文章目录
CodeWhisperer简介
CodeWhisperer是一款由亚马逊开发的基于机器学习的通用代码生成器。它能够实时提供代码建议,帮助我们在编写代码时提供自动化的建议。通过分析我们现有的代码和注释,它可以生成各种大小和范围的个性化建议,从单行代码建议到完整的函数。此外,CodeWhisperer还可以扫描我们的代码,以便突出显示和定义安全问题。
目前,CodeWhisperer可以免费使用,没有任何限制。它支持15种编程语言,包括Python、Java和JavaScript,同时也可以与多个集成式开发环境(IDE)进行集成,例如VS Code、IntelliJ IDEA、AWS Cloud9、AWS Lambda 控制台、JupyterLab和Amazon SageMaker Studio。

经过数十亿行代码的训练,CodeWhisperer能够根据您的评论和现有代码实时生成代码片段到完整函数的建议。借助它,我们可以避免耗时的编码任务,加速使用不熟悉的API进行构建工作。
为了增强代码的安全性,CodeWhisperer提供了代码扫描功能,可以检测难以发现的漏洞,并提供相应的代码建议以立即修复这些漏洞。它遵循跟踪安全漏洞的最佳实践,比如开放全球应用程序安全项目(OWASP)描述的漏洞,以及与加密库最佳实践和其他类似安全最佳实践不符的漏洞。
通过使用CodeWhisperer的代码扫描功能,您可以及时发现和解决潜在的安全问题,确保代码的健壮性和可靠性。它可以帮助您避免常见的安全漏洞,并根据最佳实践提供针对性的建议,以确保代码在安全方面符合行业标准。这样,您可以更加放心地开发和部署代码,减少潜在的安全风险。

安装CodeWhisperer
PyCharm安装
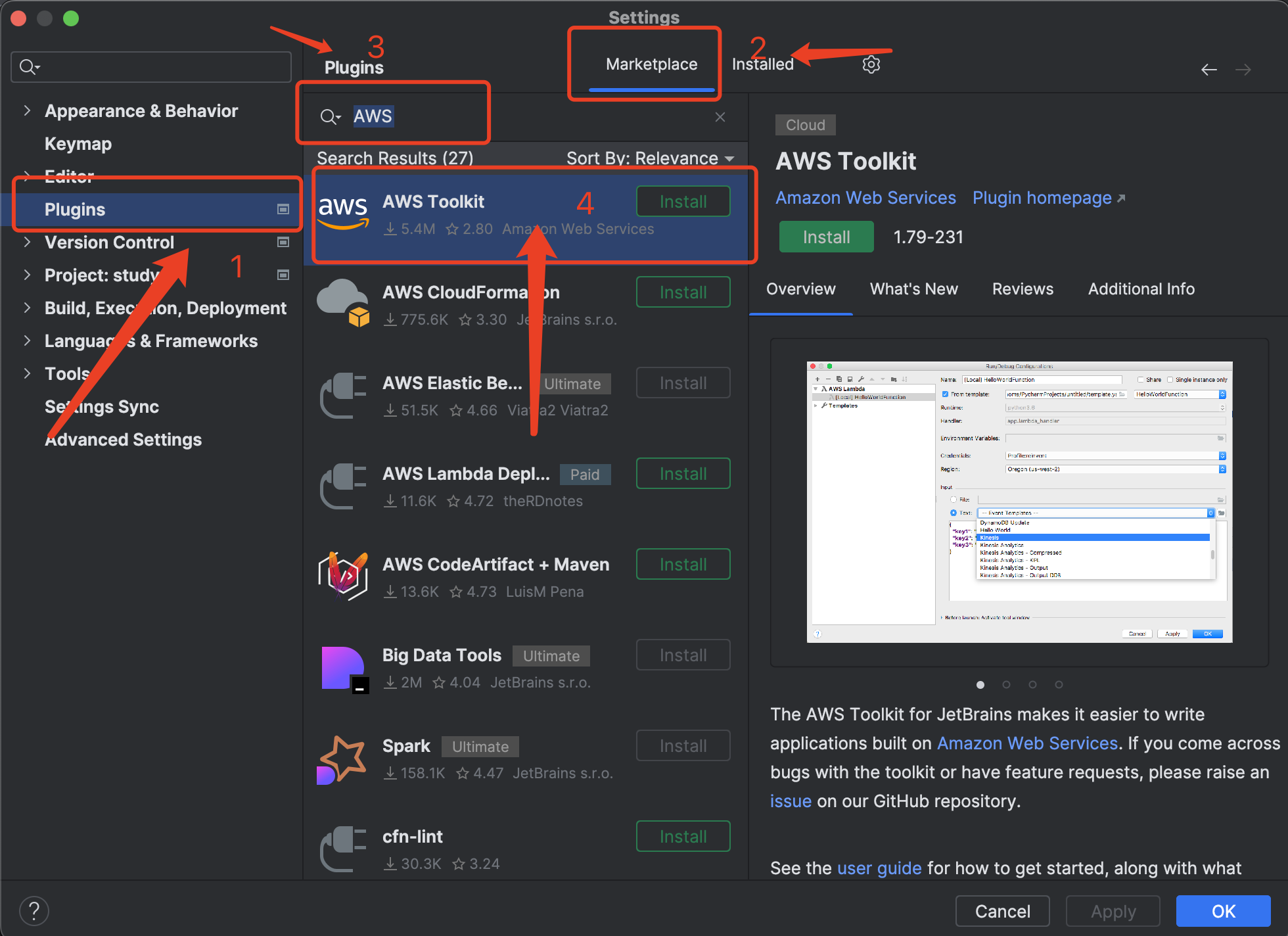
- 打开Pycharm插件管理
在JetBrains IDE中, 导航到设置菜单(在macOS 上快捷键是 command + , 在window上为 文件 => 设置), 然后单机左侧菜单上的"插件".
在菜单顶部, 单机Marketplace并在搜索栏中输入 AWS . 然后点击install**安装 **
安装成功之后需要重启 IDEA , 如下图:
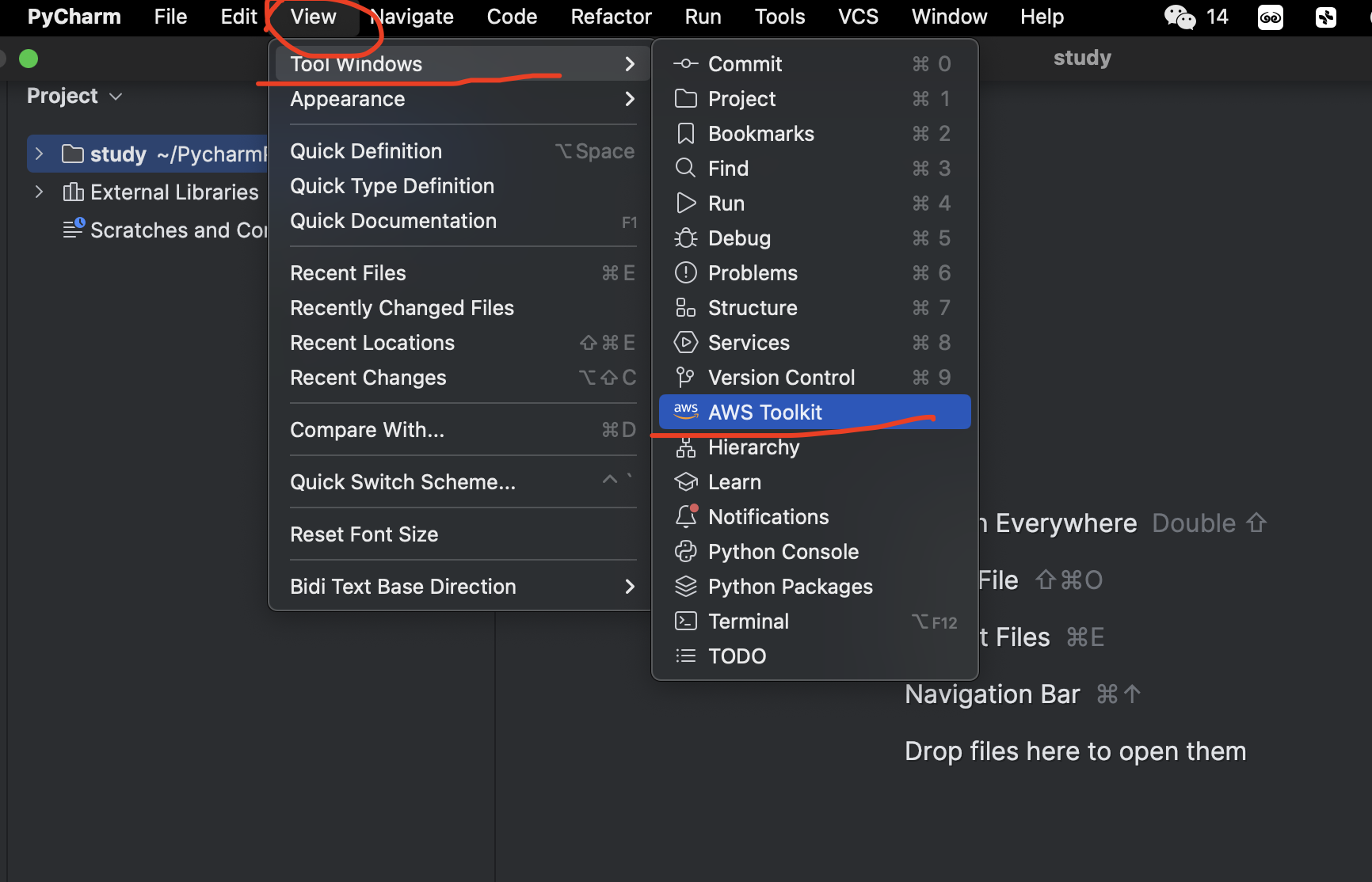
打开AWS Tookit视图(菜单View=> Tool windows => AWS Tookit), 如下图一所示
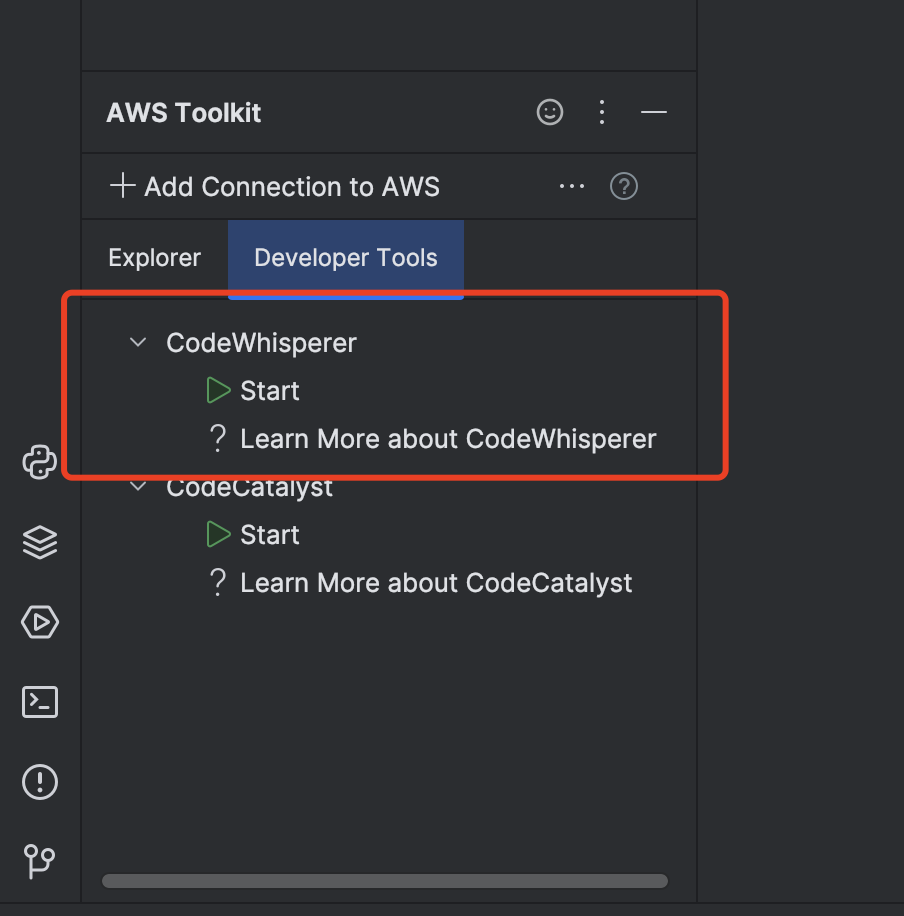
点击 Developer Tools tab 页面,选择CodeWhisperer/Start , 如下 图二所示.
