一、本学期所学知识点总结
在本学期的多元统计分析课程中,我学习了聚类分析和主成分分析(或因子分析)这两个重要的数据分析方法。通过这些学习,我对以下几个方面有了更深入的了解。
-
聚类分析:聚类分析是一种无监督学习方法,用于将数据集中的个体划分为不同的组或簇,使得同一组内的个体之间具有相似性,而不同组之间的个体具有差异性。我了解了聚类算法的基本原理,包括距离度量、聚类算法(如K-means、层次聚类等)以及评估聚类结果的指标(如轮廓系数、Davies-Bouldin指数等)。我通过实际操作和案例分析,进一步理解了聚类分析的应用场景,如市场细分、社交网络分析等。
-
主成分分析(或因子分析):主成分分析是一种降维技术,用于从高维数据中提取出最相关的特征,以便更好地理解和解释数据。我学习了主成分分析的基本原理和步骤,包括特征值分解、主成分的选择和解释、主成分得分等。同时,我也了解了因子分析作为主成分分析的一种扩展方法,用于探索潜在的隐含因子结构。我通过实际案例和数据集的分析,进一步认识了主成分分析和因子分析在数据降维和变量解释方面的应用。
在学习过程中,我发现聚类分析和主成分分析(或因子分析)之间有一些容易混淆的概念,如数据的相似性与差异性、特征值与特征向量、主成分与因子等。为了理解这些概念之间的区别与联系,我阅读了相关的教材和论文,参考了实例和案例分析,并与同学们进行了讨论和交流。通过这些努力,我逐渐清晰了这些概念的含义和应用。
二、问题研究
研究背景
在电信行业,客户流失(或称为客户流失)是一个重要的挑战。客户流失指的是已经离开或停止使用公司服务的客户。客户流失对于电信公司来说是一个重要的问题,因为失去现有客户比吸引新客户更加昂贵。因此,了解客户流失的原因和预测客户流失的模式对于电信公司来说具有重要意义。
研究目的
本研究的目的是通过应用聚类分析、主成分分析或因子分析等技术,对Telco电信客户流失数据集进行分析,以揭示客户群体之间的相似性、主要影响因素以及可能存在的模式。具体目标包括:
- 识别不同的客户群体:通过聚类分析,将客户划分为不同的群体,以发现潜在的客户细分。这有助于电信公司了解不同群体的行为和需求差异。
-确定主要影响因素:通过主成分分析或因子分析,确定对客户流失最具影响力的变量。这有助于识别关键因素并制定相应的策略,以降低客户流失率。
- 提供决策支持:通过分析客户流失数据集,为电信公司提供有关客户流失的洞察和决策支持。这可以帮助他们制定针对不同客户群体的定制化营销策略和客户保留计划。
研究意义
这项研究对电信行业具有重要意义,因为它可以帮助公司更好地理解客户行为、需求和偏好。通过聚类分析,公司可以根据不同客户群体的特点,提供个性化的产品和服务,从而增加客户满意度和忠诚度。主成分分析或因子分析可以帮助公司确定哪些因素最重要,从而更有针对性地进行客户保留措施。此外,通过准确预测客户流失,公司可以及时采取行动,采取措施留住现有客户,降低业务风险。
三、数据集
Telco客户流失数据集是一个用于研究客户流失问题的电信行业数据集。该数据集包含了有关Telco电信公司的客户信息,旨在帮助研究人员和分析师了解客户流失的模式和影响因素。
数据集包含了7043个观测值(行)和21个变量(列),提供了关于每个客户的多个方面的信息,包括个人信息、服务订阅情况、账户信息和付费情况。
下面是Telco客户流失数据集的变量和描述的表格:
| 变量名 | 描述 |
|---|---|
| customerID | 客户的唯一标识符 |
| gender | 客户的性别 |
| SeniorCitizen | 是否为老年客户的标志,1表示是,0表示不是 |
| Partner | 客户是否有合作伙伴 |
| Dependents | 客户是否有家属 |
| tenure | 客户与公司的合约期限(以月计) |
| PhoneService | 客户是否订购电话服务 |
| MultipleLines | 客户是否订购多线服务 |
| InternetService | 客户订购的互联网服务类型 |
| OnlineSecurity | 客户是否订购在线安全服务 |
| OnlineBackup | 客户是否订购在线备份服务 |
| DeviceProtection | 客户是否订购设备保护服务 |
| TechSupport | 客户是否订购技术支持服务 |
| StreamingTV | 客户是否订购流媒体电视服务 |
| StreamingMovies | 客户是否订购流媒体电影服务 |
| Contract | 客户的合约类型 |
| PaperlessBilling | 客户是否选择无纸化账单 |
| PaymentMethod | 客户的付款方式 |
| MonthlyCharges | 客户每月的费用 |
| TotalCharges | 客户的总费用累计值 |
| Churn | 客户是否已经流失,"Yes"表示已流失,"No"表示未流失 |
该数据集为研究客户流失问题提供了广泛的信息,可用于进行各种分析和建模任务,例如聚类分析、主成分分析、因子分析和客户流失预测模型的构建。通过对该数据集的分析,可以帮助电信公司识别潜在的客户细分、了解客户需求和行为,并制定相应的策略来降低客户流失率、提高客户满意度和业务的可持续发展能力。
四、主成分分析
主成分分析的思想是通过线性变换将原始的高维数据映射到一个新的低维空间,使得在新的空间中数据的方差最大化。具体而言,主成分分析通过计算数据集的协方差矩阵或相关矩阵,找到一组新的变量(称为主成分),它们是原始变量的线性组合,并且彼此之间是无关的。这些主成分按照方差的大小排序,因此,前几个主成分能够解释数据中大部分的方差,而后面的主成分所包含的方差逐渐减小。
主成分分析的步骤如下:
- 标准化数据:如果原始数据的各个变量具有不同的尺度,需要对数据进行标准化,使得每个变量具有相同的尺度。
- 计算协方差矩阵:根据标准化后的数据,计算变量之间的协方差矩阵或相关矩阵。
- 计算特征值和特征向量:对协方差矩阵进行特征值分解或奇异值分解,得到特征值和对应的特征向量。
- 选择主成分:根据特征值的大小,选择前k个最大的特征值对应的特征向量作为主成分。
- 数据转换:将原始数据投影到选取的主成分上,得到新的低维数据表示。
library(tidyverse)
theme_set(theme(plot.title = element_text(hjust = 0.5)))
data <- read.csv("WA_Fn-UseC_-Telco-Customer-Churn.csv",stringsAsFactors = TRUE)
data <- data %>% select(-customerID) %>% drop_na()
