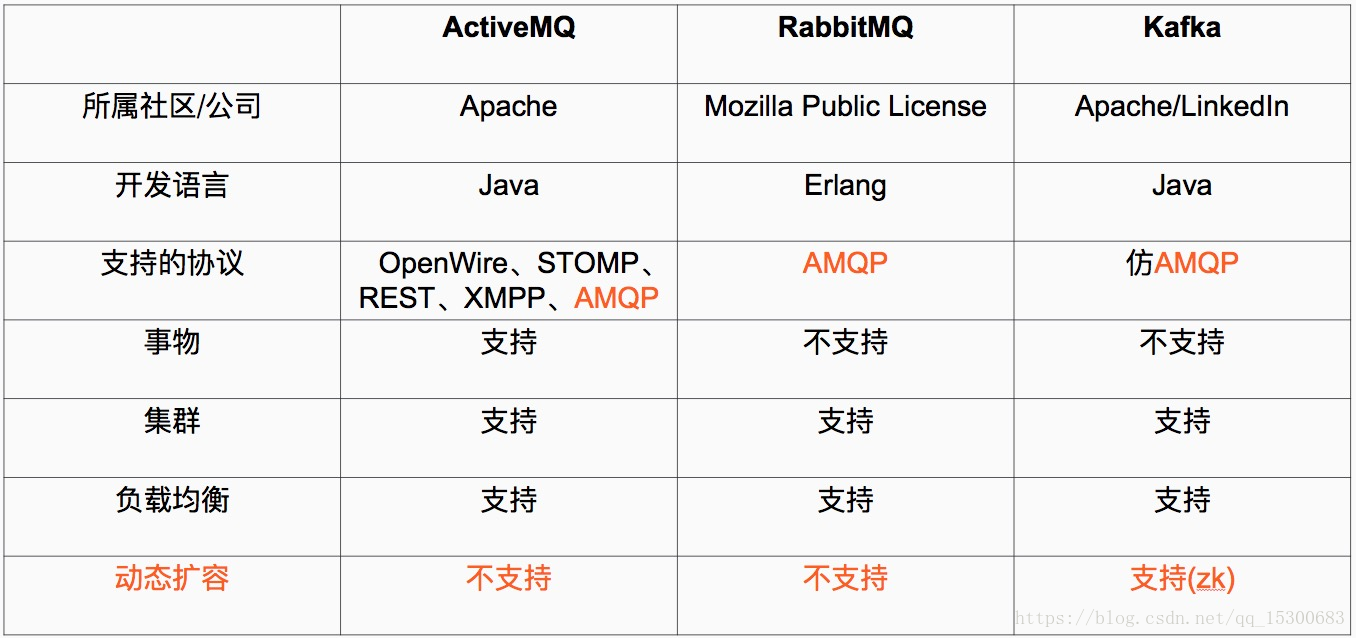
对于消息中间件的前期调研:ActiveMQ
RabbitMQ(中小型软件公司)
RocketMQ(大型软件公司,阿里制造)
Kafka(大型软件公司)
===========================================================================
1.什么是Kafka
===========================================================================有三个关键功能
- 发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 以高容错的方式存储消息记录流。
- 处理流式消息。
通常用于两大类应用(实时的流式数据存储,通常后面对接 Spark Streaming结构化流)
- 构建可在系统或应用程序之间可靠获取数据的实时流数据管道
- 构建实时流应用程序,用于转换或响应数据流(用得少)
应用场景
- 作为消息中间件,一般部署在流式组件前一个,主要为了避免高峰期计算来的压力(处理能力达不到数据采集的速度)
===========================================================================
2.Kafka User Cases
===========================================================================常见的数据来源:
网站网页单击记录日志
度量值的收集:Mysql的健康状况,系统状态日志
Maxwell(单点压力过大)--------------->存储平台 ×
Maxwell-->Kafka-->Spark streaming-->存储平台 √
Flume-->Kafka-->Spark streaming-->存储平台
Zookeeper: http://zookeeper.apache.org/ 协调服务 3.4.6
1.部署使用
2.无论是Apache 还是CDH
比如HDFS HA、YARN HA损坏,Kafka,HBase 都在ZK
a. zkCli.sh 进入当前机器的localhost模式去连接
b. ZooKeeper -server host:port
c. 命令帮助 进人console,输入help Zookeeper可以理解为一个文件夹
ls /ls /zookeeper
rmr path
Jdk:
路径: /usr/java/
jdbc:
路径: /usr/share/java
Scala: 2.11.8
Kafka: 0.8 0.10 https://spark.apache.org/docs/2.2.0/streaming-kafka-integration.html
[root@hadoop001 kafka]# nohup kafka-server-start.sh config/server.properties &
Kafka部署完成的进程,broker
producer---》broker cluster --》 consumer
Flume --> Kafka---> Spark Streaming
导航日志 --》Kafka --> 计算程序
主题Topic:DH
Topic可以理解为一个文件夹,根据不同的业务去分组
企业预警日志--》Kafka
主题Topic:AlertLog
zookeeper.connect=192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181 /kafka
bin/kafka-topics.sh --create \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181 \
--replication-factor 3 --partitions 3 --topic test
bin/kafka-console-consumer.sh \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181 \
--from-beginning --topic test
===========================================================================
3.Kafka 安装部署
===========================================================================下载地址:
Zookeeper:(分布式协调服务 HA 选举)
http://mirror.bit.edu.cn/apache/zookeeper/current/
Scala:
http://www.scala-lang.org/download/2.11.8.html
Kafka:
http://kafka.apache.org/downloads
一.Zookeeper部署
1.下载解压zookeeper-3.4.6.tar.gz
[root@hadoop001 software]# tar -xvf zookeeper-3.4.6.tar.gz
[root@hadoop001 software]# mv zookeeper-3.4.6 zookeeper
[root@hadoop001 software]#
[root@hadoop001 software]# chown -R root:root zookeeper
2.修改配置
[root@hadoop001 software]# cd zookeeper/conf
[root@hadoop001 conf]# ll
total 12
-rw-rw-r--. 1 root root 535 Feb 20 2014 configuration.xsl
-rw-rw-r--. 1 root root 2161 Feb 20 2014 log4j.properties
-rw-rw-r--. 1 root root 922 Feb 20 2014 zoo_sample.cfg
[root@hadoop001 conf]# cp zoo_sample.cfg zoo.cfg
[root@hadoop001 conf]# vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/software/zookeeper/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=hadoop001:2888:3888
server.2=hadoop002:2888:3888
server.3=hadoop003:2888:3888
~
"zoo.cfg" 36L, 1028C written
[root@hadoop001 conf]# cd ../
[root@hadoop001 zookeeper]# mkdir data
[root@hadoop001 zookeeper]# touch data/myid
[root@hadoop001 zookeeper]# echo 1 > data/myid
[root@hadoop001 zookeeper]#
3.hadoop002/003,也修改配置,就如下不同
[root@hadoop001 software]# scp -r zookeeper 192.168.137.141:/opt/software/
[root@hadoop001 software]# scp -r zookeeper 192.168.137.142:/opt/software/
