目录
目录
11.Like Glob Limit Order Group Having Distinct
1.sqlite安装
到SQLite Download Page下载sqlite-tools-win32-x86-3390400.zip解压打开即可,使用.help 命令可以查看sqlite支持的点命令,在SQLite 命令 | 菜鸟教程中有对点命令的详细说明。
常用的点命令:
.show
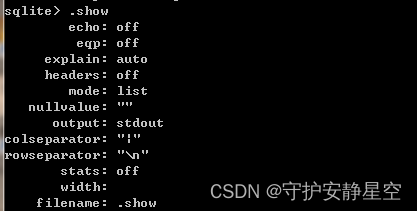
1.打开表头显示
.header on
2.列模式打开
.mode column
3.显示运行时间戳
.timer on
4.创建数据库
.open test.db
5.查看创建的表的命令(demo是表名字)
.schema demo
以上是sqlite这个软件带的点命令简单说明,这与sql命令不是同一类命令。sql命令以分号 ; 结尾。
2.sqlite基本数据类型
NULL: 表示该值为NULL值。
INTEGER: 无符号整型值。
REAL: 浮点值。
TEXT: 文本字符串,存储使用的编码方式为UTF-8、UTF-16BE、UTF-16LE。
BLOB: 存储Blob数据,该类型数据和输入数据完全相同。
在声明产生表格时可以使用类型亲缘性(Type Affinity):
为了最大化SQLite和其它数据库引擎之间的数据类型兼容性,SQLite提出了"类型亲缘性(Type Affinity)"的概念。我们可以这样理解"类型亲缘性 ",在表字段被声明之后,SQLite都会根据该字段声明时的类型为其选择一种亲缘类型,当数据插入时,该字段的数据将会优先采用亲缘类型作为该值的存储方式,除非亲缘类型不匹配或无法转换当前数据到该亲缘类型,这样SQLite才会考虑其它更适合该值的类型存储该值。SQLite目前的版本支持以下五种亲缘类型:
| 亲缘类型 | 描述 |
| TEXT | 数值型数据在被插入之前,需要先被转换为文本格式,之后再插入到目标字段中。 |
| NUMERIC | 当文本数据被插入到亲缘性为NUMERIC的字段中时,如果转换操作不会导致数据信息丢失以及完全可逆,那么SQLite就会将该文本数据转换为INTEGER或REAL类型的数据,如果转换失败,SQLite仍会以TEXT方式存储该数据。对于NULL或BLOB类型的新数据,SQLite将不做任何转换,直接以NULL或BLOB的方式存储该数据。需要额外说明的是,对于浮点格式的常量文本,如"30000.0",如果该值可以转换为INTEGER同时又不会丢失数值信息,那么SQLite就会将其转换为INTEGER的存储方式。 |
| INTEGER | 对于亲缘类型为INTEGER的字段,其规则等同于NUMERIC,唯一差别是在执行CAST表达式时。 |
| REAL | 其规则基本等同于NUMERIC,唯一的差别是不会将"30000.0"这样的文本数据转换为INTEGER存储方式。 |
| NONE | 不做任何的转换,直接以该数据所属的数据类型进行存储。 |
1. 决定字段亲缘性的规则:
字段的亲缘性是根据该字段在声明时被定义的类型来决定的,具体的规则可以参照以下列表。需要注意的是以下列表的顺序,即如果某一字段类型同时符合两种亲缘性,那么排在前面的规则将先产生作用。
1). 如果类型字符串中包含"INT",那么该字段的亲缘类型是INTEGER。
2). 如果类型字符串中包含"CHAR"、"CLOB"或"TEXT",那么该字段的亲缘类型是TEXT,如VARCHAR。
3). 如果类型字符串中包含"BLOB",那么该字段的亲缘类型是NONE。
4). 如果类型字符串中包含"REAL"、"FLOA"或"DOUB",那么该字段的亲缘类型是REAL。
5). 其余情况下,字段的亲缘类型为NUMERIC。
2. 具体示例:
| 声明类型 | 亲缘类型 | 应用规则 |
| INT INTEGER TINYINT SMALLINT MEDIUMINT BIGINT UNSIGNED BIG INT INT2 INT8 |
INTEGER | 1 |
| CHARACTER(20) VARCHAR(255) VARYING CHARACTER(255) NCHAR(55) NATIVE CHARACTER(70) NVARCHAR(100) TEXT CLOB |
TEXT | 2 |
| BLOB | NONE | 3 |
| REAL DOUBLE DOUBLE PRECISION FLOAT |
REAL | 4 |
| NUMERIC DECIMAL(10,5) BOOLEAN DATE DATETIME |
NUMERIC | 5 |
注:在SQLite中,类型VARCHAR(255)的长度信息255没有任何实际意义,仅仅是为了保证与其它数据库的声明一致性。
3.sqlite基本操作
