目录
(2)控制台运行创建框架命令(spiderTest是框架目录名称,按需定义)
2.4.1 需要进入爬虫框架目录 cd spiderTest
前言
本文针对初学者,我会使用最简单的图例、案例带你了解python爬虫!
需要提前下载PyCharm编辑器。
在互联网领域,爬虫一般指抓取众多公开网站网页上数据的相关技术。
想要入门Python 爬虫首先需要解决四个问题
- 熟悉python编程
- 了解HTML
- 了解网络爬虫的基本原理
- 学习使用python爬虫库
你应该知道什么是爬虫?
网络爬虫,其实叫作网络数据采集更容易理解。
就是通过编程向网络服务器请求数据(HTML表单),然后解析HTML,提取出自己想要的数据。
归纳为四大步:
- 根据url获取HTML数据
- 解析HTML,获取目标信息
- 存储数据
- 重复第一步
这会涉及到数据库、网络服务器、HTTP协议、HTML、数据科学、网络安全、图像处理等非常多的内容。但对于初学者而言,并不需要掌握这么多。
长话短说,接下来带你初步认识爬虫,如果你是入门小白或者初学爬虫,相信这些知识对你会有所启发!
一.Scrapy的基本执行过程
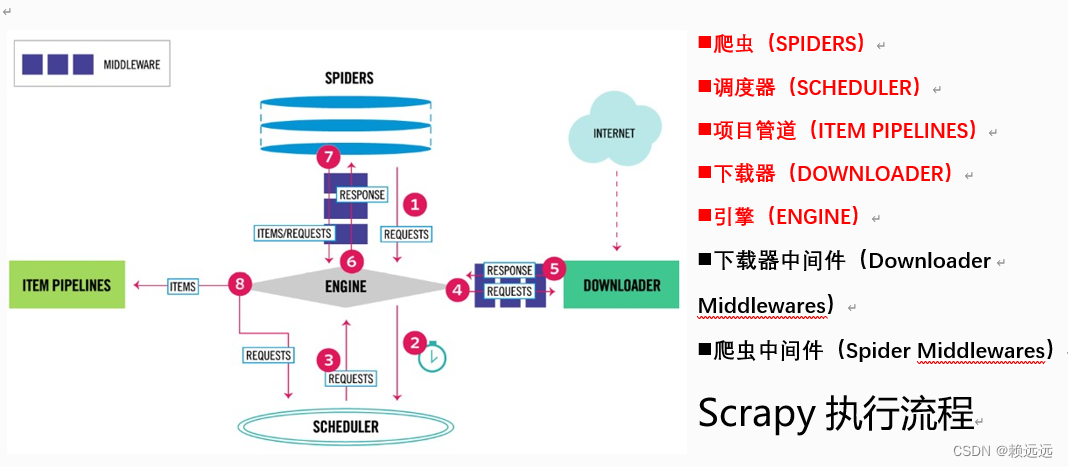
第①步:爬虫(Spider)使用URL(要爬取页面的网址)构造一个请求(Request)对象,提交给引擎(Engine)。如果请求要伪装成浏览器,或者设置代理IP,可以先在爬虫中间件中设置,再发送引擎。
第②步:引擎将请求安排给调度器(Scheduler),调度器根据请求的优先级确定执行顺序。
第③步:引擎从调度器获取即将要执行的请求。
第④步:引擎通过下载器中间件,将请求发送给下载器下载页面。
第⑤步:页面完成下载后,下载器会生成一个响应(Response)对象并将其发送给引擎。下载后的数据会保存于响应对象中。
第⑥步:引擎接收来自下载器的响应对象后,通过爬虫中间件,将其发送给爬虫(Spider)进行处理。
第⑦步:爬虫将抽取到的一条数据实体(Item)和新的请求(如下一页的链接)发送给引擎。
第⑧步:引擎将从爬虫获取到的Item发送给项目管道(Item Pipelines),项目管道实现数据持久化等功能。同时将新的请求发送给调度器,再从第②步开始重复执行,直到调度器中没有更多的请求,引擎关闭该网站。
Scrapy组件总结

