目录
- 前言
- 一、单链表找三等分点(链表可能有环)
- 二、讲几个熟悉的设计模式
- 三、Spring IoC、AOP是什么,是如何实现的,Spring MVC是什么?
- 四、怎么实现线程安全,各个实现方法有什么区别,synchronized是不是可重入锁?
- 五、HashMap底层实现,怎么实现HashMap线程安全?
- 六、JVM内存管理
- 七、 怎么判断哪些对象需要被GC,GC的方法, HotSpot GC算法以及7种垃圾回收器。
- 八、类加载机制
- 九、线程和进程的区别
- 十、HTTP有没有状态,如何理解HTTP的无状态,如何解决HTTP的无状态?
- 十一、Java IO、NIO和异步IO
- 十二、AJAX是什么,实现原理
- 十三、设计一个线程池
- 十四、MySQL优化、索引的实现
- 十五、事务的隔离级别
- 十六、Hibernate和MyBatis
- 十七、Git
- 十八、Linux常用指令
- 十九、如果一个表特别大,怎么优化?
- 后记
前言
“实战面经”是本专栏的第二个部分,本篇博文是第一篇博文,如有需要,可:
一、单链表找三等分点(链表可能有环)
public class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}
public class Solution {
public ListNode findThreeEqualParts(ListNode head) {
if (head == null || head.next == null) {
return null;
}
// 快慢指针检查链表是否有环,将其转换为无环链表
ListNode slow = head;
ListNode fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) {
// 得到相遇节点
fast = head;
while (fast.next != slow.next) {
fast = fast.next;
slow = slow.next;
}
// 断开环,将链表转换为无环链表
slow.next = null;
break;
}
}
// 使用快慢指针算法查找三等分点
// 上三等分点(三分之一)
ListNode oneThird = head;
// 下三等分点(三分之二)
ListNode twoThirds = head;
ListNode current = head;
int count = 0;
while (current != null) {
count++;
current = current.next;
if (count % 3 == 1) {
twoThirds = twoThirds.next;
} else if (count % 3 == 2) {
oneThird = oneThird.next;
}
}
// 如果链表元素不足以分成3部分相等长度,返回 null
if (count / 3 < 2) {
return null;
}
return oneThird.next;
}
}
代码逻辑说明:
1. 代码分为两部分,首先通过快慢指针判断单链表有没有环,有环就把换拆开。然后通过另一对快慢指针查找三等分点。
2. 三等分点这个描述可能有坑,问清楚出题者想要哪个。
二、讲几个熟悉的设计模式
1. 单例模式:
在程序的整个生命周期中,对于classA最多只存在一个实例,且这个实例由classA自己管理。Spring的IoC中就默认使用单例模式;
2. 代理模式:
为其他对象提供代理来控制对这个对象的访问。Spring的 AOP中就使用了代理模式;
3. 工厂方法模式:
定义创建对象的接口,让子类决定实例化哪个类。工厂方法模式让一个类的实例化推迟到其子类。
三、Spring IoC、AOP是什么,是如何实现的,Spring MVC是什么?
1. IoC: 即Inversion of Control,控制反转,就是把对象的生命周期管理托管出去达到代码解耦的目的。IoC的实现方式有依赖监控(DL)和依赖注入(DI),由于依赖监控对业务代码有侵入性,因此已被抛弃,现在主要通过依赖注入来实现IoC。依赖注入就是在需要的时候才建立依赖关系,将程序所依赖的对象注入进去。
2. AOP: 即面向切面的编程,它不能代替OOP,而是它的补充,AOP适用于具有横切逻辑的场景,如性能监控、事务管理和日志记录。AOP的实现主要依靠Java动态代理,分为两种:JDK动态代理和CGLib动态代理:
1) JDK动态代理: 适用于业务逻辑通过接口实现的场景;
2) CGLib动态代理: 可以不依赖于接口,它可以为被代理类生成一个子类,然后拦截父类的所有方法调用,然后织入增强逻辑。
3. MVC即Model、View和Controller
1) Controller: 控制Web程序的入口和对请求的响应。
2) Model: 是数据模型,比如我们在某个请求中特定的user对象就是一个model。
3) View: 是web程序里的可视部分,比如html页面等。
四、怎么实现线程安全,各个实现方法有什么区别,synchronized是不是可重入锁?
