秋招也逐渐接近为尾声,通过一篇博客来记录秋招过程中的一些面经,主要来源自己实习、提前批、秋招面经和niuke整理。
一、百度
1、代码题
leetcode
Leetcode_125:回文串
Leetcode_647:回文子串
Leetcode_151:一个英文句子全部逆序输出
Leetcode_557:句子中每个单词不改变位置,但是每个单词都需要逆序输出
Leetcode_141:单链表如果有环怎么判断?
Leetcode_70:跳台阶问题
Leetcode_516:最长回文子序列
Leetcode_912:快排
其他
①n个孩子围成一圈,然后隔m个人出去,最后留下的是谁?(约瑟夫环问题)
/*
已知 n 个人(以编号1,2,3 … n 分别表示)围成一圈。
从编号为 1 的人开始报数,数到 m 的那个人出列;他的下一个人又从 1 开始报数,数到 m 的那个人又出列;
依此规律重复下去,直到最后剩下一个人。要求找出最后出列的人的编号
*/
// 通过环形链表形式实现,遇到第m个直接删除该节点
public static int solve(int n, int m){
if(m == 1 || n < 2) return n;
// 创建环形链表
Node head = createLinkedList(n);
// 遍历删除
int count = 1; // 用来记录当前数到几号了
Node cur = head;
Node pre = null;
while(head.next != head){
// 删除节点
if(count == m){
count = 1;
pre.next = cur.next;
cur = pre.next;
}else {
count++;
pre = cur;
cur = cur.next;
}
}
return head.value;
}
public static Node createLinkedList(int n){
Node head = new Node(1);
Node next = head;
for(int i = 2; i <= n; i++){
next.next = new Node(i);
next = next.next;
}
// 头尾相连
next.next = head;
return head;
}
class Node{
int value;
Node next;
public Node(int value) {
this.value = value;
}
}
2、Linux
linux常用命令?
ls: 列出目录alias:例如,要设置ls为颜色而不每次键入标志--color,您将使用:
alias ls="ls --color=auto"
pwd:所在目录的绝对路径(完整路径)cd:切换目录cp:复制文件和文件夹
前者是源文件,后者是目标文件
cp file_to_copy.txt new_file.txt
rm:删除包含内容的目录:rm -rfmv:移动(或重命名)文件和目录
前者源文件,后者目标文件
mv source_file destination_folder/
mv command_list.txt commands/
mkdir:创建文件夹chmod:更改文件权限
- r (只读) 4
- w (写入) 2
- x (执行) 1
cat:预览文件ps:打印有关正在运行的程序的信息kill:kill PID号vim:命令模式(Command Mode)、输入模式(Insert Mode)和命令行模式(Command-Line Mode)。i – 切换到输入模式,在光标当前位置开始输入文本;: – 切换到底线命令模式,以在最底一行输入命令;which:查找文件grep:搜索与正则表达式匹配的行并打印它们
# 使用-c标志计算与给定条件匹配的次数
grep -c "linux" long.txt
# 2
在linux上创建一个文件,创建失败了可能是什么原因?除了权限还有其他原因吗?
-
当前目录对应的磁盘空间不足;在某个目录下创建文件时,实际上是在这个目录对应的磁盘上操作,如果这个磁盘已经满了,自然就创建失败。
-
inode不足;由于一个文件对应一个inode,当磁盘里的小文件过多时,就会出现block数量还很多,但是inode分配完了,也就是空间还很多,但是也无法创建,那是因为创建文件时,申请inode号失败。
———理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做”扇区”(Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个”块”(block)。这种由多个扇区组成的**”块”,是文件存取的最小单位**。”块”的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在”块”中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为”索引节点”。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
linux的读文本筛选,如果有4列需要按照第三列降序排列,怎么实现?
apple:10:2.5
orange:20:3.4
banana:30:5.5
pear:90:2.3
# 三列数据,中间以 : 间隔
# apple:10:2.5
# orange:20:3.4
# banana:30:5.5
# pear:90:2.3
sort -n -k 3 -t : -r **.txt
# -n 以数值大小排序
# -k 3 第三列排序
# -t : 以:作为分隔符
# -r 倒序(降序)
linux服务器很卡如何判断,用什么命令?