1.表的创建
CREATE TABLE DEMO(ID INT,D1_D7 TEXT,TIME TEXT,TYPE TEXT);2.表的删除
DROP TABLE DEMO;3.插入数据
INSERT INTO DEMO VALUES(12345,'A1A2A3A4A5A6A7A8','2022-01-01 10-09-21.567','EXT');
--用一个表填充另外一个表
INSERT INTO first_table_name [(column1, column2, ... columnN)]
SELECT column1, column2, ...columnN
FROM second_table_name
[WHERE condition];4.查询表格数据
SELECT * FROM DEMO;5.修改表格数据
UPDATE DEMO SET ID = 75;6.删除表格数据
DELETE FROM DEMO;7.条件判断
增删改查表的语句都可以增加条件判断 WHERE,sqlite的条件语句要与表达式或者运算符相配合.
8.sqlite运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加法 - 把运算符两边的值相加 | a + b 将得到 30 |
| - | 减法 - 左操作数减去右操作数 | a - b 将得到 -10 |
| * | 乘法 - 把运算符两边的值相乘 | a * b 将得到 200 |
| / | 除法 - 左操作数除以右操作数 | b / a 将得到 2 |
| % | 取模 - 左操作数除以右操作数后得到的余数 | b % a will give 0 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果相等则条件为真。 | (a == b) 不为真。 |
| = | 检查两个操作数的值是否相等,如果相等则条件为真。 | (a = b) 不为真。 |
| != | 检查两个操作数的值是否相等,如果不相等则条件为真。 | (a != b) 为真。 |
| <> | 检查两个操作数的值是否相等,如果不相等则条件为真。 | (a <> b) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 | (a > b) 不为真。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 | (a < b) 为真。 |
| >= | 检查左操作数的值是否大于等于右操作数的值,如果是则条件为真。 | (a >= b) 不为真。 |
| <= | 检查左操作数的值是否小于等于右操作数的值,如果是则条件为真。 | (a <= b) 为真。 |
| !< | 检查左操作数的值是否不小于右操作数的值,如果是则条件为真。 | (a !< b) 为假。 |
| !> | 检查左操作数的值是否不大于右操作数的值,如果是则条件为真。 | (a !> b) 为真。 |
| 运算符 | 描述 |
|---|---|
| AND | AND 运算符允许在一个 SQL 语句的 WHERE 子句中的多个条件的存在。 |
| BETWEEN | BETWEEN 运算符用于在给定最小值和最大值范围内的一系列值中搜索值。 |
| EXISTS | EXISTS 运算符用于在满足一定条件的指定表中搜索行的存在。 |
| IN | IN 运算符用于把某个值与一系列指定列表的值进行比较。 |
| NOT IN | IN 运算符的对立面,用于把某个值与不在一系列指定列表的值进行比较。 |
| LIKE | LIKE 运算符用于把某个值与使用通配符运算符的相似值进行比较。 |
| GLOB | GLOB 运算符用于把某个值与使用通配符运算符的相似值进行比较。GLOB 与 LIKE 不同之处在于,它是大小写敏感的。 |
| NOT | NOT 运算符是所用的逻辑运算符的对立面。比如 NOT EXISTS、NOT BETWEEN、NOT IN,等等。它是否定运算符。 |
| OR | OR 运算符用于结合一个 SQL 语句的 WHERE 子句中的多个条件。 |
| IS NULL | NULL 运算符用于把某个值与 NULL 值进行比较。 |
| IS | IS 运算符与 = 相似。 |
| IS NOT | IS NOT 运算符与 != 相似。 |
| || | 连接两个不同的字符串,得到一个新的字符串。 |
| UNIQUE | UNIQUE 运算符搜索指定表中的每一行,确保唯一性(无重复)。 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 如果同时存在于两个操作数中,二进制 AND 运算符复制一位到结果中。 | (A & B) 将得到 12,即为 0000 1100 |
