
作者 | JiekeXu
来源 |公众号 JiekeXu DBA之路(ID: JiekeXu_IT)
如需转载请联系授权 | (个人微信 ID:JiekeXu_DBA)
大家好,我是 JiekeXu,很高兴又和大家见面了,今天和大家一起来看看 一文搞懂 Oracle 统计信息,欢迎点击上方蓝字“JiekeXu DBA之路”关注我的公众号,标星或置顶,更多干货第一时间到达!
目 录
前 言
1、为什么需要统计信息
2、 手动收集统计信息
2.1 常用采集命令
2.2 METHOD_OPT 详解
3、锁定统计信息
4、 查看直方图信息
4.1 直方图
4.2 查看表的统计信息
5、收集数据字典统计信息
5.1 查询以查找最近的统计信息收集
5.2 收集几个聚簇索引的统计信息
5.3 不需要收集统计信息的情况
参考链接
前 言
以下四个地址是我个人博客地址,一般情况下文章首发于墨天轮或者微信公众号,然后同步至 CSDN 和 腾讯云,其他网站均属于盗版链接,感兴趣的朋友可关注我的公众号或者墨天轮地址,第一时间获取最新文章信息。
————————————————————————————
微信公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————下图是近期汇总网上资料整理的 Oracle 统计信息脑图笔记,图片可能不太清晰,感兴趣的可在公众号后台回复关键字【Oracle统计信息】下载查看。

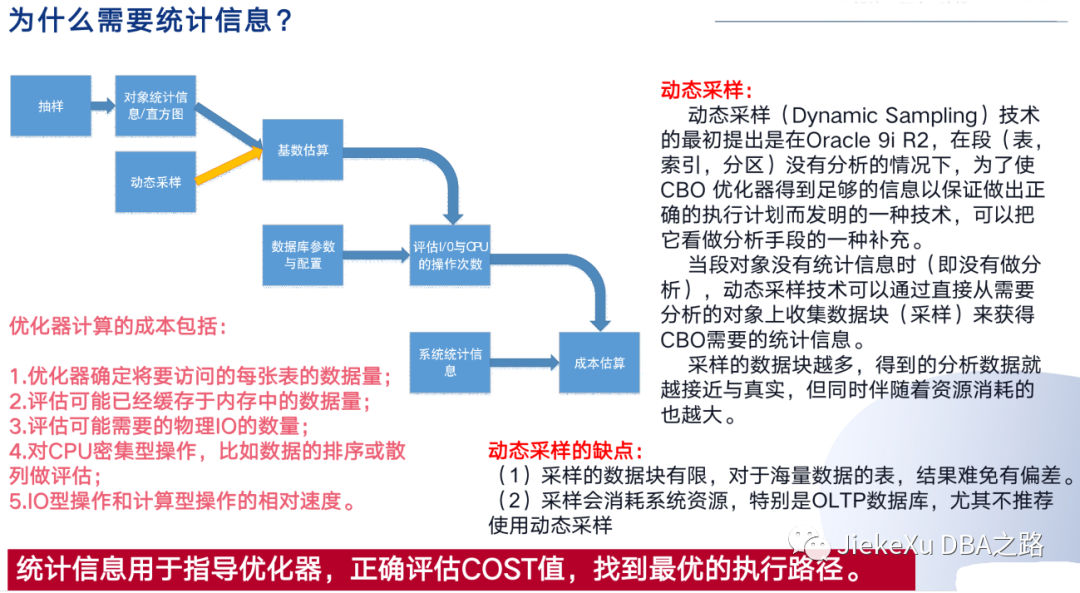
1、为什么需要统计信息
统计信息对于优化器生成一个好的执行计划来说是必要的。
• 优化器为了产生最佳的执行计划,依赖于对象统计信息
• 保持最新的统计信息非常重要
• 当统计信息已经过时,需要刷新
对象统计信息,是优化器引擎生成执行计划的必要输入,过时或错误统计信息很可能导致一个错误的执行计划。
统计信息包含哪些信息?