- 服务器性能分析:
top命令是 Linux 下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,默认5秒刷新一下进程列表,所以类似于 Windows 的任务管理器 - 虚拟机分析:
数据库方面:排除高并发因素先要找到导致CPU过高的SQL
mysql> show full processlist;
如何查看日志,grep如何过滤多个条件
① grep -E "word1|word2|word3" file.txt
满足任意条件(word1、word2和word3之一)将匹配。
② grep word1 file.txt | grep word2 |grep word3
必须同时满足三个条件(word1、word2和word3)才匹配。
grep参数:
-i:忽略大小写进行匹配。-v:反向查找,只打印不匹配的行。-n:显示匹配行的行号。-r:递归查找子目录中的文件。-l:只打印匹配的文件名。-c:只打印匹配的行数。
3、计算机网络
tcp为啥传输可靠
- 确认重传机制:接收方收到报文就会确认,发送发送一段时间后没有确认就会重传;
- 数据校验:TCP报文头有校验字段,用于验证报文是否损坏;
- 流量控制:当接收方来不及处理发送方的数据,可以通过滑动窗口,提示发送方降低发送速率,防止包丢失;
- 拥塞控制:当网络拥塞时,通过拥塞窗口,减少数据的发送;
- 序号机制:确保数据按序到达。
七层模型每层含义和常见协议
- 物理层:确保原始的数据可在各种物理媒体上传输;
- 数据链路层 :在不可靠的物理介质上提供可靠的传输;该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等
- 网络层 :对子网间的数据包进行路由选择;网络层还可以实现拥塞控制、网际互连等功能
- 传输层 :端到端,即主机到主机的层次;负责将上层数据分段并提供端到端的、可靠的或不可靠的传输
- 会话层:理主机之间的会话进程,即负责建立、管理、终止进程之间的会话
- 表示层 :解决用户信息的语法表示问题;数据的压缩和解压缩, 加密和解密等工作都由表示层负责
- 应用层 :操作系统或网络应用程序提供访问网络服务的接口
传输层和数据链路层如何联系
当你输入一个网址并按下回车键的时候,首先,应用层协议对该请求包做了格式定义;紧接着传输层协议加上了双方的端口号,确认了双方通信的应用程序;然后网络协议加上了双方的IP地址,确认了双方的网络位置;最后链路层协议加上了双方的MAC地址,确认了双方的物理位置,同时将数据进行分组,形成数据帧,采用广播方式,通过传输介质发送给对方主机。而对于不同网段,该数据包首先会转发给网关路由器,经过多次转发后,最终被发送到目标主机。目标机接收到数据包后,采用对应的协议,对帧数据进行组装,然后再通过一层一层的协议进行解析,最终被应用层的协议解析并交给服务器处理。
cookie和session
共同之处:都是用来跟踪浏览器用户身份的会话方式。
Cookie工作原理:
- 浏览器第一次发送请求到服务器端
- 服务端创建cookie,该cookie包含用户的信息,然后将cookie发送到浏览器端
