note
- 一些大模型的评估基准benchmark:
- 多轮:MTBench
- 关注评估:agent bench
- 长文本评估:longbench,longeval
- 工具调用评估:toolbench
- 安全评估:cvalue,safetyprompt等
文章目录
常见评测benchmark
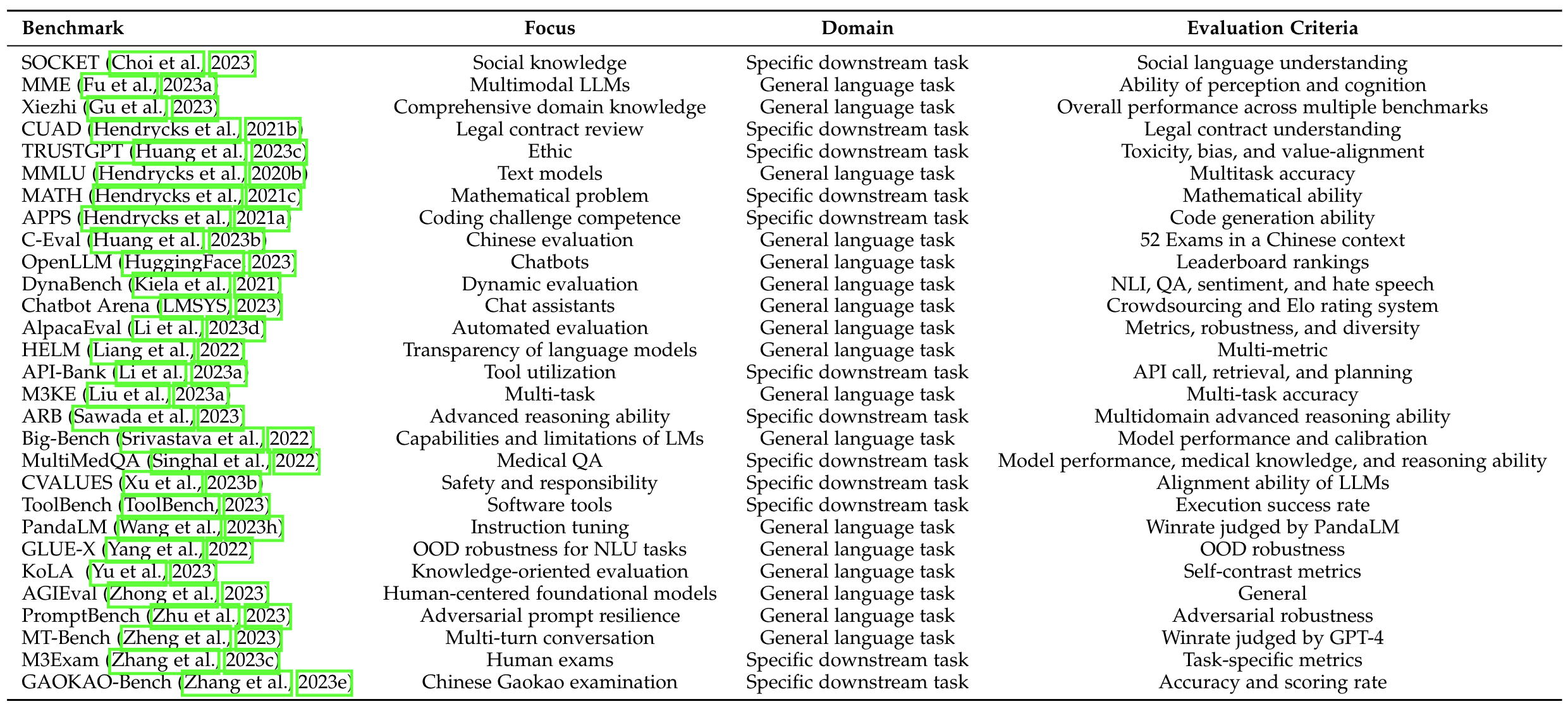
图源自《A Survey on Evaluation of Large Language Models》
以下的几个指标都是chatglm2使用到的评估指标:
MMLU
| Model | Average | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|
| ChatGLM-6B | 40.63 | 33.89 | 44.84 | 39.02 | 45.71 |
| ChatGLM2-6B (base) | 47.86 | 41.20 | 54.44 | 43.66 | 54.46 |
| ChatGLM2-6B | 45.46 | 40.06 | 51.61 | 41.23 | 51.24 |
Chat 模型使用 zero-shot CoT (Chain-of-Thought) 的方法测试,Base 模型使用 few-shot answer-only 的方法测试
SuperCLUE:中文通用大模型综合性评测基准
- 项目链接:
- SuperCLUE :https://github.com/CLUEbenchmark/SuperCLUE
- SuperCLUE琅琊榜:https://github.com/CLUEbenchmark/SuperCLUElyb
- 网站:https://www.cluebenchmarks.com/
- SuperCLUE从三个不同的维度评价模型的能力:基础能力、专业能力和中文特性能力。SuperCLUE的特点包括:多个维度能力考察(3大类,70+子能力)、
