一、简要介绍

人类反馈强化学习(RLHF)可以有效地将大型语言模型(LLM)与人类偏好对齐,但收集高质量的人类偏好标签是一个关键瓶颈。论文进行了一场RLHF与来自人工智能反馈的RL的比较(RLAIF) -一种由现成的LLM代替人类标记偏好的技术,论文发现它们能带来相似的改善。在总结任务中,人类评估者在70%的情况下更喜欢来自RLAIF和RLHF的生成,而不是基线监督微调模型。此外,当被要求对RLAIF和RLHF总结进行评分时,人们倾向于两者评分相等。这些结果表明,RLAIF可以产生人类水平的性能,为RLHF的可扩展性限制提供了一个潜在的解决方案。
二、研究背景
从人类反馈中强化学习(RLHF)是一种使语言模型适应人类偏好的有效技术,并被认为是现代会话语言模型如ChatGPT和Bard成功的关键驱动力之一。通过强化学习(RL)的训练,语言模型可以在复杂的序列级目标上进行优化,这些目标不易用传统的监督微调进行区分。
对高质量的人类标签的需求是扩大RLHF规模的一个障碍,一个很自然的问题是,人工生成的标签能否达到类似的结果。一些研究表明,大型语言模型(LLM)表现出与人类判断的高度一致——甚至在某些任务上优于人类。Bai等人(2022b)是第一个探索使用人工智能偏好来训练一种用于RL微调的反馈模型——一种被称为“来自人工智能反馈的强化学习”(RLAIF)的技术。虽然他们表明,将人类和人工智能偏好的混合结合“Constitutional AI”自我视觉技术优于监督的精细基线,但他们的工作并没有直接比较人类和人工智能反馈的效率,RLAIF能否成为RLHF合适的替代品仍是一个保留问题。
在这项工作中,论文直接比较了RLAIF和RLHF的总结任务。给定一个文本和两个候选响应,论文使用现成的LLM分配一个偏好标签。然后,论文训练了一个关于LLM偏好的反馈模型(RM)。最后,论文使用强化学习来微调一个策略模型,使用RM来提供反馈。
论文的结果表明,RLAIF达到了与RLHF相当的性能,以两种方式测量。首先,论文观察到,RLAIF和RLHF策略分别有71%和73%的时间比监督微调(SFT)基线更受到人类的青睐,但这两种获胜率在统计学上没有显著差异。第二,当被要求直接比较来自RLAIF和RLHF的生成时,人类对两种方案同样喜欢(即50%的win rate)。这些结果表明,RLAIF是RLHF可行的替代方案,不依赖人类注释,提供吸引人的缩放属性。
此外,论文还研究了最大限度地将人工智能产生的偏好与人类偏好对齐的技术。论文发现,用详细的提示驱动论文的LLM和使用思维链推理可以改善对齐。令人惊讶的是,论文观察到少量的情境学习和自洽性——在这个过程中,论文对多个思维链的基本原理进行抽样并对最终偏好进行平均——都没有提高准确性,甚至降低准确性。最后,论文进行了缩放实验,以量化LLM标签器的大小和在训练中使用的偏好示例的数量与与人类偏好对齐之间的权衡。
论文的主要贡献如下:
1.论文证明了RLAIF在总结任务上取得了与RLHF相当的性能
2.论文比较了各种生成人工智能标签的技术,并为RLAIF从业者确定最佳设置

三、准备工作(Preliminaries)
论文首先回顾了现有工作引入的RLHF pipeline,包括3个阶段:监督微调、反馈模型训练和基于强化学习的微调。
监督微调(Supervised Fine-tuning)

反馈建模(Reward Modeling)


其中σ是sigmoid函数。
强化学习(Reinforcement Learning)