| | | 如果存在于任一操作数中,二进制 OR 运算符复制一位到结果中。 | (A | B) 将得到 61,即为 0011 1101 |
| ~ | 二进制补码运算符是一元运算符,具有"翻转"位效应,即0变成1,1变成0。 | (~A ) 将得到 -61,即为 1100 0011,一个有符号二进制数的补码形式。 |
| << | 二进制左移运算符。左操作数的值向左移动右操作数指定的位数。 | A << 2 将得到 240,即为 1111 0000 |
| >> | 二进制右移运算符。左操作数的值向右移动右操作数指定的位数。 | A >> 2 将得到 15,即为 0000 1111 |
9.sqlite表达式
SELECT column1, column2, columnN
FROM table_name
WHERE [CONDITION | EXPRESSION];
例子:
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0
1.布尔表达式:
SELECT * FROM COMPANY WHERE SALARY = 10000;ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 4 James 24 Houston 10000.0
2.数值表达式:
SELECT (15 + 6) AS ADDITIONADDITION = 21
3.日期表达式:
SELECT CURRENT_TIMESTAMP;
10.sqlite的删改查条件添加 WHERE
1. 查询条件语句
SELECT column1, column2, columnN
FROM table_name
WHERE [condition]
查询条件例子
SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0
2.修改条件语句:
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];3.删除条件语句:
DELETE FROM table_name
WHERE [condition];11.Like Glob Limit Order Group Having Distinct
1.LIKE
SQLite 的 LIKE 运算符是用来匹配通配符指定模式的文本值。如果搜索表达式与模式表达式匹配,LIKE 运算符将返回真(true),也就是 1。这里有两个通配符与 LIKE 运算符一起使用:
-
百分号 (%)
-
下划线 (_)
百分号(%)代表零个、一个或多个数字或字符。下划线(_)代表一个单一的数字或字符。这些符号可以被组合使用。
语法说明:
SELECT column_list
FROM table_name
WHERE column LIKE 'XXXX%'
SELECT column_list
FROM table_name
WHERE column LIKE '%XXXX%'
SELECT column_list
FROM table_name
WHERE column LIKE 'XXXX_'
SELECT column_list
FROM table_name
WHERE column LIKE '_XXXX'
SELECT column_list
FROM table_name
WHERE column LIKE '_XXXX_'这里可以使用 AND 或 OR 运算符来结合 N 个数量的条件。在这里,XXXX 可以是任何数字或字符串值。
例子:
| 语句 | 描述 |
|---|---|
| WHERE SALARY LIKE '200%' | 查找以 200 开头的任意值 |
| WHERE SALARY LIKE '%200%' | 查找任意位置包含 200 的任意值 |
| WHERE SALARY LIKE '_00%' | 查找第二位和第三位为 00 的任意值 |
| WHERE SALARY LIKE '2_%_%' | 查找以 2 开头,且长度至少为 3 个字符的任意值 |
| WHERE SALARY LIKE '%2' | 查找以 2 结尾的任意值 |
| WHERE SALARY LIKE '_2%3' | 查找第二位为 2,且以 3 结尾的任意值 |
| WHERE SALARY LIKE '2___3' | 查找长度为 5 位数,且以 2 开头以 3 结尾的任意值 |
2.Glob
SQLite 的 GLOB 运算符是用来匹配通配符指定模式的文本值。如果搜索表达式与模式表达式匹配,GLOB 运算符将返回真(true),也就是 1。与 LIKE 运算符不同的是,GLOB 是大小写敏感的,对于下面的通配符,它遵循 UNIX 的语法。
-
星号 (*)
-
问号 (?)