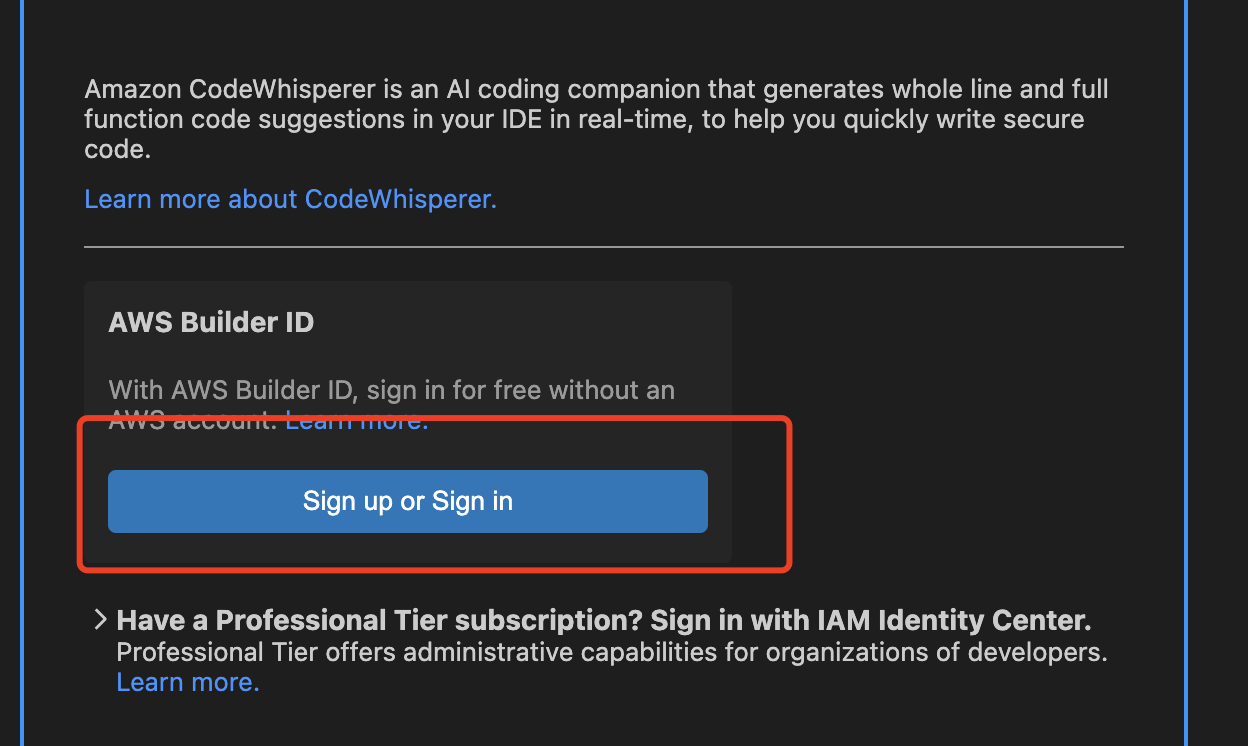
点击Start,在弹出的窗口中选择 Use a personal email to sign up and sign in with AWS Builder ID , 点击Connect按钮, 如下图所示:

在弹出的窗口中,选择Open and Copy Code, 如下图:
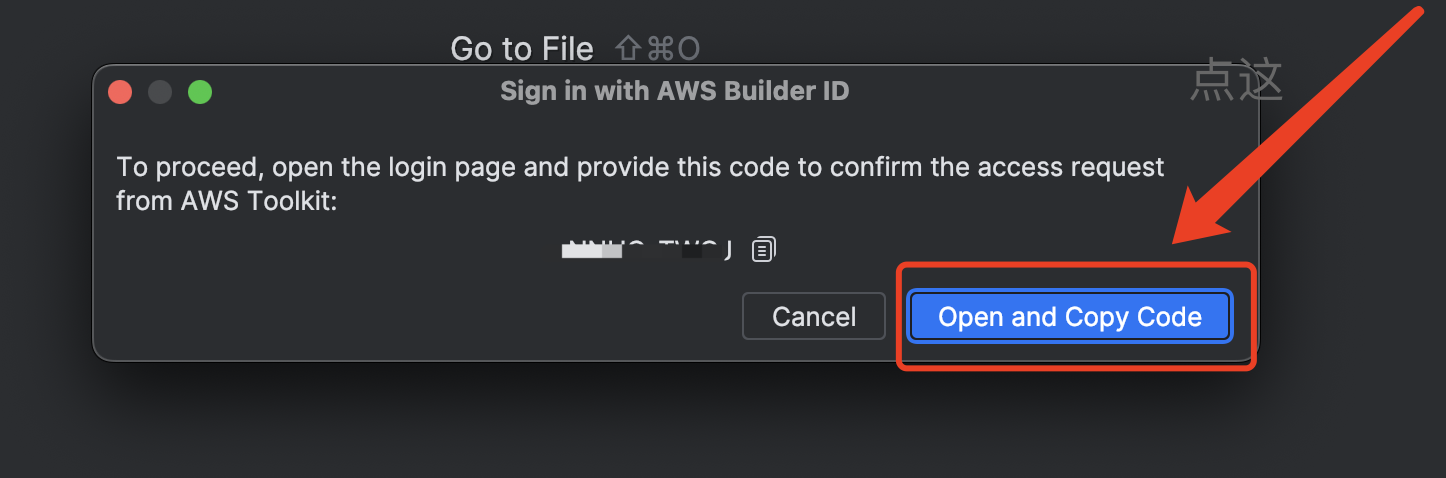
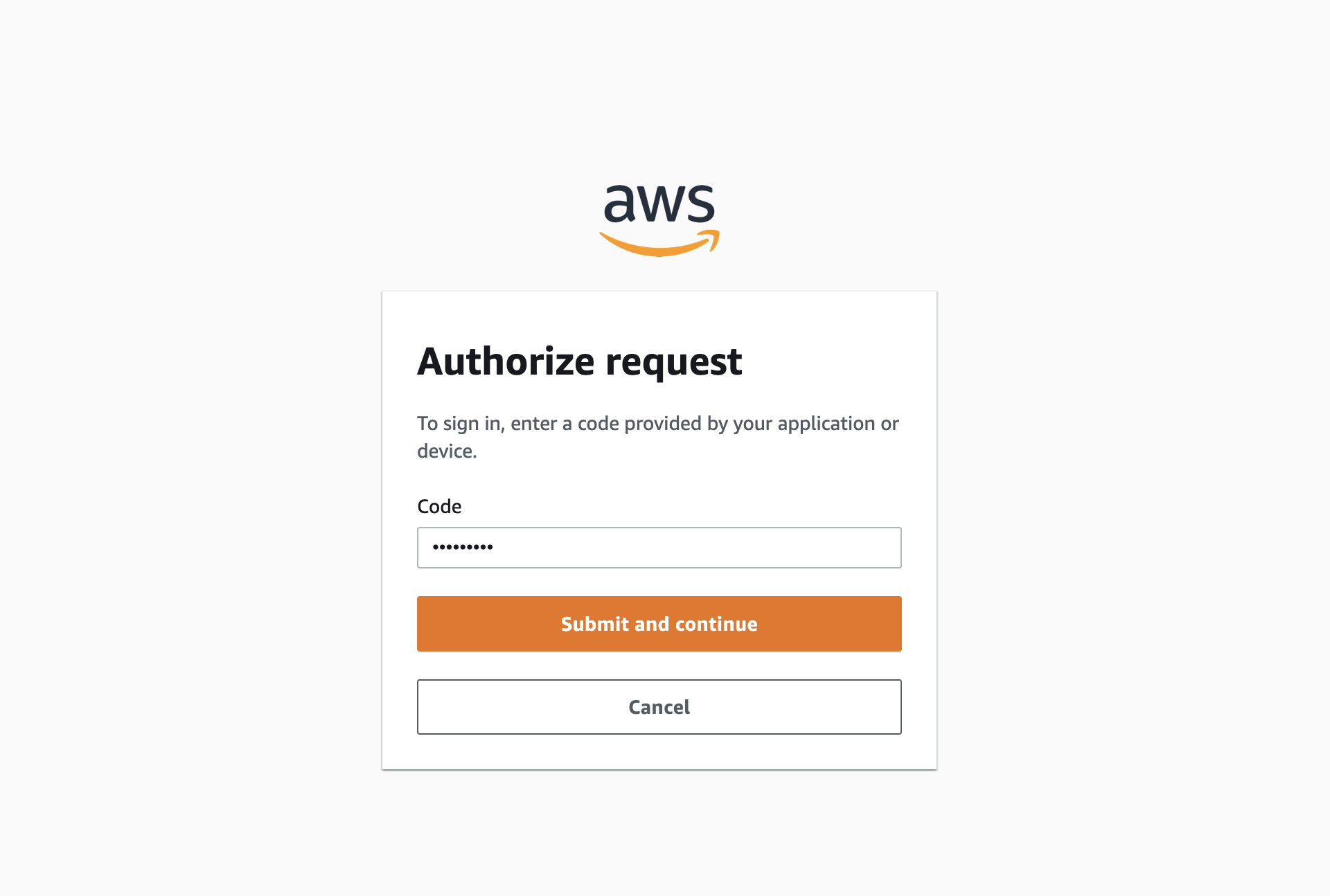
点击之后会在浏览器中打开一个页面, 在页面中粘贴 上面弹窗中打码的值, 点击
Submit and continue, 如下图:
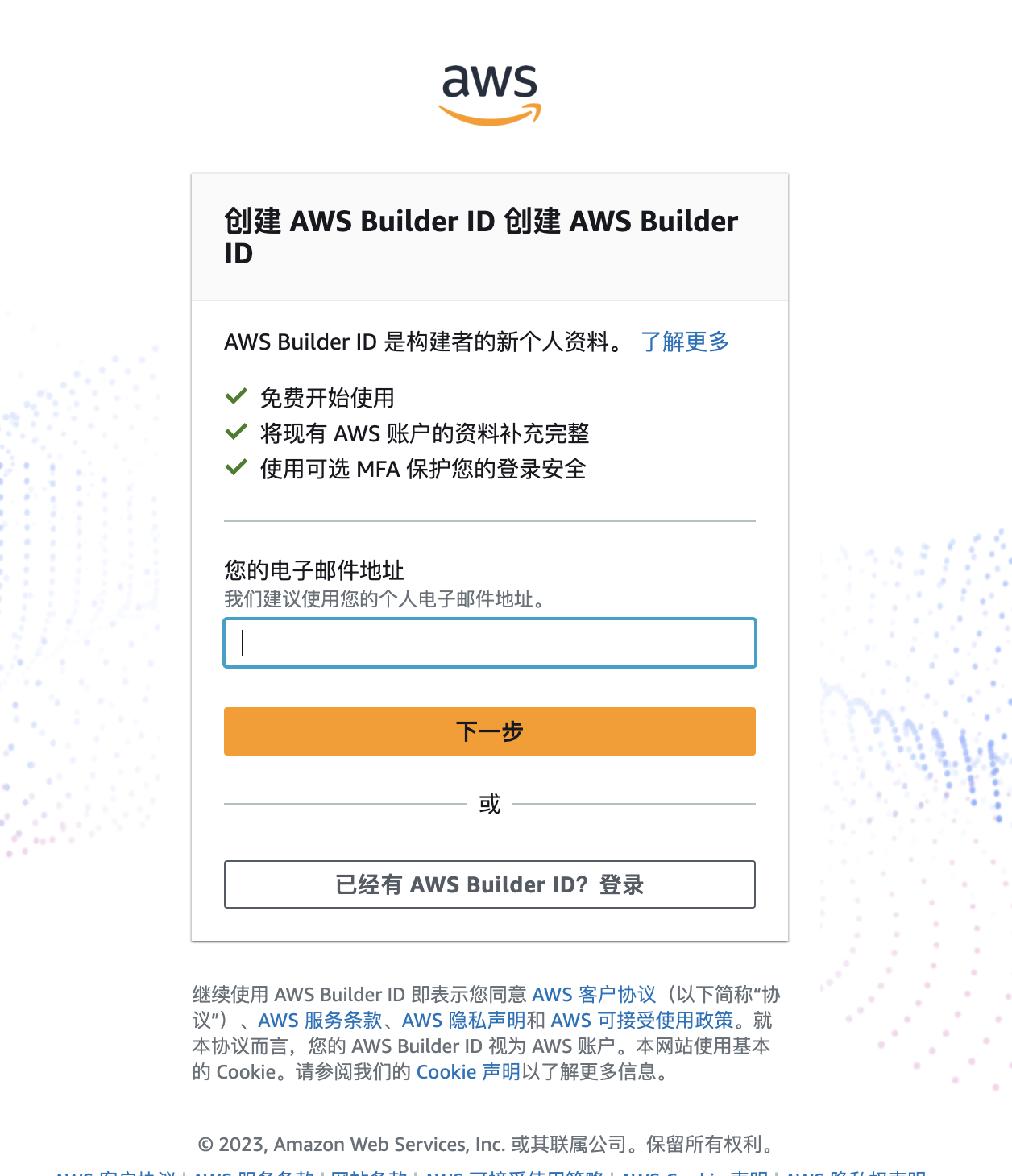
输入个人邮箱, 这里大部分邮箱都是可以通过的, 如果失败的话可以尝试一下国际版的邮箱
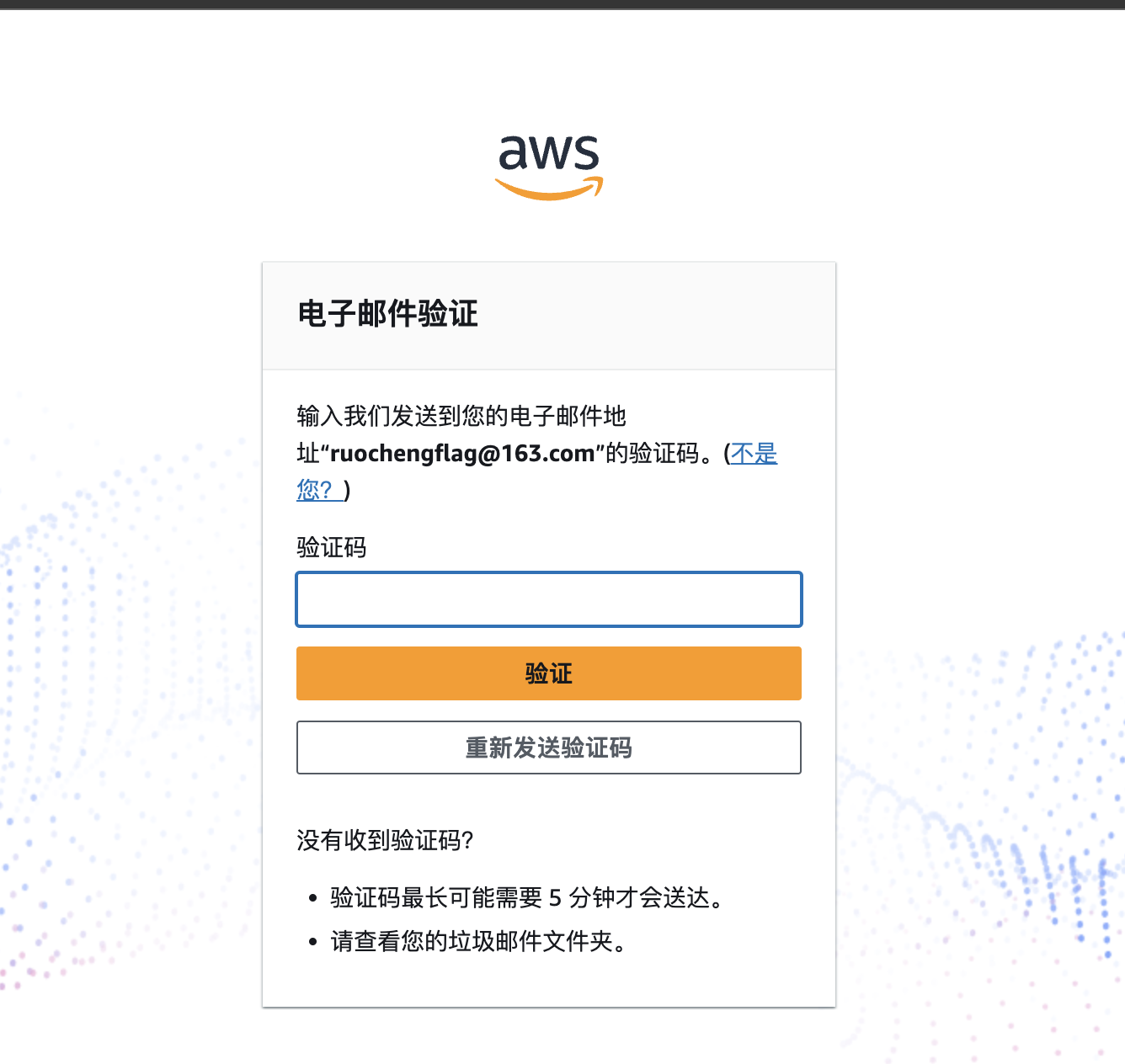
输入完邮箱之后点击下一步, 会让你输入姓名 , 输入完姓名,点击下一步 如图一所示, CodeWhisperer会想邮箱中发送一个验证码, 如图二所示

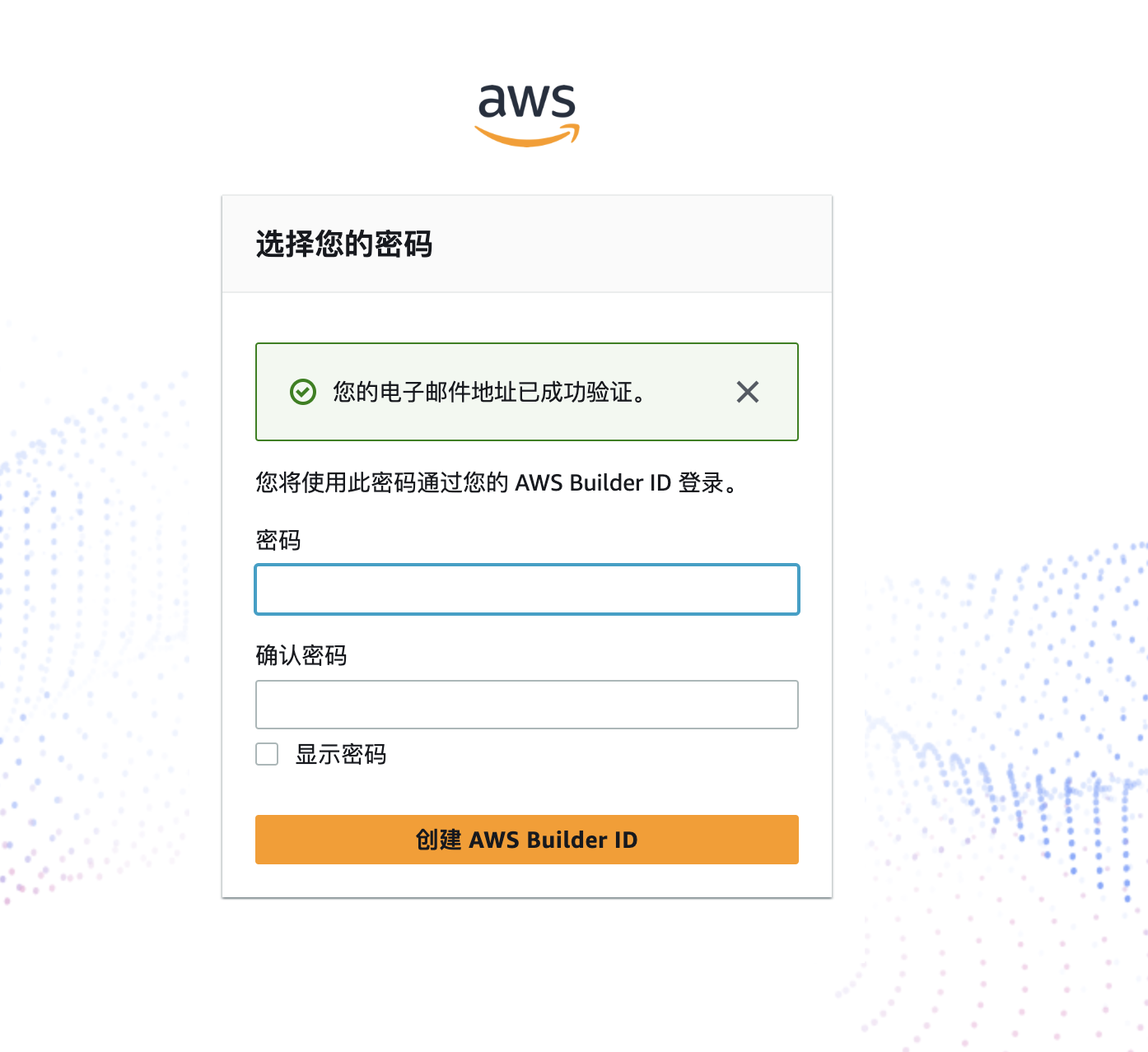
输入完验证码之后, 会让你填一下密码, 这个密码就是你
Amazon的密码, 设置完密码后, 点击创建 AWS Builder ID
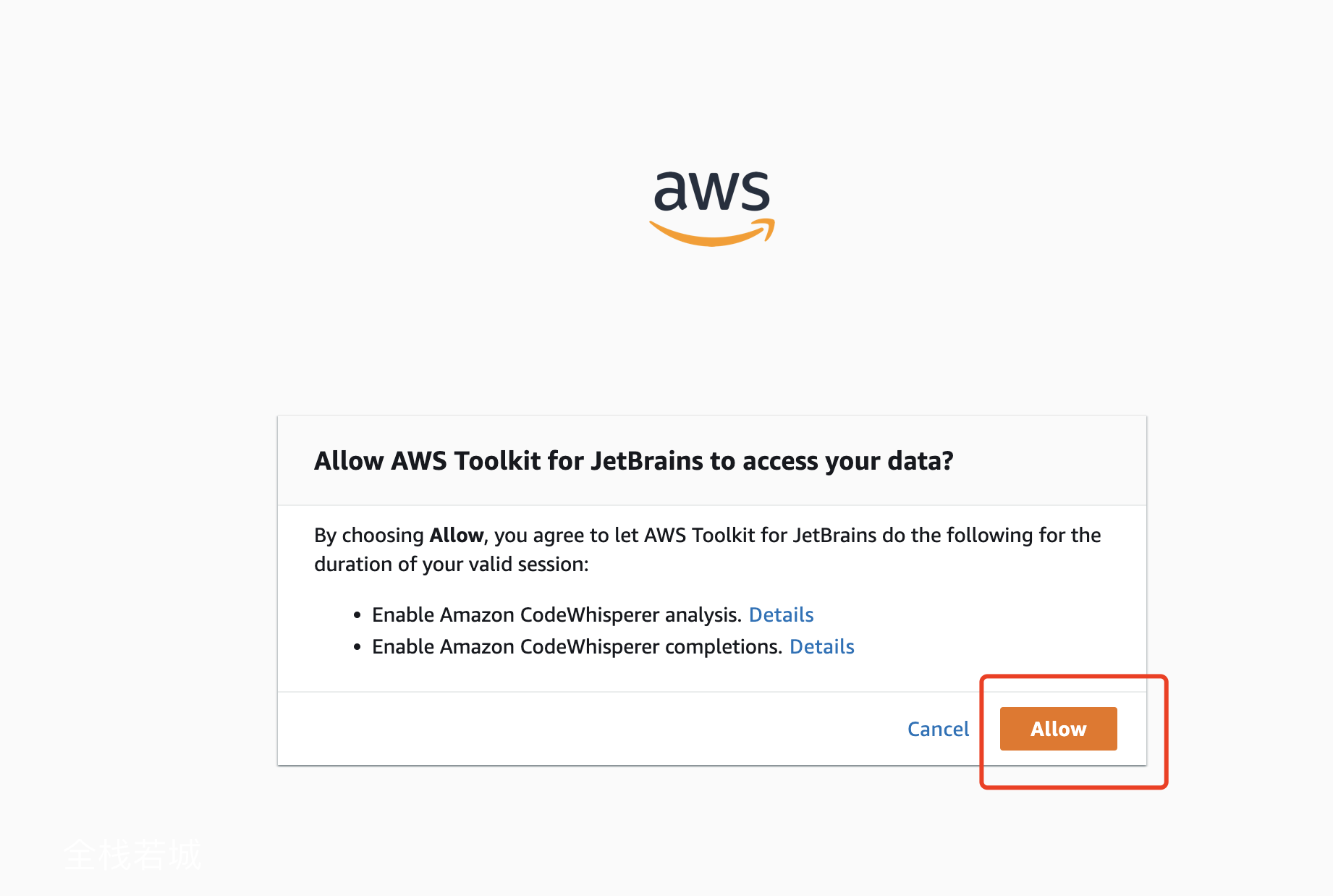
在最后一个页面中点击
Allow按钮, 如下图:
出现一下提示后, 表示注册成功 , 如下图:

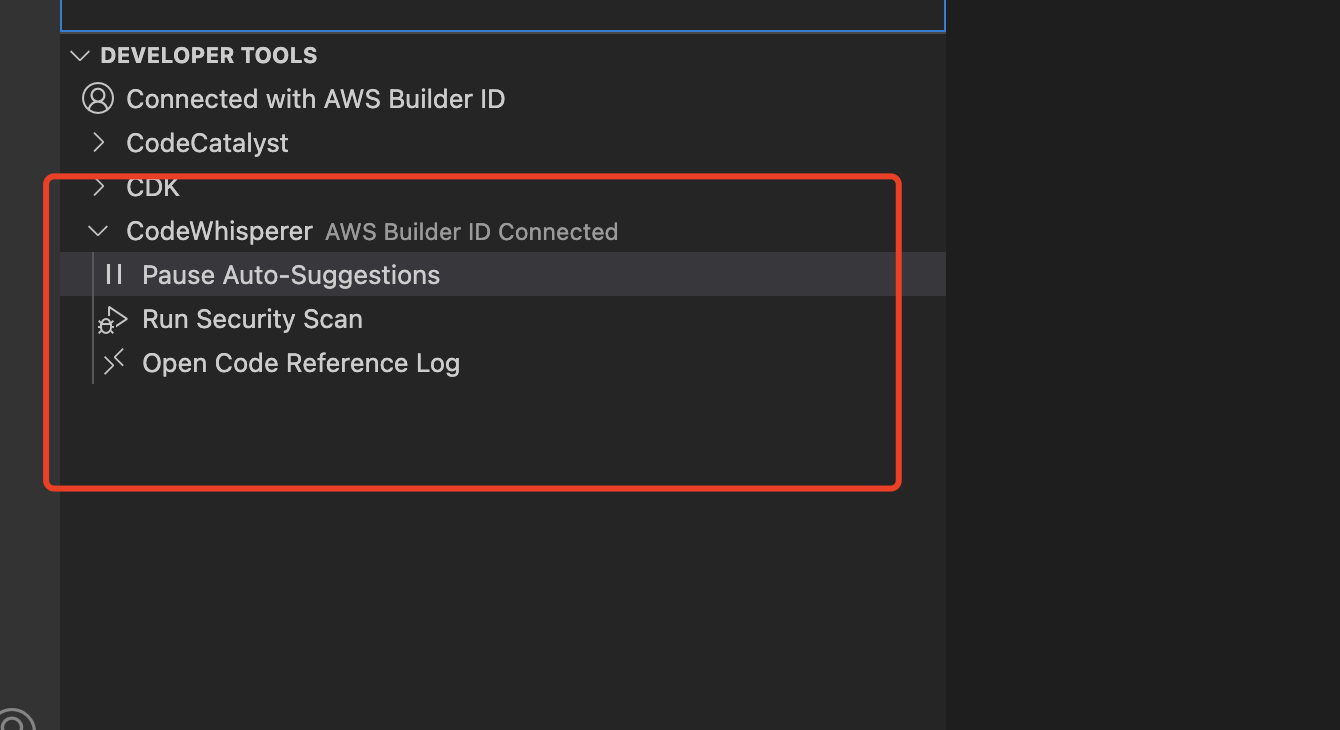
返回IDEA, 在AWS Toolkit视图中的 Developer Tools中可以打开或者关闭代码生成功能, 如下图所示:

注意:以上步骤完成之后就可以愉快的进行
**ai**编程了哦!!!
CodeWhisperer体验
如下图所示, 直接添加注释, CodeWhisperer会根据注释来生成 我们所需要的代码, 非常的便捷.
VSCode安装
- 安装
AWS Toolkit插件, 具体到VS Code侧边栏搜索并安装
- 侧边栏点击
aws=>DEVELIOPER TOOL=>Codewhisper=>Start
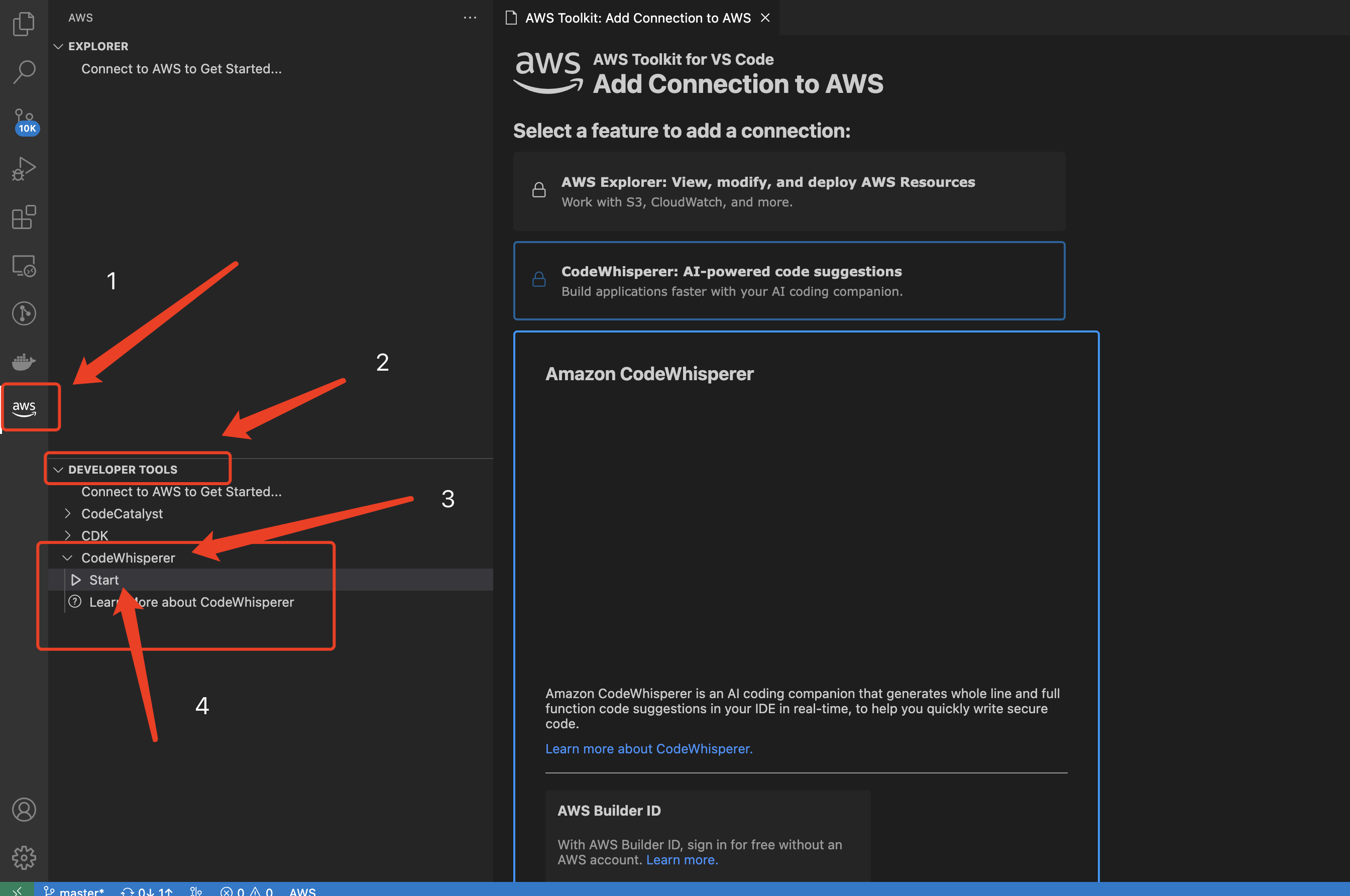
- 在下拉菜单中点击
AWS Builder ID来配置对应的id 等信息, 详细操作步骤同[**PyCharm安装**](#wDgGQ)
- 当侧边栏出现如下图所示的样子,就可以愉快的编程啦!