- 浏览器再次访问服务端时会携带之前创建的cookie
- 服务端通过cookie中携带的信息区分用户,cookie实际是保存在浏览器端。

Session工作原理:
- 浏览器第一次发送请求到服务器端
- 服务器端创建一个Session,同时会创建一个特殊的Cookie(name为
JSESSIONID的固定值,value为session对象的ID),然后将该Cookie发送至浏览器端 - 浏览器端再次发送请求到服务器端,浏览器端访问服务器端时就会携带该name为JSESSIONID的Cookie对象
- 服务器端根据name为
JSESSIONID的Cookie的value(sessionId),去查询Session对象,从而区分不同用户。
session:
简单的说,当你登陆一个网站的时候,如果web服务器端使用的是session,那么所有的数据都保存在服务器上,客户端每次请求服务器的时候会发送当前会话sessionid,服务器根据当前sessionid判断相应的用户数据标志,以确定用户是否登陆或具有某种权限。由于数据是存储在服务器上面,所以你不能伪造。
cookie:
如果浏览器使用的是cookie,那么所有数据都保存在浏览器端,比如你登陆以后,服务器设置了cookie用户名,那么当你再次请求服务器的时候,浏览器会将用户名一块发送给服务器,这些变量有一定的特殊标记。服务器会解释为cookie变量,所以只要不关闭浏览器,那么cookie变量一直是有效的,所以能够保证长时间不掉线。
二者区别:
-
cookie数据保存在客户端,session数据保存在服务端。
-
cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗(CSRF cookie跨站点伪造攻击),如果主要考虑到安全应当使用session
-
session会在一定时间内保存在服务器上
-
单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K
-
将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中
http keep-alive
众所周知,HTTP是短连接,client向server发送一个request,得到response后,连接就关闭。之所以这样设计使用,主要是考虑到实际情况。
例如,用户通过浏览器访问一个web站点上的某个网页,当网页内容加载完毕之后,用户可能需要花费几分钟甚至更多的时间来浏览网页内容,此时完全没有必要继续维持底层连。当用户需要访问其他网页时,再创建新的连接即可。因此,HTTP连接的寿命通常都很短。这样做的好处是,可以极大的减轻服务端的压力。一般而言,一个站点能支撑的最大并发连接数也是有限的,面对这么多客户端浏览器,不可能长期维持所有连接。每个客户端取得自己所需的内容后,即关闭连接,更加合理。
为什么引入 keep-alive:
通常一个网页可能会有很多组成部分,除了文本内容,还会有诸如:js、css、图片等静态资源,有时还会异步发起AJAX请求。只有所有的资源都加载完毕后,我们看到网页完整的内容。然而,一个网页中,可能引入了几十个js、css文件,上百张图片,如果每请求一个资源,就创建一个连接,然后关闭,代价实在太大了。
