我是一个00后的老程序员,半夜00点有个Python群友发来一个题目,我以为是leetcode算法题呢,这不轻而易举、手到擒来、简简单单、有手就行,哪怕是博利叶排序我也能招架得住啊,结果发来一个链接。
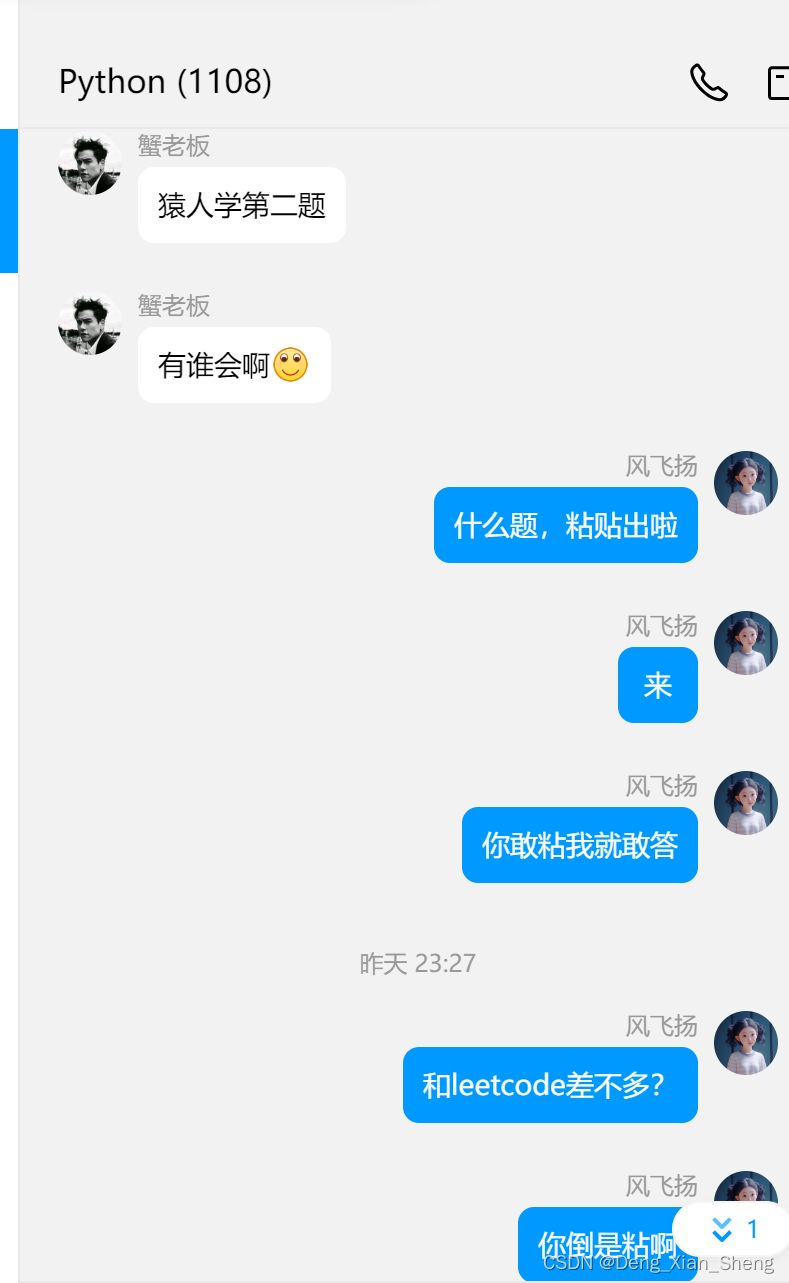
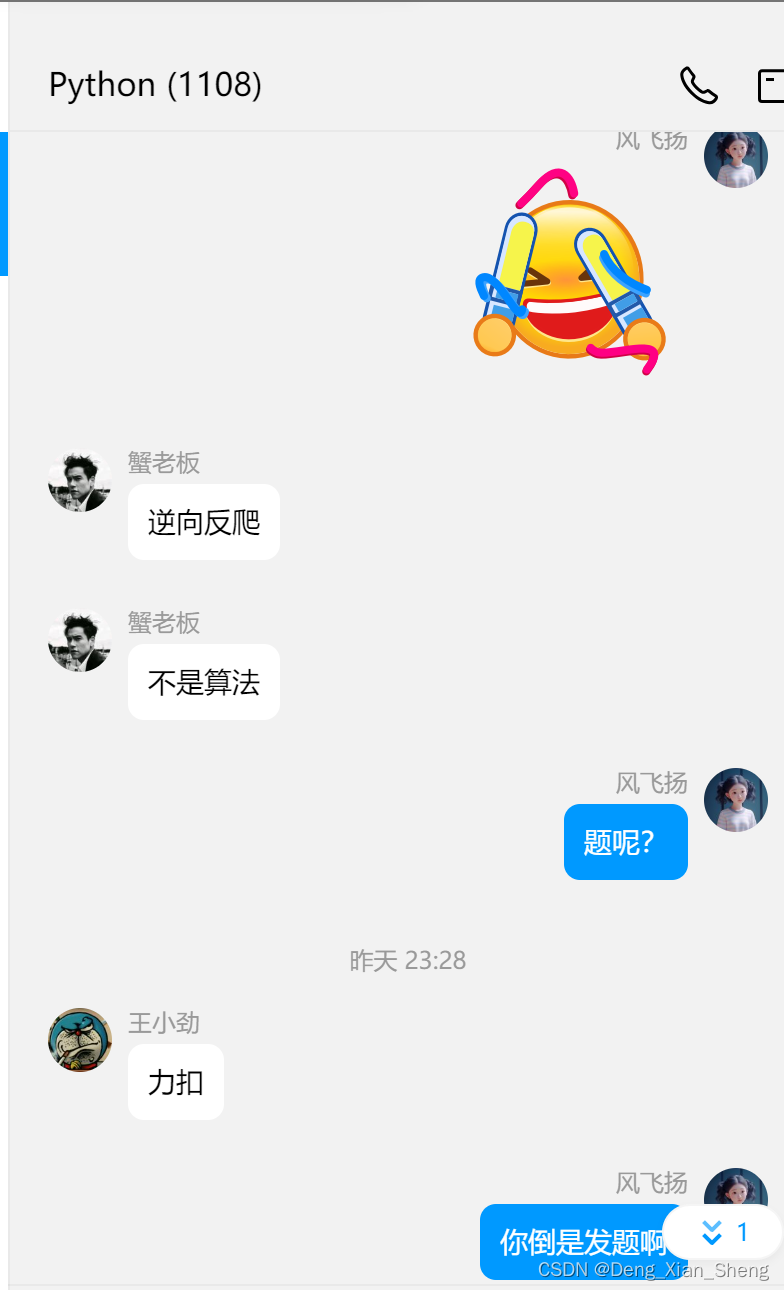
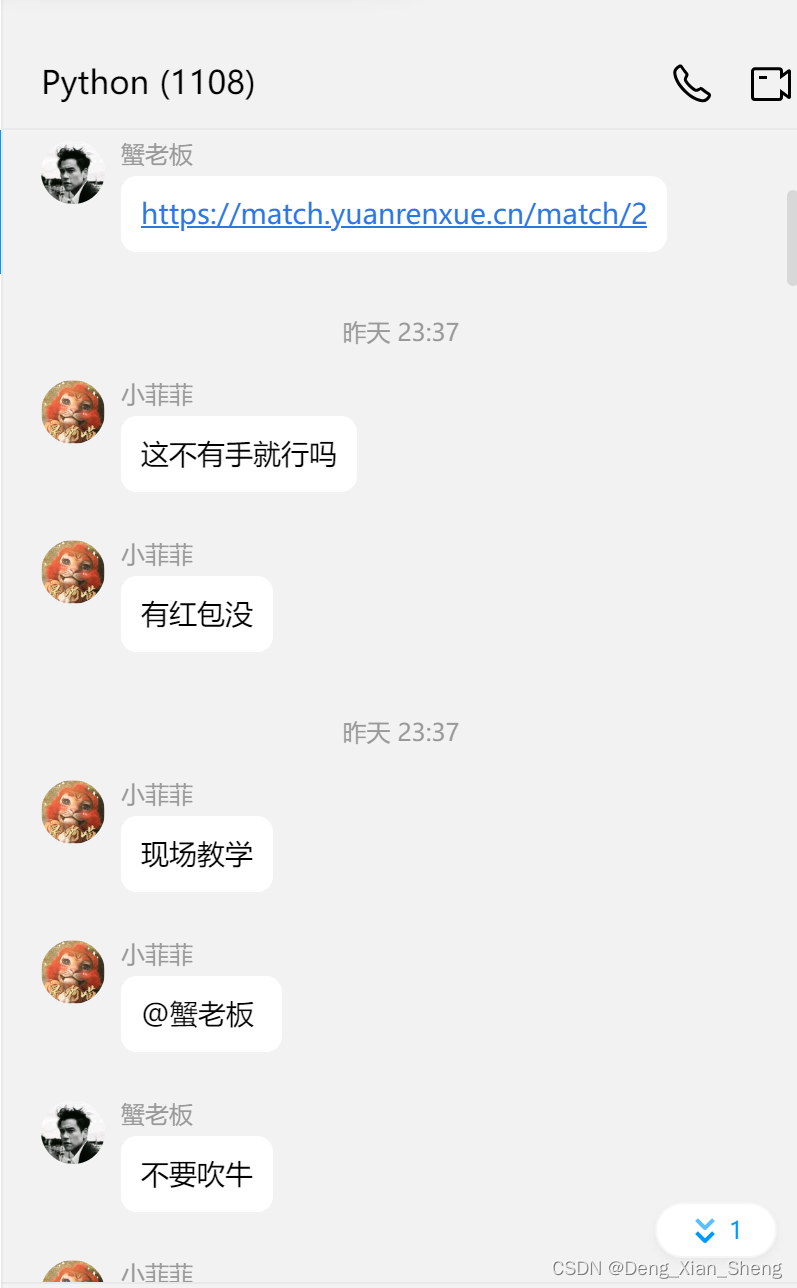
题发出来了,做这个题花了约2个小时半。
这是做完截的图
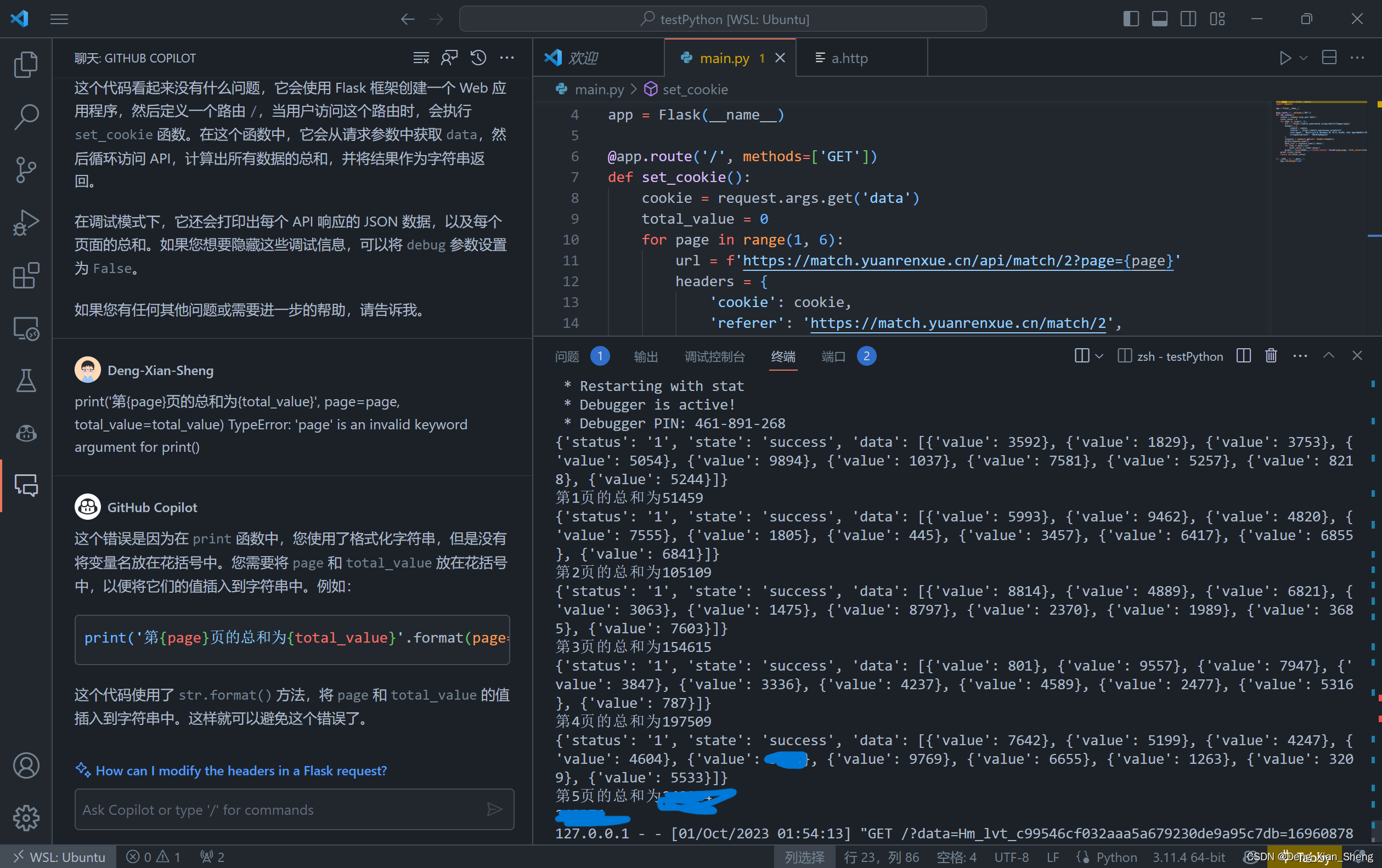
说说我的思路:
首先我刚看到页面,非常简陋。
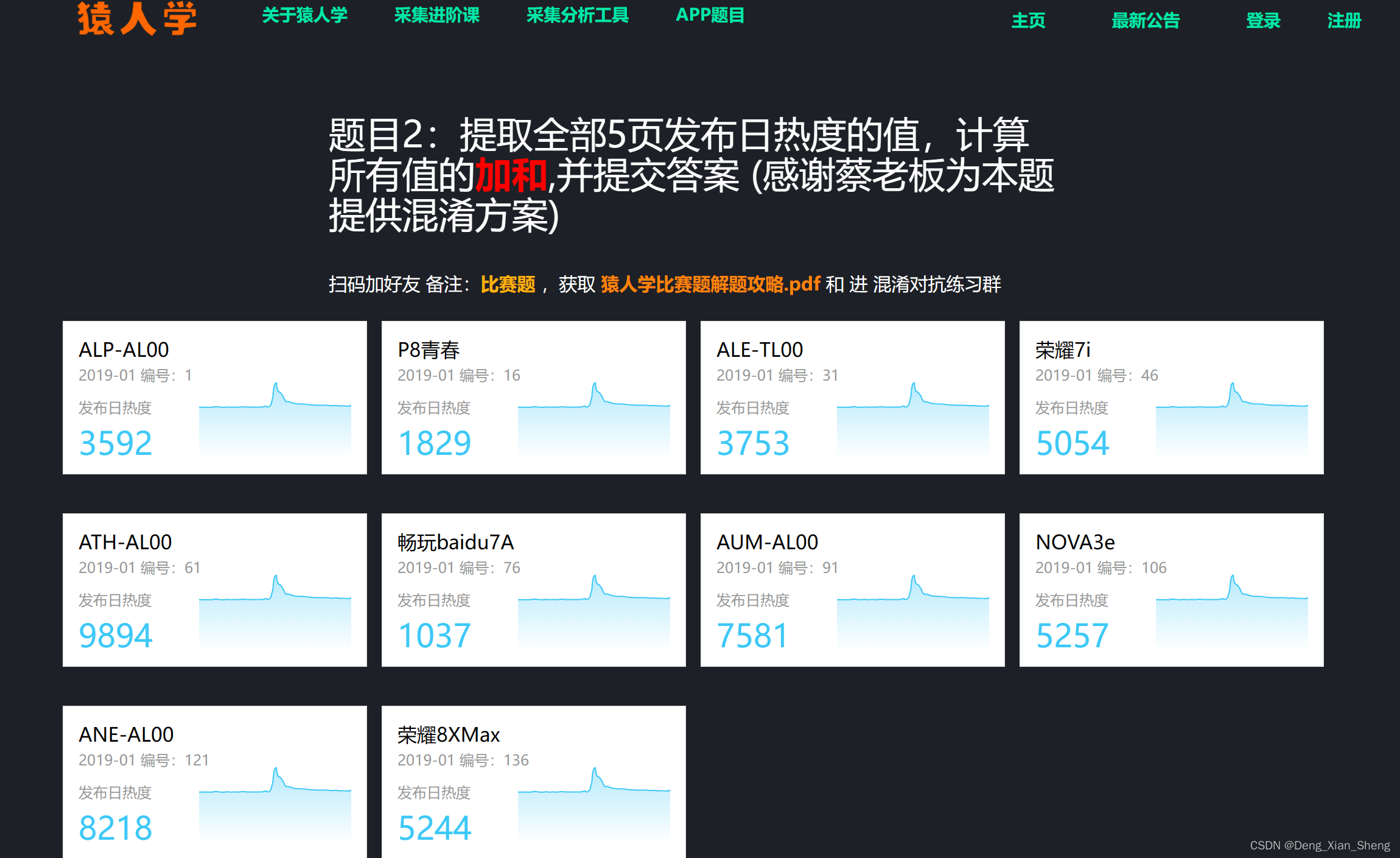
看了看题目,让我拿1~5页的数据
打开检查元素,发现请求接口获取的数据,page1~5
发现需要cookie
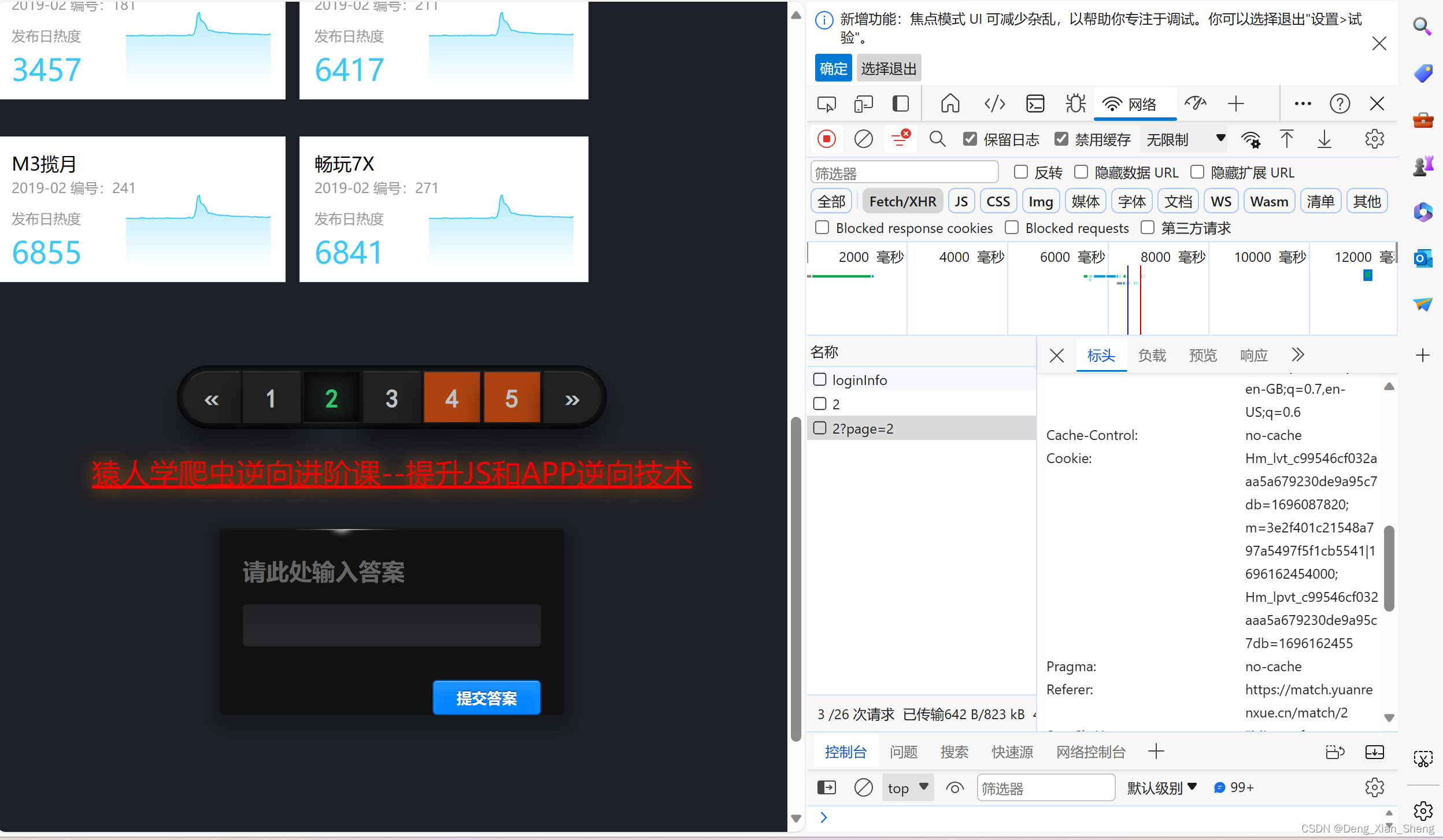
发现cookie超时非常短

于是打开刷新页面看看后端如何返回的cookie,一般情况下都是Set-Cookie Header头,但是它没有。
有趣的是这个页面是加了防debug的,我直接用edge给他关了。
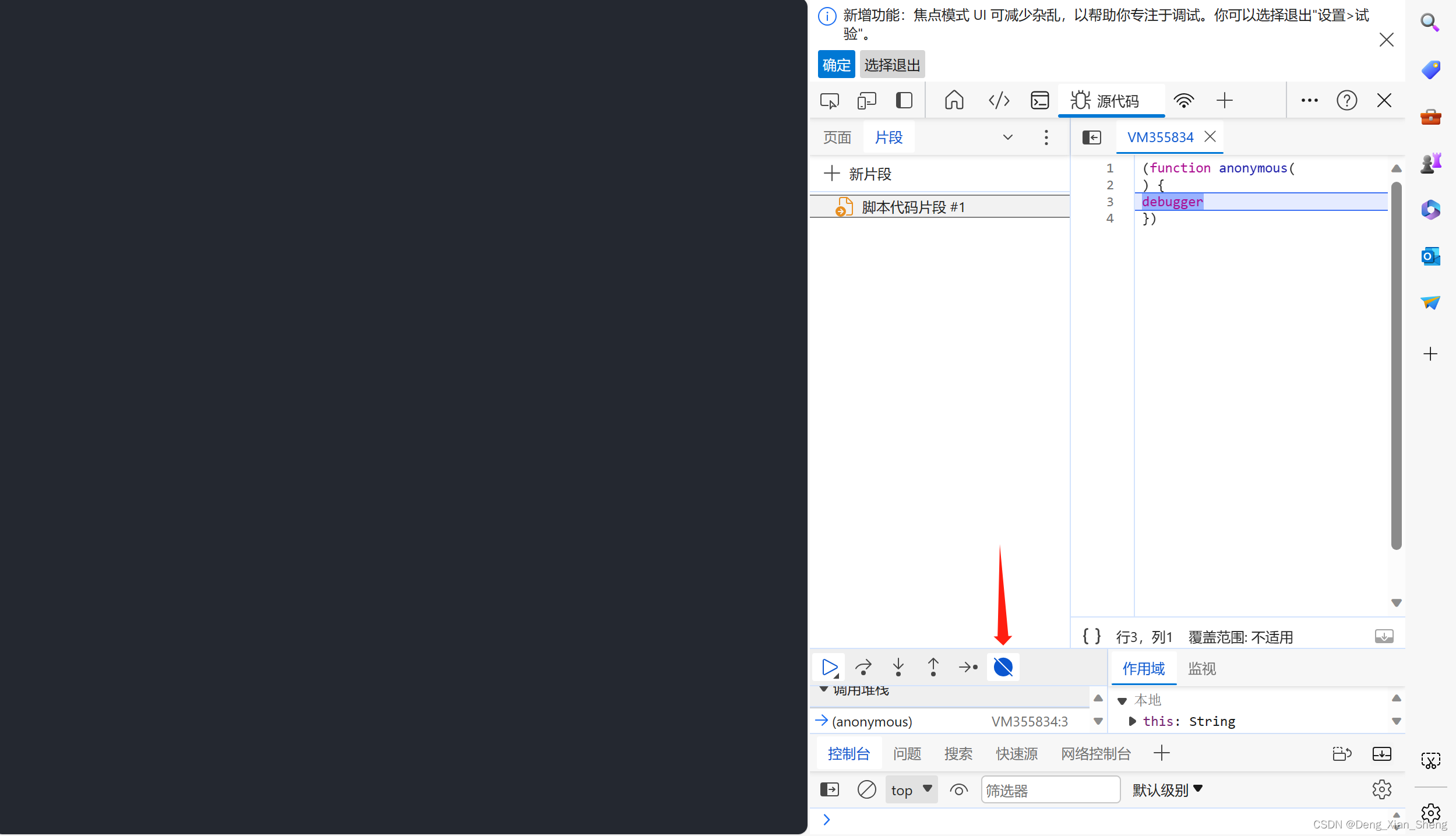
于是,我测试接口,发现提示cookie超时与后端有关,我以为是前端判断(因为cookie是前端生成的),那么,cookie肯定通过某种方式注册到了后端
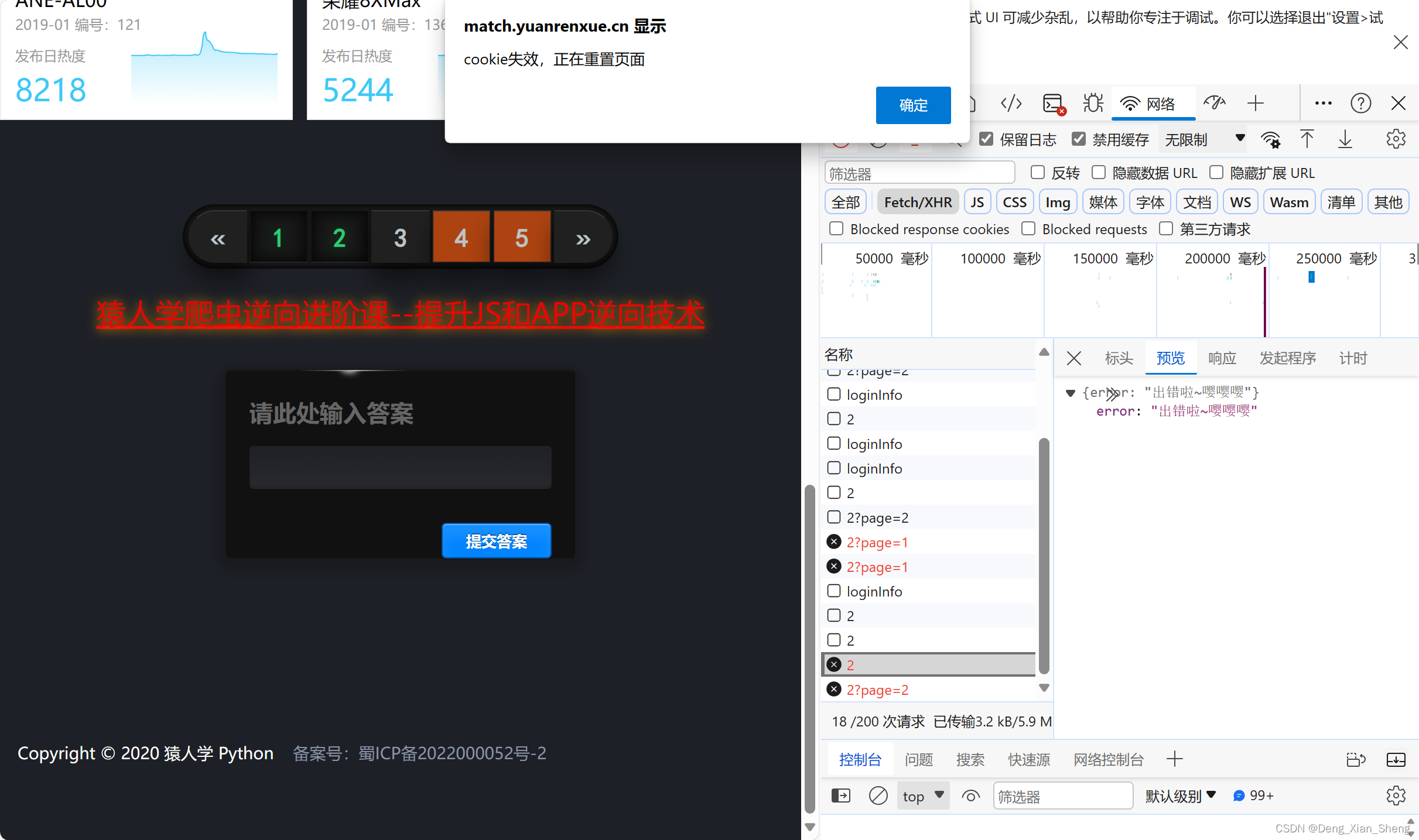