1. 线程安全可以使用加锁策略和无锁策略来实现。加锁可以使用synchronized关键字和Lock,无锁可以使用CAS的实现类和版本号机制。
2. 各个实现方法的区别
1) synchronized和Lock的区别和联系:
- synchronized不需要手动解锁,而Lock需要手动解锁;
- Lock将锁对象化,可以监控锁的状态。
- Lock可以设置枷锁等待时间,超时就放弃加锁。
- Lock可以设置为公平锁,而synchronized是非公平锁。
- synchronized和Lock都是可重入的。
2) CAS的实现类有Unsafe,用对象的旧值和当前值进行比较,如果它们相等就认为这个对象没有被其他线程改变过,就可以被赋予新值,否则就重试。
3) 版本号机制适合于数据库,每次更新都给对应的行设置一个新的版本号,当发现版本号没变时,才进行更新,可以避免CAS的ABA问题。
五、HashMap底层实现,怎么实现HashMap线程安全?
1. 红黑树: 为了解决链表过长的问题,当链表上元素大于8时,就会转换为红黑树。红黑树是一棵自平衡二叉树,通过节点的旋转和变色来达到自平衡的目的。
2. Node数组: 在Java 8之后HashMap内部使用一个Node数组作为哈希表,Node有一个属性是next,用来构建链表,当需要变化为红黑树时,就会把Node换成它的子类的子类TreeNode。
3. put的过程,put会调用putVal:
1) 判断表当前是否已经创建,如果未创建,就调用resize函数通过默认设置创建表,默认大小是16;
2) 判断当前要加进来的键值对应的桶里有没有节点:
- 如果是空就创建新的Node放到这个桶里,否则:
- 如果桶里是一个普通的Node,创建新的Node添加到链表的最后一个;
- 如果链表的长度大于8,调用
treeifyBin把链表转换为红黑树; - 如果桶里是一个TreeNode,就调用
putTreeVal把新的键和值插入到红黑树中去;
- 这期间,如果发现键和桶里的键相等,就用新的Value覆盖原先的Value;
3) 最后,如果节点的数量大于临界值,就调用resize函数进行扩容,将表的长度变为原来的二倍;
4. resize的过程:
1) 如果已经超过最大容量限制(2的30次方),就不再扩容,否则创建新表,容量是旧表的两倍;
2) 遍历旧表在新表上重新定位各节点,如果节点是一个普通的没有后继的Node,就通过重定位到hash & (newCap - 1);如果是个TreeNode,就调用split函数进行rehash;如果是一个链表的第一个节点,就对链表进行拆分,求节点的hash & oldCap,等于0的被添加到lo链表中,等于1的被添加到hi链表中。
3) 最后将lo链表定位到它在旧表中的index,hi链表在lo表的index + oldCap的位置;
5. HashMap提供的三种视图:
1) keySet(): 包含所有key的一个Set视图;
2) values(): 包含所有value的一个Collection视图;
3) entrySet(): 包含所有entry的一个Set视图。
6. HashMap线程安全的三种方法:
1) Hashtable: 使用对象锁,效率比较低;
2) Collections.synchronizedMap(): 同样使用对象锁,效率比较低;
3) ConcurrentHashMap: 使用CAS + synchronized,锁的粒度更细,每次只锁一个桶,所以可以多个线程同时操作多个桶。扩容的时候单线程初始化,多线程复制,所以效率比较高。
六、JVM内存管理
