目录
1.5 总结:mysql的优化 那些字段/场景适合创建索引 那些不适合
1 索引
1.1 索引的概念
索引就是一种帮助系统能够更加快速的查找信息的数据结构。
1.2 索引的作用
①数据库利用各种快速定位技术,能够大大加快查询速度,这是创建索引的最主要的原因。
②当表很大或查询涉及到多个表时,使用索引可以成千上万倍地提高查询速度。
③可以降低数据库的IO成本,并且索引还可以降低数据库的排序成本。
④通过创建唯一性索引,可以保证数据表中每一行数据的唯一性。
⑤可以加快表与表之间的连接。
⑥在使用分组和排序时,可大大减少分组和排序的时间。
⑦建立索引在搜索和恢复数据库中的数据时能显著提高性能。
1.3 索引的副作用
①索引需要占用额外的磁盘空间。
对于 MyISAM 引擎而言,索引文件和数据文件是分离的,索引文件用于保存数据记录的地址。而 InnoDB 引擎的表数据文件本身就是索引文件。
②进行增删改数据时候要花费更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅在经常被搜索的列(以及表)上面创建索引即可。
1.4 创建索引的原则
①表的主键、外键必须有索引。因为主键具有唯一性,外键关联的是主表的主键,查询时可以快速定位。
②记录数超过300行的表应该有索引。如果没有索引,每次查询都需要把表遍历一遍,会严重影响数据库的性能。
③经常与其他表进行连接的表,在连接字段上应该建立索引。
④唯一性太差的字段不适合建立索引。
⑤更新太频繁地字段不适合创建索引。
⑥经常出现在 where 子句中的字段,特别是大表的字段,应该建立索引。
⑦经常进行 GROUP BY、ORDER BY 的字段上应该建立索引;
⑧索引应该建在选择性高的字段上。
⑨索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引。