自动化测评(一键测评)、广泛的代表性模型(9个模型)、人类基准。
SuperCLUE琅琊榜还有一些不同模型之间的对战获胜数据(如下图),考虑到gpt3.5训练语料中中文语料不多,比某些国产大模型要稍逊色也是可以理解的:

知识评估:C-Eval
C-Eval
项目链接:
如果是做题问答,可以用Ceval指标,chatglm2-6b项目中就有代码
我们选取了部分中英文典型数据集进行了评测,以下为 ChatGLM2-6B 模型在 MMLU (英文)、C-Eval(中文)、GSM8K(数学)、BBH(英文) 上的测评结果。在 evaluation 中提供了在 C-Eval 上进行测评的脚本。
| Model | Average | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|
| ChatGLM-6B | 38.9 | 33.3 | 48.3 | 41.3 | 38.0 |
| ChatGLM2-6B (base) | 51.7 | 48.6 | 60.5 | 51.3 | 49.8 |
| ChatGLM2-6B | 50.1 | 46.4 | 60.4 | 50.6 | 46.9 |
Chat 模型使用 zero-shot CoT 的方法测试,Base 模型使用 few-shot answer only 的方法测试
类似的知识类评估基准还有:
GSM8K
8.5k高质量的小学数学应用题
| Model | Accuracy | Accuracy (Chinese)* |
|---|---|---|
| ChatGLM-6B | 4.82 | 5.85 |
| ChatGLM2-6B (base) | 32.37 | 28.95 |
| ChatGLM2-6B | 28.05 | 20.45 |
所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 http://arxiv.org/abs/2201.11903