JVM内存分为: 虚拟机栈、本地方法栈、程序计数器、堆和方法区
其中虚拟机栈、本地方法栈和程序计数器是线程私有的,堆和方法区是线程共享的。
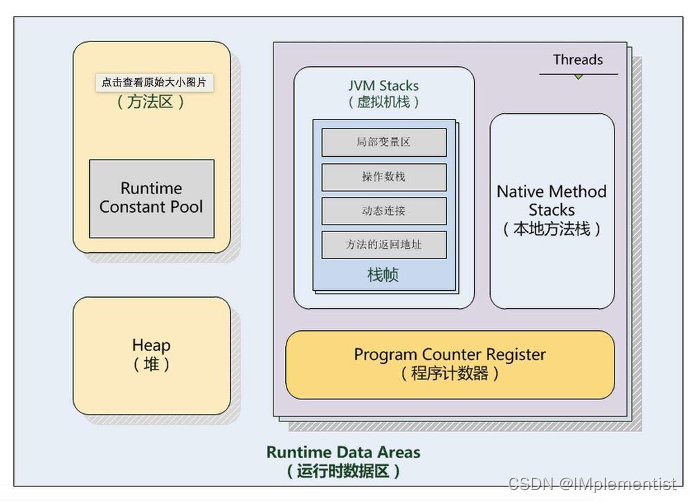
1. 程序计数器: 用于记录线程当前所执行的字节码的行号;
2. 虚拟机栈: 用于存放方法调用的栈帧,而栈帧中存放着局部变量表、操作数栈动态链接和方法返回地址;
3. 本地方法栈: 本地方法栈和虚拟机栈类似,用来执行Native方法;
4. 堆: 堆里用来存放通过new创建的对象;
5. 方法区: 用于存储已被虚拟机加载的类信息、常量、静态变量。常量池就在方法区中。
七、 怎么判断哪些对象需要被GC,GC的方法, HotSpot GC算法以及7种垃圾回收器。
1. 没有被其他对象引用的对象就需要被GC。
2. 判断垃圾的算法有引用计数器法和可达性分析算法:
1) 引用计数器法: 每个对象都有一个计数器,被引用则+1,完成引用(即设置对象=null)就-1,计数器为0的对象可以被回收;
2) 可达性分析算法: 通过判断对象的引用链是否可达来判断对象是否需要被回收;
3. 垃圾回收算法:
1) 标记清除算法: 会造成内存碎片;
2) 复制算法: 将内存分为对象面和空闲面,每次GC时将存活的对象复制到空闲面的连续空间,清除对象面,然后对象面和空闲面调换身份,适合对象存活率低的场景;
3) 标记整理算法: 移动所有存活的对象,并使它们在内存中连续,清除其他内存,适合对象存活率高的场景。
4) 分代收集算法:
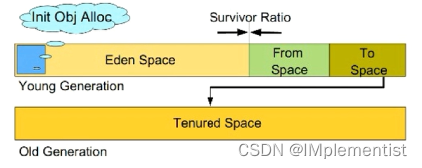
a) 年轻代: 分为Eden区和Survivor区,而Survivor区又分为From区和To区(三者 默认比例8:1:1),Eden区是对象出生的地方。每次发生GC,将Eden区和From区的 存活对象复制到To区,然后清理Eden和From区,将From区和To区的身份调换。
b) 老年代: 用于存放大对象(即年轻代中Eden或者From区放不下的对象)或者年 轻代中经过一定GC次数仍然存活的对象。
4. 触发Minor GC和Full GC的条件:
1) Minor GC: 当Eden区满时;
2) Full GC:
a) 程序中调用System.gc(),建议系统执行GC,但不一定执行;
b) 老年代空间不足;
c) 方法区空间不足。
5. 垃圾收集器:
1) 年轻代垃圾收集器(复制算法):
a) Serial收集器: 单线程,Client模式下默认的年轻代收集器;
b) ParNew收集器: 多线程收集;
c) Parallel Scavenge收集器: 多线程收集,比起关注用户线程停顿时间,更关注系 统吞吐量,Server模式下默认的年轻代收集器。
2) 老年代垃圾收集器:
a) Serial Old收集器: 单线程,标记整理算法,Client模式下默认的老年代收集器;
b) Parallel Old收集器: 多线程,标记整理算法;
c) CMS收集器: 标记清除算法。
6. CMS收集器:
1) 初始标记: Stop-The-World,初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快
2) 并发标记: 并发追溯标记,程序不会停顿
3) 并发预清理: 查找执行并发标记阶段从年轻代晋升到老年代的对象
4) 重新标记: 暂停虚拟机,扫描CMS堆中的剩余对象
5) 并发清理: 清理垃圾对象,程序不会停顿
6) 并发重置: 重置CMS收集器的数据结构
