前言
通过Selenium获取京东商品数据,并写入到Excel表格中,然后统计每个店铺名称出现的频率,并选取前5个,显示到可视化数据中。
- 在了解以下内容前,我们需要先提前了解Selenium,Selenium相关文章:链接
一、方法
1、打开京东页面,并在输入框中输入商品名称,点击搜索
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 创建了一个Chrome浏览器的WebDriver实例
drive = webdriver.Chrome()
# 打开京东页面
drive.get('https://www.jd.com/')
# 搜索框输入商品名称
drive.find_element(By.CSS_SELECTOR, '#key').send_keys("手机")
# 点击搜索
drive.find_element(By.CSS_SELECTOR, '.search-m .button').click()
# 其余代码写入...
time.sleep(20)
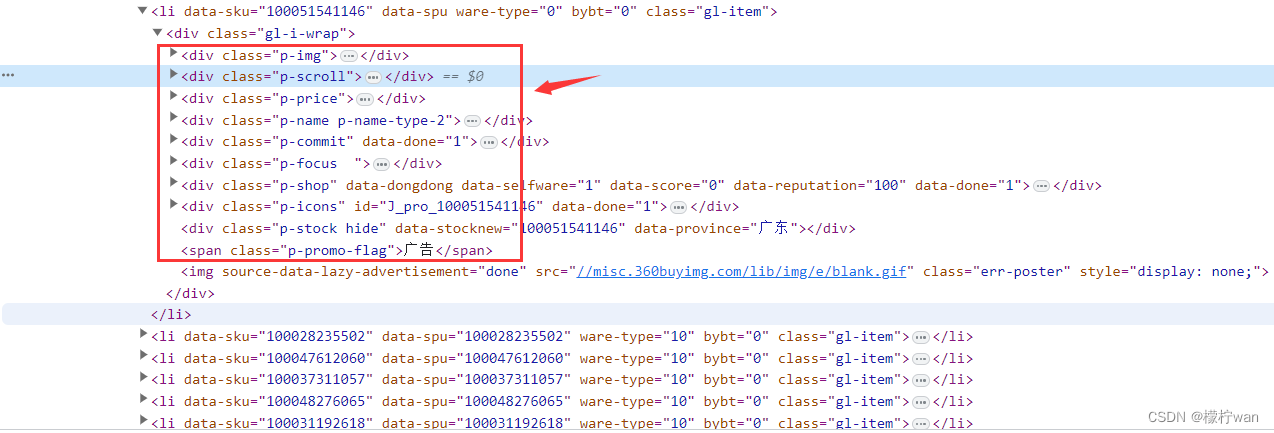
2、搜索出商品后,我们应该如何获取所有商品数据了,我们先打开开发者模式,找到商品数据,如下:

找到商品数据后,我们就可以获取了(注:默认商品数据只会加载一部分,我们需要通过滑动加载所有商品数据)
# 执行JavaScript脚本,将当前页面滚动条位置滑动到最底部
drive.execute_script("window.scrollTo(0, document.body.scrollHeight)")
# 等待页面加载完成
time.sleep(2)
# 获取所有商品数据,随机选择一个商品鼠标右键-Copy-Copy XPATH,获取到//*[@id="J_goodsList"]/ul/li[1]
# [1]代表第1个商品,我们现在要获取所有,所以不需要[1]。
Product_list = drive.find_elements(By.XPATH, '//*[@id="J_goodsList"]/ul/li')
获取到所有商品列表后,我们现在需要获取商品名称、商品金额、商品评论总数、商家名称、商品链接、并写入到列表中
names, prices, commits, shops, url = [], [], [], [], []
for i in Product_list:
# 获取商品名称、商品金额、商品评论总数、商家名称、商品链接
name = i.find_element(By.CSS_SELECTOR, '.p-name').text
price = i.find_element(By.CSS_SELECTOR, '.p-price').text
commit = i.find_element(By.CSS_SELECTOR, '.p-commit').text
shop = i.find_element(By.CSS_SELECTOR, '.p-shop').text
get_url = i.find_element(By.CSS_SELECTOR, '.p-commit [target="_blank"]').get_attribute('href')
# 把获取到的数据写入列表中
names.append(name)
prices.append(price)
commits.append(commit)
shops.append(shop)
url.append(get_url)
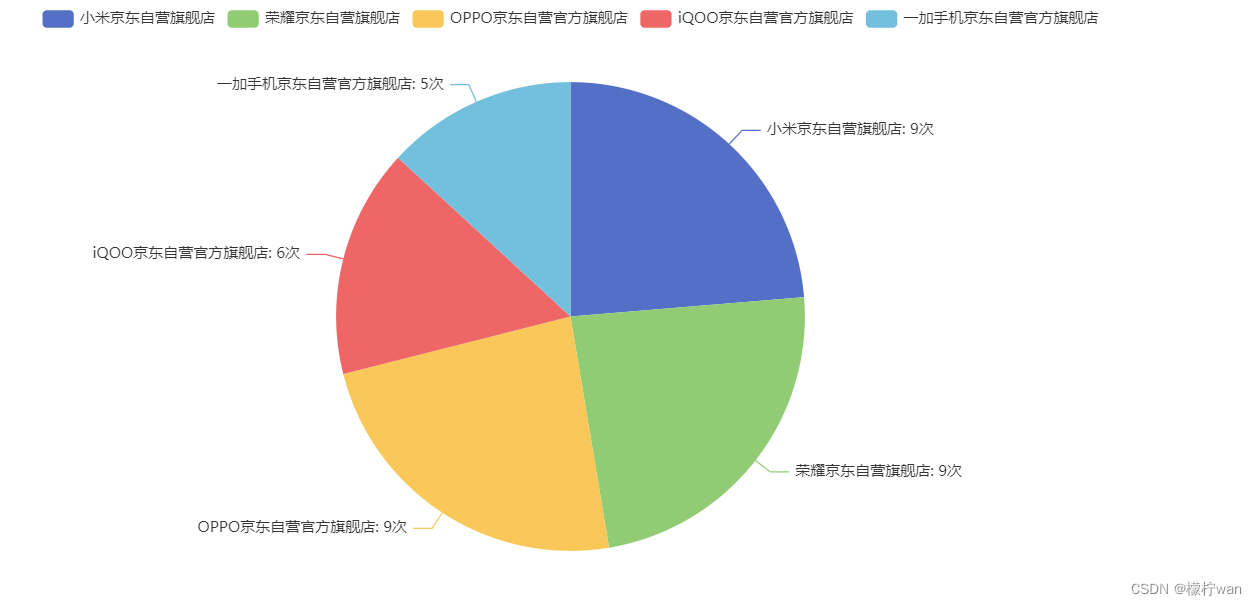
统计每个店铺名称出现的频率,并选取前5个,显示到可视化数据中
# Pandas 是一个开源的 Python 数据分析库
import pandas as pd
# Pyecharts 是一个基于 Python 的数据可视化库
# Pyecharts 能够提供多种图表样式,包括折线图、柱状图、散点图、地图等,并且支持实时刷新数据
# 官网:https://gallery.pyecharts.org/
from pyecharts import options as opts