* 我们使用翻译 API 翻译了 GSM8K 中的 500 道题目和 CoT prompt 并进行了人工校对
BBH
| Model | Accuracy |
|---|---|
| ChatGLM-6B | 18.73 |
| ChatGLM2-6B (base) | 33.68 |
| ChatGLM2-6B | 30.00 |
所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 https://github.com/suzgunmirac/BIG-Bench-Hard/tree/main/cot-prompts
工具学习:ToolBench
链接:https://github.com/OpenBMB/ToolBench
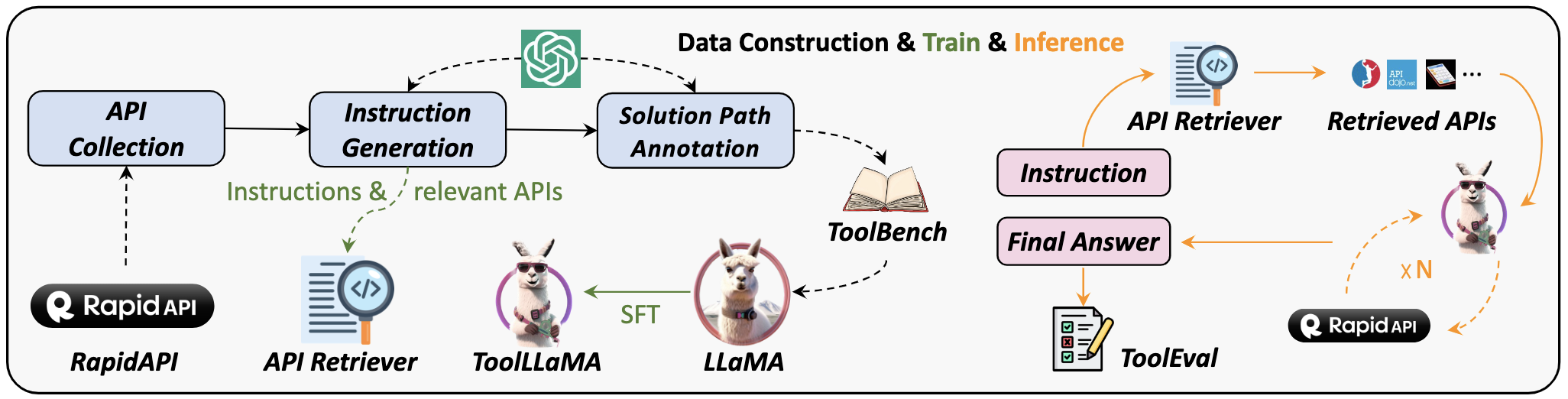
ToolBench的总体思路是基于BMTools,在有监督数据中训练大型语言模型。
1. 项目内容
ToolBench仓库中提供了相关数据集、训练和评估脚本,以及在ToolBench上微调的功能模型ToolLLaMA,具体特点为:
- 支持单工具和多工具方案
其中单工具设置遵循LangChain提示风格,多工具设置遵循AutoGPT的提示风格。
-
模型回复不仅包括最终答案,还包含模型的思维链过程、工具执行和工具执行结果
-
支持真实世界级别的复杂性,支持多步工具调用
-
丰富的API,可用于现实世界中的场景,如天气信息、搜索、股票更新和PowerPoint自动化
-
所有的数据都是由OpenAI API自动生成并由开发团队进行过滤,数据的创建过程很容易扩展
2. 评估方法
- 机器评估:研究人员对每个工具随机抽取100个链步(chain steps)来构建机器评估测试平台,平均27个最终步骤和73个中间工具调用步骤,其中最终步骤的评估使用Rouge-L指标,中间步骤的评估使用ExactMatch指标进行评估。
