总结:使用save()方法更新某一具体的记录(如用户密码),必须要提供该记录的ID。
以常见的用户管理为例,当我们调用userRepository.save()时,这是它背后的逻辑:
- 如果实体的ID为
null或者不在数据库中,save()将会执行一个插入操作来创建一个新的记录。- 如果实体的ID在数据库中存在,那么
save()将会执行一个更新操作,更新现有的记录。
如果发现save()方法总是创建新的记录,即使设置了名称为唯一,这通常说明实体的ID字段在save()被调用时为null或者不存在于数据库中。请检查以下几点:
-
实体ID的生成策略:确保实体类中ID字段的生成策略是正确的。如果使用的是自动生成的ID(比如使用
@GeneratedValue),请确保在更新实体时ID字段被正确设置 -
实体的状态:在更新之前确保实体的状态是持久化状态。如果你从前端传递一个带有名称和密码但没有ID的对象,JPA会认为这是一个新的实体并尝试插入。
-
结合上述两点可以得出结论:如果要使用save()方法更新某一具体的记录(如用户密码),必须要提供该记录的ID。否则数据库会默认自增一个ID,新创建一个同名的用户,然后分配他密码,而不是更改原本用户的密码。
-
-
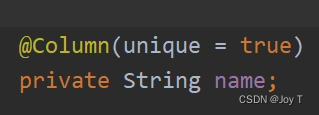
唯一约束的配置:即使设置了名称为唯一,如果在保存时没有提供ID,JPA仍会尝试插入新的记录。唯一约束违反会在数据库层面抛出异常,不会阻止JPA尝试执行插入操作。确保你处理了这类异常。所以说唯一约束并不是万能的,并不是一蹴而就的,我们仍然需要防止JPA的某些行为,不能只停留在数据库的安全规范上,所以尽量在JPA中使用逻辑判断和异常处理,以作者的代码为例:
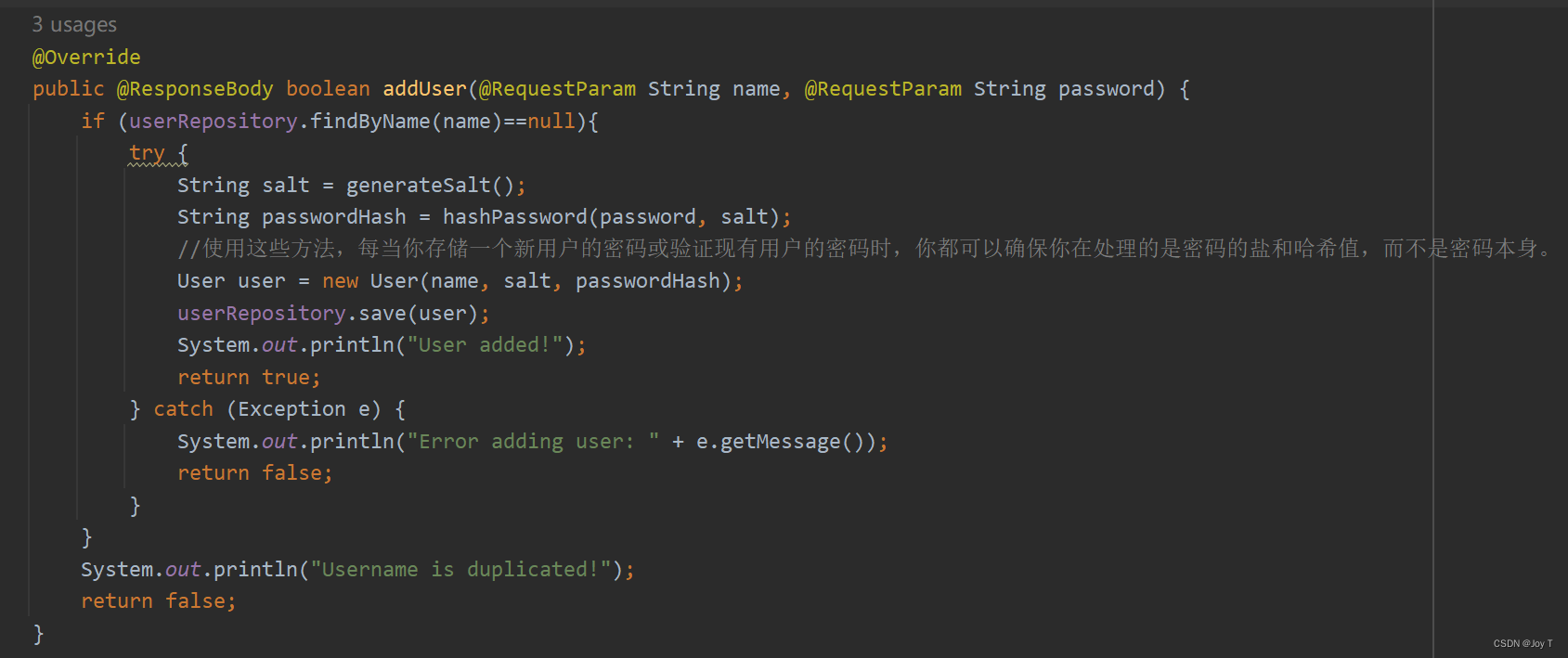
仅仅增加唯一性约束不能保证解决所有问题哦: