Processes and threads
进程是正在运行的程序,包括下列部分的抽象:
- (独立的)地址空间
- 一个或者多个线程
- 打开的文件(以描述符fd的形式呈现)
- 套接字
- 信号量Semaphore
- 共享的内存区域
- 定时器
- 信号句柄signal handler
- 其他的资源和状态信息
这些东西都存在于进程控制块(PCB)中。在linux中,是struct task_struct。
进程的资源
我们查看/proc/<pid>目录,就能看到进程号为<pid>的进程的相关信息。
一个进程如果想查看自己的相关信息,可以访问/proc/self目录。
+-------------------------------------------------------------------+
| dr-x------ 2 tavi tavi 0 2021 03 14 12:34 . |
| dr-xr-xr-x 6 tavi tavi 0 2021 03 14 12:34 .. |
| lrwx------ 1 tavi tavi 64 2021 03 14 12:34 0 -> /dev/pts/4 |
+--->| lrwx------ 1 tavi tavi 64 2021 03 14 12:34 1 -> /dev/pts/4 |
| | lrwx------ 1 tavi tavi 64 2021 03 14 12:34 2 -> /dev/pts/4 |
| | lr-x------ 1 tavi tavi 64 2021 03 14 12:34 3 -> /proc/18312/fd |
| +-------------------------------------------------------------------+
| +----------------------------------------------------------------+
| | 08048000-0804c000 r-xp 00000000 08:02 16875609 /bin/cat |
$ ls -1 /proc/self/ | 0804c000-0804d000 rw-p 00003000 08:02 16875609 /bin/cat |
cmdline | | 0804d000-0806e000 rw-p 0804d000 00:00 0 [heap] |
cwd | | ... |
environ | +----------->| b7f46000-b7f49000 rw-p b7f46000 00:00 0 |
exe | | | b7f59000-b7f5b000 rw-p b7f59000 00:00 0 |
fd --------+ | | b7f5b000-b7f77000 r-xp 00000000 08:02 11601524 /lib/ld-2.7.so |
fdinfo | | b7f77000-b7f79000 rw-p 0001b000 08:02 11601524 /lib/ld-2.7.so |
maps -----------+ | bfa05000-bfa1a000 rw-p bffeb000 00:00 0 [stack] |
mem | ffffe000-fffff000 r-xp 00000000 00:00 0 [vdso] |
root +----------------------------------------------------------------+
stat +----------------------------+
statm | Name: cat |
status ------+ | State: R (running) |
task | | Tgid: 18205 |
wchan +------>| Pid: 18205 |
| PPid: 18133 |
| Uid: 1000 1000 1000 1000 |
| Gid: 1000 1000 1000 1000 |
+----------------------------+
线程
线程是内核调度任务到CPU上运行的基本单位。一个线程有下列性质:
- 每个线程都有自己的栈、自己的寄存器值(用来保存自己已经运行到了哪一步)
- 线程在进程的上下文上运行,在一个进程里的线程都会共享资源
- 内核调度的是线程而不是进程。此外,对于用户态的线程(比如golang里的goroutine),内核是不感知的
- 在经典的线程实现里,线程信息被当成一个一个分开的数据结构(链表节点),然后被链接到进程的数据结构里。比如,windows的核对线程做了下图所示的实现:
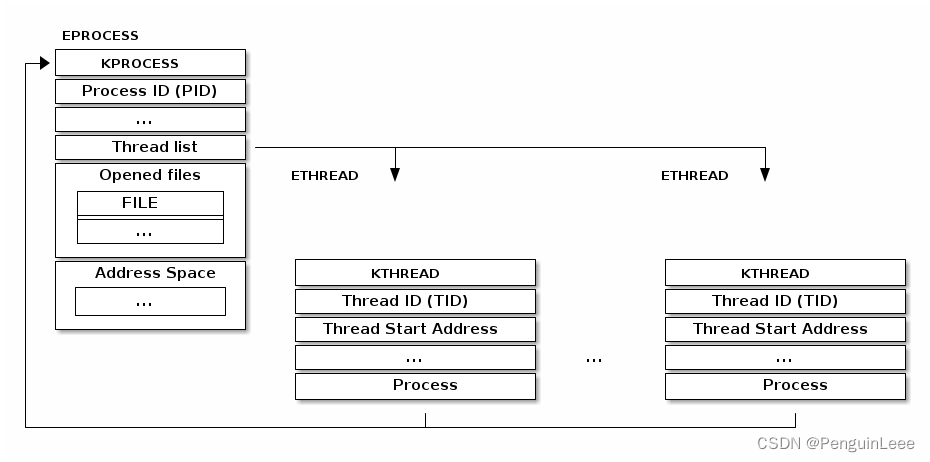
我们可以看到,一个进程控制块中有一个线程链表,每一个链表元素(线程)又指向它所属的进程。
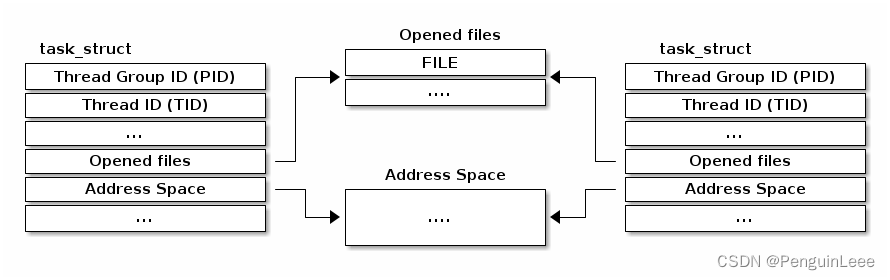
Linux对线程的实现有所不同。(线程和进程的)基本单元称为task,于是进程和线程对应的数据结构就是struct task_struct,这个结构用于描述进程和线程。在struct task_struct中,并不会记录资源,而是用指针指向对应的资源。
如下图,假如有两个线程在一个进程里(有相同的线程组ID,即PID),它们就会指向同一个描述资源的数据结构(比如打开的文件、地址空间、namespace)。如果两个线程不属于一个进程,那么它们指向的描述资源的数据结构必然不同。
一般来说,PID和TGID是相同的。但理论上操作系统内核可以为一个进程内的线程分配不同的TGID,只是在实际的Linux实现中通常没有这种情况。
系统调用clone()
在Linux中,开新线程pthread_create()或者新进程fork()的时候,都使用了clone()系统调用:
int clone(int (*fn)(void *_Nullable), void *stack, int flags,
void *_Nullable arg, ... /* pid_t *_Nullable parent_tid,
void *_Nullable tls,
pid_t *_Nullable child_tid */ );
它允许调用者自己决定哪些资源可以被共享,主要通过flags组成的二进制掩码来向clone()函数传达下列信息:

- CLONE_FILES - 和父进程共享文件描述符表
- CLONE_VM - 和父进程共享地址空间
- CLONE_FS - 和父进程共享文件系统信息(比如根目录、pwd)
- CLONE_NEWNS - 不和父进程共享挂载(mount)命名空间,自己开个新的
- CLONE_NEWIPC - 不和父进程共享进程间通信(比如System V IPC对象,POSIX 消息队列等)的命名空间,自己开个新的
- CLONE_NEWNET - 不和父进程共享网络命名空间
比如,用了这三个flag:CLONE_FILES | CLONE_VM | CLONE_FS就意味着开了一个线程。如果没用它们,就意味着开了个进程。
命名空间和容器技术
容器技术中主要使用cgroup和namespace实现资源的隔离。比如说,如果没有容器技术,那么所有的进程都可以在/proc目录下看到。在容器中运行的进程就不对别的容器可见(或者可杀)了。
/*
* A structure to contain pointers to all per-process
* namespaces - fs (mount), uts, network, sysvipc, etc.
*
* The pid namespace is an exception -- it's accessed using
* task_active_pid_ns. The pid namespace here is the
* namespace that children will use.
*
* 'count' is the number of tasks holding a reference.
* The count for each namespace, then, will be the number
* of nsproxies pointing to it, not the number of tasks.
*
* The nsproxy is shared by tasks which share all namespaces.
* As soon as a single namespace is cloned or unshared, the
* nsproxy is copied.
*/
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct time_namespace *time_ns;
struct time_namespace *time_ns_for_children;
struct cgroup_namespace *cgroup_ns;
};
在进程控制块中,
struct task_struct {
... ...
struct fs_struct *fs;
struct files_struct *files;
struct nsproxy *nsproxy; // 名称空间指针
... ...
