“ 通过介绍微信打造的大型中文预训练语言模型WeLM的设计思路、数据集、模型结构、训练方式、多样化的评估结果等方面,全面解析这一模型的技术原理和应用价值。”

01
—
微信的“chatgpt”叫做“WeLM”(WeChat Language Model)。
官方介绍:WeLM 是一个非常擅长理解和生成文本的通用语言模型。
WeLM没有对自然语言相关的任务做任何约束或者预置。仅通过调用模型来补全您输入的文本,可以体验或者完成各种自然语言的任务,例如:用户对话、问答、文案生成、文本改写、阅读理解、翻译、文章续写等语言任务。
用户可以通过调用 WeLM 的 API 解决多种多样涉及文本的任务。
官方地址:
https://welm.weixin.qq.com/docs/tutorial/
注意!!WeLM 没有提供聊天界面,只能通过填写表格,申请调用令牌 token 通过API 调用。
API 调用的限制 Limits and Quotas on API Requests:
Up to 30 requests every 1 minute for each token.
Up to 1000000 characters can be generated every 24 hours.
The quota is reset every 24 hours (starting from the first request, within the next 24 hours).
1分钟最多30个请求,一天最多生成100万个字符。
现有的文档资料中,没看到支持上下文的长度限制。后面技术文档里提到了2048的Content windows 大小,应该是这个数值长度。
02
—
数据
WeLM是在一个精选数据集上进行预训练的,该数据集来源多样,旨在覆盖多个领域。
(1) 中国社区使用了广泛的主题和语言;
(2) 数据经过严格的去重、降噪和过滤有害内容的处理,以确保高质量;
(3) 过滤掉与下游任务显著重叠的所有数据,以保证评估的公正性。
WeLM利用Common Crawl每月发布的碎片构建了一个通用的网页子集。
下载了2020年8月至2022年1月之间的所有WET文件,并使用langdetect 2过滤掉非中文页面。对于特定领域的语料库,混合了来自各种来源的数据,包括新闻、书籍、热门在线论坛以及学术著作。
与通用领域数据类似,WeLM使用langdetect来保留只有中文的数据源。此外,还添加了约750GB的英文数据,这些数据是从上述来源收集而来的,以便语言模型可以学习双语知识。完整的数据包括超过10TB的原始文本数据。
由于数据中存在大量噪音,如无意义的文本、冒犯性语言、占位符文本和源代码,尤其是针对通用领域爬取来的网络数据。
为了减少这些噪音,首先根据Raffel等人的方法应用一组基于规则的过滤器。在剩下的数据中,手动构建了一个平衡的标记数据集,包含80k个正负样本,正负比例为1:1。正样本是有效的、干净的文本,负样本是带有不同类型噪音的文本。
WeLM使用Fasttext 3在构建的标记数据上训练了一个二元分类器。只保留概率大于0.9的正样本。这个基于规则+Fasttext的过滤过程减少了87.5%的全部数据。
然后是对训练数据去重,WeLM采用了两步去重方法,包括使用md5算法过滤重复段落和使用SimHash算法去重相似内容的文档。最终成功去除了40.02%的重复内容。
为了消除数据污染并确保评估的公平性,使用类似于GPT-3中使用的方法,过滤掉与WeLM的开发和测试数据重叠的文本。
具体做法:计算每个文档与我们使用的开发和测试数据之间的17-gram匹配。如果在一个文档中找到≥2个重复的17-gram或1个重复的34-gram,就将其从语料库中删除。这进一步删除了剩余数据的0.15%。
经过过滤和平衡数据处理后,WeLM的语料库包含262B个标记。由于数据分布不均衡,又在预训练过程中对数据进行重新采样以平衡不同来源的数据。
通过这种方式,训练数据具有多样性和代表性,涵盖不同领域。经过平衡处理后,来自common crawl的数据占总数据的75%以上,但在平衡后,只有50%的训练数据来自common crawl。
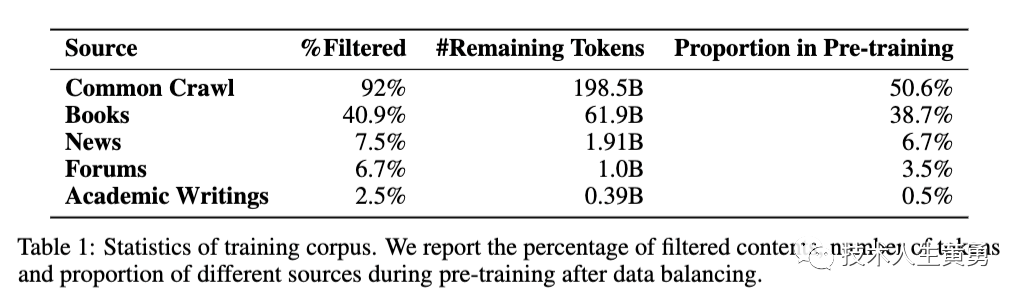
通过图表可以看出,common crawl的主题分布非常不均衡,大多数文档集中在少数几个主题上。经过数据平衡处理后,主题分布变得更加平滑。
03
—
模型和实现
WeLM使用基于Megatron-LM4和DeepSpeed5的训练和评估代码库,支持高效训练大型语言模型。
一个训练了四种不同大小的语言模型,从1.3B到10B。采用与GPT-3 相同的自回归Transformer解码器架构,但有一些主要的区别。
相对编码是基于相对位置的旋转位置嵌入,相比于原始的GPT中使用的绝对位置编码,相对编码在处理长文本的语义方面表现更好,对于需要对完整文章或书籍进行建模的任务非常有帮助。
使用了SentencePiece分词器,包含62k个标记,除了30k个中文标记外,还包括英语、日语和韩语等常用语言的常见词汇。保留所有空格和制表符,有助于下游任务。
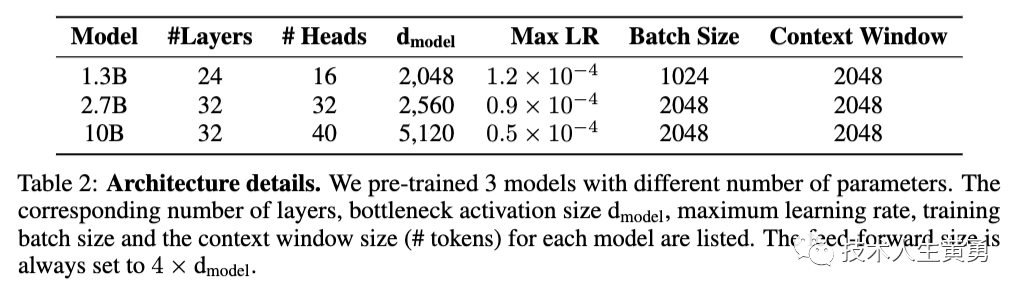
WeLM预训练了3个不同参数个数的模型。列出了每个模型对应的层数、瓶颈激活大小、最大学习速率、训练批量大小和上下文窗口大小(标记数)
(注:原文提到4个模型,但是图表中只列了3个模型的细节)
WeLM使用AdamW优化器进行模型训练,采用余弦学习率调度器。
使用DeepSpeed ZeRO stage 1优化来减少GPU内存消耗。当模型规模超过单个GPU时,使用张量并行方案。
所有模型都使用FP16混合精度训练,避免下溢。
