zookeeper有两种运行模式:独立模式和仲裁模式。独立模式就是只运行一个Zookeeper Server,这自然没法解决服务崩溃导致系统不可用的问题。仲裁模式就是以集群的方式运行Zookeeper Server,这样在Leader不可用时,集群内部会发起选举,而推选一个新的Leader。既然我们要使用zookeeper,肯定是有分布式协作需求,所以本文只讲述仲裁模式的部署。(转载请指明出于breaksoftware的csdn博客)
为了方便大家测试,我们将Zookeeper Server部署在同一台机器上,通过对外提供不同的端口号来模拟多机部署。
首选我们要选择部署几个Server服务(不考虑Observer)。2个?3个?4个?如果一定要在三个数字中选,大部分建议是选择3个。
如果选择2,那么依据少数服从多数的原则,要求Leader的必须获得2票。如果坏了一台机器,剩下的那台机器肯定得不到2票,那么整个系统将不可用。于是损失一台机器的系统可用率是0。
如果选择是3,要求Leader的票数也必须>=2。如果坏了一台机器,剩下的两台机器可以抉择出哪台可以得到2票,从而系统可用。如果又坏了一台,剩下一台机器不可能得到2票。于是损失一台机器的系统可用率是100%,损失两台机器的系统可用率是0。
如果选择4,要求Leader的票数>=3。如果坏了一台机器,剩下的三台机器可以抉择出哪台可以得到3票,从而系统可用。如果又坏了一台,剩下的两台机器不可能得到3票。于是损失一台机器的系统可用率是100%,损失两台机器的系统可用率是0。
| 集群机器数 | 损失1台机器系统可用率 | 损失2台机器系统可用率 |
| 2 | 0 | 0 |
| 3 | 100% | 0 |
| 4 | 100% | 0 |
可以看出来在损失2台机器的情况下,集群部署3台或者4台的系统可用率是相等的。部署4台并不比部署3台要可靠。
也许有人开始质疑“少数服从多数”这个选举原则。如果4台机器只要有机器获得2票,就可以被认为是Leader,那不就提高了可用率了么?答案是这样的设计会导致严重的问题。
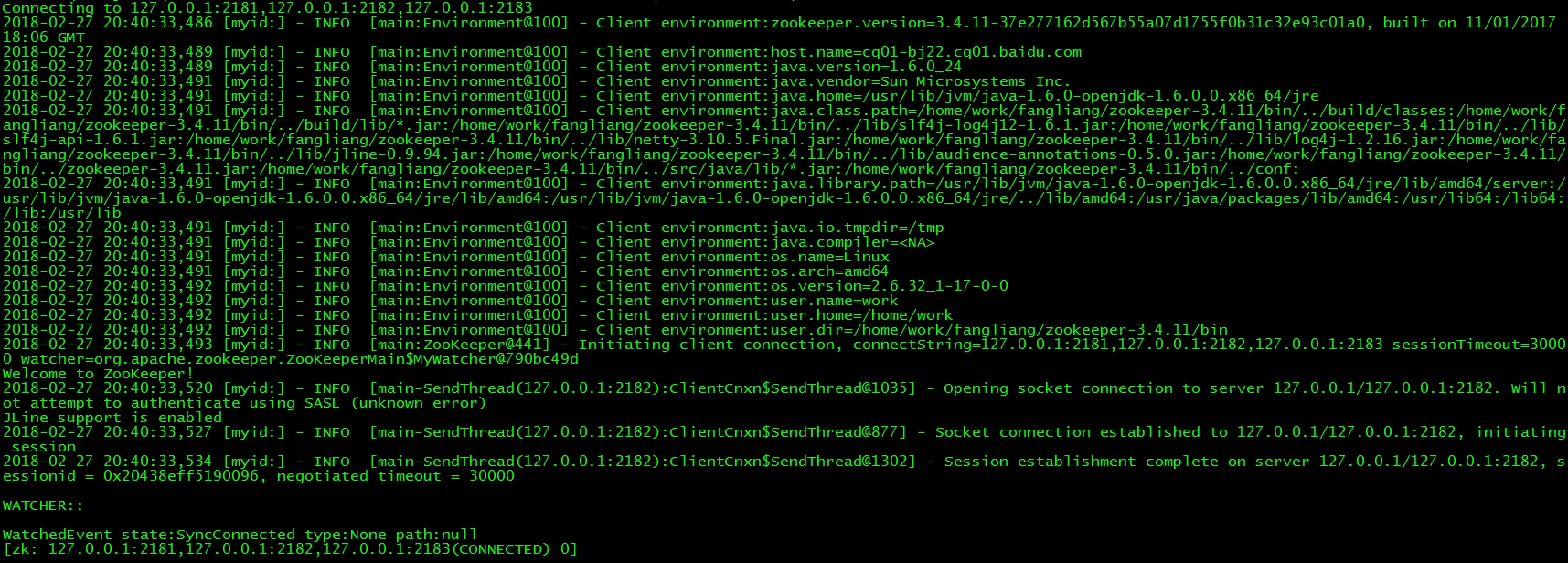
如下图,ABCD构成了一个集群,其中A是Leader。开始时甲连接的是A机器,ABCD各机器上服务保持了数据一致性。假如此时乙用户要连接任何一台服务,那么甲乙对数据的修改是彼此透明的。
但是,如果此时CD和AB断开了连接。以获得2票成为Leader的原则,很有可能CD选举出C为Leader,D从此和C同步数据。AB选举出A为Leader,B只和A同步数据。假如此时乙用户要接入,而不巧接入到C或者D。那么甲乙对数据的修改就是隔离的。这样一个系统中出现两个Leader的现象称之为“脑裂”,这当然是不能接受的。
选择好数量后,我们从https://www.apache.org/dyn/closer.cgi/zookeeper/下载并解压压缩包。以我环境为例,解压后文件路径为
$ pwd /home/work/fangliang/zookeeper-3.4.11
进入该目录,新建一个叫multi_server的文件夹。然后在其下新建z1、z2和z3三个目录,这三个目录分别用于保存三个Zookeeper Server的信息。
mkdir multi_server cd multi_server mkdir -p z1/data mkdir -p z2/data mkdir -p z3/data echo 1 > z1/data/myid echo 2 > z2/data/myid echo 3 > z3/data/myid
myid文件的内容是其对应的服务id。
然后在z1、z2和z3下分别创建z1.cfg,z2.cfg,z3.cfg三个文件。以z1.cfg为例,我们在文件中填充
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/work/fangliang/zookeeper-3.4.11/multi_server/z1/data clientPort=2181 server.1=127.0.0.1:2222:2223 server.2=127.0.0.1:3333:3334 server.3=127.0.0.1:4444:4445
相应的,我们需要将z2.cfg和z3.cfg文件中dataDir指向自己目录,clientPort指向其他的端口
dataDir=/home/work/fangliang/zookeeper-3.4.11/multi_server/z2/data clientPort=2182
dataDir=/home/work/fangliang/zookeeper-3.4.11/multi_server/z3/data clientPort=2183
整个文件的目录树如下
multi_server/
|-- z1
| |-- data
| | |-- myid
| |-- z1.cfg
|-- z2
| |-- data
| | |-- myid|
| |-- z2.cfg
`-- z3
|-- data
| |-- myid
`-- z3.cfg
接下来我们开始启动各个服务。
首先启动z1。
且到z1目录下,执行
../../bin/zkServer.sh start ./z1.cfg当前目录下会生成一个日志文件zookeeper.out。