2、 手动收集统计信息
https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/DBMS_STATS.html#GUID-CA6A56B9-0540-45E9-B1D7-D78769B7714C
调整默认采集参数
可以使用 SET 命令进行调整:
DBMS_STATS.SET_GLOBAL_PREFS/SET_TABLE_PREFS/SET_SCHEMA_PREFS/SET_DATABASE_PREFS
设置完成后,下次采集生效。

2.1 常用采集命令
使用 dbms_stats 包
• gather_table_stats 收集单表统计信息
• gather_schema_stats 收集用户统计信息
例子:exec dbms_stat.gather_table_stats(user, ‘TABLE_NAME’, degree=>16);
采样比例通过参数 ESTIMATE_PRECENT 来控制,模式设置是 AUTO_SAMPLE_SIZE。建议收集统计信息使用默认 AUTO_SAMPLE_SIZE,对于 Oracle 12c 如果要生成 HYBIRD 或 TOP Frequency,必须使用 AUTO_SAMPLE_SIZE 进行采样。
2.2 METHOD_OPT 详解
Method_opt 默认是 FOR ALL COLUMNS SIZE AUTO
FOR ALL [INDEXED | HIDDEN] COLUMNS [size_clause]
FOR COLUMNS [column_clause] [size_clause]
size_clause 定义为 size_clause := SIZE {integer | REPEAT | AUTO | SKEWONLY}
column_clause 定义为column_clause := column_name | extension name | extension
• - integer:直方图桶的数量。必须在 [1,2048] 范围内。
• - REPEAT:仅在已有直方图的列上收集直方图
• - AUTO:Oracle 根据数据分布和列的工作负载确定要在其上收集直方图的列。
• - SKEWONLY:Oracle 根据列的数据分布确定要在其上收集直方图的列。
• - column_name:列的名称
• - extension : 可以是 (,[, …]) 格式的列组或表达式column_name Colume_name
默认值为 FOR ALL COLUMNS SIZE AUTO。可以使用 SET_DATABASE_PREFS 过程、SET_GLOBAL_PREFS 过程 SET_SCHEMA_PREFS 过程 和SET_TABLE_PREFS 过程更改默认值。
• 列上面是否创建直方图由列的使用情况决定(COL_USAGE$)
• 全局禁用直方图
dbms_stats.set_global_prefs( method_opt => 'FOR ALL COLUMNS SIZE 1’ );• 给指定的某些列创建直方图method_opt => 'FOR ALL COLUMNS SIZE 1, FOR COLUMNS SIZE 254 CUST_ID PROD_ID');• 给指定的某些列禁用直方图dbms_stats.set_table_prefs('SH','SALES','METHOD_OPT','FOR ALL COLUMNS SIZE AUTO,FOR COLUMNS SIZE 1 PROD_ID');• 更新直方图统计信息
METHOD_OPT=>’FOR ALL COLUMNS REPEAT’
• 备注: 不会修改桶的数量使用非默认的 METHOD_OPT…
不要使用 ‘FOR ALL INDEX COLUMNS SIZE 254’
• 收集统计信息时间变长
• 统计信息占用空间更多
• 不收集非索引列直方图不要使用 ‘FOR ALL COLUMNS SIZE 254’
• 收集统计信息时间变长
• 统计信息占用空间更多
两种类型的扩展统计信息
扩展统计信息 – Column Group
Column groups 统计
• 当 SQL 语句中单个表的多个列被 where 条件同时引用时候,Column groups 统计非常有用
列之间的相关性会导致错误的估计 Cardinality

使用 column group 统计提升 Cardinality 估算的准确度.
eg:
dbms_stats.create_extend_stats(NULL, ‘TAB1’,‘(COl1,COL2)’);
dbms.gather_table_stats(NULL, ‘TAB1’);
dbms_stats.create_extend_stats(NULL, ‘CALENDAR’,‘(MONTH_NAME,STAR_SIGN)’);
dbms.gather_tabe_stats(NULL, ‘CALENDAR’);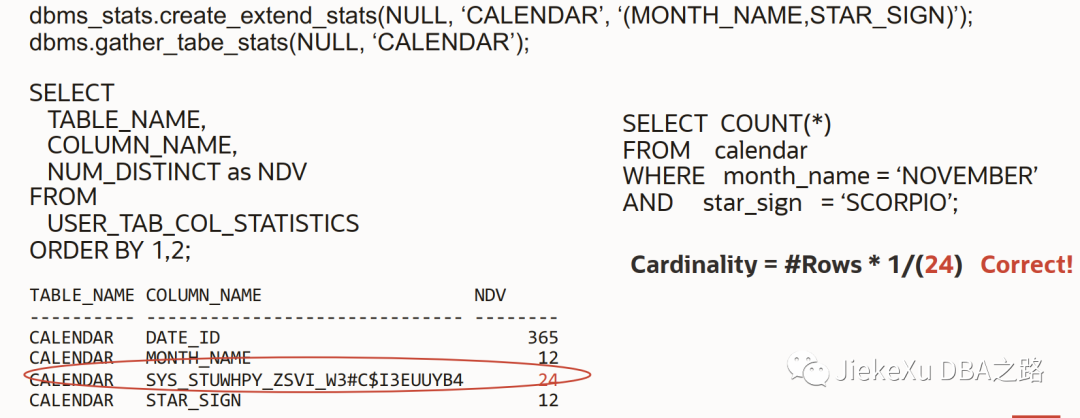
Expression 统计信息
• Expression statistics 当表列在 where 条件中以复杂表达式出现时候,表达式统计信息非常有用
其他 dbms_stats 详细介绍:
GATHER_DATABASE_STATS
此过程收集数据库中所有对象的统计信息。要运行此过程,您需要 SYSDBA 角色,或者同时具有 ANALYZE ANY DICTIONARY 和 ANALYZE ANY 系统权限。
DBMS_STATS.GATHER_DATABASE_STATS (
estimate_percent NUMBER DEFAULT to_estimate_percent_type
(get_param('ESTIMATE_PERCENT')),
block_sample BOOLEAN DEFAULT FALSE,
method_opt VARCHAR2 DEFAULT get_param('METHOD_OPT'),
degree NUMBER DEFAULT to_degree_type(get_param('DEGREE')),
granularity VARCHAR2 DEFAULT GET_PARAM('GRANULARITY'),
cascade BOOLEAN DEFAULT to_cascade_type(get_param('CASCADE')),
stattab VARCHAR2 DEFAULT NULL,
statid VARCHAR2 DEFAULT NULL,
options VARCHAR2 DEFAULT 'GATHER',
statown VARCHAR2 DEFAULT NULL,
gather_sys BOOLEAN DEFAULT TRUE,
no_invalidate BOOLEAN DEFAULT to_no_invalidate_type (
get_param('NO_INVALIDATE')),
obj_filter_list ObjectTab DEFAULT NULL);GATHER_DICTIONARY_STATS
这个过程收集字典模式 SYS、SYSTEM 和 RDBMS 组件模式的统计信息。
要运行此过程,您需要 SYSDBA 角色,或者同时具有 ANALYZE ANY DICTIONARY 和 ANALYZE ANY 系统权限
GATHER_FIXED_OBJECTS_STATS
此过程收集所有固定对象(动态性能表)的统计信息。要运行此过程,您必须具有 SYSDBA 或 ANALYZE ANY DICTIONARY 系统权限才能执行此过程。
GATHER_INDEX_STATS
这个过程收集索引统计信息。它试图并行化尽可能多的工作。
限制在各个参数中描述。该操作不会与某些类型的索引并行,包括集群索引、域索引和位图连接索引。granularity 和 no_invalidate 参数与这些类型的索引无关。
Granularity:要收集的统计信息的粒度(仅在表已分区时相关)。
no_invalidate:如果设置为 TRUE,则不会使依赖游标无效。如果设置为 FALSE,该过程将立即使依赖游标失效。使用 DBMS_STATS.AUTO_INVALIDATE。让 Oracle 决定何时使依赖游标失效,这是默认设置。
GATHER_PROCESSING_RATE
此过程开始收集处理速率的工作,处理速率在以分钟为单位定义的间隔后结束。
GATHER_SCHEMA_STATS
这个过程收集 schema 中所有对象的统计信息。
要调用此过程,您必须是表的所有者,或者需要 ANALYZE ANY 特权。对于 SYS 拥有的对象,您必须是表的所有者,或者您需要 ANALYZE ANY DICTIONARY 特权或 SYSDBA 特权。
下面的示例指定如果表 SH.SALES 和 SH.cost 过时,将收集它们的统计信息。
DECLARE
filter_lst DBMS_STATS.OBJECTTAB := DBMS_STATS.OBJECTTAB();
BEGIN
filter_lst.extend(2);
filter_lst(1).ownname := 'SH';
filter_lst(1).objname := 'SALES';
filter_lst(2).ownname := 'SH';
filter_lst(2).objname := 'COSTS';
DBMS_STATS.GATHER_SCHEMA_STATS(ownname=>'SH',obj_filter_list=>filter_lst);
END;GATHER_SYSTEM_STATS
此过程收集系统统计信息。要运行此过程,您必须拥有 GATHER_SYSTEM_STATISTICS 角色。
假设您希望在白天执行数据库应用程序处理 OLTP 事务,在晚上运行报表。
如果需要收集系统白天的统计信息,则需要收集 720 分钟的统计信息。将统计信息存储在 MYSTATS 表中。
BEGIN
DBMS_STATS.GATHER_SYSTEM_STATS (
interval => 720,
stattab => 'mystats',
statid => 'OLTP');
END;如果需要收集系统夜间统计信息,则需要收集 720 分钟的统计信息。将统计信息存储在 MYSTATS 表中。
BEGIN
DBMS_STATS.GATHER_SYSTEM_STATS (
interval => 720,
stattab => 'mystats',
statid => 'OLAP');
END;GATHER_TABLE_STATS
此过程收集表、列和索引统计信息。它试图并行化尽可能多的工作,但是有一些限制,这些限制在单个参数中描述。
要调用此过程,您必须是表的所有者,或者需要 ANALYZE ANY 特权。对于 SYS 拥有的对象,您要么需要是表的所有者,要么需要 ANALYZE ANY DICTIONARY 特权或 SYSDBA 特权。除集群索引、域索引和连接索引外,索引统计信息收集可以并行化。
DBMS_STATS.GATHER_TABLE_STATS (
ownname VARCHAR2,
tabname VARCHAR2,
partname VARCHAR2 DEFAULT NULL,
estimate_percent NUMBER DEFAULT to_estimate_percent_type
(get_param('ESTIMATE_PERCENT')),
block_sample BOOLEAN DEFAULT FALSE,
method_opt VARCHAR2 DEFAULT get_param('METHOD_OPT'),
degree NUMBER DEFAULT to_degree_type(get_param('DEGREE')),
granularity VARCHAR2 DEFAULT GET_PARAM('GRANULARITY'),
cascade BOOLEAN DEFAULT to_cascade_type(get_param('CASCADE')),
stattab VARCHAR2 DEFAULT NULL,
statid VARCHAR2 DEFAULT NULL,
statown VARCHAR2 DEFAULT NULL,
no_invalidate BOOLEAN DEFAULT to_no_invalidate_type (
get_param('NO_INVALIDATE')),
stattype VARCHAR2 DEFAULT 'DATA',
force BOOLEAN DEFAULT FALSE,
context DBMS_STATS.CCONTEXT DEFAULT NULL, -- non operative
options VARCHAR2 DEFAULT get_param('OPTIONS'));
| 参数 | 描述 |
|---|---|
| ownname | schema 名称 |
| tabname | 表的名称。 |
| partname | 分区的名称。 |
| estimate_percent | 确定百分比 要采样的行。有效范围介于 0.000001 和 100。默认使用 DBMS_STATS.AUTO_SAMPLE_SIZE 使数据库能够确定最佳统计数据的适当样本大小。您可以使用“SET_DATABASE_PREFS过程”、“SET_GLOBAL_PREFS过程”、“SET_SCHEMA_PREFS过程”和“SET_TABLE_PREFS过程”更改默认值。 |
| block_sample | 确定数据库是否使用随机块抽样(TRUE) 或随机行抽样 (FALSE).默认值为 FALSE. 随机块采样效率更高, 但如果数据不是随机分布在磁盘上的,那么样本值可能会有些 相关。此参数仅在估计统计数据时相关。 |
