前言
本文将介绍如何使用Scrapy和Selenium这两个强大的Python工具来自动获取个人CSDN文章的质量分数。我们将详细讨论Scrapy爬虫框架的使用,以及如何结合Selenium浏览器自动化工具来实现这一目标。无需手动浏览每篇文章,我们可以轻松地获取并记录文章的质量分数,从而更好地了解我们的博客表现。
CSDN文章质量分查询链接
Scrapy相关基础知识:
爬虫框架Scrapy学习笔记-1
爬虫框架Scrapy学习笔记-2
文章目录
1. Scrapy的安装
首先,我们需要安装Scrapy。建议在单独的虚拟环境中进行安装,你可以使用Virtualenv环境或Conda环境。执行以下命令来安装Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy==2.5.1
pip install pyopenssl==22.0.0
pip install cryptography==36.0.2
scrapy version
scrapy version --verbose
2. Scrapy的工作流程
Scrapy是一个强大的Python爬虫框架,我们可以按照以下步骤来使用它:
2.1 创建项目
使用以下命令创建一个Scrapy项目:
scrapy startproject csdn
2.2 进入项目目录
cd csdn
2.3 生成Spider
生成一个Spider来定义爬取规则:
scrapy genspider cs csdn.net
这将会生成一个Spider文件,你可以在其中定义你的爬取规则。
2.4 调整Spider
在生成的Spider文件中,你需要定义起始URL(start_urls)和如何解析数据的方法(通常是parse函数)。
例如:
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'cs'
allowed_domains = ['csdn.net']
start_urls = ['http://csdn.net/']
def parse(self, response):
pass
2.5 调整Settings配置
在项目目录中的settings.py文件中,你可以调整各种配置选项。
以下是一些需要调整的配置选项:
- LOG_LEVEL:设置日志级别,你可以将其设置为"WARNING"以减少日志输出。
LOG_LEVEL = "WARNING"
- ROBOTSTXT_OBEY:设置是否遵守Robots协议,如果你不希望爬虫遵守Robots协议,可以将其设置为False。
ROBOTSTXT_OBEY = False
- ITEM_PIPELINES:打开管道以处理爬取的数据,你可以配置不同的管道来处理不同类型的数据。
ITEM_PIPELINES = {
'csdn.pipelines.CsdnPipeline': 300,
}
2.6 运行Scrapy程序
使用以下命令来运行Scrapy程序:
scrapy crawl csdn
2.7 找URL
在这一步,我们需要找到用于获取文章数据的URL。可以通过以下步骤来找到URL:
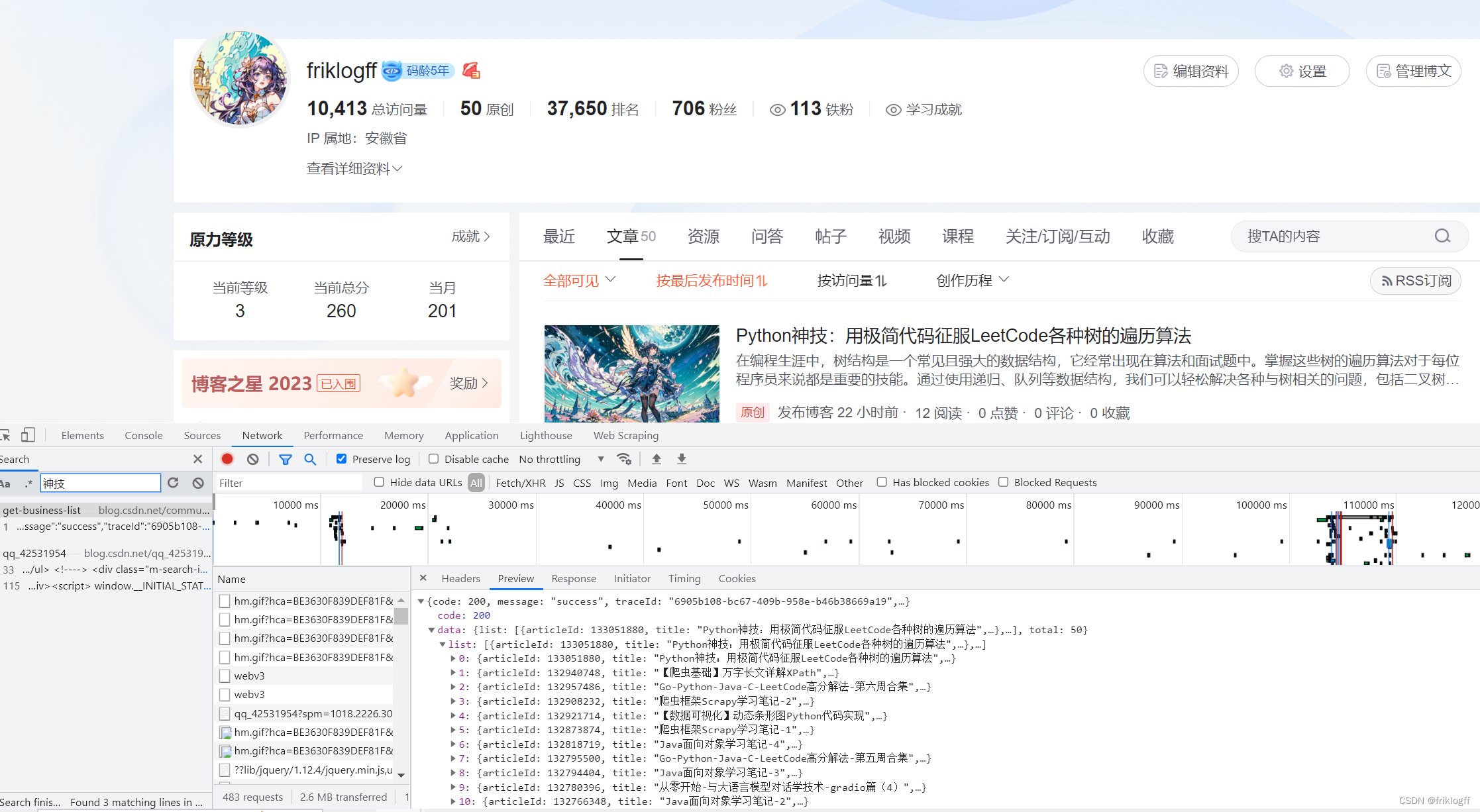
我们可以先点开搜索按钮预设一个搜索值
然后在Fetch/XHR或JS中逐个点,加载出来就会在左侧被搜索到

这里我们最终在header中找到这个连接,我们会发现其实链接是通用的,你可以跳过上一步直接使用这个连接,只需要替换你的username
https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_42531954
另外,这里page=1&size=20,当你的文章大于20篇,你可以调整size,这里我刚好有50篇,于是我调整size=50
2.8 查看处理 response,交给管道
import scrapy
class CsSpider(scrapy.Spider):
name = 'cs'
allowed_domains = ['csdn.net']
start_urls = ['https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=50&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_42531954']
def parse(self, response):
print(response.text)
分析response.text,发现返回值为字典
稍作处理后传递给管道
import scrapy
class CsSpider(scrapy.Spider):
name = 'cs'
allowed_domains = ['csdn.net']
start_urls = ['https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=50&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_42531954']
def parse(self, response):
# print(response.text)
data_list = response.json()["data"]["list"]
for data in data_list:
url = data["url"]
title = data["title"]
yield {
# 宁典可以充当item -> dict
"url": url,
"title": title
}
csdn/csdn/pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class CsdnPipeline:
def process_item(self, item, spider):
print("我是管道,我看到的东西是", item)
with open("data.csv", mode="a", encoding="utf-8") as f:
f.write(f"{item['url']},{item['title']}\n")
return item
3. 使用Selenium获取质量分数
如果你的chromedriver出现问题,你可以从这里找到解决方案
自动化管理chromedriver-完美解决版本不匹配问题
以下是使用Selenium的代码示例:
import csv
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
option = Options()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--disable-blink-features=AutomationControlled')
option.add_argument('--headless') # 启用无头模式
driver = webdriver.Chrome(options=option)
# 用于存储CSV数据的列表
data = []
#
# 打开CSV文件并读取内容
with open('data.csv','r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
# 每行包括两个字段:链接和标题
link, title = row
# 将链接和标题作为元组添加到数据列表中
data.append((link, title))
# 使用浏览器访问网页
driver.get("https://www.csdn.net/qc")
for link,title in data:
driver.find_element(By.CSS_SELECTOR, ".el-input__inner").send_keys(f"{
link}",link)
driver.find_element(By.CSS_SELECTOR, ".trends-input-box-btn").click()
time.sleep(0.5)
soc = driver.find_element(By.XPATH, '//*[@id="floor-csdn-index_850"]/div/div[1]/div/div[2]/p[1]').text
print(title,soc)
time.sleep(1)
driver.quit()
这段代码是一个Python脚本,使用了CSV模块和Selenium库来自动化获取CSDN文章的质量分数。下面我将逐行详细解释这段代码的功能和作用:
- 导入必要的库:
import csv
