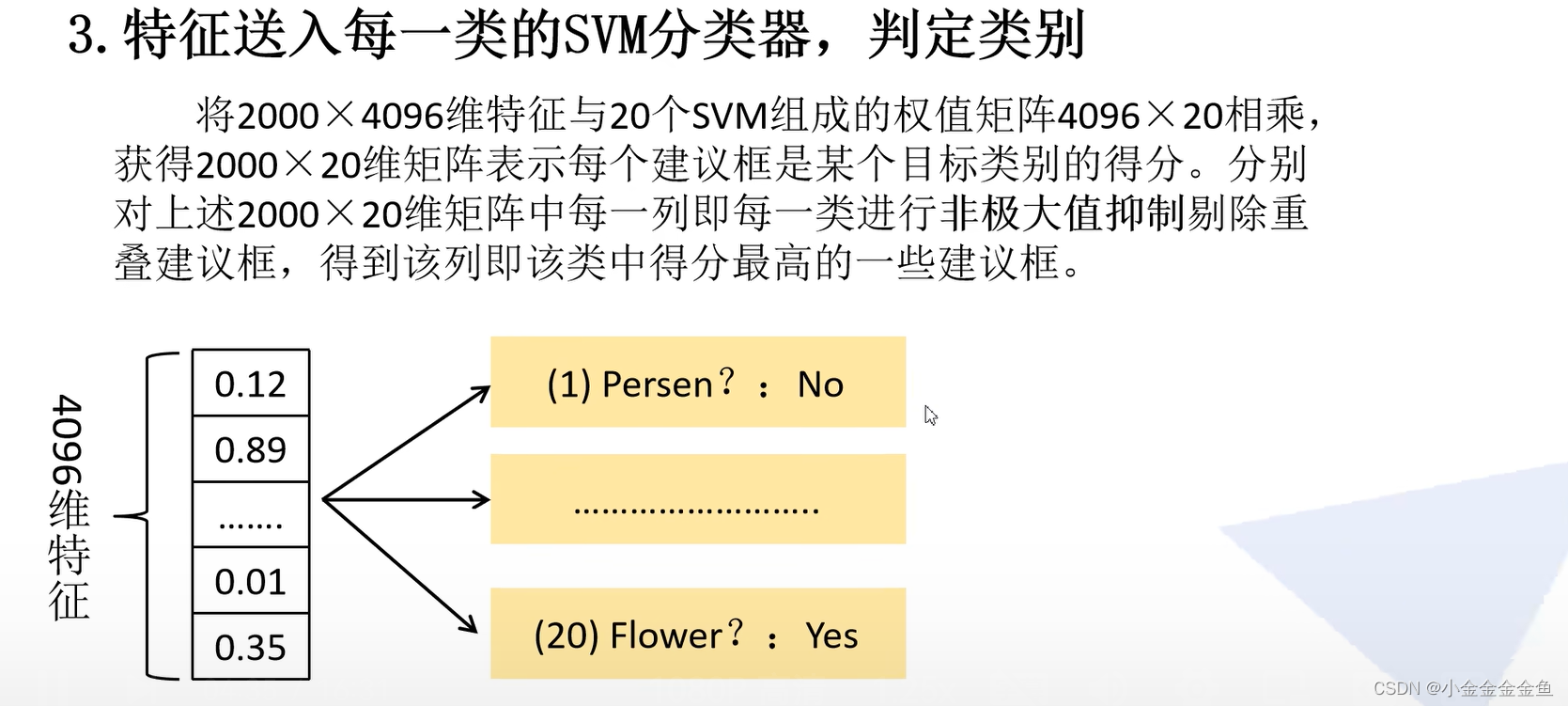
SVM二分类器
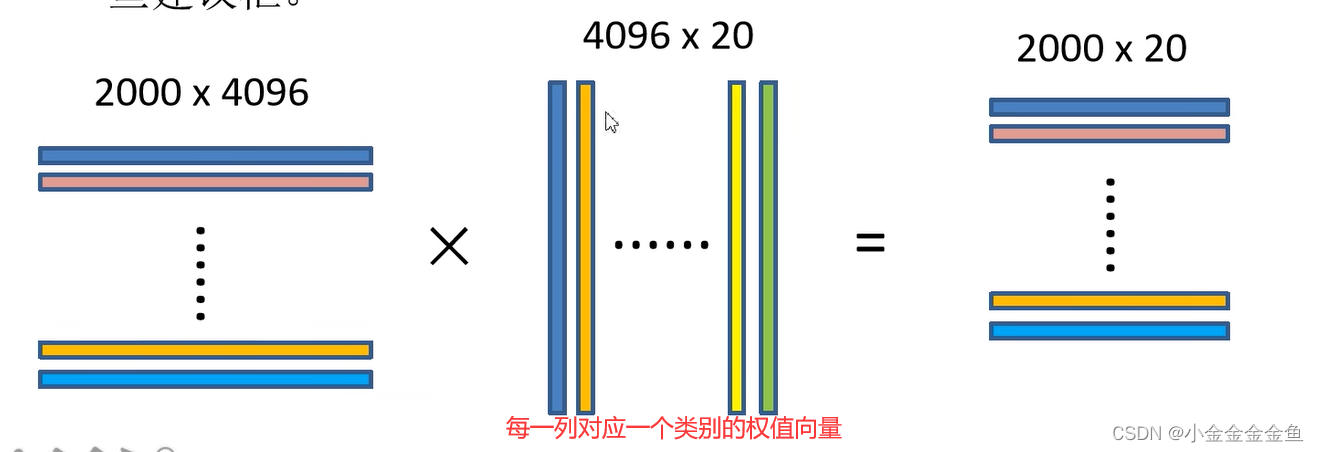
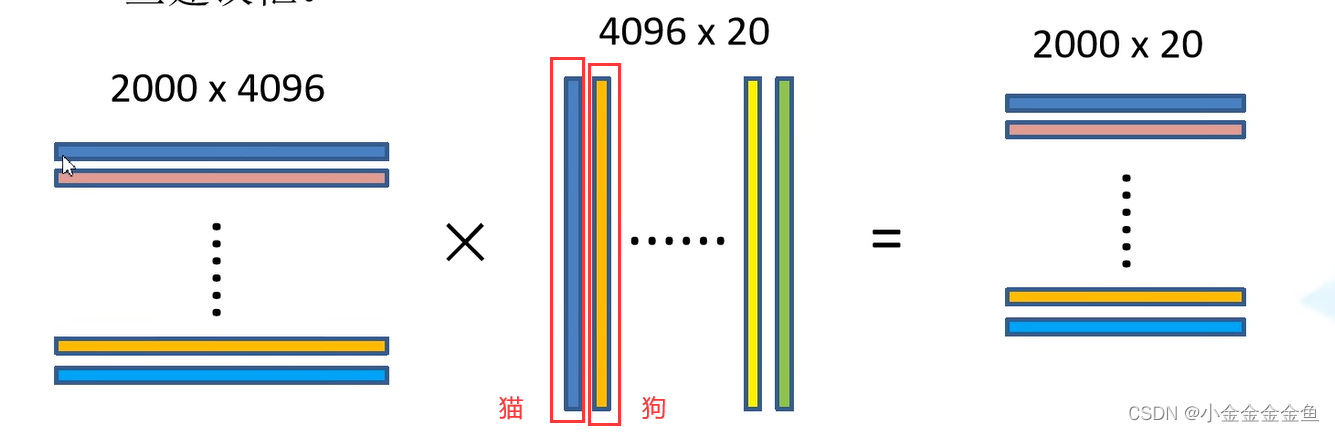
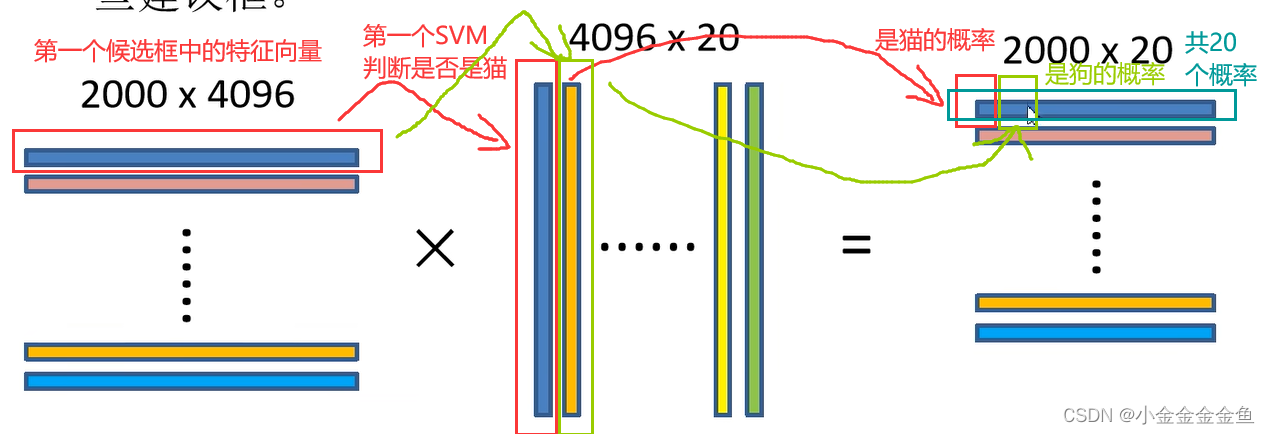

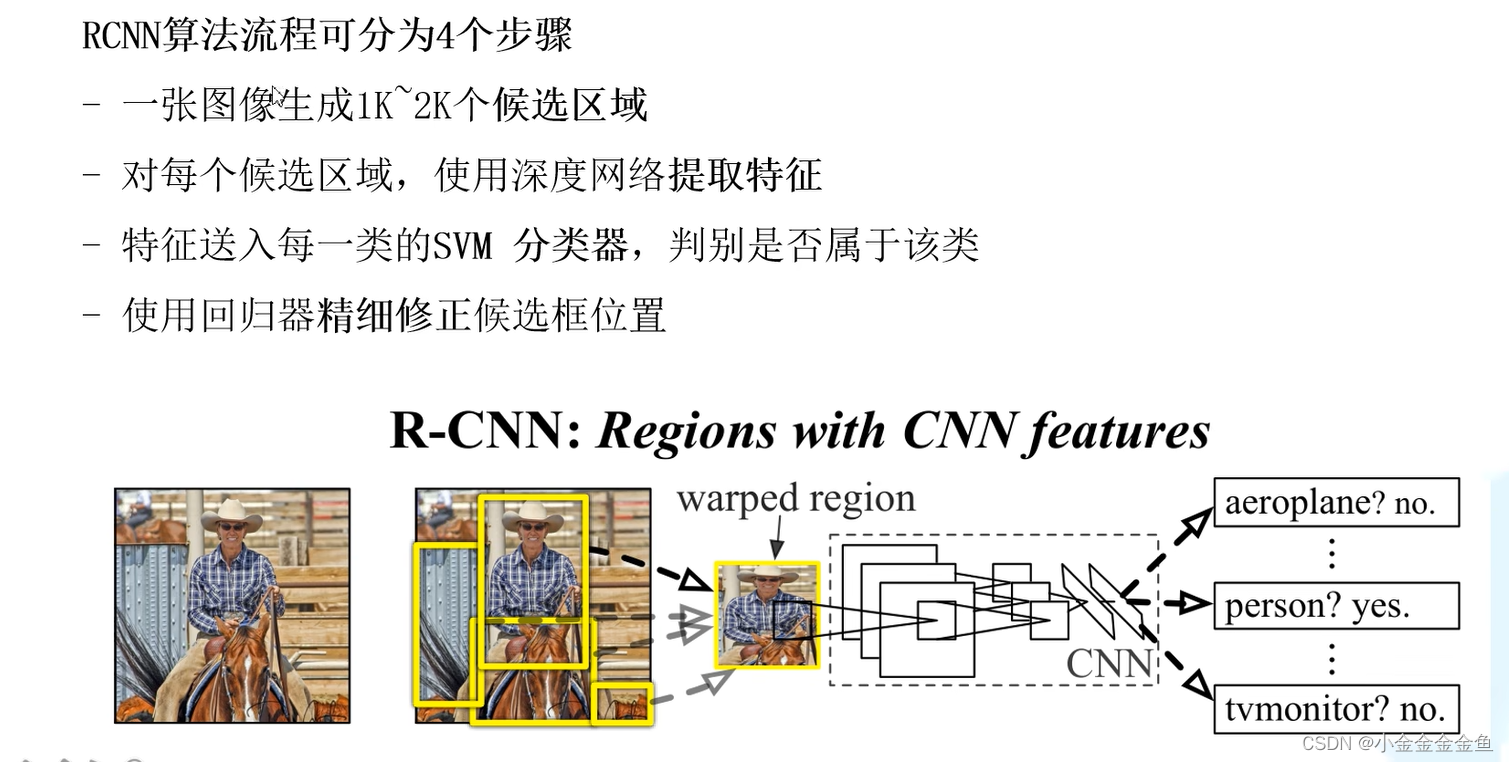

1:通过SS算法,生成候选框
2:卷积神经网络,候选框 --> 一系列特征向量
3:通过SVM进行目标分类
4:通过回归器调整候选框坐标

(通过SS得到候选框,但是有很多重叠
计算候选框对应的特征向量时,每一个候选框都会对重叠部分进行卷积操作,所以有很多冗余 —> 在faster RCNN中优化的部分)
Fast R-CNN