from pyecharts.charts import Pie
# 使用Pandas的DataFrame构造函数来创建一个DataFrame对象
df = pd.DataFrame(
{
"商品名称": names,
"金额": prices,
"总评论数": commits,
"商家": shops,
'商品地址': url
}
)
# df.iloc[:, 3]: 读取第四列,value_counts() 统计每个商家名称出现的频率,并选取前5个
group_data = df.iloc[:, 3].value_counts().head(5)
# 获取商家名称和对应次数,并写入列表:[['商家A', 6], ['商家B', 10], ['商家C', 3]]
data = [list(z) for z in zip(group_data.index.tolist(),
group_data.values.tolist()
)]
# 生成图表
pip = (Pie()
.add(series_name="商家", data_pair=data)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}次"))
.render("1.html")
)
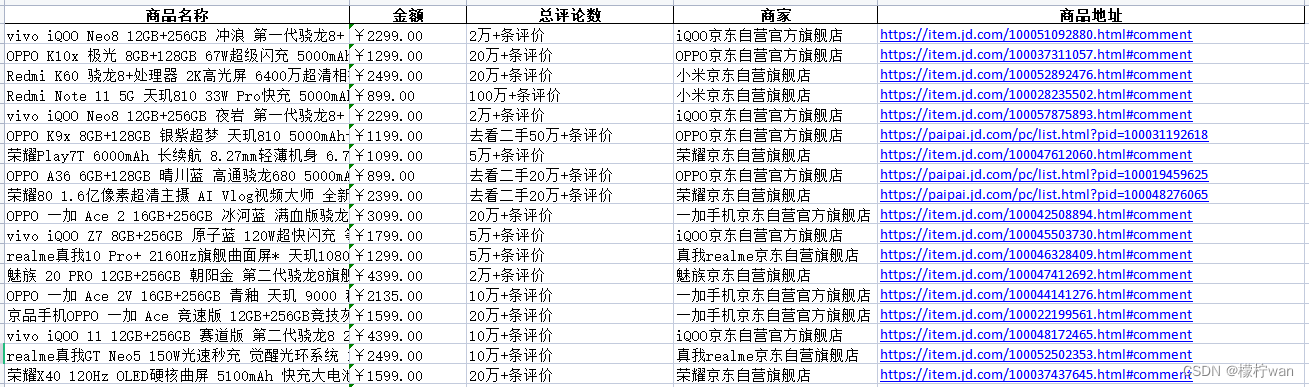
把获取到的商品数据,写入Excel中
# 写入Excel文件,设置为 index=True (默认值),则会在 Excel 文件的第一列加入行索引
df.to_excel('1.xlsx', sheet_name='京东商品', index=False)
完整代码
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# Pandas 是一个开源的 Python 数据分析库
import pandas as pd
# Pyecharts 是一个基于 Python 的数据可视化库
# Pyecharts 能够提供多种图表样式,包括折线图、柱状图、散点图、地图等,并且支持实时刷新数据
# 官网:https://gallery.pyecharts.org/
from pyecharts import options as opts
from pyecharts.charts import Pie
class jd:
def __init__(self, name, number):
# 创建了一个Chrome浏览器的WebDriver实例
self.drive = webdriver.Chrome()
# 最大化窗口
self.drive.maximize_window()
# 隐式等待,设置最大的等待时长,只对查找元素(find_elementXXX)生效
self.drive.implicitly_wait(2)
# 商品名称
self.name = name
# 页数
self.number = int(number)
def get_products(self):
'''代码执行'''
# 通过get()方法打开网页
self.drive.get('https://www.jd.com/')
# 搜索框输入商品名称
self.drive.find_element(By.CSS_SELECTOR, '#key').send_keys(self.name)
# 点击搜索
self.drive.find_element(By.CSS_SELECTOR, '.search-m .button').click()
time.sleep(1)
names, prices, commits, shops, url = [], [], [], [], []
for i in range(self.number):