| method_opt | METHOD_OPT- 在全局、架构、数据库或字典级别设置首选项时,只允许语法。除此之外,method_opt 接受以下任一选项,或两者组合:‘FOR ALL’ |
| degree | 确定程度 用于收集统计信息的并行性。默认值为 NULL,可以使用 DEGREE=>NULL, DEGREE=>n, or DEGREE=>DBMS_STATS.DEFAULT_DEGREE 设置并行度。 |
| granularity | 要收集的统计信息的粒度(仅是分区表时才相关)。‘ALL’- 收集所有(子分区、分区和全局)统计信息’APPROX_GLOBAL AND PARTITION’- 类似于但在这种情况下,全局统计信息是从分区级别统计信息聚合而来的。此选项将聚合除列的非重复值数和索引的不同键数之外的所有统计信息。还会聚合表级别列的现有直方图。聚合将仅使用具有统计信息的分区,因此要获得准确的全局统计信息,用户应确保具有所有分区的统计信息。如果无法执行聚合(例如,如果缺少其中一个分区的统计信息),则会收集全局统计信息。'GLOBAL AND PARTITION’partname NULL ‘AUTO’- 根据分区类型确定粒度。这是默认值。‘DEFAULT’- 收集全局和分区级别的统计信息。此选项已过时,虽然目前受支持,但仅出于旧版原因将其包含在文档中。对于此功能,应使用“GLOBAL AND PARTITION”。请注意,默认值现在为 ‘AUTO’。‘GLOBAL’- 收集全球统计数据,‘GLOBAL AND PARTITION’ - 收集全局和分区级别的统计信息。即使它是复合分区对象,也不会收集子分区级别统计信息。‘PARTITION’- 收集分区级统计信息。‘SUBPARTITION’- 收集子分区级别的统计信息。 |
| cascade | 确定是否收集索引统计信息作为收集表统计信息的一部分。指定此选项相当于在表的每个索引上运行GATHER_INDEX_STATS过程。使用常量DBMS_STATS.AUTO_CASCADE使数据库能够确定是否需要收集索引统计信息。这是默认值。您可以使用SET_DATABASE_PREFS、SET_GLOBAL_PREFS、SET_SCHEMA_PREFS和SET_TABLE_PREFS过程更改默认值。 |
| no_invalidate | 控制在收集统计信息时从属游标的无效。该参数有以下值:• TRUE:从属游标不会失效。• FALSE:从属游标标记为立即失效。• AUTO:这是默认值。滚动失效用于在一段时间内使所有依赖的游标失效。对数据库的性能影响会降低,特别是在大量游标失效的情况下。如果设置为TRUE,则数据库不会使依赖的游标失效。如果设置为FALSE,则该过程立即使相关游标无效。 |
| force | 即使它被锁定,也会收集表的统计信息, |
| options | 确定在GATHER_TABLE_STATS过程中使用的options参数。首选项采用以下值:GATHER— 收集表中所有对象的统计信息。这是默认值。GATHER AUTO— Oracle建议在批量加载表并获取在线统计信息后,使用GATHER AUTO来收集必要的统计信息,例如直方图。这只适用于不使用INCREMENTAL统计信息的表。对于使用增量统计的分区表,如果表被标记为陈旧或没有统计信息,那么使用GATHER AUTO的GATHER_TABLE_STATS将收集表的统计信息。此外,将收集标记为陈旧或没有统计信息的分区和子分区的统计信息。对于不使用增量统计的表,使用带有GATHE的GATHER_TABLE_STATS |
3、锁定统计信息
(1).锁定统计信息,禁止搜集表的统计信息;
(2).删除统计信息后锁定,使之每次都用动态采样:
(3).改变统计信息对表数据的估算。
Oracle锁定统计信息:
(1)锁定统计信息
exec dbms_stats.lock_table_stats('ownname',tabname'cascade=>TRUE);(2).验证统计信息锁定情况select table_name,stattype_locked from dba_tab_statistics where stattype_locked is not null;(3).解锁统计信息exec dbms_stats.unlock_table_stats('ownname','tabname');(4).删除统计信息
exec dbms_stats.delete_table_stats('ownname',tabname'cascade=>TRUE);(5)设置统计信息exec dbms_stats.set_table_stats('ownname',tabname'numrows=>1000):Oracle锁定统计信息存在的问题统计信息处于锁定状态,新建索引不会自动收集统计信息,存在性能风险,建议新建索引前解锁,创建完成后锁定。
4、 查看直方图信息
4.1 直方图
• 用来更进一步描述某列的数据分布情况
• 基于SQL使用情况来创建
sys.col_usage$保存了谓词条件列和join条件列的使用情况
当采集统计信息时候,这些列就是创建直方图的候选列
• 直方图类型
• Frequency ---- 列的NDV<=254
• Top-frequency----列的NDV>254 但是高频的254个列值占总行数比例大于100-100/n
• Hybrid Histogram —列的NDV>254 但是高频的254个列值占总行数比例小于100-100/n
• Height-balanced—如果使用了AUTO_SAMPLE_SIZE将不再创建这个类型的直方图被 Hybrid 直方图替换
列的NDV > 254
如果使用 estimate_percent 依然会创建
升级后保留
select a.column_name,
b.num_rows,
a.num_nulls,
a.num_distinct Cardinality,
round(a.num_distinct / b.num_rows * 100, 2) selectivity,
a.histogram,
a.num_buckets
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.table_name = b.table_name
and a.owner = 'PROD'
and a.table_name = 'T_FILE';4.2 查看表的统计信息
统计信息收集如下数据:
(1)表自身的分析: 包括表中的行数,数据块数,行长等信息。
(2)列的分析:包括列值的重复数,列上的空值,数据在列上的分布情况。
(3)索引的分析: 包括索引叶块的数量,索引的深度,索引的聚合因子等。这些统计信息存放在数据字典里,如:
DBA_TABLES
DBA_OBJECT_TABLES
DBA_TAB_STATISTICS
DBA_TAB_COL_STATISTICS
DBA_TAB_HISTOGRAMS
DBA_INDEXES
DBA_IND_STATISTICS
DBA_CLUSTERS
DBA_TAB_PARTITIONS
DBA_TAB_SUBPARTITIONS
DBA_IND_PARTITIONS
DBA_IND_SUBPARTITIONS
DBA_PART_COL_STATISTICS
DBA_PART_HISTOGRAMS
DBA_SUBPART_COL_STATISTICS
DBA_SUBPART_HISTOGRAMS例如:查看普通表 T_STATS 统计信息。
select owner, table_name , object_type, stale_stats, last_analyzed
from dba_tab_statistics
where owner = 'SCOTT'
and table_name = 'T_STATS';
--查看表的 DML 变化量
select table_owner, table_name, inserts, updates, deletes, timestamp
from all_tab_modifications
where table_owner = 'SCOTT'
and table_name = 'T_STATS';查询 DBA_TAB_STATISTICS 视图,STALE_STATS 列代表统计信息是否陈旧,值为 YES 表示统计信息是陈旧的,需要及时收集,值为 NO 表示统计信息是正常的,不需要重新收集。Oracle 对于表的 DML 变化,记录在视图 DBA_TAB_MODIFICATIONS 中,当 DML 累计达到表行数的 10% 时,就认为统计信息是陈旧的,需要及时收集。所以,Oracle 的定时任务也是对 STALE_STATS 进行筛选、统计和收集。
5、收集数据字典统计信息
5.1 查询以查找最近的统计信息收集
set linesize 200
select max(end_time) LATEST, operation from DBA_OPTSTAT_OPERATIONS
where operation in ('gather_dictionary_stats', 'gather_fixed_objects_stats')
group by operation;
--命令如下