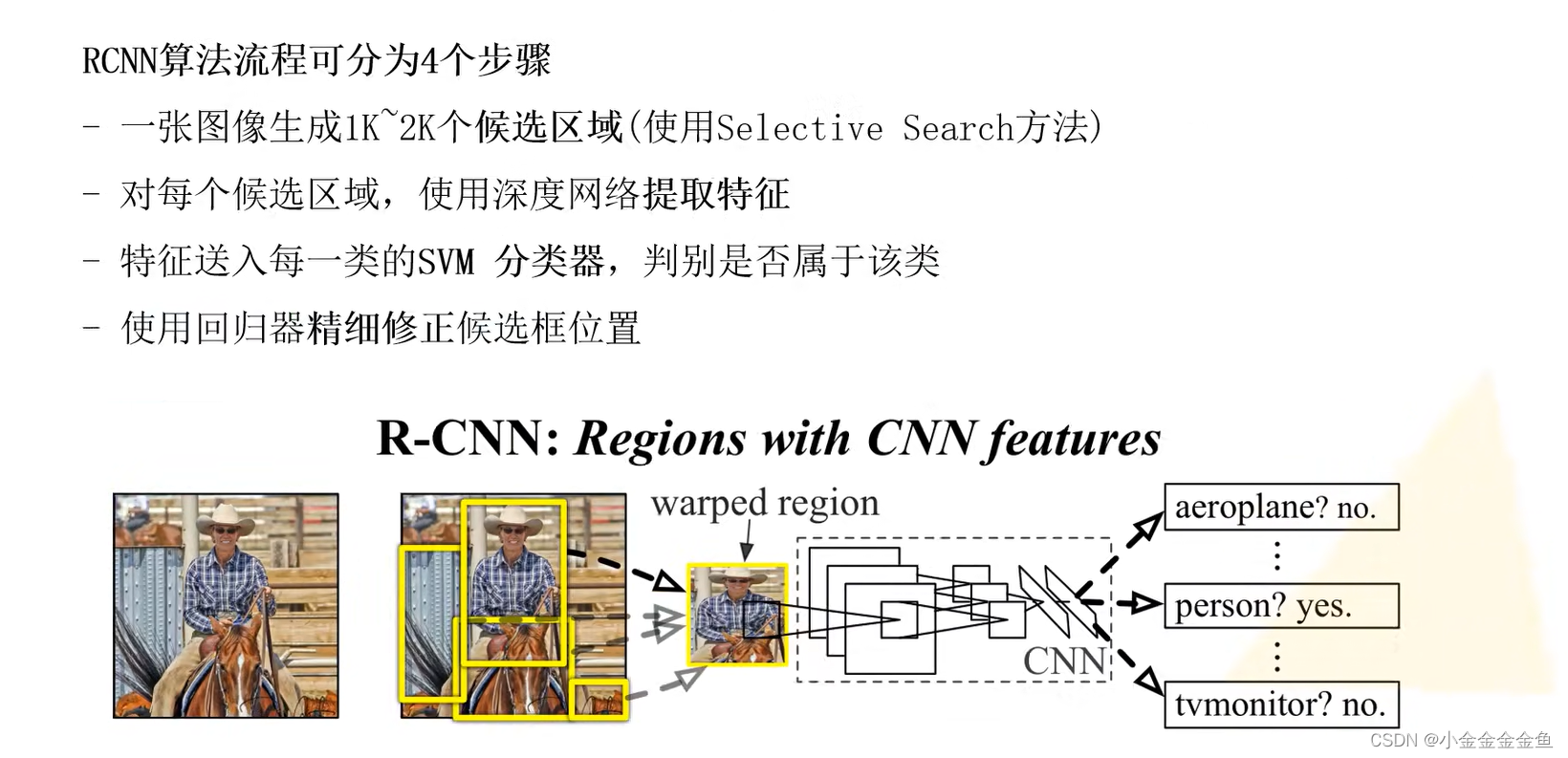
从第二步开始不同:
RCNN将每个候选区域分别输入网络,得到特征向量;
而Fast R-CNN是把整幅图像输入网络得到特征图(特征图就是feature map 卷积提取出来的特征),
然后通过SS算法(ss=selective search,第一步提取候选框的算法)在原图生成一个候选区域,映射到特征图上,得到特征矩阵。
(只要卷一次,卷了再切)
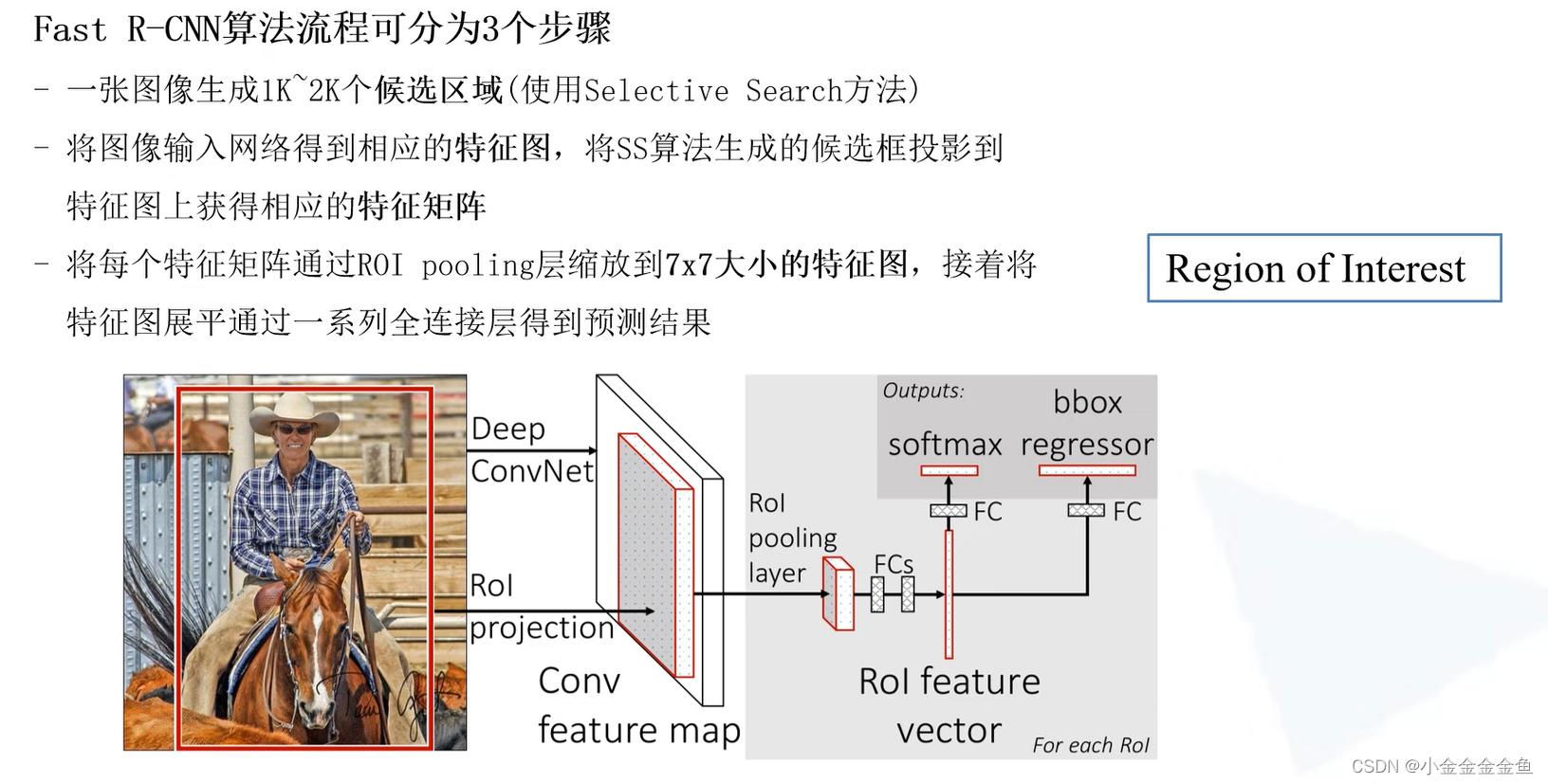
第三步:
每个特征矩阵
预测结果:目标所属的类别、边界框的回归参数。
而R-CNN中,专门训练SVM分类器,对候选区进行分类。又专门训练回归器,对候选区域的边界框进行调整。
而在Fast R_CNN中,讲这些结合在一个网络中。不需要单独训练分类器以及边界框回归器。
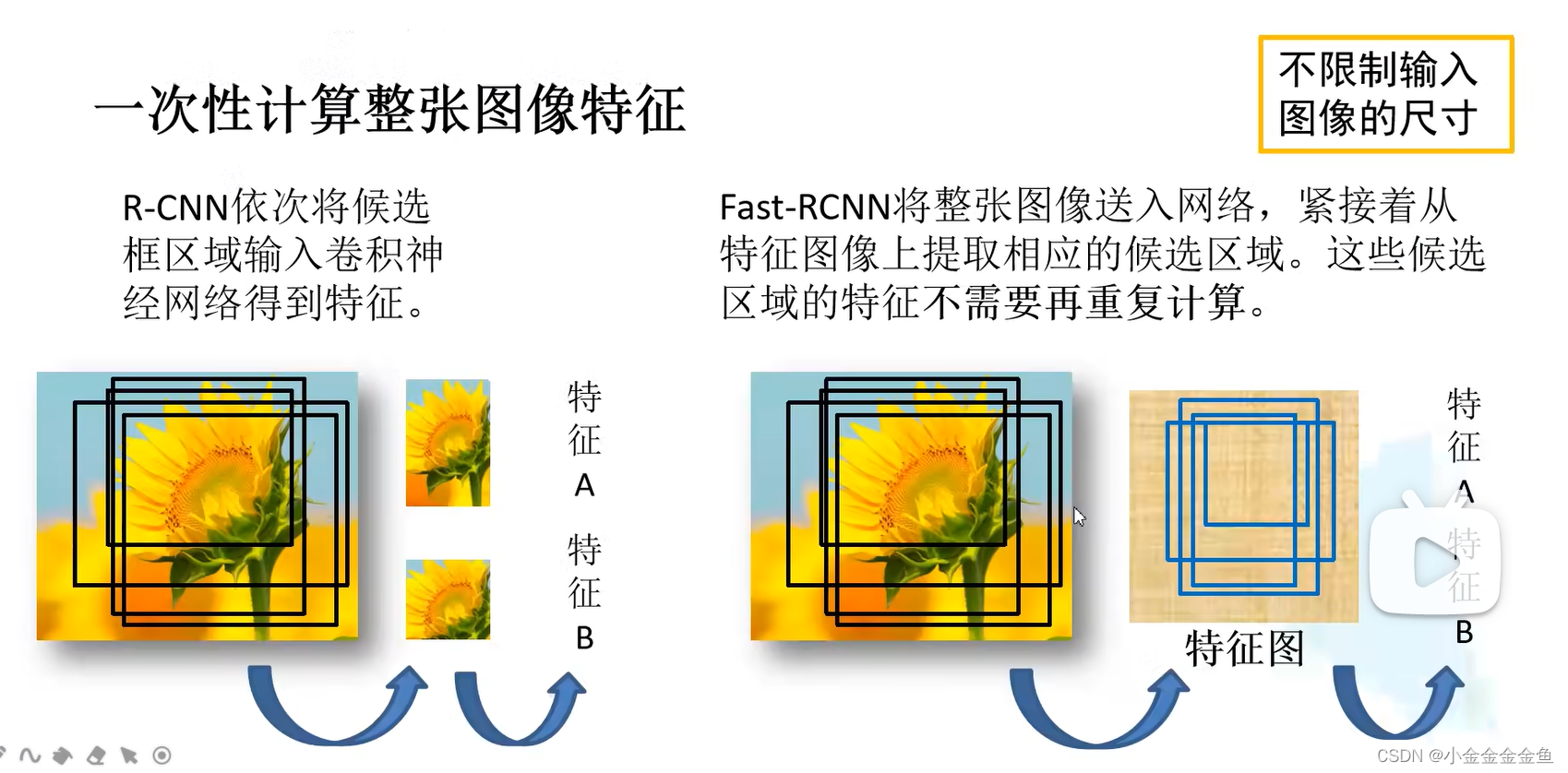
左:RCNN:
对每一个候选区域进行缩放,输入到网络之中,生成对应的特征。
会生成大量冗余,一些重叠的区域其实只要计算一次就行,而RCNN在不反复计算。
Fast R-CNN 如何** 生成候选框特征:**
将整张图片输入网络中,生成特征图。
通过候选区域原图与特征图的映射关系,直接在特征图中获取特征矩阵,这样可避免候选区域特征的重复计算。
Fast R-CNN 数据采样:
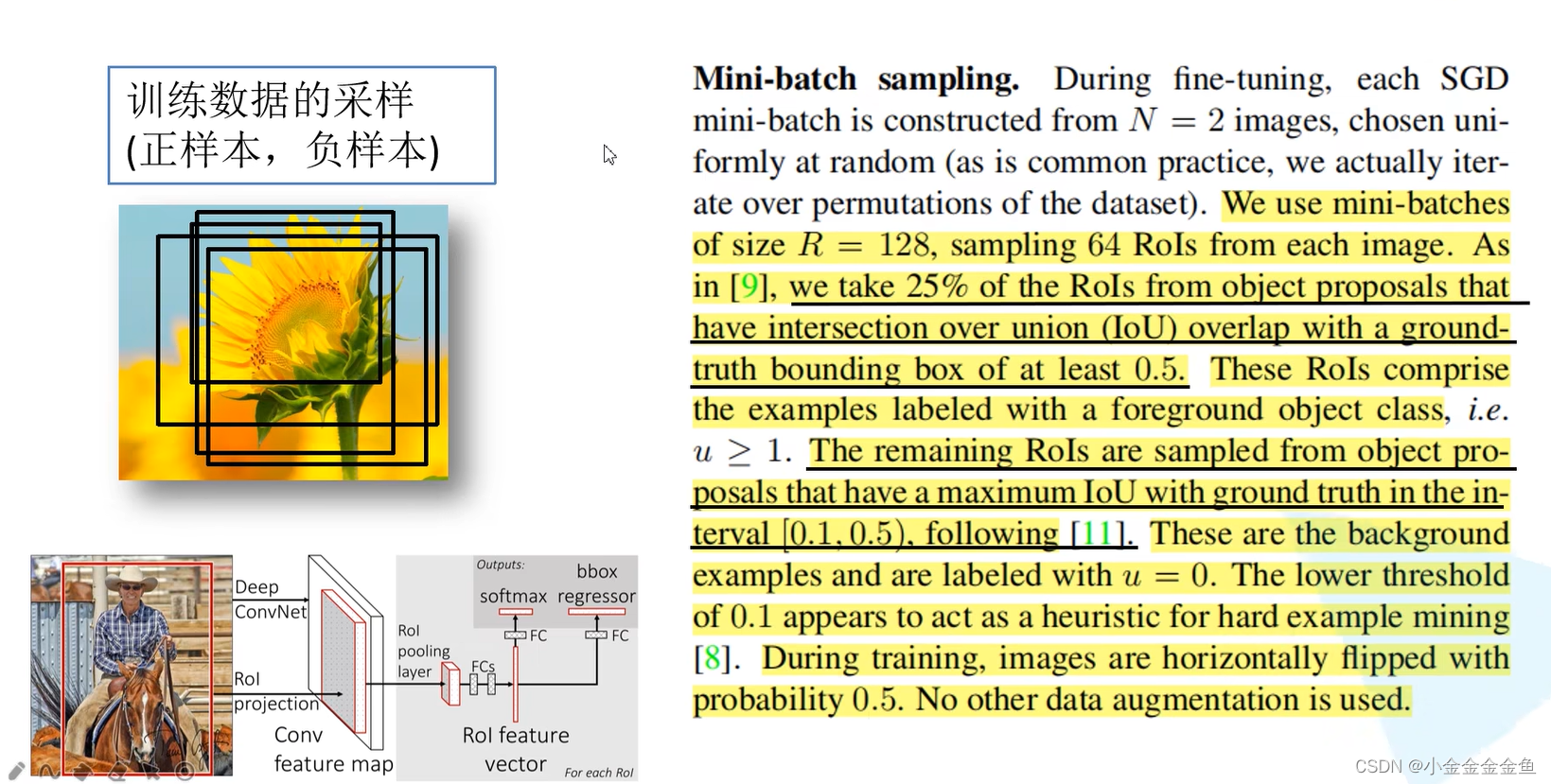
在训练过程当中,并不是使用SS算法提供的所有的候选区域,随机采样,而且对采样区分正样本、负样本。
正样本:候选框中确实存在所检测的目标的样本。
负样本:……没有要检测的目标。
若全部都是正样本,则网络有很大概率以为候选区域中就是要检测的目标。(类似于overfit 你都不知道错误的是什么样的,自然认为所有的都是对的)
(这里面阈值下界设置为0.1很有意思,其目的是为了获取和真实bounding box交并比至少为0.1的ROI作为负样本,即和真实目标有一定重叠,可以让模型学习较难的负样本。)
