1 安装hadoop程序
1.1 linux上安装环境,就是软件包,跟mysql本质上1样
1.2 windows上安装环境(这样才能在windows中跑hadoop程序,测试java写的hadoop程序是否可用)
参考下面的资料自己在电脑上成功安装:
Hadoop-3.0.0版本Windows安装
2 项目构建(和普通项目基本一样)
和普通项目构建只有3处不同:
(1)需要导入hadoop的JAR包,包含几十个jar包
(2)重写map方法和reduce方法
(3)运行在安装有hadoop的环境上

2.1 创建1个普通的项目
2.2 导入Hadoop的JAR包
2.2.1 手动导入
直接添加外部依赖库
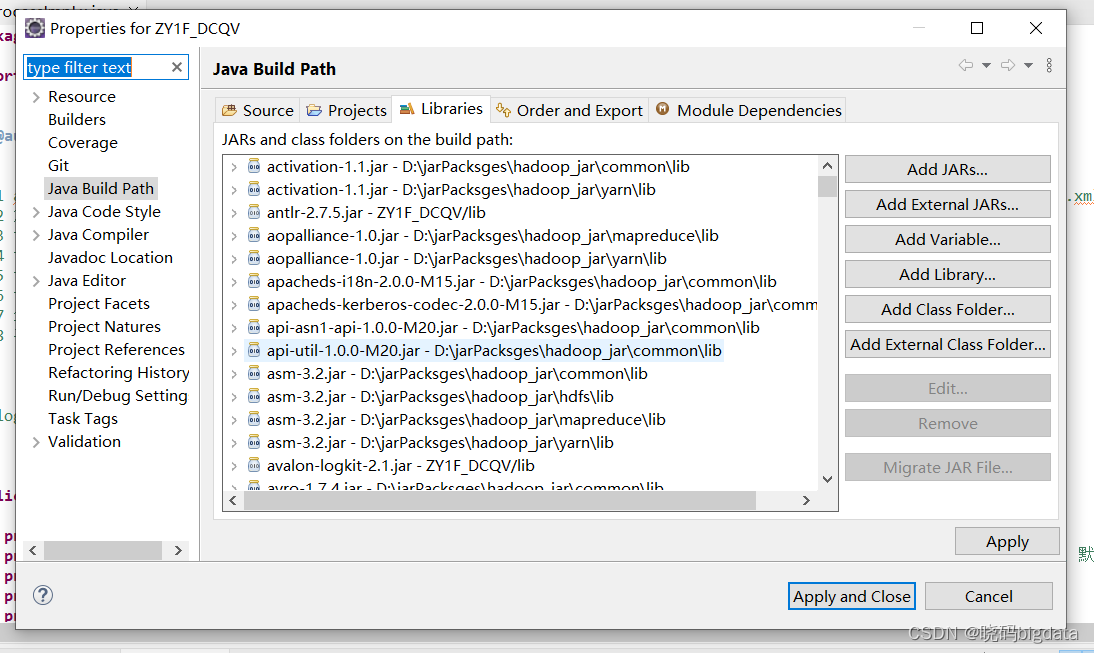
2.2.2 maven导入
1 看尚硅谷的课程
2 使用Maven搭建Hadoop开发环境
2.3 一共就写3个类,分别编写Driver,Mapper,Reducer
2.3.1 主函数逻辑类Driver
2.3.2 重写map方法
2.3.3 重写Reduce方法
2.4 在安有hadoop的Windows上测试或者在linux上测试代码
2.5 打包成JAR包
2.6 在linux环境上部署运行(必须使用hadoop命令)
两步:
1 su yarn切换到yarn用户
2 hadoop jar EXEMPLE_RUNNABLE.jar …
如果打包成普通jar包,那么需要在运行时指定main方法入口:
% hadoop jar EXEMPLE.jar MainClassName
好处是可以随意指定jar包中需要运行的main方法
如果打包成runnable jar包,在打包时就指定了main方法入口:
% hadoop jar EXEMPLE_RUNNABLE.jar …
3 其它需要知道的重要的内容
3.1 分区
3.2 shuffle
4 几个小案例
1 这个案例非常好:hadoop 启动wordcount实例,包括hadoop自带jar包和eclipsejar包。
5 hadoop和java运行jar包命令
5.1 hadoop
5.1.1 指定主函数
// 主函数包括两个参数
hadoop jar study_demo.jar com.ncst.hadoop.MaxTemperature /input/sample.txt /output
5.1.2 默认主函数
// 主函数包括两个参数
hadoop jar study_demo.jar /input/sample.txt /output
5.2 java命令
java -jar
或者 java -cp