
前言
本文将会讲解 OpenStack 平台计算服务组件 Nova ,结合抽象概念和简单易懂的实战操作,帮助您更好的理解 Nova 计算服务在 OpenStack 中的作用
系统配置:宿主机 Ubuntu 20.04(WSL2)
简介
OpenStack
官网链接:Open Source Cloud Computing Infrastructure - OpenStack
OpenStack 是开源的云计算平台,用于构建和管理公有云和私有云基础设施。它提供了一组模块化的工具和服务,使用户能够创建和管理虚拟机、存储、网络、身份验证、镜像和其他云基础设施资源
我们知道 OpenStack 是 IaaS 层的云操作系统,OpenStack 为虚拟机提供并管理三大类资源:计算、网络和存储
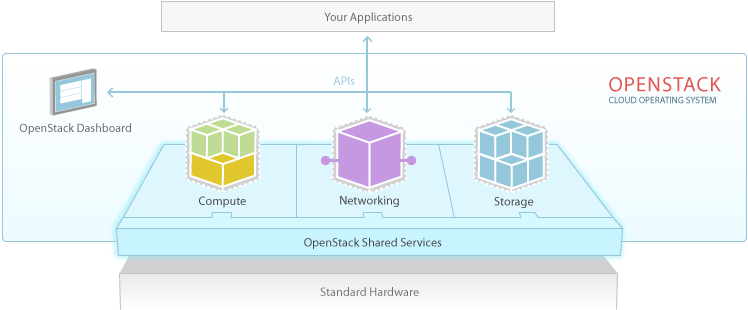
服务组件
官网服务组件介绍:Open Source Cloud Computing Platform Software - OpenStack
目前 OpenStack 官方展示服务多达三十种,但是这些服务我们一般不会全都使用,下面仅介绍主要服务和其中的核心服务
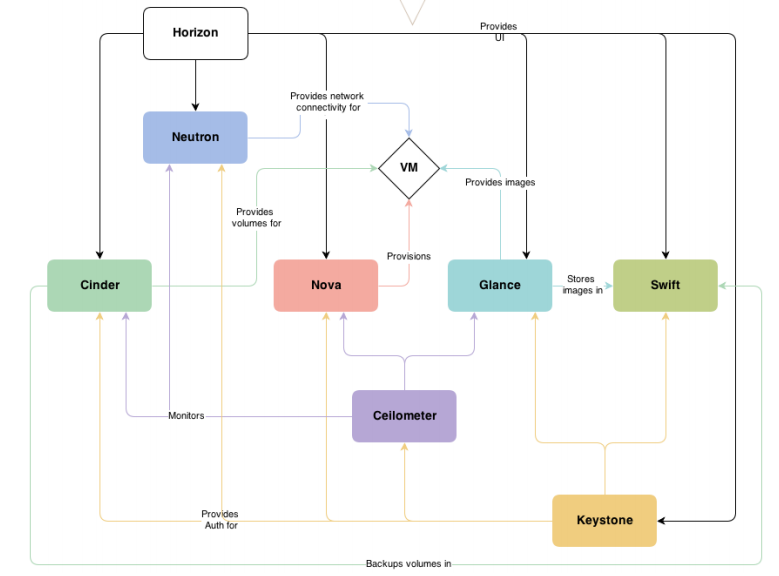
Nova:管理计算资源(核心)

Neutron:管理网络资源(核心)
Glance:为 VM 提供 OS 镜像,属于存储范畴(核心)
Cinder:块存储服务(核心)
Swift:对象存储服务
Keystone:身份认证服务(核心)
Ceilometer:监控服务
Horizon:Web 操作界面(核心)
Quantum:网络管理服务
节点组成
OpenStack 是分布式系统,由若干不同功能的节点(Node)组成
- 控制节点(Controller Node)
管理 OpenStack,其上运行的服务有 Keystone、Glance、Horizon 以及 Nova 和 Neutron 中管理相关的组件。 控制节点也运行支持 OpenStack 的服务,例如 SQL 数据库(通常是 MySQL)、消息队列(通常是 RabbitMQ)和网络时间服务 NTP。 - 网络节点(Network Node)
其上运行的服务为 Neutron。 为 OpenStack 提供 L2 和 L3 网络。 包括虚拟机网络、DHCP、路由、NAT 等。 - 存储节点(Storage Node)
提供块存储(Cinder)或对象存储(Swift)服务。 - 计算节点(Compute Node)
其上运行 Hypervisor(默认使用 KVM)。 同时运行 Neutron 服务的 agent,为虚拟机提供网络支持。
为了拓扑简洁同时功能完备,可以部署下面两种虚拟机节点
- devstack-controller:控制节点 + 网络节点 + 块存储节点 + 计算节点
- devstack-compute:计算节点
虚拟化