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
这里导入了CSV模块(用于读取CSV文件)、time模块(用于添加延迟等待)、以及Selenium相关的模块和类。
- 配置Selenium选项:
option = Options()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--disable-blink-features=AutomationControlled')
option.add_argument('--headless') # 启用无头模式
这部分代码配置了Selenium的选项。其中,Options是用于配置Chrome浏览器的选项,add_experimental_option用于设置Chrome的实验性选项,以避免被检测为自动化程序。--disable-blink-features=AutomationControlled用于禁用某些自动化特性,而--headless则启用了无头模式,使得浏览器在后台运行,不会显示界面。
- 创建Chrome WebDriver实例:
driver = webdriver.Chrome(options=option)
这里创建了一个Chrome WebDriver实例,使用了上述配置选项。WebDriver将用于模拟浏览器操作。
- 创建一个空列表用于存储数据:
data = []
这个列表将用于存储从CSV文件中读取的数据。
- 打开CSV文件并读取内容:
with open('data.csv', 'r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
link, title = row
data.append((link, title))
这部分代码使用open函数打开名为"data.csv"的CSV文件,并使用csv.reader来读取文件的内容。每一行都包括两个字段:链接和标题,这些数据被添加到之前创建的data列表中。
- 使用浏览器访问网页:
driver.get("https://www.csdn.net/qc")
这行代码使用WebDriver打开了CSDN网站的首页,准备开始搜索文章的质量分数。
- 迭代处理CSV文件中的每一行数据:
for link, title in data:
driver.find_element(By.CSS_SELECTOR, ".el-input__inner").send_keys(f"{
link}", link)
driver.find_element(By.CSS_SELECTOR, ".trends-input-box-btn").click()
time.sleep(0.5)
soc = driver.find_element(By.XPATH, '//*[@id="floor-csdn-index_850"]/div/div[1]/div/div[2]/p[1]').text
print(title, soc)
time.sleep(1)
在这个循环中,我们对CSV文件中的每一行数据执行以下操作:
- 使用
driver.find_element通过CSS选择器定位搜索框,并在搜索框中输入文章链接。 - 使用
driver.find_element定位搜索按钮,并模拟点击搜索按钮。 - 延迟0.5秒以等待页面加载完毕。
- 使用XPath表达式定位质量分数元素,并提取其文本内容。
- 打印文章标题和质量分数。
- 延迟1秒以确保不会频繁访问网站。
- 最后,使用
driver.quit()关闭浏览器窗口,释放资源。
这段代码的主要作用是自动化地访问CSDN网站,搜索文章链接,提取文章的质量分数,并将结果打印出来。这对于批量获取文章质量分数非常有用,而无需手动一个个查看。
当然,我将为你添加前言、摘要和总结来完善这篇文章。
总结
通过本文的学习,你将掌握使用Scrapy和Selenium自动获取个人CSDN文章质量分数的技能。这将帮助你更好地了解你的博客表现,以及哪些文章受到了更多的关注和评价。
同时,你也学到了如何设置Scrapy爬虫项目,配置爬虫规则,以及如何处理数据。这些技能对于进行各种网络数据采集任务都是非常有用的。
希望本文对你的网络数据采集和分析工作有所帮助,让你能够更好地理解你的读者和观众。如果你有任何问题或疑问,欢迎提出,我们将竭诚为你提供帮助。