发现有个loginInfo接口,我以为是cookie注册的接口,然后我尝试调用该接口,设置Header头的cookie为随意值,发现并不是,我设置的随意的cookie并不生效,不知道用来干嘛的。
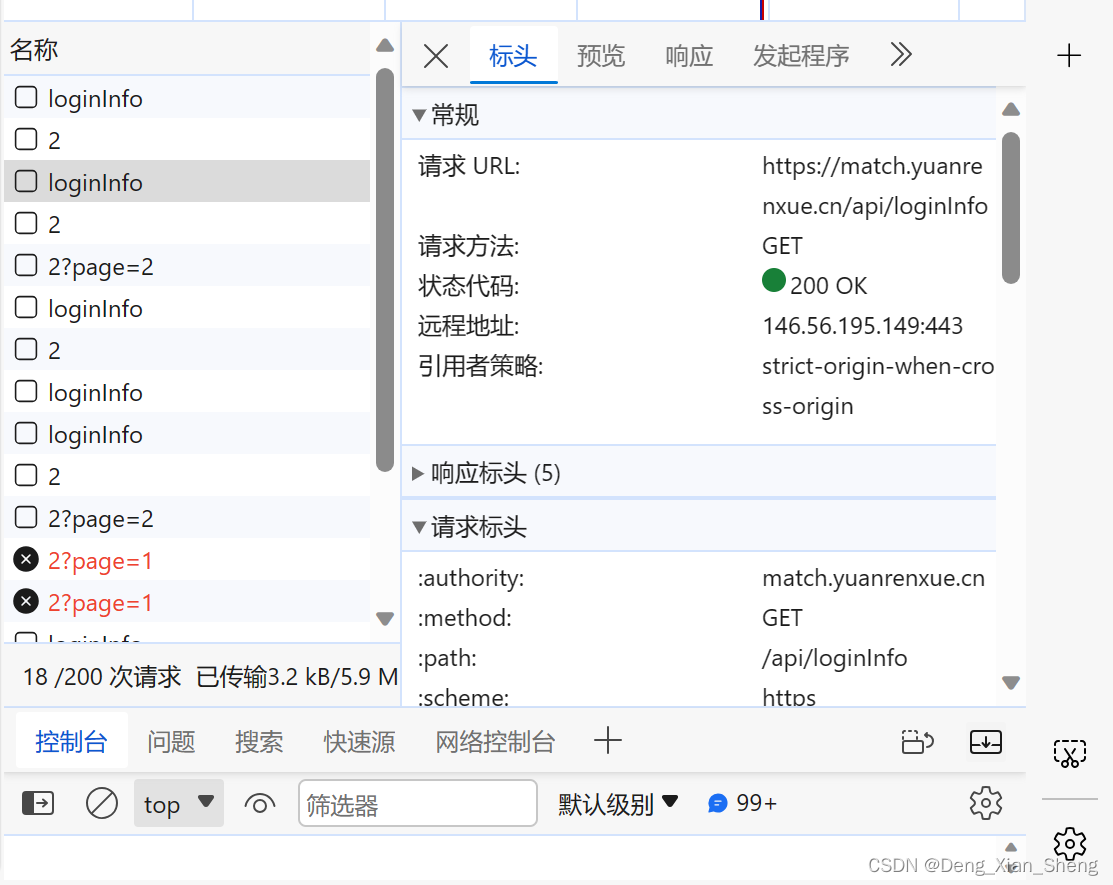
ps:貌似请求列表的接口会延长cookie超时时间,但是仍然会超时(最大超时时间)而不请求列表,超时会更快。
此时我有点儿焦躁了,因为我需要通过对方的js获取cookie生成逻辑。
找到了jquery.cookie.mini.js我一看,这简单啊,老方法,先用edge本地替换该js,然后修改该js代码打印cookie出来看看,再说下一步。
使用本地副本替代网页资源 (“替代”选项卡)
ps:为什么说老方法,之前破解一个前端接口传参都加密的网站,那个网站调用了加密库,我直接替换加密库,把密码打印了出来。