注:本章节为前置预备知识,可以酌情跳过
方式
虚拟化是云计算的基础,虚拟化使得在一台物理服务器上可以跑多台虚拟机,虚拟机共享物理机的 CPU、内存、IO 硬件资源,但逻辑上虚拟机之间是相互隔离的,物理机我们一般称为宿主机(Host),宿主机上面的虚拟机称为客户机(Guest)
其中主要是通过 Hypervisor 实现 Host 的硬件虚拟化 ,根据 Hypervisor 的实现方式和所处的位置,虚拟化又分为两种:1型虚拟化和2型虚拟化
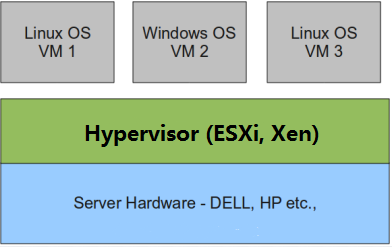
1型虚拟化
Hypervisor 直接安装在物理机上,多个虚拟机在 Hypervisor 上运行。Hypervisor 实现方式一般是特殊定制的 Linux 系统。
Xen 和 VMWare 的 ESXi 都属于这个类型
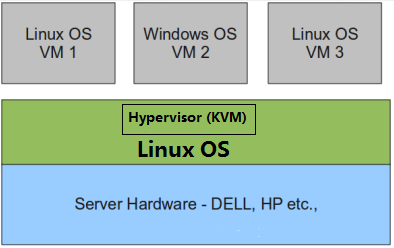
2型虚拟化
物理机上首先安装常规的操作系统,比如 Redhat、Ubuntu 和 Windows。Hypervisor 作为 OS 上的一个程序模块运行,并对管理虚拟机进行管理。
KVM、VirtualBox 和 VMWare Workstation 都属于这个类型
对比
1 型虚拟化对硬件虚拟化功能进行了特别优化,性能上比 2 型要高
2 型虚拟化因为基于普通的操作系统,会比较灵活,比如支持虚拟机嵌套。嵌套意味着可以在 KVM 虚拟机中再运行 KVM
KVM
官网链接:KVM (linux-kvm.org)
本次将会使用 **KVM(Kernel-Based Virtual Machine)**作为虚拟化工具,顾名思义,KVM 是基于 Linux 内核实现的
KVM 内核模块叫 kvm.ko,只用于管理虚拟 CPU 和内存,IO 部分的虚拟化(比如存储和网络设备)需要交给 Linux 内核和 QEMU 来实现
注:博主下面使用的是基于 WSL2 的虚拟机作为宿主机,如果您是使用 VMWare Workstation 创建的虚拟机作为宿主机,不保证正确,毕竟 WSL2 和 VMWare Workstation 两种虚拟化方式不同
Libvirt
官网链接:libvirt: The virtualization API
注:此处仅会简单讲解,后面会详细讲解 Libvirt 体系架构
Libvirt 是目前使用最为广泛的对KVM虚拟机进行管理的工具,除了能管理 KVM 这种 Hypervisor,还能管理 Xen,VirtualBox 等。OpenStack 底层也使用 Libvirt
主要包含下面三部分:后台 daemon 程序 libvirtd、API 库和命令行工具 virsh
- libvirtd 是服务程序,接收和处理 API 请求
- API 库使得其他人可以开发基于 Libvirt 的高级工具,比如 virt-manager,这是个图形化的 KVM 管理工具,后面我们也会介绍
- virsh 是我们经常要用的 KVM 命令行工具,后面会有使用的示例
注:如果你使用的是原生不支持 GUI 的虚拟化方式,需要使用 VcXsrv,之前博主写过相应文章,直接主页搜索 “『GUI界面』传输” 安装配置即可
安装
验证 CPU 是否支持硬件虚拟化
注:数字大于0,则代表CPU支持硬件虚拟化,反之则不支持
grep -Eoc '(vmx|svm)' /proc/cpuinfo
检查 VT 是否在 BIOS 中启用
# 安装
apt-get install cpu-checker -y
# 执行
kvm-ok
然后执行之后输出如下内容即为成功
INFO: /dev/kvm exists
KVM acceleration can be used
执行如下命令安装 KVM 相关包
sudo apt-get install qemu-kvm qemu-system Libvirt-bin virt-manager bridge-utils vlan -y
然后下面是 libvritd 的相关命令,可以启动服务和设置开机自启动服务
systemctl start libvirtd
systemctl enable libvirtd
# 查看虚拟化启动服务和自启动状态
systemctl list-unit-files |grep libvirtd.service
验证 libvirtd 是否启用,输出 active 表示启用
systemctl is-active libvirtd
验证 kvm,输出 kvm_intel、kvm 表示安装成功(但是我没有成功输出也暂时没有影响)
lsmod | grep kvm
创建虚机
这里我们使用小型虚拟机镜像 CirrOS,比较适合测试学习
镜像下载首页:Index of / (cirros-cloud.net)
镜像下载地址:cirros-0.3.3-x86_64-disk.img (cirros-cloud.net)
然后我们需要给镜像放在 /var/lib/Libvirt/images/ 目录下,这是 KVM 默认查找镜像文件的地方

启动虚拟机管理图形界面
virt-manager
然后按照如下步骤创建虚拟机,我们使用的是 .img 镜像文件,需要选择第四项,如果您使用的是 ISO 镜像需要选择第一项
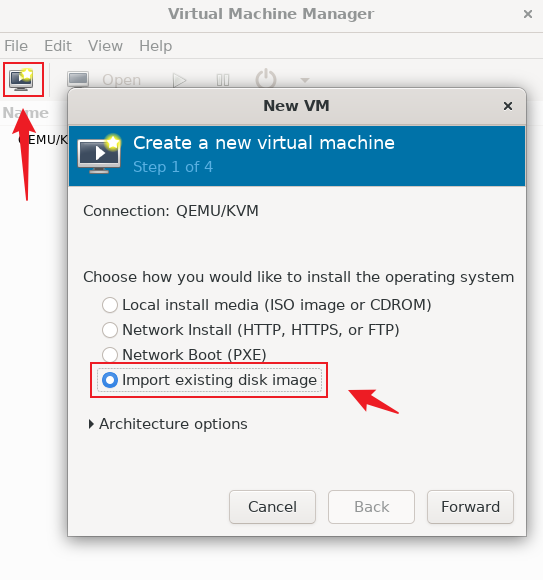
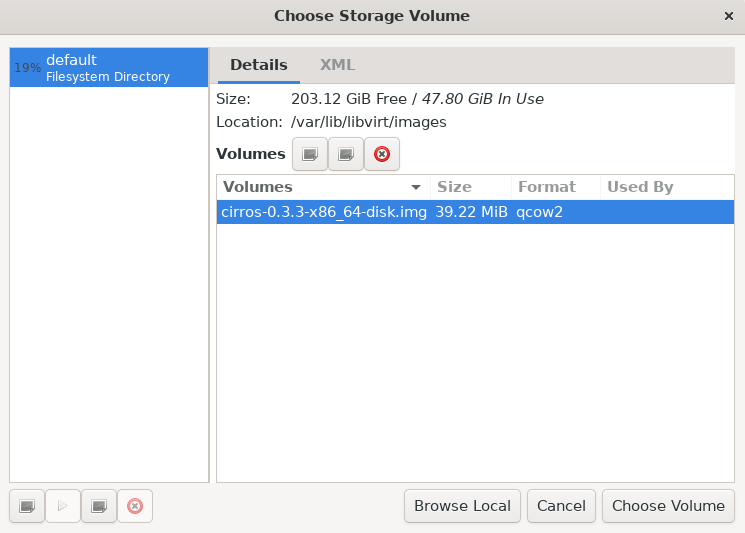
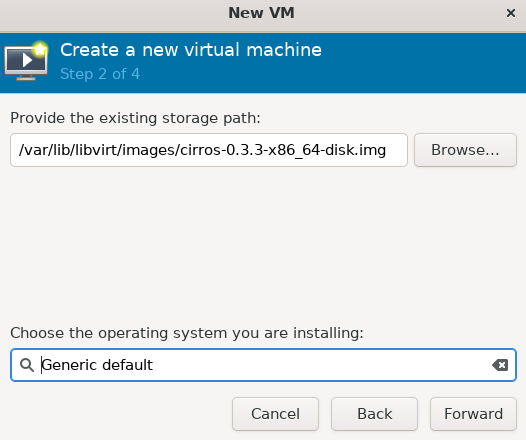
后续都是默认即可
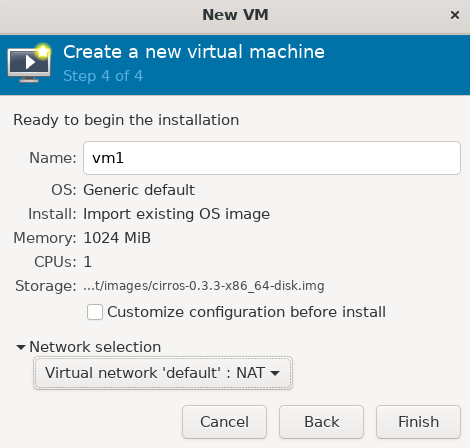
此时回到主页,我们可以看到 vm1 虚拟机已经创建成功
我们可以使用 virsh 管理虚机,比如使用如下命令查看宿主机上的虚机
# 执行如下
virsh list
# 输出列表
Id Name State
----------------------
1 vm1 running
问题
如果您不是最新的 WSL2,可能没有默认启动 systemd,需要使用如下步骤开启
git clone https://github.com/DamionGans/ubuntu-wsl2-systemd-script.git
cd ubuntu-wsl2-systemd-script/
bash ubuntu-wsl2-systemd-script.sh
# Enter your password and wait until the script has finished
但是在进入目录之后,您需要手动修改以下两个参数
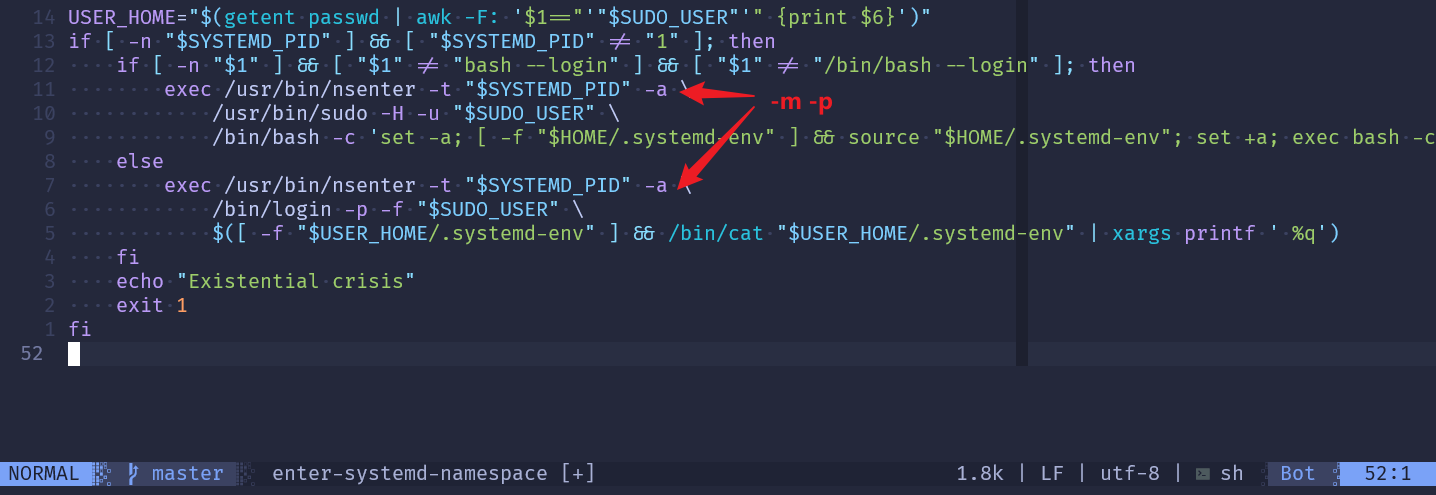
如果您的 WSL 版本为 0.67.6+(使用 wsl --version 检查版本),可以按照如下步骤开启 systemd
若要启用 systemd,请使用 sudo 通过管理员权限在文本编辑器中打开 wsl.conf 文件,并将以下行添加到 /etc/wsl.conf:
[boot]
systemd=true
然后,需要通过 PowerShell 使用 wsl.exe --shutdown 来关闭 WSL 发行版以重启 WSL 实例。 发行版重启后,systemd 应该就会运行了。 可以使用 systemctl list-unit-files --type=service 命令进行确认,该命令会显示服务的状态
DevStack
简介
DevStack(Develop OpenStack)是 OpenStack 社区提供的快速部署工具,是专为开发 OpenStack 量身打造的工具
DevStack 不依赖于任何自动化部署工具,纯 Bash 脚本实现,因此不需要花费大量时间耗在部署工具准备上,而只需要简单地编辑配置文件,然后运行脚本即可实现一键部署 OpenStack 环境。利用 DevStack 基本可以部署所有的 OpenStack 组件,但并不是所有的开发者都需要部署所有的服务,比如 Nova 开发者可能只需要部署核心组件就够了,其它服务比如 Swift、Heat、Sahara 等其实并不需要。DevStack 充分考虑这种情况,一开始的设计就是可扩展的,除了核心组件,其它组件都是以插件的形式提供,开发者只需要根据自己的需求定制配置自己的插件即可
部署
下面我们将会详解介绍如何单机部署 DevStack
我们需要添加用户
DevStack 应该以非 root 用户(但拥有 sudo 权限)执行,手动添加 stack 用户
# 添加 stack 用户
sudo useradd -s /bin/bash -d /opt/stack -m stack
# 授予 sudo 权限
echo "stack ALL=(ALL) NOPASSWD: ALL" | sudo tee /etc/sudoers.d/stack
# 以 stack 用户登录
sudo su - stack
然后配置 pip
# 创建文件夹
cd && mkdir .pip && cd .pip
# 创建并编辑配置文件
sudo vim pip.conf
# 添加如下配置
[global]
timeout = 6000
index-url = http://mirrors.aliyun.com/pypi/simple/
trusted-host = mirrors.aliyun.com
下载 DevStack(执行如下命令之前需要自行配置 GitHub SSH 密钥)
生成密钥命令:ssh-keygen -t rsa -C “stack”
git clone https://opendev.org/openstack/devstack -b stable/ussuri
然后我们进入 devstack 文件夹内部,然后创建配置文件 local.conf,添加如下内容
解释参数:
ADMIN_PASSWORD:OpenStack 用户admin和demo的密码DATABASE_PASSWORD:MySQL 管理员用户密码RABBIT_PASSWORD:RabbitMQ 密码SERVICE_PASSWORD:服务组件和 KeyStone 交互的密码GIT_BASE:源代码托管服务器HOST_IP:绑定的 IP 地址
[[local|localrc]]
HOST_IP=172.22.124.174
GIT_BASE=https://opendev.org
ADMIN_PASSWORD=111111
DATABASE_PASSWORD=$ADMIN_PASSWORD
RABBIT_PASSWORD=$ADMIN_PASSWORD
SERVICE_PASSWORD=$ADMIN_PASSWORD
执行目录内脚本
# 安装
./stack.sh
# 停止
./unstack.sh
# 停止并删除配置
./clean.sh
如果安装中出现如下错误,可以执行命令 FORCE=yes ./stack.sh 来进行安装
[ERROR] ./stack.sh:227 If you wish to run this script anyway run with FORCE=yes
/opt/stack/devstack/functions-common: line 241: /opt/stack/logs/error.log: No such file or directory
Nova
官方仓库:openstack/nova: OpenStack Compute (Nova). Mirror of code maintained at opendev.org. (github.com)
简介
现在我们开始进入本篇文章核心主题,管理虚拟机实例的计算服务 Nova
Nova 处理 OpenStack 云中实例(instances)生命周期的所有活动,其为负责管理计算资源、网络、认证、所需可扩展性的平台