- 人工评估:在天气、地图、股票、翻译、化学和WolframAlpha工具中随机抽取10个query,然后评估工具调用过程的通过率、最终答案以及和ChatGPT最终答案的比较。
- ChatGPT评估:通过ChatGPT对LLaMA和ChatGPT的答案和工具使用链进行自动评估。
3. 工具学习的研究
论文:https://arxiv.org/pdf/2304.08354.pdf
包括工具增强型和工具导向型学习,并制定了一个通用的工具学习框架:从理解用户指令开始,模型应该学会把一个复杂的任务分解成几个子任务,通过推理动态地调整计划,并通过选择合适的工具有效地征服每个子任务。
factool
https://github.com/GAIR-NLP/factool
zhenbench case
https://github.com/zhenbench/zhenbench
使用gpt进行评估模型
东南大学:https://arxiv.org/abs/2303.07992
评估框架由两个主要步骤组成:
- 首先,受HELM[21]的场景驱动评估策略的启发,我们设计了一种基于特征的多标签注释方法来标记测试问题中涉及的答案类型、推理操作和语言。这些标签不仅有助于我们逐个分析ChatGPT的推理能力,而且它们的组合也可以帮助我们发现许多ChatGPT擅长或不擅长的潜在QA场景。
- 然后,遵循CheckList[22]的测试规范,测试目标分为三个部分:最小功能测试(MFT)、不变性测试(INV)和方向性期望测试(DIR)。
- 第一个反映了模型执行各种推理任务的准确性,
- 而第二个和第三个反映了推理的可靠性。
- 为了在INV和DIR测试中获得更多可分析的结果,我们采用了Chain-of-Thought(CoT)[5]方法,设计提示模板以建立其他测试用例。
FlagEval天秤
1. 项目内容
- 项目链接:
- 项目地址:https://github.com/FlagOpen/FlagEval
- 网站:https://flageval.baai.ac.cn/
