案例背景
真的很容易疯....上班的单位的表格都是不同的人做的,所以就会出现各种合并单元格的情况,要知道我们用pandas读取数据最怕合并单元格了,因为没规律...可能前几列没合并,后面几列又合并了....而且pandas对于索引很严格,这种合并单元读取进来就是空的,还怎么查找数据......例如:

还有这种: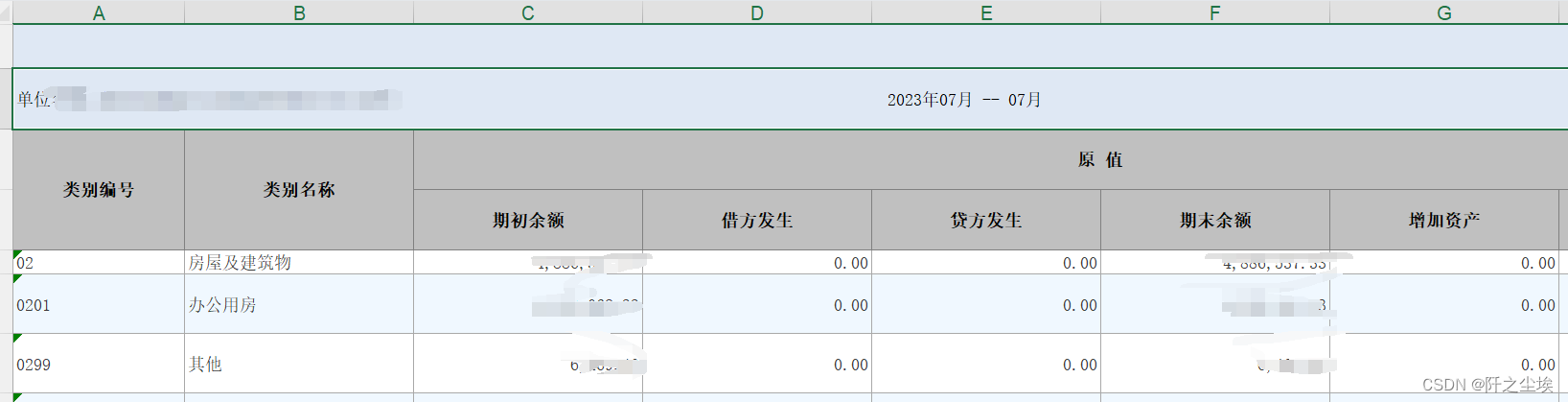
读取的时候....真的很无语。虽然手工做的表头方便人看,但真的不方便代码来取数。
下面我们来看看怎么自动化读取这种多合并表格的数据,并规范表头。就用这个资产的样例
代码实现
读取数据,前2行都是标题没用跳过,然后header=0,1表示2行作为多层索引。
name='资产类别统计表2023.7.xlsx'
df=pd.read_excel(f'{name}',skiprows=2,header=[0,1],converters={'类别编号': str})
df.head(3)
可以看到有‘unnamed’这种合并单元出现的空值的情况。
我们可以打印查看一下行索引名称:
df.columns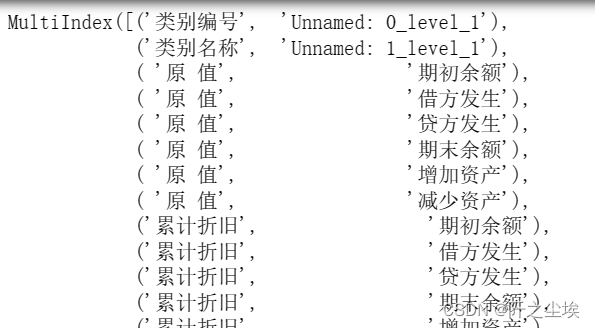
像这种只有部分下面缺失的,可以直接用上面的第一层索引填充第二层索引,让它还是两层索引,然后继续做多层索引数据框。
cols = df.columns.map(lambda x: [x[0]if 'Unnamed' in i else i for i in x])
multi_cols = pd.MultiIndex.from_arrays([list(col) for col in zip(*cols)])
df.columns=multi_cols
df.head(2)
这样就是处理好, 然后按照多层索引的方法去进行取数。
若多层索引不熟悉,只想变成正常 的二维数据框,那么就这样:
cols = df.columns.map(lambda x: ''.join('' if 'Unnamed' in i else i for i in x))
cols
把第一层和第二层的名称都进行合并,然后赋值:
df.columns=cols
df.head(2)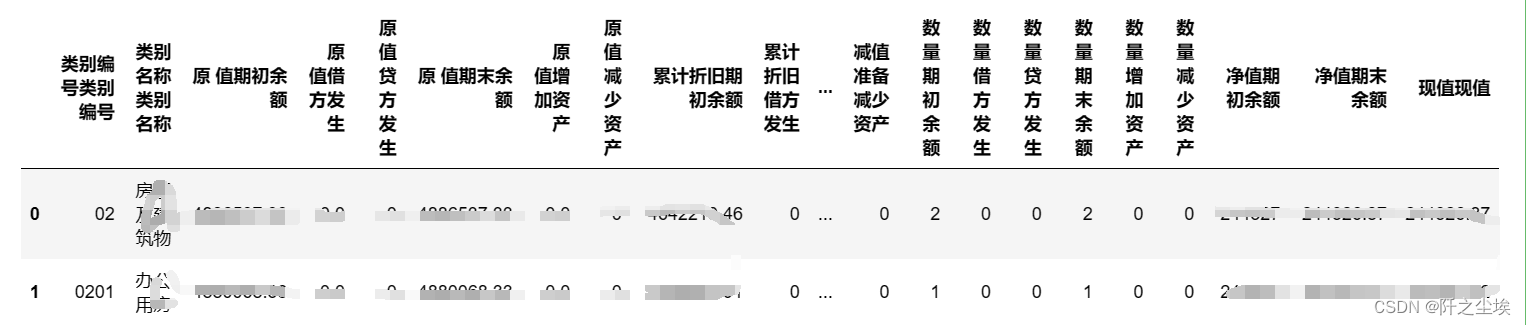
这样就变成了单层数据框,完成!
后面就正常的pandas索引进行取数修改筛选计算等工作了。