# 将因子变量转换为数字变量
df <- data %>% mutate_if(is.factor, as.numeric)
# 计算相关系数矩阵
cor_matrix <- cor(df)
# 绘制相关系数图
library(corrplot)
corrplot(cor_matrix, method = "circle", tl.cex = 0.7)

根据相关系数矩阵中每个变量与"Churn"(客户流失)之间的相关系数,可以得出以下结论:
-
性别(gender)与客户流失之间的相关系数接近于零,表明性别对客户流失的影响较小,即性别与客户流失之间没有明显的线性关系。
-
老年人标识(SeniorCitizen)与客户流失之间的相关系数为正值,说明年龄较大的客户更有可能发生流失。
-
合作伙伴(Partner)和家属(Dependents)与客户流失之间的相关系数均为负值,表示没有合作伙伴和家属的客户更有可能发生流失。
-
在各种服务中,与客户流失相关性较高的是OnlineSecurity、OnlineBackup、DeviceProtection和TechSupport。相关系数的负值表明没有这些服务的客户更容易发生流失。
-
合同类型(Contract)与客户流失之间的相关系数为负值,表示选择月付合同(Month-to-month)的客户更容易发生流失,相比之下,选择长期合同(One year、Two year)的客户更稳定。
-
是否选择电子账单(PaperlessBilling)与客户流失之间的相关系数为正值,表明选择电子账单的客户更容易发生流失。
-
付款方式(PaymentMethod)、月费用(MonthlyCharges)和总费用(TotalCharges)与客户流失之间的相关系数在0.1左右,表明它们对客户流失的影响较小。
library(psych)
# 执行主成分分析
pca_result <- principal(df)
# 提取主成分分析结果的特征值
eigenvalues <- pca_result$values
# 计算方差解释比例
variance_explained <- eigenvalues / sum(eigenvalues)
# 绘制碎石图
plot(1:length(variance_explained), variance_explained, type = "b", pch = 19, xlab = "主成分个数", ylab = "方差解释比例", main = "主成分分析的碎石图")
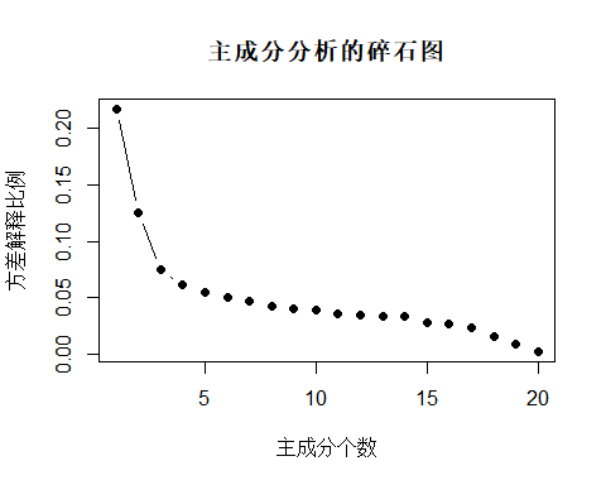
根据碎石图的拐点,结合主成分解释总体方差的比例(约为80%),选择主成分个数为3。
# 执行主成分分析并设置3个主成分
pca_result <- principal(df, nfactors = 3)
pca_result$loadings
在执行主成分分析后,我们可以提取主成分的结果,并对其进行解读。以下是提取的主成分结果及其解释:
- 主成分1(RC1)的负荷(loadings)为3.958,解释的方差比例为0.198,累积方差比例为0.198。
- 主成分2(RC2)的负荷(loadings)为2.828,解释的方差比例为0.141,累积方差比例为0.339。
