一、为什么会出现分库分表
应用数据量过大,mysql服务器无法支持怎么办?
方案一:通过提升服务器硬件能力来提高数据处理能力,比如增加存储容量 、CPU等,这种方案成本很高,并且如果瓶颈在MySQL本身那么提高硬件也是有很的。
方案二:把数据分散在不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的,如下图:将电商数据库拆分为若干独立的数据库,并且对于大表也拆分为若干小表,通过这种数据库拆分的方法来解决数据库的性能问题。
二、分库分表的四种实现形式
分库分表包括分库和分表两个部分,在生产中通常包括:垂直分库、水平分库、垂直分表、水平分表四种方式。
垂直分表
将一个表按照字段分成多表,每个表存储其中一部分字段。
- 为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
- 充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
垂直分库
按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
它带来的提升是:
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
- 垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
水平分库
是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
它带来的提升是:
- 解决了单库大数据,高并发的性能瓶颈。
- 提高了系统的稳定性及可用性。
- 当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
水平分表
是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
它带来的提升是:
- 优化单一表数据量过大而产生的性能问题
- 避免IO争抢并减少锁表的几率
- 库内的水平分表,解决了单一表数据量过大的问题,分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
三、分库分表常用技术方案:
分库分表的技术方案总体上来讲分为两大类:应用层依赖类中间件、中间层代理类中间件。
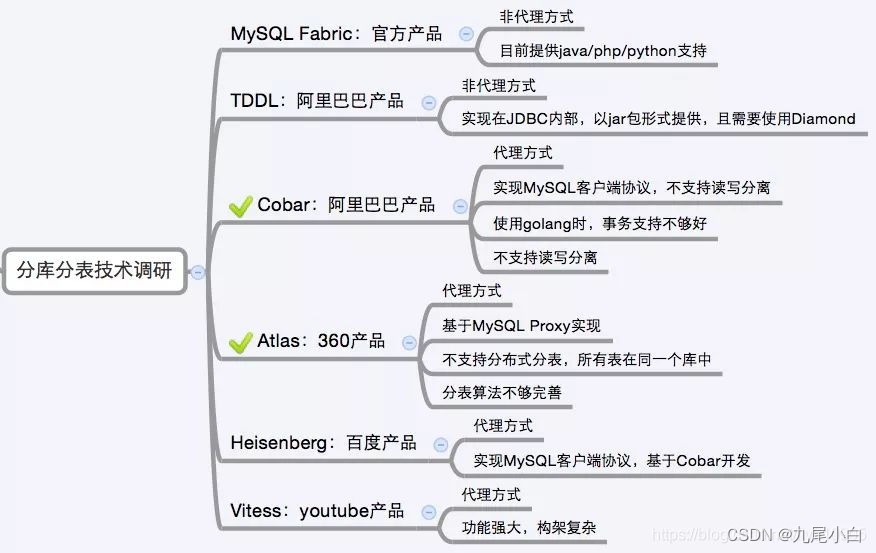
1.应用层依赖类中间件
这类分库分表中间件的特点就是和应用强耦合,需要应用显示依赖相应的jar包(以Java为例),比如知名的TDDL、当当开源的sharding-jdbc、蘑菇街的TSharding、携程开源的Ctrip-DAL等。
此类中间件的基本思路:
就是重新实现JDBC的API,通过重新实现DataSource、PrepareStatement等操作数据库的接口,让应用层在基本(注意:这里用了基本)不改变业务代码的情况下透明地实现分库分表的能力。
中间件给上层应用提供熟悉的JDBC API,内部通过sql解析、sql重写、sql路由等一系列的准备工作获取真正可执行的sql,然后底层再按照传统的方法(比如数据库连接池)获取物理连接来执行sql,最后把数据结果合并处理成ResultSet返回给应用层。
**优点:**就是无需额外部署,只要和应用绑定一起发布即可
**缺点:**就是不能跨语言,比如Java写的sharding-jdbc显然不能用在C#项目中,所以携程的dal也要重新写一套C#的客户端。
2.中间层代理类中间件
这类分库分表中间件的核心原理是在应用和数据库的连接之间搭起一个代理层,上层应用以标准的MySQL协议来连接代理层,然后代理层负责转发请求到底层的MySQL物理实例,这种方式对应用只有一个要求,就是只要用MySQL协议来通信即可,所以用MySQL Workbench这种纯的客户端都可以直接连接你的分布式数据库,自然也天然支持所有的编程语言。比较有代表性的产品有开创性质的Amoeba、阿里开源的Cobar、社区发展比较好的Mycat 等。
原博文及相关扩展:
分库分表:中间件方案对比
TDDL
分库分表-分布式事务理论和方案