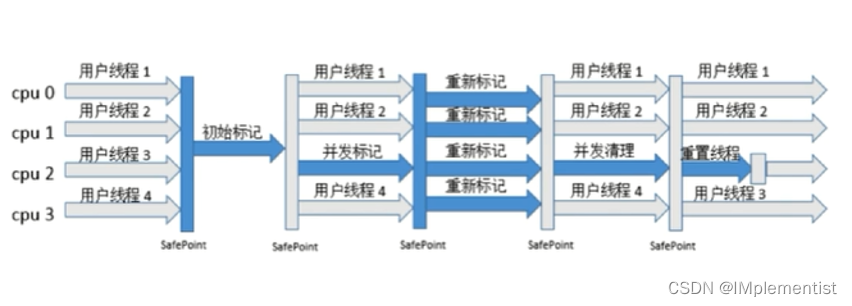
存在的问题:
1) 采用标记清除算法,不对内存进行压缩,会造成空间碎片化的问题
2) CPU资源非常敏感。在并发阶段,虽然不会导致用户线程停顿,但是会因为占用了一部分线程而导致应用程序变慢,总吞吐量会降低。
3) CMS收集器无法处理浮动垃圾,可能会出现“Concurrent Mode Failure(并发模式故障)”失败而导致Full GC产生。
4) 浮动垃圾: 由于CMS并发清理阶段用户线程还在运行着,伴随着程序运行自然就会有新的垃圾不断产生,这部分垃圾出现的标记过程之后,CMS无法在当次收集中处理掉它们,只好留待下一次GC中再清理。这些垃圾就是“浮动垃圾”。
7. G1收集器:
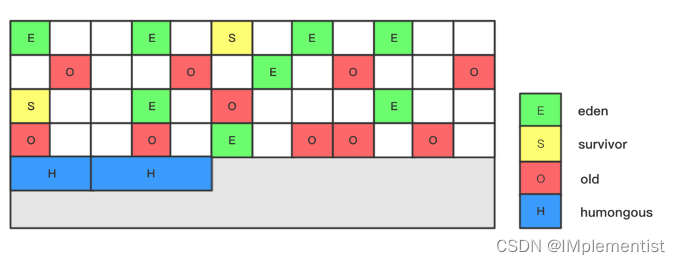
1) 在G1算法中,堆内存被划分为多个大小相等的内存块(Region),每个Region是逻辑连续的一段内存。每个Region被标记了E、S、O和H,说明每个Region在运行时都充当了一种角色,其中H是以往算法中没有的,它代表Humongous,这表示这些Region存储的是巨型对象(humongous object,H-obj),当新建对象大小超过Region大小一半时,直接在新的一个或多个连续Region中分配,并标记为H。
2) GC模式: G1中提供了三种模式垃圾回收模式,Young GC、Mixed GC和Full GC,在不同的条件下被触发。
a) Young GC: 发生在年轻代的GC算法,一般对象(除了巨型对象)都是在eden region中分配内存,当所有eden region被耗尽无法申请内存时,就会触发一次young gc,这种触发机制和之前的Young GC差不多,执行完一次Young GC,活跃对象会被拷 贝到survivor region或者晋升到old region中,空闲的region会被放入空闲列表中,等 待下次被使用。
b) Mixed GC: 当越来越多的对象晋升到老年代old region时,为了避免堆内存被 耗尽,虚拟机会触发一个混合的垃圾收集器,即Mixed GC,除了回收整个young region,还会回收一部分的old region,可以选择哪些old region进行收集,从而可以对 垃圾回收的耗时时间进行控制。
c) Full GC: 如果对象内存分配速度过快,导致老年代被填满,就会触发一次Full GC,G1的Full GC算法就是单线程执行的Serial Old,会导致异常长时间的暂停时间, 需要进行不断的调优,尽可能的避免Full GC。
8. 各收集器的关系
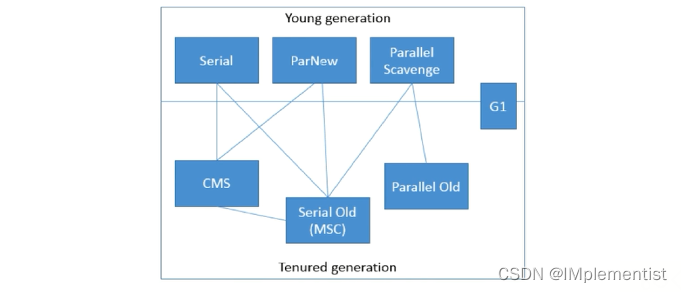
八、类加载机制
共有Bootstrap ClassLoader、Ext ClassLoader和App ClassLoader,其中Bootstrap是Ext的父加载器,Ext是App的父加载器。
1. Bootstrap ClassLoader: 负责加载Java的核心库;
2. Ext ClassLoader: 负责加载ext文件夹下的类;
3. App ClassLoader: 负责加载程序所在目录下的类;
4. 双亲委派机制: 子加载器判断当前需要加载的类是否已经加载过,如果没有就调用父加载器去加载。
5. 双亲委派机制为什么安全: ClassLoader加载的class文件来源很多,一些来源的class文件是不可靠的,比如我可以自定义一个java.lang.Integer类来覆盖jdk中默认的Integer类:
package java.lang;
