完全二叉树
满二叉树:二叉树每个节点的度都达到最大值(2),由此可有等比求和计算出节点总数:2^k-1
完全二叉树:除了最后一层。前面节点的度都满了,最后一层可以不满,但是必须从左至右连续,所以满二叉树也是完全二叉树的一种特殊形式,其总结点的范围在:2^(k-1) ~ 2^k-1
而满二叉树也是完全二叉树的一种特殊形式

二叉树的顺序结构与实现
其实堆就是一种特殊的二叉树结构(完全二叉树),但是堆实现排序相较于冒泡排序是相当快的,并且堆也可以迅速的找出一堆数据中的前几个最值,而堆恰恰就是用顺序表数组来实现的,所以就先来了解一下二叉树顺序结构。
二叉树的顺序结构
完全二叉树的形式可以很好的与数组契合,因为节点的连续性,所以用顺序表结构的数组存储完全二叉树是十分合适的,并且可以直接通过数组下标的关系找到对应的子节点和父节点。

而对于二叉树的其他形式是不适合用数组来存储的,可能会复杂并且存在空间的浪费。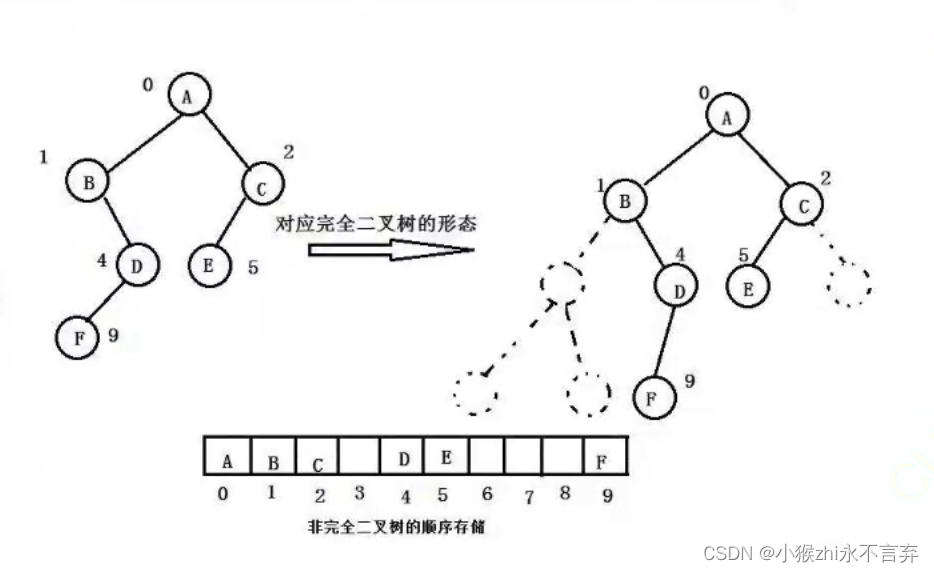
堆的概念与结构
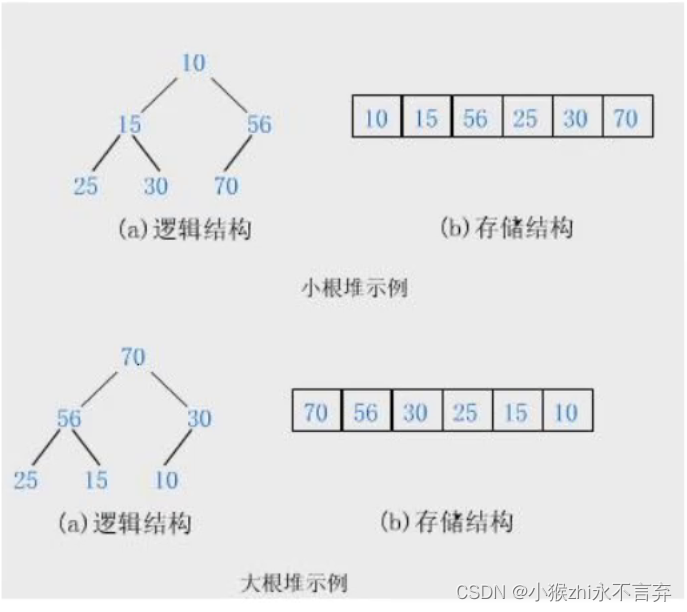
首先我们要知道,堆的结构是完全二叉树,并且推也分为两种:大(根)堆,小(根)堆。
而堆也只有大堆和小堆两种形式,其他不满足条件的都不属于堆。
大(根)堆:树中的任意一个节点存储的值都小于等于其父节点存储的的值
小(根 )堆:树中的任意一个节点存储的值都大于等于其父节点存储的的值
堆的基本实现
堆是可以用顺序表结构的数组来实现的,所以可以借鉴前面栈的实现方法,而下面介绍的是大(根)堆的写法:
需要实现的函数
typedef struct Heap
{
int sz;
int capacity;
int* arr;
}Heap;
void Init(Heap* hp);//初始化堆
void Push(Heap* hp, int x);//增数据
void Pop(Heap* hp);//删数据
int GetTop(Heap* hp);//得到根数据
void Destroy(Heap* hp);//空间释放void Init(Heap* hp)
{
hp->arr = (int*)malloc(sizeof(int) * 3);
hp->capacity = 3;
hp->sz = 0;//指向实际数据的下一个节点
}
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void Adjust_up(int* arr,int child)
{
while (child > 0)
{
int parent = (child - 1) / 2;//不可以作为while的条件,child==0时
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
child = parent;
}
else
return;
}
}
void Push(Heap* hp, int x)
{
if (hp->sz == hp->capacity)
{
hp->capacity *= 2;
int* tmp = (int*)realloc(hp->arr, sizeof(int) * hp->capacity);
assert(tmp);
hp->arr = tmp;
}
hp->arr[hp->sz] = x;
hp->sz++;
//向上调整保证是堆
Adjust_up(hp->arr,hp->sz-1);
}
void Adjust_down(int* arr,int last)
{
int parent = 0;
int child = parent * 2 + 1;//假设较大值是左孩子
while (child<last)
{
if (child + 1 < last && arr[child] < arr[child + 1])//先防止越界,再验证较大值(只有一个左孩子时可能会越界)
child += 1;
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
return;
}
}
void Pop(Heap* hp)//删除根节点的数据
{
assert(hp->sz);//保证有数据
//防止改变堆的父子大小关系,保证其他数据的关系不变,则选择尾元素换到头
hp->arr[0] = hp->arr[hp->sz - 1];
hp->sz--;
//向下调整
Adjust_down(hp->arr,hp->sz);
}
int GetTop(Heap* hp)
{
assert(hp->sz);
return hp->arr[0];
}
void Destroy(Heap* hp)
{
free(hp->arr);
hp->capacity = hp->sz = 0;
}