1.5 总结:mysql的优化 那些字段/场景适合创建索引 那些不适合
1.小字段
2.唯一性强的字段。
3.更新不频繁,但是查询比较高的字段。
4.表记录超过300+行
5.主键、外键、唯一键
2 索引的分类以及创建
准备工作:
首先需要在数据库中创建一张表,进行接下来的索引操作:
create table user (id int(10),name varchar(15),cardid int(18),phone int(11),address varchar(60));
插入一些数据:
insert into user values(1,'zhangsan',111222556,12345678,'beijing');
insert into user values(2,'lisi',123456,12345678,'nanjing');
insert into user values(3,'wangwu',123321,12345214,'xijing');
insert into user values(4,'zhouliu',1230987,1234908,'dongjing');
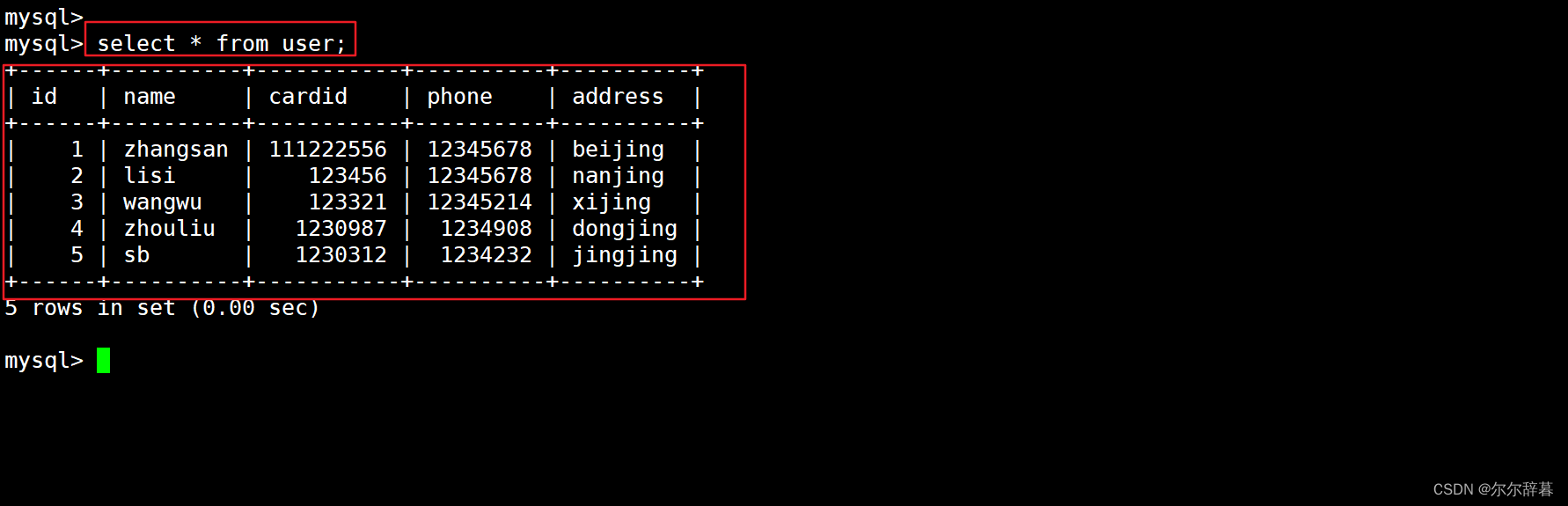
insert into user values(5,'sb',1230312,1234232,'jingjing');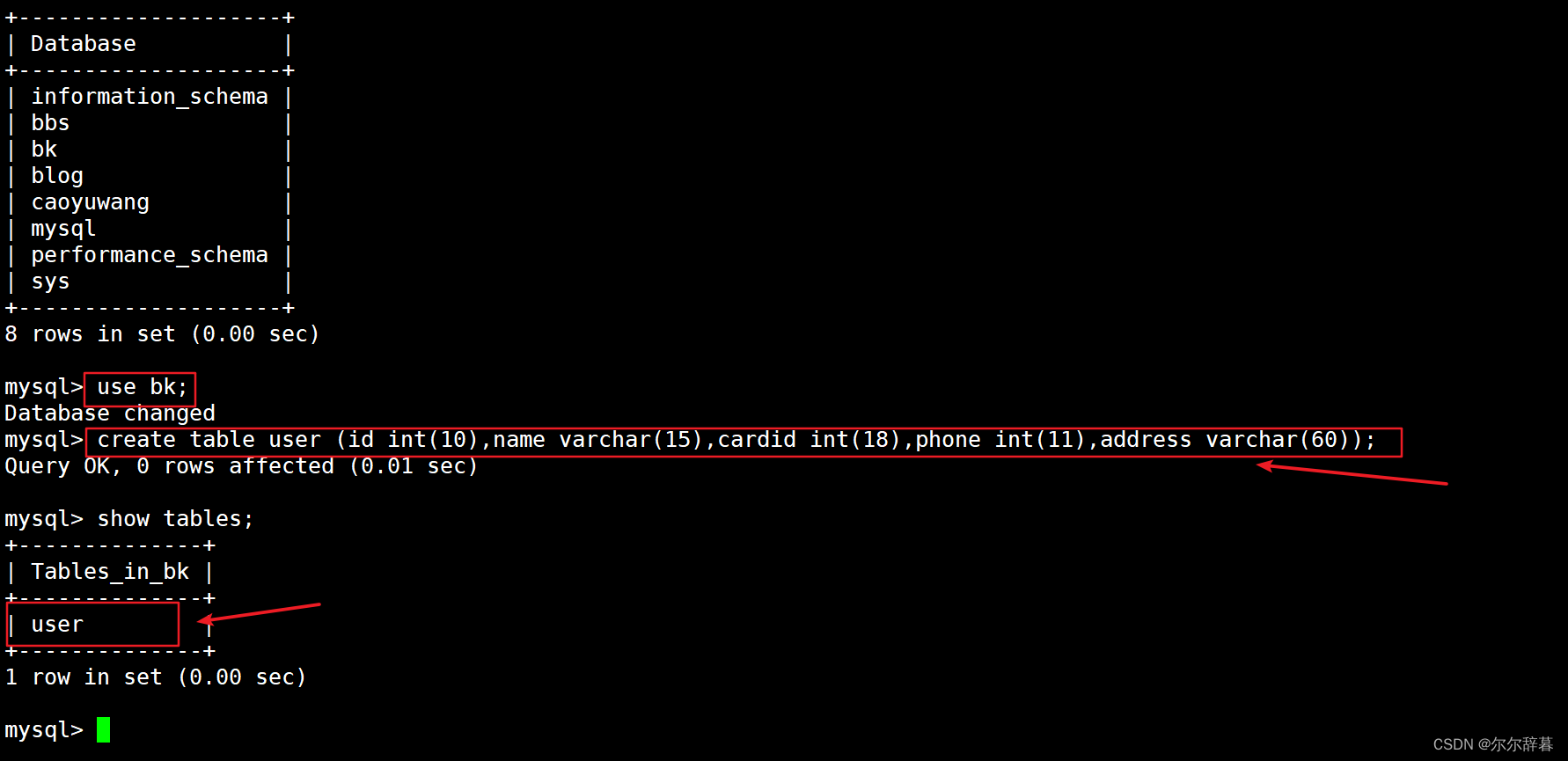
2.1 普通索引
普通索引:最基本的索引类型,没有唯一性之类的限制。
总结:针对所有字段,没有特殊的需求和规则。
创建普通索引的方式:
方式一:直接创建索引
CREATE INDEX 索引名 ON 表名 (字段名[(length)]);