- 主成分3(RC3)的负荷(loadings)为1.569,解释的方差比例为0.078,累积方差比例为0.418。
这些数据告诉我们每个主成分解释了多少方差,以及累积方差比例是多少。在这个例子中,主成分1(RC1)解释了约19.8%的方差,主成分2(RC2)解释了约14.1%的方差,主成分3(RC3)解释了约7.8%的方差。累积方差比例表示前n个主成分解释的方差比例之和,对于3个主成分,累积方差比例为41.8%。
# 获取主成分权重
weights <- pca_result$weights
# 计算每个样本的主成分得分
scores <- as.matrix(df) %*% weights
# 计算每个样本的总主成分得分
total_scores <- rowSums(scores)
# 将总的主成分得分添加到数据框中
data$score <- total_scores
五、聚类分析
首先选择需要进行聚类分析的变量,并对数据进行预处理。然后,我们使用K均值聚类算法对经过标准化处理的数据进行聚类,并选择聚类数量为3。
df1 <- data %>% filter(Churn == "Yes") %>% select(-Churn,-score)
df2 <- df1 %>% mutate_if(is.factor, as.numeric)
scaled_data <- scale(df2)
# 执行聚类分析
k <- 3 # 设置聚类数目
set.seed(123)
kmeans_result <- kmeans(scaled_data, centers = k)
# 提取聚类结果
cluster_labels <- kmeans_result$cluster
# 将聚类结果添加到原始数据集
clustered_data <- bind_cols(df1, cluster = cluster_labels)
cluster1_data <- clustered_data %>% filter(cluster == 1)
summary(cluster1_data)

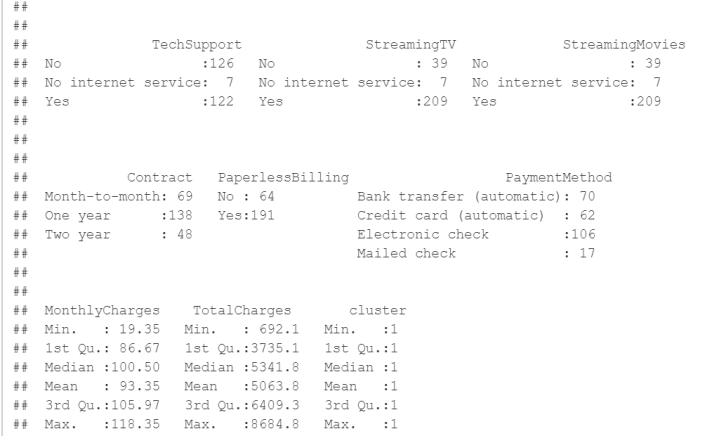
聚类类别1的分析结果如下:
- gender:聚类类别1中有113个女性和142个男性客户。
- SeniorCitizen:在聚类类别1中,约21.6%的客户为老年人。
- Partner:聚类类别1中有82个客户没有配偶,173个客户有配偶。
- Dependents:聚类类别1中有178个客户没有家属,77个客户有家属。
- tenure:聚类类别1中客户的平均续约时长约为53.6个月,最小值为14个月,最大值为72个月。
以下是聚类类别1中其他变量的统计信息:
- PhoneService:12个客户没有电话服务,243个客户有电话服务。
- MultipleLines:58个客户没有多线服务,185个客户有多线服务。
- InternetService:53个客户使用DSL,195个客户使用光纤,7个客户没有互联网服务。
- 其他变量(OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport、StreamingTV、StreamingMovies、Contract、PaperlessBilling、PaymentMethod、MonthlyCharges、TotalCharges)的分布和描述。