这里其实看一下Adjust_down 和 Adjust_up 这两个函数的实现就行了,主要就是插入数据时要用到向上调整数据,而删除根元素时会用到向下调整数据,这两个函数使用之前都要保证原数据的父子关系不会发生改变,即:除了增加或删除的数据,其余子树都是堆的形式。
用堆进行排序
经过堆的实现,我们知道一个数据按照堆去存放,根节点的值要么是最大值要么就是最小值,所以我们多进行几次不就可以依次得到最大值(最小值)。假如用实现大(根)堆的方式来实现,首先将数组中的数一个个按照向上调整建堆的方式插入进去,这样根就是最大的一个数,此时接下来就有两种途径:1.将剩余的数继续按照向上调整的方式再次建堆,找第二大的数(这样就改变了其他数之间的父子关系,故要全部重新插入)。2.将最后一个数和根(最大值)进行交换,再运用向下调整(类似于Pop 函数)实现接下来操作(这样不会改变原数据的父子关系,所以子树依旧是大堆的形式)。所以第二种方式就轻松了很多。
向上调整建堆法
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void Push(int* arr,int child)
{
while (child > 0)
{
int parent = (child - 1) / 2;
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
child = parent;
}
else
return;
}
}
void Pop(int* arr,int len)
{
int parent = 0;
int child = parent * 2 + 1;//假设较大值是左孩子
while (child<len)
{
if (child + 1 < len && arr[child] < arr[child + 1])//先防止越界,再验证较大值(只有一个左孩子)
child += 1;//可能存在越界
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
return;
}
}
int main()
{
int arr[] = { 6,1,7,0,3,5,8,2,9,4 };
int len = sizeof(arr) / sizeof(int);
for (int i = 1; i < len; i++)//向上建堆
{
Push(arr, i);//传下标
}
while(len>0)
{
Swap(&arr[0], &arr[len-1]);//将最大值放到最后面
Pop(arr, len - 1);//传最后一个数的下一个下标
printf("%d ", arr[len-1]);
len--;//每循环一次就排好了一个数
}
return 0;
}有一点要注意的是,每次找到最大的数换到数组的最后,则每向下调整一次就得到当前推中的最大值,数据就会逐渐少一,所以依次进行之后数据就按照升序的方式排列了,即:运用大根堆法实现升序,运用小根堆法实现降序。
向下调整建堆法
上面的堆排序其实是运用向上调整来建堆,并交换首尾两数运用向下调整重新建堆。那么可不可以建堆也用向下调整的方式来完成呢,而在一份完整的数据面前我们想用向下调整的条件是:该节点的左右子树都是大堆(小堆)的形式才可以。
假如我们想要建立一个小堆。就以上面代码中的数组为例,我们现在的目的就是找可以向下调整的节点,即:该节点的左右子树都是小堆,而我们从图中可以确定的小堆就是最靠近叶节点的分支节点,因为该分支节点的两个分支是叶节点,故一定是小堆,即图中为3的节点,所以我们就从该位置开始向下调整,并且要逆着继续执行,找前面的分支节点,就依次从后向前,这样就可以保证你任何时候向下调整的节点的左右子树一定是堆。
步骤即:


代码实现
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void Adjust_down(int* arr, int i,int len)
{
int parent = i;
int child = i * 2 + 1;
while (child < len)
{
if (child + 1 < len && arr[child] > arr[child + 1])//防止有右孩子不存在的情况
child++;//找较小的子节点
if (arr[parent] > arr[child])//如果父节点本来就小,不用换
{
Swap(&arr[parent], &arr[child]);
parent = child;
child = parent * 2 + 1;
}
else
return;
}
}
int main()
{
int arr[]= { 6,1,7,0,3,5,8,2,9,4 };
int len = sizeof(arr) / sizeof(int);