![]()
四、RLAIF方法(RLAIF Methodology)
在本节中,论文将描述用于使用LLM生成首选项标签的技术、论文如何执行RL,以及评估度量。
4.1 LLM的首选项标签(Preference Labeling with LLMs)
论文用一个“现成的”LLM对候选对象之间的反馈偏好,这个LLM是一个预先训练或指令调整的模型,但没有针对特定的下游任务进行微调。给定一篇文本和两个候选摘要,LLM被要求评价哪个摘要更好。LLM的输入结构如下(示例见表1):
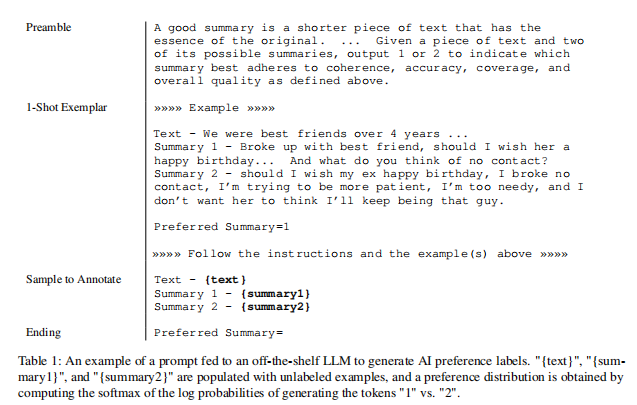
1.Preamble-介绍和描述手头任务的说明
2.Few-shot exemplars(可选)一个文本的例子,一对摘要,一个思维链推理(如果适用),和一个偏好判断
3.Sample to annotate-被标记的一个文本和一对摘要
4.Ending-用来提示LLM的结束字符串(例如:“Preferred Summary=”)
在给出LLM的输入后,论文得到生成令牌“1”和“2”的对数概率,并计算softmax来推导出偏好分布。从LLM中获得偏好标签有很多选择,比如从模型中解码自由响应并启发式地提取偏好(例如output = "The first summary is better"),或者将偏好分布表示为一个热表示。然而,论文没有尝试这些替代方案,因为论文的方法已经产生了很高的准确性。
寻址位置偏差(Addressing Position Bias)
候选向LLM展示的顺序可能会影响它更喜欢的候选。论文发现了存在这种位置偏差的证据,特别是对于较小尺寸的LLM标签器(见附录a)。
为了减少偏好标记中的位置偏差,论文对每一对候选者进行两个推断,其中候选者呈现给LLM的顺序是相反的。然后将这两种推断的结果取平均值,得到最终的偏好分布。
思维链推理(Chain-of-thought Reasoning)
论文实验从人工智能标签用户中引出思维链(COT)推理,以改善与人类偏好的一致性。论文将标准提示符(即“Preferred Summary=”)的结尾替换为“ Consider the coherence, accuracy, coverage, and overall quality of each summary and explain which one is better. Rationale:”然后解码来自LLM的响应。最后,论文将原始提示符、响应和原始结束字符串“首选摘要=”连接在一起,并按照第前文中的评分程序来获得偏好分布。插图如图3所示。

在zero-shot提示中,LLM没有给出推理应该是什么样的例子,而在few-shot提示中,论文提供了COT推理的例子。有关例子见表7和表8。


自洽性(Self-Consistency)
对于思维链提示,论文还进行了自洽性的实验——这是一种通过抽样多个推理路径,并聚合每个路径末端产生的最终答案来改进思维链推理的技术。在非零解码下对多个思想链原理进行采样,然后按照前文中的方法得到每个原理的LLM偏好分布。然后取结果的平均值,得到最终的偏好分布。

4.2从人工智能反馈中获得的强化学习(Reinforcement Learning from AI Feedback)
在偏好被LLM标记出来之后,一个反馈模型(RM)就会被训练来预测偏好。由于论文的方法产生了软标签(例如,preferencei= [0.6,0.4]),论文将交叉熵损失应用于RM产生的反馈分数的softmax,而不是前文中提到的损失。softmax将RM中的无界分数转换为一个概率分布。
在人工智能标签的数据集上训练一个RM可以看作是模型蒸馏的一种形式,特别是因为论文的人工智能标签器通常比论文的RM更大、更强大。另一种方法是绕过RM,在RL中直接使用AI反馈作为反馈信号,尽管这种方法计算上更昂贵,因为AI标签比RM大。
使用经过训练的RM,论文使用适应于语言建模领域的Advantage Actor Critic(A2C)算法进行强化学习(详见附录B)。虽然最近的许多工作使用近端策略优化(PPO)—一种类似的方法,增加了一些技术,使训练更加保守和稳定(例如,裁剪目标函数),论文使用A2C,因为它更简单,但仍然有效的解决论文的问题。
4.3 评估
论文用三个指标来评估论文的结果-人工智能标签器对齐(Labeler Alignment),成对准确性(Pairwise Accuracy),和获胜率(win rate)。
人工智能标签对齐测量人工智能标记的偏好与人类偏好的准确性。对于一个单一的例子,它是通过将一个软ai标记的偏好转换为一个二进制表示(例如,preferencei= [0.6,0.4]→[1,0])来计算的,如果标签与目标人类偏好一致,则分配一个1,否则为0。它可以这样表示为:
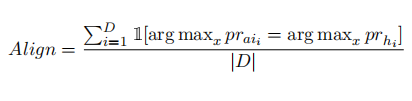