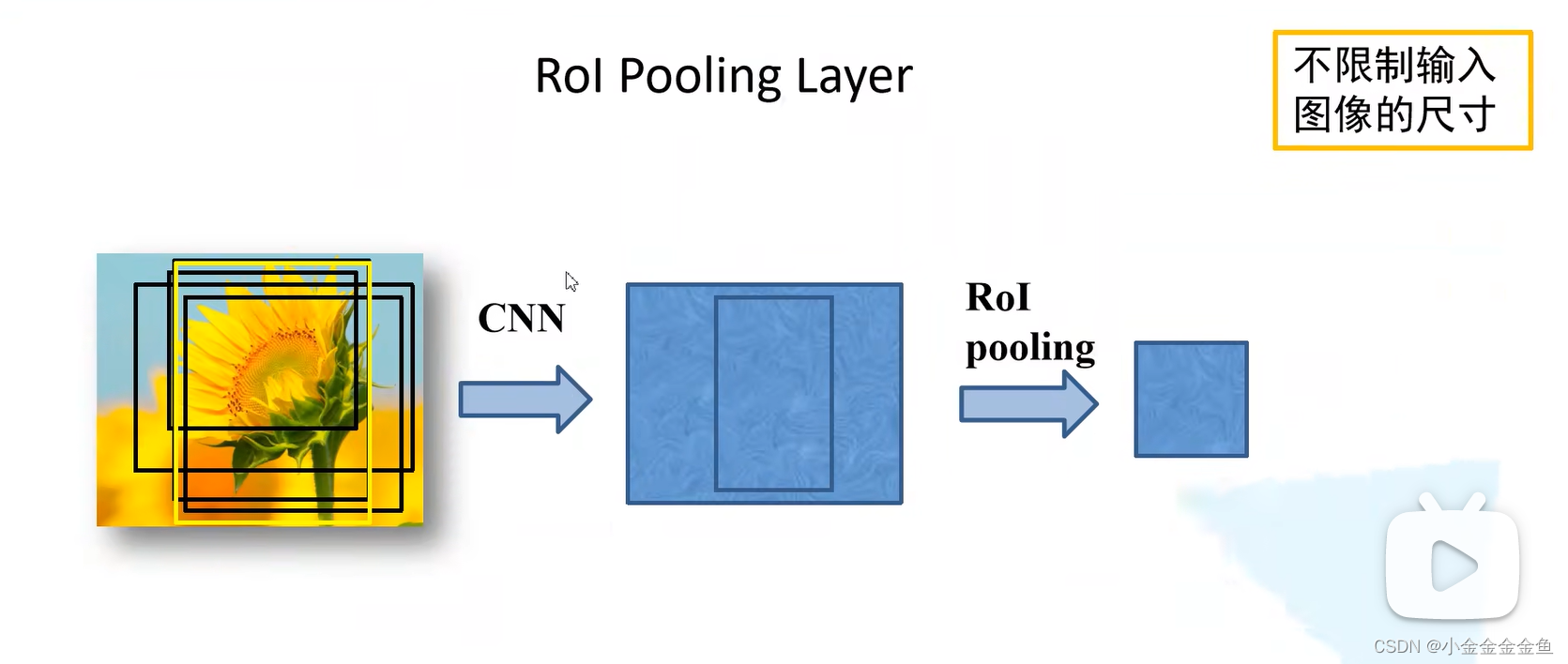
将用于训练样本的候选框通过ROI pooling层缩放到统一尺寸
ROI pooling层:(对其中一个channel举例:)
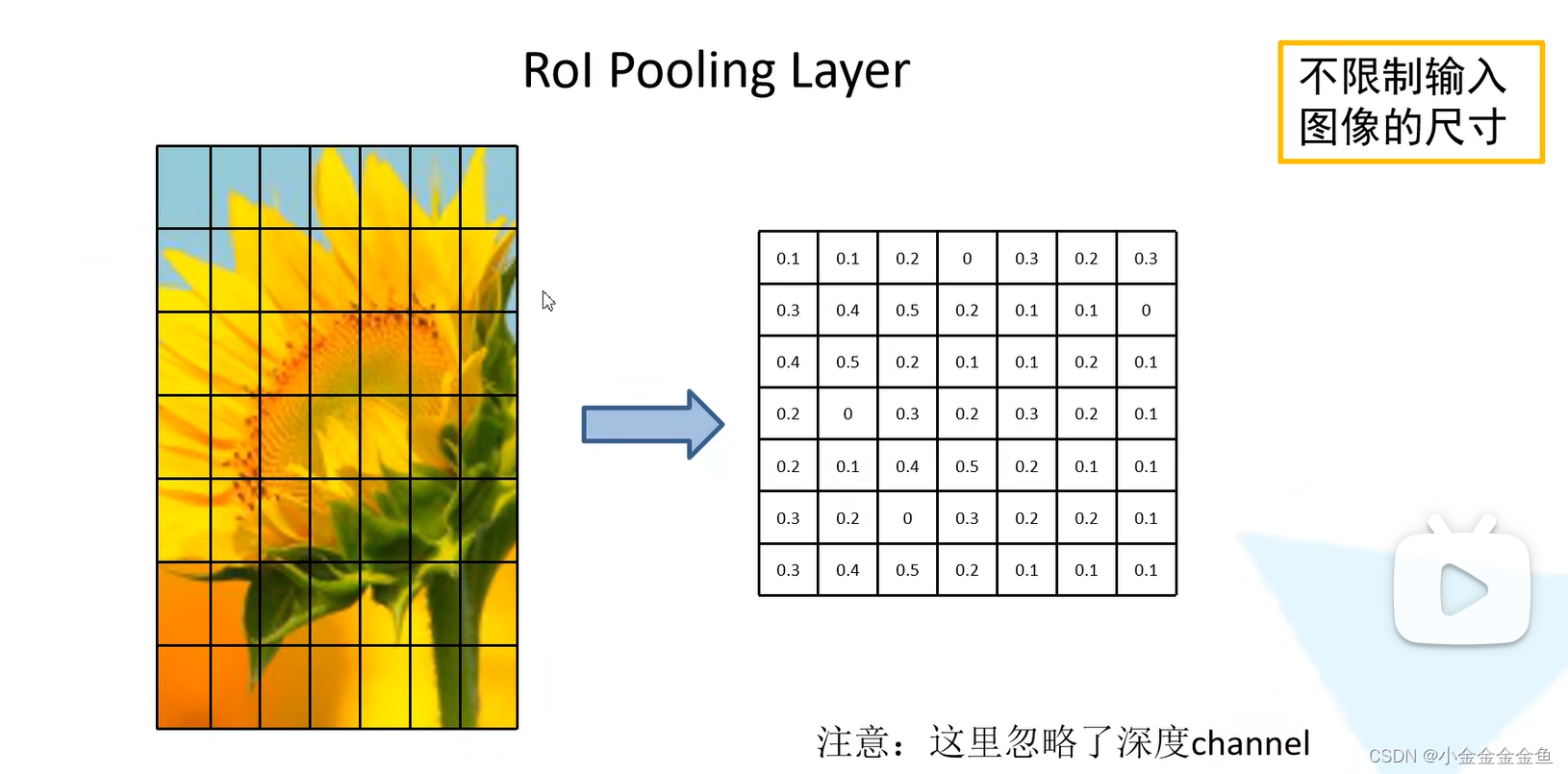
假设上图左边的图是一个候选区域在特征图上对应的特征矩阵。(真正的特征矩阵展示的是看不懂的抽象信息)
将这个特征矩阵划分为7*7=49份。划分之后对每个区域执行最大池化下采样
(这一个区域有很多像素,不要先入为主,以为一个一个区域是一个像素块)
Fast R-CNN网络框架
将整张图片输入网络中,生成特征图。
通过候选区域原图与特征图的映射关系,直接在特征图中获取特征矩阵。
将特征矩阵通过ROI Pooling层统一缩放成指定的尺寸。
进行展平处理。
通过两个全连接层,得到ROI Feature vector。
在此基础上并联两个全连接层:其中一个用于目标概率的预测,另一个用于边界框回归参数的预测。
- 目标概率预测–分类器:
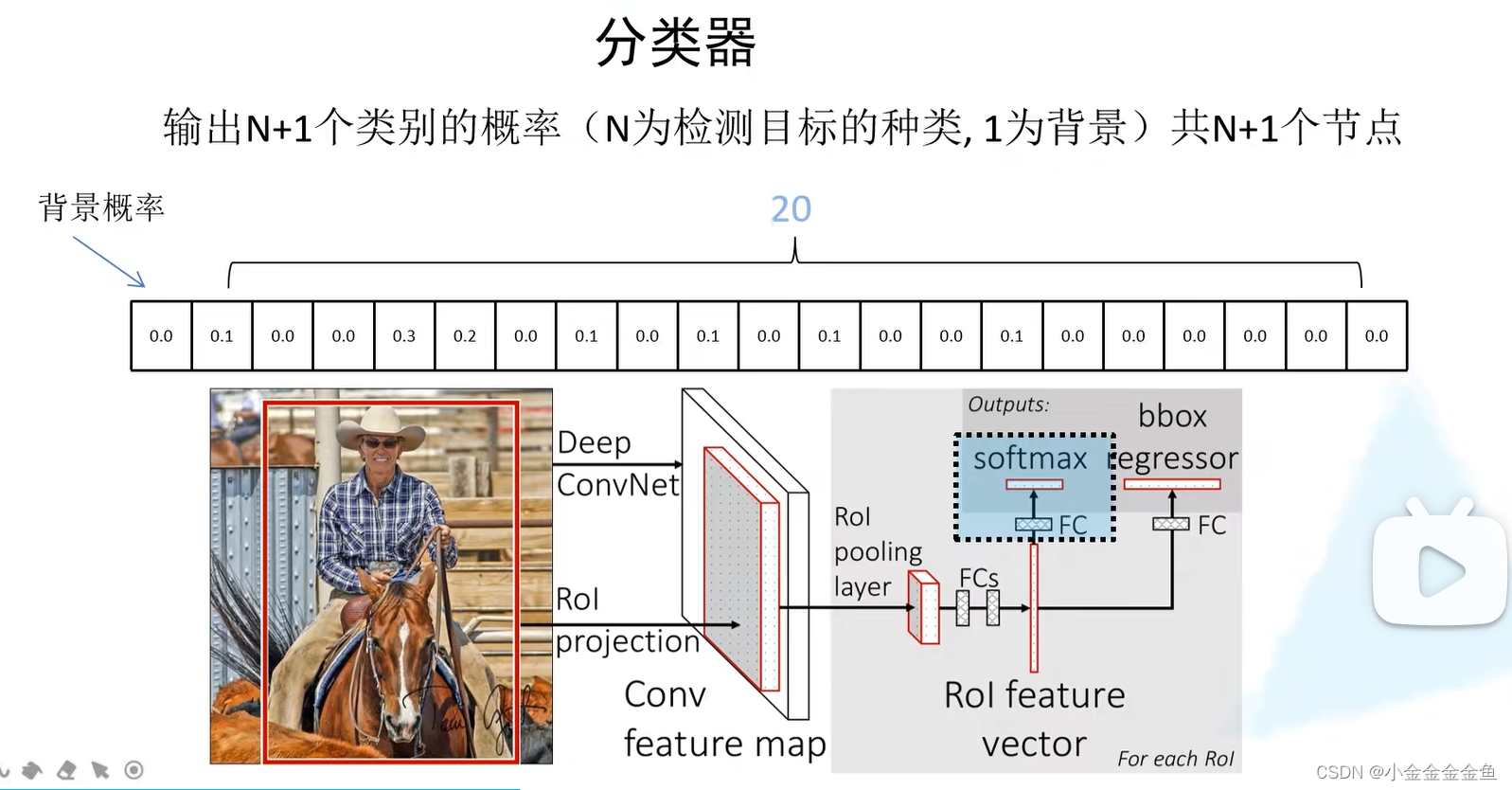
图上这个概率经过softmax处理,所以是满足概率分布的(和为1)。
- 边界框回归器:
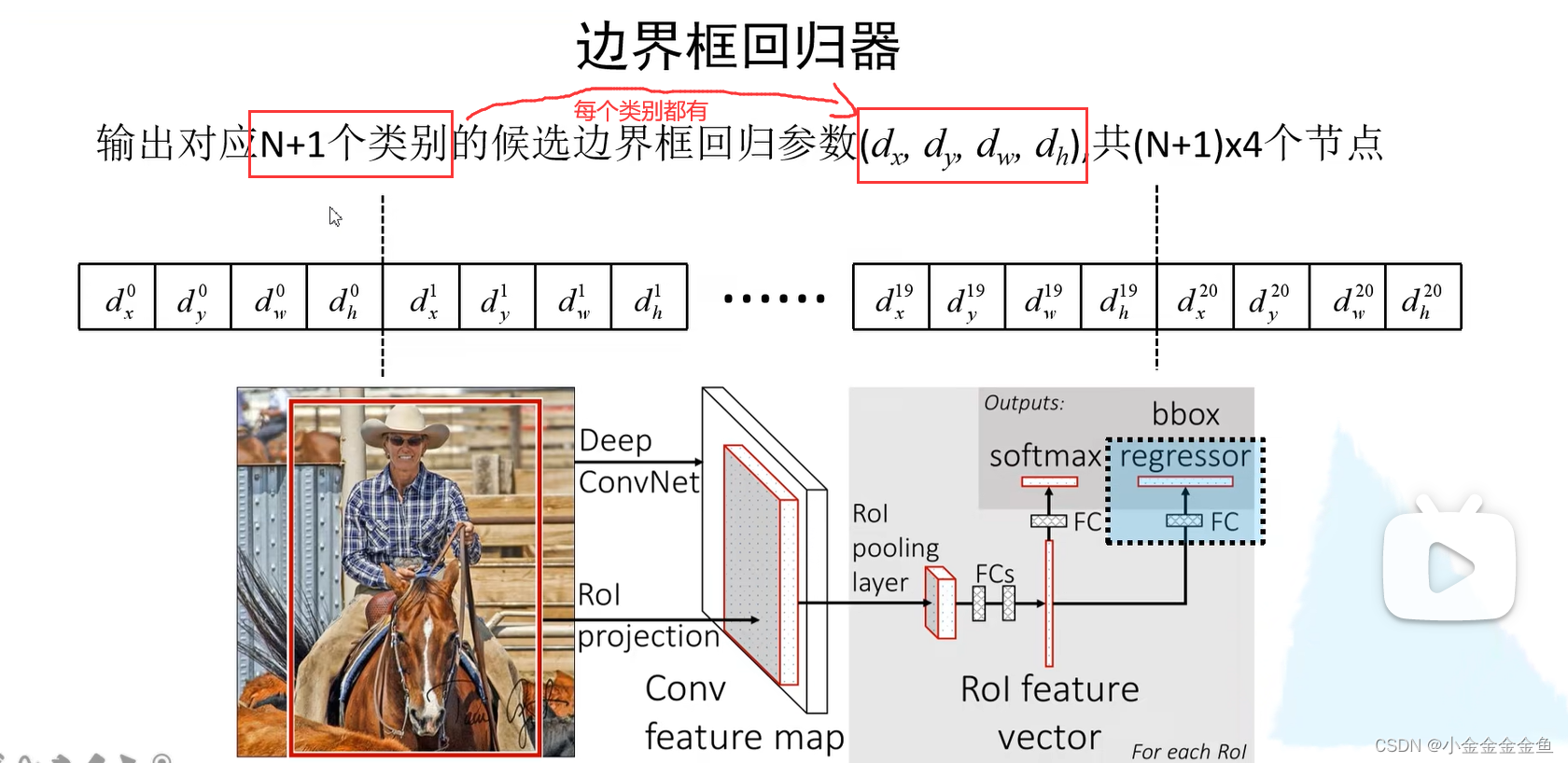
所以这里的全连接层节点个数应该为(N+1)*4
Fast RCNN如何利用预测参数得到最后的预测边界框
P:候选框坐标参数。
G:最终预测框坐标参数
d:通过全连接层输出的边界框回归参数
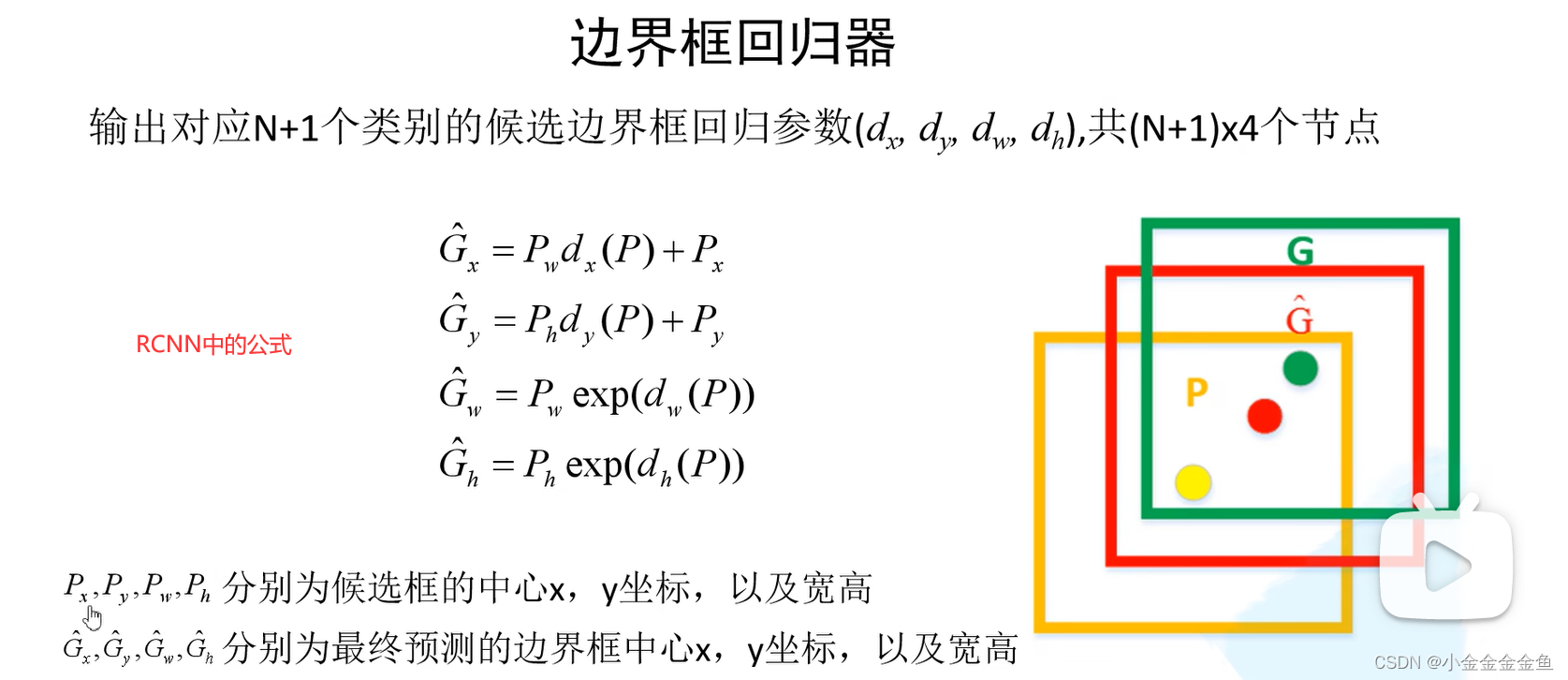
通过公式看出,dx、dy是调整候选边界框中心坐标的回归参数。
橙色框 --> 红色框
绿色框:ground-truth框,(用来计算损失?)
橙色框:通过SS算法得到的候选边界框
(真实标签的位置是自己标定的,但是回归参数是计算出来的)
Fast RCNN损失计算

需要预测候选框的类别,概率,边界框的回归参数,所以涉及两个损失:分类损失、边界框回归损失
k:k个目标种类
p0:候选区域为背景的概率
- 计算分类损失:
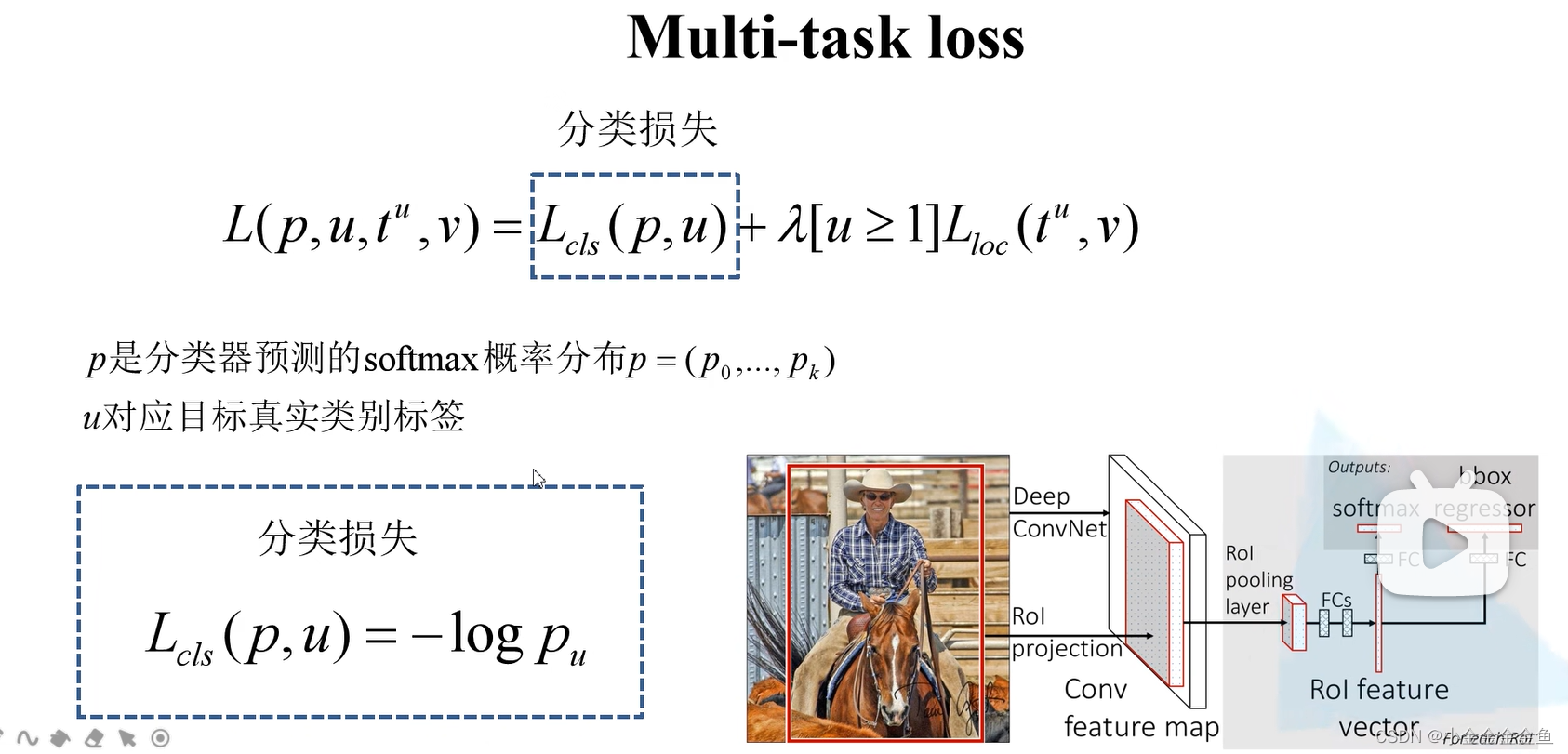
pu:分类器预测当前候选区域为类别u的概率 - 计算边界框回归损失:

(两个公式的数学本质是似然函数的负对数,上面的公式适用于只能属于一类,各个分类构成一个完备事件组;下面的公式适用于可以属于多类,各个分类是相互独立的随机事件。模型训练的本质是寻找极大似然估计)

(没听懂,以后再说吧……)

(Lloc(tu,v) 就是四个坐标与真实值差值的加和)
x:(tui-vi)这个的差值
v的计算↓

vx:(Gx-Px)/Pw
vy:(Gy-Py)/Ph
vw:(Gw-Pw),再对两边取ln
vh:(Gh-Ph),再对两边取ln
(
Vw=log(Gw/Pw)
)
右下角链接点进去这样↓:
(这个损失最大的好处就是结合了l1和l2的优点,对x求导,导数是在-1到1变化的,当x>1,导数都是1)
λ:平衡分类损失与边界框回归损失
艾弗森括号:计算公式:当u>=1时,这一项等于1,否则等于0
u:目标真实标签
u>=1:候选区域确实属于要检测的某一类别(正样本),此时才有边界框回归损失;否则为背景,对应负样本
总损失L()等于平衡分类损失+边界框回归损失
对总损失进行反向传播,即可训练整个Fast R-CNN网络
Fast R-CNN步骤回顾
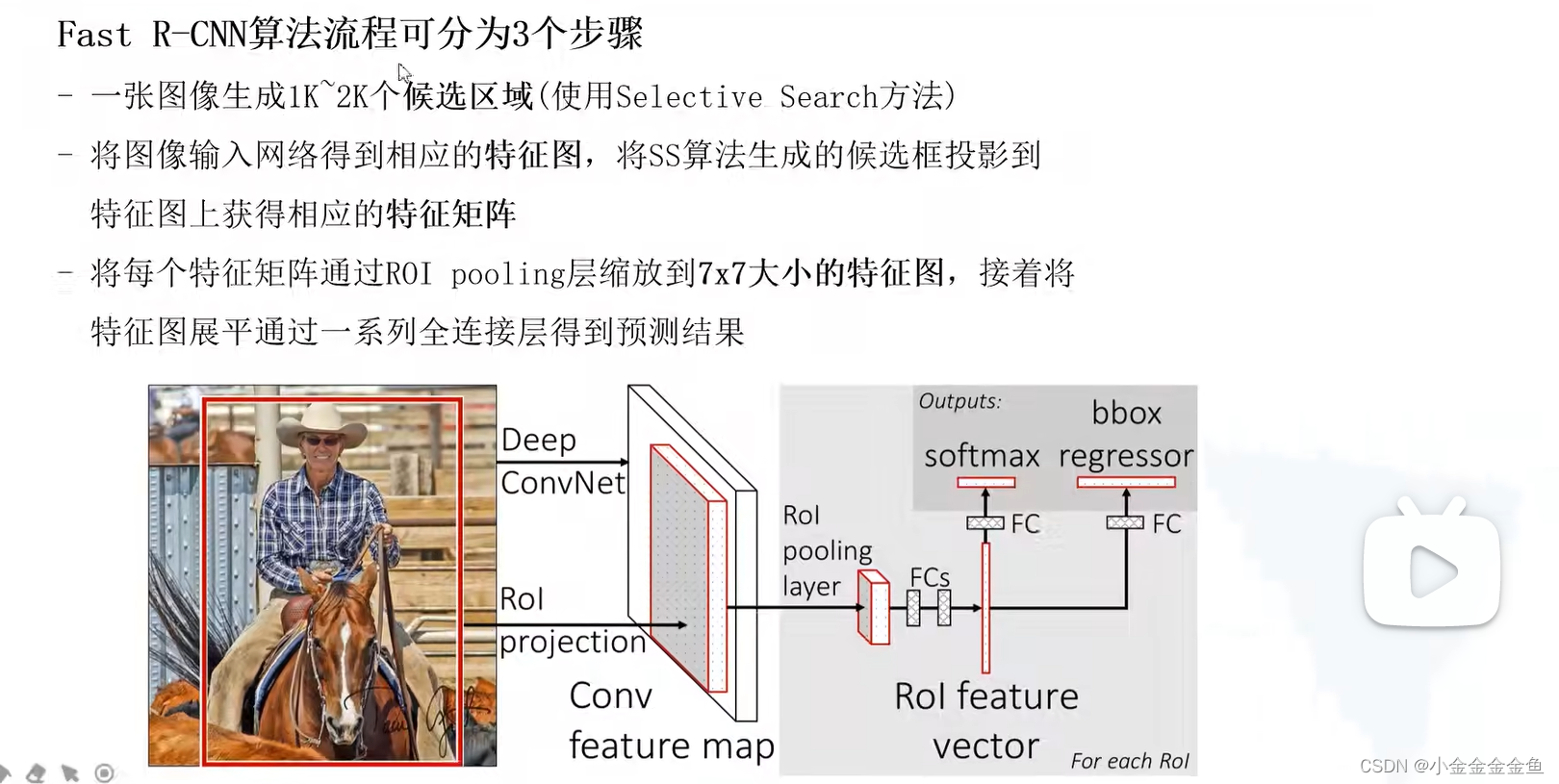
(
如何将生成的候选区域投影到特征图上?
投影方法:找到候选框ROI在原始图像上的位置,然后等比例缩放到特征图的相同位置上
)


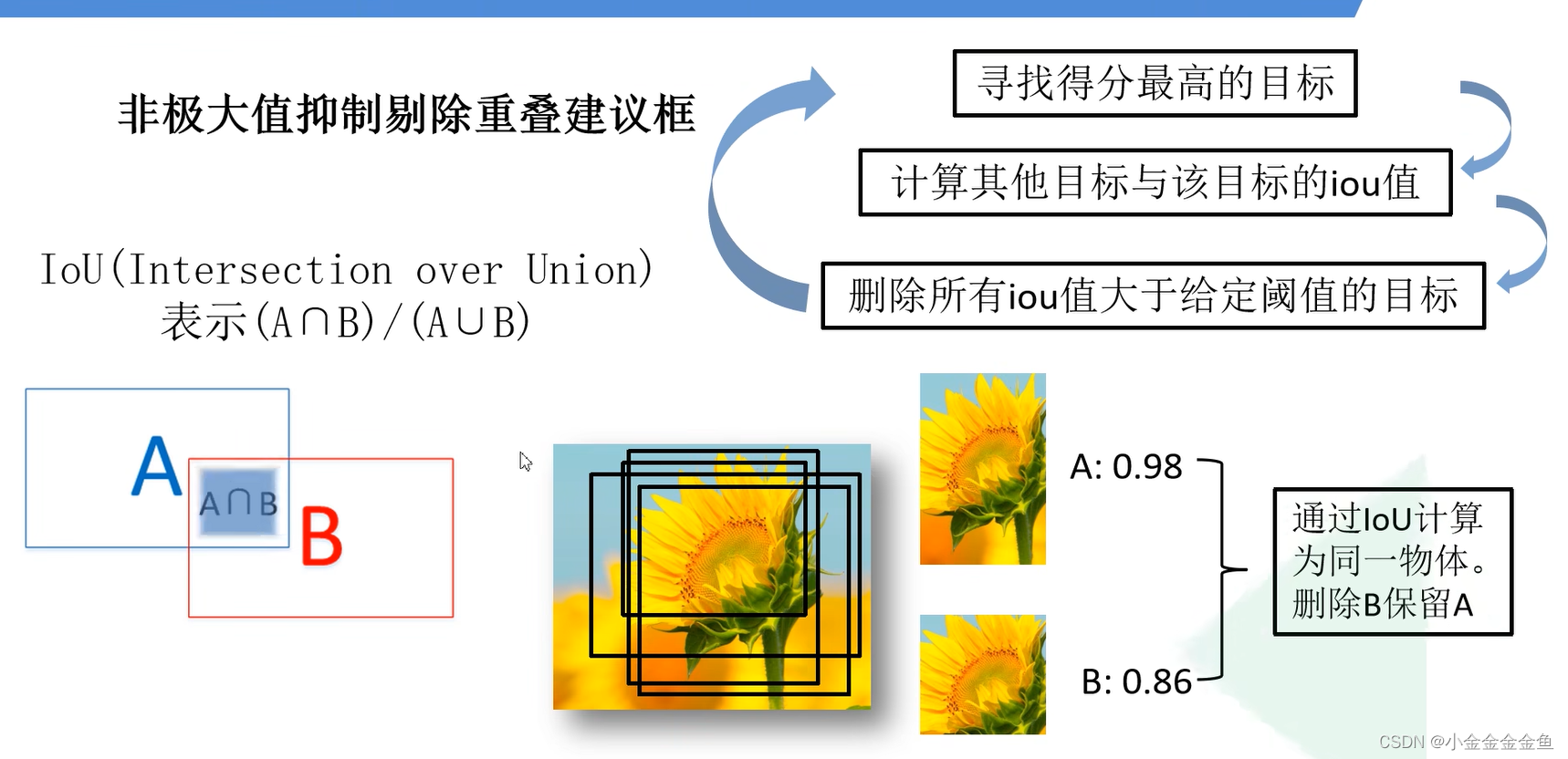
(每一类的候选框不止一个,在一张图片中每一类别可能有多个,这就是为什么要用NMS)
Faster RCNN
核心:理解RPN部分


