简介
上篇文章介绍到如何使用mavon-editor,没想到没过过久公司来了新需求,又在之前需求上继续优化。由于mavon-editor暂不支持直接复制本地电脑word内容进行粘贴展示并转换成markdown,于是新增一个切换按钮,使用wangeditor进行word文档编辑,用户需在markdown与word之间进行切换使用,目前实现了切换两种富文本框内容格式互相转换,md格式通过拿到html后转换展示在wangeditor上,wangeditor的word文档内容也能切换成md格式展示在markdown格式编辑器的mavon-editor上。废话不多说上代码,下面是演示截图与代码,其中md转换html转载来自 https://cloud.tencent.com/developer/article/2239608?from=15425&areaSource=102001.2&traceId=MC_FGLecJ4GHAO_jTuPPV
安装wangeditor
yarn add @wangeditor/editor-for-vue
# 或者 npm install @wangeditor/editor-for-vue --save
在此不多介绍wangeditor编辑器,是一款非常好用的富文本编辑器,具体可以参考其官网:https://www.wangeditor.com/
按照完毕后项目实现页面如下,通过按钮进行两者内容切换
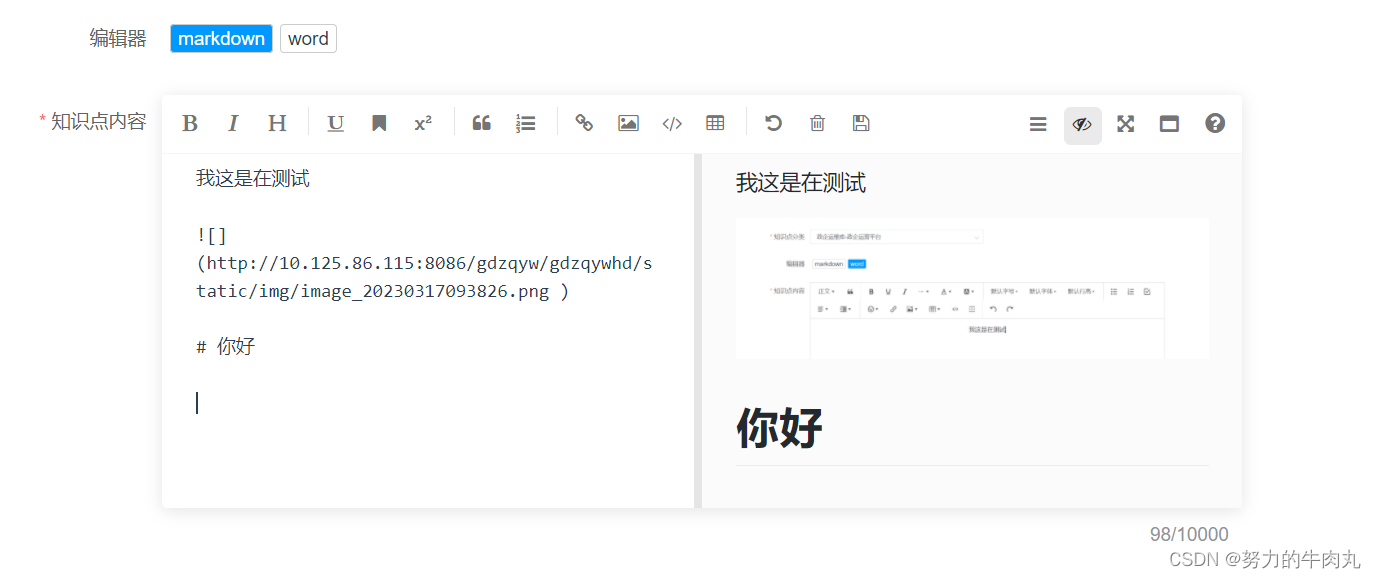
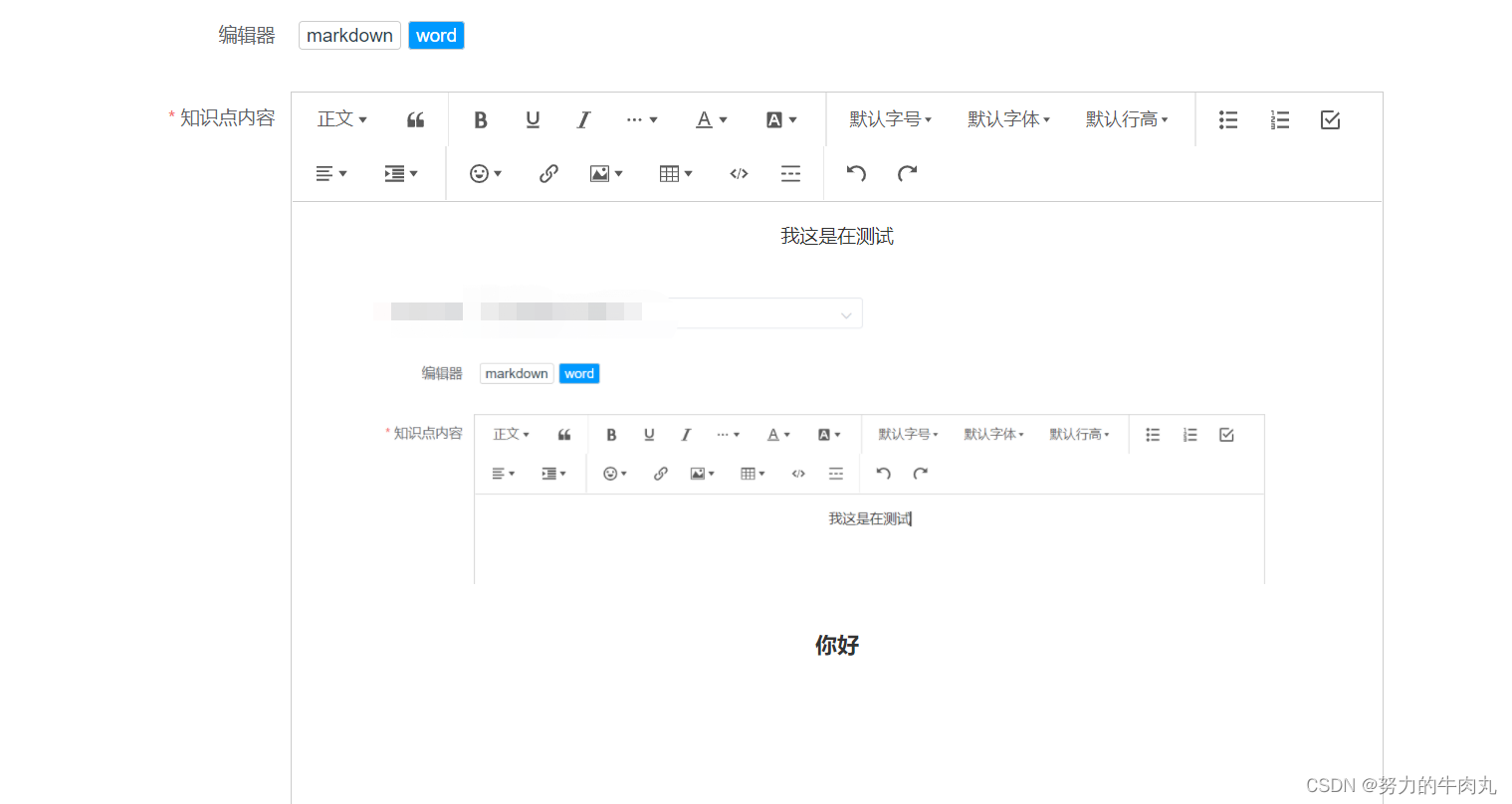
通过获取不同富文本编辑器返回的html内容,再在下面转换js中进行转换拿到md格式,以下为在vue项目中写法,在代码最后导出此方法。具体做法在vue项目中的公共组件文件夹中新建一个js文件,将此方法粘贴进去最后再需要使用的地方引入即可,如下图

随后在代码中使用

/**
* 把 html 内容转化为 markdown 格式 V1.0
*
* @author kohunglee
* @param {string} htmlData 转换前的 html
* @return {string} 转化后的 markdown 源码
*/
function html2md(htmlData){
let codeContent = new Array // code标签数据
let preContent = new Array // pre标签数据
let tableContent = new Array // table标签数据
let olContent = new Array // ol标签数据
let imgContent = new Array // img标签数据
let aContent = new Array // a标签数据
let pureHtml = htmlData
// 源代码
console.log("转换前的源码:" + pureHtml)
// 函数:删去html标签
function clearHtmlTag(sourceData = ''){
return sourceData.replace(/\<[\s\S]*?\>/g,'')
}
// 复原ol标签
function olRecover(olData = ''){
let result = olData
let num = olData.match(/\<li\>/ig).length
for(let i = 1; i <= num; i++){
let line = '[~wrap]'
if(i == 1) line = '[~wrap][~wrap]'
result = result.replace(/\<li\>/i, line + i + '. ')
}
result = result.replace(/\<\/li\>/, '')
return result
}
// 函数:复原img标签
function imgRecover(imgHtml = ''){
let imgSrc,imgTit,imgAlt,result