成对准确性衡量的是一个训练过的反馈模型对一组人类偏好的准确性。给定一个共享的上下文和一对候选响应,根据人类标签,如果RM对首选候选对象的得分高于非首选候选对象的得分,则成对准确性为1。否则,该值为0。这个量在多个例子上取平均值,以测量RM的总精度。
获胜率Win Rate通过衡量一个策略被人类偏好高于另一个策略的频率来评估两个策略的端到端的质量。给定一个输入和两个生成,人类注释者选择偏好哪一个。策略A优于策略B的百分比称为“Win Rate of A vs. B".
五、实验细节(Experimental Details)
5.1数据集
根据Stiennon等人(2020年)的工作,论文使用了由OpenAI管理的过滤后的Reddit TL;DR数据集。TL;DR包含了来自Reddit的300万篇关于不同主题的文章(也被称为“subreddits”),以及原作者所写的文章的摘要。此外,OpenAI还会对数据进行过滤,以确保高质量,其中包括使用一般人群可以理解的子红数据白名单。此外,只使用摘要中包含24到48个令牌的帖子。过滤后的数据集包含123,169篇文章,其中5%作为验证集保存。关于该数据集的更多细节可以在原始论文中找到。
此外,OpenAI从过滤后的TL;DR数据集中整理了一个人类偏好数据集。对于一个给定的帖子,从不同的策略中生成两个候选人摘要,并要求标签人员对他们更喜欢的摘要进行评级。总数据集包括92k的成对比较。
5.2 LLM标签(LLM Labeling)
为了评估人工智能标记技术的有效性(例如,驱动、自洽性),论文从TL;DR偏好数据集中选择了一些例子,其中人类注释者更喜欢一个摘要而不是另一个摘要。论文在数据集训练分割的随机15%子集上评估人工智能标签对齐,以实现更快的实验迭代,产生2851个用于评估的例子。对于反馈模型训练,TL;DR偏好数据集的完整训练分割由LLM标记,并用于训练——而不管置信度分数如何。
论文使用PaLM 2作为标记偏好的LLM。除非另有说明,论文使用最大上下文长度为4096个标记的大模型大小。对于思想链的生成,论文设置了最大解码长度为512个标记,样本温度为T=0(即贪婪解码)。对于自洽性实验,论文使用温度T = 1和top-K采样,其中K=为40。
5.3模型训练(Model Training)
论文在OpenAI过滤后的TL;DR数据集上训练一个SFT模型,使用PaLM 2超小值(XS)作为论文的初始检查点。
然后,论文从SFT模型中初始化论文的RMs,并在OpenAI的TL;DR人类偏好数据集上训练它们。对于表1和前文的结果,论文使用PaLM 2 L生成ai标记的偏好,使用“OpenAI+COT0-shot”提示符,没有自洽性,然后在完整的偏好数据集上训练RM。
对于强化学习,论文使用附录b中描述的A2C来训练策略。策略模型和价值模型都是从SFT模型中初始化的。论文使用过滤后的Reddit TL;DR数据集作为初始状态来推出论文的策略。
有关更多的训练细节,请参见附录C。
5.4人工评估
论文从人类中收集了1200个排名来评估RLHF和RLAIF的策略。对于每个评级任务,评估者都会看到一个帖子和4个总结,它们来自不同的策略(来自RLAIF、RLHF、SFT和人类参考),并被要求按照无联系的质量对它们进行排序。文章来自于TL的保留集;DR监督微调数据集,这没有在任何其他评估中使用。一旦收集到这些排名,就有可能计算出任何两种策略的获胜率。
六、结果
6.1 RLAIF vs. RLHF
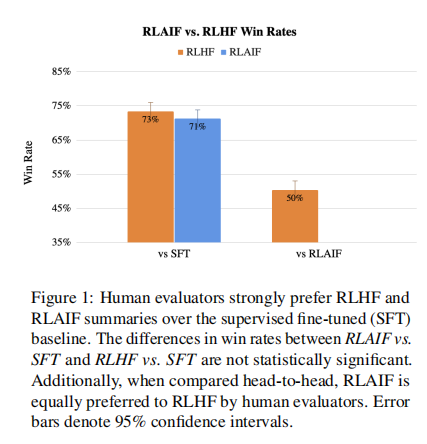
论文的结果表明,RLAIF具有与RLHF类似的性能(见表1)。在71%的情况下,人类评估者首选RLAIF。相比之下,RLHF有73%的时间比SFT更可取。虽然RLHF略优于RLAIF,但差异没有统计学意义4。论文还直接比较了RLAIF和RLAIF的胜率。RLHF,发现他们同样受欢迎——即获胜率是50%。为了更好地理解RLAIF与RLHF之间的比较情况,论文定性地比较了第6节中由两种策略生成的摘要。
论文还比较了RLAIF和RLHF摘要与人类编写的参考摘要。79%的情况下RLAIF摘要优于参考摘要,80%的情况下RLHF优于参考摘要。RLAIF和RLHF之间的胜率与参考摘要之间的差异也没有统计学意义。
在论文的研究结果中,一个混杂的因素是,论文的RLAIF和RLHF策略往往比SFT策略产生更长的总结,这可以解释一些质量改进。与Stiennon等人(2020年)类似,论文进行了事后分析,结果表明,尽管RLAIF和RLHF策略都受益于产生较长的总结,但在控制了长度后,两者的表现仍优于SFT策略。
这些结果表明,RLAIF是一种不依赖于人类注释的RLHF的可行替代方案。为了理解这些发现如何很好地推广到其他自然语言处理任务,需要在更广泛的任务上进行实验,论文将其留给未来的工作。
6.2 驱动技术(Prompting Techniques)
论文实验了三种类型的驱动技术——序言特异性、思维链推理和few-shot的上下文学习——并在表2中报告了结果。

