保证redis都是热点数据
假说说1000w条数据,redis只能存20w
我们这时候就用拒绝策略去保证存的都是热点数据
我们先来看一下几种拒绝策略
检测易失数据(可能会过期的数据集server.db[i].expires )
① volatile-lru:挑选最近最少使用的数据淘汰
② volatile-lfu:挑选最近使用次数最少的数据淘汰
③ volatile-ttl:挑选将要过期的数据淘汰
④ volatile-random:任意选择数据淘汰
检测全库数据(所有数据集server.db[i].dict )
⑤ allkeys-lru:挑选最近最少使用的数据淘汰
⑥ allkeys-lfu:挑选最近使用次数最少的数据淘汰
⑦ allkeys-random:任意选择数据淘汰
应用:
数据库中有1000w的数据,而redis中只有30w数据,如何保证redis中数据都是热点数据?
解决:
限定 Redis 占用的内存,Redis 会根据自身数据淘汰策略,留下热数据到内存。所以,计算一下 30W 数据大约占用的内存,然后设置一下 Redis 内存限制即可,并将淘汰策略为volatile-lru或者allkeys-lru。
设置Redis最大占用内存:
打开redis配置文件,设置maxmemory参数,maxmemory是bytes字节类型
热点key怎么处理

原因大概有两种
1、⽤户消费的数据远⼤于⽣产的数据(热卖商品、热点新闻、热点评论、明星直播)。 在⽇常⼯作⽣活中⼀些突发的的事件,例如:双⼗⼀期间某些热门商品的降价促销,当这其中的某 ⼀件商品被数万次点击浏览或者购买时,会形成⼀个较⼤的需求量,这种情况下就会造成热点问 题。 同理,被⼤量刊发、浏览的热点新闻、热点评论、明星直播等,这些典型的读多写少的场景也会产 ⽣热点问题。
2、请求分⽚集中,超过单 Server 的性能极限。 在服务端读数据进⾏访问时,往往会对数据进⾏分⽚切分,此过程中会在某⼀主机 Server 上对相应 的 Key 进⾏访问,当访问超过 Server 极限时,就会导致热点 Key 问题的产⽣。
危害
- 流量集中
- 容易造成雪崩
- 请求过多,缓存分⽚服务被打垮。
解决
方案一
当服务器阻塞的时候就直接返回,不让他去访问db,而不忙的时候在访问db,然后将数据写入服务器端的本地缓存(这里用一下阿里云社区的图)。把这里想想成双十一抢购,随机抽取几个幸运星,让他访问数据库,而其他的都不让他访问