#(列名(length)):length是可选项,下同。如果忽略 length 的值,则使用整个列的值作为索引。如果指定,使用列的前 length 个字符来创建索引,这样有利于减小索引文件的大小。在不损失精确性的情况下,长度越短越好。
#索引名建议以“_index”结尾。
create index 索引名 on 表名 (字段名(LEN));
查询:show create table 表名;举例:对name创建普通索引
create index name_index on user (name);
查询:show create table user; 或者 show index from user;
desc user; #查看表结构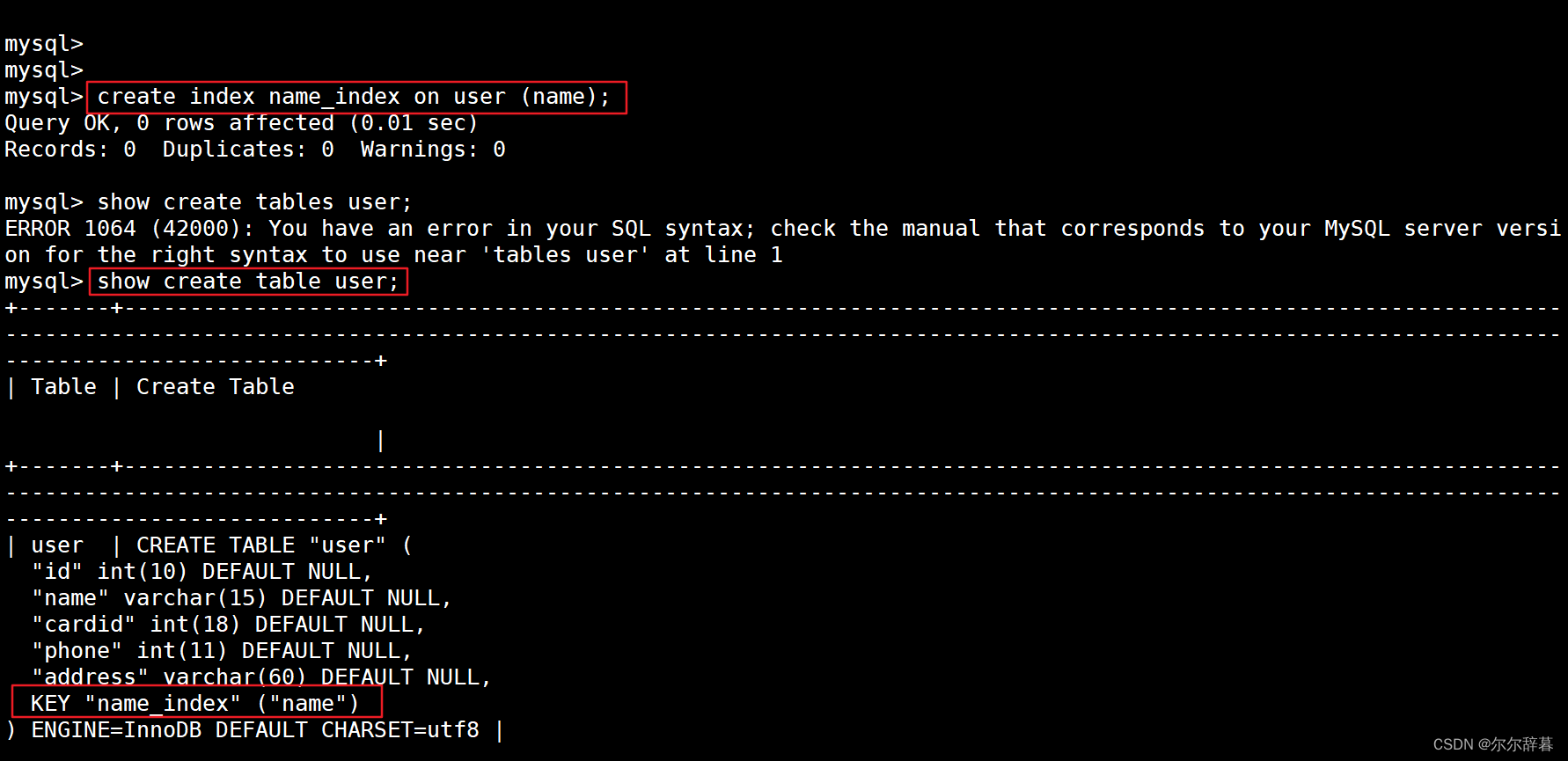
方式二:修改表方式创建
ALTER TABLE 表名 ADD INDEX 索引名 (字段名);
举例:对id创建普通索引
alter table user add index id_index(id);
查询:show create table user;
查看表结构:desc user;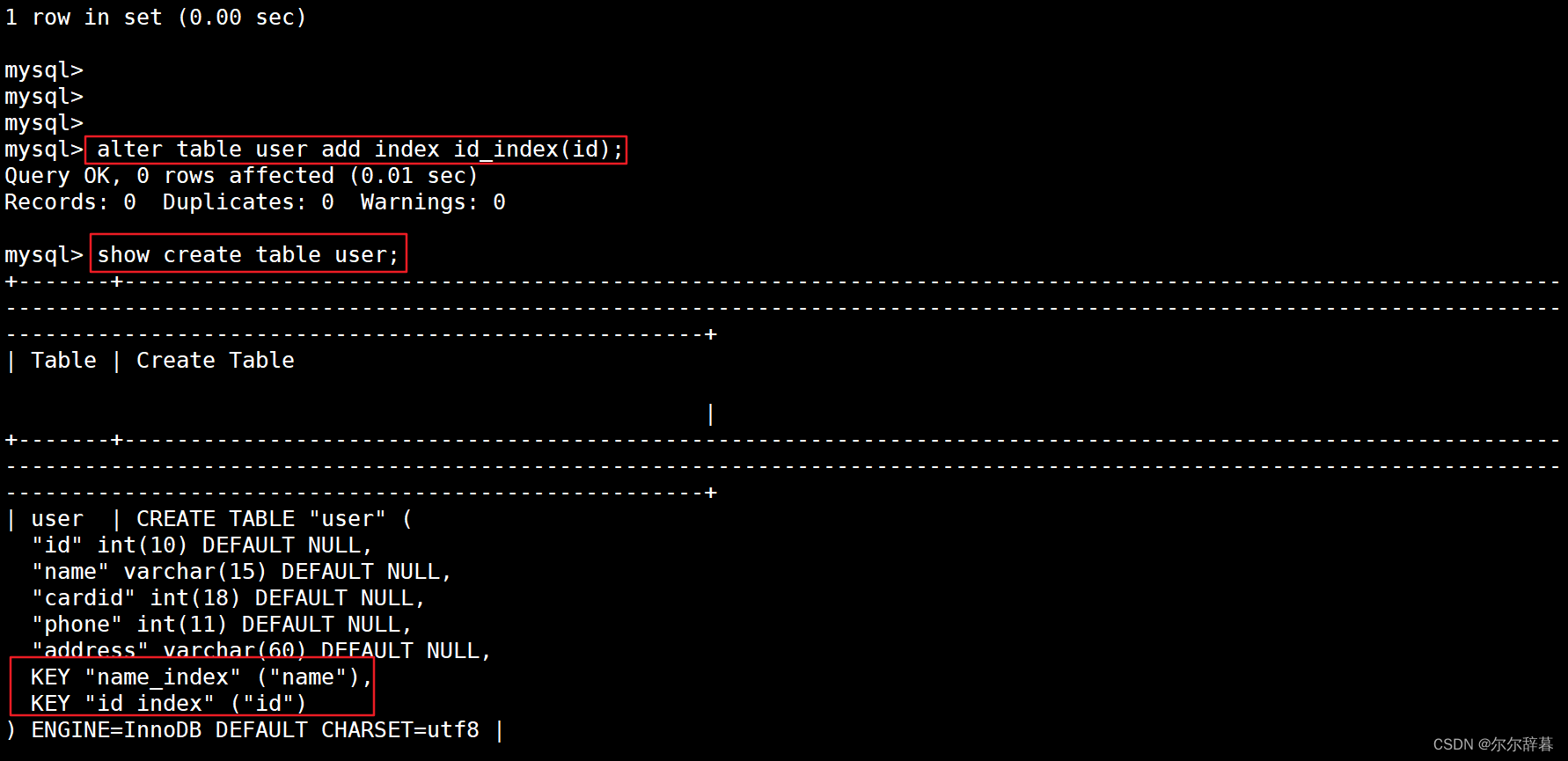
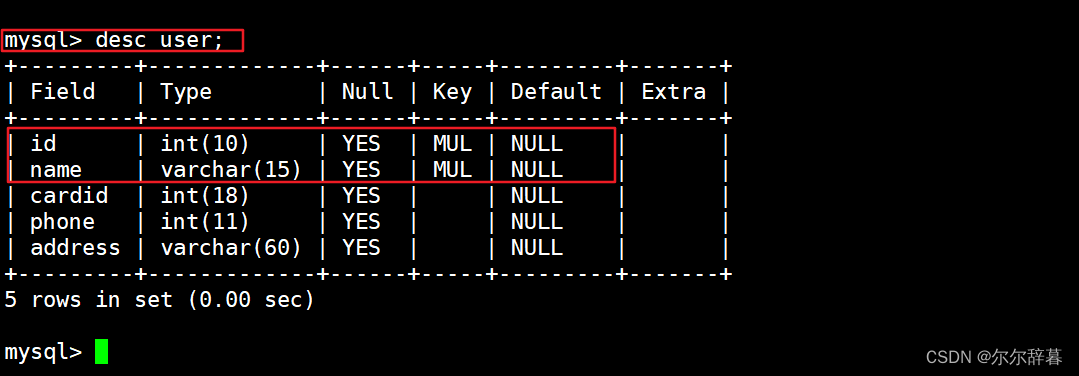
方式三:创建表的时候指定索引
CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型,...,INDEX 索引名 (字段名));
举例:将name创建普通索引
create table usertable (id int(10),name varchar(10),cardid int(18),phone int(11),address varchar(30),index name_index(name));
