1. BERT预训练模型训练步骤:
- 使用Masked LM方式将语料库中的某一部分的词语掩盖住,模型通过上下文预测被掩盖的信息,从而训练出初步的语言模型
- 在语料库中选出连续的上下语句,并使用Tranformer模块识别语句的连续性
- 通过1和2实现通过上下文进行双向预测的预训练语言表征模型
- 通过少量经过标记的数据以监督学习的方式对模型进行Fine-Tuning
2. Contextualized word embedding
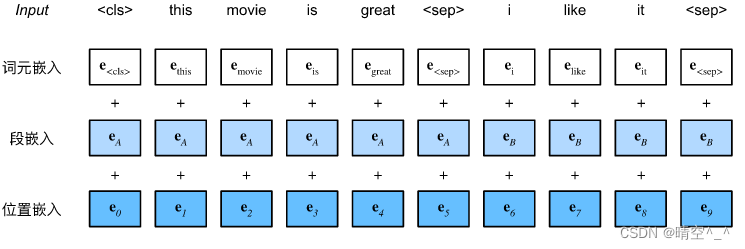
BERT选择Transformer编码器作为其双向架构。在Transformer编码器中常见是,位置嵌入被加入到输入序列的每个位置。然而,与原始的Transformer编码器不同,BERT使用可学习的位置嵌入。BERT的输入序列的嵌入是词元嵌入、片段嵌入和位置嵌入的总和。
3. Masking Input(完形填空)——> self-supervised
为了训练深度双向表征,BERT采用了一个直接的方法:随机的掩盖一定比例的Token,然后只预测这些被掩盖的Token。这个过程就是Masked LM,也被称为完形填空。在这个任务中,被掩盖的Token的最终隐藏向量被输入到词汇表的输出Softmax层,就像一个标准的语言模型一样。在BERT云训练过程中,并不总是用实际的[MASK] token替换被掩盖的单词。相反,其训练一个数据生成器来随机选择15%的token。例,在下面句子中:
台湾大学
选择湾,然后执行以下过程:
- 80%时间中,用[Mask] Token掩盖之前的词。例如:The
[Mask]is cute. - 10%的时间,用随机单词掩盖这个单词。例如:The playing is cute.
- 10%的时间,保持单词不变。
这个转换编码器不知道哪个单词将要被预测,或者哪个单词被随机单词取代。故,其必须保持每个输入Token的分布的上下文特征。另外,因为随机取代对于所有的Token来说发生的概率很低,并不会损害模型的理解能力。
如图:
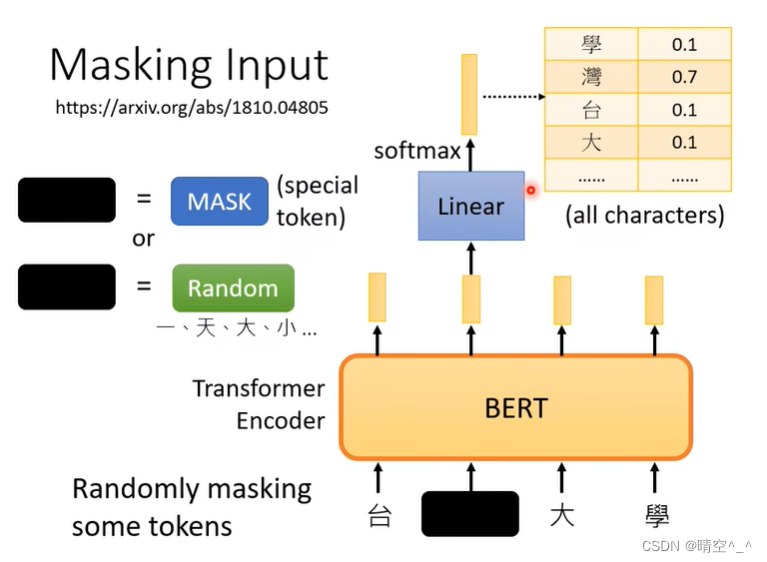
如图,对于BERT来说,输入于输出尺寸相同。在台湾大学李宏毅教授课程中,以输入序列“台湾大学”为例,模型随机将“湾”字进行遮蔽,之后对“湾”字位置的输出矩阵进行MLP处理,再通过softmax进行分类得到当前遮蔽字的分类。
4. Next Sentence Prediction
BERT输入为一个序列对,文本对被两个特殊的词元填充,[CLS]判断文本对的中的两个文本序列是否是相邻的(即第二个文本序列是不是第一个文本序列的next sentence)。[SEP]对文本对进行切割,是两个文本序列的分隔符。
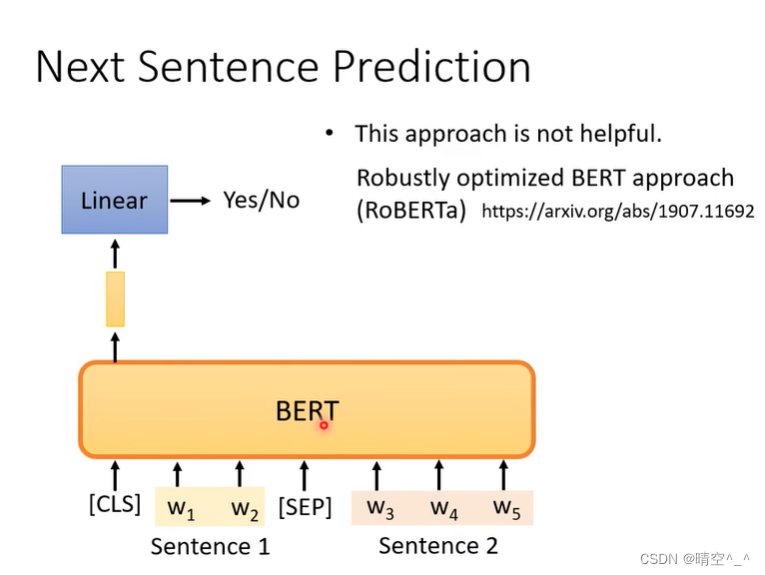
如图,对[CLS]所在位置的输出矩阵进行二分类来判断当前序列中第二个序列是否为第一个序列的next sentence。
5. Downstream Tasks ——> Fine-tune
BERT网络只是一个编码器,其本身不可以完成一个特定的任务。但是因为BERT出色的架构设计,在预训练好的BERT网络后加入根据特定任务设计的解码器,并利用数据集对这个网络进行fine-tune,就可以使整个网络具有优秀的表现。

如图,这就类似于CV中的Backbone特征提取网络,只需要在BERT后加入针对下游任务设计的解码器就可完成完整的网络设计。
不需要从零开始训练Backbone特征提取网络。再设计好下游任务解码器后,利用下游任务特定的数据集对整个预训练网络进行fine-tune就可以出色的解决问题。
具体的下游任务包括,单文本分类、文本对分类或回归、文本标注和问答等。具体的方法和代码已经有很多成熟的方案,本人能力有限就不多做赘述。