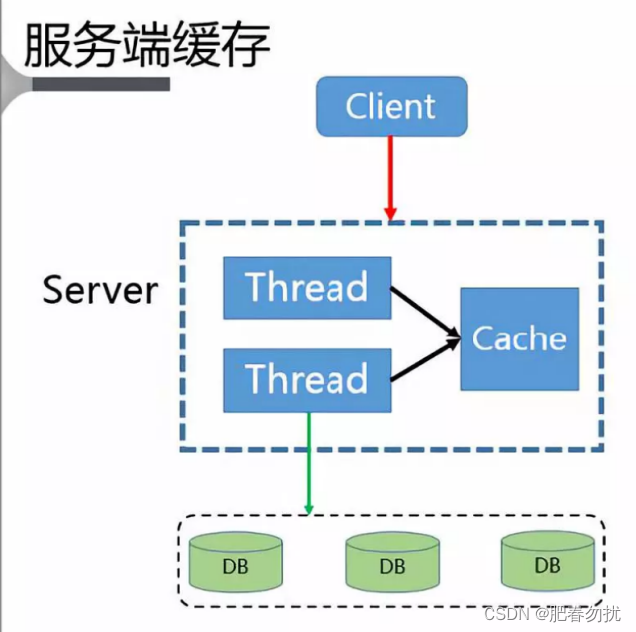
问题:1、缓存失效,多线程构建缓存问题 2、缓存丢失,缓存构建问题 3、脏读问题
方案二
使用 Memcache、Redis 方案
⽅案通过在客户端单独部署缓存的⽅式来解决热点 Key 问题。
就是客户端先对服务器访问,在对同一主机上的缓存进行访问
快,但是浪费资源。
方案三
使用客户端本地缓存
以上传统的方法都有些毛病
读写分离方案解决热读
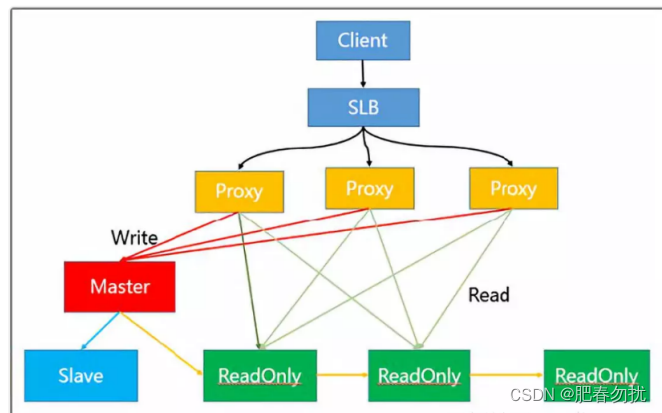
借助阿里这副图奴就会轻松理解
热点数据解决方案
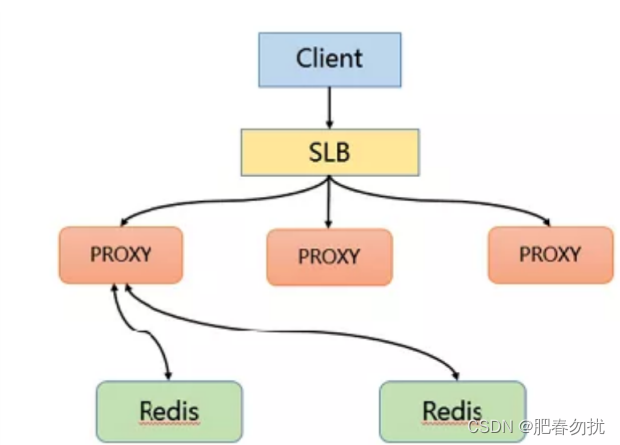
通过主动发现热点并对其进⾏存储来解决热点 Key 的问题
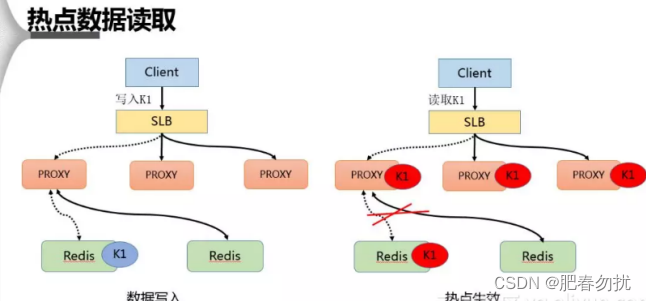
在热点 Key 的处理上主要分为写⼊跟读取两种形式,在数据写⼊过程当 SLB 收到数据 K1 并将其通 过某⼀个 Proxy 写⼊⼀个 Redis,完成数据的写⼊。 假若经过后端热点模块计算发现 K1 成为热点 key 后, Proxy 会将该热点进⾏缓存,当下次客户端 再进⾏访问 K1 时,可以不经 Redis。
最后由于 proxy 是可以⽔平扩充的,因此可以任意增强热点数据的访问能⼒。
热点数据是怎么计算出来的呢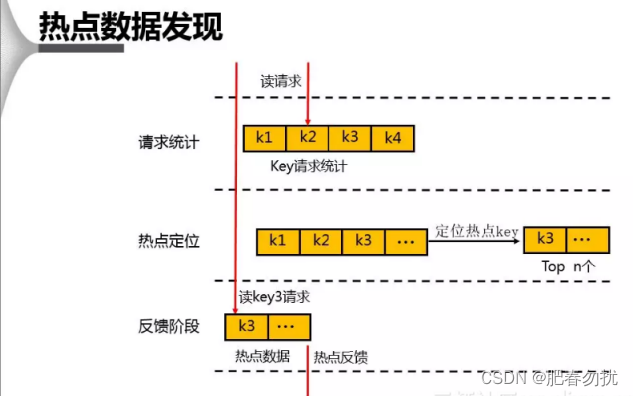
对于 db 上热点数据的发现,⾸先会在⼀个周期内对 Key 进⾏请求统计,在达到请求量级后会对热 点 Key 进⾏热点定位,并将所有的热点 Key 放⼊⼀个⼩的 LRU 链表内,在通过 Proxy 请求进⾏访 问时,若 Redis 发现待访点是⼀个热点,就会进⼊⼀个反馈阶段,同时对该数据进⾏标记
有过热的key怎么办
有过热的key怎么办?比如说有那么光几个key访问量就超几十万。
主要在于事前预测和事中解决,比如我们预测一下鹿晗是微博热搜
事中解决方面,主要可以考虑:热点key的拆分、多级缓存、热key备份、限流等方案来解决。
一般来说,如果一个key在1秒内被访问次数达到上千次,就可以认为是热key了