训练时的批量大小为1024和2048,上下文窗口大小为2048。设置每个模型的最大学习率,并在训练过程中逐渐增加学习率,然后逐渐衰减。学习率在达到最小学习率后停止衰减,最小学习率设为最大学习率的10%。
根据Hoffmann等人的分析,随着计算预算的增加,模型大小和训练数据量应该以大致相等的比例增加。因此,WeLM选择在计算预算下使用128个A100-SXM4-40GB GPU训练一个10B大小的模型,训练数据量超过300B个标记。这是类似于GPT-3和Gopher的训练大小。最大的模型在大约24天内训练完成。
训练10B规模的模型时,会出现不稳定问题,导致损失突然上升,影响模型权重和收敛速度。
为了解决这个问题,可以从损失突然上升前的检查点重新开始训练,并跳过接下来的200个数据批次。同时,降低学习率和重置动态损失比例也有帮助。类似的策略也被其他研究者使用过。

图3a展示了训练损失曲线。图3b展示了在CLUE基准上模型性能的平均值,并将其可视化在训练过程中。
从上面图表可以看到,随着时间的推移,训练损失和平均模型性能都有所提高。较大的模型明显比较小的模型表现更好。
04
—
模型评估
为了测试WeLM模型在多个自然语言处理( Natural Language Processing, NLP)任务上的表现,采用了in-context learning方法,通过输入任务相关的提示信息,让模型继续预测单词并输出结果。
对于生成任务,直接使用WeLM解码生成答案。
对于分类任务,使用预定义的verbalizer将每个标签与某些单词相关联,然后在推理时使用WeLM计算这些单词的困惑度,选择困惑度最低的单词对应的标签作为模型预测。
为了评估WeLM的不同能力,用了四种评估方法:单语言评估、跨语言/混合语言评估、多种提示训练评估和其他发现评估。
其中,还包括WeLM的可解释性、自我校准和记忆能力等方面的研究。,以反思WeLM的不同能力。
单语言评估(中文)
WeLM在中文NLP任务中的评估中,进行了零样本 zero-shot和少量样本 few-shot两种情景的实验。评估数据集涵盖了18个中文NLP任务。与CPM、Pangu和Ernie 3.0等相似规模的中文预训练语言模型相比,WeLM在大多数任务中表现最好。
WeLM在中文机器阅读理解任务中表现优异,包括CMRC2018、DRCD和DuReader。将其作为生成任务,输入文本和问题,输出答案。在DuReader中,选择了Zhidao子集进行评估。WeLM在这项任务中表现显著优于其他模型。
WeLM在四个中文填空和补全任务上进行了评估:People_daily (PD),Children_fairy_tale (CFT),CHID和CMRC2017。
其中PD和CFT任务要求模型预测来自PD新闻数据集和CFT数据集的句子中的被掩盖的词语。
CHID提供了10个候选的中文成语,并要求模型从中选择正确的一个。
CMRC2017任务将查询中的普通名词和命名实体进行掩盖,并要求模型预测被掩盖的词语。