初步了解了爬虫组件以及实现流程,接下来让我们来实现一个简单爬虫!!!
二.Scrapy的实现
我们这次的实践使用开发工具PyCharm进行操作,目的是爬取 http://woodenrobot.me 下的每一个文档标题
主要分为4个步骤:

2.1Scrapy框架安装
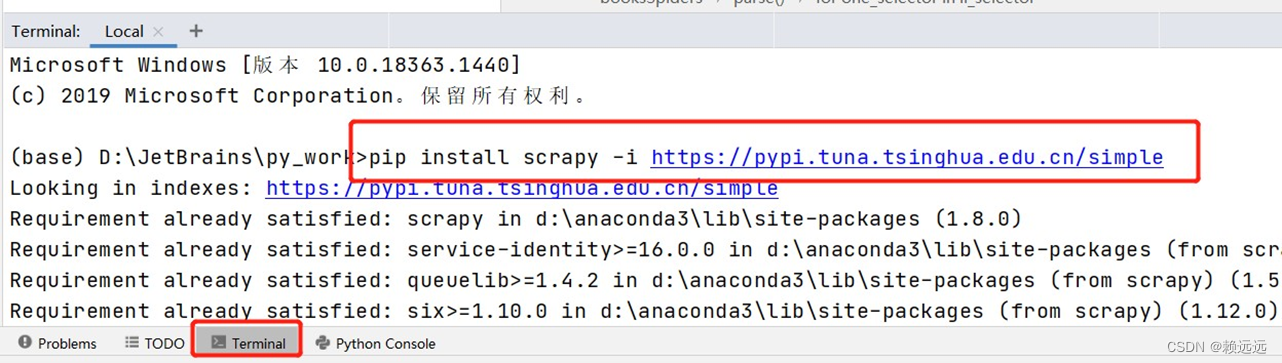
下载爬虫框架,在终端输入命令(可以直接输入 pip install scrapy 下载,但会很慢,我们选择从国内镜像源下载):
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完后验证安装是否成功,随便创建一个.py文件,输入如下代码,
import scrapy
print(scrapy.version_info)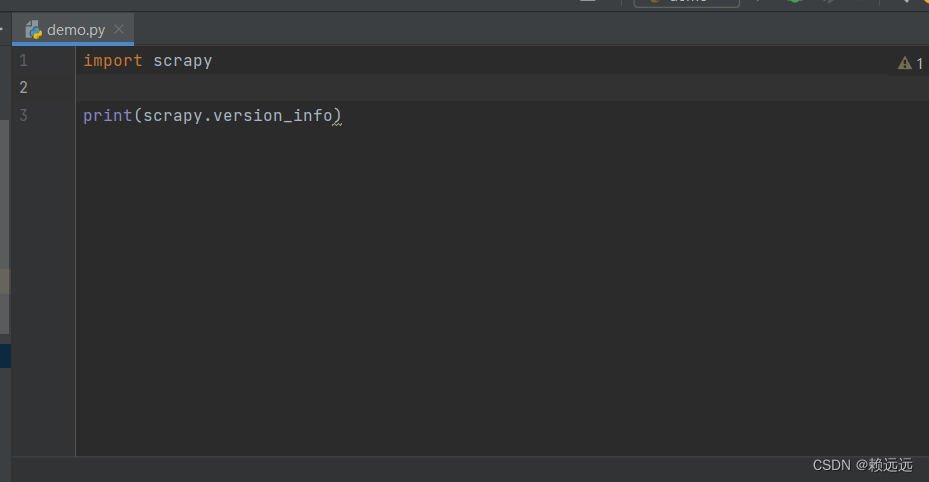
结果:

2.2创建项目
(1)爬虫框架组件介绍

(2)控制台运行创建框架命令(spiderTest是框架目录名称,按需定义)
scrapy startproject spiderTest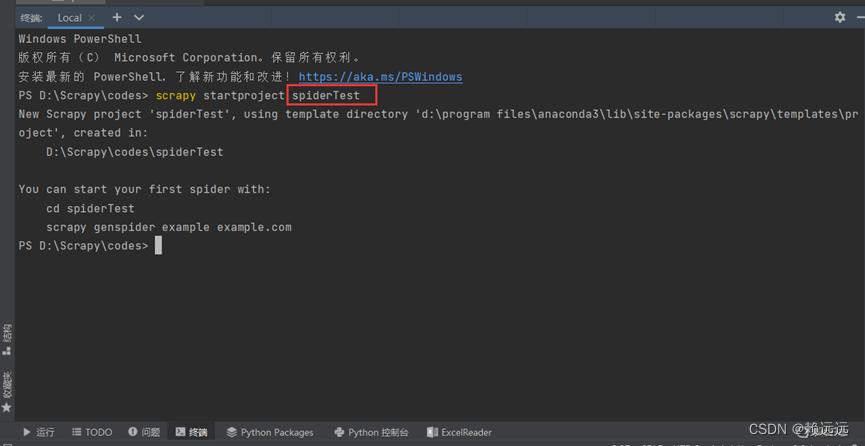
运行后自动生成了目录框架
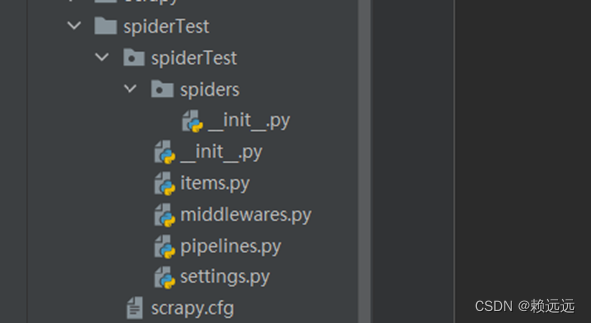
2.3编写爬虫程序
Spider类介绍

我们编写的爬虫程序,需要继承Spider类
2.3.1 在spiders下创建、编写爬虫文件,代码如下
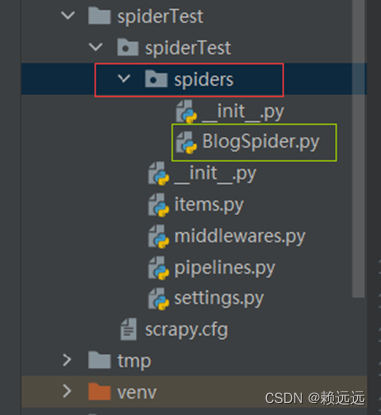
from scrapy.spiders import Spider
# BologSpider继承Spider类
class BlogSpider(Spider):
#爬虫的名称
name = 'test'
# 获取一个博客的url
start_urls = ['http://woodenrobot.me']
def parse(self, response,):
# 根据标题的xpath路径,提取出标题元素
title = response.xpath("//a[@class = 'post-title-link']/text()").getall() #getall()获取所有元素,返回列表
title_one = response.xpath("//a[@class = 'post-title-link']/text()").get() # get()获取第一个元素
# 便利title列表元素并输出
for title1 in title:
print(title1)
# 输出获取的一个元素
print(title_one)
2.4 终端运行爬虫程序
2.4.1 需要进入爬虫框架目录 cd spiderTest