imgSrc = imgHtml.match(/(?<=src=['"])[\s\S]*?(?=['"])/i)
imgTit = imgHtml.match(/(?<=title=['"])[\s\S]*?(?=['"])/i)
imgAlt = imgHtml.match(/(?<=alt=['"])[\s\S]*?(?=['"])/i)
imgTit = (imgTit != null) ? ` "${
imgTit}"` : ' '
imgAlt = (imgAlt != 'null') ? imgAlt : " "
result = ``
return result
}
// 函数:复原a标签
function aRecover(aData = ''){
let aHref = '' + aData.match(/(?<=href=['"])[\s\S]*?(?=['"])/i)
let aTit = '' + aData.match(/(?<=title=['"])[\s\S]*?(?=['"])/i)
let aText = '' + aData.match(/(?<=\<a\s*[^\>]*?\>)[\s\S]*?(?=<\/a>)/i)
let aImg = aData.match(/<img\s*[^\>]*?\>[^]*?(<\/img>)?/i)
let aImgSrc,aImgTit,aImgAlt
aTit = (aTit != 'null') ? ` "${
aTit}"` : ' '
aText = clearHtmlTag(aText)
let result = `[${
aText}](${
aHref}${
aTit})`
if(aImg != null){
// 函数:如果发现图片,则更换为图片显示模式
aImgSrc = aImg[0].match(/(?<=src=['"])[\s\S]*?(?=['"])/i)
aImgTit = aImg[0].match(/(?<=title=['"])[\s\S]*?(?=['"])/i)
aImgAlt = aImg[0].match(/(?<=alt=['"])[\s\S]*?(?=['"])/i)
aImgTit = (aImgTit != null) ? ` "${
aImgTit}"` : ' '
aImgAlt = (aImgAlt != 'null') ? aImgAlt : " "
result = `[](${
aHref}${
aTit})`
}
return result
}
// 函数:复原table标签
function tableRecover(tableData = null){
if(tableData[0] == null){
// 如果不存在 th 标签,则默认表格为一层
let result = ''
let colNum = tableData[1].length
for(let i = 0; i < colNum; i++){
result += `|${
clearHtmlTag(tableData[1][i])}`
}
result += `|[~wrap]`
for(let j = 0; j < colNum; j++){
result += `| :------------: `
}
result += `|[~wrap]`
return result
}
let colNum = tableData[0].length // 如果存在 th 标签,则按 th 的格数来构建整个表格
let result = ''
for(let i = 0; i < colNum; i++){
result += `|${
clearHtmlTag(tableData[0][i])}`
}
result += `|[~wrap]`
for(let j = 0; j < colNum; j++){
result += `| :------------: `
}
result += `|[~wrap]`