- 由智源研究院将联合多个高校团队打造,是一种采用“能力—任务—指标”三维评测框架的大模型评测平台,旨在提供全面、细致的评测结果。该平台已提供了 30 多种能力、5 种任务和 4 大类指标,共 600 多个维度的全面评测,任务维度包括 22 个主客观评测数据集和 84433 道题目。
2. 能力框架
能力框架:刻画模型认知能力边界
- 基础语言能力:简单理解(信息分析、提取概括、判别评价等)、知识运用(知识问答、常识问答、事实问答)推理能力(知识推理、符号推理)。
- 高级语言能力:特殊生成(创意生成、代码生成、风格生成,修改润色等)、语境理解(语言解析、情境适应、观点辨析等)。
- 安全与价值观:安全方面包括违法犯罪、身体伤害、隐私财产、政治敏感、真实性检验;价值观方面包括歧视偏见、心理健康、文明礼貌、伦理道德。
- 综合能力:通用综合能力、领域综合能力。

具体的指标
rouge指标
ROUGE-1、ROUGE-2、ROUGE-L和 BERTScore
- ROUGE指标是在机器翻译、自动摘要、问答生成等领域常见的评估指标。ROUGE通过将模型生成的摘要或者回答与参考答案(一般是人工生成的)进行比较计算得到得分。
- 一般看f值,f是取了f和r的调和平均值
- 下面的
rouge包不能直接使用中文文本,需要分词后使用,如果文本长度不长时可以手动修改,如“你好吗”改为“你 好 吗”
from rouge import Rouge
hypothesis = "the #### transcript is a written version of each day 's cnn student news program use this transcript to he lp students with reading comprehension and vocabulary use the weekly newsquiz to test your knowledge of storie s you saw on cnn student news"
