一、需求分析
最近在测试模型的时候,部分输出obj文件很不直观,想要找到点云对应到图像文件也不好找,所以记录一下利用文件名找到同一时刻对应的其他传感器输出
我的需求如下:
测试得到的输出是单个独立的文件夹,每个文件夹里有地面真相、环境点、预测三个obj文件,要同时使用图像和点云来更好的呈现可视化,因此我需要根据LiDAR数据的文件名来找到同一时刻下其他传感器的数据,即根据某个传感器数据名找到同一时刻其他传感器数据并保存到一起。


二、代码实现
1、导入必要的包
import os
import shutil
import json
from nuscenes.nuscenes import NuScenes
# 导入数据集
nuscenes_mini_path = 'D:/数据集/目标检测系列/v1.0-mini/'
nusc = NuScenes(version='v1.0-mini', dataroot=nuscenes_mini_path, verbose=True)
导入成功有如下输出:
2、读取标注并寻找sample_token
# 读取nuScenes数据集数据标注文件(在nuScenes数据集路径下,找一下)
with open('sample_data.json', encoding='utf-8') as data_file:
datas = json.load(data_file)
length = len(datas)
# 文件名,留意下nuScenes的文件名组织,最重要的是时间戳得找对
find_file_name = 'n008-2018-08-01-15-16-36-0400__LIDAR_TOP__1533151604048025'
sample_token = None
find_sample = None
# 以下是根据部分文件名定位出具体的一条数据,然后提取其中的sample_token
for data in datas:
if data['filename'].find(find_file_name):
sample_token = data['sample_token']
break
if sample_token is None:
print('没有找到')
else:
find_sample = nusc.get('sample', sample_token) # 根据sample_token 获取到整个sample
print(find_sample)
这一步我们得到了整个sample,在我的需求下,我关心data数据,其记录了每个传感器的token值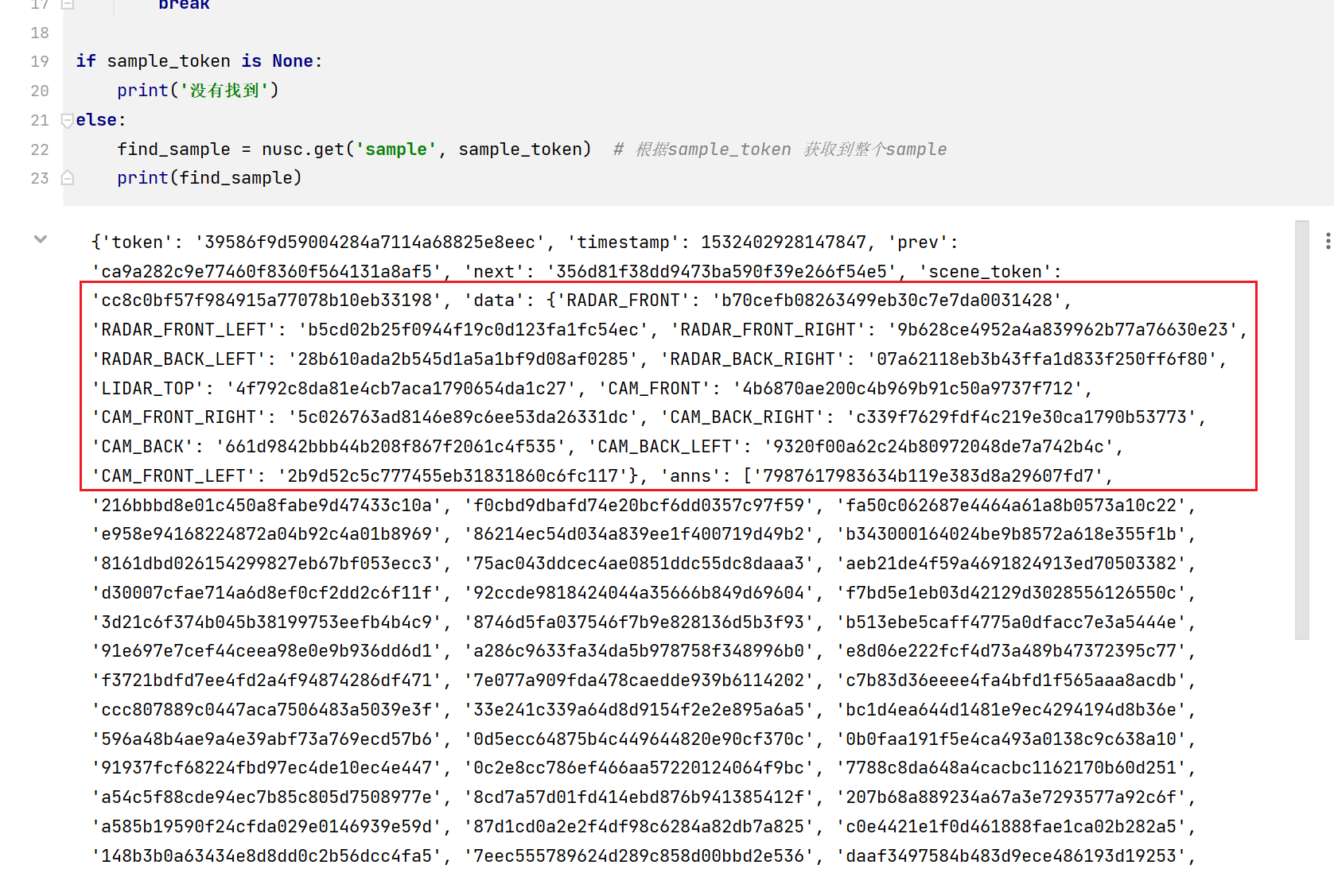
3、复制文件
# 需要提取的传感器
sensors = ['CAM_FRONT', 'CAM_FRONT_RIGHT', 'CAM_BACK_RIGHT', 'CAM_BACK', 'CAM_BACK_LEFT', 'CAM_FRONT_LEFT']
# 保存路径
save_path = 'save_dir/'
tar_path = save_path + sample_token
# 在save_path下,创捡名为sample_token的文件夹
if not os.path.exists(tar_path):
os.makedirs(tar_path)
for sensor in sensors:
sensor = nusc.get('sample_data', find_sample['data'][sensor])
per_img = nuscenes_mini_path + sensor['filename']