基于此背景,我们希望连接能够在短时间内得到复用,在加载同一个网页中的内容时,尽量的复用连接,这就是HTTP协议中keep-alive属性的作用。
- HTTP 1.0 中默认是关闭的,需要在http头加入"
Connection: Keep-Alive",才能启用Keep-Alive; - HTTP 1.1 中默认启用
Keep-Alive,如果加入"Connection: close",才关闭。
什么是keep-alive:
keep-alive 是客户端和服务端的一个约定,如果开启 keep-alive,则服务端在返回 response 后不关闭 TCP 连接;
4、数据库
手撕sql:学生表和成绩表查询某个学生成绩
# 查询1课程比2课程成绩高的学生的信息及课程分数
SELECT s.sid,s.sname,s.sage,s.ssex,sc1.score,sc2.score FROM student s ,sc sc1,sc sc2 WHERE
sc1.`cid`=1 AND sc2.`cid`=2 AND sc1.`score`>sc2.`score` AND sc1.`sid`=s.`sid`AND sc2.`sid`=s.`sid`;
# 查询平均成绩大于等于60分的同学的 学生编号、学生姓名、平均成绩
SELECT s.sid,s.sname,AVG(sc1.`score`) AS 'avg_score'
FROM student s ,sc sc1
WHERE s.sid=sc1.`sid`
GROUP BY s.sid
HAVING avg_score>=60
ORDER BY avg_score DESC;
# 查询名字中包含“风”的学生信息
SELECT s.sid,s.sname,s.sage,s.ssex
FROM student s
WHERE sname LIKE '%风%';
# 查询1990年出生的学生信息
SELECT s.* FROM student s WHERE s.sage>='1990-01-01' AND s.sage<='1990-12-31';
SELECT s.* FROM student s WHERE s.sage LIKE '1990-%';
# 查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
SELECT sc.cid,AVG(score) AS avg_score
FROM sc
GROUP BY sc.cid ORDER BY avg_score DESC,sc.cid ASC;
# 查询每门课程的学生人数
SELECT cid AS '课程编号',COUNT(sid)AS '课程人数'
FROM sc
GROUP BY sc.cid;
# 查询本月过生日的学生姓名和出生年月
# _____ :五个下划线长度
SELECT s.sname,s.sage FROM student s WHERE s.sage LIKE '_____07%'; # 1990-07-01 横杠代表 1990-