查询:show create table usertable;
desc usertable; #查看表结构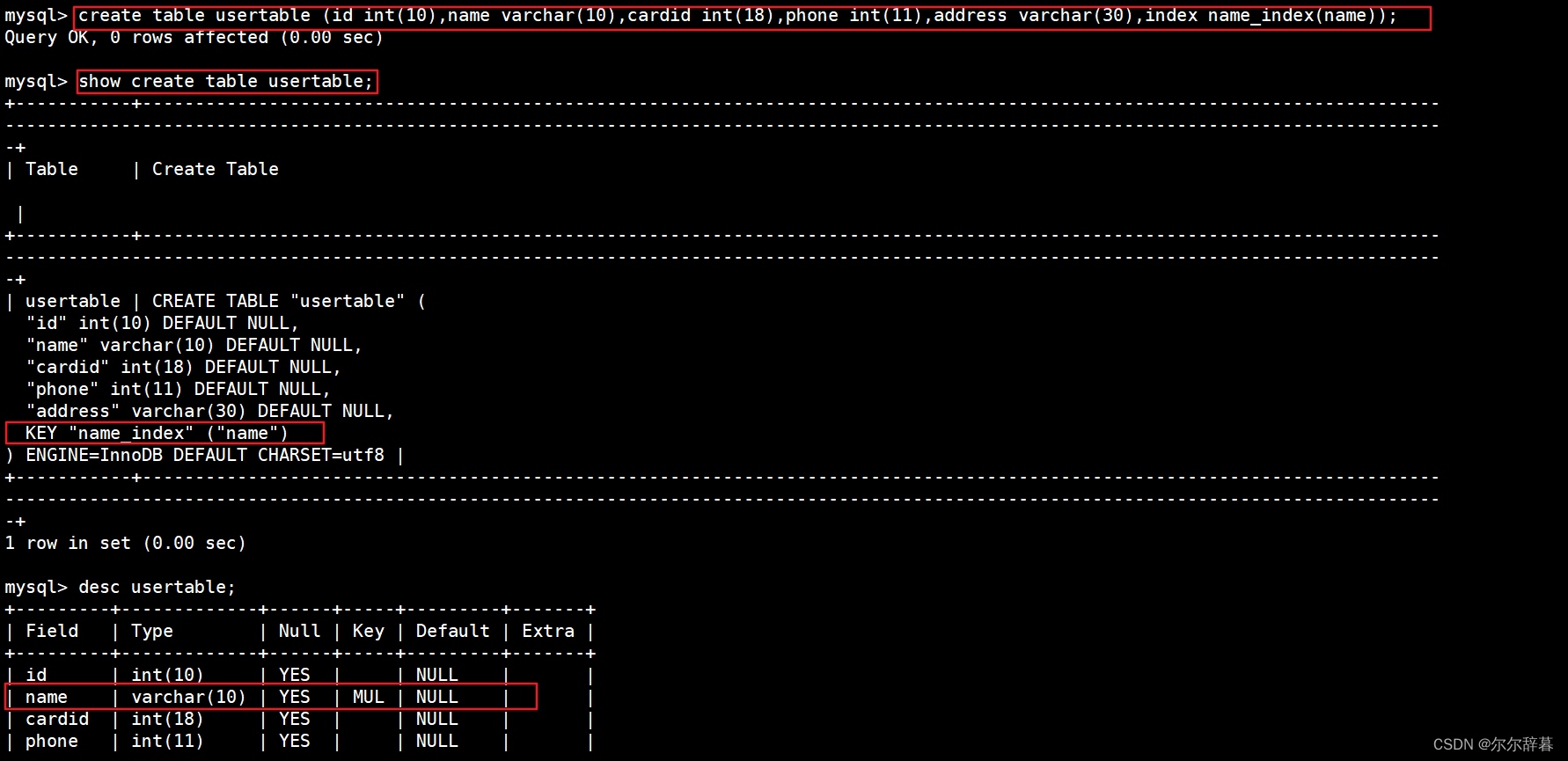
2.2 唯一索引
①与普通索引类似,但区别是唯一索引列的每个值都唯一。唯一索引允许有空值(注意和主键不同)。
②如果是用组合索引创建,则列值的组合必须唯一。添加唯一键将自动创建唯一索引。
总结:针对唯一字段,仅允许出现一次空值。
创建方式:
方式一:直接创建唯一索引:
CREATE UNIQUE INDEX 索引名 ON 表名(字段名);
举例:给cardid创建唯一索引
create unique index cardid_index on user(cardid);
查询:show create table user;
desc user; #查看表结构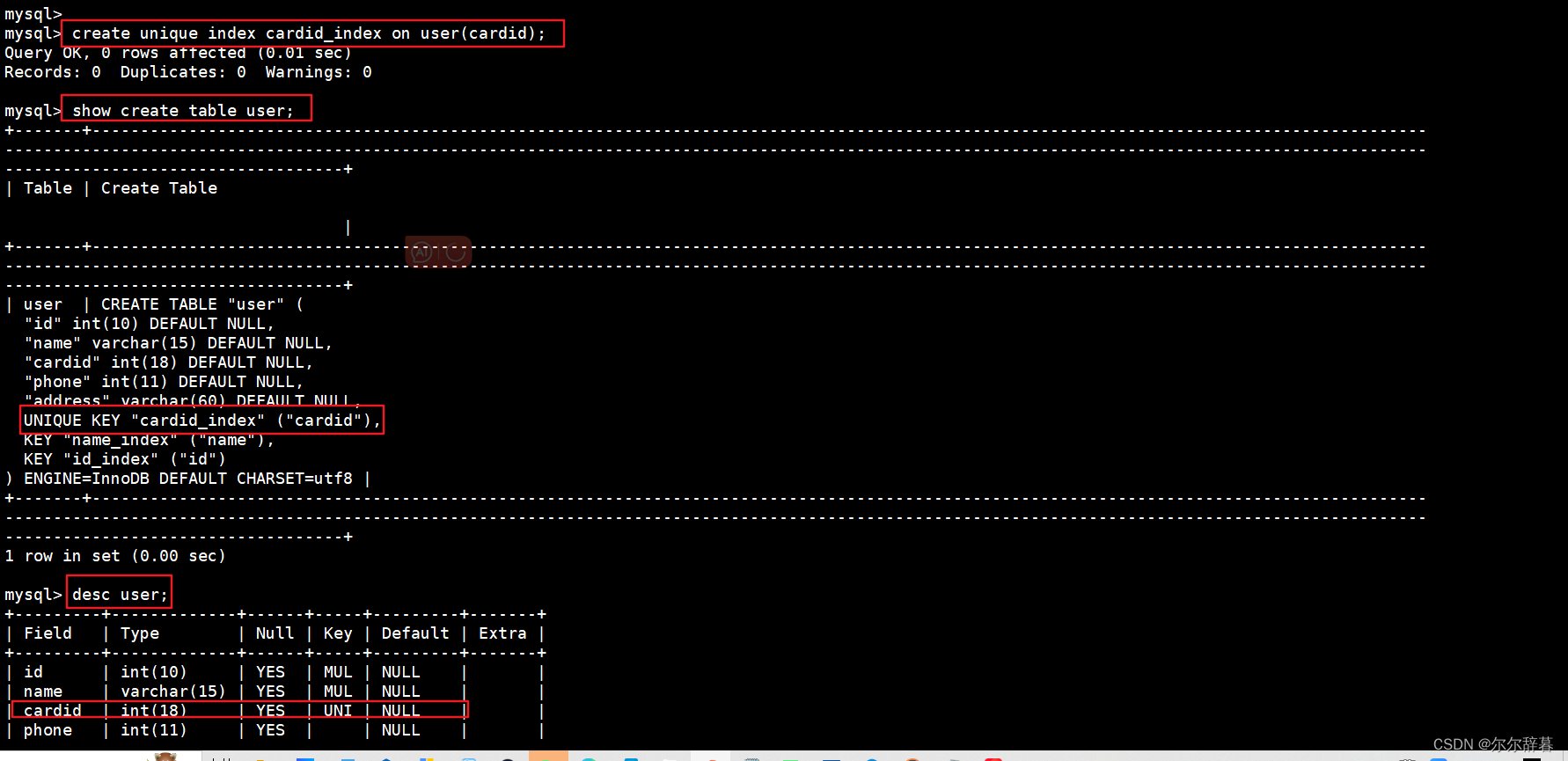
方式二: 修改表方式创建唯一索引:
ALTER TABLE 表名 ADD UNIQUE 索引名 (字段名);
举例:给phone创建唯一索引
alter table user add unique phone_index(phone);
查询:show create table user;
desc user; #查看表结构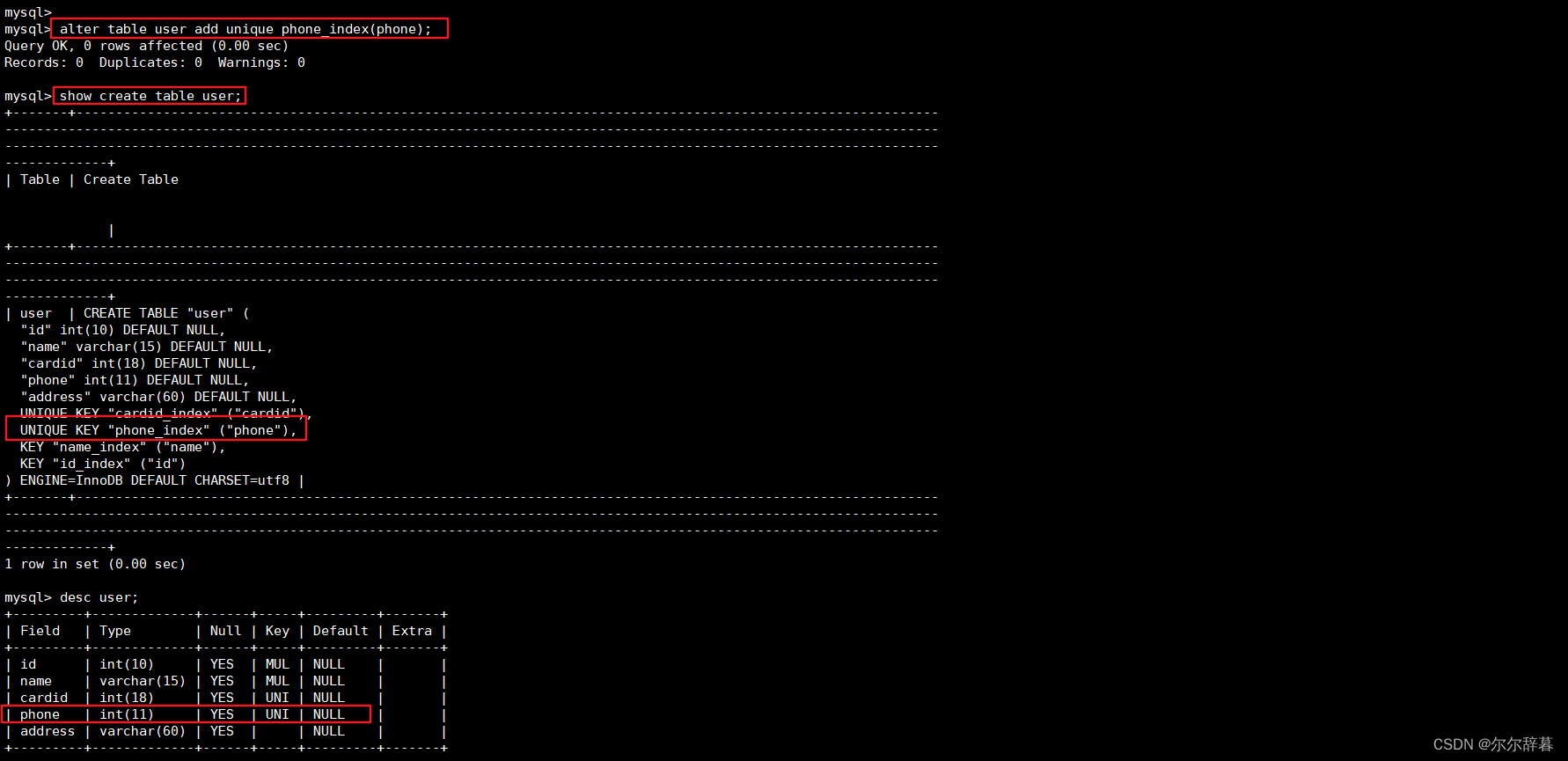
方式三:创建表的时候指定唯一索引
CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型,...,UNIQUE 索引名 (字段名));
举例:创建表时给id创建唯一索引