但是 Nova 并不具有虚拟化能力,它需要使用 Libvirt API 来与被支持的 Hypervisor 交互
组件
1.API Server(Nova-Api)
API Server 对外提供与云基础设施交互的接口,也是外部可用于管理基础设施的唯一组件
2.Message Queue(Rabbit MQ Server)
OpenStack 节点之间通过消息队列使用 AMQP(Advanced Message Queue Protocol)完成通信。
3.Compute Worker(Nova-Compute)
Compute Worker 管理实例生命周期,通过 Message Queue 接收实例生命周期管理的请求,并承担操作工作。
4.Network Controller(Nova-Network)
Network Controller 处理主机的网络配置,包括 IP 地址分配、为项目配置 VLAN、实现安全组、配置计算节点网络。
5.Volume Workers(Nova-Volume)
Volume Worker 用来管理基于 LVM(Logical Volume Manager)的实例卷。Volume Worker 有卷的相关功能,例如新建卷、删除卷、为实例附加卷、为实例分离卷。
6.Scheduler(Nova-Scheduler)
调度器 Scheduler 把 Nova-API 调用映射为 OpenStack 组件。调度器作为 Nova-Schedule 守护进程运行,通过恰当的调度算法从可用资源池获得计算服务。
AMQP
AMQP(Advanced Message Queuing Protocol,高级消息队列协议),是应用层协议的开放标准,为面向消息的中间件而设计
主要用于实现存储与转发交换器发送来的消息,队列同时也具备灵活的生命周期属性配置,可实现队列的持久保存、临时驻留与自动删除
基本工作流程:
发布者(Publisher)发布消息(Message),经由交换机(Exchange)
交换机根据路由规则将收到的消息分发给与该交换机绑定的队列(Queue)
最后 AMQP 代理会将消息投递给订阅了此队列的消费者,或者消费者按照需求自行获取
图示如下:
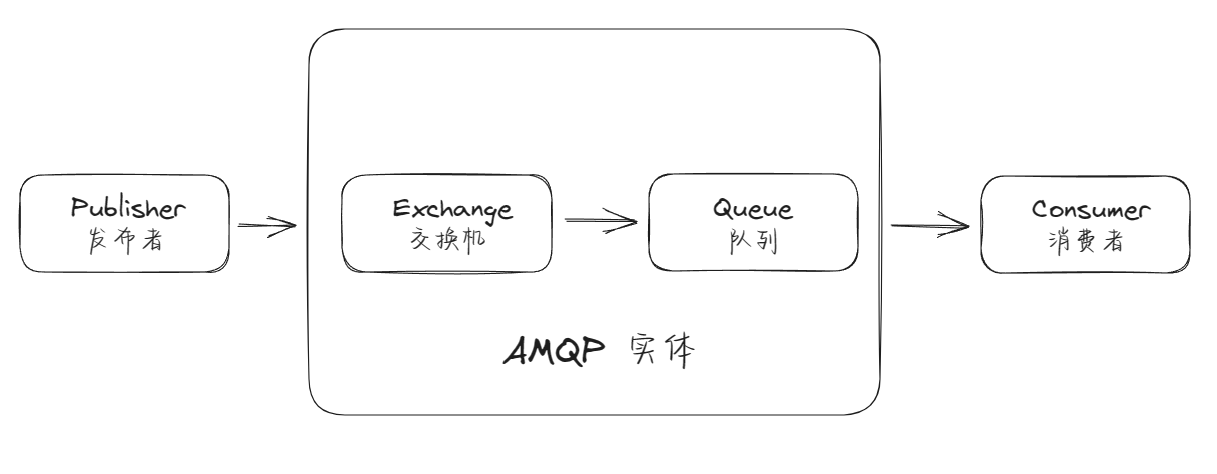
交换器
交换机是用来发送消息的 AMQP 实体
交换机拿到一个消息之后将它路由给一个或零个队列
它使用哪种路由算法是由交换机类型和绑定(Bindings)规则所决定的
AMQP 0-9-1 的代理提供了四种交换机
Fanout exchange(扇型交换机 / 广播式交换器)
该类交换器不分析所接收到消息中的Routing Key,默认将消息转发到所有与该交换器绑定的队列中去
广播式交换器最为简单,转发效率最高,但是安全性较低,消费者应用程序可获取本不属于自己的消息
Direct exchange(直连交换机)