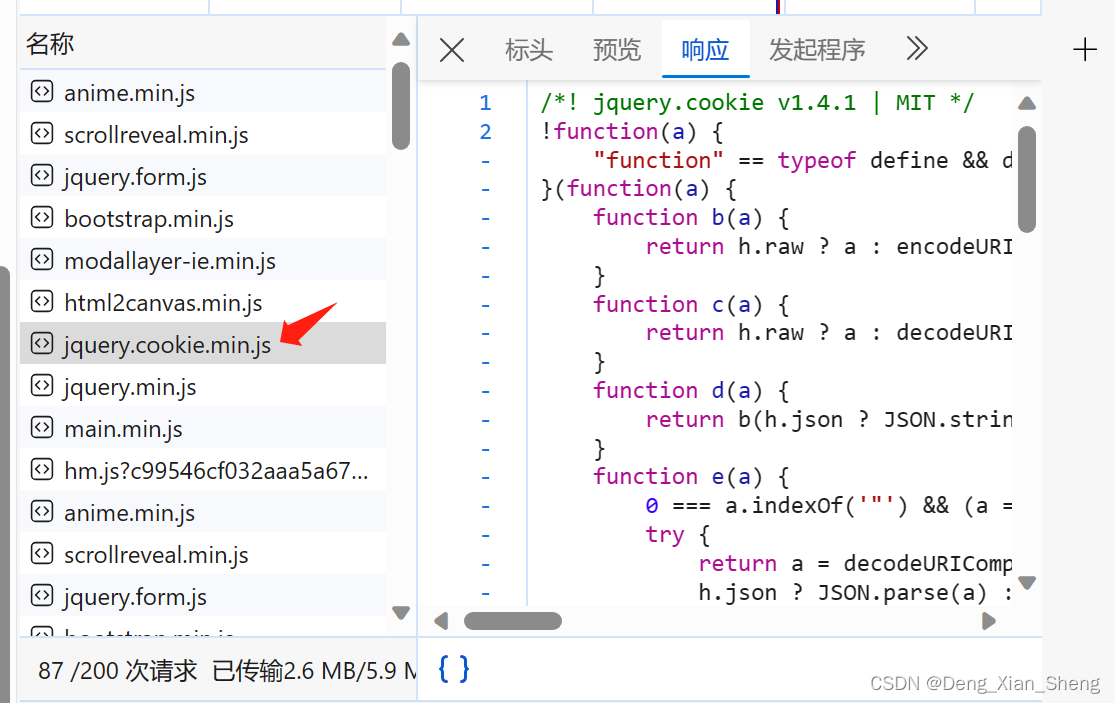
但是我发现,设置cookie的代码没调用这个js文件。
此时我计划落空,非常焦躁。
然后,我还点击了4和5页,弹出一堆话,让我设置什么。没看懂。
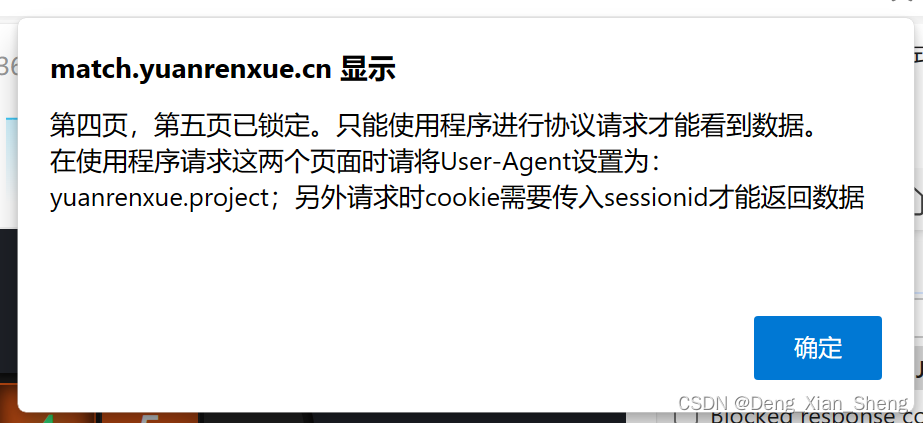
ps:我找到了除jquery.cookie.mini.js之外的另一个可能携带cookie生成逻辑的js文件,但是那个js很长,这种题,实在是没有什么大兴趣逆向那么大的js。要是有个小姐姐奖励我或许可以考虑。
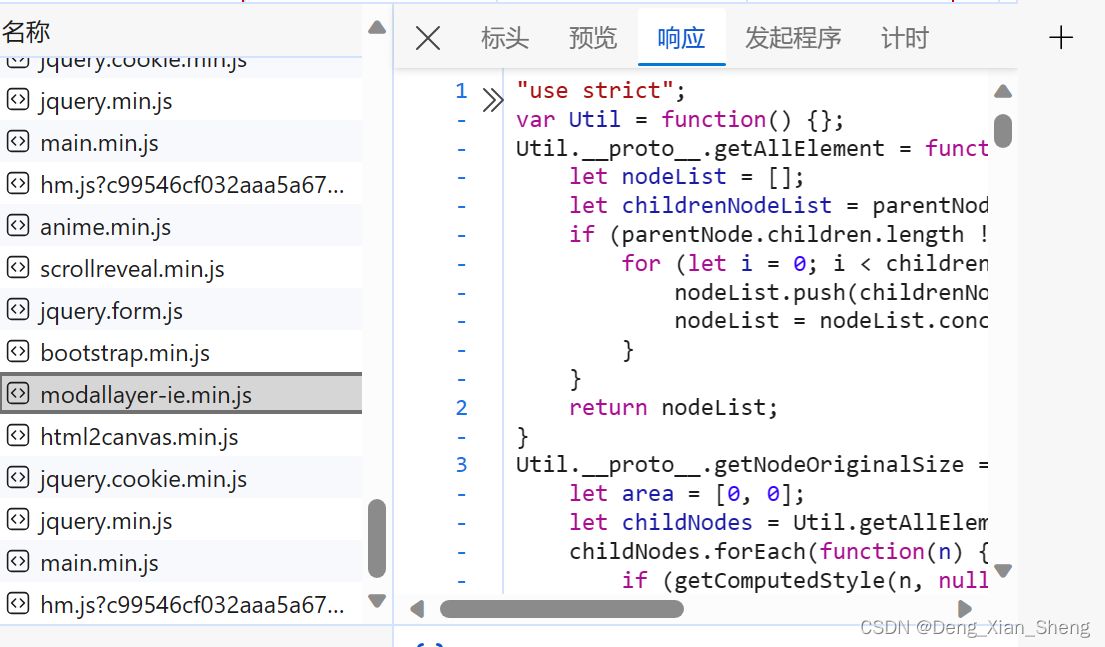
现在来看,也许逻辑就在html里的script标签,这也说不定。
我又想到了一个鬼点子,我写了个js,会获取cookie发送到一个服务。
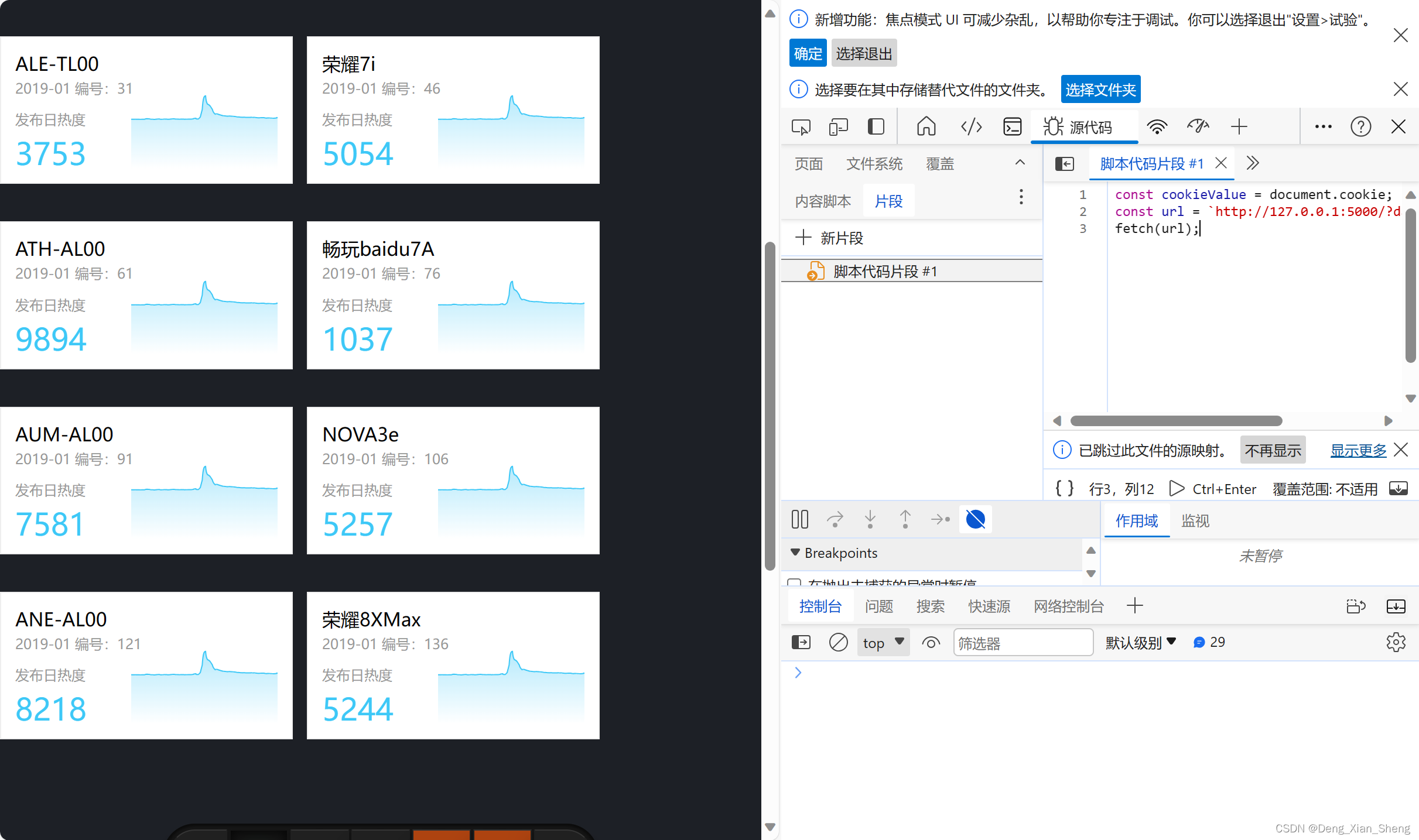