reference = "this page includes the show transcript use the transcript to help students with reading comprehension and vocabulary at the bottom of the page , comment for a chance to be mentioned on cnn student news . you must be a teac her or a student age # # or older to request a mention on the cnn student news roll call . the weekly newsquiz tests students ' knowledge of even ts in the news"
rouger = Rouge()
scores = rouger.get_scores(hypothesis, reference)
[
{
"rouge-1": {
"f": 0.4786324739396596,
"p": 0.6363636363636364,
"r": 0.3835616438356164
},
"rouge-2": {
"f": 0.2608695605353498,
"p": 0.3488372093023256,
"r": 0.20833333333333334
},
"rouge-l": {
"f": 0.44705881864636676,
"p": 0.5277777777777778,
"r": 0.3877551020408163
}
}
]
其他人工评估指标
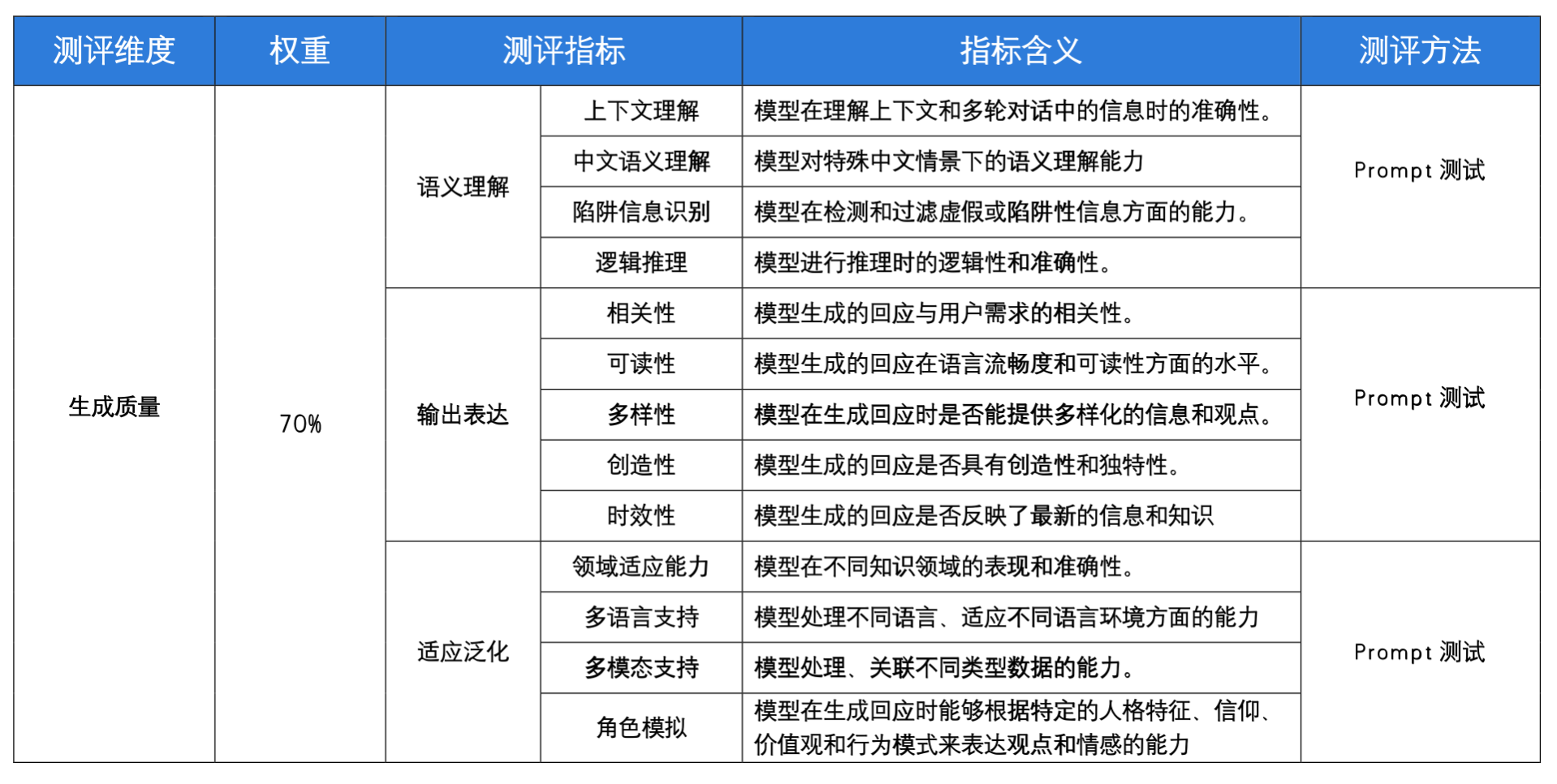
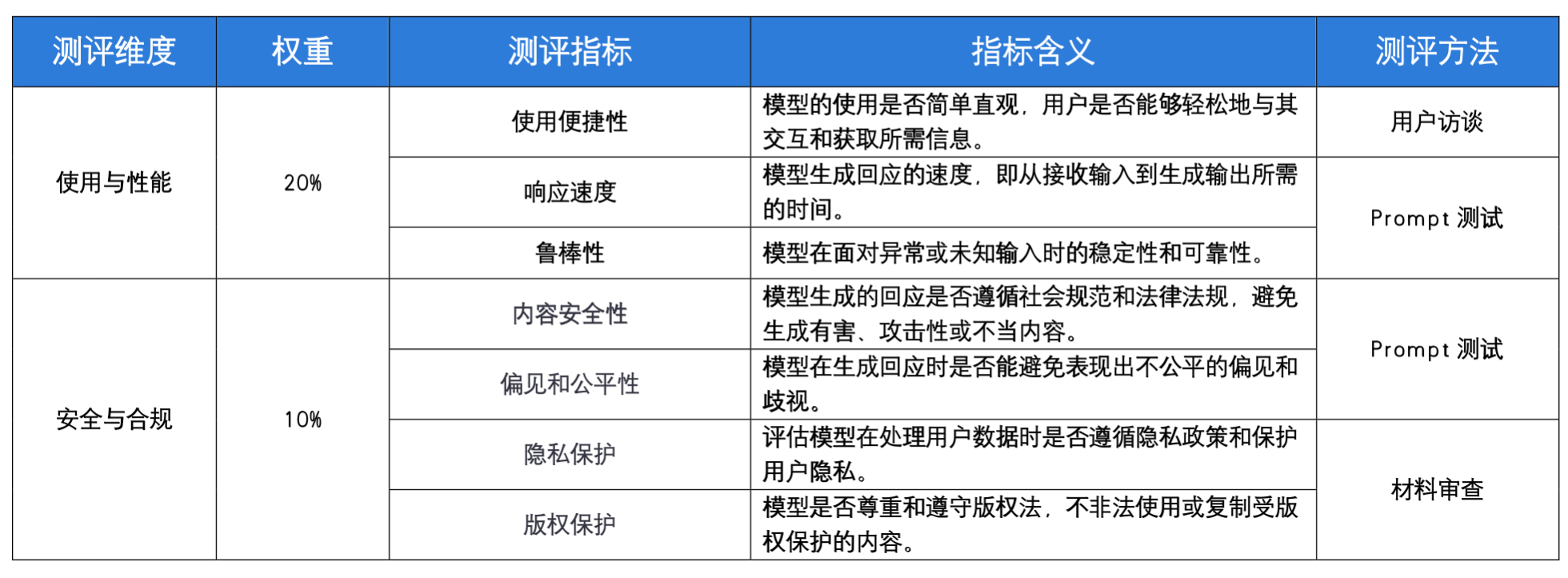
注:“领域适应能力”测试中的知识领域包括,代码编程、数学计算、创意写作、舆情分析、医学咨询、历史知识、法律信息、科学解释、翻译。
测评结果:
 总得分率=生成质量70%+使用与性能20%+安全与合规*10%,评估截止日期为2023年6月30日。
总得分率=生成质量70%+使用与性能20%+安全与合规*10%,评估截止日期为2023年6月30日。
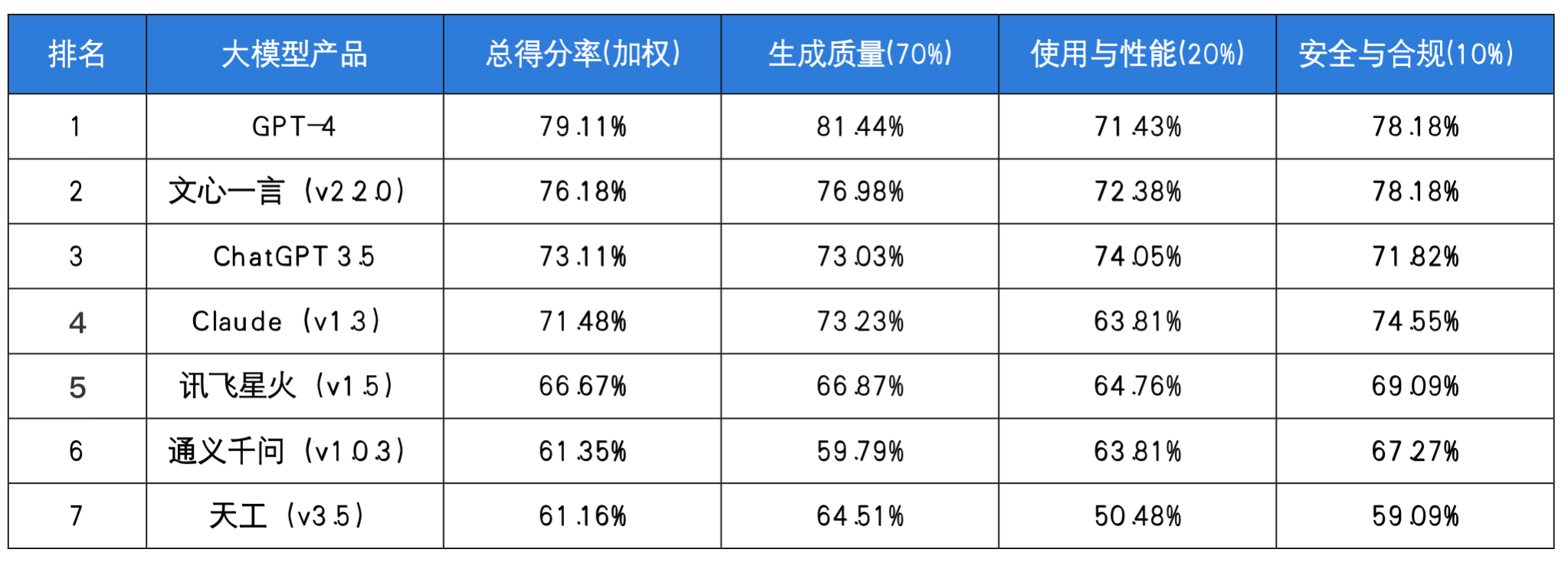
评估后的大模型选择:
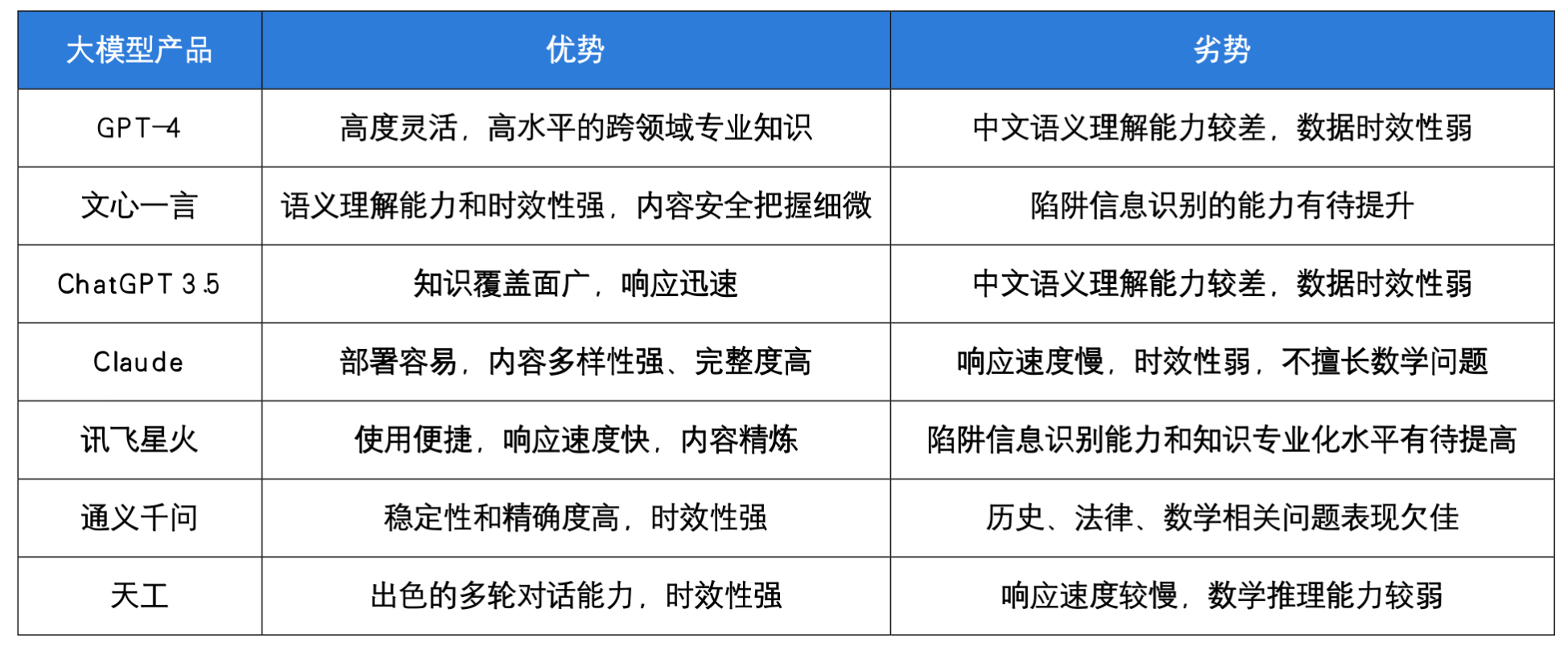
相关排行榜
LMSYS、c-Eval、SuperCLUElyb、PubMedQA排行榜
大模型的[知识]和[推理]能力
[知识]和[推理]是两项可以显著区分大小模型的能力,其中
- 知识型的能力是模型能力的基础,推理能力是进一步的升华
- [推理]能力的区分度是最高的,比如说gsm8k这个数据集,GPT492分,LLaMA7b只有七分,模型每大一点基本上都是十几二十分的差距;
- [知识]的区分度没有[推理]这么高,但也很高;这里面模型每大一个台阶基本上是五六分的差距;
- [推理]能力小的模型基本没有,很多时候acc只有个位数;
- [知识]能力小模型也会有一点,比如MMLU上11Bflant5也有40+;
关于英文推理能力的benchmark,可以参见https://github.com/FranxYao/chain-of-thought-hub)
Reference
[1] ROUGE: A Package for Automatic Evaluation of Summaries
[2] NLP评估指标之ROUGE
[3] 大模型评测综述:A Survey on Evaluation of Large Language Models
[4] 目前大语言模型的评测基准有哪些-某乎
[5] ChatGPT作为知识库问答系统的问答能力评测
[6] C-Eval: 构造中文大模型的知识评估基准
[7] FlagEval 天秤大模型评测体系及开放平台,打造更全面的引领性评测基准
[8] SuperCLUE琅琊榜:https://www.superclueai.com/