public class Integer {
public Integer(int value) {
……
}
}
这样是非常不安全的,如果使用双亲委派机制,这个自定义的Integer类不会被加载。因为委托BootStrapClassLoader加载后会加载JDK中的Integer类而不会加载自定义的这个,也就保证了安全性。
九、线程和进程的区别
1. 进程是系统分配资源的最小单位,线程是CPU调度的最小单位。
2. 一个进程中包含一个或多个线程,一个线程必然属于某个进程。
3. 进程切换的开销比线程大。
4. 并发方面,多进程比多线程健壮。在多线程中,一旦一个线程发生异常,整个进程及其所有的线程就都死掉了,但是在多进程中,一个进程死掉了并不会影响其他进程。
十、HTTP有没有状态,如何理解HTTP的无状态,如何解决HTTP的无状态?
1. HTTP是无状态的。
2. 无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。即服务端响应请求之后,不会记录任何信息。
3. 解决HTTP的无状态就是进行会话跟踪:
1) URL重写: 把状态信息拼在URL里;
2) 隐藏表单域: 在页面中设置隐藏的表单来记录状态信息;
3) Session: 用Session把状态信息存在服务器上;
4) Cookie: 用Cookie把状态信息存在客户端。
十一、Java IO、NIO和异步IO
1. Java IO: 是面向流的同步阻塞IO,当用户线程发出请求后,用户线程就会被阻塞住,一个典型的例子就是InputStream类中的read方法,里面有一个死循环,直到读完。
2. Java NIO: 是面向缓冲区的同步非阻塞IO,可以在一个线程中将需要监听的通道注册到Selector上,注册完成之后,一旦通道处于就绪的状态,Selector就可以监听到。Selector可以不断地向通道发起轮询,查看通道的状态。
3. 对比:
1) 对于多个客户端,IO需要创建多个线程,让它们处于阻塞状态,会造成严重 的资源浪费。而NIO只需要创建一个线程;
2) 线程切换效率低下,线程较多的时候需要频繁的线程切换,应用的性能也会急 剧下降;
3) 同时IO中数据读写是以字节为单位的,效率不如NIO中以缓冲区的块为单位 那么高。
4. Java 异步IO: Java实现了异步IO,这些异步IO的实现类是Channel类的一些子类。当线程发起IO之后就可以继续执行下面的程序,然后当IO完成之后通过回调函数通知主线程。我对异步IO的理解就是,当我们需要跳转到商城的商品页面时,用异步IO,先跳转页面然后等待图片一个一个加载。
十二、AJAX是什么,实现原理
AJAX是异步的JavaScript和XML,可以通过在后台与服务器进行少量数据交换,使网页实现异步更新。可以指更新网页的部分,不需要重新加载整个页面。AJAX通过 XMLHttpRequest对象进行异步查询,它在客户端运行,减少了服务器工作量。
十三、设计一个线程池
划分为以下模块来设计:
1. 线程的创建模块: 当线程数低于corePoolSize的时候,收到一个任务就创建一个线程去执行;如果达到了corePoolSize,就往等待队列里放。如果等待队列也满了,单线程数还没有达到maxPoolSize就创建线程去执行等待队列里放不下的任务。如果线程数达到maxPoolSize了,就需要通过handler去处理这些任务。
2. 等待队列: 前面提到了,用来存放暂时没有被分配线程而等待执行的任务。