SELECT s.sname,s.sage FROM student s WHERE s.sage LIKE '%07%';
一个元音字母开头或者ok结尾的过滤:
SELECT name
FROM names
WHERE LOWER(SUBSTRING(name,1,1)) IN ('a', 'e', 'i', 'o', 'u') OR name LIKE '%ok'
数据库索引
Innodb存储引擎将数据划分为若干个页,页作为磁盘与内存之间交互的最小单位(16KB)
在一个数据页中,用户记录是按照主键由小到大的顺序串联而成的单向链表
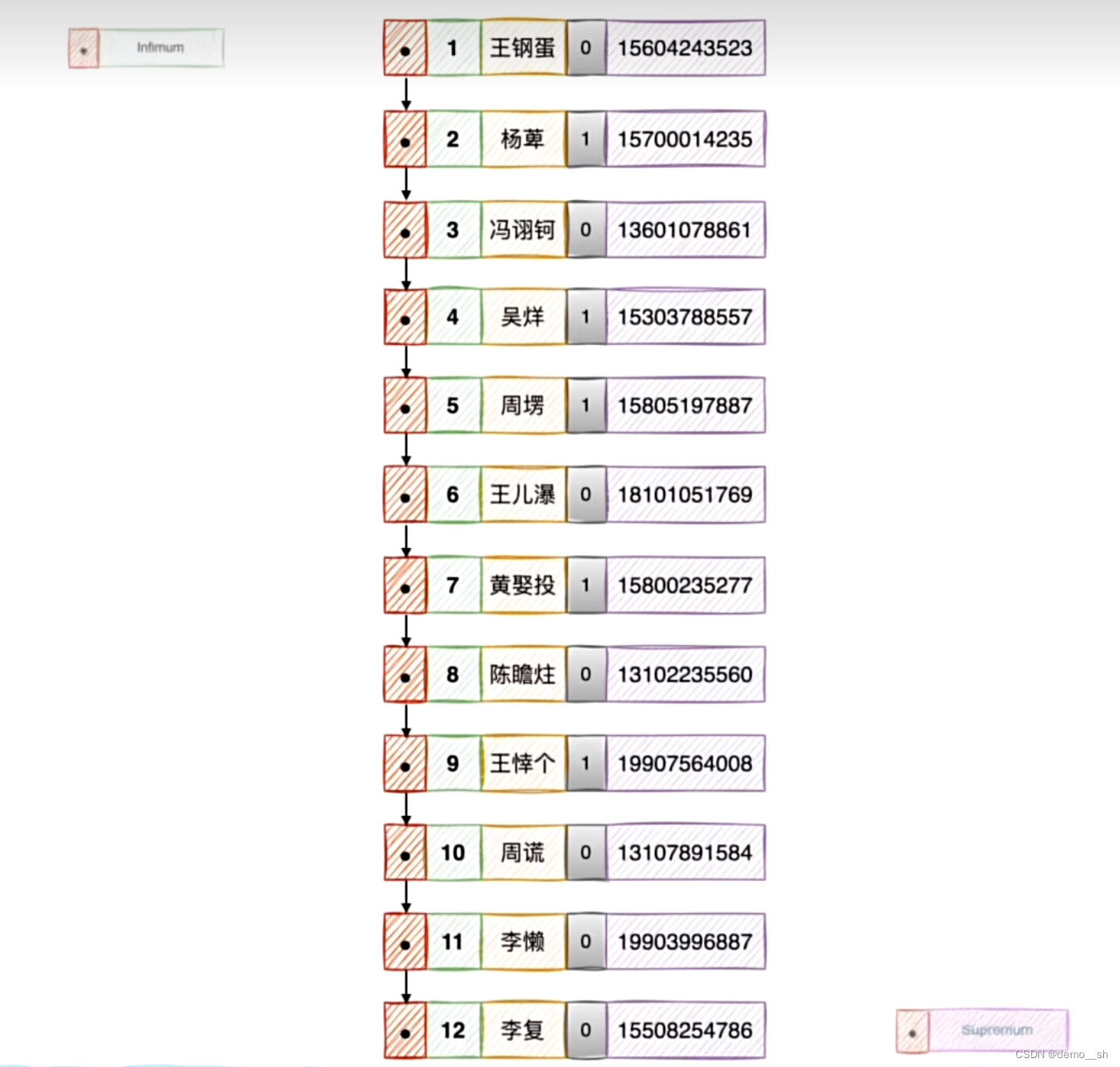
每个数据页中,Innodb会自动添加两条记录,分别是Infimum最下记录和Supremum最大记录
当每个数据页记录太大时,Innodb将页分为多个组,每个组选出小组长代表各个组,称这个目录为槽,槽在物理空间中是连续的,意味着通过一个槽可以很轻松的找到它的上一个和下一个。

当一个数据页不够用时,就再申请一个数据页,每个数据页通过双向链表的方式连接。
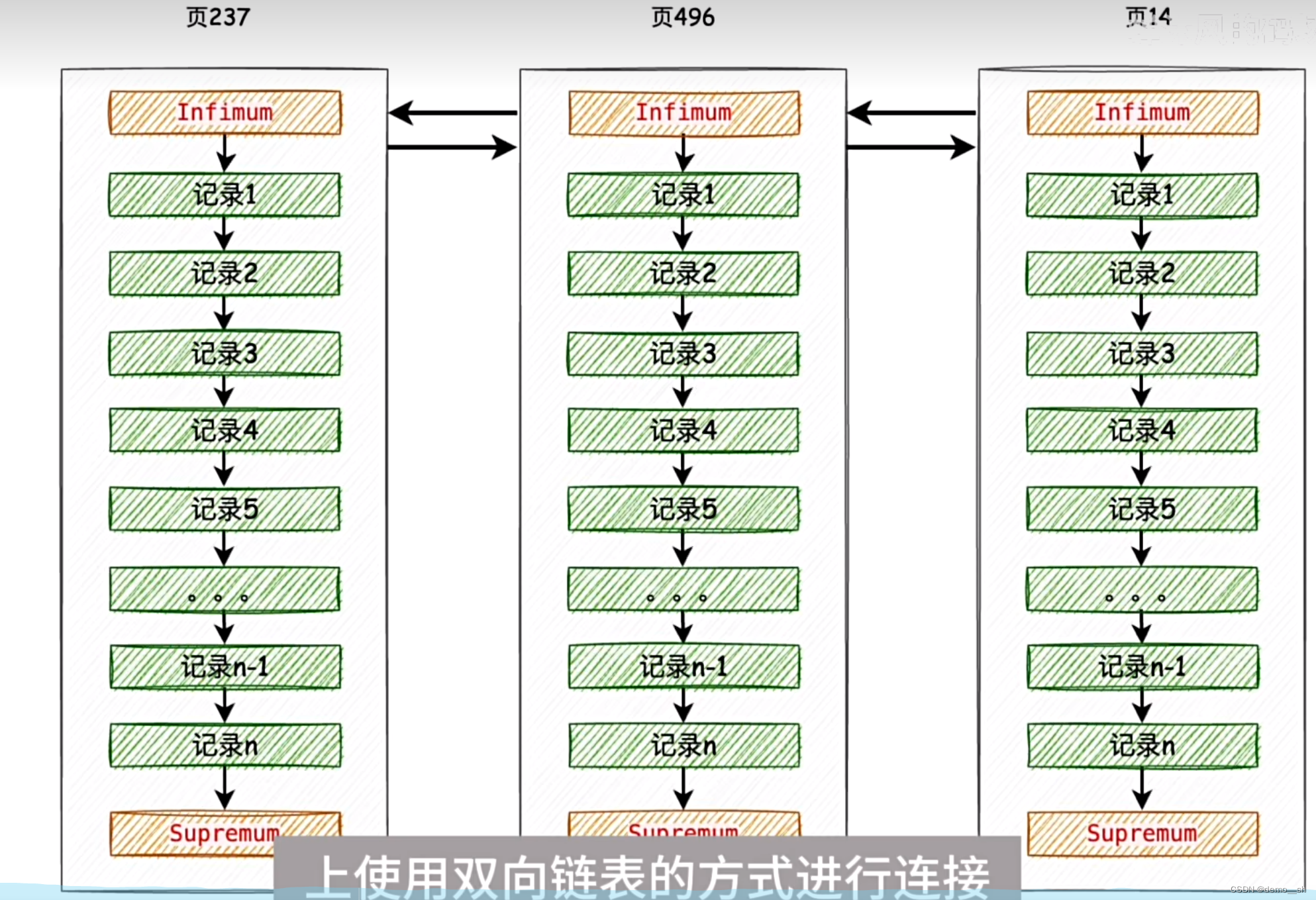
给每个数据页添加一个目录,目录项记录(根节点)只包含每个数据页中的最小主键值和对应的页号
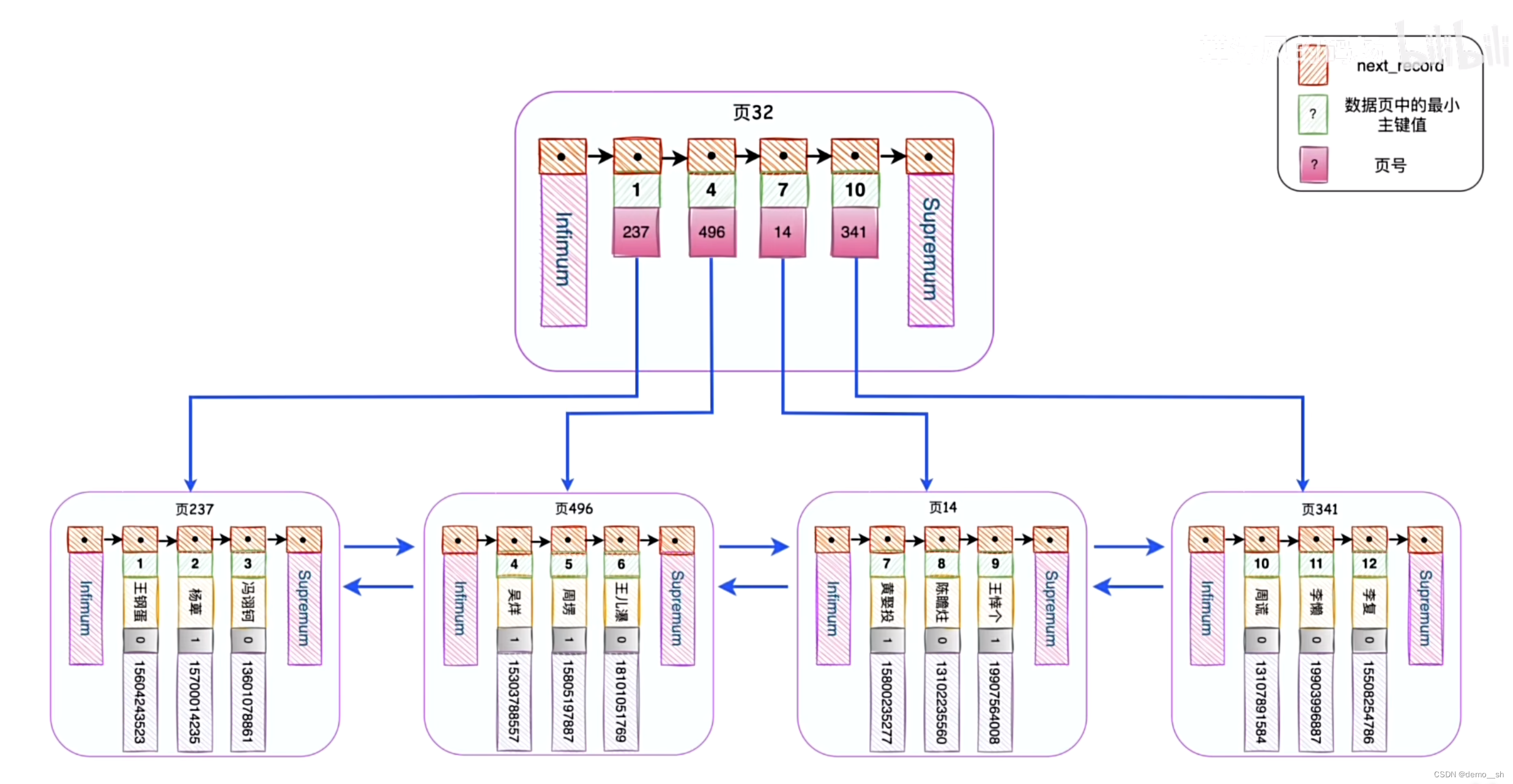
目录项不够用了怎么办?如果添加的目录页数据项也多了,就为目录项添加目录项目录页(根节点)。
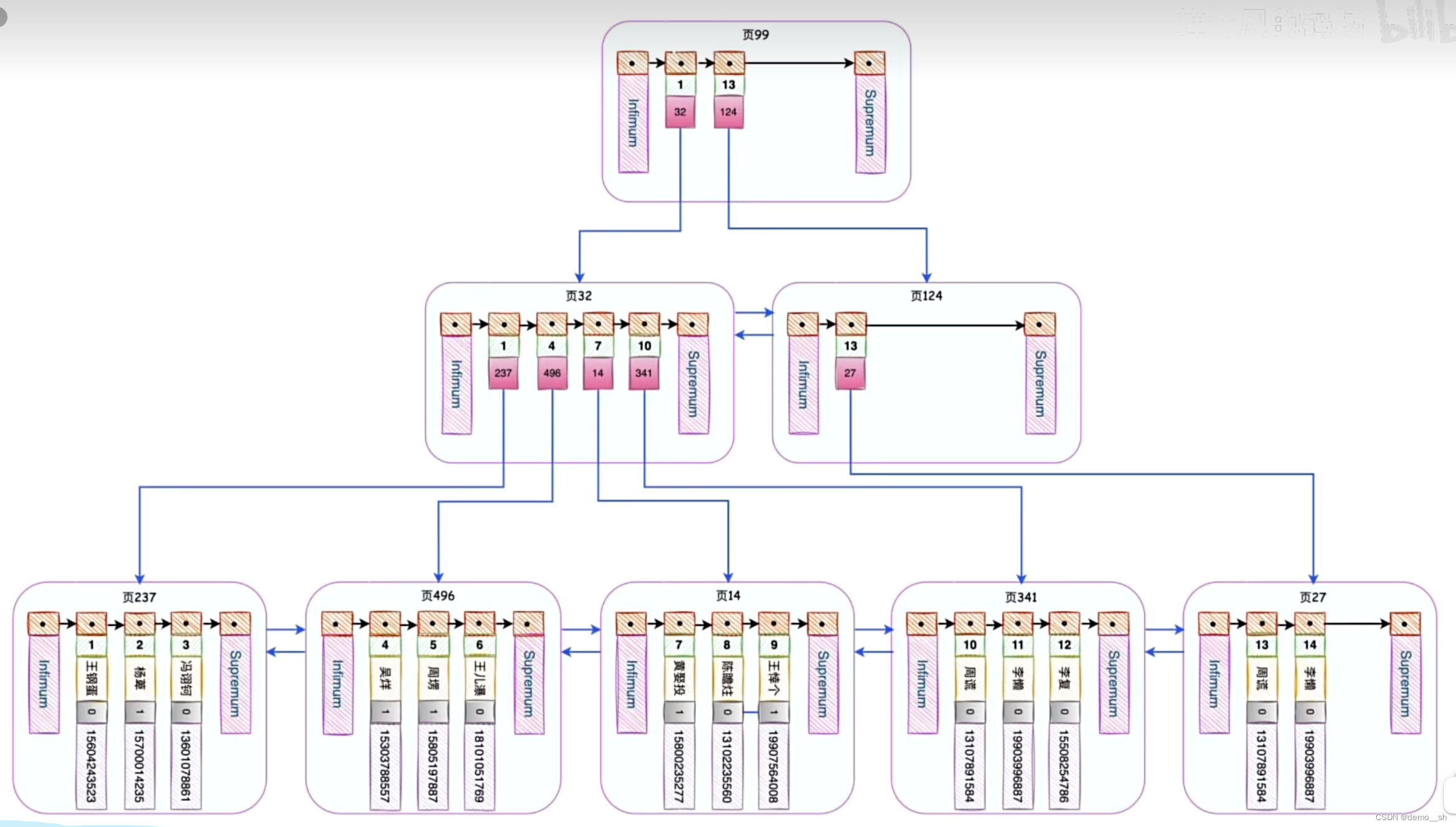
章->目录页->书架

B+树的叶子结点保存了所有的用户数据,即索引即数据,数据即索引。
主键索引有两个特点:
- 按照主键的大小对用户记录和数据页排序,记录用单向链表连接,数据页使用双向链表连接
- B+树的叶子节点保存了用户的完整记录
5、数据结构
八种常见的数据结构
- 哈希表
哈希表也叫散列表,是一种可以通过key-value直接访问的数据结构,可以实现快速查询、插入、删除。在jdk8中,Java中经典的HashMap,以数组+链表+红黑树构成。
- 队列
一种特殊的线性表,先进先出机制。
- 树
一种非线性结构,由n个有限节点组成的有层次关系的集合;其中包含二叉树、完全二叉树、满二叉树、二叉查找树、平衡二叉树、B树、B+树。
- 堆
堆可以看成是一个树的数组对象,具有特点:堆是一颗完全二叉树;大根堆;小根堆。
- 数组
是一种线性表的数据结构,连续的空间存储相同类型的数据;优点:查询速度快;缺点:数组在创建时大小确定,无法扩容,只能存储一种数据类型,添加、删除慢。
- 栈
先进后出的规则
- 链表
是一种线性表的链式存储结构,链表的内存不是连续的。链表通过一个指向下一个元素地址的引用将链表中的元素串联起来。链表分为:单向链表、双向链表、循环链表。
- 图
一个图就是一些顶点的集合,这些顶点通过一系列边连接。节点之间的关系是任意的,图中任意两个数据元素之间都有可能相关。
6、开发相关
1.Spring的注入的底层原理是什么
- 手动set注入:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<!--扫描service包-->
