目录
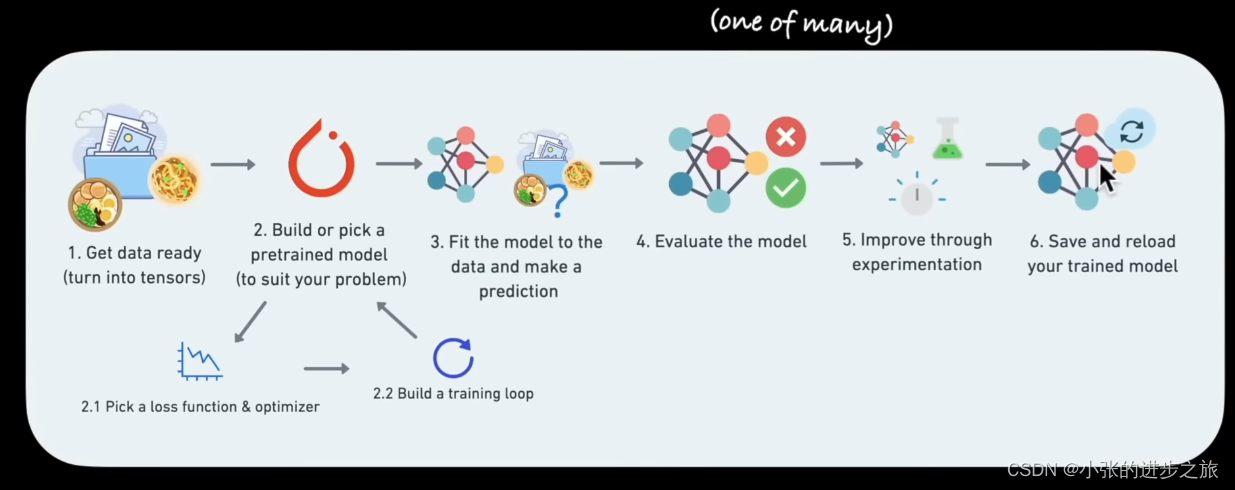
整体的流程图
 PyTorch里面的神经网络都在torch.nn里面: torch.nn — PyTorch 2.0 documentation
PyTorch里面的神经网络都在torch.nn里面: torch.nn — PyTorch 2.0 documentation
里面的各种神经网络都是由专业的软件工程师来构建的.
在使用的过程中如果有问题的话其实都可以在PyTorch的Github论坛中和其他人进行讨论
#import the package
import torch
from torch import nn
import matplotlib.pyplot as plt
# Data (preparing and loading)
#1.1 Create a train/test split 1.1 对数据进行分割
train_split=int(0.8*len(X))
X_train, y_train=X[:train_split]
X_test, y_test = X[train_split:], y[train_split:]
#1.2 Visualize data 1.2 把数据可视化
def plot_predictions(train_data=X_train, train_labels=y_train,
test_data=X_test, text_labels = y_test,
predictions=None):
plt.figure(figsize=(10,7))
#plot trainning data in blue
plt.scatter(train_data, train_labels, c="b", s=4, label="Training data")
#plot test data in green
plt.scatter(test_data, test_labels, c="g", s=4, label="Testing data")
#if predictions is not None:
#plot the predictions if they exist
plt.scatter(text_data, predictions, c="b", label="Predictions")1. 数据获取
数据的格式
数据可以是任何形式的数据: Excel spreadsheet; 图片, 视频, 音频, DNA,文本
数据的分类:
1) 训练数据(Training set) 用来构建模型
2) 验证数据(Validation set)
3) 测试数据(test set)
一般以上数据的比例为图中所示:

2. 构建模型
在构建模型的时候要使用class进行模型的构建,如果没有基础,最好在以下网址上先进行学习一下OOP的相关知识:
Object-Oriented Programming (OOP) in Python 3 – Real Python
感觉在这个博文里也介绍的非常详细了:python——class类和方法的用法详解_python class_Irving.Gao的博客-CSDN博客
# Build model
from torch import nn
# 2.1 Creat linear regression model class
class LinearRegressionModel(nn.Module): #nn.module是PyTorch中基础的modules
def_init_(self):
super()._init_()
self.weights = nn.Parameter(torch.randn(1, requires_grad=True,
dtype=torch.float))
self.bias = nn.Parameter(torch.randn(1, requires_grad=True,
dtype=torch.float))
#Forward method to define the computation in the model
def forward(self,x:torch.Tensor)->torch.Tensor:
return self.weight*x+self.bias
构建模型的思路:
首先生成随机的数值(在回归里包括weight和bias),然后通过不断调整来得到最合适的数值来构建模型. 调整的算法主要包括以下:
1. 梯度下降法(Gradient descent) 2. 反馈 (backpropagation)

构建模型的一些关键
用于模型的构建:
- torch.nn: contains all of the buildings for computional graphs (a neural network can be considered a computational graph)
- torch.nn.Parameter; what parameters should our model try and learn, often a Pytorch layer from torch.nn will set these for us
- torch.nn.Module: The base class for all neural network modules, if you subclass it, you should overwrite forward() 所有神经网络模块的基类,如果你将其子类化,你应该覆盖forward()
用于模型的优化
- torch.optim: this where the optimizers in PyTorch live, they will help with gradient descent
其他
- def forward(): all nn.Module subclasses require you to overwrite foward(), this method defines what happens in the forward computation
检查模型的内部结构
在构建了模型以后, 再看一下模型内部的结构是如何的
一般使用.parameters( )来看
# create a random seed
torch.manual_seed(42)
# create an instance of the model (this is a subclass of nn.Module)
model_0 = LinerRegressionModel()
#Check out the parameters
list(model_0.parameters())结果如下:

如果要用字典来查看的话:
model_0.state_dict() 得到的结果如下: 
检查模型的准确性
预测, 将测试集的数据带入模型看预测的效果如何, torch.inference_mode( ) 和 torch.no_grad( ) 两个方法都是比较常用的,但是torch.inference_mode( )是用的比较常见的.
#Make predictions with model
with torch.inference_mode():
y_preds = model_0 (X_test) #使用测试集的X来预测Y
#也有另外一个公式可以用于预测
with torch.no_grad():
y_preds = model_0(X_test)3. 训练模型
训练模型的流程其实主要就是将原本随机的参数的准确性提高, 然后让模型具有更好的预测性
一些基本的概念:
- 损失函数(Loss function) 用于测量你的模型的不准确性有多高,一般得到的数值越低越好
损失函数的种类很多, 比如说, nn.L1loss, nn.MSELoss, nn.CrossEntropyLoss, nn.CTCLoss
- Optimizer: Takes into account the loss of a model and adjust the model's parameters
所以在进行训练的时候,我们需要训练集和测试集来进行训练
3.1 设定损失函数和optimizer
# Setup a loss function
loss_fn = nn.L1Loss()
# Setup an optimizer (stochastic gradient descent)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
在optimizer中学习率 (learning rate)是一个很重要的参数, 一般是根据经验来得出的数据, 数值越大代表每次变化越大, 数值越小,代表每次变化越小.
那么在构建模型的时候,应该如何选择损失函数和optimizer呢? 应该要根据实际问题的情况来具体选择. 比如说对于回归的问题,可以使用nn.L1Loss( ) 或者 torch.optim.SGD( )已经足够了,但是对于分类来说, nn.BCELoss( )可能比较好一点.
比如说损失函数L1Loss就是以MAE作为计算的.
 3.2 构建一个training loop
3.2 构建一个training loop
在构建training loop流程的一些事项
- 循环通过数据 Loop through the data
- 前向传递(这涉及到数据在我们模型的'forward()'函数中的移动)--也称为前向传播 Forward pass (this involves data moving through our model's 'forward()' function)-also called forward propagation
- 计算损失(将前向传递的预测值与地面真实标签进行比较)Calculate the loss (compare forward pass predictions to ground true labels)
- 优化器零梯度 Optimizer zero grad
- 通过网络向后损失,计算我们模型的每个参数相对于损失的梯度 Loss backwards through the network to calculate the gradients of each of the parameters of our model with respect to the loss
- 优化器步骤--使用优化器来调整我们模型的参数,试图改善损失Optimizer step - use the optimizer to adjust our model's parameters to try and improve the loss
# An epoch is one loop through the data (this is a hyperparameter because we've set it
epochs=100 #根据实际情况来确定数值
### Trainning
# 1. Loop through the data
for epoch in range(epochs):
model_0.train( ) # train the model in PyTorch set all paragrameters that require gradients to require gradients
# 2. Forward pass
y_pred = model_0(X_train)
# 3. calculate the loss
loss = loss_fn(y_pred, y_train)
# 4. Optimizer zero grad
loss.backward()
# 5. Perform backprogation on the loss with respect to the parameters of the model
loss.backward()
# 6. Step the optimizer (perform gradient descent)
optimizer.step() 3.3 构建一个Testing Loop
### Testing
model_0.eval( ) # turn off different settings in the model not needed for evaluation/testing(dropout/batch norm layer)
with torch.inference_mode(): #turns off gradient tracking & a couple more things behind the scenes 有了这一步所以所以在测试的时候不做任何的学习
#with torch.no_grad(): # 在旧的版本可能是torch.no_grad()
#1. Do the forward pass
test_pred= model_0 (X_test)
#2. Calculate the loss
test_loss = loss_fn (test_pred, y_test)
# print out what's "happening"
if epoch%10 == 0: 每10次进行一次的Loss的确认
print (f"Epoch: {epoch}|Loss: {loss}| Test loss: {test_loss}")
#Print out model state_dict( )
print(model_0.state_dict()) 4. 保存模型
三种主要用于保存模型的方法:
- “torch.save( )" allows you save a PyTorch object in Python's pickle format
- "torch.load( )" allows you load a saved PyTorch object
- "torch.nn. Module.load_state_dict( )', allows to load a model's saved state dictionary,也就是主要保存的是模型的参数
# Saving our PyTorch model
from pathlib import Path
#1. Create models directory
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exit_ok=True)
#2. Create model save path
MODEL_NAME = "01_pytorch_workflow_model_0.pth"
MODEL_SAVE_PATH = MODEL_PATH/MODEL_NAME
#3. Save the model state dict
print(f"Saving model to:{MODEL_SAVE_PATH}")
torch.save (obj=model_0.state_dict(), f=MODEL_SAVE_PATH).pth是PyTorch 保存模型的常见文件类型
5 加载模型
如果使用的是state_dict()来保存模型的话, 因为在保存模型的时候保存的是参数,所以在加载的时候也是加载的参数
#To load in a saved state_dict we have to instantiate a new instance of our model class
loaded_model_0 = LinearRegressionModel( )
# Load the saved state_dict of model_0 (this will update the new instance with updated parameters)把参数带入模型中
load_model_0.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
Referenece Video: https://www.youtube.com/watch?v=Z_ikDlimN6A&t=6412s