for(let k = 0; k < tableData[1].length;){
for(let z = 0; z < colNum; z++,k++){
result += `|${
clearHtmlTag(tableData[1][k])}`
}
result += `|[~wrap]`
}
return result+`[~wrap]`
}
// 去掉样式和脚本极其内容
pureHtml = pureHtml.replace(/<style\s*[^\>]*?\>[^]*?<\/style>/ig,'').replace(/<script\s*[^\>]*?\>[^]*?<\/script>/ig,'')
// 储存pre的内容,并替换<pre>中的内容
preContent = pureHtml.match(/<pre\s*[^\>]*?\>[^]*?<\/pre>/ig)
pureHtml = pureHtml.replace(/(?<=\<pre\s*[^\>]*?\>)[\s\S]*?(?=<\/pre>)/ig,'`#preContent#`')
// 储存code的内容,并替换<code>中的内容
codeContent = pureHtml.match(/(?<=\<code\s*[^\>]*?\>)[\s\S]*?(?=<\/code>)/ig)
pureHtml = pureHtml.replace(/(?<=\<code\s*[^\>]*?\>)[\s\S]*?(?=<\/code>)/ig,'`#codeContent#`')
// 储存a的内容,并替换<a>中的内容
aContent = pureHtml.match(/<a\s*[^\>]*?\>[^]*?<\/a>/ig)
pureHtml = pureHtml.replace(/<a\s*[^\>]*?\>[^]*?<\/a>/ig,'`#aContent#`')
// 储存img的内容,并替换<img>中的内容
imgContent = pureHtml.match(/<img\s*[^\>]*?\>[^]*?(<\/img>)?/ig)
pureHtml = pureHtml.replace(/<img\s*[^\>]*?\>[^]*?(<\/img>)?/ig,'`#imgContent#`')
// 获取纯净(无属性)的 html
pureHtml = pureHtml.replace(/(?<=\<[a-zA-Z0-9]*)\s.*?(?=\>)/g,'')
// 标题:标获取<h1><h2>...数据,并替换
pureHtml = pureHtml.replace(/<h1>/ig,'[~wrap]# ').replace(/<\/h1>/ig,'[~wrap][~wrap]')
.replace(/<h2>/ig,'[~wrap]## ').replace(/<\/h2>/ig,'[~wrap][~wrap]')
.replace(/<h3>/ig,'[~wrap]### ').replace(/<\/h3>/ig,'[~wrap][~wrap]')
.replace(/<h4>/ig,'[~wrap]#### ').replace(/<\/h4>/ig,'[~wrap][~wrap]')
.replace(/<h5>/ig,'[~wrap]##### ').replace(/<\/h5>/ig,'[~wrap][~wrap]')
.replace(/<h6>/ig,'[~wrap]###### ').replace(/<\/h6>/ig,'[~wrap][~wrap]')
// 段落:处理一些常用的结构标签
pureHtml = pureHtml.replace(/(<br>)/ig,'[~wrap]').replace(/(<\/p>)|(<br\/>)|(<\/div>)/ig,'[~wrap][~wrap]')
.replace(/(<meta>)|(<span>)|(<p>)|(<div>)/ig,'').replace(/<\/span>/ig,'')
// 粗体:替换<b><strong>