<context:component-scan base-package="com.autowired.service"></context:component-scan>
<!--装载bean -->
<bean name="userService" class="com.autowired.service.UserService">
<property name="orderService" ref="orderService"></property>
</bean>
<bean name="orderService" class="com.autowired.service.OrderService"></bean>
</beans>
@Component
public class UserService {
private OrderService orderService;
public void setOrderService(OrderService orderService) {
this.orderService = orderService;
}
public void test(){
System.out.println(orderService);
}
}
- xml自动注入方式:
autowire参数设置为:byName或者byType
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<!--扫描service包-->
<context:component-scan base-package="com.autowired.service"></context:component-scan>
<!--装载bean -->
<bean name="orderService" class="com.autowired.service.OrderService"></bean>
<!--autowire属性指定类型(byType,byName) 自动注入 -->
<bean name="userService" class="com.autowired.service.UserService" autowire="byName"></bean>
</beans>
@Component
public class UserService {
private OrderService orderService;
public void setOrderService(OrderService orderService) {
this.orderService = orderService;
}
public void test(){
System.out.println(orderService);
}
}
- @Autowired注解自动注入:
在使用XML配置文件需要添加下面配置: 打开注解使用权限
<!--打开注解使用权限 -->
<context:annotation-config></context:annotation-config>
注入:
@Component
public class UserService {
@Autowired
private OrderService orderService;
public UserService(OrderService orderService) {
this.orderService = orderService;
}
public void fangfa(OrderService orderService,OrderService orderService1){
this.orderService = orderService;
}
public void test(){
System.out.println(orderService);
}
}
依赖注入的优点:
- 减少了一个类和其他类的耦合并且减少依赖;
- 可以方便的分离出配置文件;
- 减少依赖程序中的构造代码;
- 客户端对依赖项变化不敏感。
2. java基本数据类型

八种基本数据类型:byte、short、int、long、float、double、char、boolean。
3. 抽象类和接口的区别
抽象类:被abstract关键词修饰的类成为抽象类;被abstract关键词修饰的方法称为抽象方法,抽象方法只有方法的声明,没有方法体。抽象类的特点:
- 抽象类只能被实例化,不能被继承;
- 包含抽象方法的一定是抽象类,但抽象类不一定含有抽象方法;
- 抽象类中的抽象方法的修饰符只能为public或者protected,默认为public;
- 一个子类继承一个抽象类,则子类必须实现父类的抽象方法,否则子类必须定义为抽象类;
- 抽象类可以包含属性、方法、构造方法,但是构造方法不能用于实例化,主要用途是被子类调用;
接口:被interface关键词修饰
- 接口可以包含变量、方法,其中变量被隐式指定为public static final,方法被隐式指定为public abstract;
- 一个接口可以实现多个接口;
接口只是功能的定义,而抽象类既可以为功能的定义也可以为功能的实现。
4. Java一些集合哪些是线程安全的
Vector、Hashtable、CurrentHashMap
5. 保证并发线程安全的方法
Java语言中各种操作共享的数据有5种类型:
- 不可变
不可变的对象一定是线程安全的
- 绝对线程安全
方法本来就有synchronized关键字修饰,再手动添加同步手段,保证多线程的安全
- 相对线程安全
相对线程安全需要保证该对象的单个操作是线程安全的,在必要的时候可以使用同步措施实现线程安全
- 线程兼容
Java中大部分类都是线程兼容的,通过添加同步措施,可以保证在多线程环境中安全使用这些类的对象
- 线程对立
无法通过添加同步措施,实现线程中的安全使用
6.Java线程安全的实现:
-
互斥同步
- 互斥:互斥是实现同步的一种手段,主要的互斥实现方式:
临界区(Critical Section)、互斥量(Mutex)、信号量(Semaphore) - 同步:多个线程并发访问共享数据,保证共享数据同一时刻只被一个(或者一些,使用信号量)线程使用。
- 互斥:互斥是实现同步的一种手段,主要的互斥实现方式:
-
非阻塞同步
- 先进行操作,如果不存在冲突(即没有其他线程争用共享数据),则操作成功。
- 如果有其他线程争用共享数据,产生了冲突,使用其他的补偿措施。
- 常见的补偿措施:不断尝试,直到成功为止,比如循环的CAS(Compare and Swap 比较并交换)操作
-
无同步方案
同步只是保证共享数据争用时正确性的一种手段,如果不存在共享数据,自然无须任何同步措施。
- 栈关闭:多个线程访问同一个方法的局部变量时,不会出现线程安全问题。
- 可重入代码:可重入代码又叫纯代码(Pure Code),可在代码执行的任何时候中断他它,转去执行另外一段代码(包括递归调用它本身),控制权返回后,原来的程序不会出现任何错误。
- 线程本地存储:如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行----如果能保证,我们就可以把共享数据的可见范围限制在同一个线程内-----这样,无须同步也能保证线程之间不出现数据争用的问题。
6. 回答信号量、锁
Semaphore(信号量)控制访问特定资源的线程数量,它通过协调各个线程,以确保合理的使用公共资源。
应用场景: Semaphore(信号量)可以用来做流量分流,特别是对公共资源有限的场景,比如数据库连接。假设有这个需求,读取几万个文件的数据到数据库,由于文件读取是IO密集型任务,可以启动几十个线程并发读取,但是数据库连接数只有10个,这时就必须控制最多只有10个线程能够拿到数据库连接进行操作。这个时候,就可以使用Semaphore做流量控制。
信号量和锁的区别:Java.util.concurrent.Semaphore 使用方法和synchronized关键字类似,区别在于前者可以同时允许规定数量的线程执行,而后者对于不同的线程是互斥的,Semaphore 可以提供公平和不公平锁。
7. 跨设备如何传输文件
- 使用nginx搭建文件服务器
- 使用sftp协议进行传输
8. 设计模式
常见的设计模式:
- 工厂模式:将对象的创建和使用分离开,客户端只需要知道产品的接口,无需关心具体的实现;
- 单例模式:保证一个类只有一个实例,并提供全局访问点;
- 观察者模式:对象间的一种一对多的依赖关系,当一个对象状态发生变化时,所有依赖它的对象都会得到通知并自动更新;
- 装饰器模式:定义一系列算法,将每个算法封装起来并可互换使用,使得算法的变化不会影响到使用算法的客户端;
- 适配器模式:将一个类的接口转换成客户端所期望的一种接口,使得原本由于接口不兼容而不能一起工作的类可以一起工作;
- 建造者模式:将一个复杂对象的构建和其表示分离,使得同样的构建过程可以创建不同的表示。
9. 四种修饰符的可见范围

7、测试相关
如何测试电梯
- 功能:上升、下降、停止、开门、关门、梯内电话、灯光、指示灯、通风等;
- 性能:速度、反应时间、关门时间等;
- 压力:超载、尖锐物碰撞电梯壁等;
- 安全:停电、报警装置、轿箱停靠位置、有人扒门时的情况等;
- 可用性:按键高度、操作是否方便、舒适程度等;
- UI:美观程度、光滑程度、形状、质感等;
- 稳定性:长时间运行情况等;
- 兼容性:不同电压是否可工作、不同类型电话是否可安装等