# 也可以直接使用下面这句保存带标注的图片
# 其中out_path需要指定文件名,如outpath = 'save_dir/test.png'
# 如果想实现标注的个性化(边框颜色之类),需要重写render_sample_data方法
# nusc.render_sample_data(sensor['token'],with_anns=True,out_path='') # with_anns表示带标注
shutil.copy(per_img, tar_path)
上述代码段,首先创建了需要提取的传感器列表,并指定了一个保存路径,并且会在保存路径下再创建一个以sample_token文件夹,用于保存数据。随后就是复制每个每个传感器对应的数据到相应路径,运行效果如下图

4、1-3步完整代码段
import os
import shutil
from nuscenes.nuscenes import NuScenes
import json
# 导入数据集
nuscenes_mini_path = 'D:/数据集/目标检测系列/v1.0-mini/'
nusc = NuScenes(version='v1.0-mini', dataroot=nuscenes_mini_path, verbose=True)
# 读取nuScenes数据集数据标注文件
with open('sample_data.json', encoding='utf-8') as data_file:
datas = json.load(data_file)
length = len(datas)
# 文件名,留意下nuScenes的文件名组织,最重要的是时间戳得找对
find_file_name = 'n008-2018-08-01-15-16-36-0400__LIDAR_TOP__1533151604048025'
sample_token = None
find_sample = None
# 以下是根据部分文件名定位出具体的一条数据,然后提取其中的sample_token
for data in datas:
if data['filename'].find(find_file_name):
sample_token = data['sample_token']
break
if sample_token is None:
print('没有找到')
else:
find_sample = nusc.get('sample', sample_token) # 根据sample_token 获取到整个sample
print(find_sample)
# 需要提取的传感器
sensors = ['CAM_FRONT', 'CAM_FRONT_RIGHT', 'CAM_BACK_RIGHT', 'CAM_BACK', 'CAM_BACK_LEFT', 'CAM_FRONT_LEFT']
# 保存路径
save_path = 'save_dir/'
tar_path = save_path + sample_token
# 在save_path下,创捡名为sample_token的文件夹
if not os.path.exists(tar_path):
os.makedirs(tar_path)
for sensor in sensors:
sensor = nusc.get('sample_data', find_sample['data'][sensor])
per_img = nuscenes_mini_path + sensor['filename']
shutil.copy(per_img, tar_path) #复制操作