};
上面是struct nsproxy的结构,可以用于对不同类型的资源进行分隔(基于名称空间实现)。
目前,它支持IPC、网络(网络协议栈隔离,参考docker网络)、cg(计算资源使用隔离,比如CPU占比和mem上界)、mount(访问文件隔离)、PID(允许不同的Namespace下的进程可以有同一个PID)、时间的名称空间。
访问当前进程
访问当前进程是一个频繁的操作,比如:
- 打开文件,要访问对应的fd
- 访问虚拟内存,需要访问当前进程的页表
- 超过90%的系统调用需要访问进程控制块
- 访问current宏 ,是一个全局指针,指向当前进程的
struct task_struct结构体,即表示当前进程。 例如current ->pid就能得到当前进程的pid,current->comm就能得到当前进程的名称。
如下图,为了在多核环境下支持进程控制块的快速访问,每个CPU核都有一个变量,用来存储当前运行进程的控制块的指针:
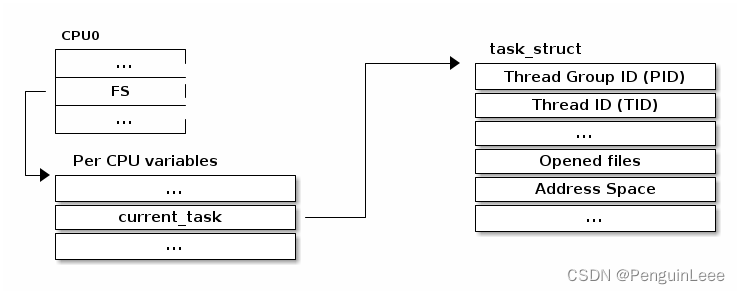
另一种访问struct task_struct结构体的方法是使用current宏。如下代码展示了current宏被用来进行进程控制块访问的细节。
/* how to get the current stack pointer from C */
register unsigned long current_stack_pointer asm("esp") __attribute_used__;
/* how to get the thread information struct from C */
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)(current_stack_pointer & ~(THREAD_SIZE – 1));
}
#define current current_thread_info()->task
进程上下文切换
下图展示了linux内核做进程上下文切换的过程:
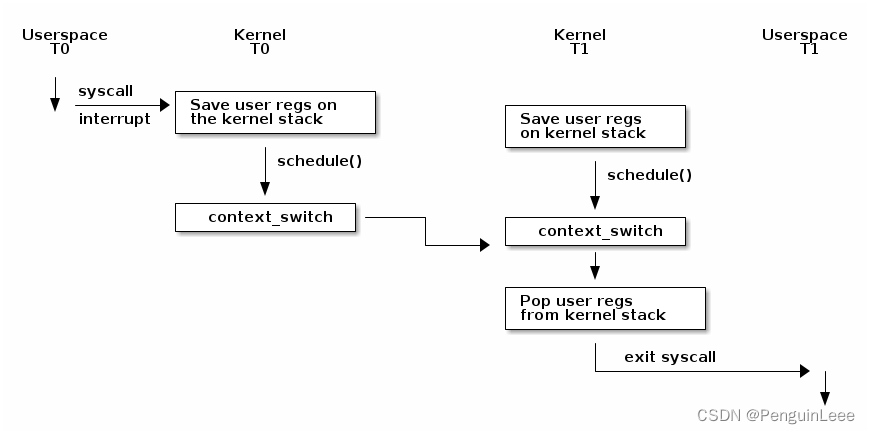
这里的T0指线程0,T1指线程1。
在上述流程中,比如用户线程调用了系统调用,首先进入了内核态,把用户态的CPU上下文写到了线程自己的内核栈上,然后调用了schedule()方法,主动放弃CPU,进行上下文切换,切换到另一个线程,继续运行。
阻塞和唤醒task(包括进线程)
Task状态
下图展示了task状态的变换逻辑。
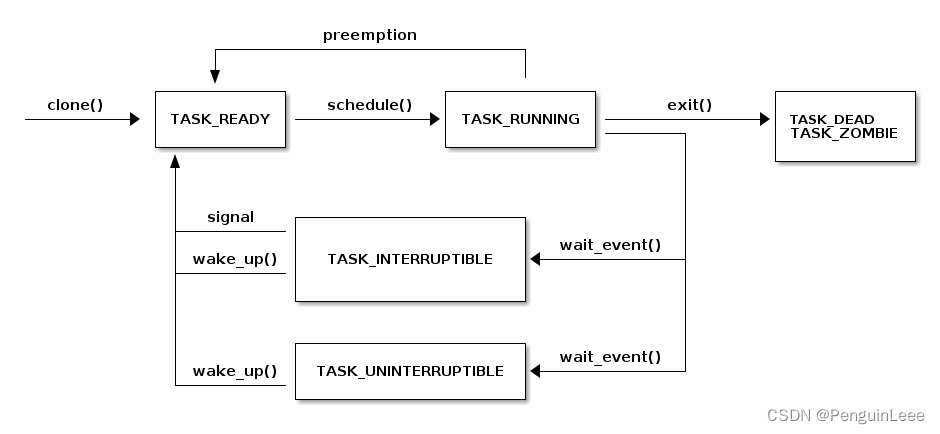
TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE 有以下区别:
在 TASK_INTERRUPTIBLE 状态下,线程正在等待某个条件的满足,但它可以被一个信号中断(interrupt)而唤醒。
当线程进入 TASK_INTERRUPTIBLE 状态时,它会进入可中断的等待队列,等待条件的满足。
如果线程收到了一个信号,如 Ctrl+C 发送的 SIGINT,它会从睡眠状态中被唤醒,然后可以选择如何处理这个信号(比如直接结束进程)。
在 TASK_UNINTERRUPTIBLE 状态下,线程也在等待条件的满足,但它无法被信号中断。
当线程进入 TASK_UNINTERRUPTIBLE 状态时,它会进入不可中断的等待队列。
这种状态通常用于一些关键性的操作,例如文件系统的写操作。在这种情况下,即使线程收到了信号,也不能被中断,以确保关键操作的完整性。
阻塞当前线程
阻塞当前线程是高性能的重要操作——在当前线程等待IO操作的时候,去运行别的线程。
为了完成阻塞步骤,需要:
- 把当前线程状态设置为TASK_UINTERRUPTIBLE或者TASK_INTERRUPTIBLE
- 把线程加入到等待队列里
- 从linux调度器里拿到一个可以调度的线程
- 切换上下文到这个可以调度的线程,开始执行
唤醒一个task
我们可以调用wake_up函数唤醒线程,它主要做:
- 从等待队列里选取一个线程
- 设置线程状态为TASK_READY
- 把线程放到调度器的READY队列里
- 在SMP系统中,需要考虑的事情更多:每一个CPU都有自己的队列,于是需要考虑负载均衡、处理器亲和性等一系列事情
#define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL)
/**
* __wake_up - wake up threads blocked on a waitqueue.
* @wq_head: the waitqueue
* @mode: which threads
* @nr_exclusive: how many wake-one or wake-many threads to wake up
* @key: is directly passed to the wakeup function
*
* If this function wakes up a task, it executes a full memory barrier before
* accessing the task state.
*/
void __wake_up(struct wait_queue_head *wq_head, unsigned int mode,
int nr_exclusive, void *key)
{
__wake_up_common_lock(wq_head, mode, nr_exclusive, 0, key);
}
static void __wake_up_common_lock(struct wait_queue_head *wq_head, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