2.4.2 命令执行爬虫程序
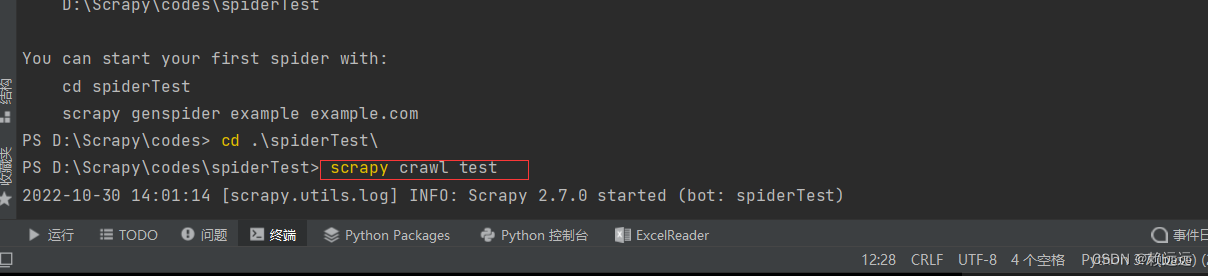
获取结果
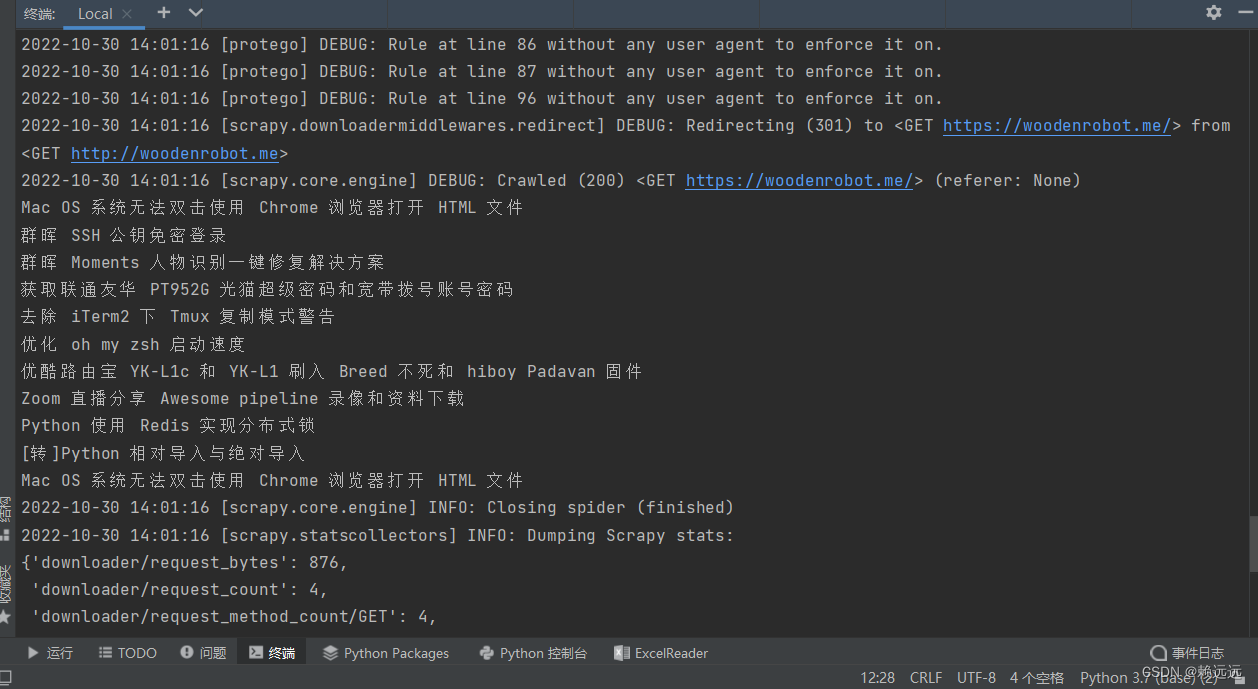
三、结语
1.总结
到这里你应该对爬虫爬取网页数据有了一个初步的概念,但想要真正学会编写高级的爬虫程序,还需要学习很多知识。
有一点还要提的就是如果你不会使用开发者工具定位爬取网页的标题(如下图),则需要另外去学习网页元素的定位,几分钟就能学会,这也是学习爬虫所必须掌握的,这里不多扩展。

2.python的学习建议
如果你不懂python,那么需要先学习python这门非常easy的语言(相对其它语言而言)。
编程语言基础语法无非是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理这些,学起来会显枯燥但并不难。
刚开始入门爬虫,你甚至不需要去学习python的类、多线程、模块之类的略难内容。找一个面向初学者的教材或者网络教程,花个十几天功夫,就能对python基础有个三四分的认识了,这时候你可以玩玩爬虫喽!
当然,前提是你必须在这十几天里认真敲代码,反复咀嚼语法逻辑,比如列表、字典、字符串、if语句、for循环等最核心的东西都得捻熟于心、于手。
可以去牛客网在线练习,这个python入门题单从最开始的Hello World到实践任务、数据分析、机器学习,都会非常详细地职导你应该使用什么函数,应该怎么输入输出。