pureHtml = pureHtml.replace(/(<b>)|(<strong>)/ig,'**').replace(/(<\/b>)|(<\/strong>)/ig,'**')
// 斜体:替换<i><em><abbr><dfn><cite><address>
pureHtml = pureHtml.replace(/(<i>)|(<em>)|(<abbr>)|(<dfn>)|(<cite>)|(<address>)/ig,'*').replace(/(<\/i>)|(<\/em>)|(<\/abbr>)|(<\/dfn>)|(<\/cite>)|(<\/address>)/ig,'*')
// 删除线:替换<del>
pureHtml = pureHtml.replace(/\<del\>/ig,'~~').replace(/\<\/del\>/ig,'~~')
// 引用:替换<blockquote>
pureHtml = pureHtml.replace(/\<blockquote\>/ig,'[~wrap][~wrap]> ').replace(/\<\/blockquote\>/ig,'[~wrap][~wrap]')
// 水平线:替换<hr>
pureHtml = pureHtml.replace(/\<hr\>/ig,'[~wrap][~wrap]------[~wrap][~wrap]')
// 表格 <table>,得到数据,删除标签,然后逐层分析储存,最终根据结果生成
tableContent = pureHtml.match(/(?<=\<table\s*[^\>]*?\>)[\s\S]*?(?=<\/table>)/ig)
pureHtml = pureHtml.replace(/<table\s*[^\>]*?\>[^]*?<\/table>/ig,'`#tableContent#`')
if(tableContent !== null){
// 分析储存
tbodyContent = new Array
for(let i = 0; i < tableContent.length; i++){
tbodyContent[i] = new Array // tbodyContent[i]的第一个数据是thead数据,第二个是tbody的数据
tbodyContent[i].push(tableContent[i].match(/(?<=\<th>)[\s\S]*?(?=<\/th?>)/ig))
tbodyContent[i].push(tableContent[i].match(/(?<=\<td>)[\s\S]*?(?=<\/td?>)/ig))
}
}
if(typeof tbodyContent !== "undefined"){
// 替换
for(let i = 0; i < tbodyContent.length; i++){
let tableText = tableRecover(tbodyContent[i])
pureHtml = pureHtml.replace(/\`\#tableContent\#\`/i,tableText)
}
}
// 有序列表<ol>的<li>,储存ol的内容,并循环恢复ol中的内容
olContent = pureHtml.match(/(?<=\<ol\s*[^\>]*?\>)[\s\S]*?(?=<\/ol>)/ig)
pureHtml = pureHtml.replace(/(?<=\<ol\s*[^\>]*?\>)[\s\S]*?(?=<\/ol>)/ig,'`#olContent#`')
if(olContent !== null){
for(let k = 0; k < olContent.length; k++){
let olText = olRecover(olContent[k])
pureHtml = pureHtml.replace(/\`\#olContent\#\`/i,clearHtmlTag(olText))
}
}