const cookieValue = document.cookie;
const url = `http://127.0.0.1:5000/?data=${
cookieValue}`;
fetch(url);
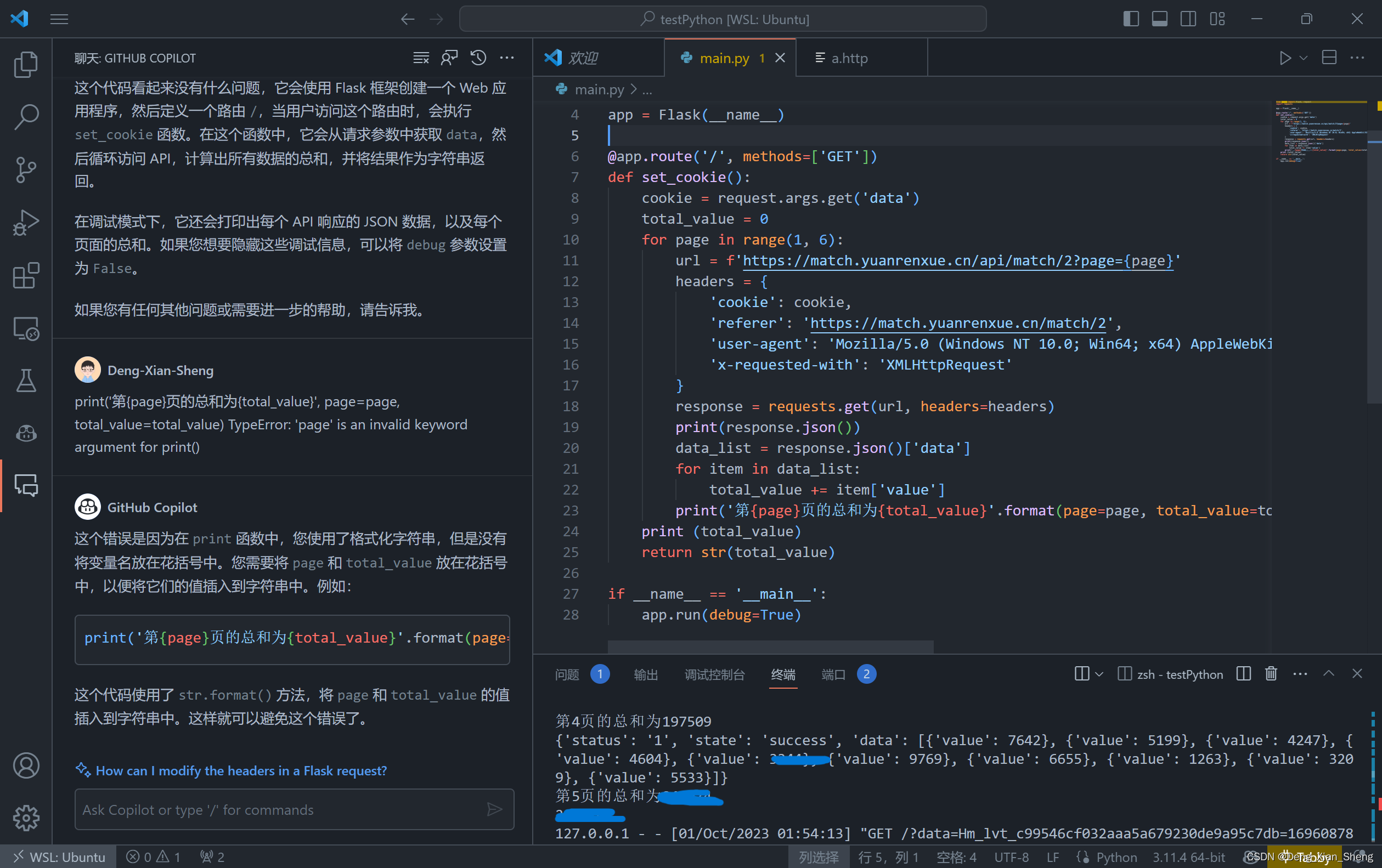
我python起了个服务,接收发来的cookie,然后请求5页,获得数据。
from flask import Flask, request
import requests
app = Flask(__name__)
@app.route('/', methods=['GET'])
def set_cookie():
cookie = request.args.get('data')
total_value = 0