第三行我们看到它发起了一次选举,但是由于其他两个服务没有启动,所以整个系统还不可用。
然后我们启动z2。
切到z2目录下,执行
../../bin/zkServer.sh start ./z2.cfg
我们查看下z2目录下日志文件
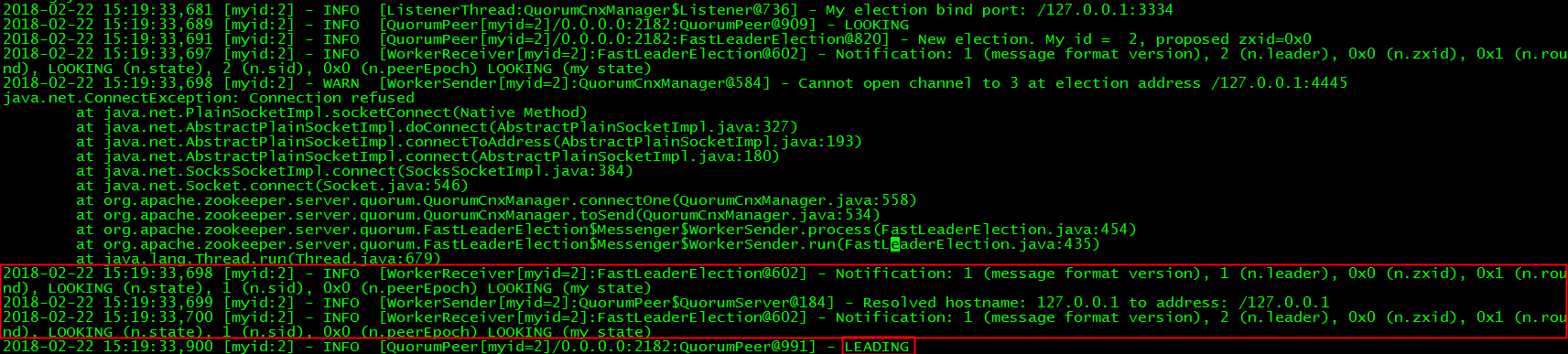
第三行显示z2也发起了一次选举,由于此时z3没有启动,所以它只能和z1进行通信。最终它们使用FastLeaderElection协商出z2作为Leader。