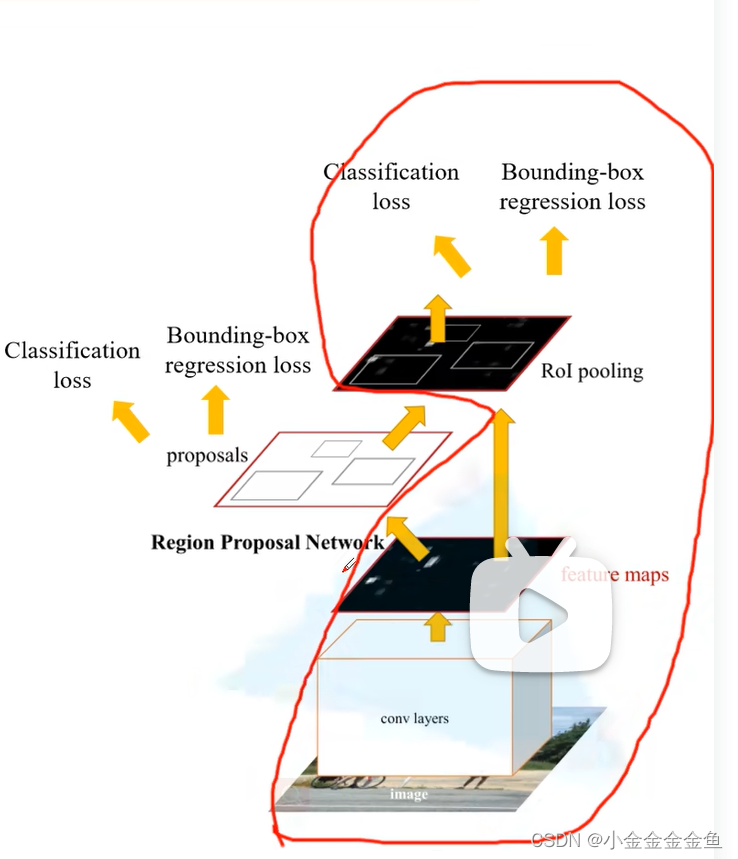
圈里的部分跟Fast R-CNN是一样的,在Faster R-CNN中专门使用Region Proposal Network (RPN)来替代SS算法
特征图(feature map):
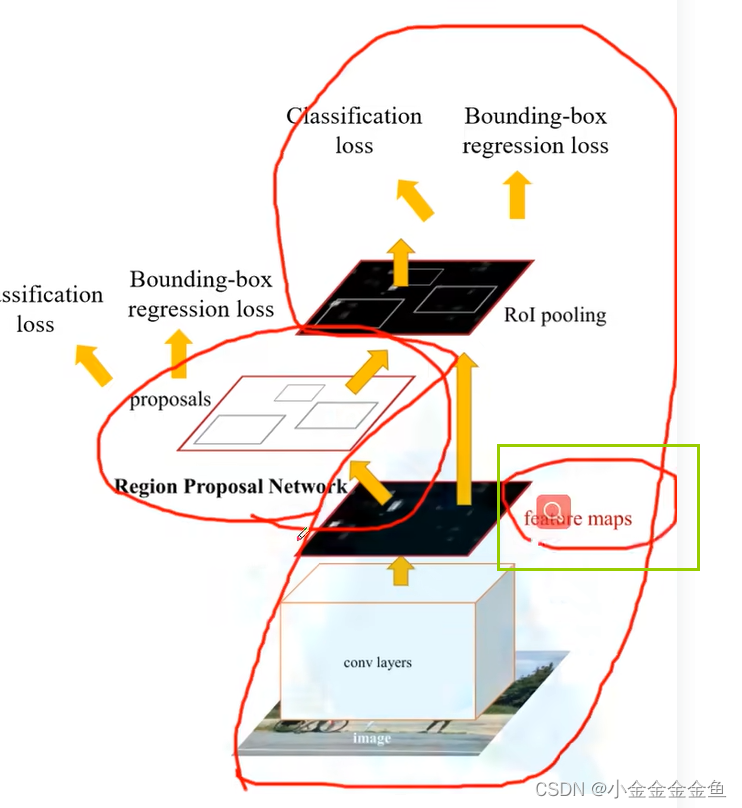
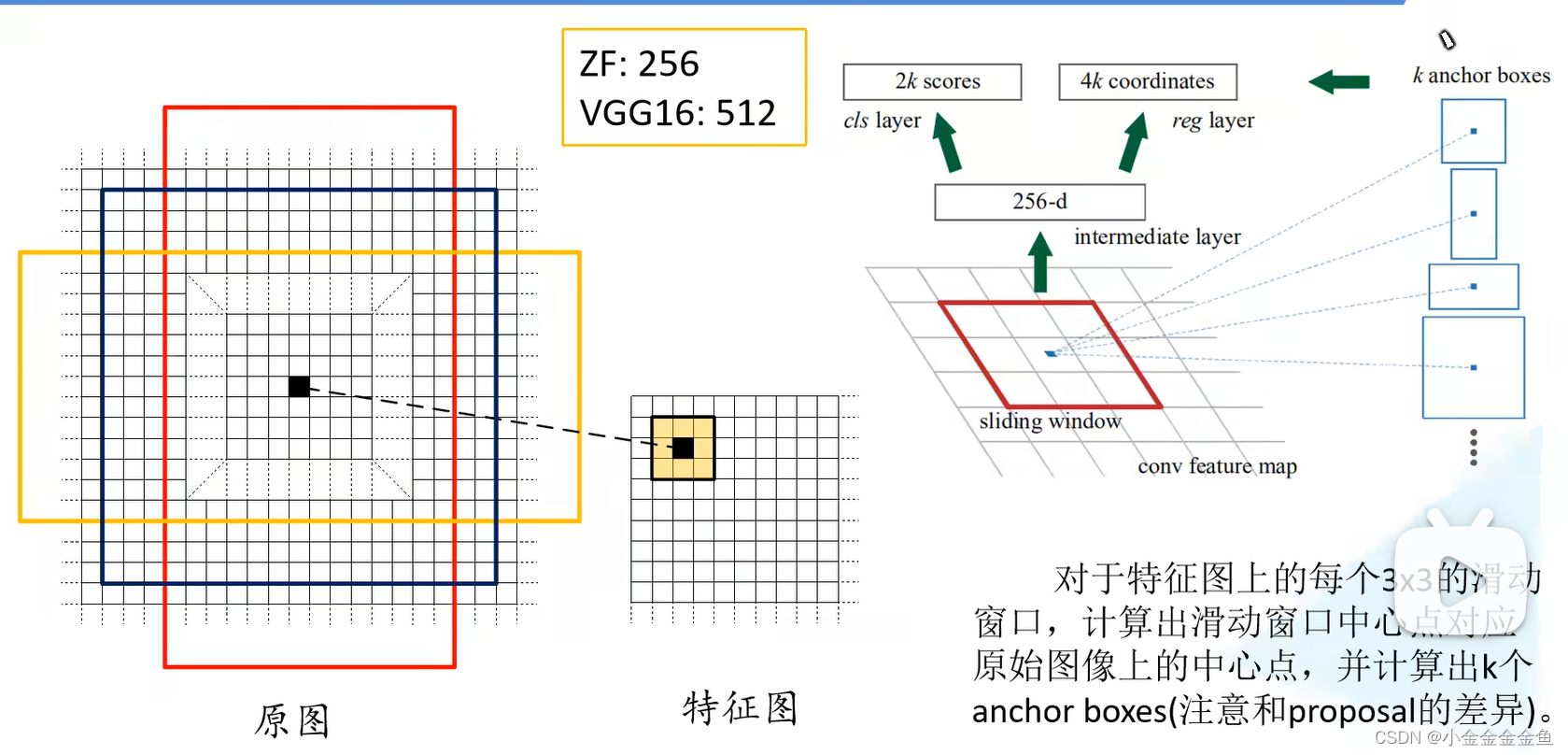
在特征图上使用滑动窗口进行滑动。每滑动到一个位置,就生成一个一维向量。
在这个向量的基础上,通过2个全连接层,分别输出目标概率、边界框回归参数。
- 2k:针对每个anchor生成两个概率:背景概率、前景概率 (
因为背景对应的真实标签坐标,而正负得分只是个值,可以有01标签,所以分类可以2k ) - 4k:针对每个anchor生成四个边界框回归参数 256:把ZF网络作为Faster
R-CNN的backbone,所生成的特征图的深度(channel)为256; 如果使用VGG16,则这个地方就是512
所以这里的一维向量的元素个数是根据backbone特征矩阵深度决定的。 - anchor:对特征图上每一个3*3的滑动窗口,首先计算中心点在原图上所对应的位置。再计算出k个anchor。
①在原图上找到特征图上的点对应的位置。
(原图宽度/特征图的宽度)取整 = 步距
特征图上x坐标乘步距=原图上对应的x坐标,y同理
②以这个点为中心计算出k个anchor box
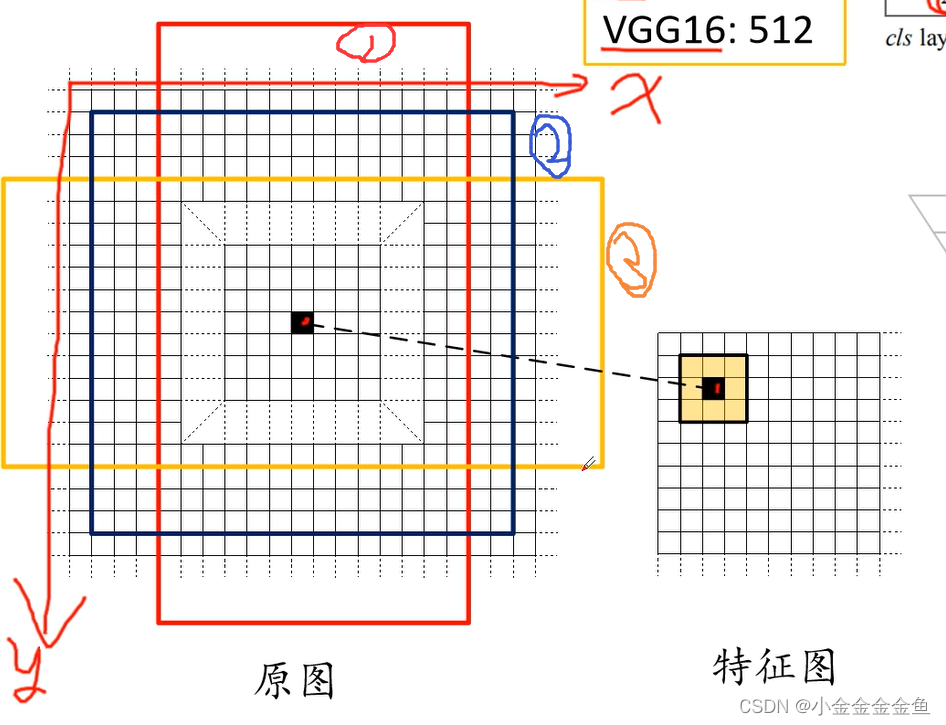
这里画出了3个anchor
(弹幕大佬:特征图里的一个像素相当于原图一块的浓缩;
anchor中心像是以一定的步长滑动的卷积核得到的中心点;
anchor不是说一般有九个,而是论文中采用六个不同的比例
)
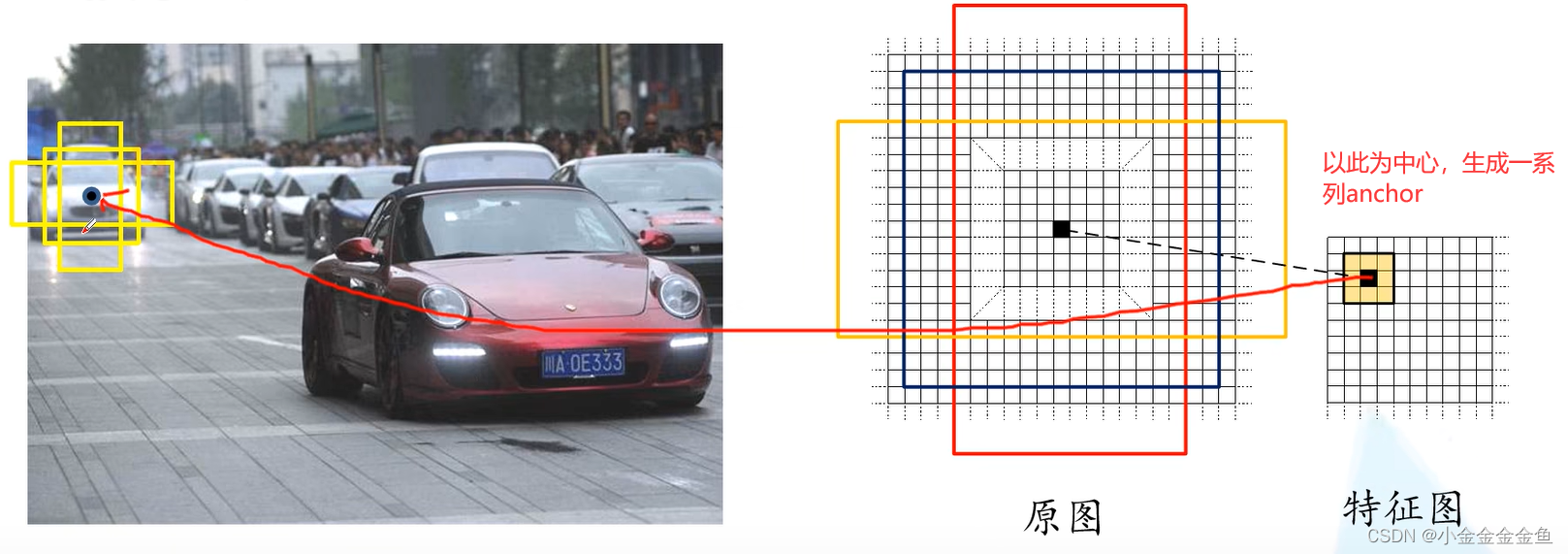
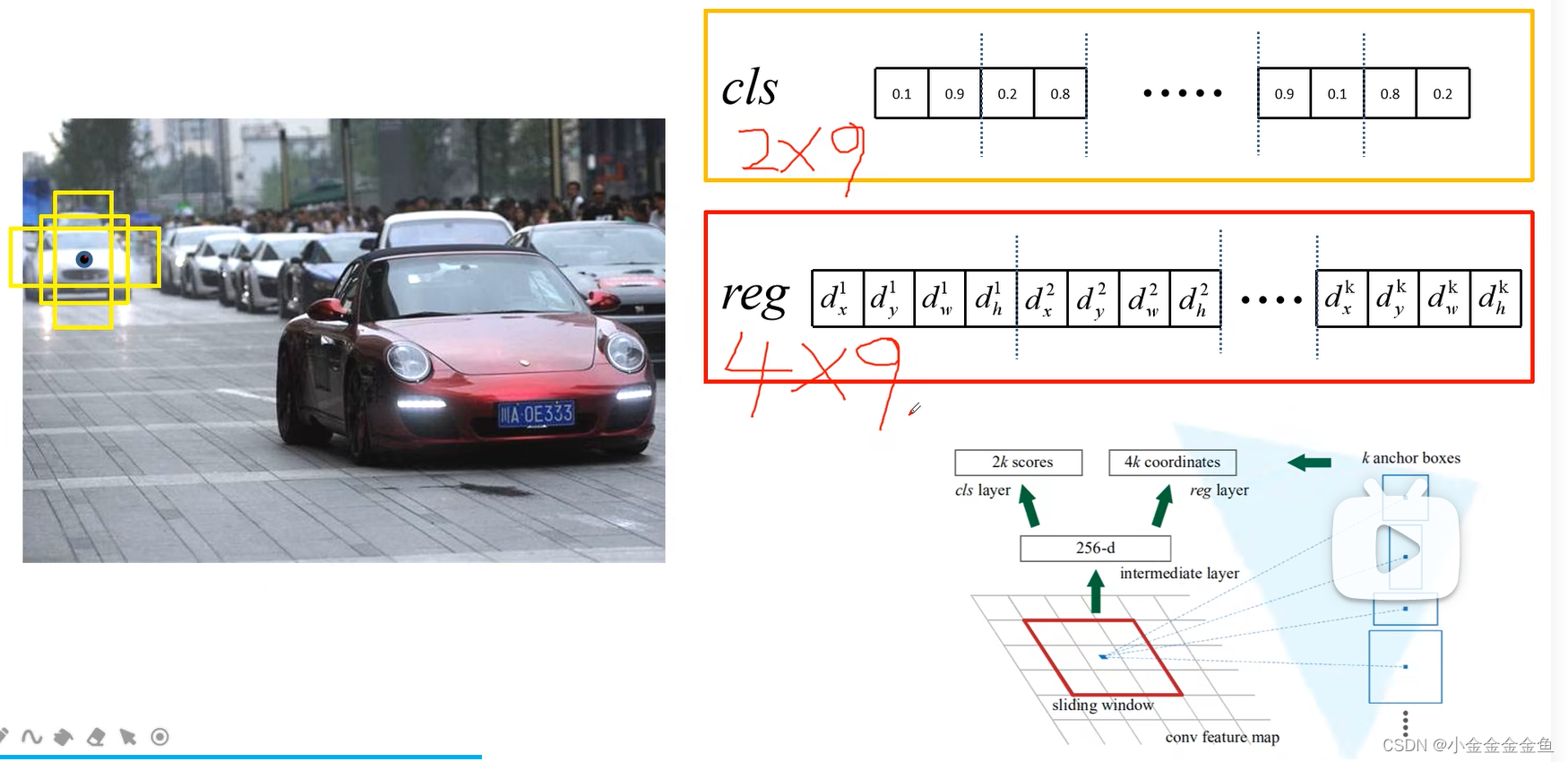
anchor中可能包含要检测的目标,也可能不包含。 - (k个anchor生成的)2k scores、4k coordinates如何影响anchor
2k scores两个两个为一组,每两个对应一个anchor
回归参数是4k,每四个为一组
图里这个:
假设第一个预测参数第一个anchor对应图里的黄框,
则是背景([0])的概率为0.1,是目标([1])的概率为0.9(此处只预测是前景还是背景);
回归参数dx、dy预测这个anchor中心坐标的偏移量。dw、dh对应anchor宽度和高度的偏移量。使用回归参数对anchor进行调整。
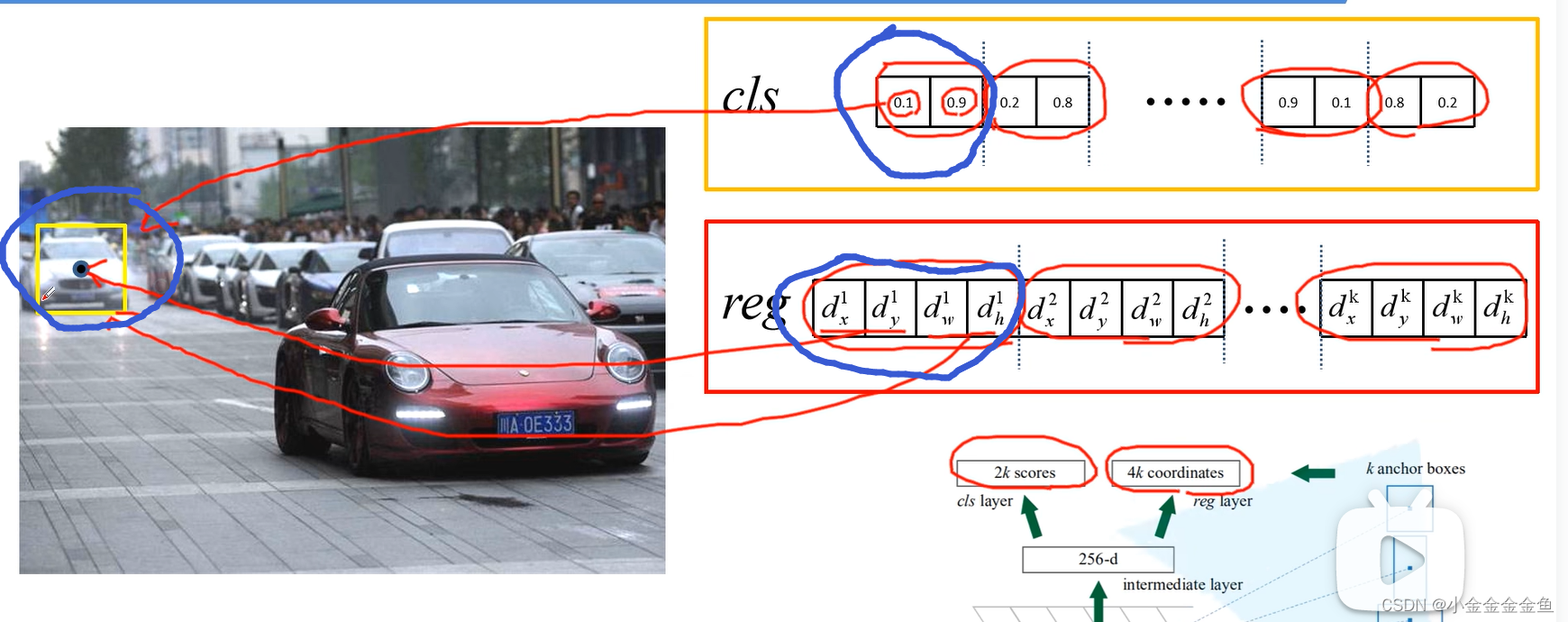
以此类推到第二个、第三个、第四个……第k个。
给出不同比例和尺寸的anchor:因为所检测的目标大小不一样,而且每个目标的长宽比也不一样。这里就给出了一系列的anchor来预测目标的位置。
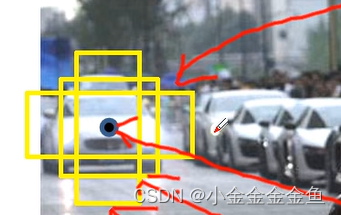
Faster R-CNN中给出的尺度和比例
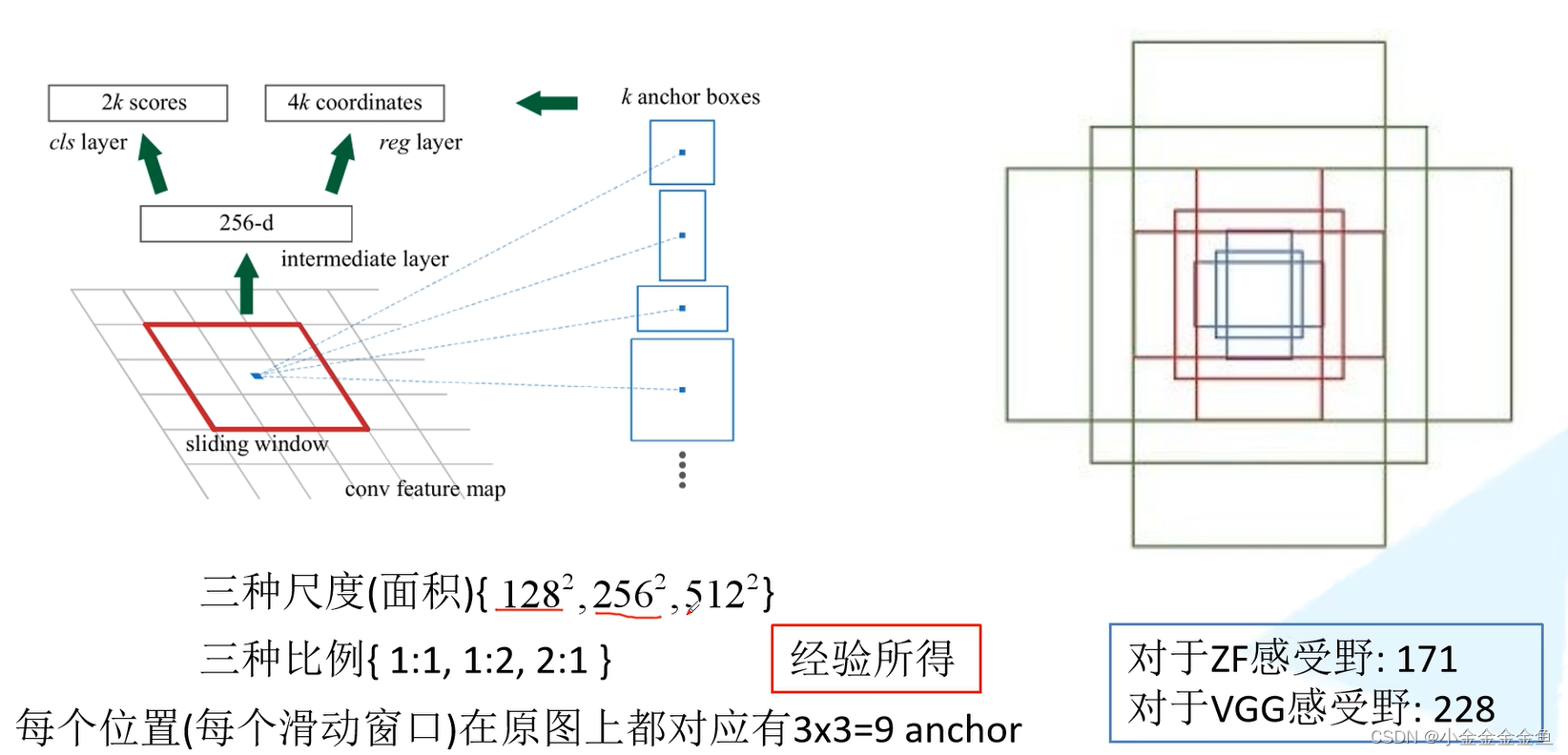
每个面积对应三种比例。
所以在每个地方都会生成9个anchor。
可以预测比感受野尺寸大的面积区域