create table nametable (id int(10),name varchar(10),cardid int(18),phone int(11),address varchar(30),unique id_index(id));
查询:show create table nametable;
desc user; #查看表结构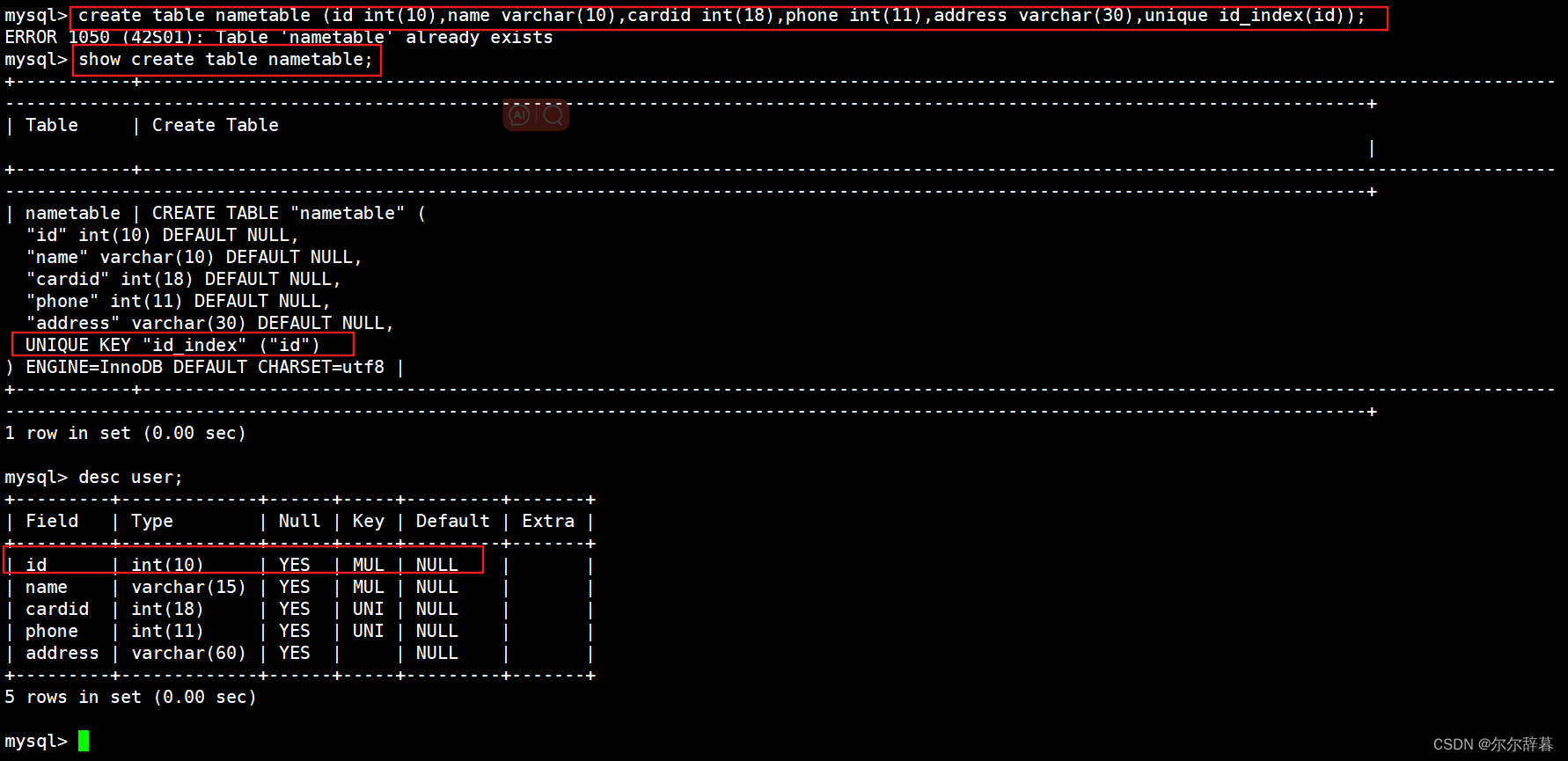
2.3 组合索引
①可以是单列上创建的索引,也可以是在多列上创建的索引。
②需要满足最左原则,因为 select 语句的 where 条件是依次从左往右执行的,
③所以在使用 select 语句查询时 where 条件使用的字段顺序必须和组合索引中的排序一致,否则索引将不会生效。
总结:多列/多字段组合形式的索引 查询时候按照排序的顺序查找 否则无效
创建方法:
方式一:直接创建组合索引
CREATE index 索引名 ON 表名 (字段1, 字段2, ...);
select 查询时 where 语句中的条件字段 要与组合索引的字段排列顺序一致(最左原则)
select * from 表名 where 字段名1='...' AND 字段名2='...' AND 字段名3='...';
举例:直接创建name,cardid,phone的组合索引
create index name_cardid_phone_index on user(name,cardid,phone);
查询:show create table user;
desc user; #查看表结构
查询是按顺序:select name cardid phone from 表名 (顺序不能乱,要按照组合顺序进行查询,否则将不生效)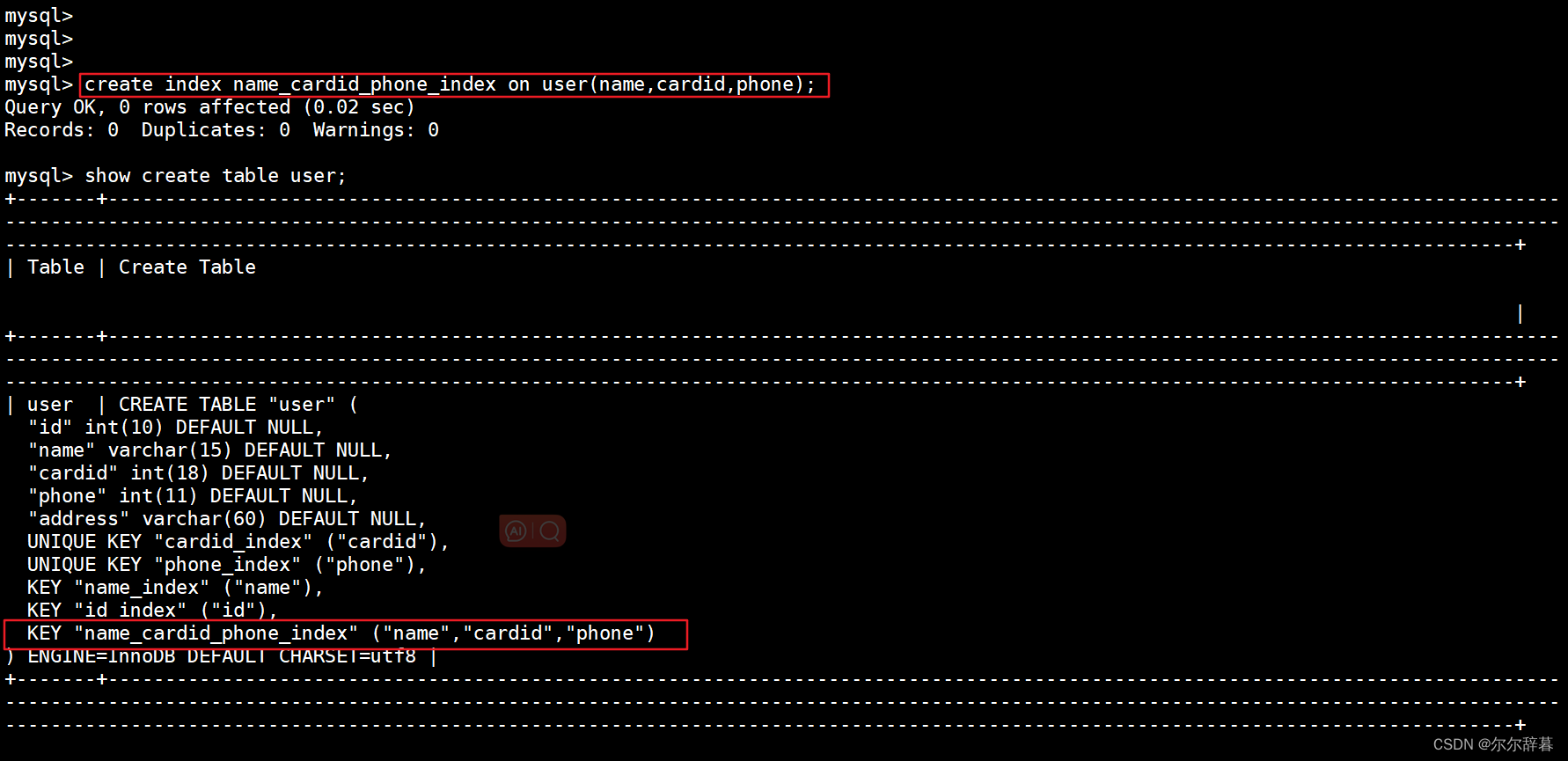
方式二:修改表方式创建组合索引:
alter table 表名 add index 索引名 (字段1,字段2,字段3,...);
举例:修改表的方式创建name,cardid,phone的组合索引
alter table user add index name_phone_cardid_index(name,phone,cardid);
查询:show create table user;
desc user; #查看表结构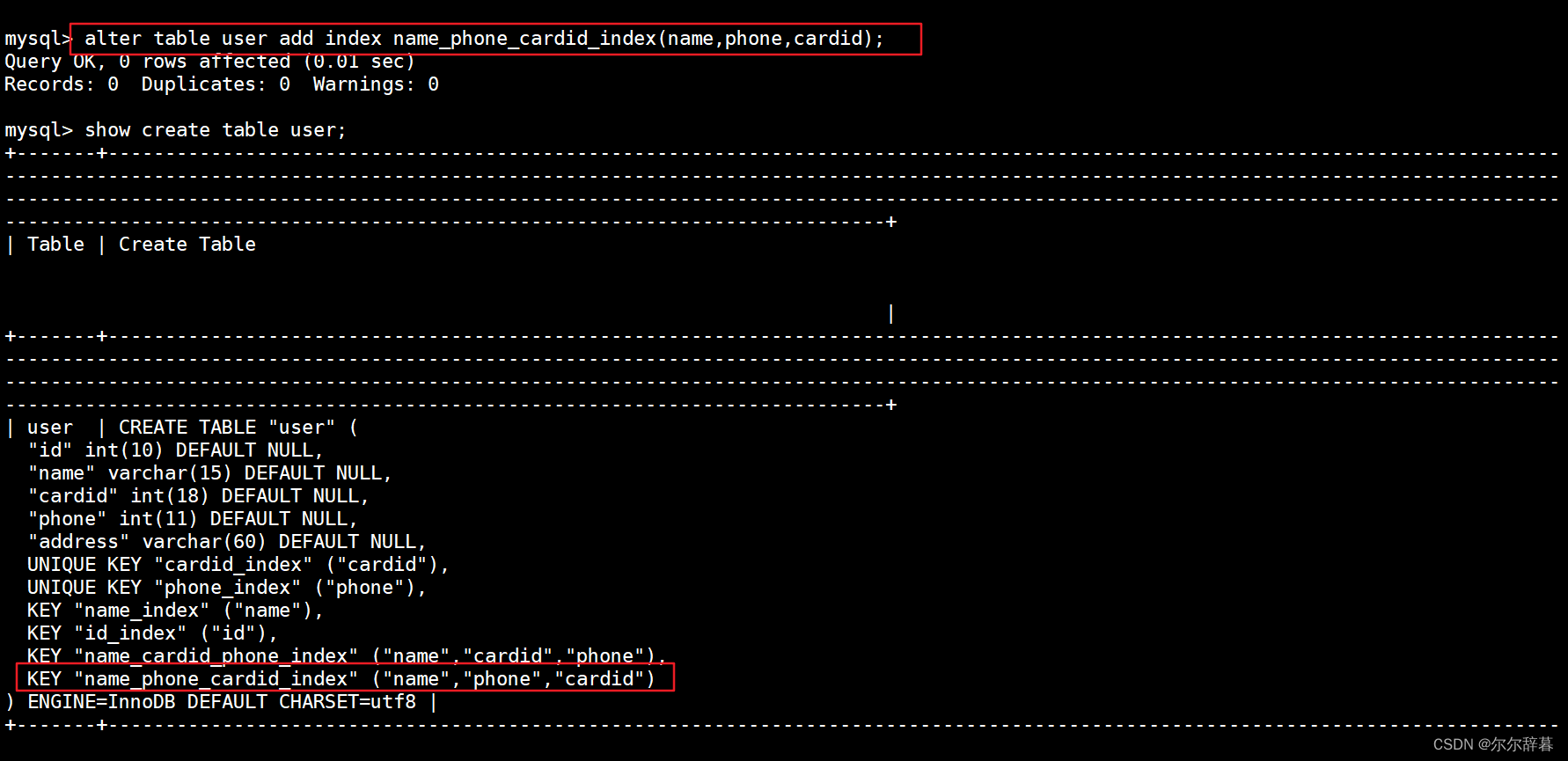
方式三: 创建表的时候指定组合索引
CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型,字段3 数据类型,INDEX 索引名 (字段1,字段2,字段3));
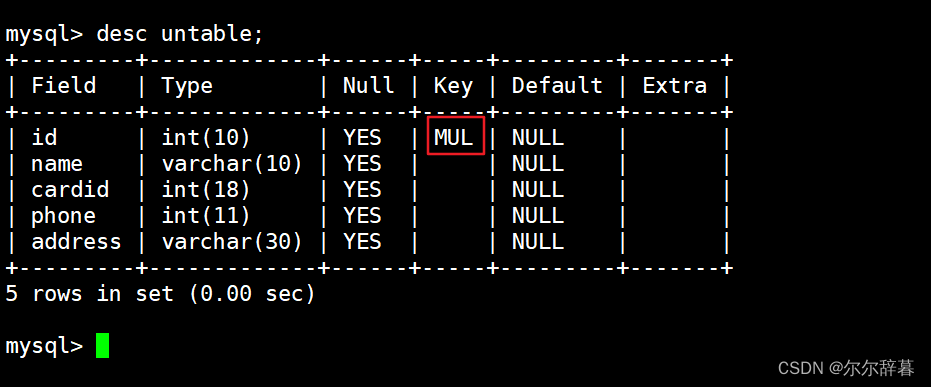
create table untable (id int(10),name varchar(10),cardid int(18),phone int(11),address varchar(30), index id_name_cardid_index(id,name,cardid));
查询:show create table untable;
desc untable; #查看表结构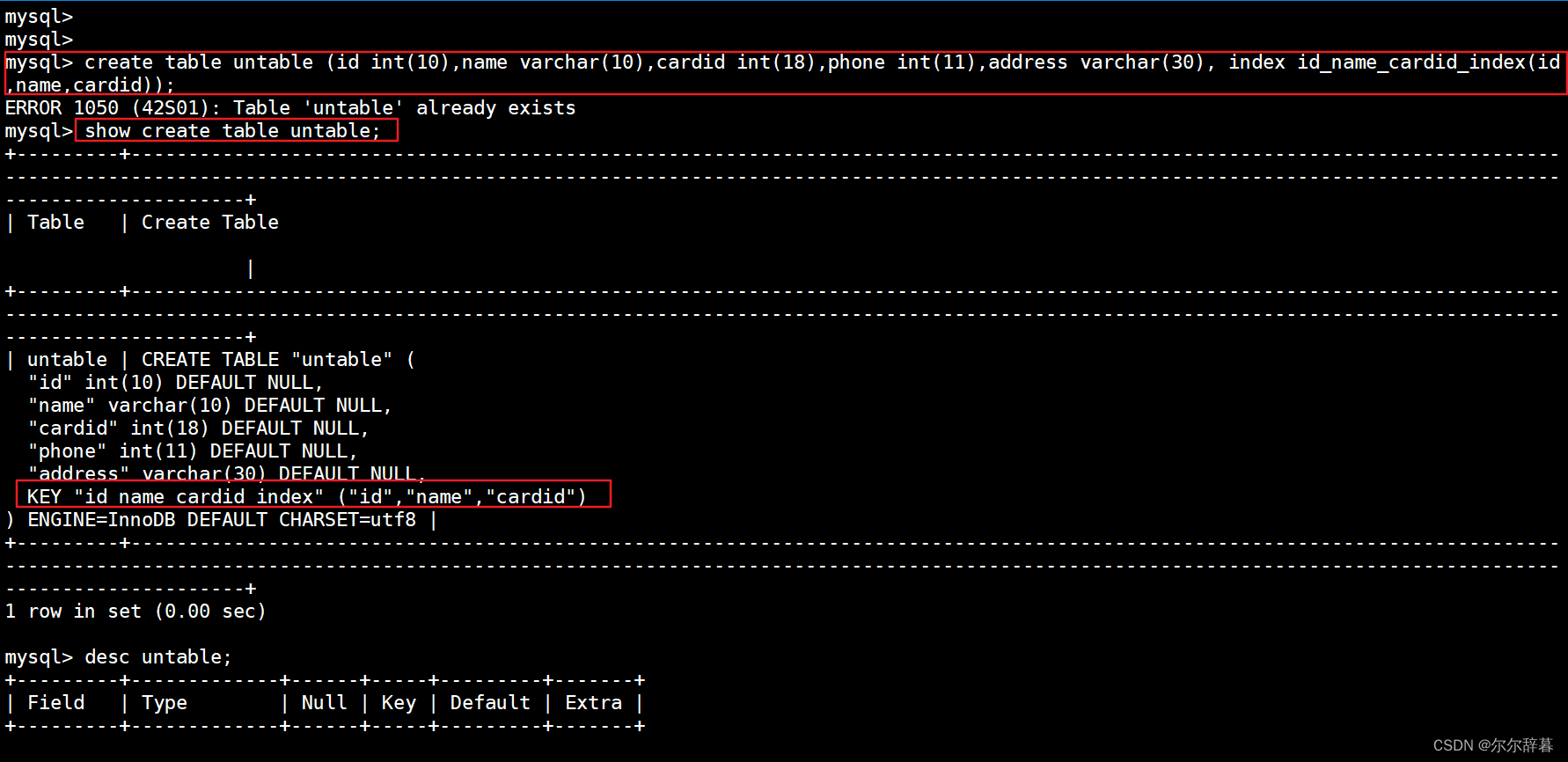
2.4 主键索引
是一种特殊的唯一索引,必须指定为“PRIMARY KEY”。一个表只能有一个主键,不允许有空值。 添加主键将自动创建主键索引。
总结:针对唯一字段,且不为空,同时一张表只允许包含一个主键索引。
创建表的时候指定:
CREATE TABLE 表名 (字段1 字段类型,字段2 字段类型,...,PRIMARY KEY (列名));
举例:给id创建主键索引