cluster2_data <- clustered_data %>% filter(cluster == 2)
summary(cluster2_data)
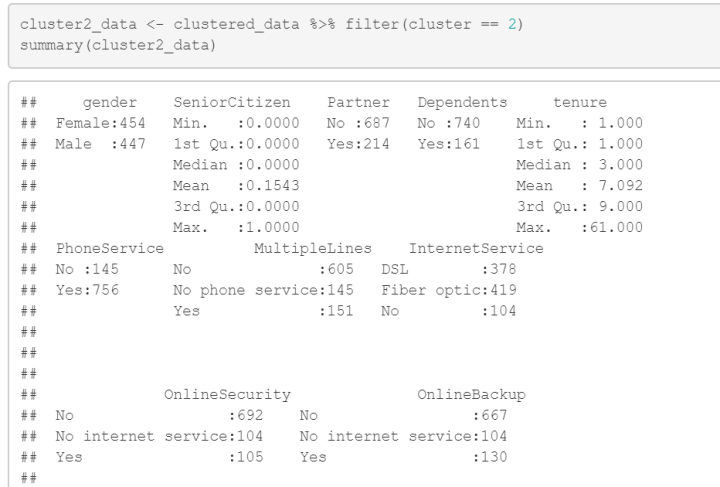

根据你提供的信息,聚类类别2的分析结果如下:
- gender:聚类类别2中有454个女性和447个男性客户。
- SeniorCitizen:在聚类类别2中,约15.4%的客户为老年人。
- Partner:聚类类别2中有687个客户没有配偶,214个客户有配偶。
- Dependents:聚类类别2中有740个客户没有家属,161个客户有家属。
- tenure:聚类类别2中客户的平均续约时长约为7.092个月,最小值为1个月,最大值为61个月。
以下是聚类类别2中其他变量的统计信息:
- PhoneService:145个客户没有电话服务,756个客户有电话服务。
- MultipleLines:605个客户没有多线服务,151个客户有多线服务。
- InternetService:378个客户使用DSL,419个客户使用光纤,104个客户没有互联网服务。
- 其他变量(OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport、StreamingTV、StreamingMovies、Contract、PaperlessBilling、PaymentMethod、MonthlyCharges、TotalCharges)的分布和描述。
cluster3_data <- clustered_data %>% filter(cluster == 3)
summary(cluster3_data)
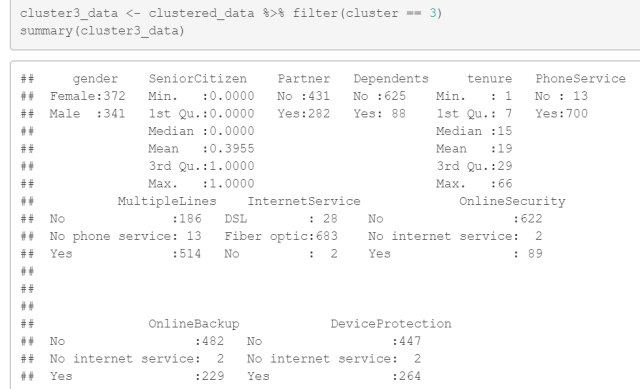
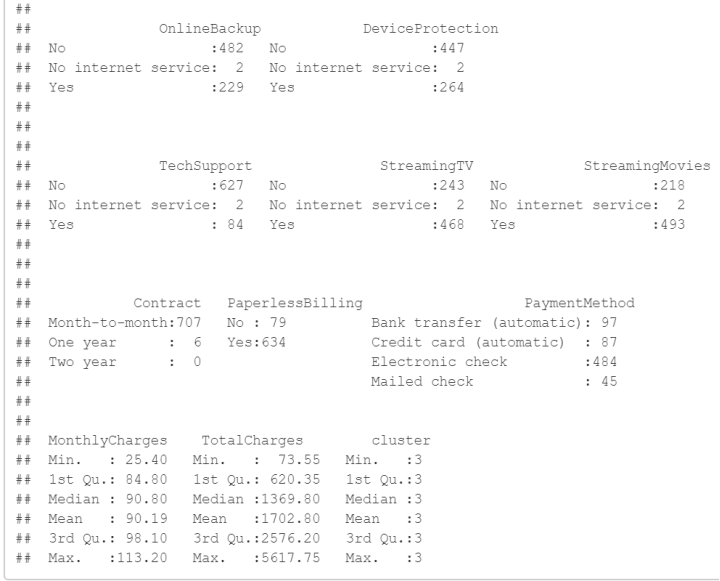
聚类类别3的分析结果如下:
- gender:聚类类别3中有372个女性和341个男性客户。
- SeniorCitizen:在聚类类别3中,约39.55%的客户为老年人。
- Partner:聚类类别3中有431个客户没有配偶,282个客户有配偶。
- Dependents:聚类类别3中有625个客户没有家属,88个客户有家属。
- tenure:聚类类别3中客户的平均续约时长约为19个月,最小值为1个月,最大值为66个月。
以下是聚类类别3中其他变量的统计信息:
- PhoneService:13个客户没有电话服务,700个客户有电话服务。
- MultipleLines:186个客户没有多线服务,514个客户有多线服务。
- InternetService:28个客户使用DSL,683个客户使用光纤,2个客户没有互联网服务。
- 其他变量(OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport、StreamingTV、StreamingMovies、Contract、PaperlessBilling、PaymentMethod、MonthlyCharges、TotalCharges)的分布和描述。