3. Handler: 前面也提到了,当线程数已经达到maxPoolSize,且没有空闲的线程执行这些任务时的处理策略。ThreadPoolExecutor里面有抛异常、直接让调用的线程来执行、直接抛弃、抛弃比较老的任务这么几种策略。
十四、MySQL优化、索引的实现
1. MySQL优化:
1) 数据库引擎方面: 如果是纯检索系统就选择MyISAM,因为MyISAM不支持事 务,且使用的是非聚簇索引;否则,就应该使用支持事务、行级锁和聚簇索引的 InnoDB。
2) 查询优化方面: 尽量使查询走索引,避免全表扫描。可以用EXPLAIN关键字和 慢查询日志分析查询语句的慢的原因,然后进行相应的优化。
2. 索引的实现: MySQL中索引采用B+树实现。
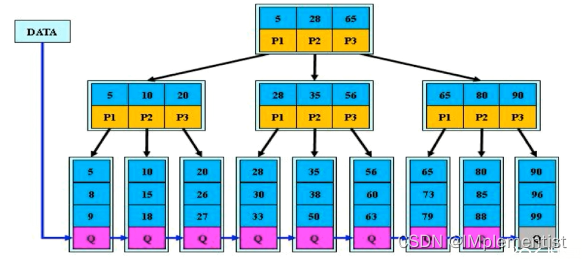
3. 结论: B+树更适合用来做存储索引
1) B+树的磁盘读写代价更低,一次性读入的索引信息更多,降低IO次数;
2) B+树的查询效率更加稳定,所有关键字值的查找长度基本相同;
3) B+树更有利于对数据库的扫描。
十五、事务的隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻象读 | 第一类丢失更新 | 第二类丢失更新 |
|---|---|---|---|---|---|
| READ_UNCOMMITED | 允许 | 允许 | 允许 | 不允许 | 允许 |
| READ_COMMITED | 不允许 | 允许 | 允许 | 不允许 | 允许 |
| REPEATABLE_READ | 不允许 | 不允许 | 允许 | 不允许 | 不允许 |
| SERIALIZABLE | 不允许 | 不允许 | 不允许 | 不允许 | 不允许 |
1. 脏读: 线程A读到线程B未提交的数据,而后线程B回滚。
2. 不可重复读: 线程A读到线程B修改的数据,导致两次读到的数据不同。
3. 幻象读: 线程A读到线程B新插入的数据,导致两次读到的数据不同
MySQL的默认事务隔离级别是REPEATABLE READ
十六、Hibernate和MyBatis
他们都是持久化层的框架,我主要使用Hibernate,它可以自动进行关系实体映射,生成SQL语句。Mybatis大概了解过,属于需要手动编写SQL语句的半自动化框架。
十七、Git
Git是版本控制系统,Github就是基于Git实现的,GitHub上常用的指令有:
- clone
- pull
- push
- commit
- merge
十八、Linux常用指令
1. vim: 编辑工具
2. cat: 查看文件内容
3. grep: 全局正则表达式搜索工具
4. find: 查找工具
5. |: 管道操作符,前面的指令输出作为后面指令的输入
十九、如果一个表特别大,怎么优化?
可以创建分区表,MySQL支持以下几类分区表:
1. RANGE分区: 行数据基于一个给定连续范围分区。
2. LIST分区: 同RANGE,区别在于给定的不是连续范围,是离散的值。
3. HASH分区: 根据用户自定义的表达式的返回值进行分区,返回值不能是负数。
4. KEY分区: 根据MySQL内部提供的哈希函数进行分区。
5. COLUMNS分区: 可以直接使用非整形的数据进行分区,分区根据类型直接比较而得,不需要转换为整形。
后记
这份面经里面,加上自我介绍面试官一共问了20个问题,在实际面试中算问了非常多了。不过知识面基本上脱离不了 “八股” 的范畴。
回答问题的时候,我们可以尽可能得根据自己所知道的知识面对问题的答案进行扩展,直到面试官打断你为止。这样可以帮助面试官了解到你对一个知识点了解的深入程度。