总的来说,论文观察到最优配置使用了详细的前导、思维链推理,而没有上下文学习(“OpenAI+COT 0-shot”)。这个组合实现了78.0%的AI标签对齐,比使用论文最基本的提示(“Base 0-shot”)高出1.9%。作为比较点,Stiennon等人(2020)估计,在人类偏好数据集上,人类注释者之间的一致性为73-77%,这表明论文的LLM表现得相当好。论文对所有其他实验使用“OpenAI+COT 0-shot”提示。
6.3自洽性(Self-Consistency)

论文使用4个和16个样本进行自洽性实验,解码温度为1,如前文中描述的那样,两种设置都显示自洽性下降大于5%。手动检查链状思维原理并没有揭示为什么自洽性可能导致较低的准确性的任何共同模式(见表10中的例子)。
关于精度下降的一个假设是,与贪婪解码相比,使用温度为1会导致模型产生更低质量的思维链基本原理,最终导致整体精度下降。使用温度在0到1之间的温度可能会产生更好的结果。

6.4 LLM标签的大小(Size of LLM Labeler)

大尺寸的模型不能广泛使用,运行起来可能缓慢和昂贵。论文实验了不同模型大小的标记偏好,并观察到对齐和大小之间的强关系。从PaLM 2 Large (L)到PaLM 2 Small (S)时,排列下降-4.2%,下降到PaLM 2 XS时,又下降-11.1%。这一趋势与在其他工作中观察到的标度律相一致(Kaplan等人,2020年)。导致性能下降的一个因素可能是在较小的LLM中,位置偏差的增加(见附录A)。
在这一趋势的最后,这些结果也表明,扩大人工智能标签器的大小可能会产生更高质量的偏好标签。由于AI标签器只用于生成一次偏好示例,而在RL训练中不会被查询,因此使用更大的AI标签器并不一定非常昂贵。此外,前文指出,少量的例子可能足以训练一个强大的RM(例如,在O(1k)的顺序上),进一步降低了使用一个更大的标记器模型的成本。
6.5 偏好示例数(Number of Preference Examples)
为了理解RM的准确性如何随着训练示例的数量而变化,论文对不同数量的人工智能标记偏好示例RM进行训练,并对人类偏好的剔除集合评估成对的准确性。论文通过对全偏好数据集进行随机子抽样,获得了不同数量的训练示例。结果如图5所示。