Ernie3.0在PD和CMRC2017上表现最好,而WeLM在其他任务上表现最好。这是预期的,因为PD和CMRC2017都是预测被掩盖的词语的任务,与Ernie 3.0的预训练目标相吻合。
NLI任务需要模型根据前提判断假设是否成立,分为三类:成立、矛盾、中立。使用中文GLUE基准测试中的CMNLI和OCNLI数据集进行3类分类任务,所有模型表现相似。这种任务在原始文本中很少出现。
WeLM在没有外部知识源的情况下回答问题,表现优异,比其他模型提高了10%以上的F1分数。评估使用的是WebQA数据集,该数据集包含来自百度知道的问题。将其视为生成任务,并通过比较模型生成的答案和真实答案来评估。
WeLM在中文隐含情感分析和ChnSentiCorp数据集上表现良好。情感分析是一项经典的NLP任务,需要模型确定给定文本的情感。
WeLM在情感分类任务上表现良好,能够处理三种情感类别,而ChnSentiCorp只有两种类别。此外,WeLM在零样本情况下也能取得良好的性能。
Winograd任务是一种需要世界知识和推理能力的句子对歧义解决问题。在CLUEWSC2020数据集上评估了WeLM模型,将任务转化为多项选择分类问题。WeLM表现最佳,但在少样本情况下,10B版本模型有所下降。
Pangu、Ernie3.0和WeLM在常识推理任务的评估,和使用的数据集C3,以及使用困惑度方法进行预测的结果上表现相似,Pangu在零样本情况下略优于WeLM,但在少样本情况下表现不佳。
在头条新闻标题分类(TNEWS)和科大讯飞应用描述分类(IFLYTEK)任务上的文本分类实验,WeLM在计算成本方面表现出色,并在这两个任务中明显优于其他模型。
文本摘要旨在提供给定长文本输入的简洁摘要。
现有的预训练语言模型通过使用类似“写一个标题/摘要”的模板来展示其零样本摘要技能。
在两个公共的中文摘要数据集上测试了WeLM的性能,结果表明WeLM可以产生合理的文本摘要。少量训练的WeLM生成的摘要更加多样化,但也可能会因词汇选择不同而导致ROUGE分数降低。

人工智能领域的一个核心挑战是开发具备足够智能的虚拟助手或聊天伴侣系统。
研究发现,WeLM在不进行任何微调的情况下,可以根据提示以不同的风格生成类似人类对话的内容。
例如,在示例中,WeLM可以扮演两个完全不同的角色:中国古代著名诗人李白和现代美国企业家埃隆·马斯克。
它甚至可以无缝地整合关于特定角色的正确背景知识。对李白来说,它利用李白曾经去过的地方和李白时代的真实历史事件来提供引人入胜的回应。对于ElonMusk来说,它利用自动驾驶和莎士比亚的知识来提供合理的答案。


文本风格转换是自然语言生成中的重要任务,可以通过预训练的大型语言模型实现零样本转换。WeLM可以根据用户需求,通过自然的人机交互,丰富和扩展给定的情境,改变句子的情感或反义词等。
句子完成是与预训练中使用的语言建模目标最相似的任务。下面的例子展示了WeLM如何完成给定句子并继续生成具有不同风格的长篇连贯文本的示例。

