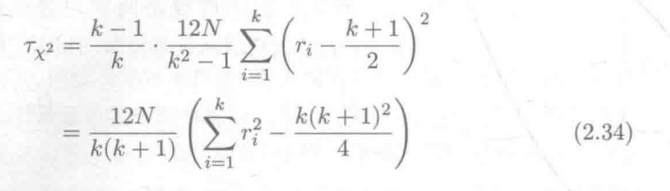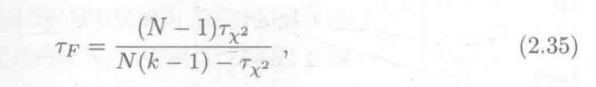第1章 绪论
1.1 表1.1若只包含编号1和4的两个样例,试给出相应的版本空间。

版本空间:与训练及一致的假设集合。
色泽=青绿,根蒂=*,敲声=*;
色泽=*,根蒂=蜷缩,敲声=*;
色泽=*,根蒂=*,敲声=浊响;
色泽=青绿,根蒂=蜷缩,敲声=*;
色泽=青绿,根蒂=*,敲声=浊响;
色泽=*,根蒂=蜷缩,敲声=浊响;
色泽=青绿,根蒂=蜷缩,敲声=浊响;
1.2 求假设空间的大小

析合范式:先合取再析取的范式;
根据1.1的排列组合,考虑所有编号的样例,一共有49种假设集合(包含空集);
全部不泛化:2*3*3=18;
一个属性泛化:2*3+3*3+2*3=21;
两个属性泛化:2+3+3=8;
三个属性泛化:1;
空集:1
如果不考虑空集的话就是有48种假设,所以k的最大值为48;
但是如果用这48种假设必定会造成冗余,所以本题应该采用18种具体的假设来计算:2^18-1(从1-18分别取排列组合)
1.3 归纳偏好的设计

归纳偏好:机器学习算法对某种类型假设的偏好;
数据包含噪声,去噪:若存在两个样例属性取值都相同,但是标记却不同,只保留标记为正例的样例,在此基础上求得版本空间;(或者保留反例)
1.4 “没有免费的午餐定理”拓展证明

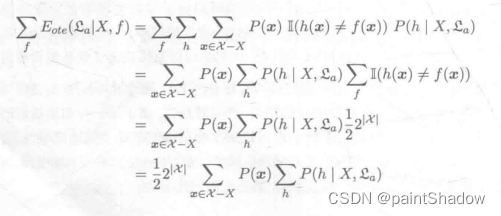
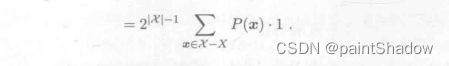

1.5 机器学习能在互联网搜索的哪些环节起作用
提交信息阶段:信息提取,语义分析;
信息匹配阶段:提高问题与各个信息的匹配程度;
展示结果阶段:根据用户感兴趣的程度进行排序;
第二章模型评估与选择
2.1 数据集的划分

分别从正反例样本中取30%的数据作为测试集,划分方式有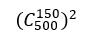
2.2 使用错误率评估结果

10折交叉验证法:把样本划分成十个大小相同的互斥子集,每次用9个子集的并集来进行训练,剩下的一个作为测试集。由于正反例各一半,所以错误率为50%和50%;
留一法:每次只使用一个数据作为测试集,剩下的全部是训练集。由于本题中正反例各一半,所以无论留下哪一种数据,都跟模型训练出来的结果相反,所以这种方法的错误率是100%。
2.3
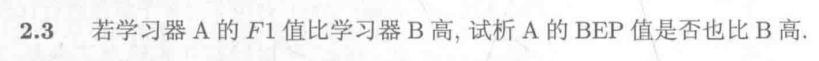
2.4

2.5 证明公式2.22
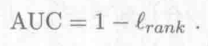
2.6 描述错误率与ROC曲线的联系
2.7

2.8

2.9
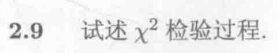
2.10