论文观察到,经过几千个例子的训练后,AI偏好RM的表现很快趋于稳定。此RM在仅进行128个例子训练时达到60%的精度,然后在只有5000个例子(大约1/20个完整数据集)训练时达到接近于对完整数据集训练的精度。
论文还在一个训练了人类偏好的RM上进行了一组平行的实验。论文发现人类和人工智能的RM遵循相似的比例曲线。一个不同之处在于,随着训练例子数量的增加,人类的偏好RM似乎在不断提高,尽管更多的训练例子只会给准确性带来很小的提高。这一趋势表明,根据人工智能偏好训练的rm可能不会像根据人类偏好训练的rm那样受益那么多。
考虑到扩大人工智能偏好示例数量的有限改进,更多的资源可能会更好地花在标记具有更大的模型尺寸上,而不是标记更多的偏好示例。
七、定性分析
为了更好地理解RLAIF与RLHF的比较情况,论文手动检查了由两种策略生成的摘要。在许多情况下,这两个策略产生了类似的总结,这反映在它们相似的获胜率上。论文确定了两种它们完全不同的模式。
论文观察到的一种模式是,RLAIF似乎比RLHF更不容易产生虚构。RLHF中的虚构通常是可信的,但与原文不一致。例如,在表11的示例#1中,RLHF摘要声明作者是20岁,但原始文本中没有提到或暗示这一点。
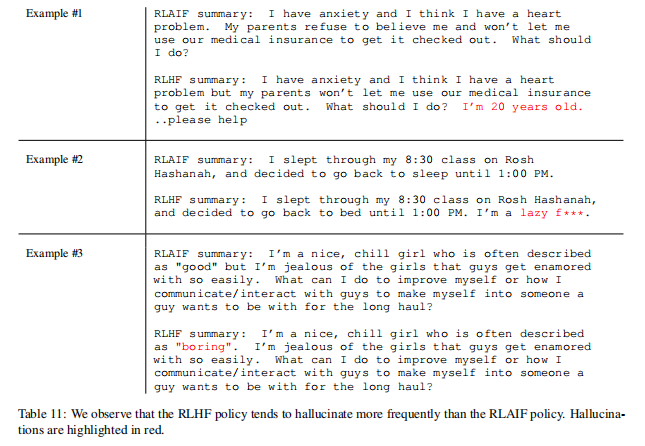
论文观察到的另一种模式是,RLAIF有时在产生连贯或符合语法总结上不如RLHF。例如,在表12的示例#1中,RLAIF摘要生成不符合语法语句。
总的来说,虽然论文观察到每项策略的某些趋势,但两者都产生了相对相似的高质量摘要。

八、结论

在这项工作中,论文展示了RLAIF可以在不依赖人类注释者的情况下产生类似于RLHF的改进。论文的实验表明,RLAIF在SFT基线上大大改善,改善的幅度与RLHF相当。在头对头的比较中,人类对RLAIF和RLHF的比例相似。论文还研究了各种人工智能标记技术,并进行了缩放研究,以了解生成对齐偏好的最佳设置。
虽然这项工作强调了RLAIF的潜力,但论文注意到这些发现的一些局限性。首先,这项工作只探索了总结的任务,留下了一个关于对其他任务的泛化性的开放问题。其次,论文没有估计LLM推断在金钱成本方面是否比人工标记更有利。此外,仍有许多有趣的开放问题,如RLHF结合RLAIF可以超越单一方法,如何使用LLM直接分配反馈执行,改进人工智能标签调整是否意味着改善最终策略,以及是否使用LLM标签相同大小的策略模型可以进一步提高策略(即模型是否可以“自我完善”)。论文把这些问题留给以后的工作吧。
作者希望本文能激发人们在RLAIF领域的进一步研究。