create table table1 (id int(10),name varchar(10),cardid int(18),phone int(11),address varchar(30),primary key(id));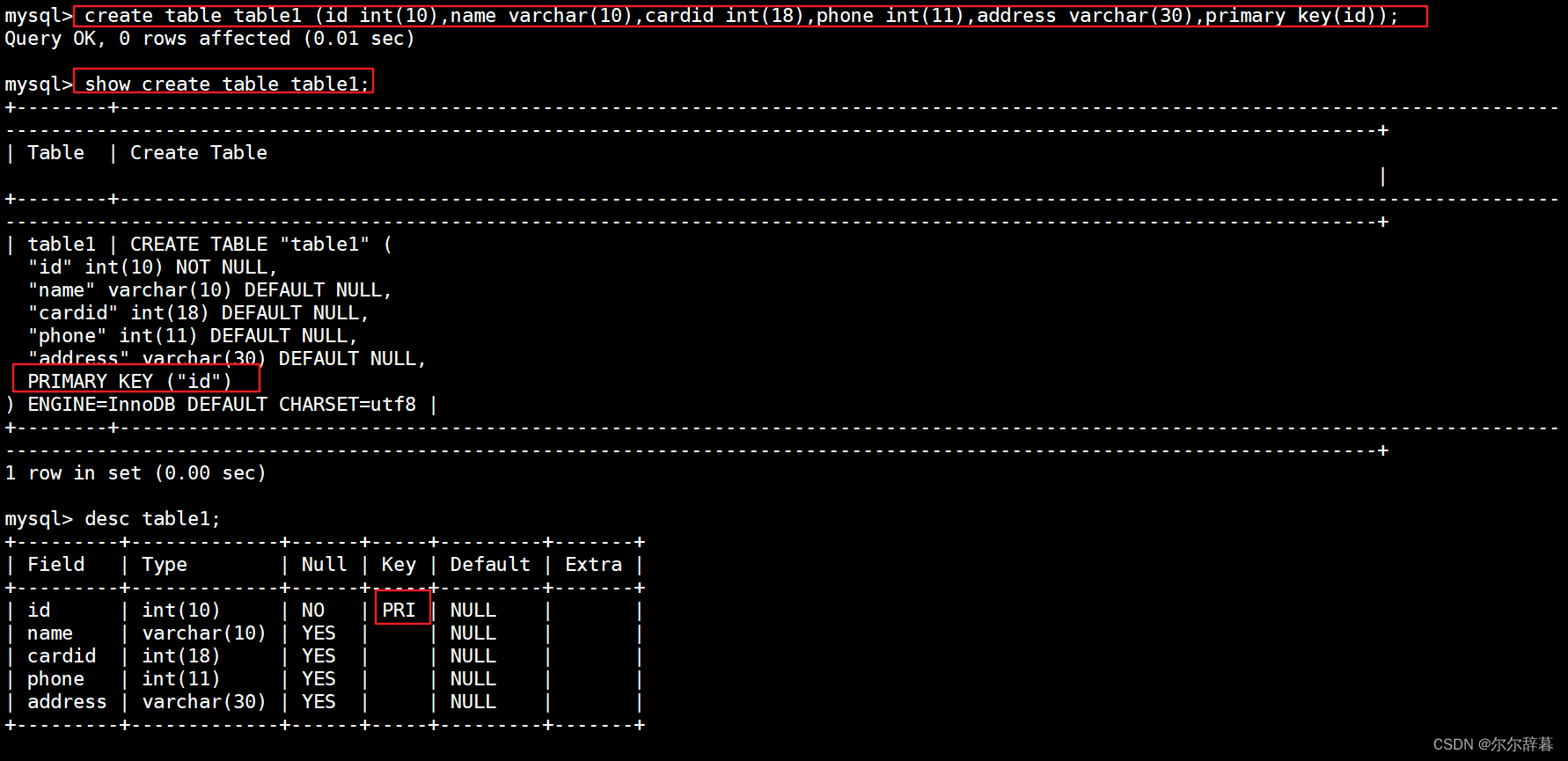
2.5 全文索引
①适合在进行模糊查询的时候使用,可用于在一篇文章中检索文本信息。在 MySQL5.6 版本以前
②FULLTEXT 索引仅可用于 MyISAM 引擎,在 5.6 版本之后 innodb 引擎也支持 FULLTEXT 索引。全文索引可以在 CHAR、③VARCHAR 或者 TEXT 类型的列上创建。
总结:以varchar char text blob clob 检索内部信息来做字段的索引。
创建方式:
方式一:直接创建索引:
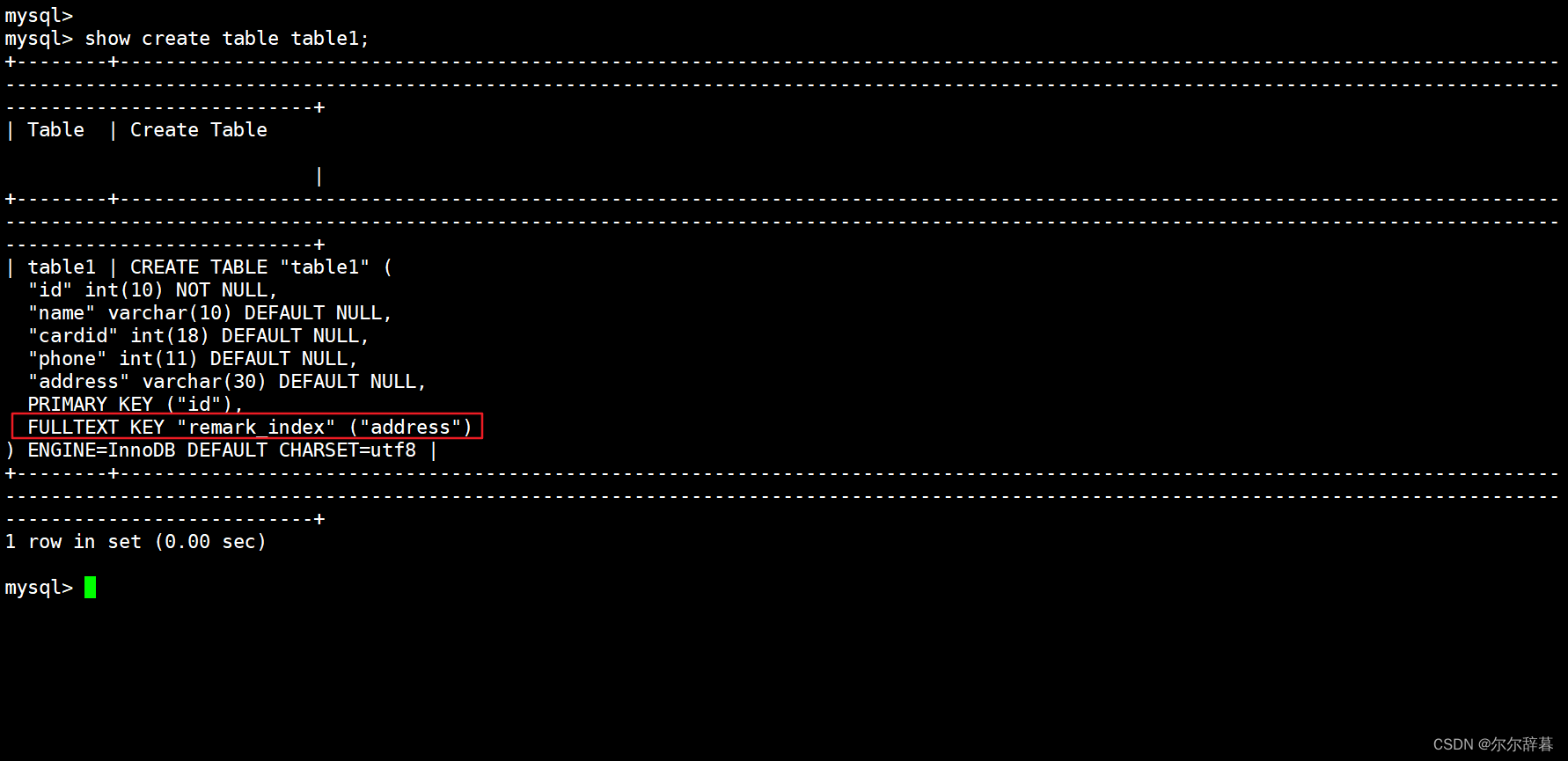
CREATE FULLTEXT INDEX 索引名 ON 表名 (列名);
举例:给remark直接创建全文索引
create fulltext index remark_index on table1(address);
查询:show create table untable;
desc untable; #查看表结构
方式二:修改表方式创建
alter table 表名 add fulltext 索引名(字段名);
举例:给remark修改表方式创建全文索引:
alter table table1 add fulltext remark_index(remark);
查询:show create table untable;
desc untable; #查看表结构方式三:创建表的时候创建
CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型...,FULLTEXT 索引名 (列名));
#数据类型可以为 CHAR、VARCHAR 或者 TEXT
查询:show create table untable;
desc untable; #查看表结构
2.6 查看索引的方法
方式一:show create table 表名;
方式二:show index from 表名;
方式三:show keys from 表名;
#以上三种方式可以与\G联合使用
各字段的含义如下:
Table:表的名称。
Non_unique:如果索引不能包括重复词,则为 0;如果可以,则为 1。
Key_name:索引的名称。
Seq_in_index:索引中的列序号,从 1 开始。
Column_name:列名称。
Collation:列以什么方式存储在索引中。在 MySQL 中,有值‘A’(升序)或 NULL(无分类)。
Cardinality:索引中唯一值数目的估计值。
Sub_part:如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为 NULL。
Packed:指示关键字如何被压缩。如果没有被压缩,则为 NULL。
Null:如果列含有 NULL,则含有 YES。如果没有,则该列含有 NO。
Index_type:用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
Comment:备注
2.7 删除索引的方法
方法一:直接删除索引
drop index 索引名 on 表名;方法二:修改表的方式删除索引
ALTER TABLE 表名 DROP INDEX 索引名;删除主键索引
ALTER TABLE 表名 DROP PRIMARY KEY;