EXECUTE DBMS_STATS.GATHER_DICTIONARY_STATS;
EXECUTE DBMS_STATS.GATHER_SCHEMA_STATS('SYS');
EXECUTE DBMS_STATS.GATHER_SCHEMA_STATS('SYSTEM');
EXECUTE DBMS_STATS.GATHER_FIXED_OBJECTS_STATS;5.2 收集几个聚簇索引的统计信息
--Bug 25286819 : CLUSTER INDEX STATS NOT GATHERED WHEN STALE TABLE OR DICTIONARY STATS ARE GATHER
exec dbms_stats.gather_schema_stats('SCOTT');
exec dbms_stats.gather_index_stats('SYS','I_OBJ#');
exec dbms_stats.gather_index_stats('SYS','I_FILE#_BLOCK#');
exec dbms_stats.gather_index_stats('SYS','I_TS#');
exec dbms_stats.gather_index_stats('SYS','I_USER#');
exec dbms_stats.gather_index_stats('SYS','I_TOID_VERSION#');
exec dbms_stats.gather_index_stats('SYS','I_MLOG#');
exec dbms_stats.gather_index_stats('SYS','I_RG#');5.3 不需要收集统计信息的情况
数据量变化非常频繁的表
• 随时间表的数据量变化非常快的表,当表中具有代表性数据量时收集统计信息
锁定统计信息以确保统计信息收集作业不会覆盖代表性统计信息
• 比如排队信息表,开始表为空,然后数据入表, 处理数据,处理完成表为空11g版本中的全局临时表
• 用来临时存放中间结果
• 一些会话有很多记录,另外一些可能只有少数记录12c中全局临时表默认包含 session 级别统计信息
• DBMS_STATS 设置 GLOBAL_TEMP_TABLE_STATS 为 SHARED 或者 SESSION中间表
• 一次写入,一次读取,然后被 Truncate 或 deleted
• 常见于 ETL 过程中的中间表
一次写入,一次读取,然后被 Truncate 或 deleted,这样的表无需收集统计信息,否则会增加 ETL 的时间,建议使用高级别的动态采样
• 通过 对中间表使用 dynamic_sampling hint 或修改 session 参数
select /*+ dynamic_sampling(t 2)*/ * from t_jiekexu t where address_change='Y';参考链接【Oracle 公益课堂 Oracle 统计信息管理】 https://www.bilibili.com/video/BV1nc411V7zh/?share_source=copy_web&vd_source=9f857c2d20b44dcbf6ea70def4b2f83d
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/DBMS_STATS.html#GUID-01FAB8ED-E4A3-4C3E-8FE2-88717DCDDA06
中亦云课堂第 40 期- Oracle 统计信息使用专题分享
全文完,希望可以帮到正在阅读的你,如果觉得此文对你有帮助,可以分享给你身边的
朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我公众号【JiekeXu DBA之路】,第一时间一起学习新知识!以下三个地址可以
找到我,其他地址均属于盗版侵权爬取我的文章,而且代码格式、图片等均有错乱,不方
便阅读,欢迎来我公众号或者墨天轮地址关注我,第一时间收获最新消息。
————————————————————————————
公众号:JiekeXu DBA之路
CSDN :https://blog.csdn.net/JiekeXu
墨天轮:https://www.modb.pro/u/4347
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————

分享几个数据库备份脚本
Oracle 表碎片检查及整理方案
OGG|Oracle GoldenGate 基础2022 年公众号历史文章合集整理Oracle 19c RAC 遇到的几个问题
OGG|Oracle 数据迁移后比对一致性