多语言评估
多语言评估包括机器翻译、跨语言问答和跨语言摘要。实验结果表明,WeLM在零样本和一次样本的情况下表现良好,且与XGLM相比表现不逊。
机器翻译是NLP中的一个经典子领域,研究如何使用计算机软件在没有人类参与的情况下在不同语言之间进行翻译。WeLM虽然主要是用中文文本进行预训练,但其中也混杂着大量的英文和日文字符。
WeLM在四个翻译方向上的表现:ZH2JA、JA2ZH、ZH2EN和EN2ZH。
在中日翻译中,JA2ZH和EN2ZH的表现明显优于ZH2JA和ZH2EN,这表明WeLM在理解外语方面比生成外语更好。与XGLM相比,WeLM在目标语言为中文的两个翻译任务中表现出色。
由于预训练语料库中日语文本的稀缺性,WeLM在ZH2JA任务上表现不佳。经验证明,WeLM在生成长篇日语文本时往往会出现语法错误或偏离源句子。
然而,在将日语和英语翻译成中文时,WeLM的表现非常出色。即使是1.3B版本的WeLM也能明显优于7.5B版本的XGLM,尽管参数只有其六分之一。
跨语言问答是指在不同语言的情况下回答问题,可以帮助人们更好地获取互联网上的信息。WeLM在XQuAD和MLQA数据集上进行了测试,表现良好。
如果使用不同语言的上下文、问题和答案,对预训练语言模型会有什么样的影响?
结果表明,使用主要语言作为提示可以提高模型性能。同时,WeLM在所有情况下都表现优于XGLM。使用中文问题时,WeLM的表现更好。
跨语言文本摘要旨在用不同语言总结输入文本。WeLM在NCLS数据集上的表现优于XGLM,但零样本表现较差。
代码切换是指说话者在两种或多种语言或语言变体之间交替使用。
在现代汉语中,常常出现英语或日语单词,因此理解代码切换文本是进行许多汉语自然语言处理任务的有用技能。
WeLM可以正确理解代码切换文本,例如在对话生成和任意风格转换示例中,我们将一个中文词语修改为相应的英文词语,WeLM仍然可以理解话语并产生正确的响应。
WeLM是一个能够正确翻译日语和英语的AI模型,它具备了多种语言的组合知识。这可能是因为在预训练语料库中存在多种语言和混合语言,使得WeLM能够探索跨语言对齐以降低训练损失。
研究发现,语言混合比例对于语言模型的性能有影响。在预训练过程中,将英文和中文的比例调整为1%和25%时,模型的性能都不如目前的13%英文和87%中文的模型。
在中文任务中,混合13%英文文本的模型表现最好,这可能是因为中文数据集中经常出现英文单词。而在英文任务中,不需要太多的中文知识,更好地专注于吸收英文知识。
05
—
多任务提示训练
通过手动编写提示,将WeLM训练在混合标记数据集上,得到了WePrompt模型,并在训练阶段未包含的任务上进行测试。显式多任务学习可以使无监督的WeLM适应不同的任务。
WeLM使用了一种改进的无监督语言模型,该模型在不同提示下的表现更好。
训练数据集
