
本文字数:4920;估计阅读时间:13 分钟
审校:庄晓东(魏庄)
发布摘要
- 新增了 31 个功能
- 实现了 16 个性能优化
- 修复了 47 处bug
本文描述了部分特别值得我们重点关注的新功能。但值得注意的是,现在有几个功能已经在生产环境就绪,或处于默认启用的状态。您可以在这篇文章的末尾找到它们。
新贡献者
特别欢迎所有23.7版本的新贡献者!ClickHouse的流行在很大程度上要归功于为社区做出贡献的贡献者们的努力。社区的茁壮成长总是令所有人都非常振奋。
如果你看到你的名字出现在下面的清单中,请联系我们...我们也会在Twitter等地方,等待你的联系。
Alex Cheng, AlexBykovski, Chen768959, John Spurlock, Mikhail Koviazin, Rory Crispin, Samuel Colvin, Sanjam Panda, Song Liyong, StianBerger, Vitaliy Pashkov, Yarik Briukhovetskyi, Zach Naimon, chen768959, dheerajathrey, lcjh, pedro.riera, therealnick233, timfursov, velavokr, xiao, xiaolei565, xuelei, yariks5s
Parquet写入的改进(Michael Kolupaev)
近几个月我们看到了ClickHouse在Parquet文件格式上的多项读取改进。除了跨行组并行读取和使用元数据进行过滤外,我们甚至还花时间确保在Hugging Face数据集上的查询是优化的。我们知道这种文件格式无处不在,对于像使用clickhouse-local进行本地分析和数据迁移这样的任务至关重要。我们持续的提高我们对Parquet的支持和对速度的追求,已经在我们公开的基准测试中得到了回报。
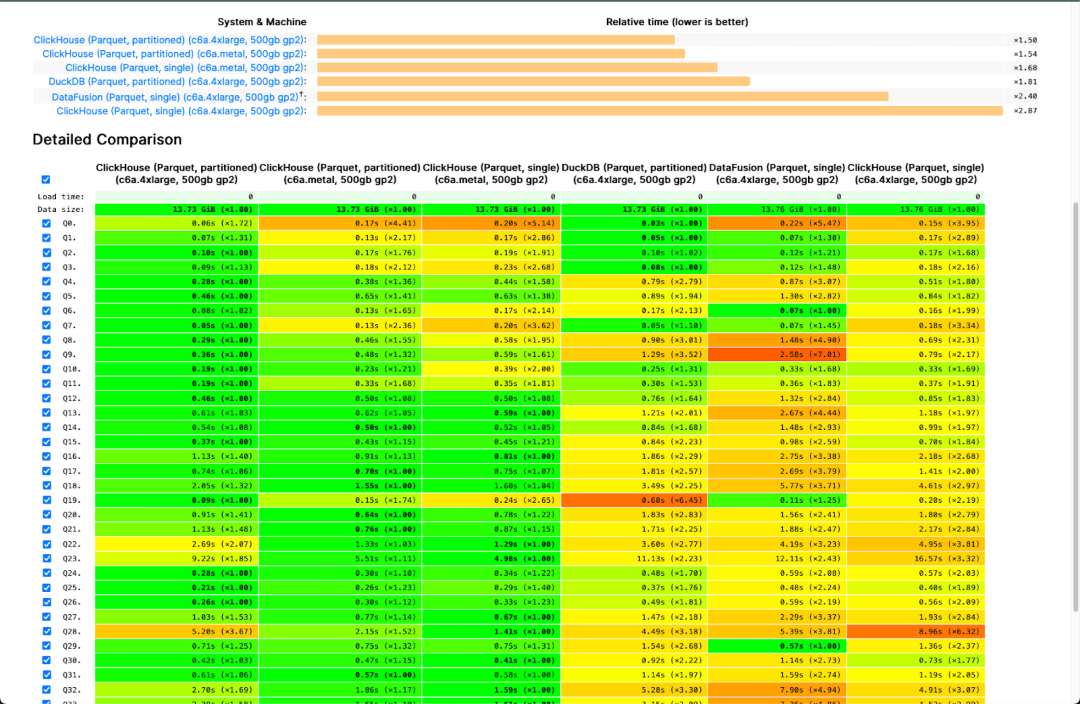
当然,读取Parquet只是故事的一半。用户不可避免地需要将ClickHouse数据写入Parquet,通常作为反向ETL工作流的一部分或需要分享数据分析的结果。因此,我们很高兴地宣布,从23.7版本开始,Parquet的写入速度现在快了6倍。
让我们使用英国房价数据的例子来说明。下面,我们使用 clickhouse-local 并从一个已经公开托管在S3上的Parquet文件中导入数据。
CREATE TABLE uk_house_price
ENGINE = MergeTree
ORDER BY (postcode1, postcode2, addr1, addr2)
SETTINGS allow_nullable_key = 1 AS
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices.parquet')
0 rows in set. Elapsed: 40.550 sec. Processed 28.28 million rows, 4.67 GB (697.33 thousand rows/s., 115.15 MB/s.)使用23.6导入此数据集的速度仍然非常快,几乎达到每秒150万行。
SELECT *
FROM uk_house_price
INTO OUTFILE 'london-prices.parquet'
28276228 rows in set. Elapsed: 19.901 sec. Processed 28.20 million rows, 4.66 GB (1.42 million rows/s., 233.98 MB/s.)使用23.7导入相同的数据集有显著的改进,总时间几乎缩短了一半!实际效果可能会有所不同,但我们观察到的改进效果高达6倍。