CodeWhisperer快捷键
| 快捷键 | 功能 |
|---|---|
| ALT+C (mac 用 option + c ) | 要求给出建议(当有暗色子出现时,按Tab 接受建议) |
| TAB | 接受建议 |
| ESC | 取消建议 |
| → | 选择下一个建议 |
| ← | 选择上一个建议 |
CodeWhisperer智能编码(pycharm版)
回到我们的
pycharm编辑器, 看下CodeWhisperer如和帮助我们自动生成代码
单行代码补全
输入字符串
class关键字, 根据输入,Codewhisperer会生成建议列表
当我们不知道接下来要做什么的时候, 代码提示会提供很大的助力. 当然每次生成的提示建议可能会不一样, 我们只需要选择自己想要的即可.

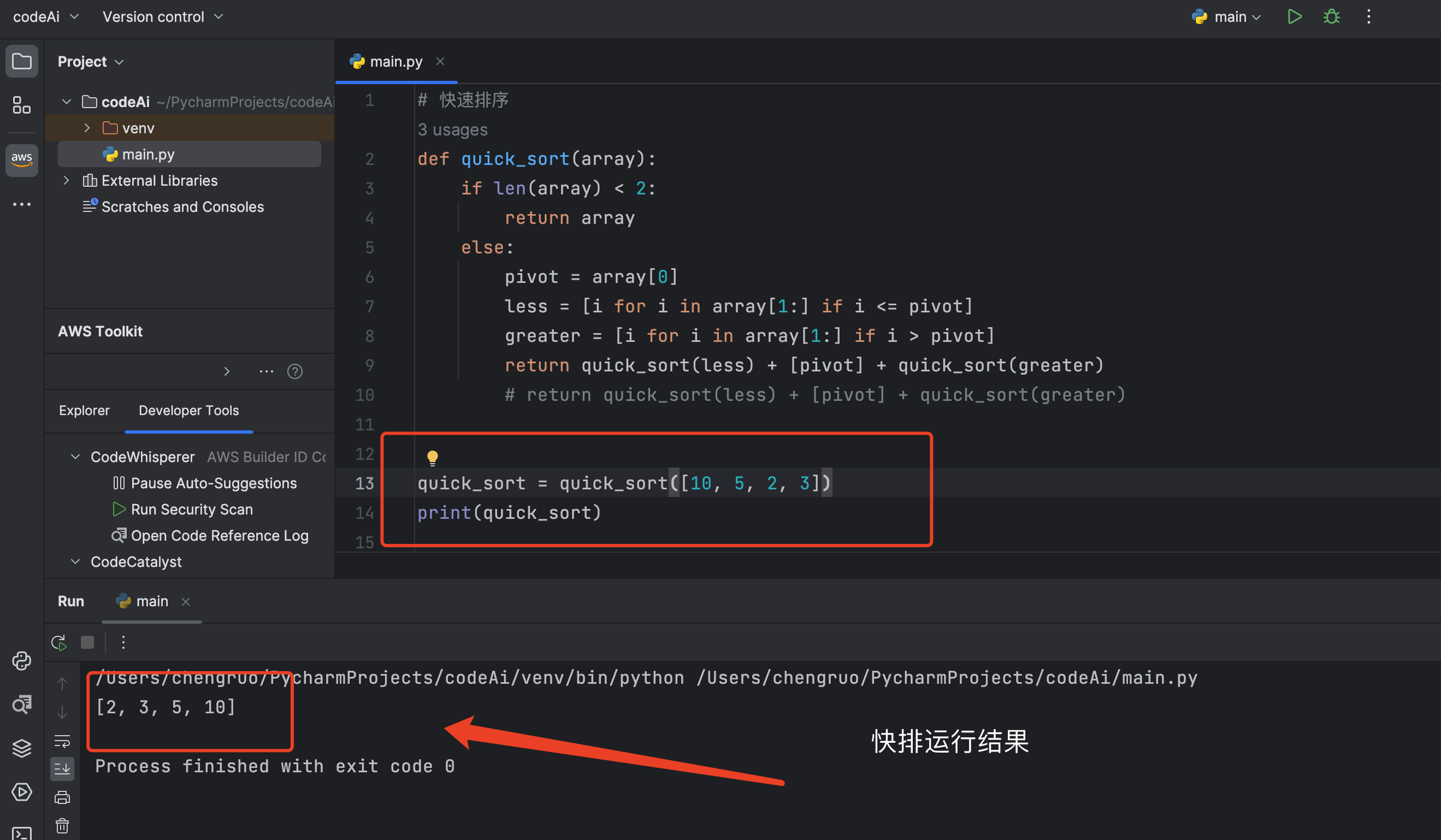
生成完整代码
CodeWhisperer可以根据编写的注释生成完整的函数
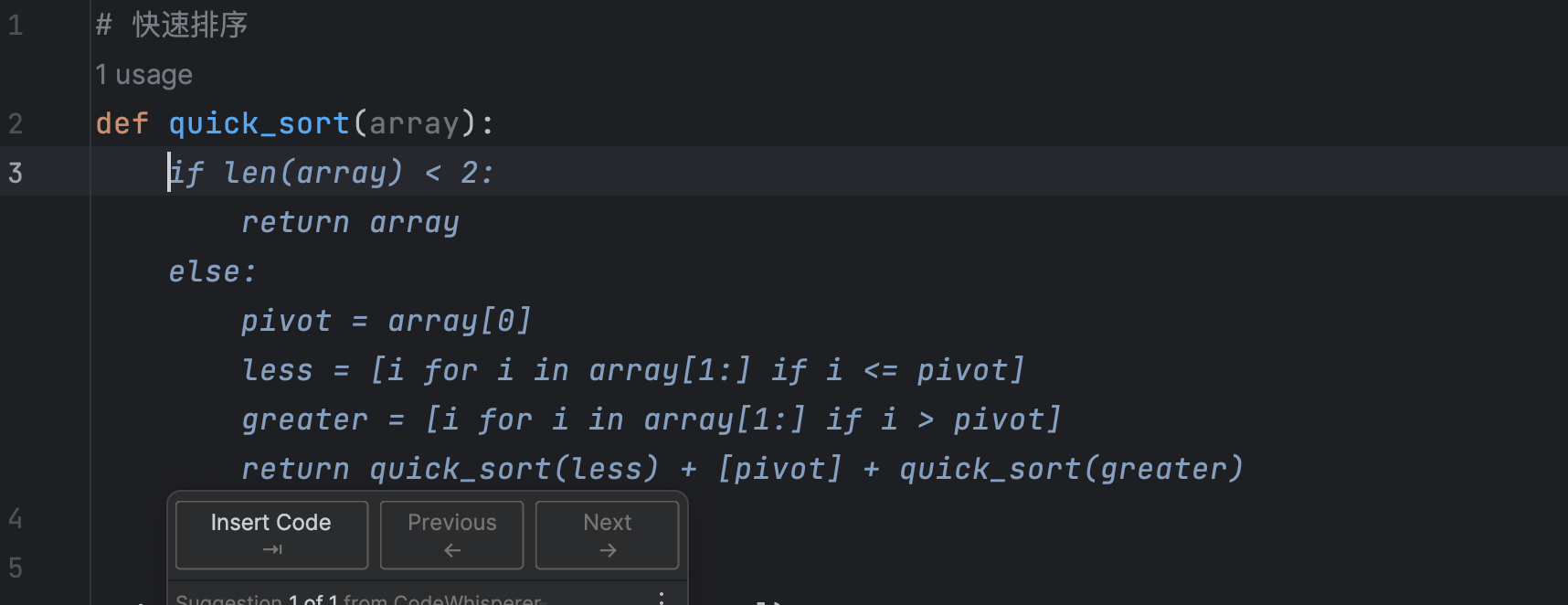
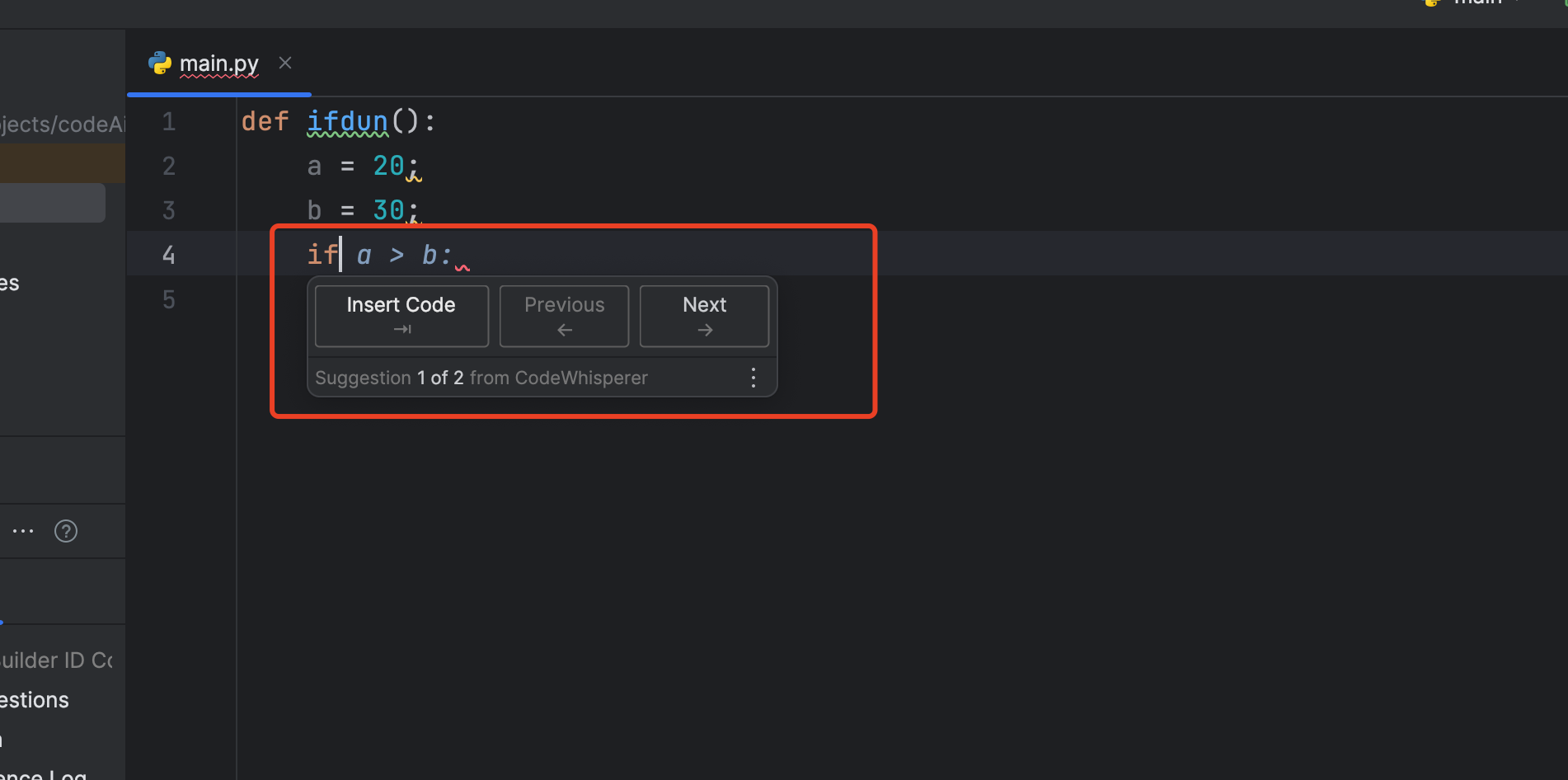
条件语句生成
定义一个函数, 定义一个变量a = 20 , 会自动生成 b , 紧接着输入 if 就会输入如下图所示提示,
关于for 和 while等代码块的生成 也是如此
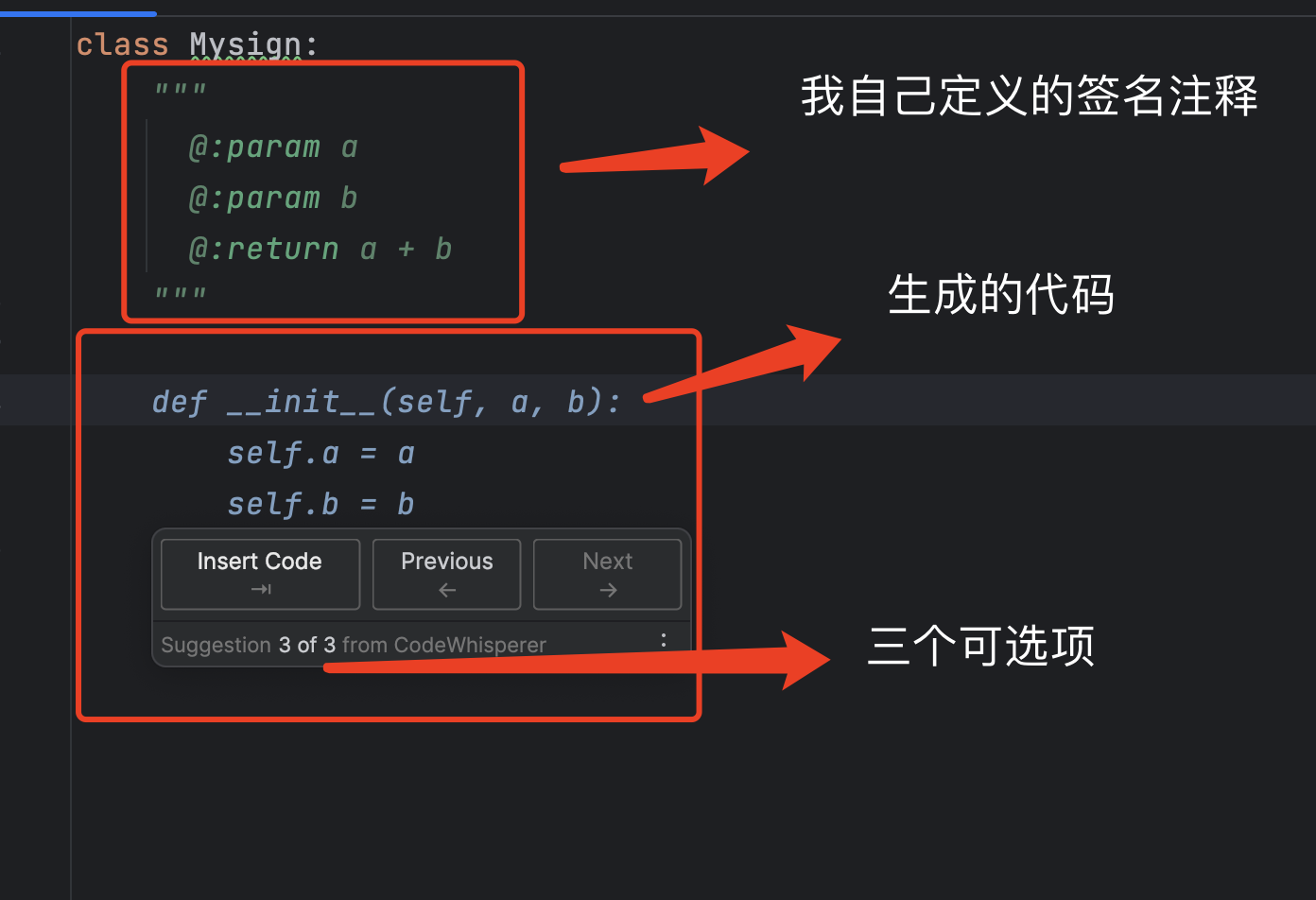
根据签名自动生成代码
如下图所示 我定义的签名分别是 param a param b return a +b, CodeWhisperer 会根据我的签名生成三个代码提示.
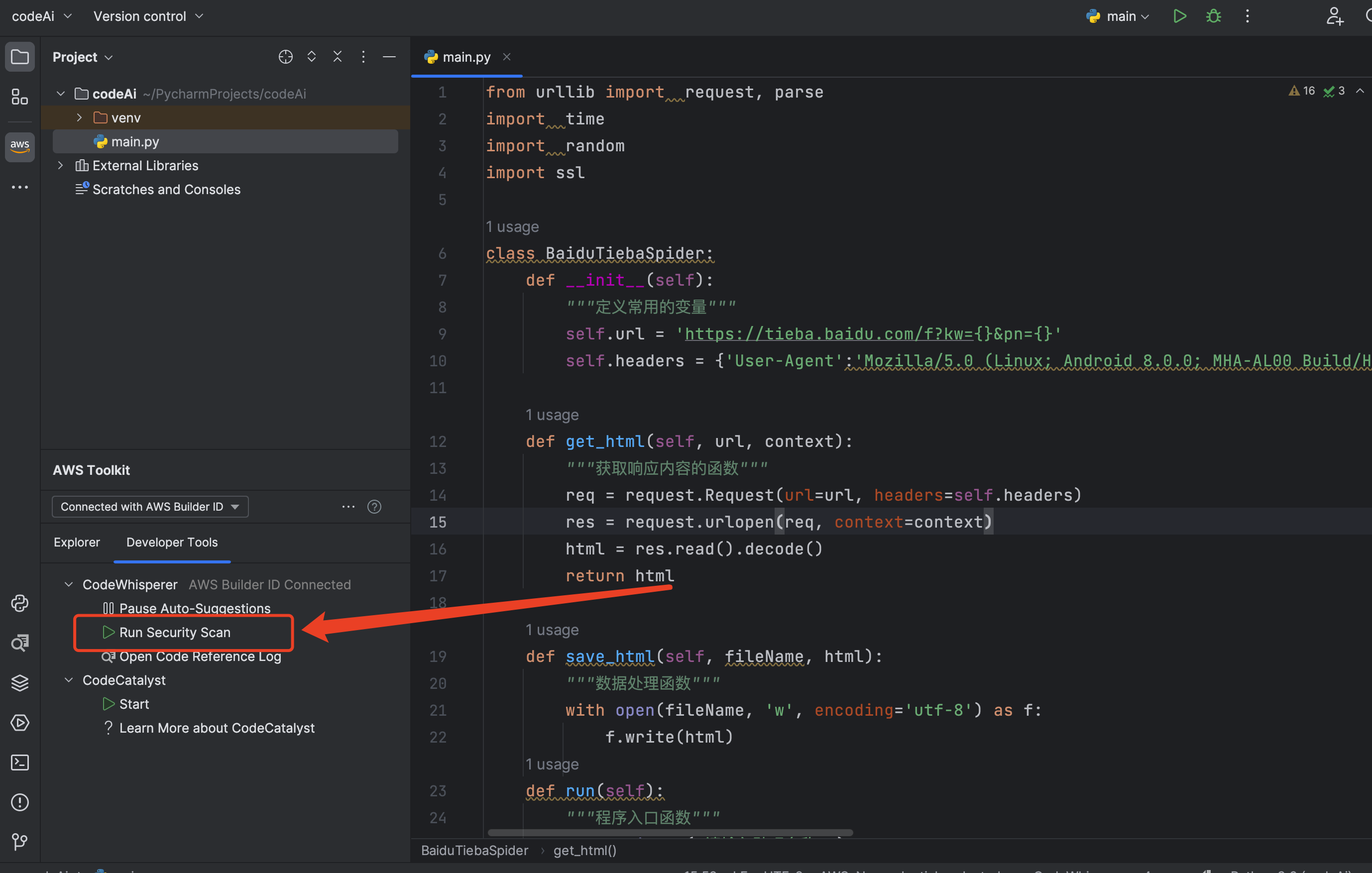
CodeWhisperer安全扫描
我们在pycharm中建立一个爬虫文件,对这个文件进行安全扫描, 查看结果
代码如下
from urllib import request, parse
import time
import random
import ssl
class BaiduTiebaSpider:
def __init__(self):