直接式交换器的转发效率较高,安全性较好,但是缺乏灵活性,系统配置量较大
相对广播交换器来说,直接交换器可以给我们带来更多的灵活性
直接交换器的路由算法很简单:一个消息的 routing_key 完全匹配一个队列的 binding_key,就将这个消息路由到该队列
绑定的关键字将队列和交换器绑定到一起。当消息的 routing_key 和多个绑定关键字匹配时消息可能会被发送到多个队列中
Topic exchange(主题交换机)
**主题交换机(topic exchanges)**中,队列通过路由键绑定到交换机上,然后,交换机根据消息里的路由值,将消息路由给一个或多个绑定队列
扇型交换机和主题交换机异同:
- 对于扇型交换机路由键是没有意义的,只要有消息,它都发送到它绑定的所有队列上
- 对于主题交换机,路由规则由路由键决定,只有满足路由键的规则,消息才可以路由到对应的队列上
Headers exchange(头交换机)
类似主题交换机,但是头交换机使用多个消息属性来代替路由键建立路由规则。通过判断消息头的值能否与指定的绑定相匹配来确立路由规则。
此交换机有个重要参数:”x-match”
- 当”x-match”为“any”时,消息头的任意一个值被匹配就可以满足条件
- 当”x-match”设置为“all”的时候,就需要消息头的所有值都匹配成功
队列
我们知道 Nova 包含众多的子服务,这些子服务之间需要相互协调和通信。 为解耦子服务,Nova 通过 Message Queue 作为子服务的信息中转站。 所以在架构图上我们看到了子服务之间没有直接的连线,它们都通过 Message Queue 联系
注:OpenStack 默认是用 RabbitMQ 作为 Message Queue
RPC 调用
Nova 基于 RabbitMQ 实现两种 RPC 调用
Nova 模块大致分为:
Invoker 模块:主要功能是向消息队列中发送系统请求消息,如Nova-API和Nova-Scheduler
Worker 模块:从消息队列中获取Invoker模块发送的系统请求消息以及向Invoker模块回复系统响应消息,如Nova-Compute、Nova-Volume和Nova-Network
RPC.CALL(基于请求与响应方式)
初始化一个 Topic Publisher 来发送消息请求到队列系统;在真正执行消息发布的动作前,立即创建一个 Direct Consumer 来等待回复消息;
一旦消息被 exchange 解包, 它就会被 routing key (例如 ‘topic.host’) 中指定的 Topic Consumer 获取,并且被传递到负责该任务的 Worker;
一旦该任务完成,就会生成一个 Direct Publisher 来发送回复消息到队列系统;
一旦消息被 exchange 解包,它就会被 routing key (例如 ‘msg_id’) 中指定的 Direct Consumer 获取,并且被传递到 Invoker