unsigned long flags;
wait_queue_entry_t bookmark;
bookmark.flags = 0;
bookmark.private = NULL;
bookmark.func = NULL;
INIT_LIST_HEAD(&bookmark.entry);
do {
spin_lock_irqsave(&wq_head->lock, flags);
nr_exclusive = __wake_up_common(wq_head, mode, nr_exclusive,
wake_flags, key, &bookmark);
spin_unlock_irqrestore(&wq_head->lock, flags);
} while (bookmark.flags & WQ_FLAG_BOOKMARK);
}
/*
* The core wakeup function. Non-exclusive wakeups (nr_exclusive == 0) just
* wake everything up. If it's an exclusive wakeup (nr_exclusive == small +ve
* number) then we wake all the non-exclusive tasks and one exclusive task.
*
* There are circumstances in which we can try to wake a task which has already
* started to run but is not in state TASK_RUNNING. try_to_wake_up() returns
* zero in this (rare) case, and we handle it by continuing to scan the queue.
*/
static int __wake_up_common(struct wait_queue_head *wq_head, unsigned int mode,
int nr_exclusive, int wake_flags, void *key,
wait_queue_entry_t *bookmark)
{
wait_queue_entry_t *curr, *next;
int cnt = 0;
lockdep_assert_held(&wq_head->lock);
if (bookmark && (bookmark->flags & WQ_FLAG_BOOKMARK)) {
curr = list_next_entry(bookmark, entry);
list_del(&bookmark->entry);
bookmark->flags = 0;
} else
curr = list_first_entry(&wq_head->head, wait_queue_entry_t, entry);
if (&curr->entry == &wq_head->head)
return nr_exclusive;
list_for_each_entry_safe_from(curr, next, &wq_head->head, entry) {
unsigned flags = curr->flags;
int ret;
if (flags & WQ_FLAG_BOOKMARK)
continue;
ret = curr->func(curr, mode, wake_flags, key);
if (ret < 0)
break;
if (ret && (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
if (bookmark && (++cnt > WAITQUEUE_WALK_BREAK_CNT) &&
(&next->entry != &wq_head->head)) {
bookmark->flags = WQ_FLAG_BOOKMARK;
list_add_tail(&bookmark->entry, &next->entry);
break;
}
}
return nr_exclusive;
}
int autoremove_wake_function(struct wait_queue_entry *wq_entry, unsigned mode, int sync, void *key)
{
int ret = default_wake_function(wq_entry, mode, sync, key);
if (ret)
list_del_init_careful(&wq_entry->entry);
return ret;
}
int default_wake_function(wait_queue_entry_t *curr, unsigned mode, int wake_flags,
void *key)
{
WARN_ON_ONCE(IS_ENABLED(CONFIG_SCHED_DEBUG) && wake_flags & ~WF_SYNC);
return try_to_wake_up(curr->private, mode, wake_flags);
}
/**
* try_to_wake_up - wake up a thread
* @p: the thread to be awakened
* @state: the mask of task states that can be woken
* @wake_flags: wake modifier flags (WF_*)
*
* Conceptually does:
*
* If (@state & @p->state) @p->state = TASK_RUNNING.