# 执行JavaScript脚本,将当前页面滚动条位置滑动到最底部
self.drive.execute_script("window.scrollTo(0, document.body.scrollHeight)")
# 等待页面加载完成
time.sleep(2)
Product_list = self.drive.find_elements(By.XPATH, '//*[@id="J_goodsList"]/ul/li')
for i in Product_list:
# 获取商品名称、商品金额、商品评论、商家名称、商品链接
name = i.find_element(By.CSS_SELECTOR, '.p-name').text
price = i.find_element(By.CSS_SELECTOR, '.p-price').text
commit = i.find_element(By.CSS_SELECTOR, '.p-commit').text
shop = i.find_element(By.CSS_SELECTOR, '.p-shop').text
get_url = i.find_element(By.CSS_SELECTOR, '.p-commit [target="_blank"]').get_attribute('href')
# 把获取到的数据写入列表中
names.append(name)
prices.append(price)
commits.append(commit)
shops.append(shop)
url.append(get_url)
# 点击下一页
self.drive.find_element(By.CSS_SELECTOR, '.pn-next').click()
time.sleep(2)
# 使用Pandas的DataFrame构造函数来创建一个DataFrame对象
df = pd.DataFrame({
"商品名称": names,
"金额": prices,
"总评论数": commits,
"商家": shops,
'商品地址': url
})
# 方法一
# df.iloc[:, 3]: 读取第四列,value_counts() 统计每个商家名称出现的频率,并选取前5个
group_data = df.iloc[:, 3].value_counts().head(5)
# 方法二
# 获取出现次数最多的前5个商家
# group_data = df.groupby("商家").size().sort_values(ascending=False).head(5)
# 代码解析:
# data = []
# for z in zip(group_data.index.tolist(), group_data.values.tolist()):
# data.append(list(z))
# 获取商家名称和对应次数,并写入列表:[['商家A', 6], ['商家B', 10], ['商家C', 3]]
data = [list(z) for z in zip(group_data.index.tolist(),
group_data.values.tolist()
)]
# 生成图表
pip = (Pie()
.add(series_name="商家", data_pair=data)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}次"))
.render("1.html")
)
# 写入Excel文件,设置为 index=True (默认值),则会在 Excel 文件的第一列加入行索引
df.to_excel('1.xlsx', sheet_name='京东商品', index=False)
if __name__ == "__main__":
name = input("请商品名称: ")
numeral = input("请输入需要获取的页数: ")
run = jd(name, numeral)
run.get_products()