"""定义常用的变量"""
self.url = 'https://tieba.baidu.com/f?kw={}&pn={}'
self.headers = {
'User-Agent':'Mozilla/5.0 (Linux; Android 8.0.0; MHA-AL00 Build/HUAWEIMHA-AL00; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/68.0.3440.91 Mobile Safari/537.36 BingWeb/6.9.6' }
def get_html(self, url, context):
"""获取响应内容的函数"""
req = request.Request(url=url, headers=self.headers)
res = request.urlopen(req, context=context)
html = res.read().decode()
return html
def save_html(self, fileName, html):
"""数据处理函数"""
with open(fileName, 'w', encoding='utf-8') as f:
f.write(html)
def run(self):
"""程序入口函数"""
name = input('请输入贴吧名称:')
firstPage = int(input("请输入起始页:"))
endPage = int(input("请输入终止页:"))
params = parse.quote(name)
# 创建未验证的SSL上下文
context = ssl.create_default_context()
context.check_hostname = False
context.verify_mode = ssl.CERT_NONE
# 1. 拼接url地址
for page in range(firstPage, endPage+1):
pn = (page - 1) * 50
url = self.url.format(params,pn)
# 发请求, 解析, 保存
html = self.get_html(url, context)
fileName = f'{
name}_第{
page}页'
self.save_html(f'{
name}/{
fileName}', html)
# 控制数据抓取的频率
time.sleep(random.randint(1,5))
if __name__ == '__main__':
spider = BaiduTiebaSpider()
spider.run()
如图一所示点击 Run Security Scan 进行代码的安全检查, 效果如图二所示
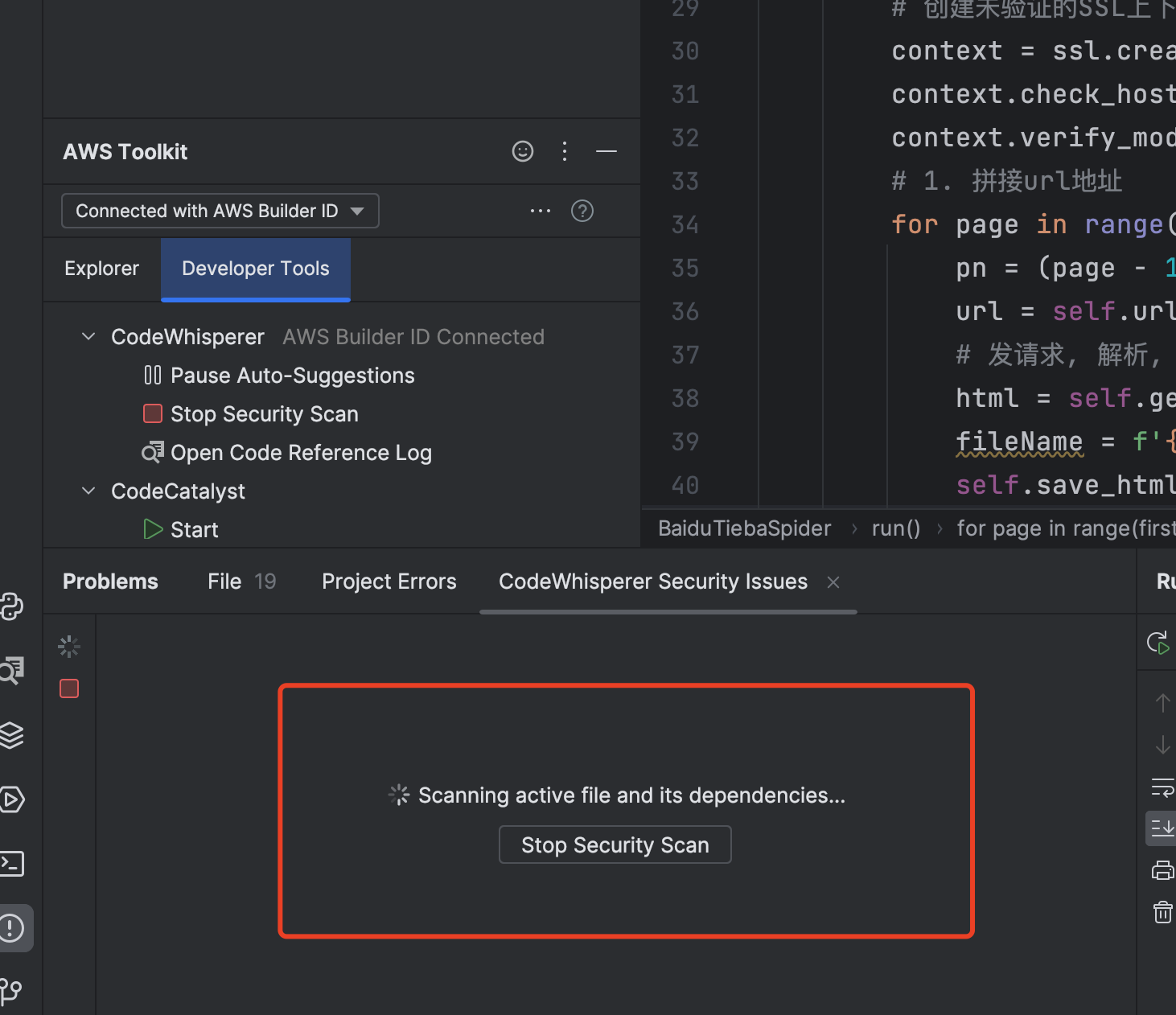
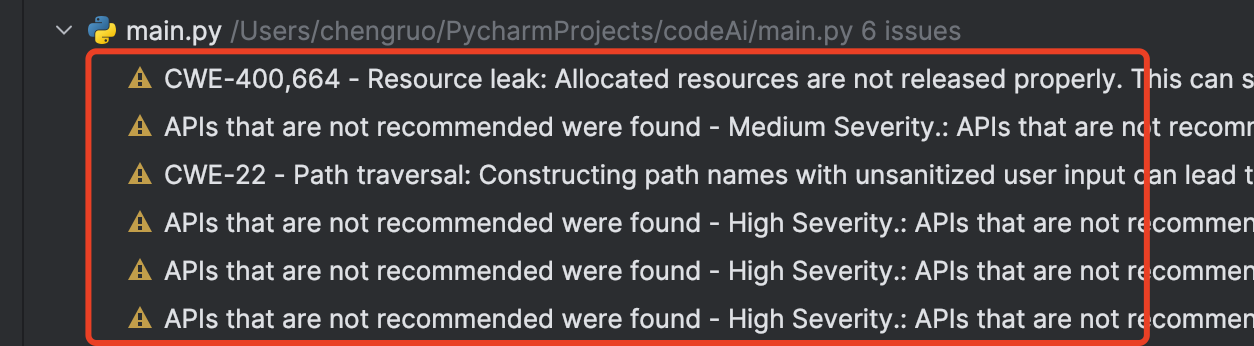
执行完成之后 ,提示我们 有如下6条建议,我们接下来可以根据建议进行修改
操作步骤:
- 双击提示的警告
- 鼠标滑入提示的代码,会出下如下图所示的修改建议
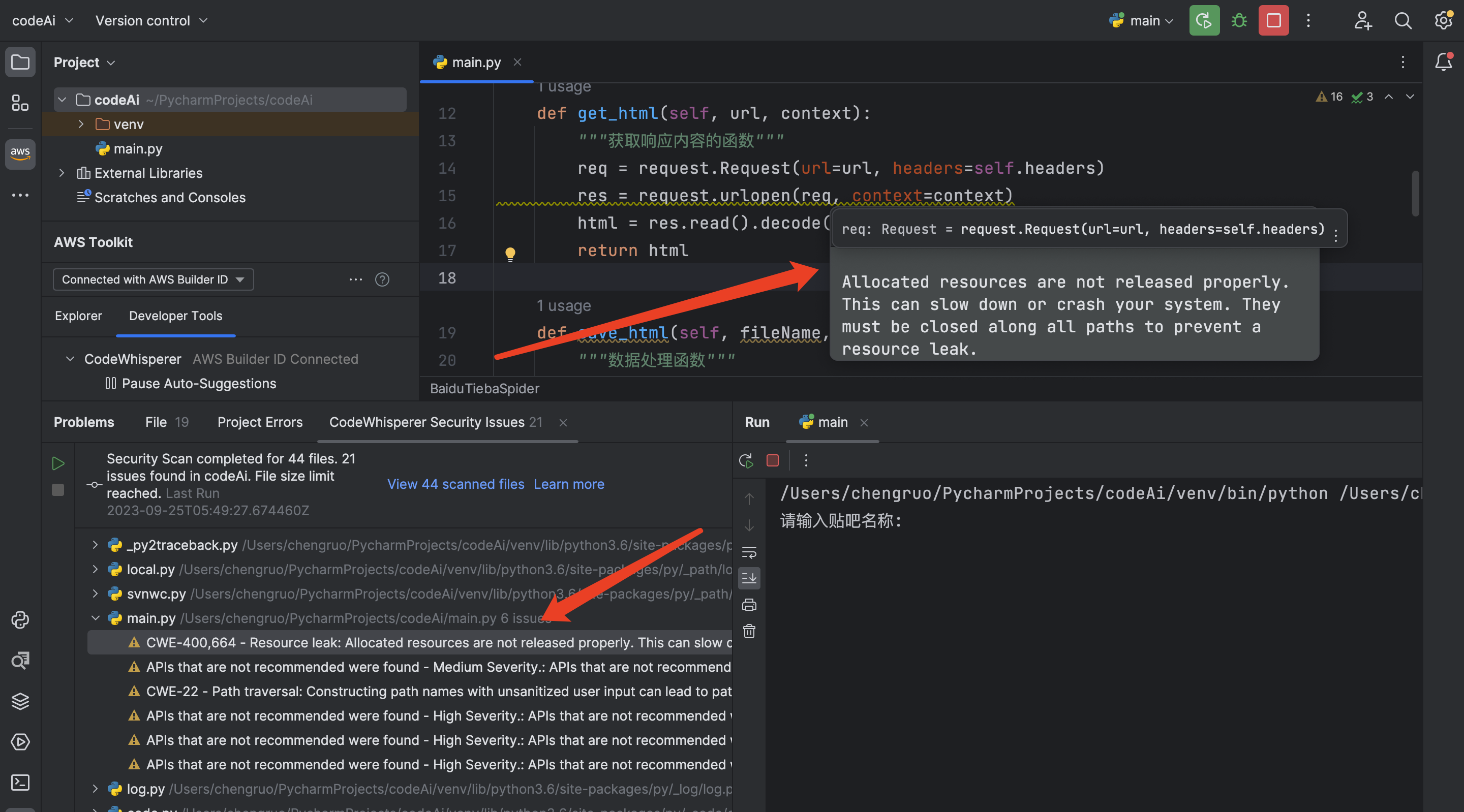
包括下面的几条修改建议都是可以点开查看的, 然后我们可以根据提示进行修改,优化等
**注意: **在CodeWhisperer Security lssues 中我们会发现 除了 main.py之外还有一些其他的, 我们没有操作的py文件检查出来一些漏洞, 其实 CodeWhisperer 是进行的全局检查, 而不是检查当前这文件
CodeWhisperer 是否可以帮助我们更好的开发吗?
从开始体验到目前为止 ,我认为是的, CodeWhisperer 他可以帮我节省大量的时间与精力, 可以让我把自身主要的精力放在代码的设计, 改进,重构以及测试上面, 使我的工作效率直接翻倍.
为什么这么说呢?
CodeWhisperer 他通过承担一些同质化的繁重的工作内容, 使我有了更多的思考的时间, 避免去做那些重复代码,或者代码封装的工作, 我只需要将自己的思路写出来, 然后根据生成的代码,进行简单的改写就可以完成大部分时间才能完成的任务, 整体来说对我的帮助还是很大的 .
项目实战体验
接下来我们使用CodeWhisperer 来编写一个 爬取王者荣耀皮肤 的一个案例
思路分析
- 导入所需的模块:
requests:用于发送HTTP请求。lxml:用于解析HTML代码。
- 设置请求头信息:
- 使用伪装的User-Agent来模拟浏览器发送请求,以防止被网站屏蔽或限制访问。
- 发送请求获取英雄列表数据:
- 通过
requests.get()方法向指定URL发送请求,获取英雄列表的JSON数据。 - 使用
headers来设置请求头信息。
- 遍历英雄列表并创建文件夹:
- 遍历英雄列表中的每个英雄。
- 获取每个英雄的
ename(英雄ID)和cname(英雄名字)。 - 如果对应英雄的文件夹不存在,则创建一个。
- 访问英雄主页并解析页面:
- 构建英雄主页的URL,并使用
requests.get()方法发送请求,获取英雄主页的HTML代码。 - 将响应的内容设置为GBK编码格式,以正确解析中文字符。
- 使用
lxml.etree.HTML()方法将HTML代码转换为可操作的Element对象。
- 提取皮肤图片的文件名信息:
- 使用XPath表达式提取包含皮肤图片文件名信息的属性值。
- 对文件名信息进行处理,提取出实际的文件名,并将其保存在一个列表中。
- 下载皮肤图片:
- 使用循环遍历每个皮肤的文件名和序号。
- 构建皮肤图片的URL,并使用
requests.get()方法发送请求,获取服务器响应的图片内容。 - 使用
open()方法以二进制写入模式打开文件,将图片内容写入本地文件。 - 打印已下载的皮肤名字。
- 使用
time.sleep()方法暂停1秒,以防止频繁请求服务器。
接下来我们根据这个思路 使用CodeWhisperer 来为我们生成关键性代码
通过思路分析生成的代码如下
"""
1. 导入所需的模块:
○ requests:用于发送HTTP请求。
○ lxml:用于解析HTML代码。
"""
import requests
from lxml import etree
"""
2. 设置请求头信息:
○ 使用伪装的User-Agent来模拟浏览器发送请求,以防止被网站屏蔽或限制访问。
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
}
"""
3. 发送请求获取英雄列表数据:
○ 通过requests.get()方法向 "https://pvp.qq.com/web201605/js/herolist.json" 发送请求,获取英雄列表的JSON数据。
○ 使用headers来设置请求头信息。
"""
# 访问英雄列表顶部户外站
url = 'https://pvp.qq.com/web201605/js/herolist.json'
response = requests.get(url, headers=headers)
"""
4. 遍历英雄列表并创建文件夹:
○ 遍历英雄列表中的每个英雄。
○ 获取每个英雄的ename(英雄ID)和cname(英雄名字)。
○ 如果对应英雄的文件夹不存在,则创建一个。
"""
hero_list = response.json()
for hero in hero_list:
hero_name = hero['ename']
hero_cname = hero['cname']
"""
5. 访问英雄主页并解析页面:
○ 构建英雄主页的"https://pvp.qq.com/web201605/herodetail/{hero_name}.shtml",并使用requests.get()方法发送请求,获取英雄主页的HTML代码。
○ 将响应的内容设置为GBK编码格式,以正确解析中文字符。
○ 使用lxml.etree.HTML()方法将HTML代码转换为可操作的Element对象。
"""
hero_url = f'https://pvp.qq.com/web201605/herodetail/{
hero_name}.shtml'
hero_response = requests.get(hero_url, headers=headers)
hero_response.encoding = 'GBK'
"""
6. 提取皮肤图片的文件名信息:
○ 使用XPath [//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname][0]表达式提取包含皮肤图片文件名信息的属性值。
○ 对文件名信息进行处理,提取出实际的文件名,并将其保存在一个列表中。
"""
hero_html = etree.HTML(hero_response.text)
hero_skin_list = hero_html.xpath('//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0]
"""
7. 下载皮肤图片:
○ 使用循环遍历每个皮肤的文件名和序号。
○ 构建皮肤图片url "http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{hero_name}/{hero_name}-bigskin-{i+1}.jpg",并使用requests.get()方法发送请求,获取服务器响应的图片内容。
○ 使用open()方法以二进制写入模式打开文件,将图片内容写入本地文件。
○ 打印已下载的皮肤名字。
○ 使用time.sleep()方法暂停1秒,以防止频繁请求服务器。
"""
hero_skin_list = hero_skin_list.split('|')
for i in range(len(hero_skin_list)):
hero_skin_name = hero_skin_list[i]
hero_skin_url = f'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{
hero_name}/{
hero_name}-bigskin-{
i+1}.jpg'
hero_skin_response = requests.get(hero_skin_url, headers=headers)
with open(f'./{
hero_name}/{
hero_skin_name}.jpg', 'wb') as f:
f.write(hero_skin_response.content)
print(f'{
hero_name} {
hero_skin_name} 下載成功')
time.sleep(1)
如上述代码所示,我们一步一步的跟着思路来使用CodeWhisperer 来生成我们所需要的代码 , 此时我们运行代码效果如下:

接下来我们只需要简单的手动改写一下就可以了 , 效果如下
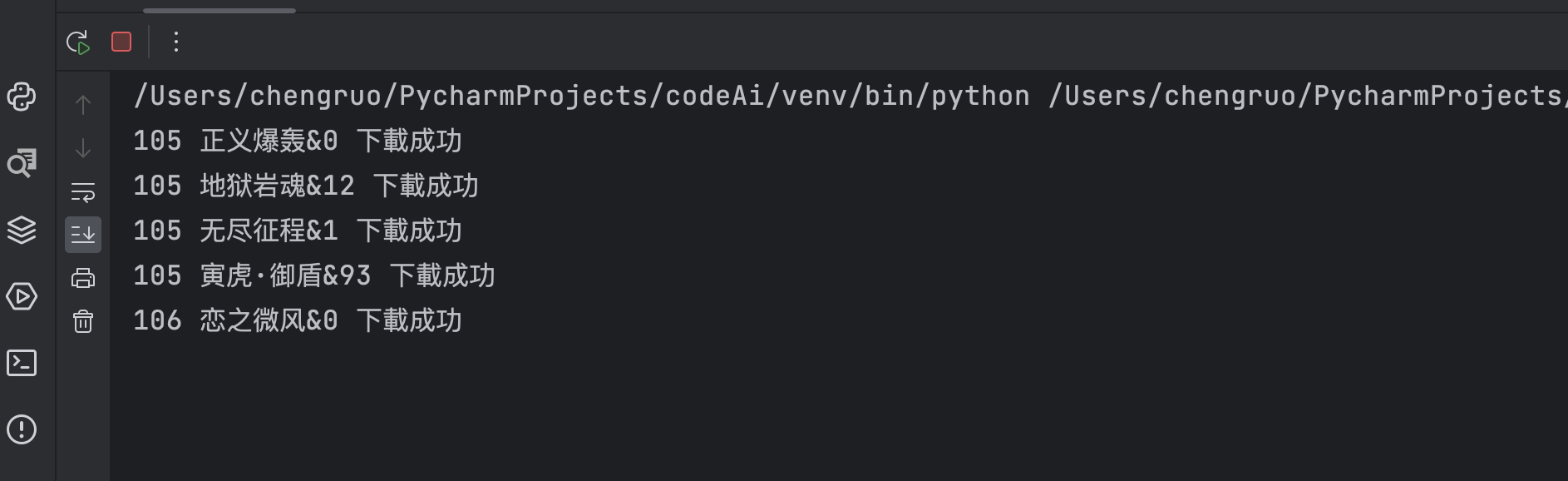
修改后代码如下:
"""
1. 导入所需的模块:
○ requests:用于发送HTTP请求。
○ lxml:用于解析HTML代码。
"""
import requests
from lxml import etree
import os
import time
"""
2. 设置请求头信息:
○ 使用伪装的User-Agent来模拟浏览器发送请求,以防止被网站屏蔽或限制访问。
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
}
"""
3. 发送请求获取英雄列表数据:
○ 通过requests.get()方法向 "https://pvp.qq.com/web201605/js/herolist.json" 发送请求,获取英雄列表的JSON数据。
○ 使用headers来设置请求头信息。
"""
# 访问英雄列表顶部户外站
url = 'https://pvp.qq.com/web201605/js/herolist.json'
response = requests.get(url, headers=headers)
"""
4. 遍历英雄列表并创建文件夹:
○ 遍历英雄列表中的每个英雄。
○ 获取每个英雄的ename(英雄ID)和cname(英雄名字)。
○ 如果对应英雄的文件夹不存在,则创建一个。
"""
hero_list = response.json()
for hero in hero_list:
hero_name = str(hero['ename'])
hero_cname = hero['cname']
if not os.path.exists(hero_cname):
os.makedirs(hero_cname)
"""
5. 访问英雄主页并解析页面:
○ 构建英雄主页的"https://pvp.qq.com/web201605/herodetail/{hero_name}.shtml",并使用requests.get()方法发送请求,获取英雄主页的HTML代码。
○ 将响应的内容设置为GBK编码格式,以正确解析中文字符。
○ 使用lxml.etree.HTML()方法将HTML代码转换为可操作的Element对象。
"""
hero_url = f'https://pvp.qq.com/web201605/herodetail/{
hero_name}.shtml'
hero_response = requests.get(hero_url, headers=headers)
hero_response.encoding = 'GBK'
"""
6. 提取皮肤图片的文件名信息:
○ 使用XPath [//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname][0]表达式提取包含皮肤图片文件名信息的属性值。
○ 对文件名信息进行处理,提取出实际的文件名,并将其保存在一个列表中。
"""
hero_html = etree.HTML(hero_response.text)
hero_skin_list = hero_html.xpath('//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0]
"""
7. 下载皮肤图片:
○ 使用循环遍历每个皮肤的文件名和序号。
○ 构建皮肤图片url "http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{hero_name}/{hero_name}-bigskin-{i+1}.jpg",并使用requests.get()方法发送请求,获取服务器响应的图片内容。
○ 使用open()方法以二进制写入模式打开文件,将图片内容写入本地文件。
○ 打印已下载的皮肤名字。
○ 使用time.sleep()方法暂停1秒,以防止频繁请求服务器。
"""
hero_skin_list = hero_skin_list.split('|')
for i in range(len(hero_skin_list)):
hero_skin_name = hero_skin_list[i]
hero_skin_url = f'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{
hero_name}/{
hero_name}-bigskin-{
i+1}.jpg'
hero_skin_response = requests.get(hero_skin_url, headers=headers)
with open(f'{
hero_cname}/{
hero_skin_name}.jpg', 'wb') as f:
f.write(hero_skin_response.content)
print(f'{
hero_name} {
hero_skin_name} 下載成功')
time.sleep(1)
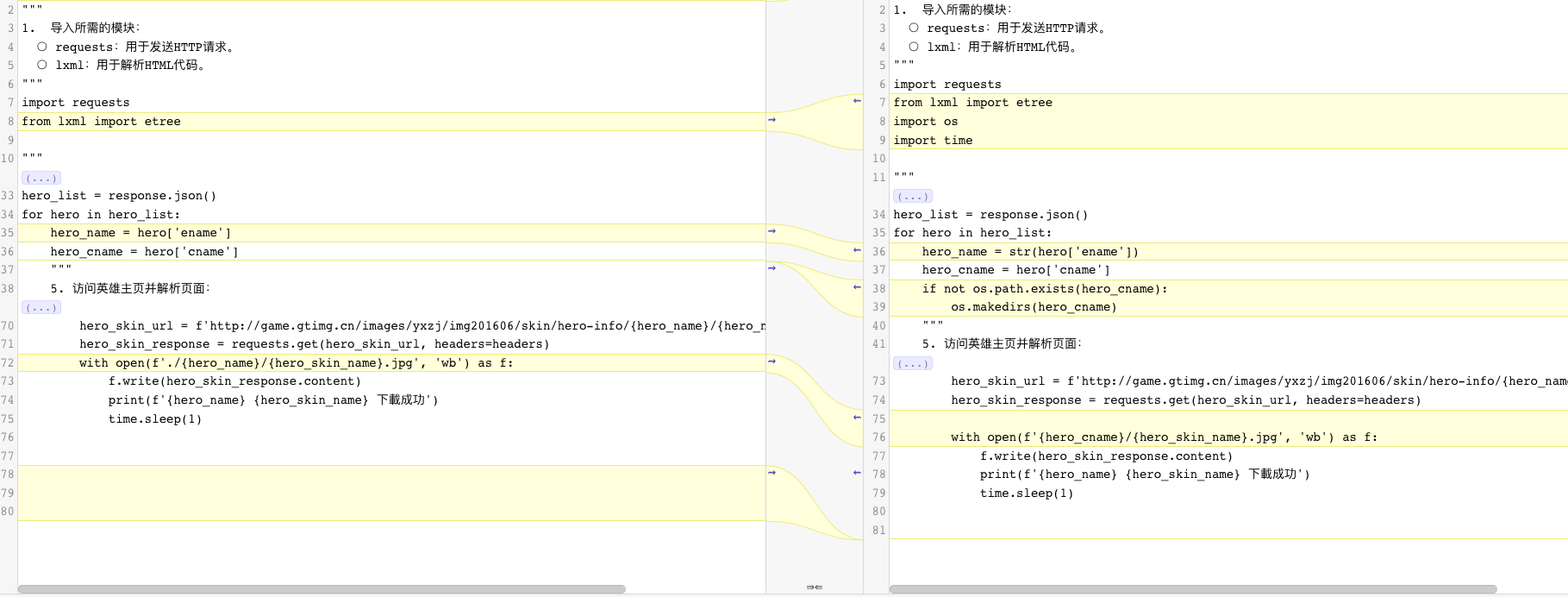
代码差异化对比
左侧为Code Whisperer 根据注释生成的代码 , 右侧 是在生成的代码基础上进行的修改,
通过对比图发现, 其实在生成代码之后 ,我们修改的内容是比较少的, 由此可见Code Whisperer的强大之处!!
总结
通过对CodeWhisperer从注册到项目体验,对于AI 大时代的来临感受颇深, 对于开发人员来说CodeWhisperer是一个宝贵的工具。它可以提供准确、多领域的编程支持,并具备良好的学习能力和用户体验。无论是初学者还是有经验的开发者,都可以从CodeWhisperer中获得有价值的帮助和指导。
还在观望的同学,建议赶紧快去开始尝试体验一下吧!!