然后z2和z1进行了数据同步。
我们再看下z1日志的变化。
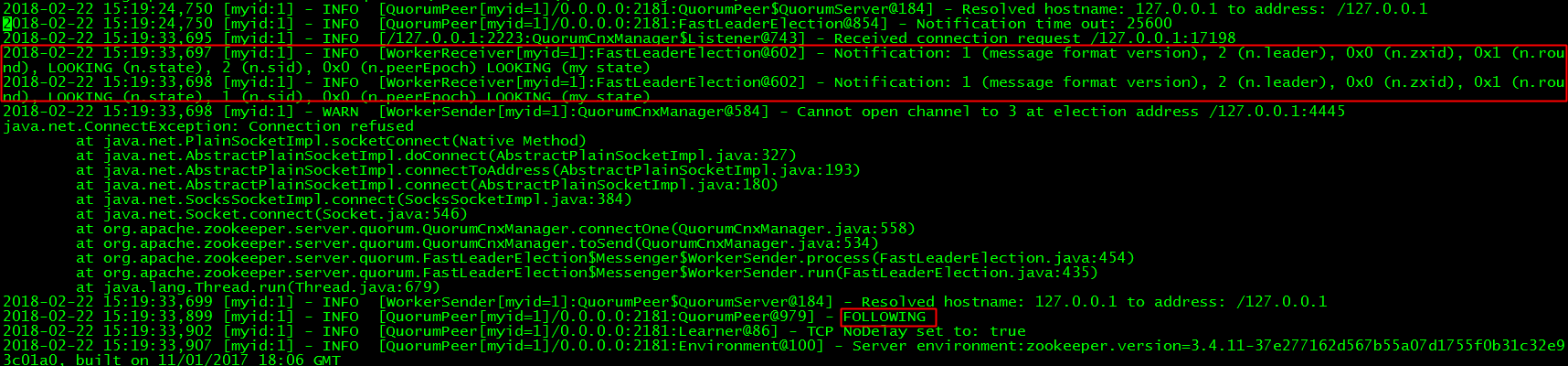
z1仍然和z3通信失败。但是和z2通信后,自己成为了follower。
最后我们启动z3。
切到z3目录下执行
../../bin/zkServer.sh start ./z3.cfg
查看z3的日志

z3发起了一次选举,但是z2此时已经是leader了,所以z3顺理成章的成为follower,并从z2服务同步了一份数据快照

此时看下z1的日志,它发现了z3

再看下z2的日志,它发现z3后,给z3同步了一次数据

我们切换到bin目录,执行
./zkCli.sh -server 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
让Client连接到上述三台机器中的一台,可以看到如下显示