SELECT *
FROM uk_house_price
INTO OUTFILE 'london-prices.parquet'
28276228 rows in set. Elapsed: 11.649 sec. Processed 28.24 million rows, 4.66 GB (2.42 million rows/s., 400.39 MB/s.)默认启用的稀疏列(Anton Popov)
ClickHouse支持稀疏列已经有一段时间了,但在23.7之前需要明确启用。这个优化旨在减少某列写入的总数据,当检测到大量的默认值时,动态地改变编码格式。除了提高压缩率,这还有助于提高查询性能和内存效率。
在23.7中,此功能默认启用。当可以应用这种编码时,用户应该立即看到压缩和性能的提升。
当写入数据Part时(无论是在插入还是合并时),ClickHouse会计算每一列的默认值的比率。如果这超过了配置的阈值,那么只有非默认的值会被写入该列。为了保留哪些行具有默认值,会写入一个单独的流,其中包含偏移量的编码。在查询时会组合这些信息,确保这种优化对用户是完全透明的。以下的图示展示了这方面的一个例子:
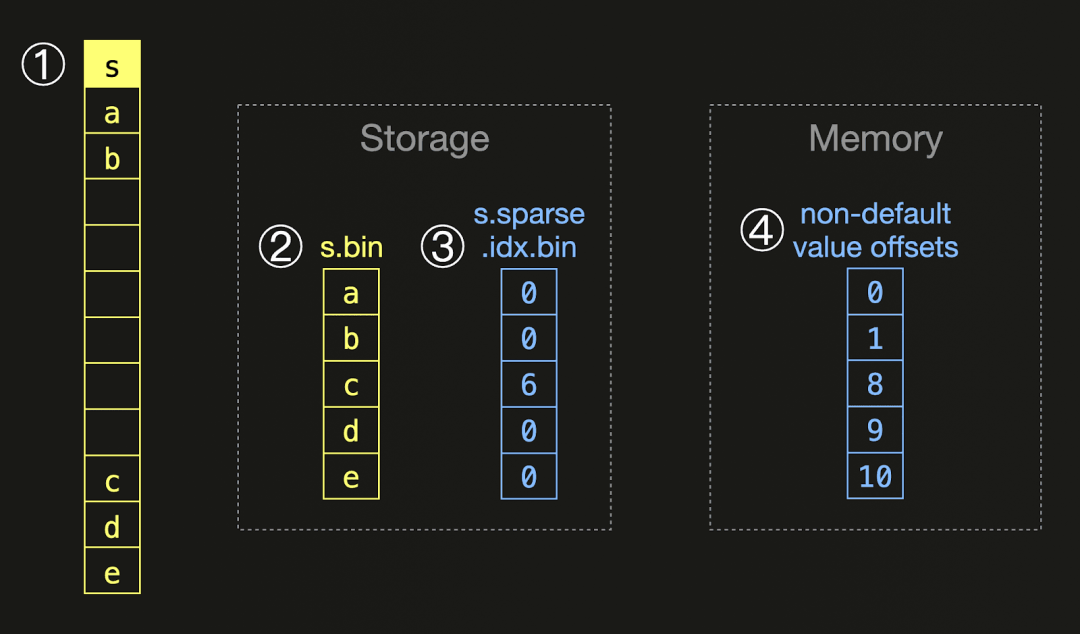
对于一个包含稀疏值的①列 s ,ClickHouse只将非默认值写入磁盘上的②列文件,并与③一个包含非默认值偏移量的稀疏编码文件一起:对于每一个非默认值,我们存储在这个非默认值之前直接存在的默认值的数量。在查询时,我们从这种编码中创建一个带有直接偏移量的④内存表示。稀疏编码的存储变种包含有重复值的数据。
在23.7之前,用户需要通过修改控制稀疏列编码使用所需的阈值的设置来明确启用稀疏列 - ratio_of_defaults_for_sparse_serialization。这默认值为1.0,实际上禁用了这个特性。在23.7中,这个值默认为0.9375。
尽管我们期望稀疏列能够使结构化数据受益,但我们希望在用户插入非结构化数据的场景下也有益处,例如具有高度可变键的JSON。在这些情况下,用户几乎不会因为只有几行的列有值而支付任何额外的开销 - 这可能带来显著的空间节省。
尽管我们预期在我们的公开ClickBench基准测试中会有所改进,但默认启用这一优化所带来的额外益处是一个令人愉快的惊喜。

实验性支持PRQL(由János Benjamin Antal提供)
在ClickHouse,我们坚信SQL是所有查询语言中的教父,它有能力处理几乎所有的数据问题。随着时间的推移,许多语言都试图与SQL竞争或取代SQL,获得了不同程度的成功。新的查询语言迅速出现,但往往也同样迅速地消失。SQL的持久性和其在连续版本中被许多数据存储系统所采纳,证明了其重要性。然而,我们也认识到与用户在熟悉的领域进行互动的重要性,并认识到有些语言比其他语言更适合某些场景。如果我们看到对一个查询语言有足够的采纳和需求,我们会考虑增加支持,并始终欢迎社区的PR!多亏了这样的社区贡献,ClickHouse现在实验性地支持PRQL。
PRQL (Pipelined Relational Query Language) 发音为“Prequel”,定位为“一个简单、强大、流水线式的SQL替代品”。这种流水线式的语法已经变得很受欢迎,并且有一个不断增长的贡献者社区。通过串联转换来形成流水线,复杂的SQL查询可以优雅地组合。在ClickHouse,我们可以看到这种查询构建风格在某些应用中有一些潜在的使用,尤其是在用户进行搜索和发现练习的场景中 - 可能是可观察性?
此外,用户不仅可以查阅详细的文档,还可以在公共环境进行实验(https://prql-lang.org/playground/)。让我们考虑使用英国房价数据集的几个简单例子。假设希望在伦敦查找最高的区域。
from uk_house_price
filter town == 'LONDON'
group district (
aggregate {
avg_price = average price
}
)
sort {-avg_price}
take 1..10
SELECT
district,
AVG(price) AS avg_price
FROM uk_house_price
WHERE town = 'LONDON'
GROUP BY district
ORDER BY avg_price DESC
LIMIT 10
┌─district───────────────┬──────────avg_price─┐
│ CITY OF LONDON │ 2016389.321229964 │
│ CITY OF WESTMINSTER │ 1107261.809839673 │
│ KENSINGTON AND CHELSEA │ 1105730.3371717487 │
│ CAMDEN │ 752077.7613715645 │
│ RICHMOND UPON THAMES │ 644835.3877018511 │
│ HAMMERSMITH AND FULHAM │ 590308.6679440506 │
│ HOUNSLOW │ 574833.3599378078 │
│ ISLINGTON │ 531522.146523729 │
│ HARLOW │ 500000 │
│ WANDSWORTH │ 464798.7692006684 │
└────────────────────────┴────────────────────┘
10 rows in set. Elapsed: 0.079 sec.如所示,ClickHouse为我们提供了与PRQL查询编译后等效的SQL语句。
对于不太有经验的SQL用户来说,一个可能更具挑战性的查询是为每个组的特定列找到最高的行。例如,下面我们按价格排序,找到英国每个邮政编码中最昂贵的房子。
from uk_house_price
filter town == 'LONDON'
filter postcode1 != ''
select {
postcode1, street, price
}
group postcode1 (
sort {-price}
take 1
)
sort {-price}
take 1..10
WITH table_0 AS
(
SELECT
postcode1,
street,
price
FROM uk_house_price
WHERE (town = 'LONDON') AND (postcode1 != '')
ORDER BY
postcode1 ASC,
price DESC
LIMIT 1 BY postcode1
)
SELECT
postcode1,
street,
price
FROM table_0
ORDER BY price DESC
LIMIT 10
┌─postcode1─┬─street──────────┬─────price─┐
│ W1U │ BAKER STREET │ 594300000 │
│ W1J │ STANHOPE ROW │ 569200000 │
│ SE1 │ SUMNER STREET │ 448500000 │
│ E1 │ BRAHAM STREET │ 421364142 │
│ EC2V │ GRESHAM STREET │ 411500000 │
│ SE10 │ WATERVIEW DRIVE │ 400000000 │
│ EC1Y │ MALLOW STREET │ 372600000 │
│ SW1H │ BROADWAY │ 370000000 │
│ W1S │ NEW BOND STREET │ 366180000 │
│ EC4V │ CARTER LANE │ 337000000 │
└───────────┴─────────────────┴───────────┘
10 rows in set. Elapsed: 0.498 sec. Processed 25.32 million rows, 574.02 MB (50.83 million rows/s., 1.15 GB/s.)
Peak memory usage: 60.70 MiB.上述查询相对于等效的SQL的简洁性相当引人注目。
作为一种编译成SQL的语言,我们很兴奋地看到PRQL是如何发展的,以及它与ClickHouse一起应用于哪些用例。如果您发现PRQL很有用并已经解决了一些问题,请告诉我们!

联系我们
手机号:13910395701
满足您所有的在线分析列式数据库管理需求