*
* If the task was not queued/runnable, also place it back on a runqueue.
*
* This function is atomic against schedule() which would dequeue the task.
*
* It issues a full memory barrier before accessing @p->state, see the comment
* with set_current_state().
*
* Uses p->pi_lock to serialize against concurrent wake-ups.
*
* Relies on p->pi_lock stabilizing:
* - p->sched_class
* - p->cpus_ptr
* - p->sched_task_group
* in order to do migration, see its use of select_task_rq()/set_task_cpu().
*
* Tries really hard to only take one task_rq(p)->lock for performance.
* Takes rq->lock in:
* - ttwu_runnable() -- old rq, unavoidable, see comment there;
* - ttwu_queue() -- new rq, for enqueue of the task;
* - psi_ttwu_dequeue() -- much sadness :-( accounting will kill us.
*
* As a consequence we race really badly with just about everything. See the
* many memory barriers and their comments for details.
*
* Return: %true if @p->state changes (an actual wakeup was done),
* %false otherwise.
*/
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
...
抢占任务
非抢占模式的内核
- 在每个定时器中断,内核都去检查当前进程的时间片是否耗尽
- 如果耗尽,就在中断上下文里设置特定的标志位
- 在中断处理快结束的时候,内核检查这个标志位,并且视情况调用schedule()函数
- 这种情况下,在内核中(比如运行系统调用时)任务是非抢占的,所以没有同步问题
抢占模式的内核
这种情况下,即使我们在跑系统调用,也可能被其他线程抢占。抢占的过程需要特殊的同步原语:preempt_disable和preempt_enable。
禁用抢占和自旋锁:为了简化在可抢占内核中的处理,并且考虑到在多处理器(SMP)情况下仍然需要同步机制,当使用自旋锁时,内核会自动禁用抢占。自旋锁是一种锁定机制,它会在某个线程或进程试图获取锁时一直自旋等待,而不是放弃CPU执行权。因此,为了避免多线程竞争条件,内核会禁用抢占,确保在持有自旋锁期间,当前执行的任务不会被抢占。
设置标志和重新启用抢占:如果在执行期间出现需要抢占当前任务的条件,例如当前任务的时间片已经用完,那么会设置一个标志(flag)。当抢占被重新启用时,例如通过执行自旋锁的解锁操作(spin_unlock()),内核会检查这个标志。如果需要抢占,那么调度器会被调用来选择一个新的任务来执行。这意味着内核会在自旋锁解锁的时候检查是否需要切换到其他任务,以确保任务的公平执行和时间片的分配。
进程上下文
我们说内核运行在进程上下文,如果内核在运行系统调用时。
在进程上下文中,我们可以用current宏访问当前进程的信息。
在进程上下文中我们可以sleep()(等待一个特定的条件)
在进程上下文中我们可以访问用户空间(除非我们在内核线程上下文中运行,此时都不涉及用户空间一说)
内核线程
内核核心(kernel core)或设备驱动程序有时需要执行需要阻塞(即等待某些条件满足)的操作。这可能涉及等待硬件设备的数据就绪、等待其他内核线程的完成等。由于这些操作可能导致线程阻塞,因此内核需要一种机制来管理这些线程,以便它们能够以阻塞方式运行。
内核线程是一种特殊类别的任务,它们不会使用用户空间的资源。这意味着它们没有分配给它们的用户地址空间,不会打开用户空间的文件,也不会执行与用户空间相关的系统调用。内核线程的工作完全在内核空间进行,它们主要用于内核内部的任务。