- 感受野:
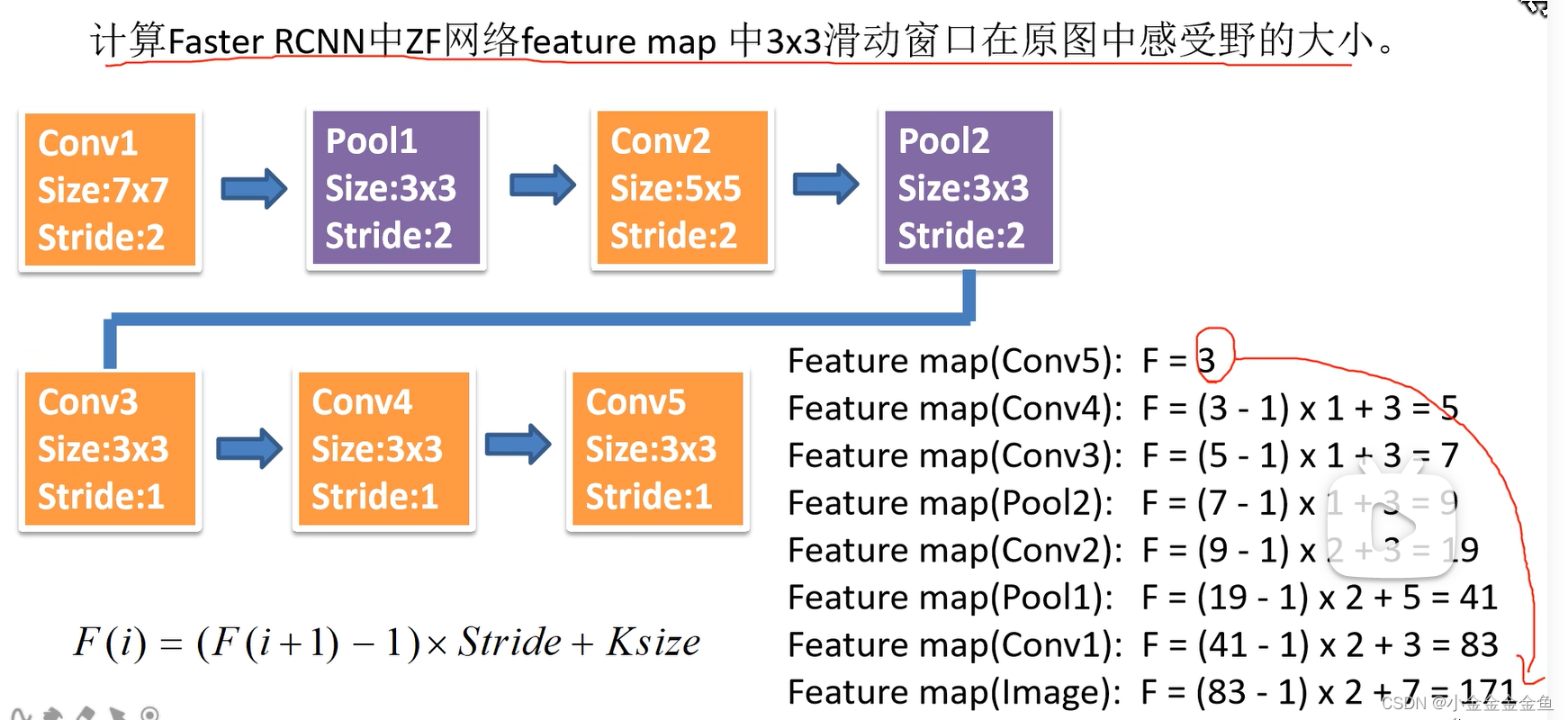
特征图3x3滑动窗口
计算到原图:171的感受野
(
假设最后一层为3x3维度
)
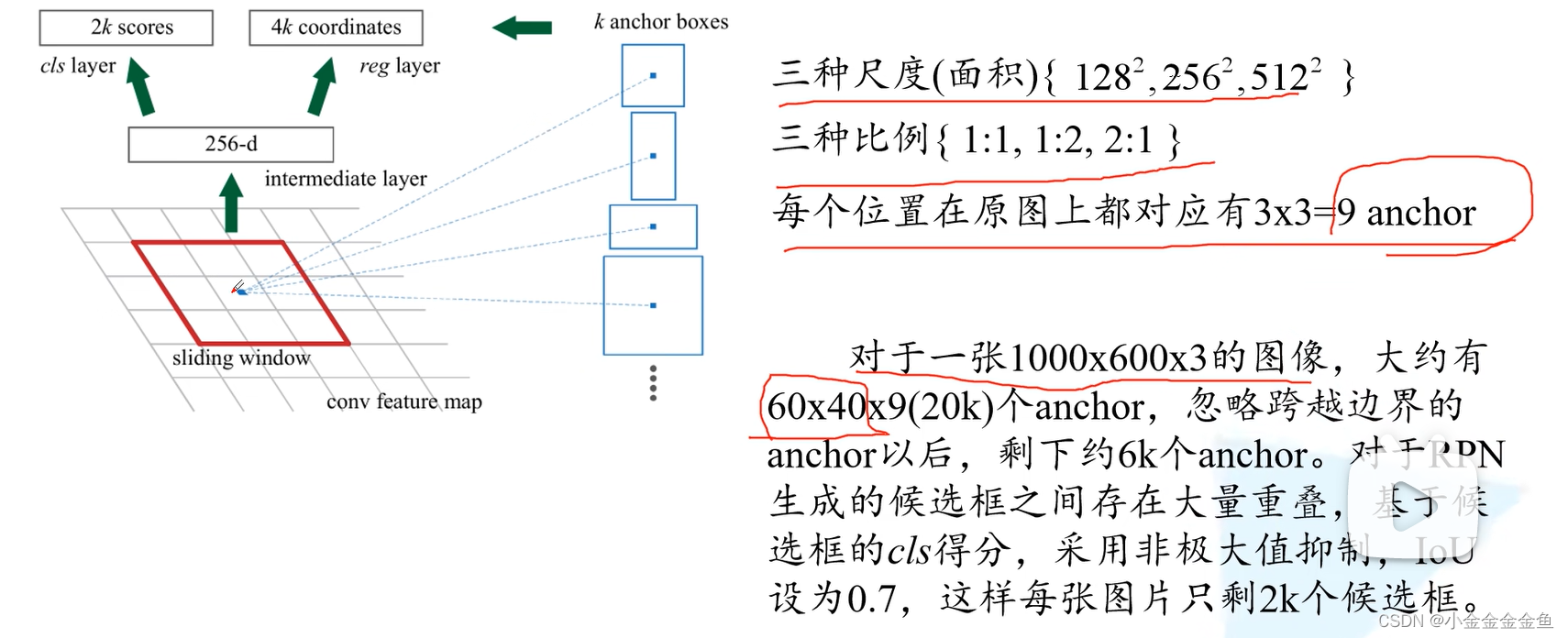
(
anchor经过RPN的回归参数调整后,才生成候选框;
anchor不是候选框,利用RPN生成的边界框回归参数,将anchor调整到所需的候选框
)
Faster RCNN损失计算
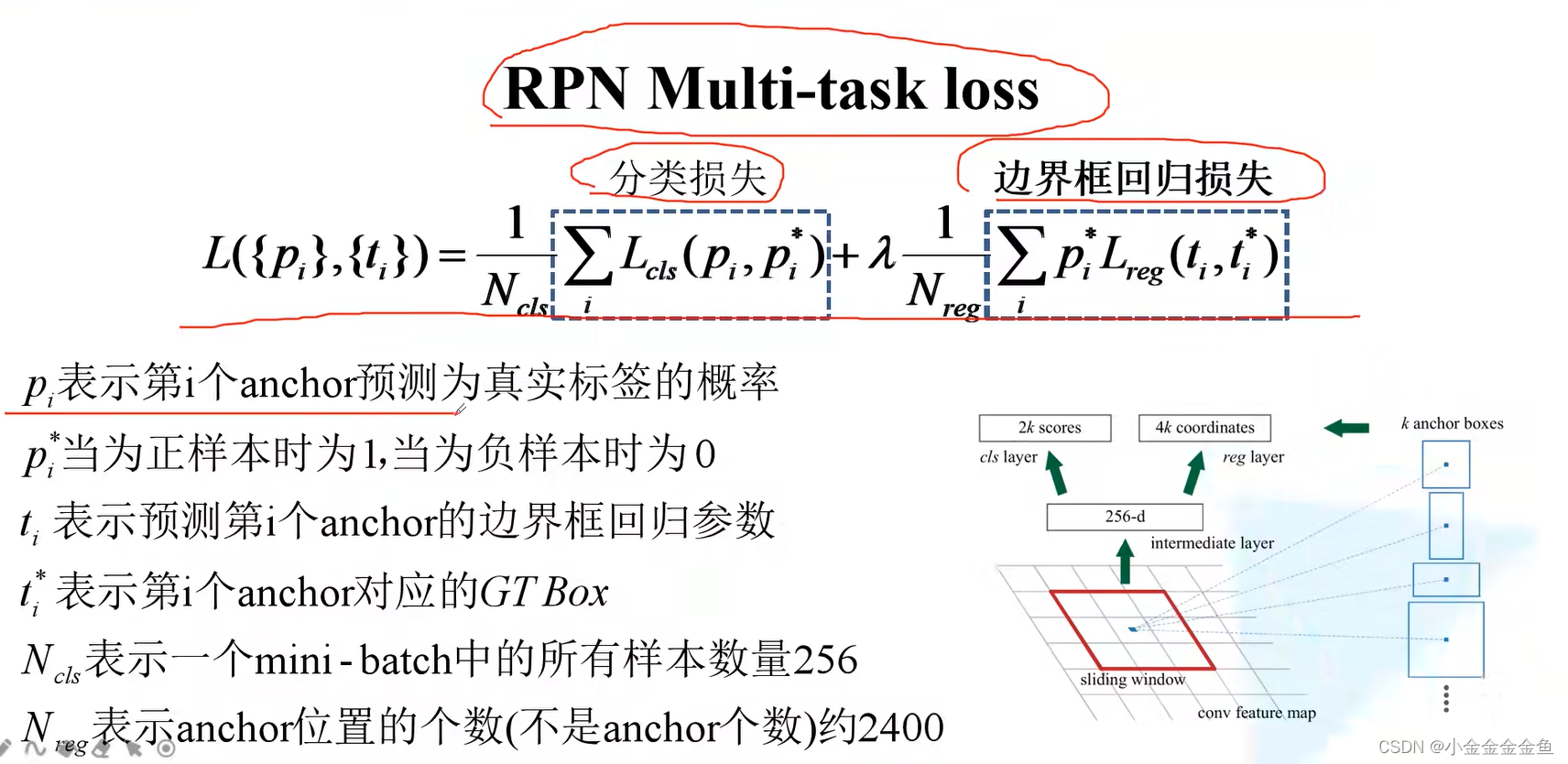
pi*与FAst RCNN中的艾弗森括号作用相同。
Nreg特征图上每个小方框都代表了一个anchor的位置,而不是anchor的个数。
λ平衡参数,平衡分类损失、边界框回归损失。
-
分类损失:
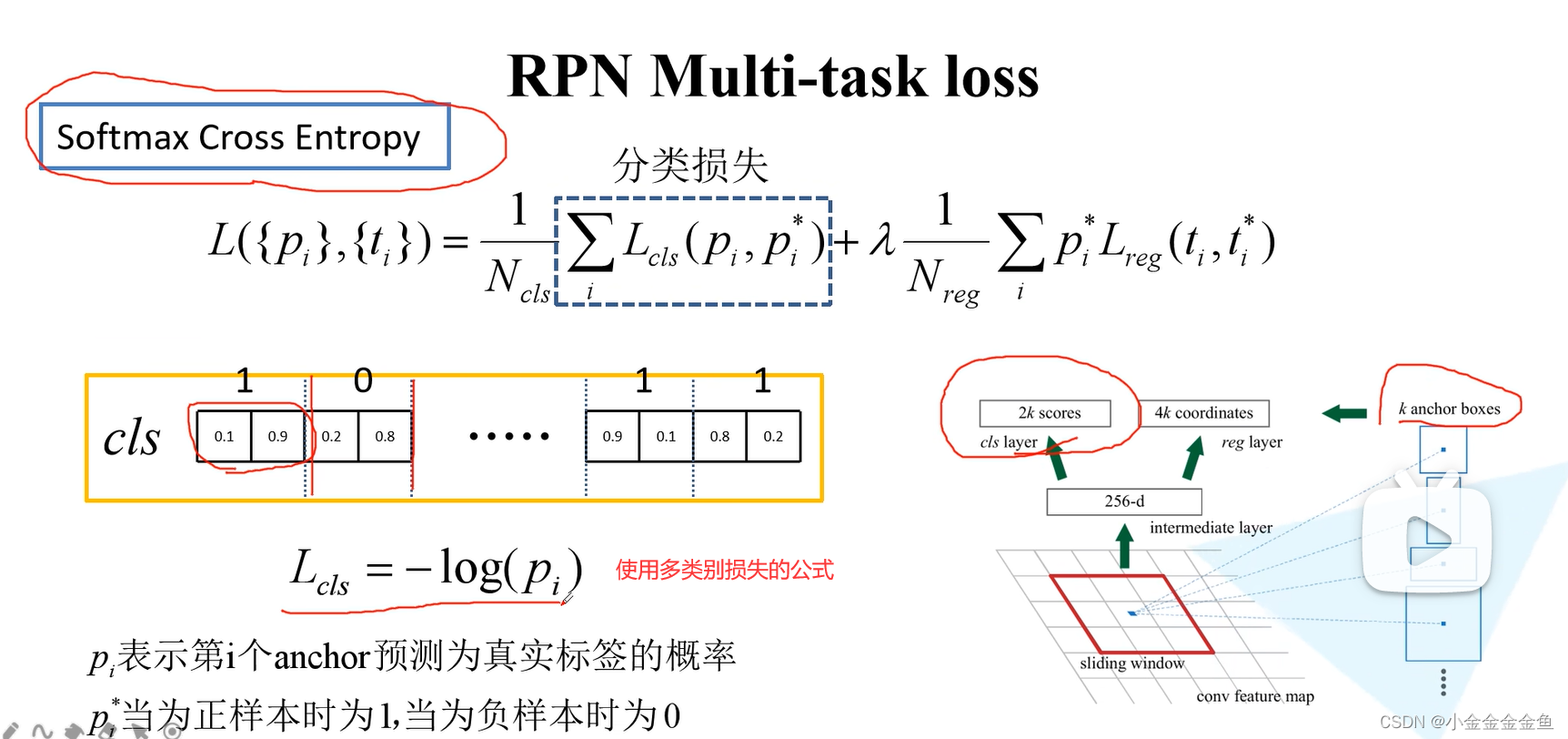
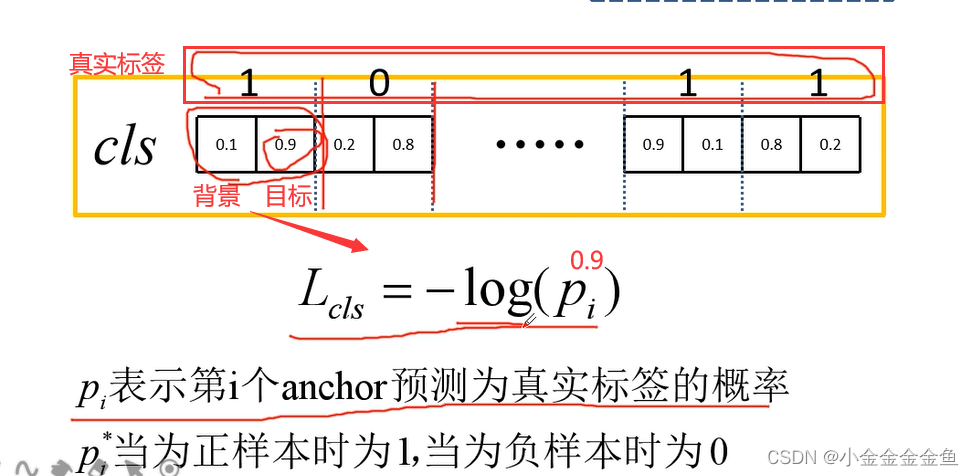
第一个anchor:
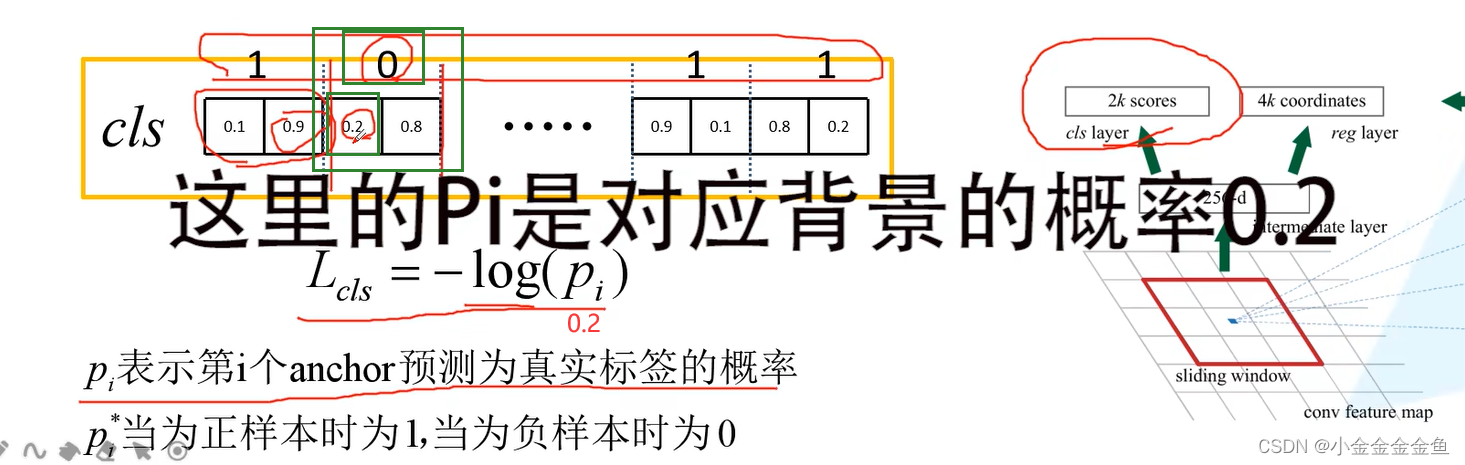
第二个anchor:
(
①写成热编码:
Pi代表的是预测为真实标签的概率
0—>(1,0) 所以loss=-log(0.2);
②正样本为(0,1)负样本为(1,0),k个标签拼起来长2k直接用交叉熵即可
)
另外一种损失的计算方法:
二分类交叉熵损失:对每个anchor只预测一个值,所以就不是2k,而是k了。
对于第一个anchor:
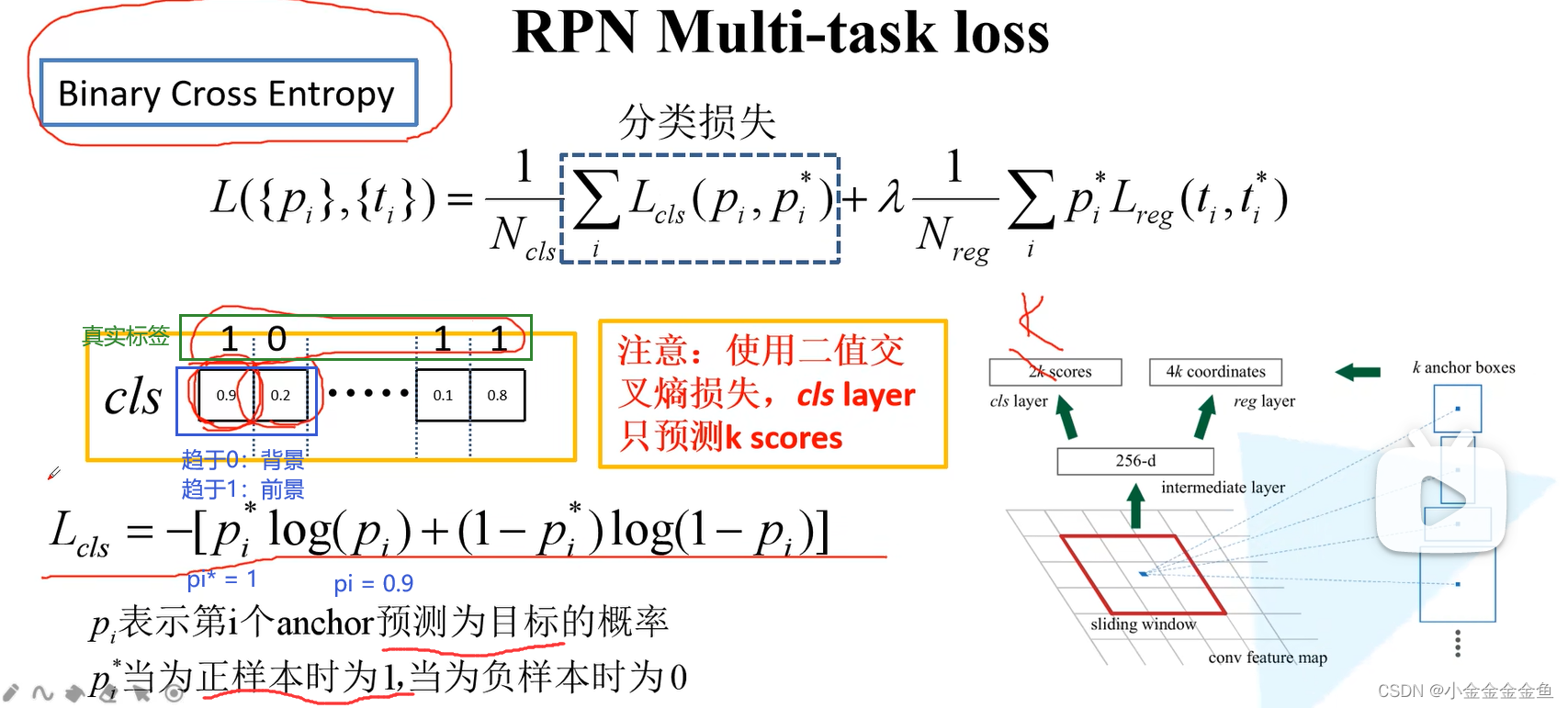
pytorch中官方文件faster RCNN就是二分类 -
边界框回归损失:
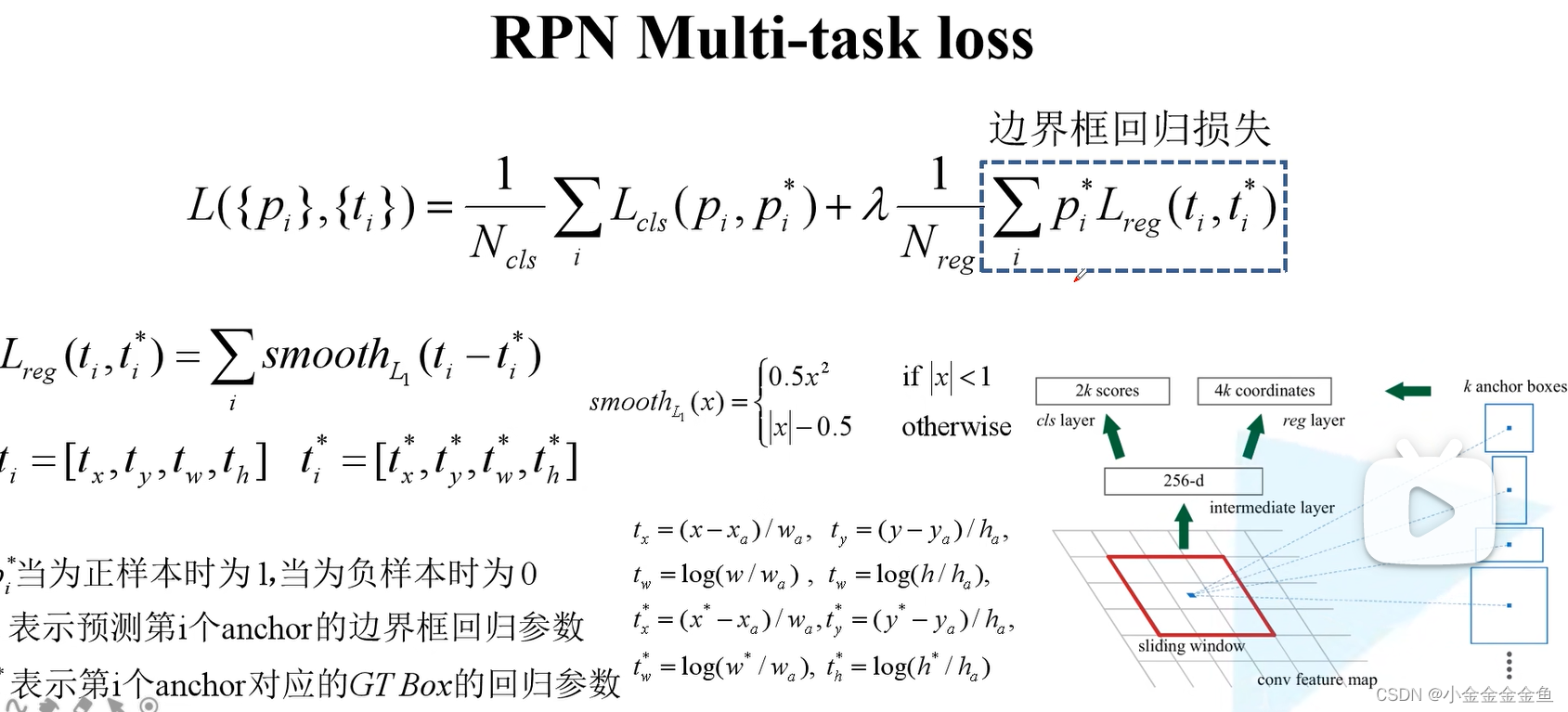
损失函数:smoothL1
ti:预测的
ti*:真实的边界框回归函数
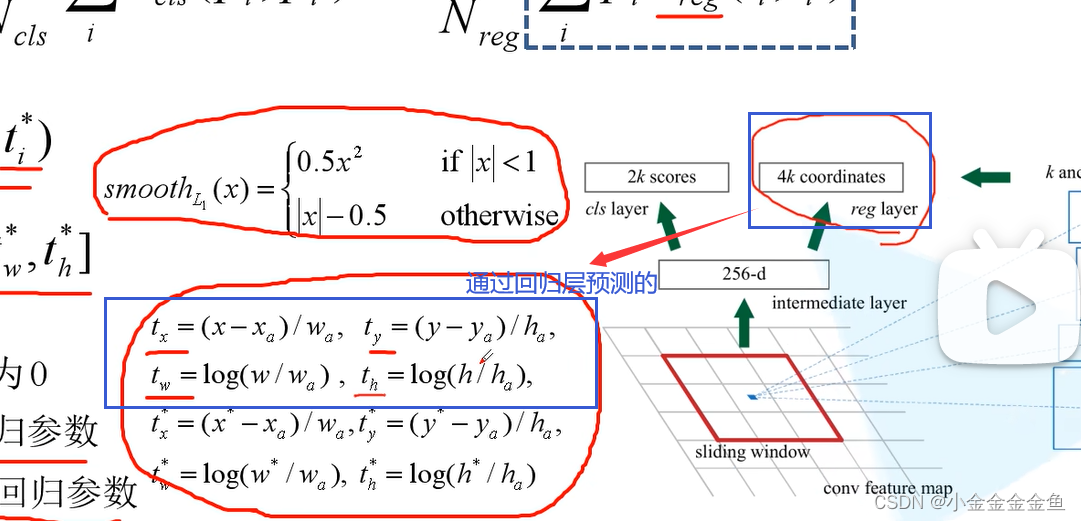