训练数据集的创建包括两个步骤:
(1)选择一组不同的标记中文NLP任务;
(2) 创建多个提示,每个提示针对每个任务都有不同的措辞。
提示是一种能够将一个标记样本转换为自然句子的模式。
提示是由内部的注释器使用基于BigScience Web的GUI 11创建的。
注释器被指示在其风格中是开放的,这样微调后的模型就可以通过不同的提示模式变得更加健壮。
提示示例如下图所示。
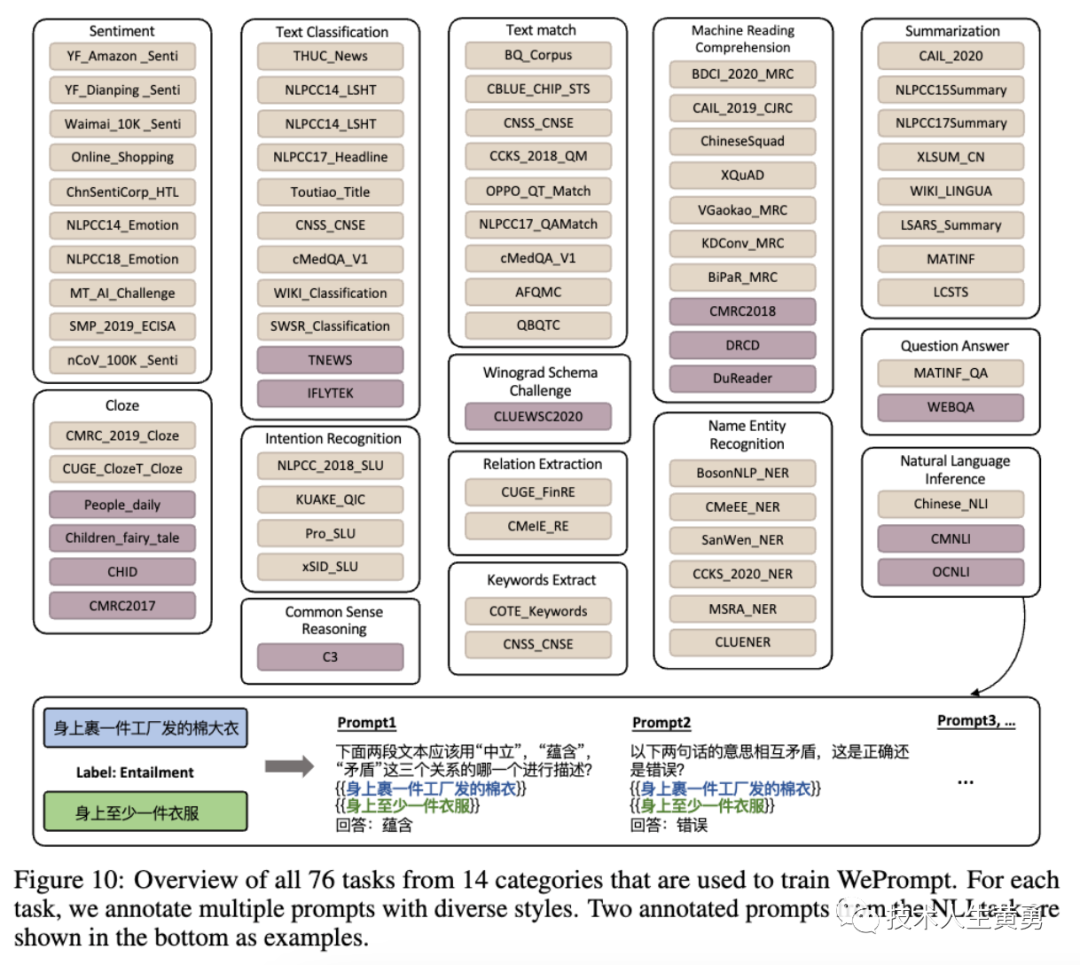
对于NLI任务,提示被创建为所有三个关系上的多选分类任务,或一个单独关系上的二元分类任务。
所有76个任务(14个类别的76个任务创建了1227个手动书写提示)的完整概述如图所示。用于评估的保留数据集以紫色显示,剩余的黄色数据集用于训练。所有76项任务都经过了重复检查,没有包含在WeLM的预训练语料库中。
WePrompt在零样本和微调性能方面表现出色,能够在大多数任务中超过体积为Ernie 3.0 Titan 23倍的模型。
WePrompt是一个能够在没有任何人工标注的情况下,自动为各种任务生成提示语的模型。
在强零样本评估中,WePrompt在训练时排除了与测试数据相同类别的所有任务,以测试其对新任务的泛化能力。
结果表明,WePrompt在大多数测试数据上表现优于零样本WeLM和Ernie 3.0 Titan,且能够产生更少的超出范围的答案。多提示语训练有助于帮助模型理解提示语的一般模式。
其中,零样本WeLM无法正确理解问题主题,而强零样本WePrompt虽然回答错误,但已经能够正确理解问题意思。
WePrompt模型的弱零样本评估方法:即在训练WePrompt时,仅排除测试数据所属的任务。结果表明,弱零样本WePrompt在大多数任务上表现优于强零样本WePrompt,但在PD和IFLYTEK任务上表现不佳。
官方认为这可能是因为语言建模和填空任务之间的相似性导致的。
此外,WePrompt对于闭卷问答任务的提升也不明显,因为这类任务在预训练语料库中已经频繁出现。
06
—
其他能力评估
官方还提供了对WeLM的另外三个能力的评估:
解释能力 Explainability:WeLM是否能够通过提供解释来解释其决策,并且解释是否能够提高模型性能。
自我校准 Self_Calibration:WeLM是否能够通过询问自身来校准其预测结果,判断预测是否正确。
记忆 Memorization:WeLM能够在多大程度上记住预训练语料库中的内容,并且频率对其记忆的影响如何。
自我解释
深度神经网络的可解释性是一个非常重要的特征,缺乏可解释性会导致人们难以信任其预测。
最近的研究表明,大型预训练语言模型可以在给定适当的说明的情况下生成预测和解释。
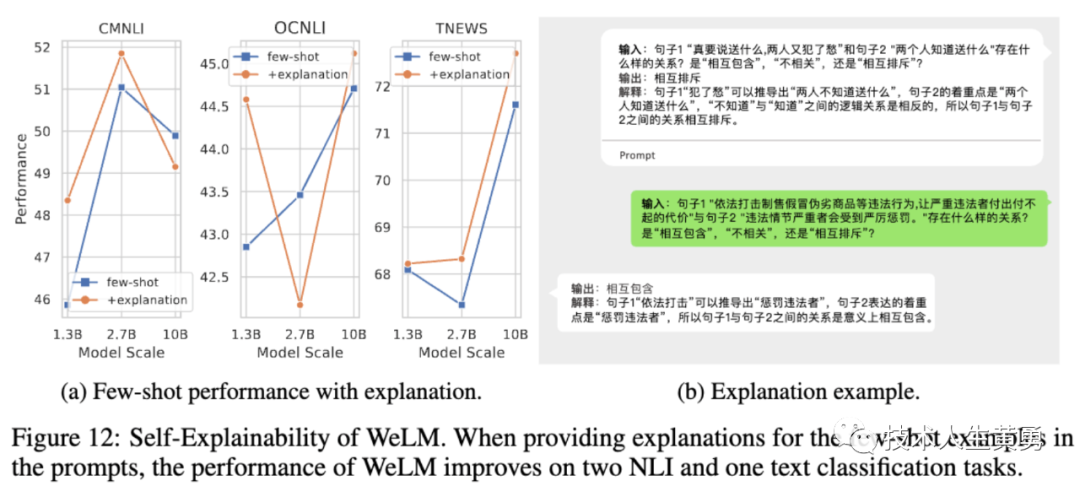
上图测试了WeLM在三个任务上添加说明是否能够产生合理的解释,并发现添加说明通常可以提高性能,但提高程度不稳定,高度依赖于任务和提供的说明。