星号(*)代表零个、一个或多个数字或字符。问号(?)代表一个单一的数字或字符。这些符号可以被组合使用。
语法说明:
SELECT FROM table_name
WHERE column GLOB 'XXXX*'
SELECT FROM table_name
WHERE column GLOB '*XXXX*'
SELECT FROM table_name
WHERE column GLOB 'XXXX?'
SELECT FROM table_name
WHERE column GLOB '?XXXX'
SELECT FROM table_name
WHERE column GLOB '?XXXX?'
SELECT FROM table_name
WHERE column GLOB '????'例子:
| 语句 | 描述 |
|---|---|
| WHERE SALARY GLOB '200*' | 查找以 200 开头的任意值 |
| WHERE SALARY GLOB '*200*' | 查找任意位置包含 200 的任意值 |
| WHERE SALARY GLOB '?00*' | 查找第二位和第三位为 00 的任意值 |
| WHERE SALARY GLOB '2??' | 查找以 2 开头,且长度至少为 3 个字符的任意值 |
| WHERE SALARY GLOB '*2' | 查找以 2 结尾的任意值 |
| WHERE SALARY GLOB '?2*3' | 查找第二位为 2,且以 3 结尾的任意值 |
| WHERE SALARY GLOB '2???3' | 查找长度为 5 位数,且以 2 开头以 3 结尾的任意值 |
3. LIMIT 子句与 OFFSET 子句
带有 LIMIT 子句的 SELECT 语句的基本语法如下:
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows]下面是 LIMIT 子句与 OFFSET 子句一起使用时的语法:
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows] OFFSET [row num]例子:
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0
SELECT * FROM COMPANY LIMIT 6;ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0
SELECT * FROM COMPANY LIMIT 3 OFFSET 2;ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0
4. Order By
SQLite 的 ORDER BY 子句是用来基于一个或多个列按升序或降序顺序排列数据。
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
SELECT
select_list
FROM
table
ORDER BY
column_1 ASC,
column_2 DESC;- ASC 默认值,从小到大,升序排列
- DESC 从大到小,降序排列
例子:
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0
结果按 SALARY 升序排序:
SELECT * FROM COMPANY ORDER BY SALARY ASC;ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 7 James 24 Houston 10000.0 2 Allen 25 Texas 15000.0 1 Paul 32 California 20000.0 3 Teddy 23 Norway 20000.0 6 Kim 22 South-Hall 45000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0
结果按 NAME 和 SALARY 升序排序:
SELECT * FROM COMPANY ORDER BY NAME, SALARY ASC;ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 2 Allen 25 Texas 15000.0 5 David 27 Texas 85000.0 7 James 24 Houston 10000.0 6 Kim 22 South-Hall 45000.0 4 Mark 25 Rich-Mond 65000.0 1 Paul 32 California 20000.0 3 Teddy 23 Norway 20000.0
结果按 NAME 降序排序:
SELECT * FROM COMPANY ORDER BY NAME DESC;ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 3 Teddy 23 Norway 20000.0 1 Paul 32 California 20000.0 4 Mark 25 Rich-Mond 65000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0 5 David 27 Texas 85000.0 2 Allen 25 Texas 15000.0
5.Group By
SQLite 的 GROUP BY 子句用于与 SELECT 语句一起使用,来对相同的数据进行分组。在 SELECT 语句中,GROUP BY 子句放在 WHERE 子句之后,放在 ORDER BY 子句之前。