(
xa是anchor的中心点水平坐标
)
Faster RCNN训练
利用损失进行反向传播,训练网络

(1)中 初始化backbone部分的网络参数
(2)中固定RPN网络的权重参数,再去初始化backbone
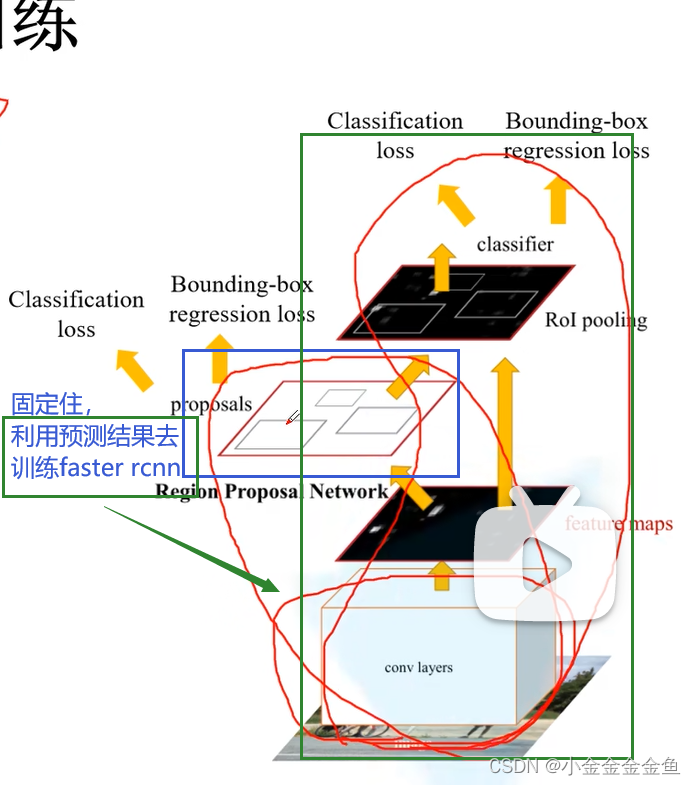
↑利用RPN的预测结果去训练faster rcnn
(3)中 固定训练faster rcnn得到的权重,把前置网络固定,单独训练RPN
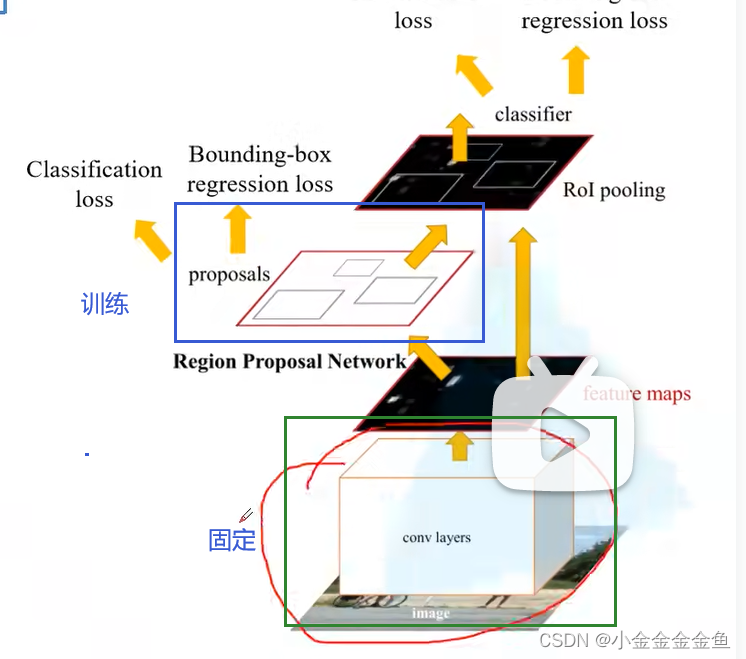
(4)中 保持backbone的权重不变,单独训练faster rcnn最后几层全连接层。
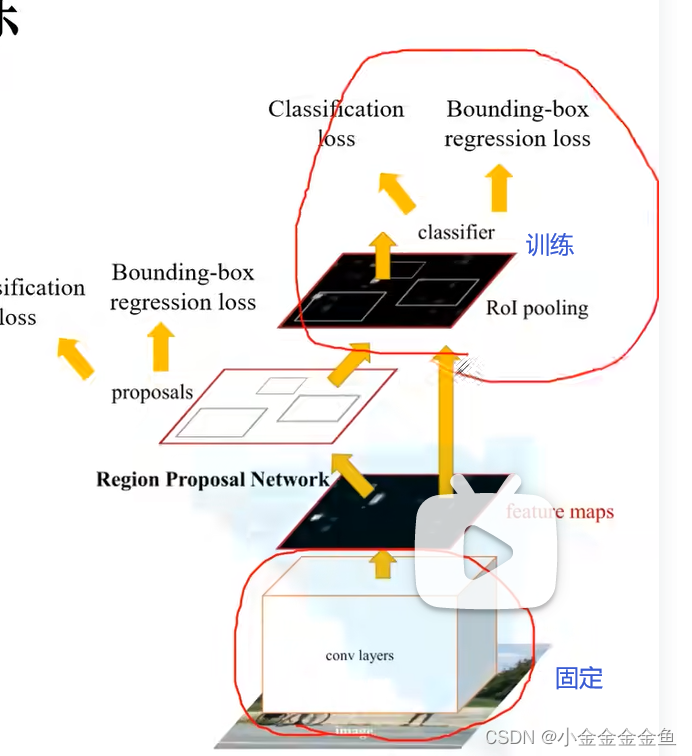
但是自己搭建faster rcnn时可以使用第一行的联合方法去训练。pytorch官方文件中也是使用的这个方法进行训练的。
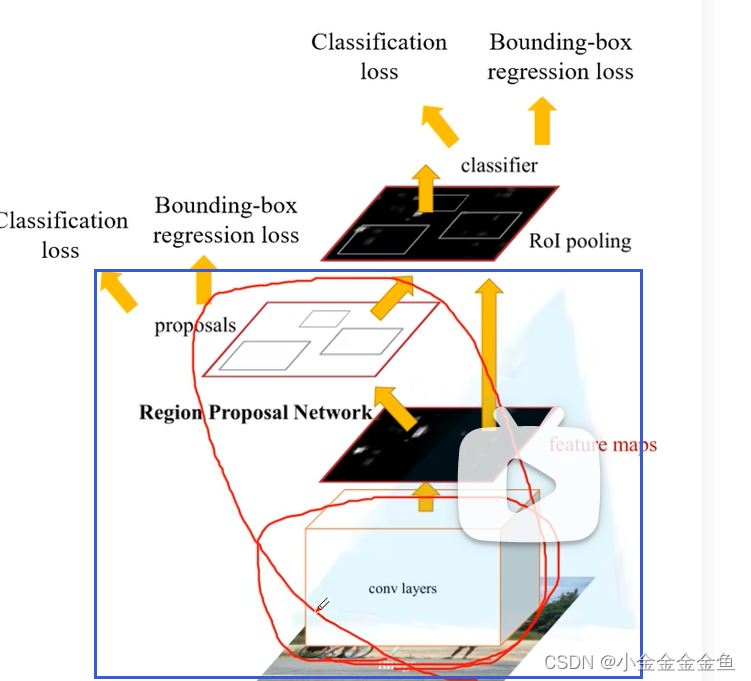
Faster R-CNN算法流程
1

2
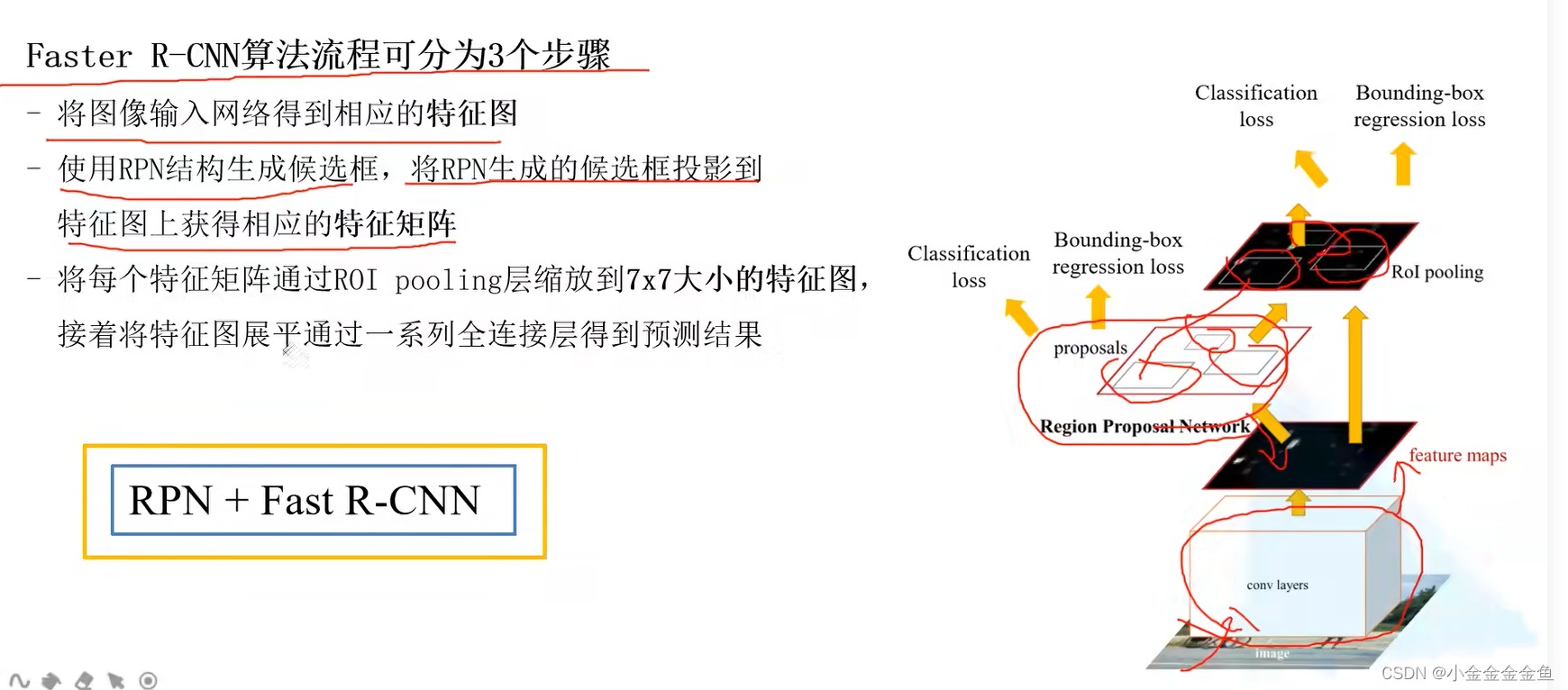
3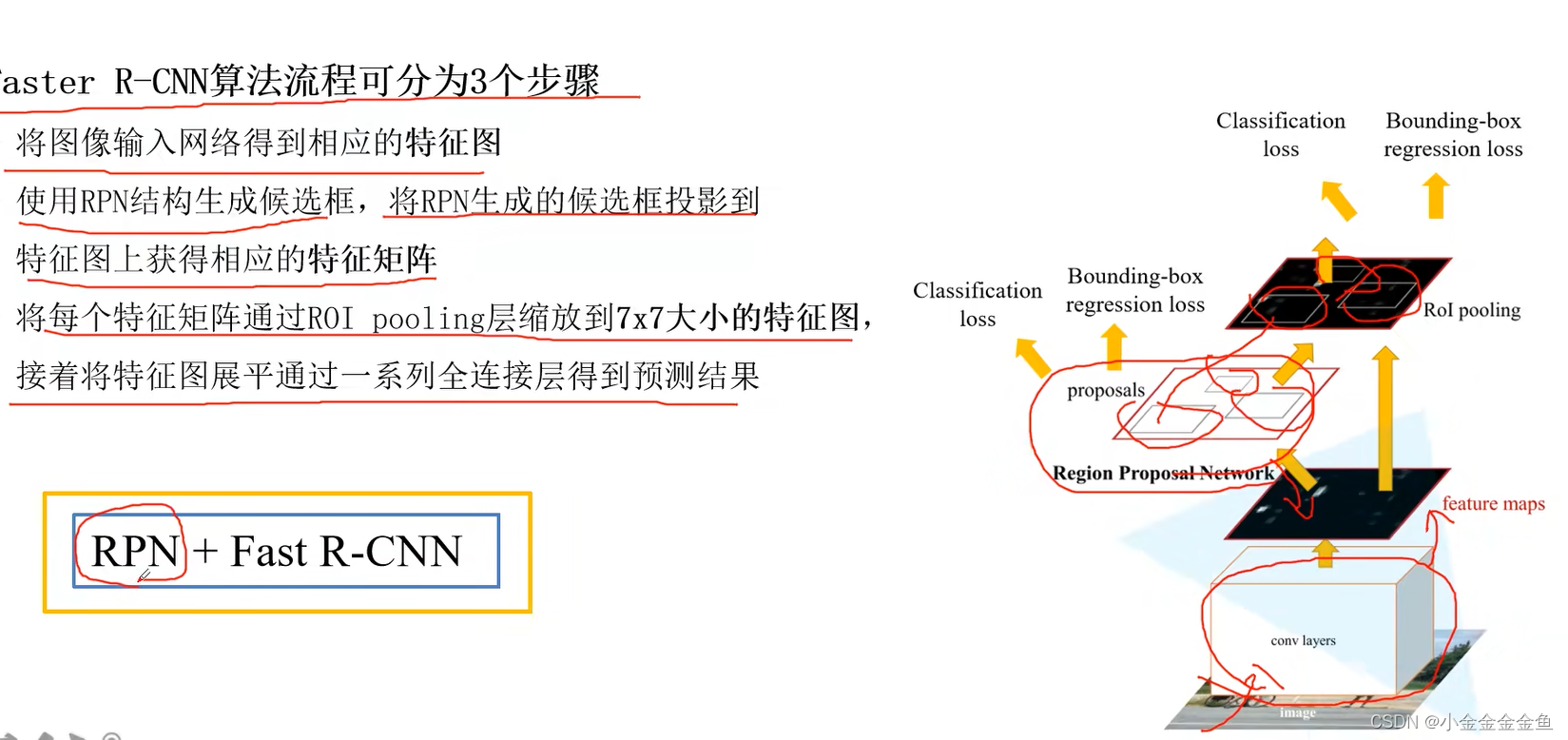
在训练、预测过程中,这是一个整体↓
不像Fast RCNN算法那样单独用SS算法生成候选区域。



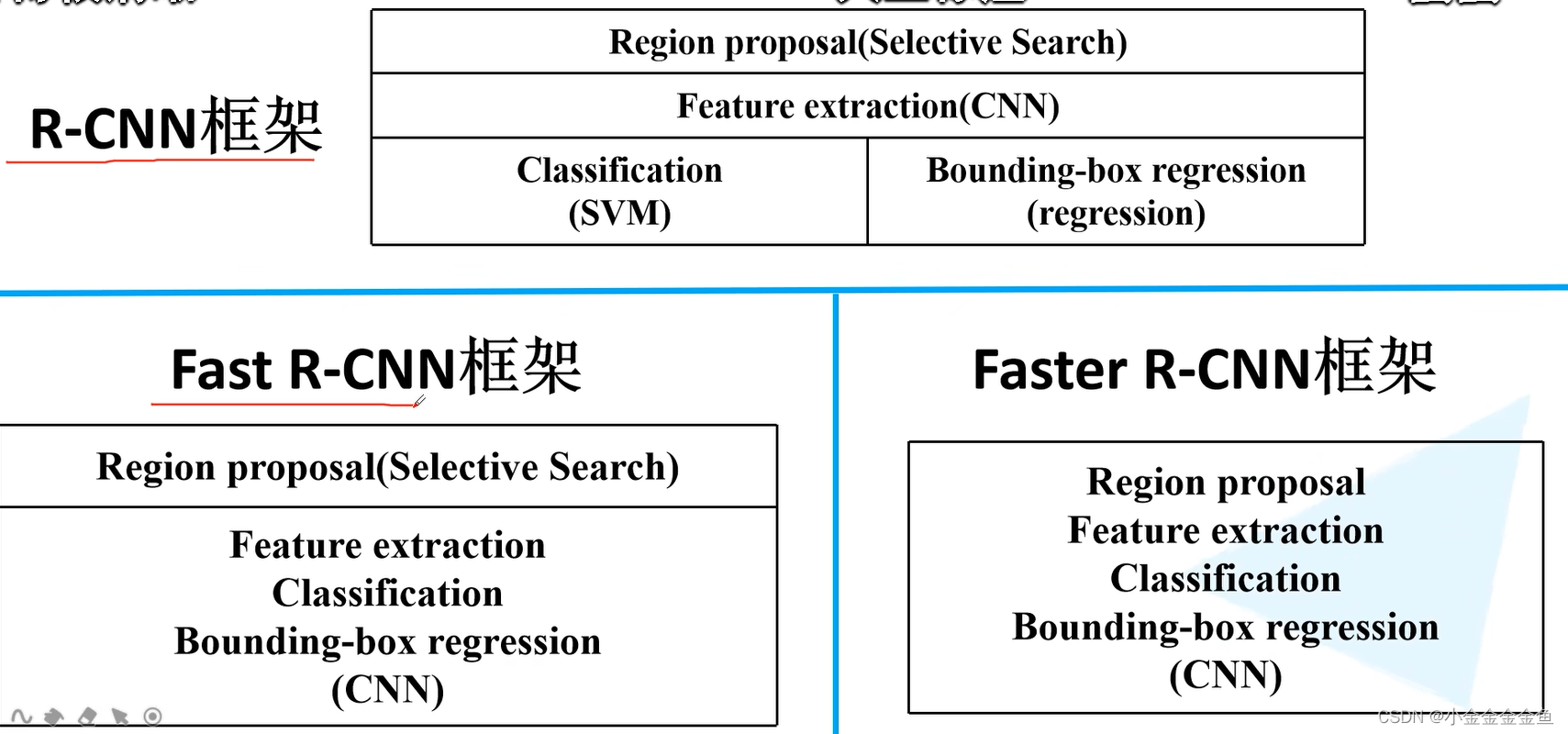
框架越来越简洁,效果越来越好