[root@hadoop002 zookeeper]# echo 2 > data/myid
[root@hadoop003 zookeeper]# echo 3 > data/myid
###切记不可echo 3>data/myid,将>前后空格保留,否则无法将 3 写入myid文件
4.启动Zookeeper集群
[root@hadoop001 bin]# ./zkServer.sh start
[root@hadoop002 bin]# ./zkServer.sh start
[root@hadoop003 bin]# ./zkServer.sh start
5.查看Zookeeper状态
[root@hadoop001 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /opt/software/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@hadoop002 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /opt/software/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[root@hadoop002 bin]#
[root@hadoop003 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /opt/software/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@hadoop003 bin]#
6.进入客户端
[root@hadoop001 bin]# ./zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, yarn-leader-election, hadoop-ha, rmstore]
[zk: localhost:2181(CONNECTED) 1]
[zk: localhost:2181(CONNECTED) 1] help
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port
[zk: localhost:2181(CONNECTED) 2]
二.Kafka部署
1.解压并配置Scala
[root@hadoop001 software]# tar -xzvf scala-2.11.8.tgz
[root@hadoop001 software]# chown -R root:root scala-2.11.8
[root@hadoop001 software]# ln -s scala-2.11.8 scala
#环境变量
[root@hadoop001 software]# vi /etc/profile
export SCALA_HOME=/opt/software/scala
export PATH=$SCALA_HOME/bin:$PATH
[root@hadoop001 software]# source /etc/profile
[root@hadoop001 software]# scala
Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_45).
Type in expressions for evaluation. Or try :help.
2.下载基于Scala 2.11的kafka版本为0.10.0.1
[root@hadoop001 software]# tar -xzvf kafka_2.11-0.10.0.1.tgz
[root@hadoop001 software]# ln -s kafka_2.11-0.10.0.1 kafka
[root@hadoop001 software]#
3.创建logs目录和修改server.properties
[root@hadoop001 software]# cd kafka
[root@hadoop001 kafka]# mkdir logs
[root@hadoop001 kafka]# cd config/
[root@hadoop001 config]# vi server.properties
broker.id=1
port=9092
host.name=192.168.137.141
log.dirs=/opt/software/kafka/logs
zookeeper.connect=192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka
4.环境变量
[root@hadoop001 config]# vi /etc/profile
export KAFKA_HOME=/opt/software/kafka
export PATH=$KAFKA_HOME/bin:$PATH
[root@hadoop001 config]# source /etc/profile
5.另外两台机器如上操作
6.启动/停止
[root@sht-sgmhadoopdn-01 kafka]# nohup kafka-server-start.sh config/server.properties &
[root@sht-sgmhadoopdn-02 kafka]# nohup kafka-server-start.sh config/server.properties &
[root@sht-sgmhadoopdn-03 kafka]# nohup kafka-server-start.sh config/server.properties &
###停止
bin/kafka-server-stop.sh
---------------------------------------------------------------------------------------------------------------------------------------------
7.模拟实验1
在一个终端,启动Producer,并向我们上面创建的名称为my-replicated-topic5的Topic中生产消息,执行如下脚本:
bin/kafka-console-producer.sh \
--broker-list 192.168.137.141:9092,192.168.137.142:9092,192.168.137.143:9092 --topic test
在另一个终端,启动Consumer,并订阅我们上面创建的名称为my-replicated-topic5的Topic中生产的消息,执行如下脚本:
bin/kafka-console-consumer.sh \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka \
--from-beginning --topic test
可以在Producer终端上输入字符串消息行,就可以在Consumer终端上看到消费者消费的消息内容。
===========================================================================
4.Kafka
===========================================================================Zookeeper在Kafka集群中扮演了什么角色
===========================================================================