语法:
下面给出了 GROUP BY 子句的基本语法。GROUP BY 子句必须放在 WHERE 子句中的条件之后,必须放在 ORDER BY 子句之前。
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN例子:
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0
SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME;NAME SUM(SALARY) ---------- ----------- Allen 15000.0 David 85000.0 James 10000.0 Kim 45000.0 Mark 65000.0 Paul 20000.0 Teddy 20000.0
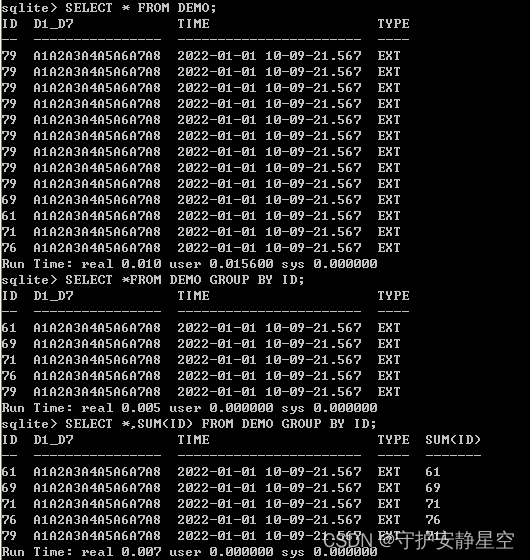
6.Having 子句
HAVING 子句允许指定条件来过滤将出现在最终结果中的分组结果。
WHERE 子句在所选列上设置条件,而 HAVING 子句则在由 GROUP BY 子句创建的分组上设置条件。
语法:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY在一个查询中,HAVING 子句必须放在 GROUP BY 子句之后,必须放在 ORDER BY 子句之前。下面是包含 HAVING 子句的 SELECT 语句的语法:
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2例子:
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0 8 Paul 24 Houston 20000.0 9 James 44 Norway 5000.0 10 James 45 Texas 5000.0
SELECT * FROM COMPANY GROUP BY name HAVING count(name) < 2;ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 2 Allen 25 Texas 15000 5 David 27 Texas 85000 6 Kim 22 South-Hall 45000 4 Mark 25 Rich-Mond 65000 3 Teddy 23 Norway 20000
7.Distinct
SQLite 的 DISTINCT 关键字与 SELECT 语句一起使用,来消除所有重复的记录,并只获取唯一一次记录。
有可能出现一种情况,在一个表中有多个重复的记录。当提取这样的记录时,DISTINCT 关键字就显得特别有意义,它只获取唯一一次记录,而不是获取重复记录。
语法:
SELECT DISTINCT column1, column2,.....columnN
FROM table_name
WHERE [condition]例子:
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0 8 Paul 24 Houston 20000.0 9 James 44 Norway 5000.0 10 James 45 Texas 5000.0
SELECT name FROM COMPANY;NAME ---------- Paul Allen Teddy Mark David Kim James Paul James James
SELECT DISTINCT name FROM COMPANY;NAME ---------- Paul Allen Teddy Mark David Kim James
4.sqlite参考资料
1.sqlite在线编辑器: SQL Online Compiler - Next gen SQL Editor
3.w3cschool
4.SQLite数据类型详解 - 虚-染D - 博客园
5.Qt帮助文档
5.QT操作sqlite
1.概述
本文假设您至少具有SQL的基本知识。您应该能够理解简单的SELECT、INSERT、UPDATE和DELETE语句。尽管QSqlTableModel类提供了一个不需要SQL知识的数据库浏览和编辑接口,但强烈建议对SQL有基本的了解。关于SQL数据库的标准文本是C. J. Date的《数据库系统简介》(第7版),ISBN 0201385902。
2.Qt数据库有关的类
这些类提供对SQL数据库的访问。
| QSqlDatabase | 处理到数据库的连接 |
| QSqlDriverCreator | 为特定驱动程序类型提供SQL驱动程序工厂的模板类 |
| QSqlDriverCreatorBase | SQL驱动程序工厂的基类 |
| QSqlDriver | 用于访问特定SQL数据库的抽象基类 |
| QSqlError | SQL数据库错误信息 |
| QSqlField | 操作SQL数据库表和视图中的字段 |
| QSqlIndex | 函数来操作和描述数据库索引 |
| QSqlQuery | 执行和操作SQL语句的方法 |
| QSqlRecord | 封装数据库记录 |
| QSqlResult | 抽象接口访问特定SQL数据库的数据 |
| QSql | 包含Qt SQL模块中使用的各种标识符 |
| QSqlQueryModel | SQL结果集的只读数据模型 |
| QSqlRelationalTableModel | 单个数据库表的可编辑数据模型,具有外键支持 |
| QSqlTableModel | 单个数据库表的可编辑数据模型 |