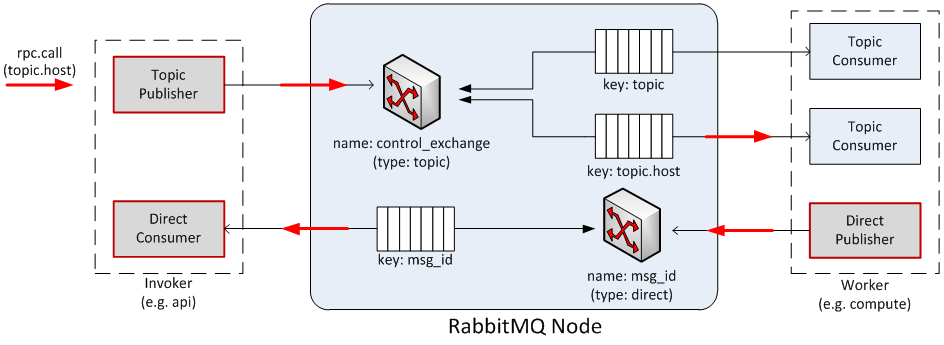
RPC.CAST(只是提供单向请求)
初始化 Topic Publisher 来发送消息请求到队列系统
一旦消息被 exchange 解包,它就会被 routing key (例如 ‘topic’) 中指定的 Topic Consumer 获取,并且被传递到负责该任务的 Worker
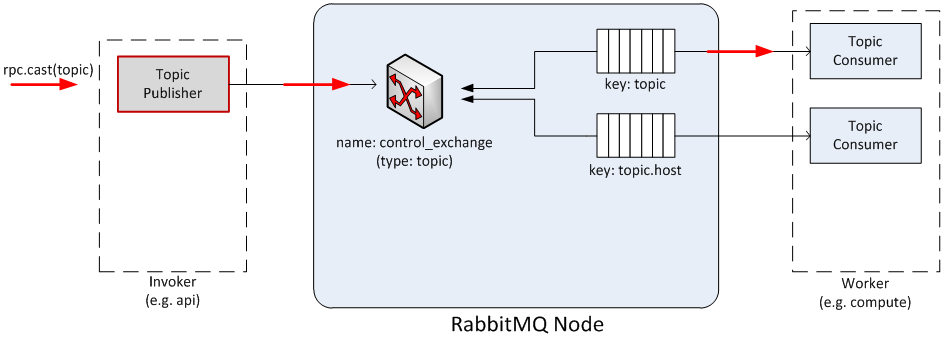
Libvirt
产生原因
各种不同的虚拟化技术都提供了基本的管理工具,比如启动、停用、配置、连接控制台等。这样在构建云管理的时候就存在两个问题
- 如果采用混合虚拟技术,上层就需要对不同的虚拟化技术调用不同管理工具,很是麻烦
- 可能有新的虚拟化技术更加符合现在的应用场景,需要迁移过去。这样管理平台就需要大幅改动
Libvirt 的主要目标是为各种虚拟化工具提供一套方便、可靠的编程接口,用一种单一的方式管理多种不同的虚拟化提供方式
体系架构
无 Libvirt 管理时虚拟机运行架构如下

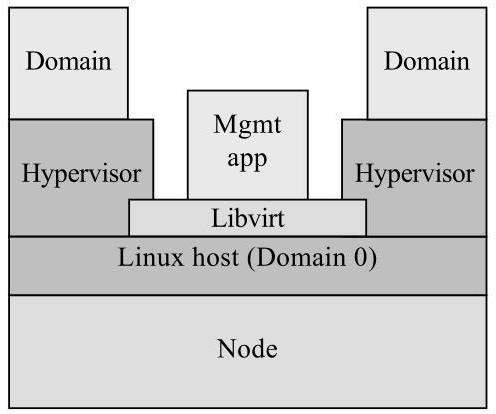
使用 Libvirt API 管理时虚拟机运行架构如下
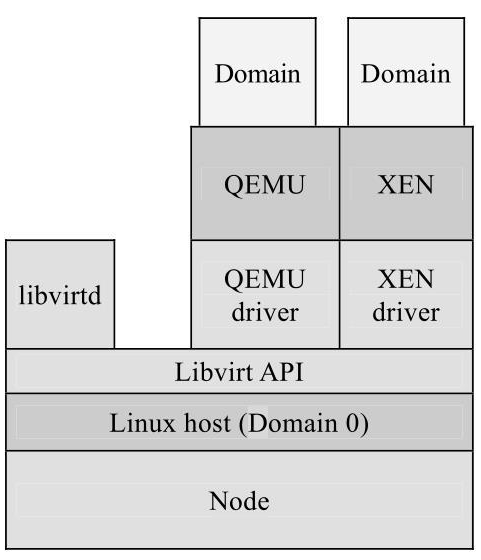
Libvirt 的控制方式有两种:
①管理应用程序和域位于同一结点上。管理应用程序通过 Libvirt 工作,以控制本地域
②管理应用程序和域位于不同结点上。该模式使用一种运行于远程结点上、名为 Libvirtd 的特殊守护进程。当在新结点上安装 Libvirt 时该程序会自动启动,且可自动确定本地虚拟机监控程序并为其安装驱动程序
该管理应用程序通过一种通用协议从本地 Libvirt 连接到远程 libvirtd
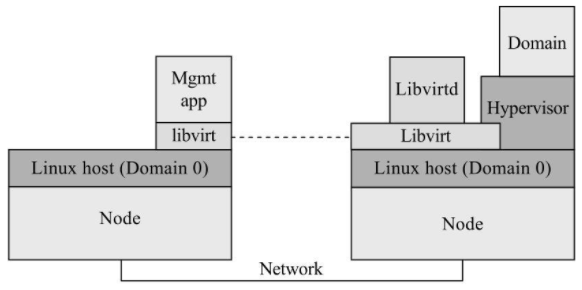 ****
****
参考链接
- 每天5分钟玩转 OPENSTACK系列教程 – Jimmy’s Blog (xjimmy.com)
- ubuntu20.04 从安装 kvm、qemu、Libvirt 到进入虚拟机 博客园 (cnblogs.com)
- 如何在 Ubuntu 20.04 上安装 KVM-腾讯云开发者社区-腾讯云 (tencent.com)
- WSL2 Ubuntu KVM踩坑记录 - 知乎 (zhihu.com)
- Windows Linux子系统安装:配置图形界面、中文环境、vscode - 知乎 (zhihu.com)
- DevStack - 深入理解OpenStack自动化部署 (gitbook.io)
- 深入理解 AMQP 协议-腾讯云开发者社区-腾讯云 (tencent.com)
- Libvirt的体系结构-腾科IT教育官网 (togogo.net)
本文由博客一文多发平台 OpenWrite 发布!