在CMNLI上,11-B WeLM在提供额外说明时表现甚至更差。在OCNLI上,2.7-B WeLM表现更差,但其他版本表现更好。在给定的示例中,我们可以看到WeLM可以模仿提示中给出的风格,为其预测产生合理的解释。
自我校准
自校准是指校准模型的预测结果。
例如,我们可以在模型提供预测结果后,提供进一步的输入来检查其准确性。WeLM能够根据不同的模型预测结果做出不同的回应。这种方法可以检查模型的行为和推理是否准确。

WeLM模型可以通过自我校准来提高其预测能力。它能够区分自己的正确和错误预测,并且在识别含有不礼貌词汇的文本方面表现良好。
记忆
根据WeLM在大规模网络内容中的预训练,测试了其记忆能力,并发现模型可以记忆一些内容,但比例不高。
较大的模型通常可以跨数据源记忆更多内容。Common crawl内容占据了训练数据的一半以上,因此WeLM可以更好地记忆它们。
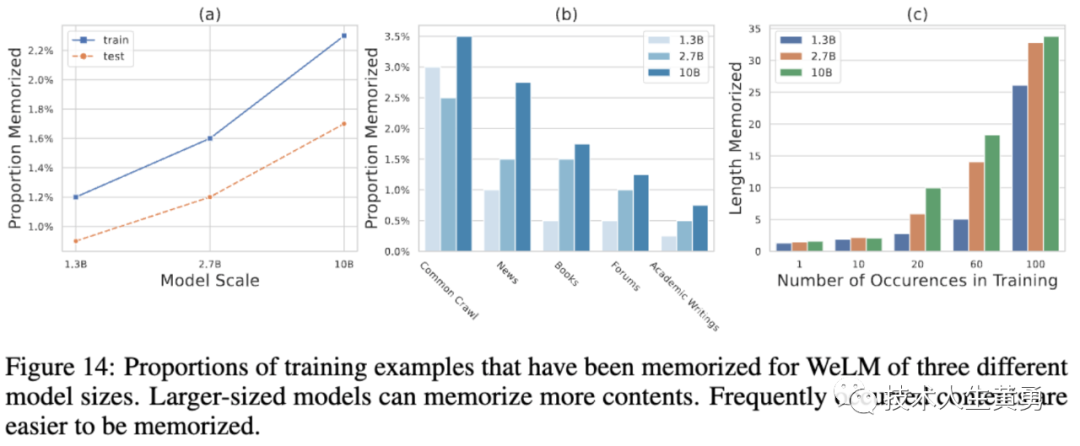
学术写作由于在训练数据中的低频率和独特的风格,是最难记忆的。同时,模型可以更好地记忆出现频率更高的文本。
模型只能记住出现一次的文本内容,无法记住太多内容。
07
—
总结
WeLM是一个针对中文的预训练语言模型,能够无缝地执行不同类型的任务,无需零或少量示范。
它在单语(中文)和跨语言(中英文/日文)任务中表现出色,超过了类似规模的现有预训练模型。
微信团队使用人工编写的提示为一大批中文监督数据集收集了数据,并通过多提示训练对WeLM进行了微调。结果模型能够在未见过的任务类型上具有强大的泛化能力,并在零示范学习中胜过无监督的WeLM。
并且WeLM具有解释和校准自身决策的基本技能。
最近各大厂都纷纷发布了自己的模型,而腾讯家未见相关新闻,翻了一下,才发现这个微信的大模型WeLM,而且很低调。不光低调,而且快有一年没有更新了。
个人猜测,大模型方向是不是在鹅厂内部被叫停了。有消息灵通的朋友知道详情吗?
参考地址
https://arxiv.org/abs/2209.10372
https://welm.weixin.qq.com/docs/tutorial/
阅读推荐:
人工智能海洋中的塞壬之歌:大型语言模型LLM中的幻觉研究综述(一)
你好,我是百川大模型|国内可开源免费商用Baichuan2揭秘
什么是AI的“智能涌现”,以及为什么理解它对创业者、从业者、普通人都价值巨大
提示攻击再次攻击大模型,被催眠后的ChatGPT可能会泄露重要信息-大模型的隐藏风险
人工智能安全吗?OpenAI正在让大模型和人类“对齐”-确保ChatGPT比人类聪明的同时还遵循人类意图
REACT:在语言模型中协同推理与行动,使其能够解决各种语言推理和决策任务。
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。