3.数据库类的分层
SQL类分为三层:
驱动层:
其中包括QSqlDriver、QSqlDriverCreator、qsqldrivercreatebase、QSqlDriverPlugin和QSqlResult类。这一层提供了特定数据库和SQL API层之间的底层桥梁。有关更多信息,请参见SQL数据库驱动程序。
SQL API层:
这些类提供对数据库的访问。使用QSqlDatabase类进行连接。数据库交互是通过使用QSqlQuery类实现的。除了QSqlDatabase和QSqlQuery, SQL API层还支持QSqlError、QSqlField、QSqlIndex和QSqlRecord。
用户接口层:
这些类将数据从数据库链接到可感知数据的小部件。它们包括QSqlQueryModel、qsqlltablemodel和QSqlRelationalTableModel。这些类被设计用于Qt的模型/视图框架。
注意:在使用任何这些类之前,必须实例化QCoreApplication对象。
4.数据库类的使用
qt使用QSqlDatabase类来连接打开数据库,基本使用流程:
- 选择数据库驱动
- 设置数据库名字,地址,ip,主机名字,用户名,密码
- 打开数据库
- 使用QSqlQuery或者QSqlQueryModel执行数据库语句
- QSqlQuery使用QSqlRecord查看每一条记录,QSqlQueryModel可以使用QTableView查看
代码片段 :
qDebug()<<QSqlDatabase::drivers();//打印所有数据库驱动
/*QSqlDatabase QSqlDatabase::addDatabase(const QString &type, const QString &connectionName = QLatin1String( defaultConnection ))
使用驱动程序类型和连接名称connectionName将数据库添加到数据库连接列表中。如果已经存在名为connectionName的数据库连接,则删除该连接。*/
QSqlDatabase db = QSqlDatabase::addDatabase("QSQLITE");//连接到数据库
/*void QSqlDatabase::setDatabaseName(const QString &name)
将连接的数据库名称设置为name。要生效,必须在打开连接之前设置数据库名称。或者,您可以close()连接,设置数据库名称,然后再次调用open()。*/
db.setDatabaseName("test.db");//设定数据库名字
/*使用当前连接值打开数据库连接。成功时返回true;否则返回false。可以使用lastError()检索错误信息。*/
bool f = db.open();
if(!f){
QSqlError err = db.lastError();//打印数据库错误
qDebug()<< err.text();
}
QSqlQuery query(db);//定义QSqlQuery 使用QSqlQuery 执行sql语句
f = query.exec("create table student(id int,name text,year int,addr text,learn int)");
if(!f){
QSqlError err = query.lastError();
qDebug()<< err.text();
}
for(int i=0;i<1000000;i++){//插入1000000条数据
f = query.exec(QString("insert into student values(%1,'ak%2',%3,'四川%4',%5)").arg(i).arg(i).arg(i/2+6).arg(i).arg(qrand()%100));
if(!f){
QSqlError err = query.lastError();
qDebug()<< err.text()<<i;
}
}
f = query.exec("select * from student");//查询student表格数据
if(!f){
QSqlError err = query.lastError();
qDebug()<< err.text();
}
do {//打印每一列数据 query.count()可以返回列宽度
QSqlRecord record = query.record();
qDebug()<<record.count();
qDebug()<<record.value(0).toInt();
qDebug()<<record.value(1).toString();
qDebug()<<record.value(2).toInt();
qDebug()<<record.value(3).toString();
qDebug()<<record.value(4).toInt();
} while (query.next());
//使用模型视图查看表格数据
QSqlQueryModel *model = new QSqlQueryModel;
// model->setTable("student");
model->setQuery(QString("select * from student order by learn"),db);
ui->tableView->setModel(model);
ui->tableView->setSelectionBehavior(QAbstractItemView::SelectRows);
ui->tableView->installEventFilter(this);