// 无序列表<ul>的<li>,以及<dd>,直接替换
pureHtml = pureHtml.replace(/(<li>)|(<dd>)/ig,'[~wrap] - ').replace(/(<\/li>)|(<\/dd>)/ig,'[~wrap][~wrap]')
// 处理完列表后,将 <lu>、<\lu>、<ol>、<\ol> 处理
pureHtml = pureHtml.replace(/(<ul>)|(<ol>)/ig,'').replace(/(<\/ul>)|(<\/ol>)/ig,'[~wrap][~wrap]')
// 先恢复 img ,再恢复 a
if(imgContent !== null){
for(let i = 0; i < imgContent.length; i++){
let imgText = imgRecover(imgContent[i])
pureHtml = pureHtml.replace(/\`\#imgContent\#\`/i,imgText)
}
}
// 恢复 a
if(aContent !== null){
for(let k = 0; k < aContent.length; k++){
let aText = aRecover(aContent[k])
pureHtml = pureHtml.replace(/\`\#aContent\#\`/i,aText)
}
}
// 换行处理,1.替换 [~wrap] 为 ‘\n’ 2.首行换行删去。 3.将其他过长的换行删去。
pureHtml = pureHtml.replace(/\[\~wrap\]/ig,'\n')
.replace(/\n{3,}/g,'\n\n')
// 代码 <code> ,根据上面的数组恢复code,然后将code替换
if(codeContent !== null){
for(let i = 0; i < codeContent.length; i++){
pureHtml = pureHtml.replace(/\`\#codeContent\#\`/i,clearHtmlTag(codeContent[i]))
}
}
pureHtml = pureHtml.replace(/\<code\>/ig,' ` ').replace(/\<\/code\>/ig,' ` ')
// 代码 <pre> ,恢复pre,然后将pre替换
if(preContent !== null){
for(let k = 0; k < preContent.length; k++){
let preLanguage = preContent[k].match(/(?<=language-).*?(?=[\s'"])/i)
let preText = clearHtmlTag(preContent[k])
preText = preText.replace(/^1\n2\n(\d+\n)*/,'') // 去掉行数
preLanguage = (preLanguage != null && preLanguage[0] != 'undefined') ? preLanguage[0] + '\n' : '\n'
pureHtml = pureHtml.replace(/\`\#preContent\#\`/i,preLanguage + preText)
}
}
pureHtml = pureHtml.replace(/\<pre\>/ig,'```').replace(/\<\/pre\>/ig,'\n```\n')
// 删去其余的html标签,还原预文本代码中的 '<' 和 '>'
pureHtml = clearHtmlTag(pureHtml)
pureHtml = pureHtml.replace(/\<\;/ig,'<').replace(/\>\;/ig,'>')
// 删去头部的空行
pureHtml = pureHtml.replace(/^\n{1,}/i,'')
return pureHtml
}
export {
html2md
}