//先向下调整建堆
for (int i = (len - 1 - 1) / 2; i >= 0; i--)//i指向元素下标而len-1是最后一个元素下标
{
Adjust_down(arr, i,len);//len是最后一个元素的下一个下标
}
//向下调整找最值
while (len > 0)
{
Swap(&arr[0], &arr[len - 1]);//交换一次就保留一个最小值放到最后面
Adjust_down(arr, 0, len - 1);//此时最后一个元素就不计算在内
printf("%d ", arr[len - 1]);//从后向前打印数据
len--;
}
return 0;
}复杂度分析
向上调整建堆:当层数节点多时,需要调整次数也多。所以数据越多,所执行调整的次数也就越多,时间复杂度也就越高。
向下调整建堆:相对于向上调整而言,向下调整建堆就明显避开了层数节点多时,需要调整次数也多等问题,恰恰相反,层数节点越多,需要调整的次数越少,时间复杂度是O(n-logn) 即:O(n) 。计算就留给你们了,和上面的方法一样。
而上面的方法实现堆排序的时间复杂度是O(n+n*logn),即:O(n log n)

堆中的TOP-K问题
我们了解到堆排序相比冒泡排序而言,效率要高得多,而且向下调整建堆又比向上调整建堆效率高,所以我们就引申到堆中的 TOP-K 的问题,即:找所有数中最大(最小)的前 K 个数。
那么直接将这给的所有数据建成堆并向下调整排序不就成了,可是1.如果给的数据过大,空间不够用呢 2.只想要前 K 个最值,但是再像之前一样建存放所有数据的堆,是不是就存在严重的空间浪费了呢。
假如说我们要找所有数据的前5个最大的值:所以我们就想到了建一个只能存放5个数的小堆,然后依次将后面的数与堆顶的值进行比较,如果大于堆顶的数就交换,进行向下调整,重新建堆,然后依次将后面的数进行上面操作就可以完成。
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void Adjust_down(int* arr, int i, int len)//i是下标,len是堆大小
{
int parent = i;
int child = parent * 2 + 1;
while (child<len)
{
if (child + 1 < len && arr[child] > arr[child + 1])
child += 1;
if (arr[parent] > arr[child])
{
Swap(&arr[parent], &arr[child]);
parent = child;
child = parent * 2 + 1;
}
else
return;
}
}
int main()
{
srand((unsigned int)time(NULL));
FILE* pf = fopen("data.txt", "w");
if (pf == NULL)
{
perror("pf=NULL");
return 1;
}
for (int i = 0; i < 1000; i++)
{
int x = rand() % 1000;//产生一万个随机数放在文件里
fprintf(pf, "%d\n", x);
}
fclose(pf);//处理完数据之后一定要及时关闭,否则数据可能丢失
//直接开辟相应大小的空间
int k = 7;
int* arr = (int*)malloc(sizeof(int) * k);
assert(arr);
//读取文件中前面7个数据放到数组中
FILE* po = fopen("data.txt", "r");
assert(po);
for(int i=0;i<k;i++)
{
fscanf(po, "%d", &arr[i]);//将前7个数存到数组里
}
for (int i = (k - 2) / 2; i >= 0; i--)//七个数向下调整建小堆
{
Adjust_down(arr, i, k);
}
//读取文件后面的数据
int val = 0;
while (feof(po)==0)
{
fscanf(po, "%d", &val);
if (val > arr[0])
{
arr[0] = val;
Adjust_down(arr, 0, k);//每执行一次,堆顶都是最小值
}
}
for (int i = 0; i < k; i++)
printf("%d ", arr[i]);
return 0;
}
而当数据过多时,我们就会将数据存在文件当中,在文件中逐一地读取数据。使用小堆其实就保证了最小值在堆顶的位置,所以我们每次新来一个值就和堆顶(最小值比较),大的话就可以直接换掉最小值,再次调整,现在堆中的最小值又在堆顶....这样就方便了很多。