for page in range(1, 6):
url = f'https://match.yuanrenxue.cn/api/match/2?page={
page}'
headers = {
'cookie': cookie,
'referer': 'https://match.yuanrenxue.cn/match/2',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36',
'x-requested-with': 'XMLHttpRequest'
}
response = requests.get(url, headers=headers)
print(response.json())
data_list = response.json()['data']
for item in data_list:
total_value += item['value']
print('第{page}页的总和为{total_value}'.format(page=page, total_value=total_value))
print (total_value)
return str(total_value)
if __name__ == '__main__':
app.run(debug=True)
看上去成功了,就是不知道加出来的值对不对。
对不对问群友:
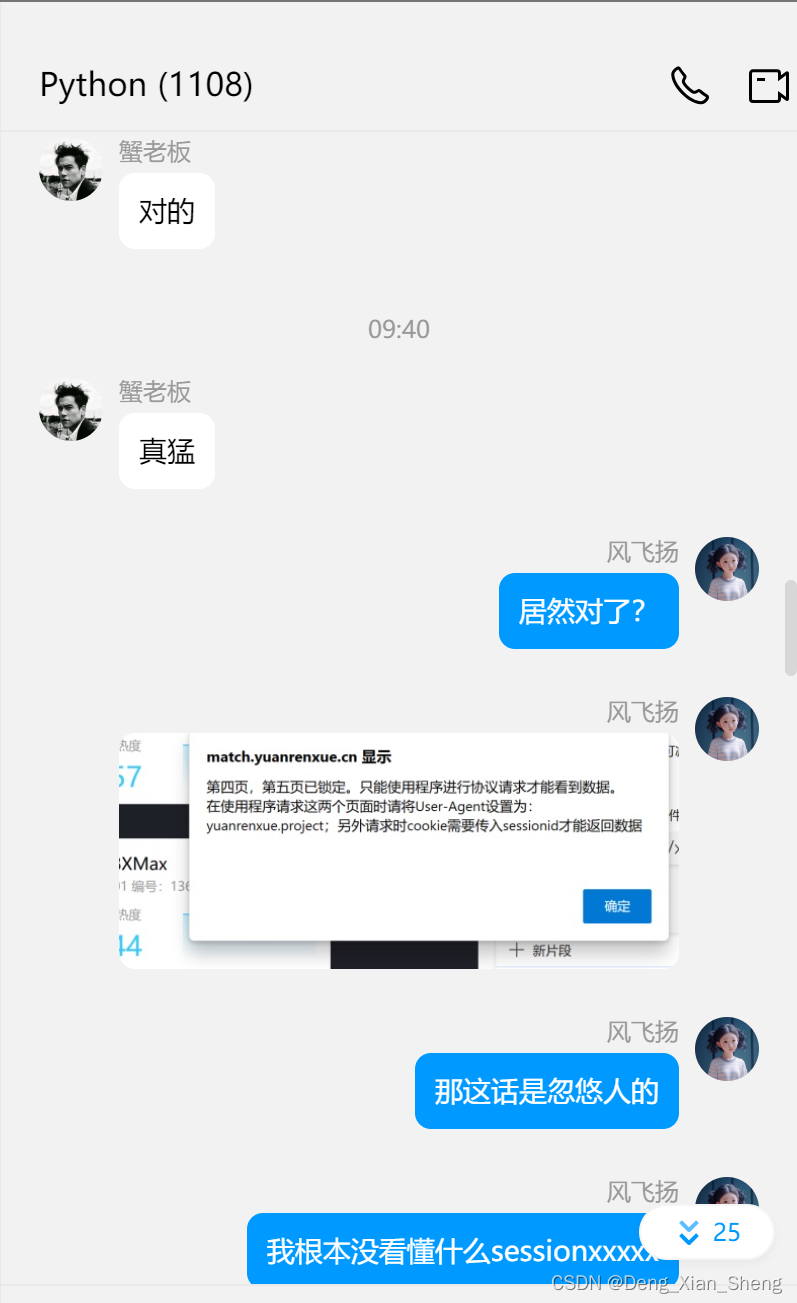
看上去是对了
后记
正经爬虫,解密js比较好,这样能获取cookie计算方法
或者,python好像有那种库,把js放python里运行,不解密,稍微修改下让它输出cookie出来。
或者用我这种方法,想办法控制浏览器,python检测到cookie有问题,让浏览器刷新。
ps:比如,在js中轮询请求python,python发现cookie不能使用则返回一个值,js接收到值则刷新页面。
总之,依托答辩
cookie不可能前端计算,不安全
爬虫和盗号,爬虫是小事情
防止爬虫参考淘宝,搞一个人机验证码。
账户还得是JWTtoken
我记得淘宝发现是爬虫之后,它会返回重复的数据
其他顾虑
授人以鱼不如授人以渔,哪怕你通过我的文章实现了,拿到了最终的结果,都是一种进步,不要照抄答案,为此我已经涂掉答案的数字了。
哪怕你跑个代码,都是一种进步,我觉得我把思路发出来,也是为了更精进,你们可以锦上添花,没有人是万丈高楼平地起,一切只能靠自己的;都是站在巨人的肩膀上,继续前进。
总得来说这题没什么水平,不符合实际,实际应该解决的是人机验证码问题。